↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
3D Gaussian Splatting (3DGS) is a popular method for novel view synthesis, but it generates a large number of Gaussians, leading to high memory usage. Existing pruning methods rely on pre-set parameters or thresholds, which require multiple training rounds to optimize for each scene and may vary across different scenes. This is inefficient and suboptimal.
This work introduces LP-3DGS, a novel learning-to-prune approach. LP-3DGS uses a trainable binary mask applied to the importance score of each Gaussian to automatically determine a favorable pruning ratio. Unlike previous methods, LP-3DGS leverages the Gumbel-Sigmoid method for a differentiable masking function. This makes LP-3DGS compatible with the existing 3DGS training process, resulting in a single round of training and an optimized pruning ratio that maximizes efficiency and quality. Extensive experiments show LP-3DGS consistently outperforms existing methods in various datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel learning-to-prune method for 3D Gaussian splatting, significantly improving efficiency without sacrificing rendering quality. It addresses a key limitation of existing methods by learning the optimal pruning ratio automatically, enhancing model compression and speed.
Visual Insights#
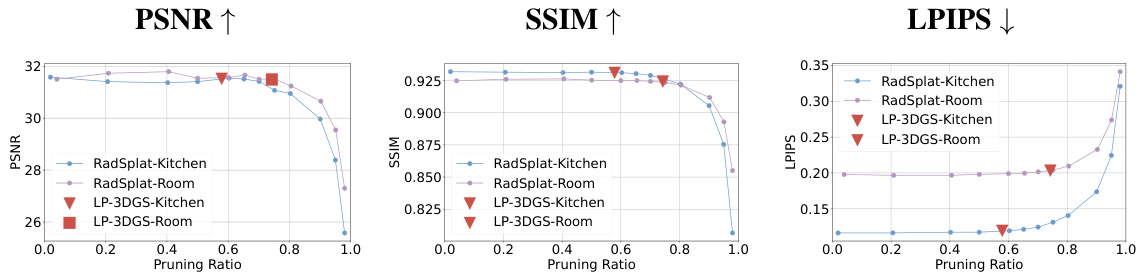
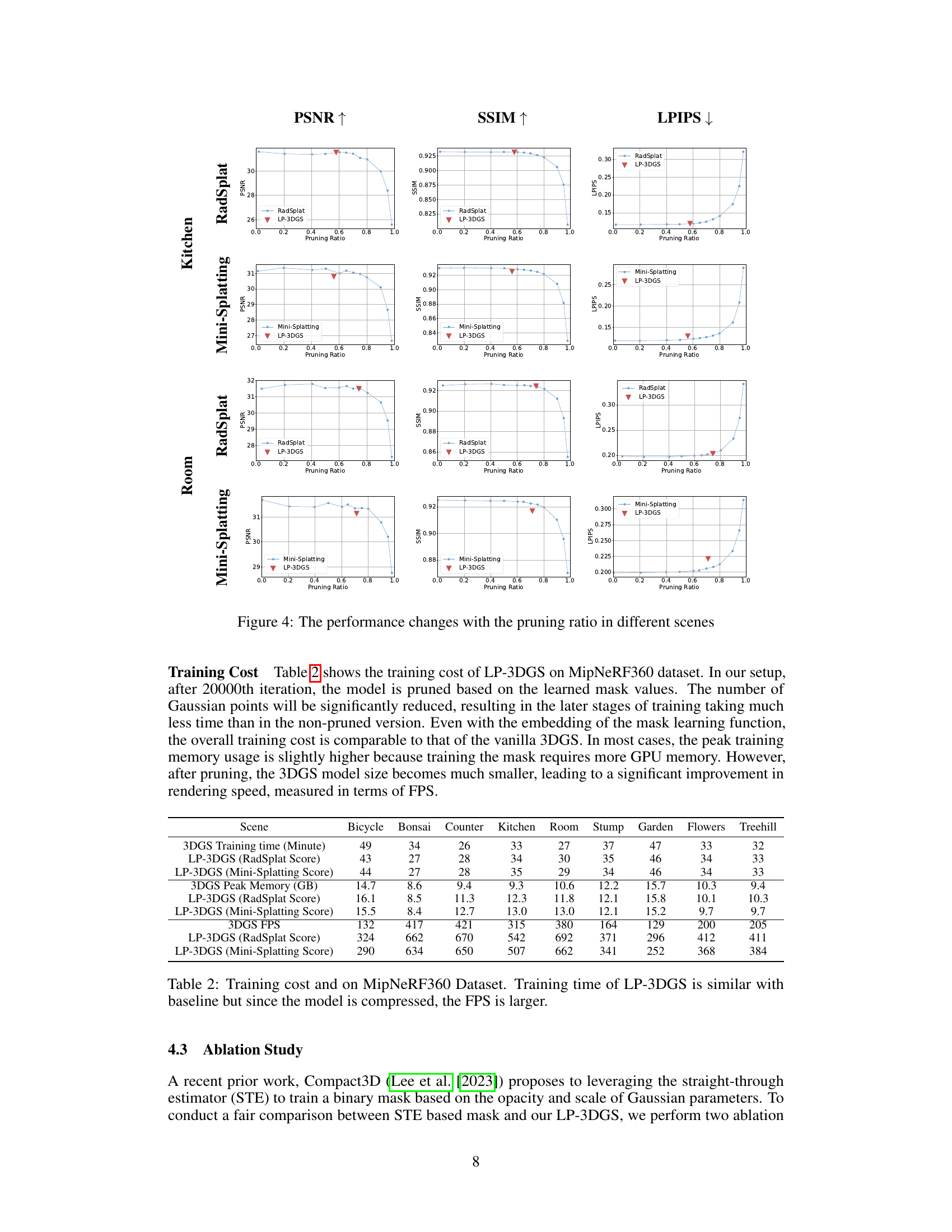
This figure demonstrates the impact of pruning ratios on the performance of RadSplat and LP-3DGS for novel view synthesis using the MipNeRF360 dataset. The blue and purple lines show how RadSplat’s performance (PSNR, SSIM, LPIPS) changes as the pruning ratio increases for two specific scenes (Kitchen and Room). In contrast, the red markers indicate that LP-3DGS consistently achieves a good balance between efficiency and high quality by automatically learning the optimal pruning ratio in a single training session, outperforming RadSplat’s multiple rounds of tuning.
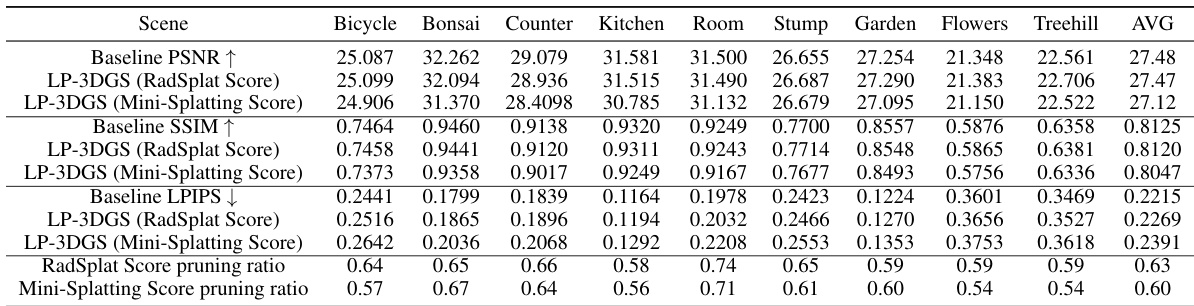
This table presents a quantitative comparison of the performance of LP-3DGS and baseline methods (RadSplat and Mini-Splatting) on the MipNeRF360 dataset. It shows the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and the achieved pruning ratio for each scene. The results demonstrate that LP-3DGS achieves comparable rendering quality while significantly reducing the model size compared to the baseline methods, showcasing its ability to adapt to different scene complexities and find optimal pruning ratios.
In-depth insights#
LP-3DGS Overview#
LP-3DGS, or Learning to Prune 3D Gaussian Splatting, presents a novel approach to optimize the efficiency of 3D Gaussian Splatting (3DGS) for novel view synthesis. The core innovation lies in learning a trainable binary mask rather than relying on pre-set thresholds for pruning redundant Gaussian points. This eliminates the need for multiple training rounds to find optimal pruning ratios, which is a significant drawback of existing methods. The method employs a differentiable Gumbel-Sigmoid function to make the masking process compatible with standard 3DGS training procedures. Results demonstrate a good balance between efficiency and quality, consistently outperforming existing pruning techniques while maintaining high rendering quality. This is achieved through a single training pass, significantly reducing training time and computational cost compared to hyperparameter tuning approaches. The compatibility with diverse importance score methods adds to its versatility and robustness.
Trainable Mask#
The concept of a “Trainable Mask” in the context of pruning 3D Gaussian Splatting (3DGS) models is a significant contribution towards improving efficiency without sacrificing rendering quality. Instead of relying on predefined, fixed thresholds for pruning redundant Gaussian points, a trainable mask learns to identify optimal pruning ratios directly during the model training process. This eliminates the need for laborious hyperparameter tuning across multiple training runs, a significant advantage of this method. The mask’s trainability allows the model to adapt to the specific characteristics of each scene, achieving a balance between model compactness and visual fidelity. The use of the Gumbel-Sigmoid function is crucial as it enables differentiability during backpropagation, thus allowing the mask to be learned end-to-end within the 3DGS framework. This contrasts with previous methods that employed less effective and less differentiable approximations (like the straight-through estimator) and represents a core innovation. The approach is shown to be compatible with existing importance scores used in 3DGS pruning, enhancing its versatility and practical applicability.
Pruning Strategies#
Effective pruning strategies are crucial for optimizing 3D Gaussian splatting. Naive methods often rely on pre-defined thresholds for pruning, which are scene-dependent and require extensive hyperparameter tuning. Learning-to-prune approaches offer a significant advantage, automatically learning optimal pruning ratios for individual scenes. This eliminates the need for manual tuning and multiple training rounds, leading to improved efficiency. However, the choice of importance score significantly influences the outcome. Different importance metrics can yield different optimal pruning ratios. Strategies that leverage differentiable masking functions, such as the Gumbel-Sigmoid method, are preferable as they allow for end-to-end training and avoid the limitations of non-differentiable methods. Careful consideration of the masking function and importance score selection is key to achieving a balance between efficient model compression and high-quality rendering. Further research could explore novel importance metrics and more sophisticated masking techniques to further improve pruning effectiveness in 3D Gaussian splatting.
Experimental Results#
The section titled “Experimental Results” would ideally present a rigorous evaluation of the proposed LP-3DGS model. It should begin by clearly defining the metrics used to assess performance, such as PSNR, SSIM, and LPIPS, alongside the datasets employed (MipNeRF360, Tanks & Temples, NeRF-Synthetic). A key aspect would be comparing LP-3DGS against relevant baselines, such as RadSplat and Mini-Splatting, possibly including other state-of-the-art (SOTA) novel view synthesis (NVS) methods. The results should be presented in a clear and organized manner, likely using tables and figures to showcase the quantitative performance differences across various metrics and datasets. Crucially, the discussion should delve into the impact of the learned pruning ratio on model size and computational efficiency, providing evidence of a favorable balance between efficiency gains and rendering quality. It would be beneficial to analyze the robustness of the method by varying hyperparameters or considering different scene complexities. Statistical significance testing is also expected to bolster the validity and reliability of the comparative analysis. Finally, the discussion should offer insightful interpretations of the findings, contextualizing the results within the broader field of NVS and highlighting the contributions of LP-3DGS.
Future Work#
Future research directions stemming from this work on LP-3DGS could explore several promising avenues. Improving the differentiability of the Gumbel-Sigmoid masking function is crucial, potentially by exploring alternative differentiable approximations to binary masks or refining the Gumbel-Softmax approach. Investigating other types of importance scores and their interplay with the trainable mask is key. Exploring different network architectures and loss functions for the trainable mask could enhance learning efficiency and accuracy. Extending the framework to handle more complex scenes and view synthesis tasks, such as dynamic scenes or scenes with significant occlusion, is another important direction. Finally, a thorough ablation study comparing different architectural choices for the trainable mask would provide deeper insights. Ultimately, these explorations would pave the way towards creating more efficient and versatile view synthesis methods.
More visual insights#
More on figures
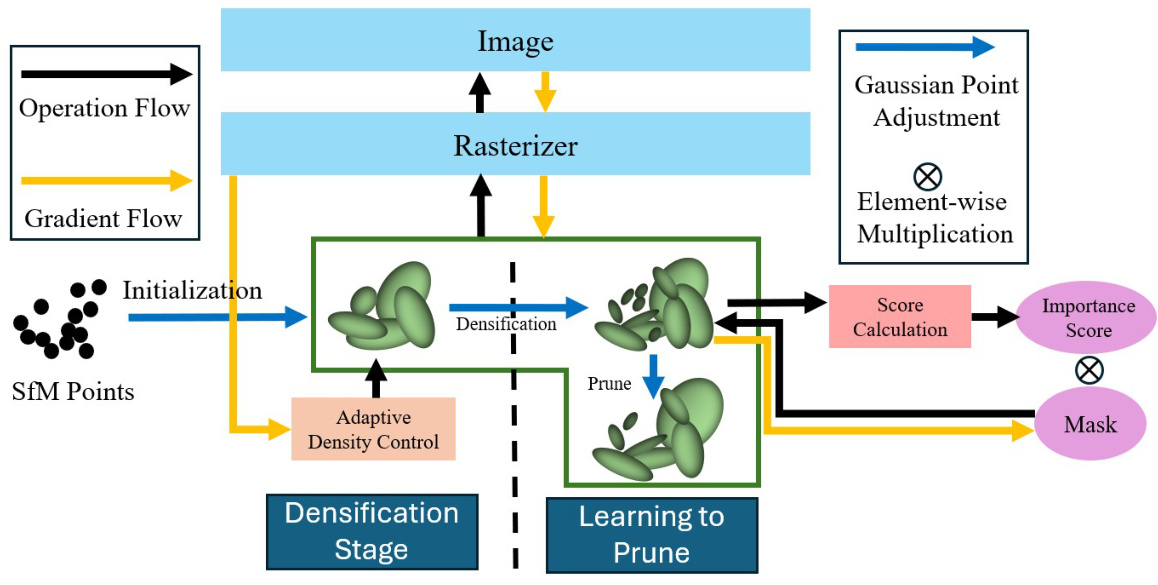
This figure illustrates the overall learning process of the proposed LP-3DGS method. The process is divided into two stages: densification and learning-to-prune. In the densification stage, the adaptive density control strategy is used to adjust the number of Gaussian points. Subsequently, in the learning-to-prune stage, a trainable mask is applied to the importance score to automatically find a favorable pruning ratio. The figure shows the flow of data and operations between different components in each stage, including initialization, densification, score calculation, element-wise multiplication of the score with the mask, and Gaussian point adjustment.
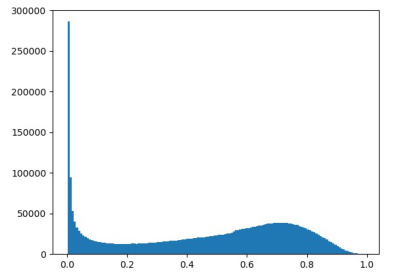
This figure compares the output distributions of the standard Sigmoid activation function and the Gumbel-Sigmoid function. The Gumbel-Sigmoid function is designed to produce outputs that are closer to either 0 or 1, making it a better approximation of a binary mask than the standard Sigmoid function. This is important because the authors are using this function to create a differentiable binary mask for pruning Gaussian points in their 3D Gaussian Splatting model.

This figure compares the output distributions of the Sigmoid and Gumbel-Sigmoid activation functions. The Sigmoid function produces a smooth curve with values spread across the entire range (0, 1). Conversely, the Gumbel-Sigmoid function concentrates the output around the values 0 and 1, resulting in a distribution much closer to a binary distribution. This demonstrates that the Gumbel-Sigmoid function is a better approximation for a binary mask which is necessary because the hard threshold function used for pruning in the traditional approach is not differentiable.
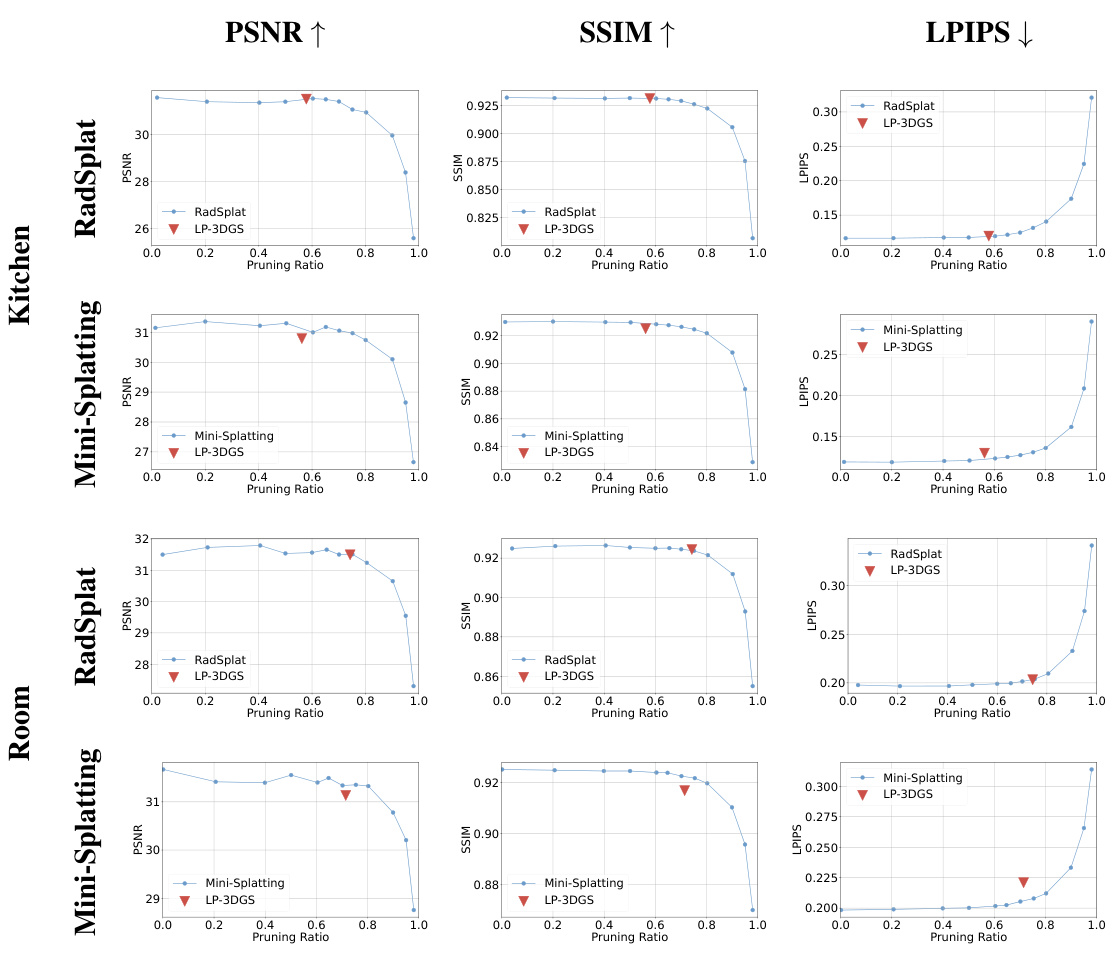
This figure demonstrates the performance of RadSplat and LP-3DGS on the MipNeRF360 dataset for Kitchen and Room scenes. RadSplat’s performance is shown with varying pruning ratios, highlighting the difficulty of manually finding the optimal ratio. LP-3DGS, in contrast, automatically finds a favorable pruning ratio in a single training session, achieving comparable or better performance than RadSplat.

This figure shows a comparison of rendered images from different methods on the MipNeRF360 dataset. The ‘Ground Truth’ column displays the real-world images. The ‘3DGS’ column shows images rendered using the original 3D Gaussian Splatting method. The ‘RadSplat’ and ‘Mini-Splatting’ columns depict the results obtained from pruning methods that were compared with LP-3DGS in the paper. The images in each row represent different scenes from the MipNeRF360 dataset, such as ‘Bicycle’, ‘Bonsai’, ‘Counter’, ‘Kitchen’, ‘Room’, ‘Stump’, ‘Garden’, ‘Flowers’, and ‘Treehill’. The figure visually demonstrates the relative performance and visual quality of each rendering method compared to the ground truth.

This figure shows the rendered images of different methods on the MipNeRF360 dataset. It visually compares the ground truth images with the results generated by 3DGS, RadSplat, and Mini-Splatting. The comparison highlights the visual quality differences and the impact of pruning on the rendering results. Each row represents a different scene from the dataset, demonstrating performance variations across different scenes.
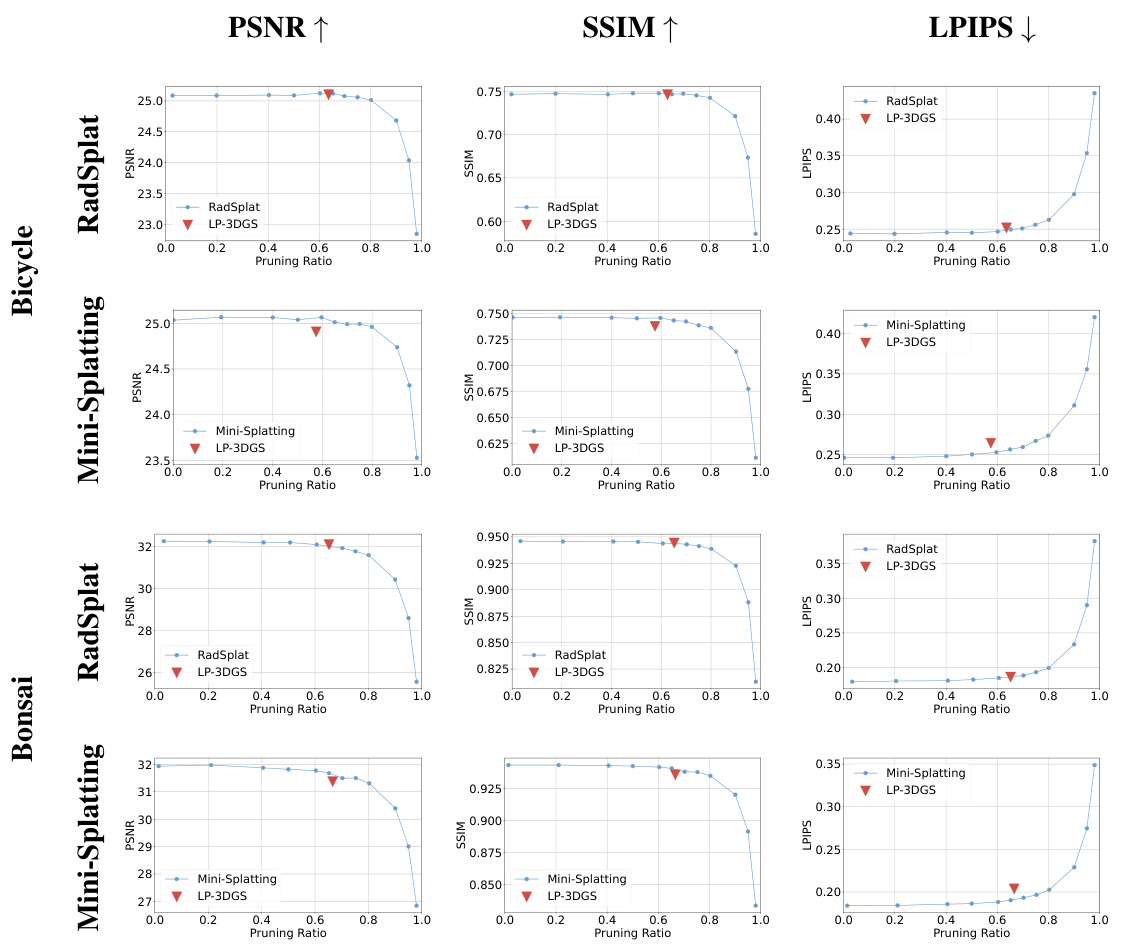
This figure compares the performance of RadSplat and LP-3DGS in terms of PSNR, SSIM, and LPIPS across different pruning ratios for the Kitchen and Room scenes from the MipNeRF360 dataset. The blue and purple lines show RadSplat’s performance with varying pruning ratios, illustrating that an optimal pruning ratio exists for each scene. LP-3DGS, represented by red triangles and squares, demonstrates its ability to find this optimal ratio within a single training session, unlike RadSplat which needs multiple rounds of training for each ratio.
This figure shows the performance comparison between RadSplat and LP-3DGS on the MipNeRF360 dataset’s Kitchen and Room scenes. It demonstrates how the rendering quality (PSNR, SSIM, LPIPS) varies with different pruning ratios. The blue and purple lines represent RadSplat’s performance, highlighting the need for multiple training runs to find the optimal pruning ratio. In contrast, LP-3DGS (red triangles and squares) achieves comparable or better performance with a single training run, efficiently finding the favorable pruning ratio.

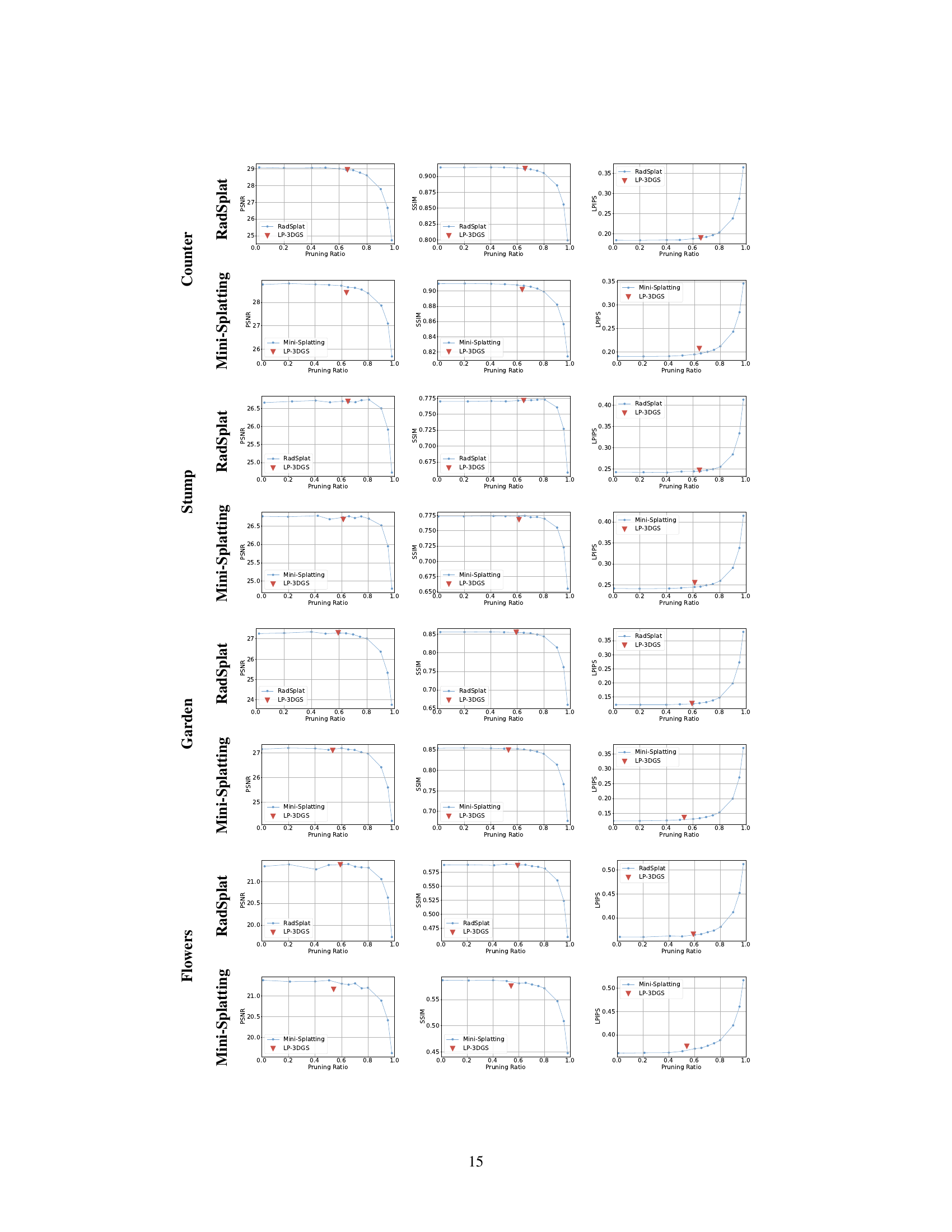
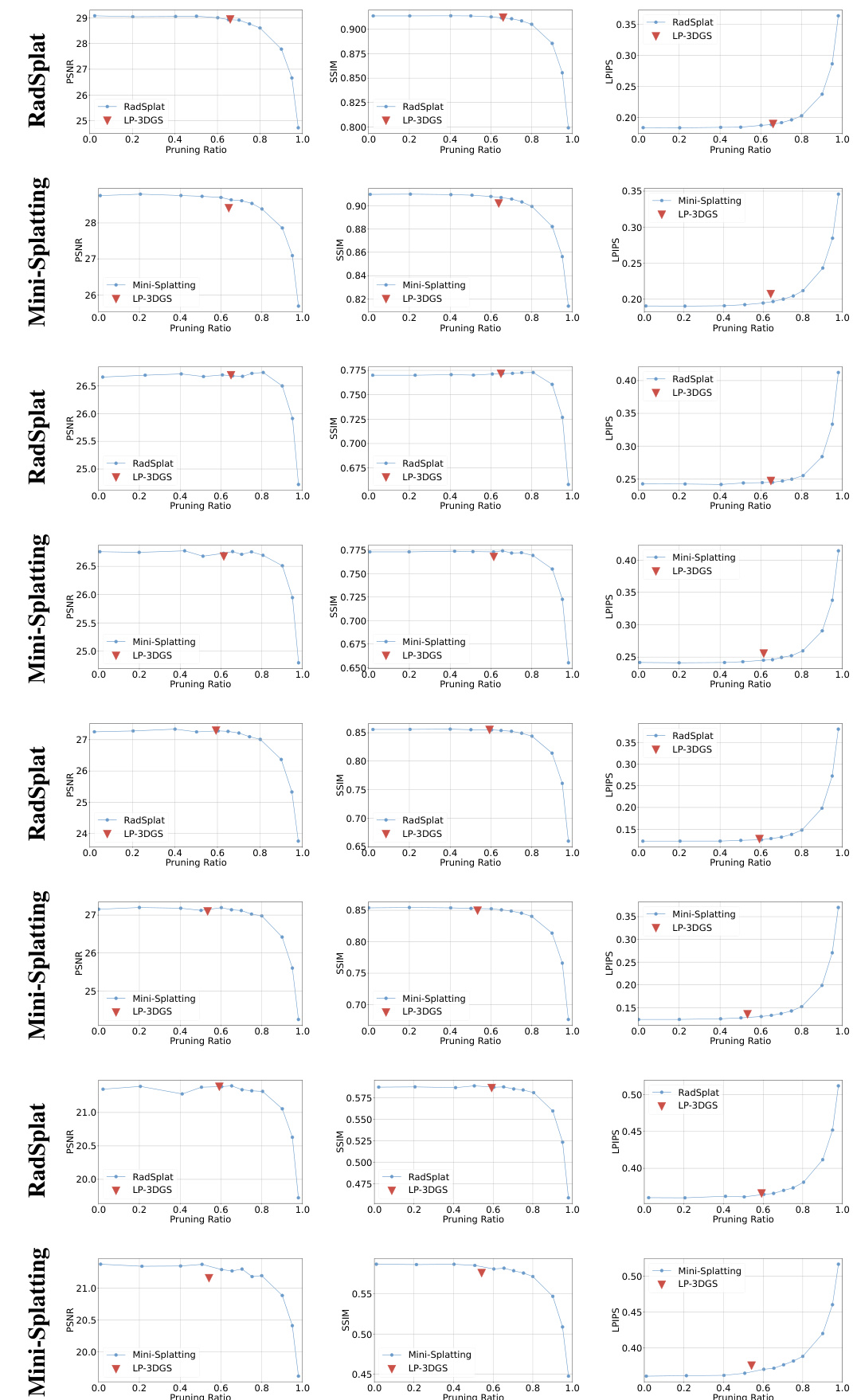
This figure visualizes the performance changes across various pruning ratios for different scenes. It uses three metrics (PSNR, SSIM, LPIPS) to evaluate the quality of the rendered images as the number of Gaussian points is reduced. The plots show how the quality of the rendering changes with increasing pruning ratios for both RadSplat and Mini-Splatting methods. The red triangles represent the performance of the proposed LP-3DGS method for each scene, highlighting its ability to find a good balance between model size and rendering quality.
More on tables
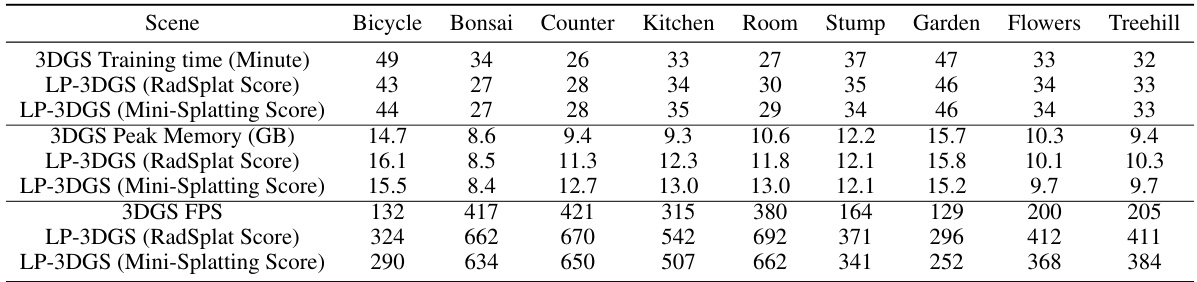
This table shows the training time, peak memory usage, and frames per second (FPS) for different models on the MipNeRF360 dataset. It compares the original 3DGS model to the LP-3DGS model using two different importance scores (RadSplat and Mini-Splatting). The results demonstrate that LP-3DGS achieves comparable training times and memory usage to the original 3DGS, but significantly improves the rendering speed (FPS) due to model compression.

This table presents a quantitative comparison of the performance of LP-3DGS and baseline methods (RadSplat and Mini-Splatting) on the MipNeRF360 dataset. It shows PSNR, SSIM, LPIPS, and the number of Gaussians for each scene. The key finding is that LP-3DGS achieves comparable performance to baselines while significantly reducing the number of Gaussians, demonstrating its ability to learn an optimal pruning ratio for each scene individually.

This table presents a comparison of the performance of LP-3DGS and baseline methods (RadSplat and Mini-Splatting) on the MipNeRF360 dataset. It shows PSNR, SSIM, LPIPS scores, and the resulting pruning ratio for each scene. The key finding is that LP-3DGS achieves comparable performance to the baselines while achieving significantly lower pruning ratios (smaller model sizes). The varying pruning ratios across scenes highlight the adaptive nature of LP-3DGS, automatically finding the optimal balance between model size and rendering quality for each scene.

This table presents a comparison of the performance of LP-3DGS and baseline methods (RadSplat and Mini-Splatting) on the MipNeRF360 dataset. It shows quantitative metrics (PSNR, SSIM, LPIPS) for each scene, demonstrating that LP-3DGS achieves comparable rendering quality to the baselines while achieving significantly higher pruning ratios (meaning a smaller model size). The varying pruning ratios per scene highlight LP-3DGS’s adaptive ability to find the optimal balance between model size and performance for each scene.
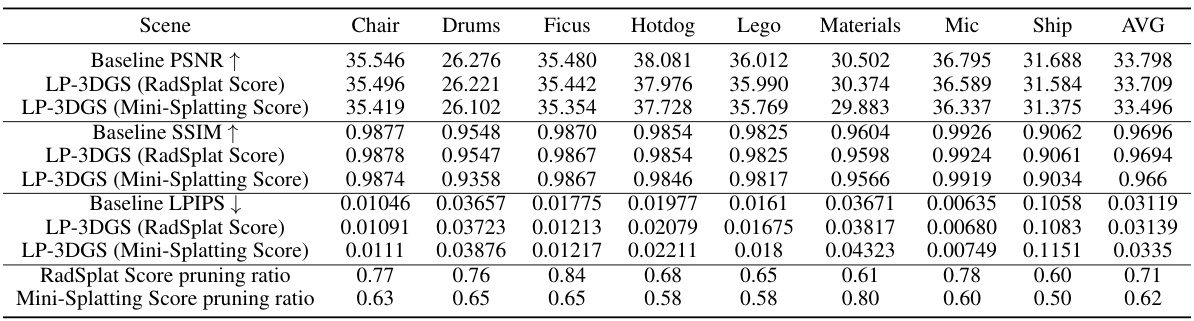
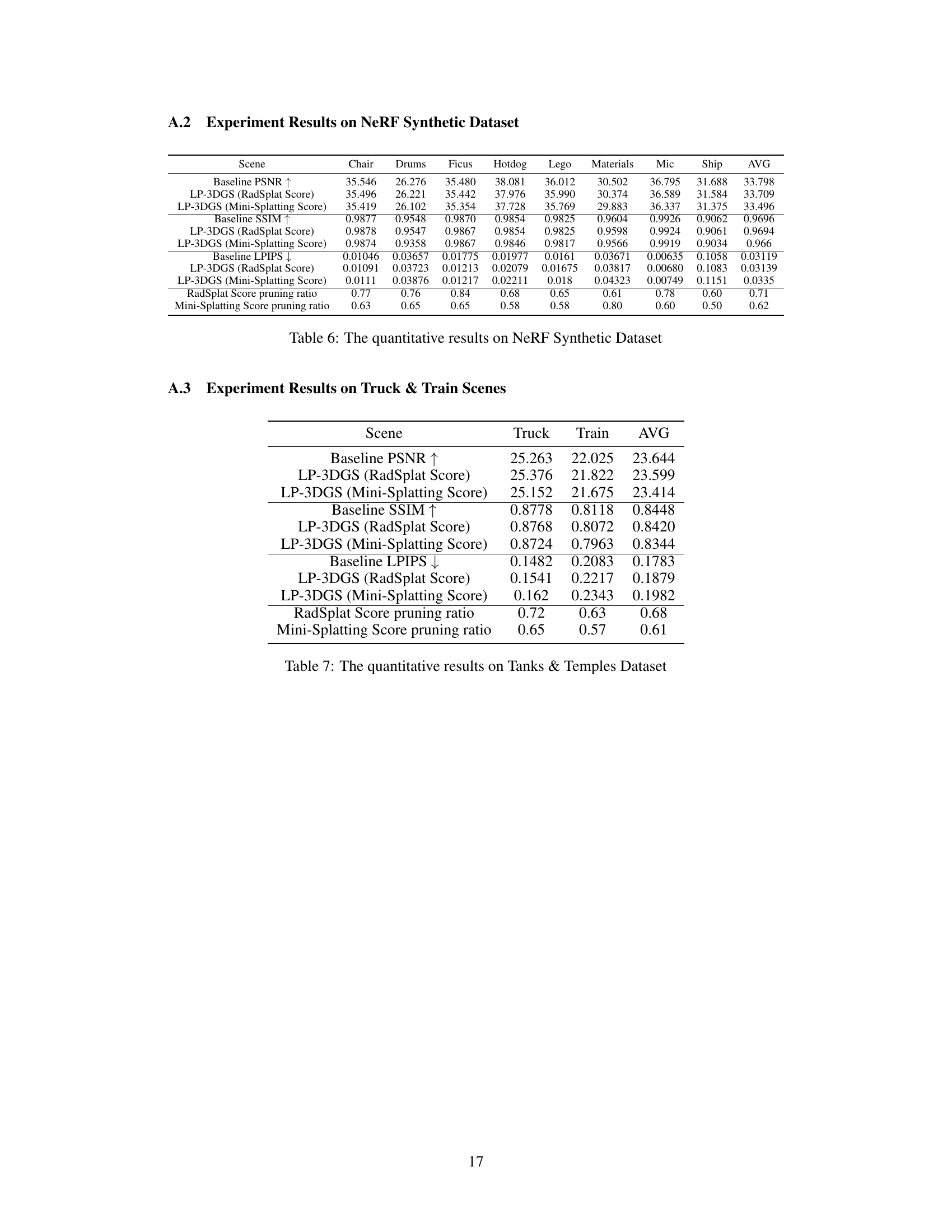
This table presents a quantitative comparison of the performance of different methods (baseline 3DGS, LP-3DGS using RadSplat scores, LP-3DGS using Mini-Splatting scores) on the NeRF Synthetic dataset. The metrics used are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Lower LPIPS values indicate better perceptual quality. The table also lists the pruning ratios achieved by RadSplat and Mini-Splatting for each scene.
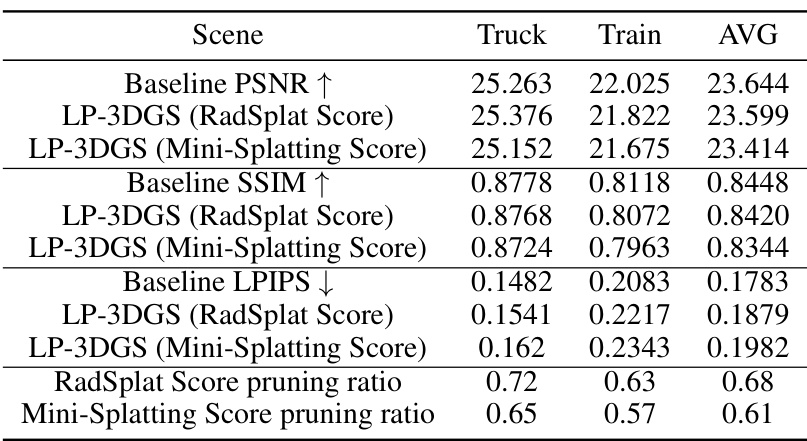
This table presents the quantitative results of the LP-3DGS model and baseline models (3DGS, RadSplat, and Mini-Splatting) on the Tanks & Temples dataset. It shows the PSNR, SSIM, and LPIPS scores for both the Truck and Train scenes, along with the achieved pruning ratios for each method. The results demonstrate LP-3DGS’s performance compared to existing methods in maintaining rendering quality while achieving significant model compression.
Full paper#