↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The increasing complexity and size of modern neural networks necessitates efficient resource utilization for training and inference. Device placement, the task of optimally allocating computational tasks across heterogeneous devices, is crucial for performance. However, existing approaches have limitations: either simplifying the problem by grouping operations before placement (‘grouper-placer’) or solely focusing on encoding node features (’encoder-placer’), both resulting in suboptimal solutions. These methods often lack end-to-end training and fail to fully leverage the underlying structure of the computation graphs.
This paper introduces HSDAG, a novel Hierarchical Structure-Aware Device Assignment Graph framework to overcome these issues. HSDAG addresses the device placement problem with an end-to-end trainable architecture that incorporates graph coarsening, node representation learning, and a policy optimization step using reinforcement learning. It combines the strengths of both ‘grouper-placer’ and ’encoder-placer’ methods by jointly learning node embeddings and group assignments. Experiments on benchmark models demonstrate significant improvements, achieving speedups of up to 58.2% compared to CPU-only execution and up to 60.24% compared to other baseline methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel framework for efficient device placement in neural network inference. It addresses limitations of existing approaches by jointly optimizing graph representation, partitioning, and node allocation in an end-to-end manner. This work is relevant to the growing field of efficient deep learning deployment, paving the way for faster and more energy-efficient AI applications. The proposed framework’s flexibility and demonstrated performance improvements (up to 58.2% over CPU execution) make it a significant contribution to the optimization of deep learning systems.
Visual Insights#
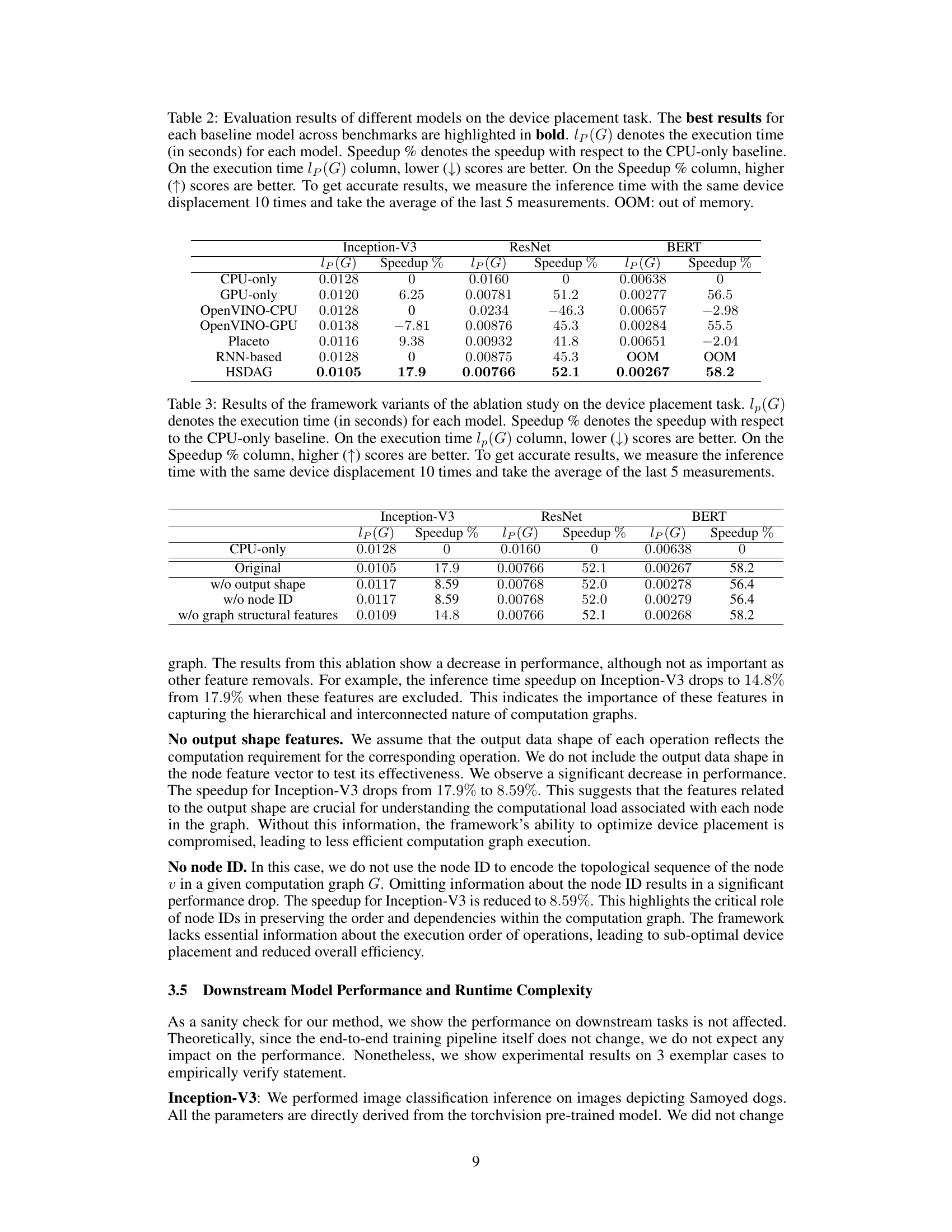
This figure illustrates the HSDAG framework’s five steps: graph construction, feature extraction, joint learning of embeddings and groups, device placement, and end-to-end parameter updates. It shows how a neural network model is converted into a computation graph, features are extracted, a GNN and MLP are used for node embedding and device placement, and the process iteratively updates parameters based on execution time rewards.
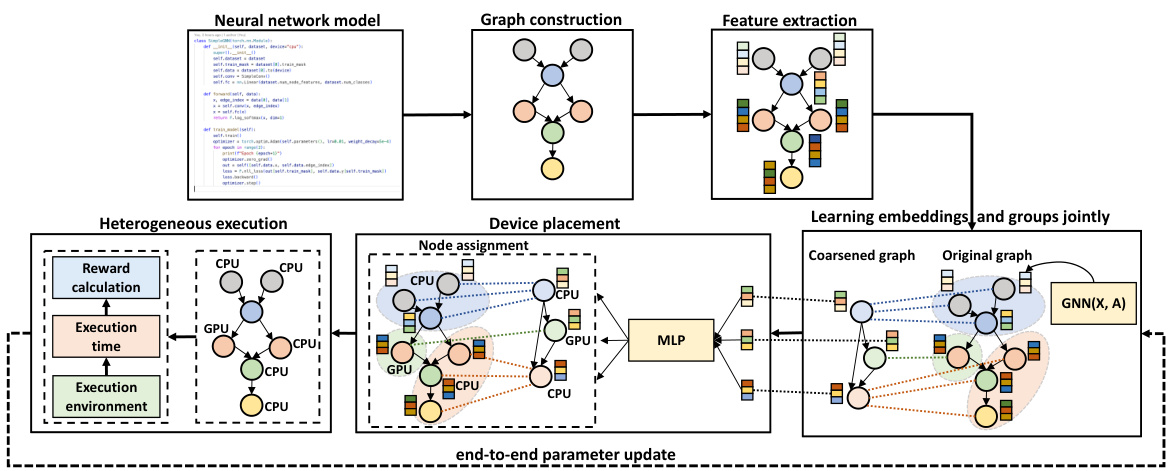
This table presents the statistics of the computation graphs for three benchmark neural network models: Inception-V3, ResNet, and BERT. For each model, it shows the number of nodes (|V|), the number of edges (|E|), and the average node degree (d). The average node degree represents the average number of connections each node has in the graph. This information is relevant to understanding the complexity and structure of the computation graphs used in the device placement experiments.
In-depth insights#
Device Placement RL#
Reinforcement learning (RL) is increasingly used for device placement in distributed systems, particularly for optimizing the execution of deep learning models. The core challenge is to efficiently map computational tasks (e.g., neural network operations) to available devices (CPUs, GPUs, etc.) to minimize latency and maximize throughput. RL’s ability to learn optimal policies in complex environments makes it well-suited to this problem. However, designing effective RL agents for device placement requires careful consideration of the state representation (computation graph structure, resource availability), the action space (device assignments), and the reward function (latency, energy consumption). Key research areas include developing efficient state representations that capture the relevant graph properties, employing effective RL algorithms that scale to large graphs, and designing robust reward functions that reflect the overall system performance goals. The choice between model-free and model-based RL approaches impacts the computational cost and data efficiency. Furthermore, incorporating prior knowledge about hardware characteristics and application requirements can significantly enhance the performance and generalizability of RL-based device placement solutions.
Graph Feature Fusion#
In a hypothetical research paper section on “Graph Feature Fusion,” the authors likely explore methods to combine different graph features for improved model performance. This could involve a variety of techniques, such as concatenation, where features are simply combined into a longer vector, or more sophisticated approaches such as attention mechanisms, which weigh the importance of different features based on their relevance to the task. The core of the section might also examine the effectiveness of different fusion strategies for various downstream tasks. For example, the impact of feature fusion on node classification accuracy or graph-level prediction tasks. Ablation studies evaluating the contribution of individual features and the overall effectiveness of the fusion methods would be crucial to demonstrate the efficacy of the proposed techniques. The choice of fusion method would likely depend on the nature of the features being combined and the computational cost associated with different approaches. The discussion would ideally conclude with the optimal feature fusion strategy, and its impact on the overall model’s performance and efficiency. The section’s strength would rest on its rigorous evaluation of different fusion strategies and a compelling demonstration of improved performance through insightful experimental results.
HSDAG Framework#
The HSDAG framework presents a novel approach to device placement optimization in neural network inference, addressing limitations of existing methods. It leverages smaller, coarsened computation graphs, enabling efficient end-to-end training. A key innovation is the joint learning of graph representations, partitioning, and pooling, bridging the gap between traditional grouper-placer and encoder-placer architectures. This unified approach allows for personalized graph partitioning with an unspecified number of groups, adapting dynamically to the model’s structure. The framework’s use of reinforcement learning with execution time as the reward ensures optimization for real-world performance. Overall, HSDAG offers a flexible and robust solution improving inference speed, showcasing potential for significant improvements in large-scale AI deployments.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a device placement framework, this would involve removing features (e.g., graph structural features, output shape features, node IDs) or modules (e.g., a specific GNN or reinforcement learning component) to determine their impact on overall performance. The goal is to understand which features and modules are essential for optimal device placement and to gain insights into the relative importance of different aspects of the framework. Analyzing the results, such as inference time speedups, allows researchers to prioritize future improvements and identify areas where simplifying the framework without sacrificing performance might be possible. By isolating the impact of each component, ablation studies provide valuable insights into the design choices and functionality of the model, which is extremely crucial for future research and development.
Future Works#
Future research directions stemming from this work could explore several promising avenues. Extending the framework to handle dynamic computation graphs is crucial, reflecting real-world scenarios where the graph structure evolves during inference. Investigating more sophisticated graph coarsening techniques could improve efficiency and scalability. A deeper exploration into different RL algorithms and reward functions is warranted. Furthermore, evaluating the framework’s performance on diverse hardware platforms beyond CPUs and GPUs would provide a comprehensive understanding of its generalizability and effectiveness. Finally, exploring applications of this approach beyond neural network inference, such as other graph-based computations, would broaden the impact and demonstrate the framework’s versatility. Addressing these aspects would solidify the framework’s position and unlock its full potential.
More visual insights#
More on tables
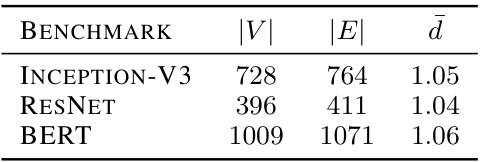
This table presents a comparison of different device placement models on three benchmark neural network models (Inception-V3, ResNet, and BERT). It shows the execution time (lp(G)) and speedup percentage relative to a CPU-only baseline. Lower execution times and higher speedup percentages indicate better performance.

This table presents the results of an ablation study that evaluates the impact of different components of the proposed framework on device placement performance. It shows the execution time (lp(G)) and speedup percentage relative to a CPU-only baseline for three benchmark models (Inception-V3, ResNet, and BERT) across several variations of the framework. The variations remove or modify features such as output shape, node ID, and graph structural features to assess their contribution to the overall performance improvement.

This table presents the performance comparison of different device placement models (CPU-only, GPU-only, OpenVINO-CPU, OpenVINO-GPU, Placeto, RNN-based, and the proposed HSDAG) on three benchmark datasets (Inception-V3, ResNet, and BERT). The evaluation metrics include execution time (lp(G)) in seconds and speedup percentage compared to the CPU-only baseline. Lower execution times and higher speedup percentages indicate better performance.

This table presents the performance comparison of different device placement models (CPU-only, GPU-only, OpenVINO-CPU, OpenVINO-GPU, Placeto, RNN-based, and HSDAG) on three benchmark models (Inception-V3, ResNet, and BERT). It shows the execution time (lp(G)) in seconds and the speedup percentage compared to the CPU-only baseline for each model. Lower execution times and higher speedup percentages indicate better performance. The table highlights the best performing model for each benchmark.
This table compares the performance of the proposed HSDAG framework against several baseline methods for device placement on three benchmark models: Inception-V3, ResNet, and BERT. It shows the execution time (lp(G)) in seconds for each model and the percentage speedup achieved compared to a CPU-only baseline. Lower execution times and higher speedup percentages indicate better performance. The table also notes instances where a model ran out of memory (OOM).
Full paper#