↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning’s reliance on error backpropagation suffers from biological implausibility issues like the weight transport and backward locking problems. These limitations hinder our understanding of biological neural systems and motivate the search for more biologically-plausible learning algorithms. Existing alternatives like Target Propagation address some of these issues but often lack efficiency or biological accuracy.
Counter-Current Learning (CCL) is introduced as a novel biologically plausible framework. It employs dual, anti-parallel networks (feedforward and feedback) to process inputs and targets simultaneously. CCL leverages layer-wise local loss functions, gradient detaching to mitigate the backward locking problem, and achieves performance comparable to other biologically plausible methods, demonstrating its effectiveness across various datasets and its potential for both supervised and unsupervised learning tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it proposes Counter-Current Learning (CCL), a biologically plausible alternative to backpropagation. This addresses a major limitation of current deep learning methods and opens new avenues for developing more biologically realistic and energy-efficient learning algorithms. Its applicability to various tasks, including autoencoders, further highlights its potential impact on the field.
Visual Insights#

This figure illustrates the Counter-Current Learning (CCL) framework. Panel (a) shows the initial setup of two anti-parallel networks, a feedforward network processing inputs and a feedback network processing targets. The networks’ architectures mirror each other. Panel (b) depicts the training process. Layer-wise losses are calculated by comparing activations between corresponding layers in the two networks. A ‘stop gradient operator’ prevents gradient flow from affecting earlier layers, promoting localized learning.
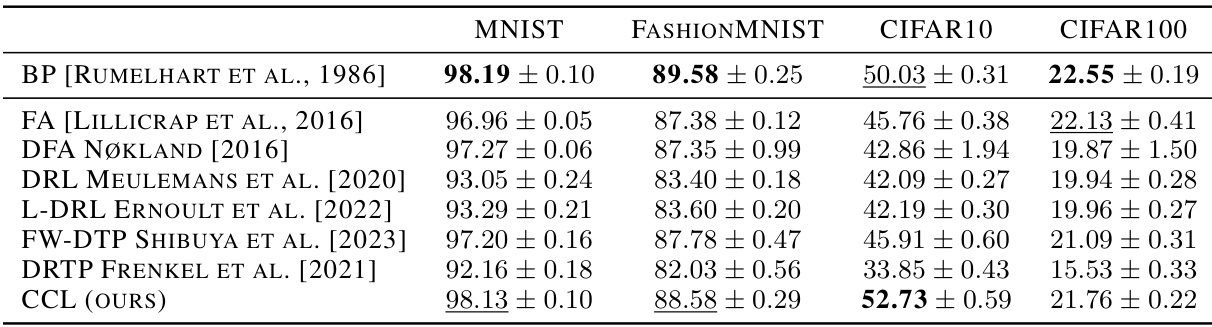
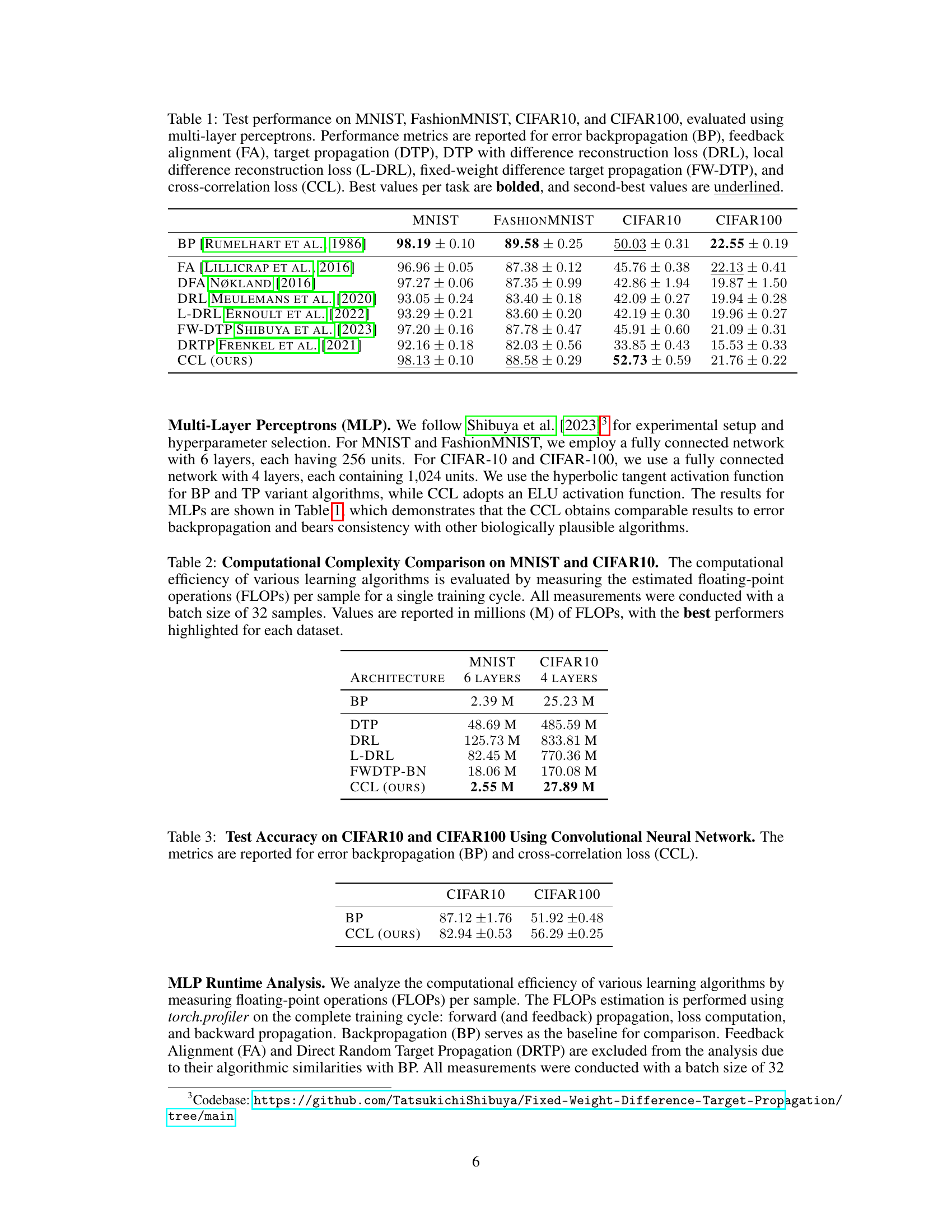
This table presents the classification accuracy results on four benchmark datasets (MNIST, FashionMNIST, CIFAR10, and CIFAR100) achieved by various biologically plausible learning algorithms including error backpropagation (BP), feedback alignment (FA), target propagation (DTP), DRL, L-DRL, FW-DTP, DRTP, and the proposed counter-current learning (CCL). The best and second-best results for each dataset are highlighted, enabling a direct comparison of the different methods.
In-depth insights#
Dual Network CCL#
The proposed “Dual Network CCL” framework presents a novel, biologically plausible approach to deep learning. It leverages a counter-current exchange mechanism, inspired by biological systems, employing two interconnected networks: a feedforward network processing input data and a feedback network processing target data. Anti-parallel signal propagation between these networks enhances learning, with each network refining the other’s transformations. Local loss functions, computed pairwise between corresponding layers, ensure biologically realistic, localized credit assignment. This contrasts with error backpropagation’s reliance on global error signals, resolving issues such as the weight transport and backward locking problems. The framework’s use of gradient detaching interrupts the long error backpropagation chain, fostering more localized updates. Comparable performance to other biologically plausible algorithms, demonstrated across various datasets, supports the framework’s potential as a viable alternative to traditional backpropagation. The extension to autoencoder tasks highlights its applicability to unsupervised learning. Overall, the “Dual Network CCL” offers a promising pathway towards more biologically inspired and efficient deep learning algorithms.
Bio-Plausible Learning#
Bio-plausible learning seeks to develop machine learning algorithms that mirror the biological mechanisms of the brain. This contrasts sharply with traditional methods like backpropagation, which lack biological realism. Key challenges in creating bio-plausible learning algorithms include the weight transport problem (backward signal propagation), the non-local credit assignment problem (global error signals), and the backward locking problem (sequential processing). Researchers have explored various bio-inspired alternatives such as target propagation, feedback alignment, and other methods that use local learning rules or avoid explicit backward passes. Counter-current learning (CCL), for example, leverages a dual-network architecture and an anti-parallel signal flow to enhance biological plausibility. While these approaches show promise, they often involve tradeoffs in computational efficiency or accuracy, highlighting the ongoing search for truly effective and biologically realistic learning algorithms. Future research will likely focus on better understanding brain mechanisms and developing new algorithms that address existing limitations.
Feature Space Dynamics#
Analyzing feature space dynamics in deep learning models offers crucial insights into the learning process. Visualizing these dynamics using techniques like t-SNE can reveal how features evolve and cluster during training, highlighting the model’s ability to discern patterns and separate classes. A thoughtful examination should consider the interplay between the model’s architecture and the chosen data representation, as both heavily influence the observed trajectories. Early-stage feature representations might show significant overlap, gradually disentangling as training progresses. This disentanglement reflects the model’s refinement of its internal feature space to better capture the underlying data structure. Further investigation could uncover the speed and smoothness of this evolution; rapid changes may indicate instability, while gradual transitions suggest a more stable learning process. Comparing feature space dynamics across different models or training strategies can unveil their relative effectiveness and robustness. For instance, a biologically inspired algorithm might exhibit a smoother, more localized feature space evolution compared to traditional backpropagation. Therefore, understanding feature space dynamics is essential for designing robust, efficient, and biologically plausible deep learning models.
Autoencoder Potential#
The application of counter-current learning (CCL) to autoencoders reveals promising potential. CCL’s ability to achieve comparable reconstruction error to backpropagation (BP) while adhering to biological plausibility suggests it offers a viable alternative for unsupervised representation learning. This is particularly significant given BP’s limitations in this domain. The results on the STL-10 dataset demonstrate that CCL can learn meaningful representations. However, the presence of some visual artifacts compared to BP indicates further research is needed to refine CCL’s performance and enhance the quality of learned features. Investigating different architectural modifications and exploring various optimization techniques would likely improve the autoencoder’s reconstruction quality and overall effectiveness. Future work could focus on reducing the computational cost of CCL to make it more competitive with BP for large-scale autoencoder tasks. This would be particularly important for applications such as image denoising, anomaly detection, and generative modeling where large datasets are commonly used. The initial findings of comparable performance are encouraging and warrant further investigation into the full potential of CCL for various autoencoding applications.
Limitations & Future#
The research paper’s “Limitations & Future Directions” section would ideally delve into the shortcomings of the proposed counter-current learning (CCL) framework. Computational cost, especially compared to backpropagation, is a crucial limitation needing thorough discussion. The analysis should also address the generalizability of CCL across diverse network architectures and datasets beyond those tested. A key aspect would be evaluating the robustness of CCL to noisy data or hyperparameter variations. Future work should explore enhancing the biological plausibility of the model further, perhaps by incorporating more realistic neural dynamics. Investigating the theoretical underpinnings of CCL’s learning mechanisms, establishing convergence properties, and comparing its performance with other biologically plausible alternatives under various conditions are also important avenues of future research. Finally, exploring the application of CCL to complex tasks like natural language processing or reinforcement learning is a compelling direction that could showcase its broader potential.
More visual insights#
More on figures

This figure illustrates the Counter-Current Learning (CCL) framework. Panel (a) shows the dual network architecture at initialization, with a feedforward network processing input and a feedback network processing target data. The networks process information in anti-parallel, enhancing each other. Panel (b) depicts the training process, where layer-wise losses are calculated using the difference in activations between corresponding layers in the two networks. Gradient detachment prevents the dependency of gradient on earlier layers, promoting local learning.

This figure shows how features from the forward and backward networks align during training using t-SNE. Distinct classes, represented by different colors, gradually converge in the feature space, indicating the effectiveness of the counter-current learning in aligning the representations of both networks.

This figure visualizes the convolutional kernels of a forward model’s first layer, trained using both backpropagation (BP) and counter-current learning (CCL). The BP-trained kernels show high-frequency components (alternating white and black pixels representing high and low weights), while CCL-trained kernels exhibit more low-frequency components (smoother transitions in weights). The authors hypothesize that this difference stems from error signals in BP carrying higher-frequency information than ideal target signals in CCL.

This figure shows a qualitative comparison of reconstruction results from an eight-layered convolutional autoencoder trained using both error backpropagation (BP) and counter-current learning (CCL). The models were tested on the STL-10 dataset. Each row displays the ground truth target, the reconstruction using BP, and the reconstruction using CCL for ten different test images. The results demonstrate that counter-current learning achieves comparable reconstruction quality to BP while exhibiting better biological plausibility.
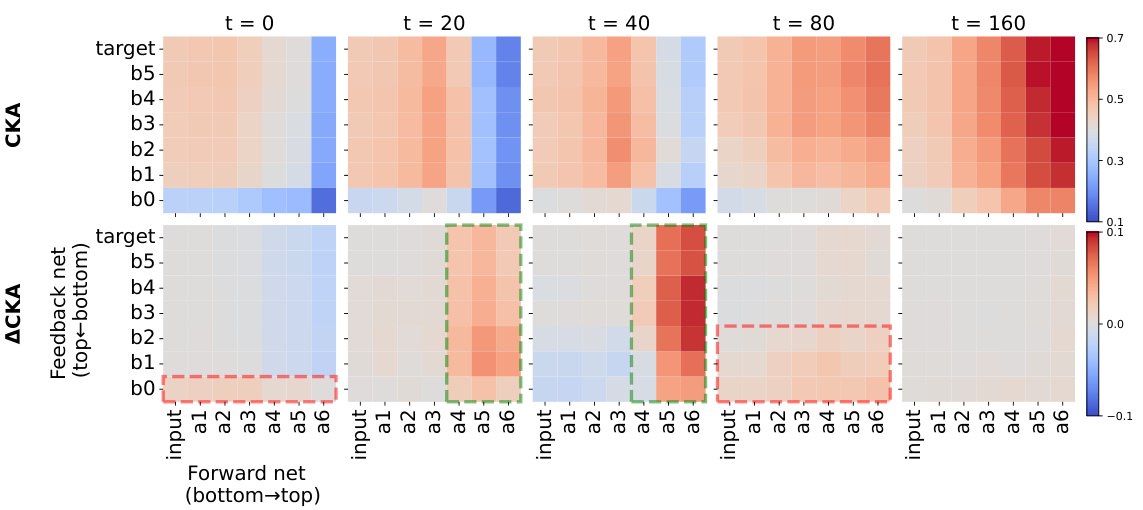
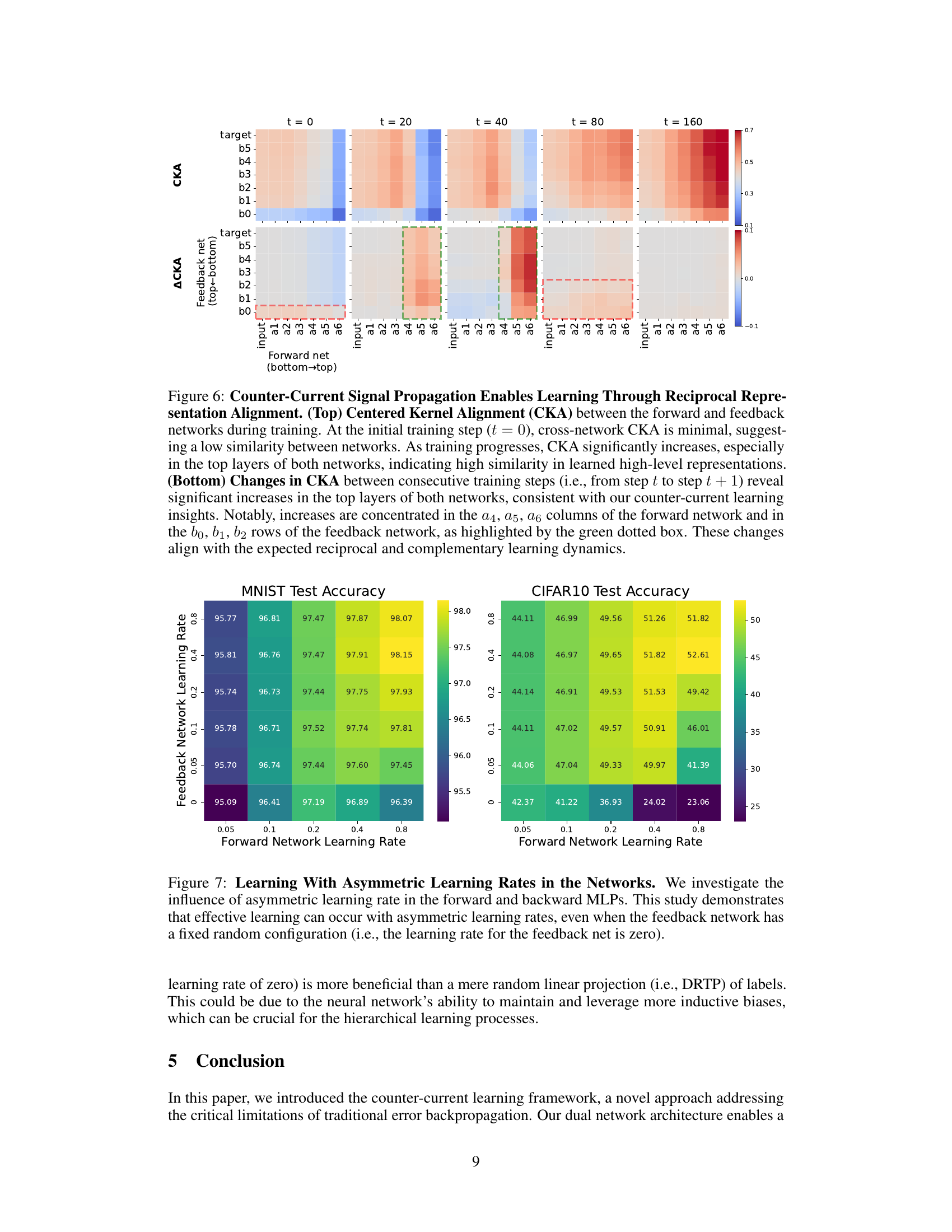
This figure visualizes the alignment of features between the forward and feedback networks in a counter-current learning framework during training. The top part shows the Centered Kernel Alignment (CKA) between layers at different stages of training. It reveals that initially, the networks show little similarity. As training proceeds, the alignment increases, particularly at higher layers, suggesting a reciprocal interaction. The bottom part shows changes in CKA between consecutive steps, highlighting the increase at higher layers. This supports the counter-current mechanism: higher layers in one network learn from lower layers in the other, creating a reciprocal and complementary learning dynamic.
This figure visualizes the alignment of features between the forward and backward networks in the counter-current learning framework over different training stages using t-SNE plots. It shows how features from different classes converge during training, indicating dynamic interaction and reciprocal learning between the two networks.

This figure visualizes the feature alignment across different layers (1, 3, and 5) of a five-layered CNN model trained on CIFAR-10 using the Counter-Current Learning (CCL) method. The t-SNE plots show the evolution of feature space alignment over different training stages (0, 10, 100, 1000, and 3000 CCL updates). Circles represent features from the forward network, while squares represent features from the feedback network. The consistent alignment of features across layers and training stages suggests the effectiveness of CCL in aligning representations between the forward and feedback networks.
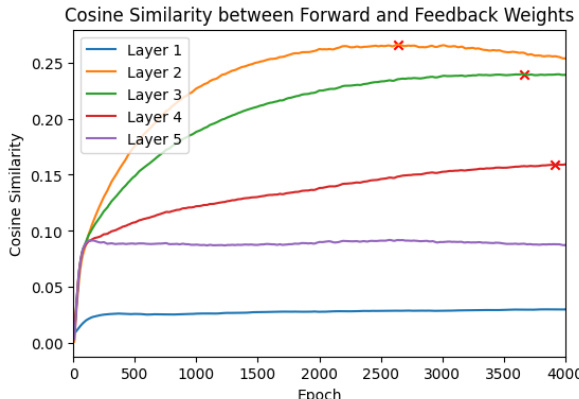
This figure shows the cosine similarity between the forward and backward network weights during training. The x-axis represents the training epoch, and the y-axis represents the cosine similarity. Each line represents a different layer in the network. The figure demonstrates that the first and last layers reach a plateau in cosine similarity relatively quickly. However, the intermediate layers show a gradual increase in cosine similarity over the course of training, indicating a slower convergence of weight alignment.
More on tables
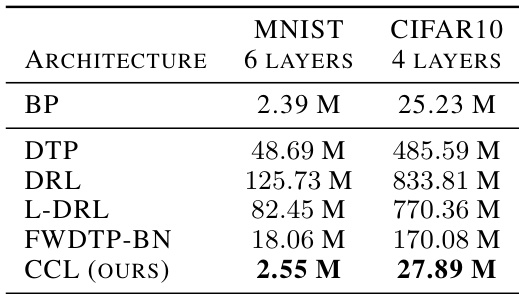
This table compares the computational efficiency of different deep learning algorithms (BP, DTP, DRL, L-DRL, FWDTP-BN, and CCL) on MNIST and CIFAR10 datasets. The efficiency is measured in terms of millions of floating-point operations (MFLOPS) per sample per training cycle, with a batch size of 32. The table highlights the best-performing algorithm for each dataset.

This table presents the test accuracy results on CIFAR-10 and CIFAR-100 datasets using a Convolutional Neural Network (CNN). The performance is compared between two learning algorithms: error backpropagation (BP) and the proposed counter-current learning (CCL). The table shows the test accuracy and standard deviation for each algorithm on each dataset.

This table compares the performance of different algorithms (BP, L-DRL, and CCL) on the CIFAR-10 dataset using a VGG-like convolutional neural network architecture. It highlights the test accuracy achieved by each algorithm, indicating that L-DRL achieves the highest accuracy, followed by BP, and then CCL. A key difference is noted, with L-DRL training on a validation set, while the other two methods do not.
Full paper#