↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current diffusion models lag behind autoregressive models in language modeling due to a significant performance gap. This is mainly attributed to limitations in training strategies and the inherent challenges in handling sequential data using diffusion-based approaches. Prior works focusing on discrete diffusion have had limited success in bridging this gap.
This paper introduces a novel framework, Masked Diffusion Language Models (MDLM), which leverages a simple masked discrete diffusion process combined with a well-engineered training recipe. The key innovation lies in the introduction of a simplified Rao-Blackwellized objective that significantly improves training efficiency and model performance. The MDLM also features efficient samplers, allowing semi-autoregressive generation, ultimately achieving state-of-the-art results for diffusion models in various language modeling benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly bridges the performance gap between diffusion and autoregressive models in language modeling, a critical area of AI research. The introduction of a simple yet effective training recipe and a refined objective function pushes masked diffusion models to state-of-the-art performance, making them a compelling alternative to traditional methods. This opens new avenues for research, impacting various downstream tasks and prompting further exploration of diffusion models’ potential in handling sequential data.
Visual Insights#

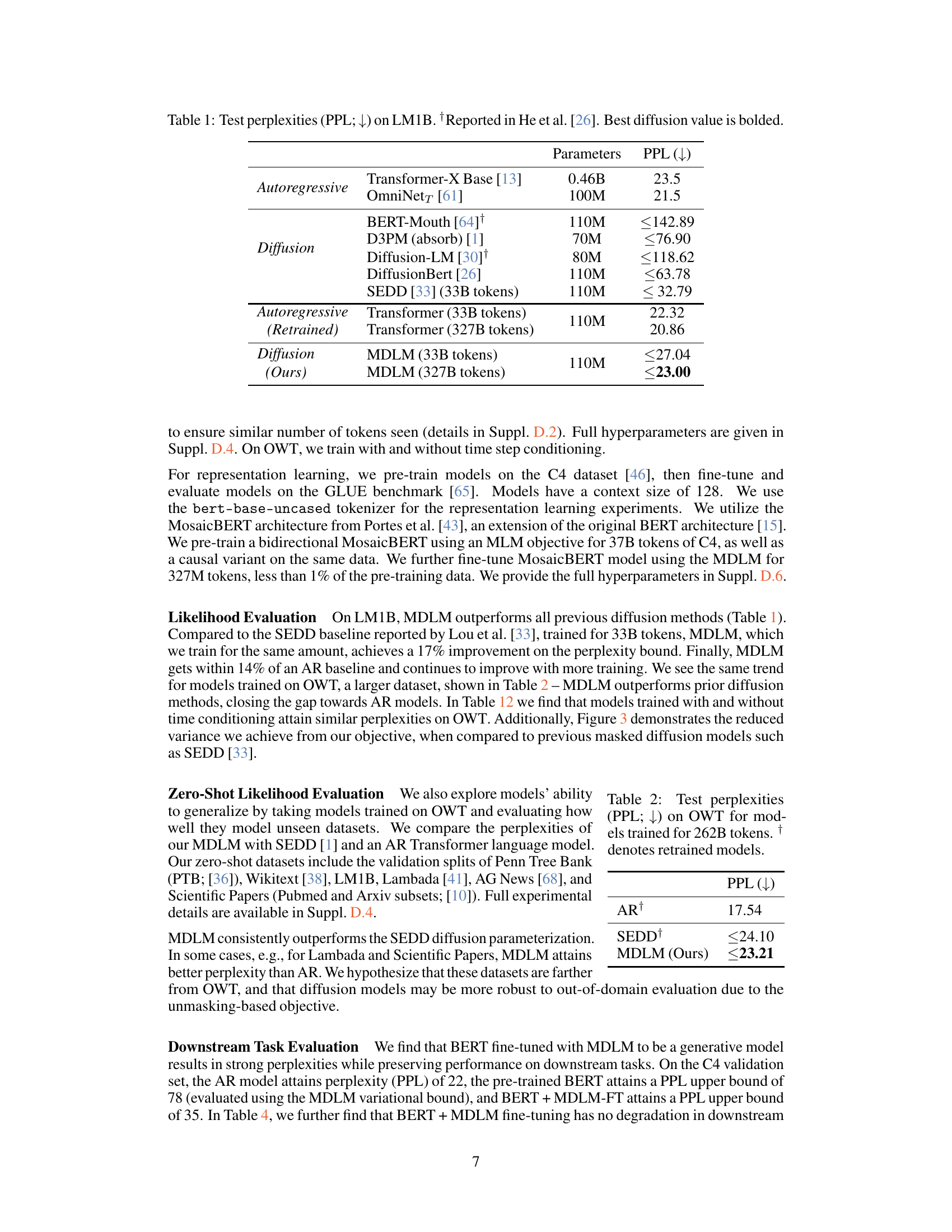
This figure shows the architecture of the proposed Masked Diffusion Language Model (MDLM) and compares its performance to other masked language models. The left panel illustrates the MDLM training process which uses a weighted average of masked cross-entropy losses. The top right panel highlights that, unlike standard MLM, MDLM’s objective is a variational lower bound and allows for efficient ancestral sampling. The bottom right panel presents a comparison of perplexity scores on the One Billion Words benchmark, demonstrating the superior performance of MDLM.
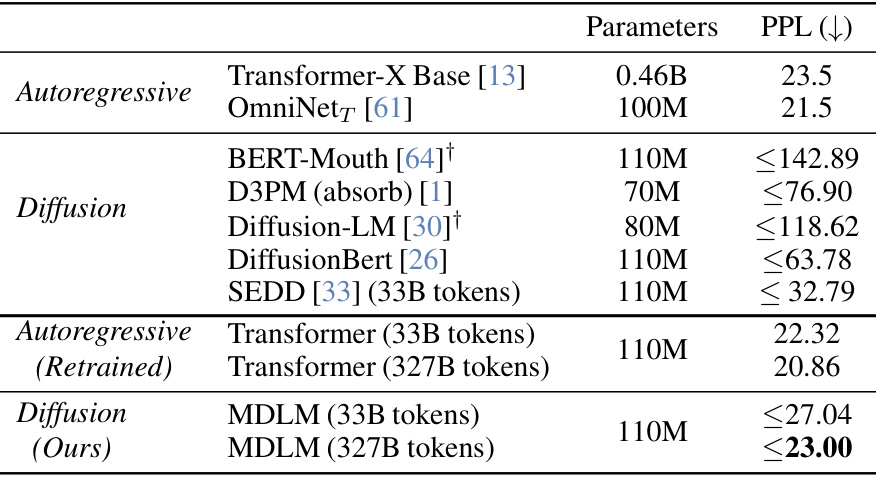
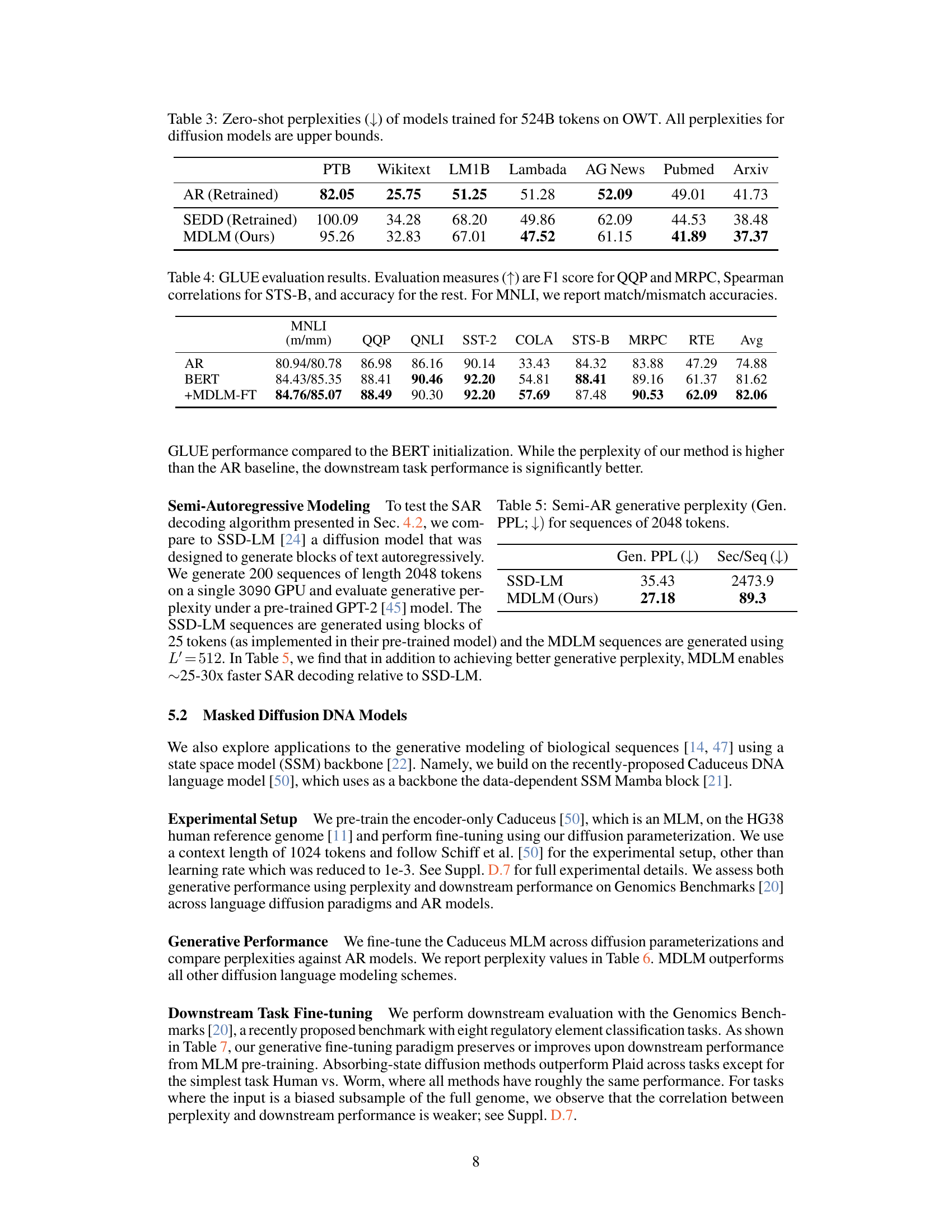
This table compares the performance of various autoregressive and diffusion language models on the One Billion Word Benchmark (LM1B) dataset. The perplexity (PPL), a measure of how well a language model predicts a text, is reported for each model. Lower perplexity indicates better performance. The table highlights that the proposed Masked Diffusion Language Model (MDLM) achieves state-of-the-art results among diffusion models and approaches the performance of the best autoregressive models.
In-depth insights#
Masked Diffusion LM#
Masked diffusion language models represent a novel approach to text generation, combining the strengths of masked language modeling with the flexibility of diffusion processes. The core idea is to introduce noise into the input text by randomly masking tokens, then train a model to reverse this process and reconstruct the original text. This differs from standard autoregressive models that generate text sequentially. The paper highlights that a simplified objective function, based on a mixture of masked language modeling losses, is surprisingly effective and results in improved performance. This simplified objective allows for the use of efficient samplers, including semi-autoregressive methods that can generate text of arbitrary lengths. The key improvements also include a well-engineered training procedure and a substitution-based parameterization that enables a tighter variational lower bound, leading to state-of-the-art results in terms of perplexity among diffusion models. The paper further explores the application of this framework to other domains, such as biological sequence modeling, demonstrating broader utility and potential.
MDLM Framework#
The MDLM framework presents a novel approach to masked diffusion language modeling, combining simplicity with effectiveness. It leverages a weighted average of masked language modeling losses, offering a straightforward objective function. This contrasts with the more complex variational lower bounds seen in previous methods, which simplifies training. The use of a Rao-Blackwellized objective further enhances efficiency and reduces variance, resulting in performance improvements. The framework also includes efficient samplers, enabling semi-autoregressive text generation. The SUBS parameterization significantly simplifies the reverse process, leading to a tighter ELBO, which leads to better performance. Flexibility is another key aspect, as the framework can easily adapt to other discrete data domains. Overall, MDLM offers a compelling balance between theoretical rigor and practical efficiency, showcasing improvements over prior masked diffusion models.
Efficient Sampling#
Efficient sampling techniques are crucial for diffusion models, especially in applications like language modeling where generating long sequences is computationally expensive. The paper likely explores strategies to accelerate the sampling process, which is inherently slow due to the iterative nature of diffusion. Ancestral sampling is a common approach, but its efficiency depends on the specific model and may be improved by optimizing the reverse diffusion process. The discussion probably delves into the tradeoffs between computational cost and sampling quality. Semi-autoregressive (SAR) methods are another focus area, balancing the speed of non-autoregressive generation with the coherence of autoregressive techniques. Caching intermediate results during sampling could significantly reduce repeated computations. The effectiveness of each method likely hinges on careful engineering, parameter optimization, and potentially novel algorithmic innovations. The overall goal is to bridge the gap between diffusion models’ quality and the speed of autoregressive models, making diffusion models more practical for real-world applications.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a thorough comparison of the proposed masked diffusion language model (MDLM) against existing state-of-the-art models. This would involve reporting perplexity scores on established benchmarks like one billion word benchmark (LM1B) and OpenWebText, showcasing MDLM’s performance relative to autoregressive (AR) and other diffusion models. Crucially, the results should highlight not only the absolute performance but also the statistical significance of any improvements, using measures like confidence intervals or p-values. Further analysis might involve breaking down performance based on factors like sequence length or token type to identify areas of strength and weakness. Finally, the discussion should acknowledge any limitations of the benchmarks and address potential biases or confounding factors that might influence the results, contributing to a well-rounded and trustworthy evaluation of MDLM’s capabilities.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of masked diffusion models, particularly for long sequences, is crucial. This includes investigating more efficient sampling techniques and optimizing the training process to reduce computational cost. Extending the framework to other modalities beyond text and DNA sequences, such as graphs or time series, would further demonstrate the versatility of the approach. A key area for development is developing theoretical understanding of the underlying mechanisms. While empirical results are strong, a more rigorous theoretical framework for analyzing the performance and properties of masked diffusion models would greatly enhance their trustworthiness and allow for better design choices. Finally, exploring applications in more complex and nuanced tasks within natural language processing, such as question answering or summarization, will highlight the practical potential of this technique and its unique advantages in generative modeling.
More visual insights#
More on figures
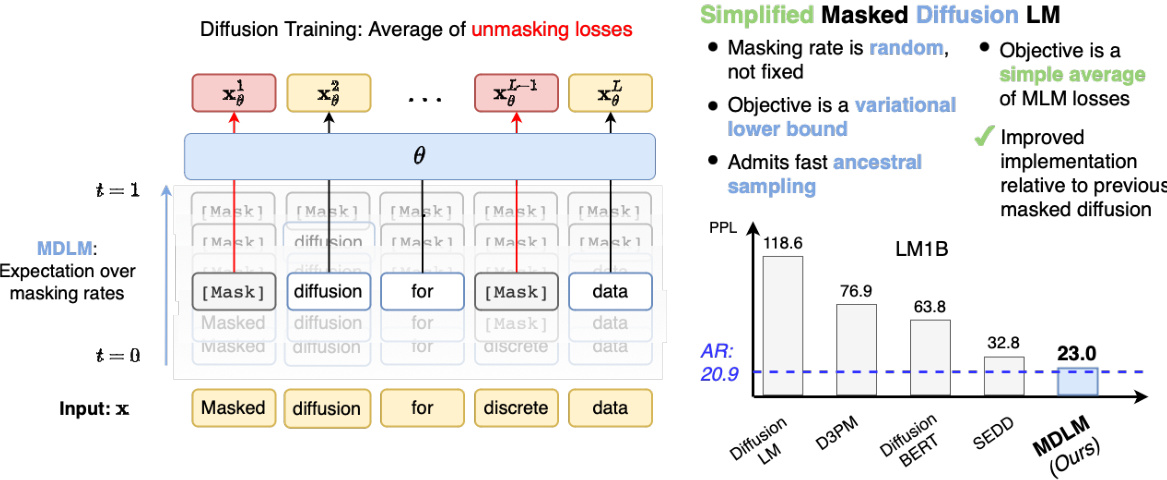
This figure illustrates the MDLM architecture and its training process. The left panel shows the model architecture, where the input is masked and processed through multiple masked diffusion layers before reaching the final output. The top right panel visually represents how MDLM’s objective is derived using a weighted average of masked cross-entropy losses, and how the weighted average relates to a variational lower bound, a more principled method in this context. The bottom right panel compares the perplexity of MDLM with other state-of-the-art models on the One Billion Words benchmark, showing that MDLM achieves the lowest perplexity.

This figure demonstrates the architecture of the proposed Masked Diffusion Language Model (MDLM) and compares its performance to other masked language models. The left panel shows the MDLM architecture, highlighting its use of a weighted average of masked cross-entropy losses during training. The top right panel contrasts MDLM’s objective function with that of traditional masked language models (MLMs), emphasizing MDLM’s derivation from a principled variational lower bound and its support for efficient ancestral sampling. The bottom right panel presents a bar chart comparing the perplexity scores achieved by MDLM and various other models on the One Billion Words (LM1B) benchmark, showcasing MDLM’s superior performance.
This figure presents a comparison between different language modeling approaches using the One Billion Words benchmark. The left panel shows the MDLM architecture, which uses a weighted average of masked cross-entropy losses for training. The top-right panel highlights the advantages of MDLM over traditional masked language models (MLM): MDLM’s objective function is a principled variational lower bound, enabling efficient ancestral sampling for text generation. The bottom-right panel displays the perplexity results of several models, including MDLM, which shows improved performance compared to other methods.
More on tables
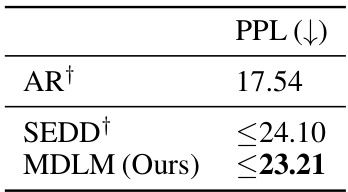
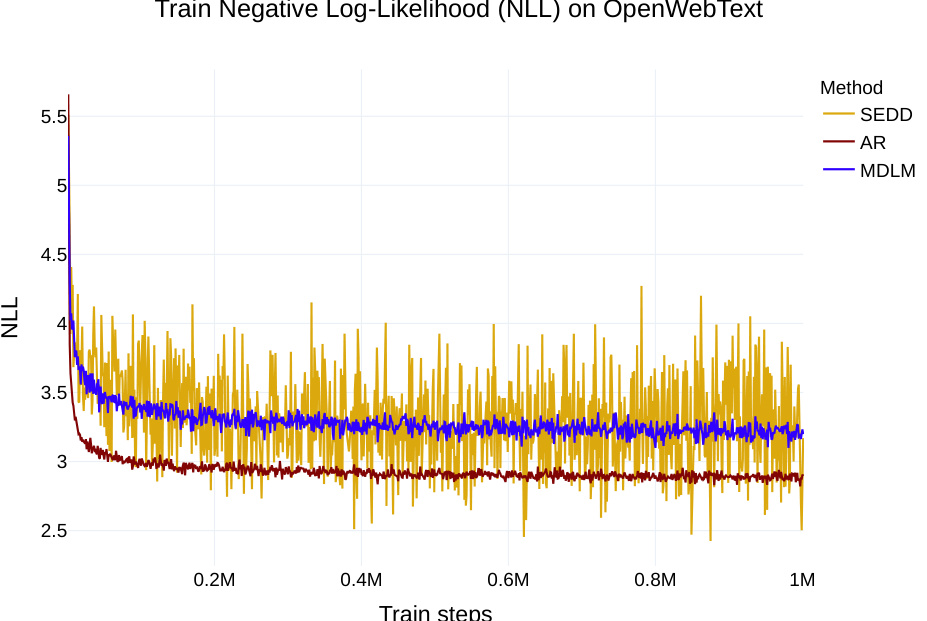
This table presents the test perplexity results on the OpenWebText (OWT) dataset for different language models. The models were trained on 262 billion tokens. The table compares the performance of an autoregressive (AR) model, a previously published masked diffusion model (SEDD), and the proposed Masked Diffusion Language Model (MDLM). The downward-pointing arrow indicates that lower perplexity scores are better.

This table presents the zero-shot perplexity results on various datasets (PTB, Wikitext, LM1B, Lambada, AG News, Pubmed, Arxiv) for three different language models: an autoregressive model (AR) and two diffusion models (SEDD and MDLM). The models were trained on the OWT dataset. The lower the perplexity, the better the model’s performance. The results show how well the models generalize to unseen datasets. Note that the perplexities for diffusion models are upper bounds.

This table presents the results of the GLUE benchmark evaluation. The GLUE benchmark is a collection of diverse natural language understanding tasks. The table shows the performance of different models on these tasks, including Autoregressive (AR) models, BERT, and BERT fine-tuned with MDLM. The metrics used are F1 score (for QQP and MRPC), Spearman correlation (for STS-B), and accuracy (for the remaining tasks). For the MNLI task, both match and mismatch accuracies are reported.

This table compares the performance of SSD-LM and MDLM in terms of generative perplexity and generation speed for sequences of length 2048 tokens. The results show that MDLM achieves significantly lower generative perplexity and much faster generation speeds compared to SSD-LM.

This table presents the results of generative fine-tuning experiments using the Caduceus MLM on the HG38 human reference genome. The table compares the perplexity scores (lower is better) achieved by several autoregressive and diffusion models. The ‘Params’ column shows the number of parameters in each model, while the ‘PPL (↓)’ column indicates the test perplexity, with error bars representing the variability across five runs with different random seeds. The best performance among the diffusion models is highlighted in bold, enabling a direct comparison of the performance among different model types and demonstrating the effectiveness of the proposed MDLM.
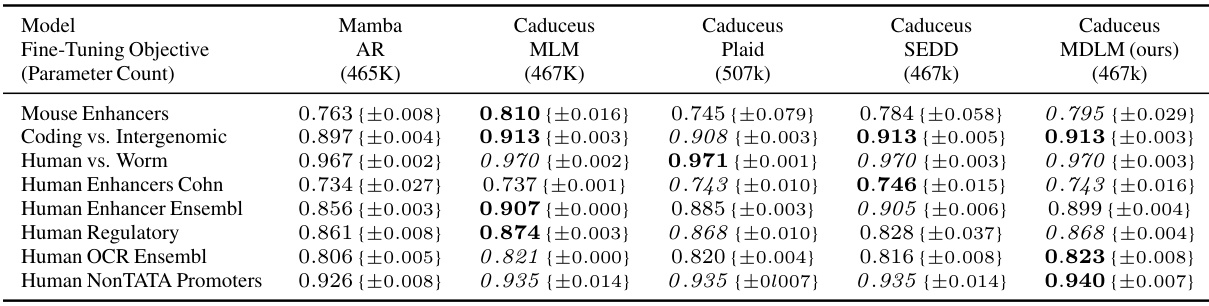
This table presents the top-1 accuracy results from 5-fold cross-validation of different models on various genomic benchmark tasks. The models include a pre-trained autoregressive Mamba model and a pre-trained Caduceus model that has been fine-tuned using different diffusion parameterizations (Plaid, SEDD, and MDLM). The best and second-best accuracy scores are highlighted for each task, and error bars are provided to show the variability across five different random seeds.
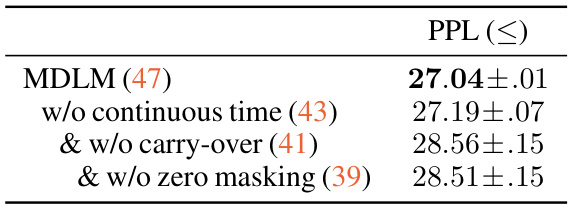
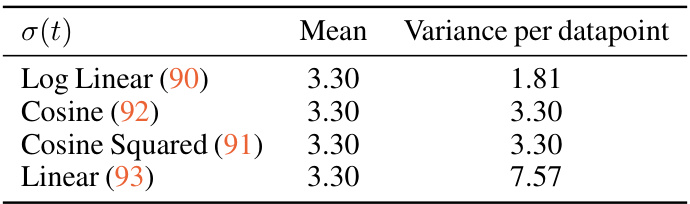
This table presents an ablation study on the MDLM model, evaluating the impact of different design choices on the model’s performance, specifically its perplexity on the LM1B benchmark. The study focuses on the effects of using a continuous-time framework, the carry-over unmasking property, and zero masking probabilities. The results show that while the continuous-time framework slightly improves performance, the carry-over and zero masking properties significantly contribute to the model’s overall perplexity.
The table compares the performance of various autoregressive and diffusion language models on the LM1B benchmark in terms of perplexity (PPL). Lower perplexity indicates better performance. It highlights the state-of-the-art performance achieved by the proposed Masked Diffusion Language Model (MDLM) compared to existing models, showcasing its improved efficiency and performance on this benchmark.

This table compares the performance of various autoregressive and diffusion language models on the LM1B benchmark. The perplexity (PPL), a measure of how well a model predicts a test set, is reported. Lower perplexity values indicate better performance. The table highlights that the proposed Masked Diffusion Language Model (MDLM) achieves a new state-of-the-art among diffusion models, approaching the perplexity of autoregressive models. The number of parameters for each model is also listed.

This table presents the test perplexity results on the One Billion Word benchmark (LM1B). It compares the performance of various autoregressive and diffusion language models, highlighting the state-of-the-art achieved by the proposed Masked Diffusion Language Model (MDLM). The table shows that MDLM significantly outperforms previous diffusion models and approaches the performance of the best autoregressive models, demonstrating the effectiveness of the proposed approach.

This table shows the results of an ablation study on the impact of time-conditioning in the MDLM model trained on the OpenWebText dataset. It compares the perplexity (PPL) achieved by the model with and without time conditioning. The results indicate that time conditioning has a minimal impact on the model’s performance.
Full paper#