↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing methods for learning 3D location-consistent image features suffer from a major memory bottleneck due to the loss function used. This limits the training of larger, more powerful models that could potentially lead to significant improvements in performance. The high computational cost also restricts the applicability of these methods for large scale training.
The paper introduces LoCo, a novel method that reformulates and efficiently approximates the average precision objective. This reduces memory usage by three orders of magnitude. The improved efficiency enables the use of significantly larger models without increasing computational resources. LoCo demonstrates superior performance on multi-view consistency and panoptic segmentation tasks, significantly outperforming previous state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on 3D-consistent image feature extraction and related areas like visual place recognition and panoptic segmentation. It addresses a critical memory bottleneck in existing methods, enabling the training of larger models and achieving superior performance in multi-view consistency tasks. The proposed memory-efficient training strategy also opens new avenues for large-scale training and improved model scalability.
Visual Insights#
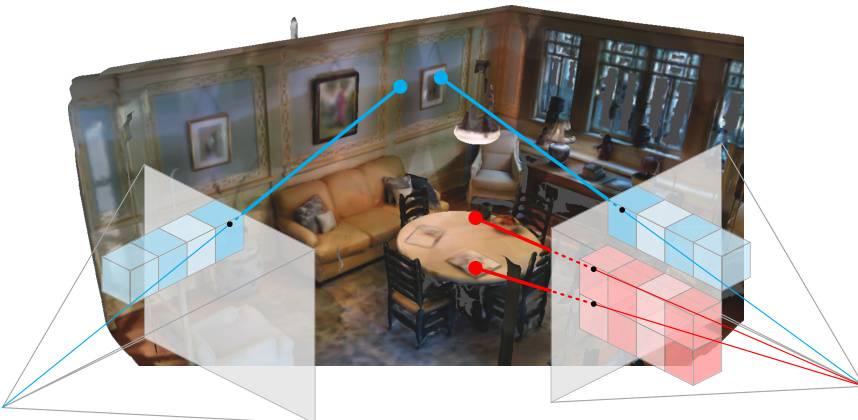
This figure illustrates the core concept of the LoCo method. It shows two sets of image patches (blue and red cubes) that project to nearby 3D locations in a scene. The LoCo method aims to learn features such that these nearby patches have similar feature vectors, while patches that project to far-apart 3D locations have dissimilar feature vectors. This is achieved by a novel, memory-efficient ranking loss function that improves on previous smooth average precision loss functions.
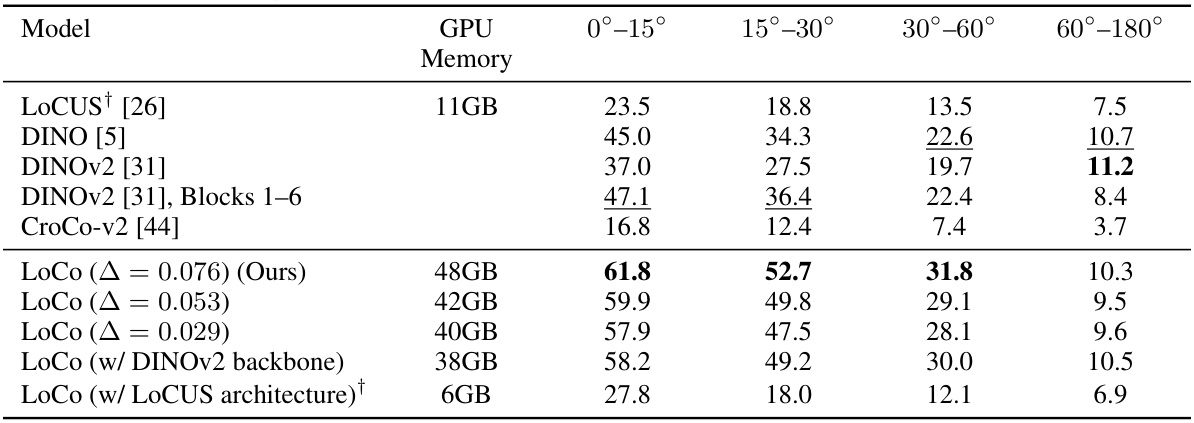
This table presents the results of a pixel correspondence task on the ScanNet dataset, comparing various feature extraction methods. The task assesses the accuracy of matching pixels representing the same 3D location across different viewpoints. The table shows the recall (percentage of correctly matched pixels) for various angular differences between viewpoints (0°-15°, 15°-30°, 30°-60°, 60°-180°). The GPU memory used during training for each method is also indicated. The results highlight the superior performance of the proposed LoCo method compared to existing state-of-the-art techniques.
In-depth insights#
LoCo Loss Reformulation#
The core idea behind the “LoCo Loss Reformulation” revolves around improving the memory efficiency of the Smooth Average Precision (sAP) loss, which is used for training location-consistent image features. The original sAP loss requires significant computational resources due to its formulation based on individual patches, leading to high memory consumption during training. The key innovation is to reformulate sAP in terms of pairs of image patches rather than individual patches. This reformulation allows the derivation of an approximation to the sAP loss that is computationally far more efficient. This is achieved by cleverly using a sigmoid function and the concept of pairwise similarity scores, enabling a significant reduction in memory usage. This approach is crucial for training large models, which was previously prohibited due to the high memory demands of the original loss function. The reformulation trades a tiny amount of accuracy for massively improved efficiency, allowing for scalability in training location-consistent image feature extractors.
Memory Efficiency Boost#
The core of the memory efficiency boost lies in reformulating the smooth average precision (AP) loss function. The original formulation required substantial memory to store and process pairwise similarity scores between all positive and negative patch pairs, limiting scalability. The authors cleverly reformulate this loss, expressing it in terms of pairs rather than individual patches, leading to a more computationally tractable form. This reformulation allows for a memory-efficient approximation of the smooth AP loss, achieving three orders of magnitude improvement in efficiency. Further optimizations are made by strategically identifying and discarding pairs with negligible gradients, thus significantly reducing computation. This two-pronged approach, coupled with clever batching strategies, enables the training of much larger models with comparable computational resources, ultimately enhancing the quality and consistency of location-consistent image features. The overall impact is a substantial reduction in memory footprint, crucial for large-scale training and deployment of sophisticated image retrieval and panoptic segmentation models.
Multi-view Consistency#
The concept of “Multi-view Consistency” in 3D vision focuses on the challenge of ensuring that image features extracted from different viewpoints of the same 3D scene location remain consistent. In essence, the goal is to create features that are robust to viewpoint changes, such as occlusions, lighting variations, and motion. This is crucial for applications that require understanding the environment’s 3D structure, such as robotic navigation, scene reconstruction, and augmented reality. The paper addresses this by introducing a method that learns location-consistent image features. The approach centers on the use of a novel, memory-efficient ranking loss function to improve training efficiency. Through experimental evaluations, the research demonstrates the learned features’ enhanced consistency across multiple views. This enhanced consistency translates to better performance on downstream tasks, such as scene-stable panoptic segmentation and pixel correspondence estimation, which heavily rely on consistent 3D understanding from varying perspectives. Therefore, improving multi-view consistency is pivotal for advancing reliable and robust 3D vision systems.
Scene-Stable Seg.#
The concept of “Scene-Stable Seg.” (Scene-Stable Segmentation) tackles a critical challenge in computer vision: achieving consistent object recognition across multiple views of the same scene. Traditional segmentation methods often fail to maintain consistent object identities when viewpoints change significantly due to occlusions, lighting variations, and other factors. Scene-stable segmentation aims to address this by ensuring that the same 3D object, regardless of the camera’s perspective, is consistently identified and segmented across images. This robustness is highly desirable for applications requiring consistent scene understanding, such as autonomous navigation or robotic manipulation. The key innovation is a shift from per-image object IDs to scene-wide IDs, thereby establishing a unified object identity across all views. This requires more sophisticated feature extraction and matching techniques that are robust to changes in appearance. The success of this approach hinges on the quality of the 3D-consistent features used, emphasizing the importance of accurate depth information or other geometric cues during training. Memory efficiency is a significant challenge in this process, demanding novel approaches to the loss function design that enables the training of larger, more performant models. Overall, the scene-stable segmentation method aims to solve a key practical problem and holds significant potential for improving the robustness and reliability of many computer vision applications.
Future Work & Limits#
Future work could explore improving robustness to noisy depth and pose estimates, making the method more practical for real-world scenarios where accurate sensor data might be unavailable. Investigating the scalability of the approach to significantly larger datasets is crucial, as is exploring its application to video data for robust temporal consistency. A key limitation is the reliance on pre-trained feature extractors; future research should focus on developing fully end-to-end location-consistent feature learning models. Furthermore, analyzing the method’s performance under diverse environments and object categories beyond the current dataset is necessary to assess generalizability. Finally, investigating the application of the efficient loss function to other visual tasks that benefit from location consistency would be a valuable extension of the current work. Addressing these points will enhance the method’s applicability and impact across broader computer vision domains.
More visual insights#
More on figures
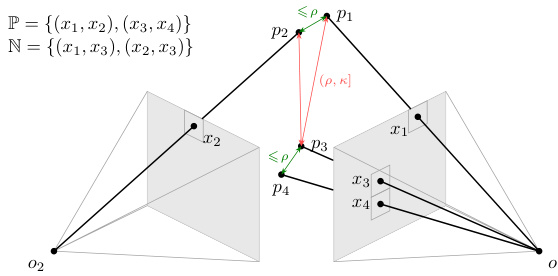
This figure illustrates the concepts of positive and negative sets for pairs of image patches in the context of learning location-consistent image features. (a) shows that positive pairs (green arrows) have 3D points closer than a threshold ρ, while negative pairs (red arrows) have 3D points further apart, but still within another threshold κ. (b) visualizes the memory-efficient strategy based on the Smooth Average Precision loss, where the loss function saturates when the absolute similarity difference between image pairs is large, enabling optimization improvements. This allows for only calculating similarity differences for a subset of pairs, reducing memory usage.
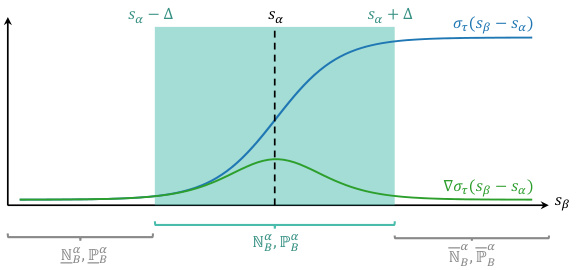
This figure illustrates the methodology for creating positive and negative sets for efficient learning. Panel (a) depicts how positive pairs (green arrows) have a 3D distance less than (p), negative pairs (red arrows) have a 3D distance between (p) and (κ), and others have a distance larger than (κ). Panel (b) shows a memory-efficient strategy by using the sigmoid function with saturation thresholds. Pairs with large similarity differences saturate the sigmoid and don’t impact training; this avoids memory costs by creating 3 subsets of positive and negative pairs (saturated below, unsaturated, and saturated above).

This figure shows a qualitative comparison of scene-stable panoptic segmentation results using the proposed LoCo method. Three images from the Matterport3D dataset are shown, each with its corresponding ground truth segmentation (top row) and the segmentation obtained using the LoCo method (bottom row). The key observation is that the object identities (colors) and segmentation masks remain consistent across significant viewpoint changes, demonstrating the scene-stable nature of the model’s output. This highlights the model’s ability to recognize and segment the same objects even under varying viewing angles and perspectives.
This figure illustrates the core concept of LoCo, a memory-efficient method for learning location-consistent image features. It shows how the method encourages similar features for image patches that project to nearby 3D locations and dissimilar features for patches projecting to distant 3D points. The use of stacked cubes helps visualize the backprojection of image patches to 3D space and how similar/dissimilar features are learned based on 3D proximity.

This figure illustrates the core concept of LoCo, a memory-efficient method for learning location-consistent image features. It shows how the approach encourages similar features for image patches that backproject to nearby 3D points and dissimilar features for patches that backproject to distant 3D points. This is achieved through a novel ranking loss function which is a more memory-efficient reformulation of the Smooth Average Precision loss.
More on tables
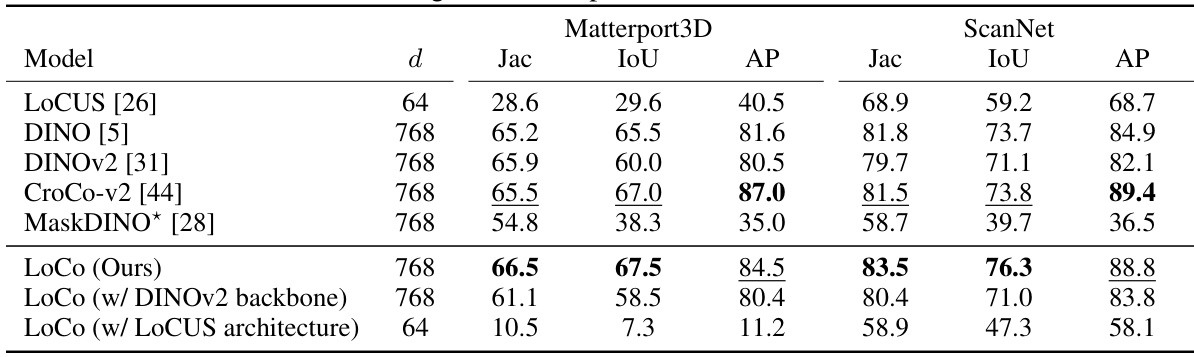
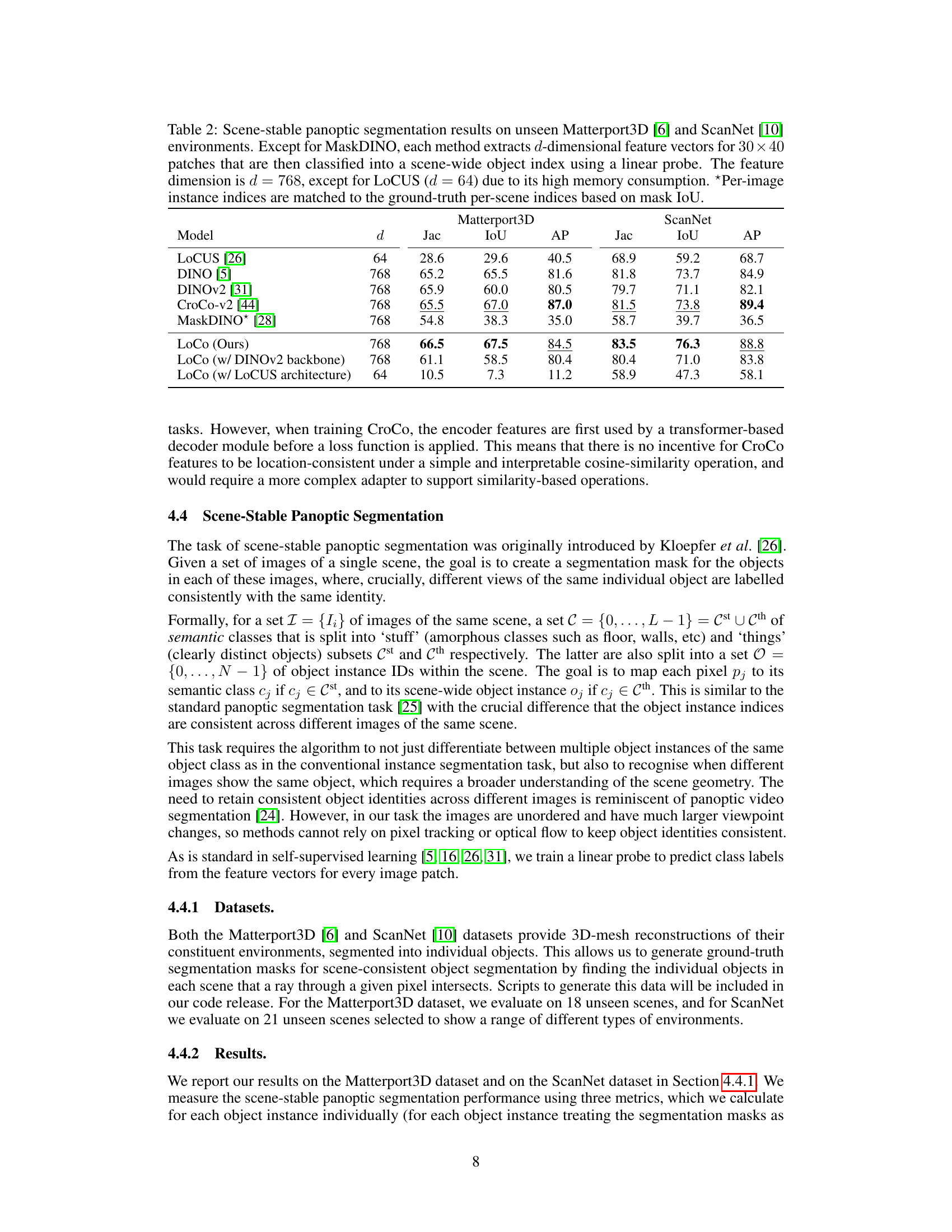
This table presents the results of scene-stable panoptic segmentation on unseen Matterport3D and ScanNet datasets. The performance of different models (LOCUS, DINO, DINOv2, CroCo-v2, MaskDINO, and the proposed LoCo) is evaluated using three metrics: Jaccard index (Jac), Intersection over Union (IoU), and Average Precision (AP). The feature dimension (d) is specified for each model, noting the smaller dimension for LOCUS due to memory constraints. A crucial point is that per-image object instance indices were matched to ground-truth per-scene indices based on IoU.

This table details the architecture of the fully convolutional residual network used in the pixel-correspondence task. It lists the layer number, kernel size, output dimension, dilation, and downsampling factor for each of the six convolutional layers. This network learns additive residuals to the frozen DINO features, enhancing the location consistency of the features.

This table presents the results of a pixel correspondence task on the ScanNet dataset. The task measures the accuracy of matching pixels between different views of the same scene, given varying degrees of viewpoint change (0-15°, 15-30°, 30-60°, 60-180°). The table compares the performance of several models: LoCo (the proposed method), LOCUS, DINO, DINOv2, and CroCo-v2, reporting the recall of accurate correspondences at a 10-pixel reprojection error threshold. GPU memory usage during training is also provided for LoCo and LoCUS. The results demonstrate the superior performance of LoCo in achieving location consistency across varying viewpoints.
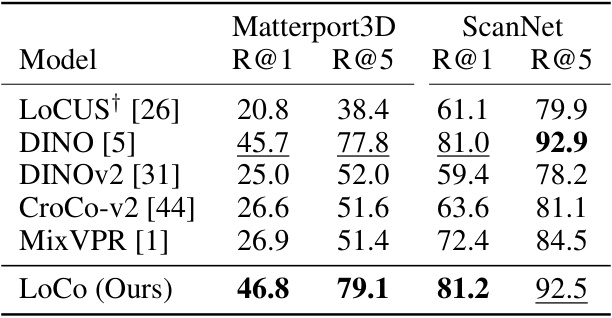
This table presents the results of visual place recognition experiments using various feature extractors on the Matterport3D and ScanNet datasets. The results are reported using the Recall@1 and Recall@5 metrics, showing the top 1 and top 5 most similar reference images retrieved for each query image. The table compares the performance of LoCo against several baselines including LOCUS, DINO, DINOv2, CroCo-v2 and MixVPR. Most methods utilize VLAD for aggregating local feature vectors, except for MixVPR which generates global image descriptors directly. The LoCo method uses 768-dimensional features, while LOCUS uses 64-dimensional features due to memory limitations.
Full paper#