↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Fine-tuning large language models (LLMs) is computationally expensive, requiring substantial GPU memory. Parameter-efficient techniques like Low-Rank Adaptation (LoRA) have been proposed, but their performance often lags behind full parameter fine-tuning. This limitation hinders broader access to LLM training, especially for researchers with limited computational resources. The paper addresses this challenge by examining layer-wise weight norms in LoRA during fine-tuning and discovers a skewed distribution. This observation motivates the proposed method.
The paper introduces Layerwise Importance Sampled AdamW (LISA), a novel optimization method that leverages the concept of importance sampling. LISA selectively updates essential LLM layers while freezing most middle layers, significantly reducing memory consumption. Experiments demonstrate that LISA outperforms LoRA and, in some cases, full parameter fine-tuning across various datasets and model sizes. The results suggest LISA provides a practical alternative to LoRA for memory-efficient LLM fine-tuning, improving accessibility for researchers with limited resources and opening up new avenues for research in parameter-efficient training strategies for large-scale LLMs. LISA’s superior performance and reduced memory requirements are significant contributions.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel memory-efficient fine-tuning method for large language models, addressing a critical challenge in the field. It offers a practical solution for researchers with limited resources, enabling them to train large models effectively. The findings open new avenues for research in parameter-efficient fine-tuning and may lead to breakthroughs in various downstream tasks.
Visual Insights#
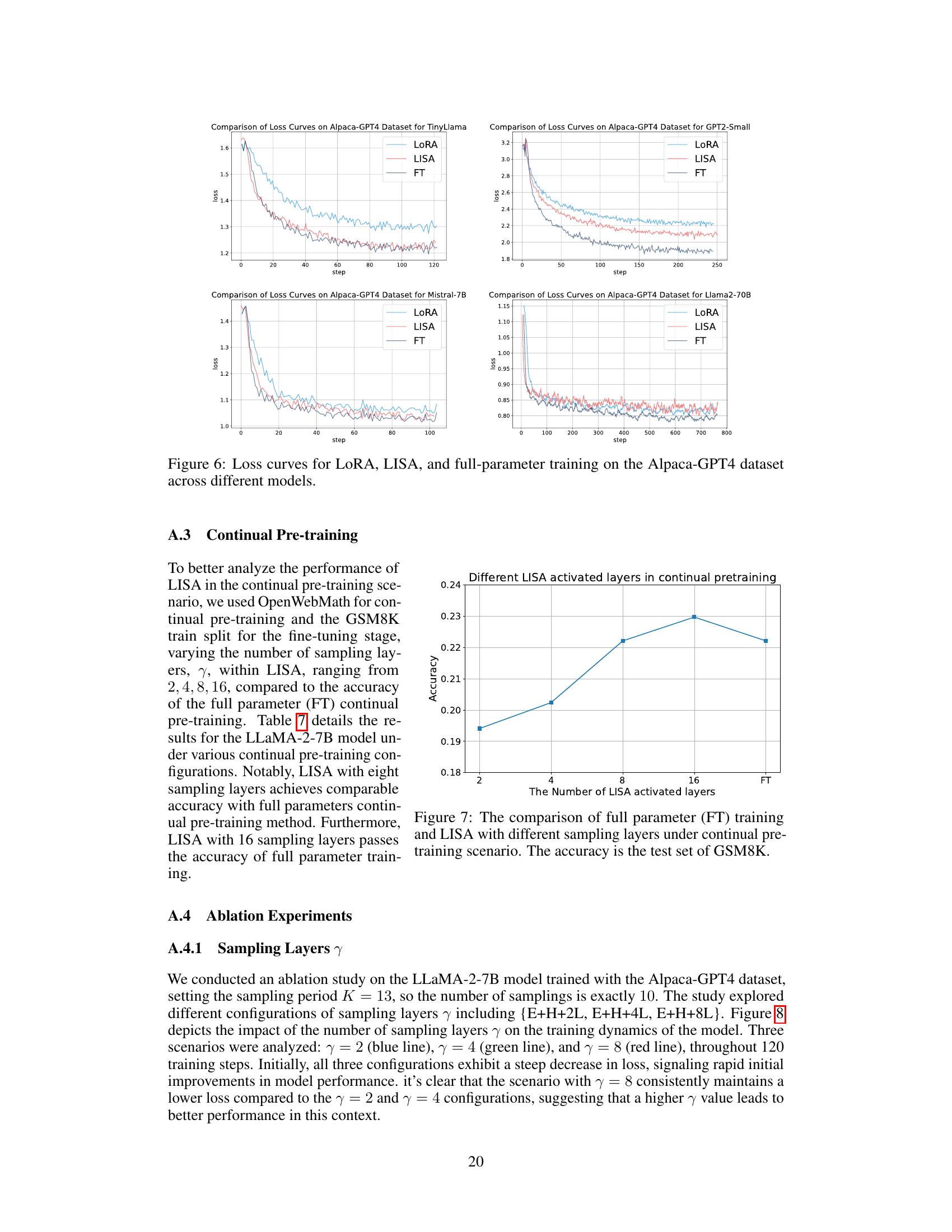
This figure compares the training loss curves of four different methods: LoRA, LISA, full parameter fine-tuning (FT), and GaLore, across four different language models (TinyLlama, GPT2-Small, Mistral-7B, and LLaMA-2-70B). The x-axis represents the training step, and the y-axis represents the loss. The figure aims to show the convergence behavior and performance of each method relative to each other and full fine-tuning. By comparing the loss curves across these different models, the figure provides a visual representation of the relative efficiency and effectiveness of LISA compared to other parameter-efficient fine-tuning techniques and full fine-tuning in different model settings.
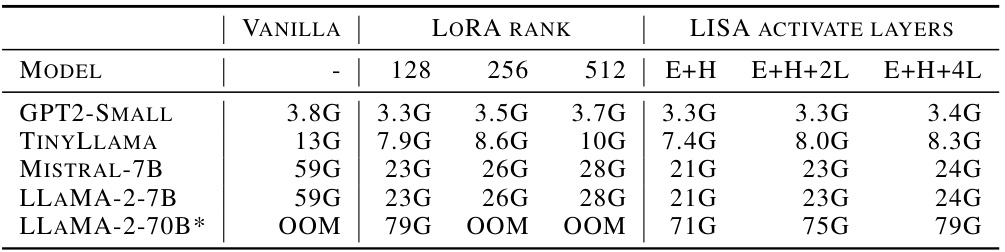
This table compares the peak GPU memory usage of several large language models (LLMs) under different fine-tuning methods: Vanilla (no fine-tuning), LoRA (low-rank adaptation), and LISA (layerwise importance sampling). It shows how memory usage varies with different LLM sizes and the number of layers activated during training. The LISA configurations show the number of layers used during training; ‘E’ denotes the embedding layer, ‘H’ the language model head, and ‘2L’ and ‘4L’ indicate two and four additional intermediate layers activated, respectively. The table highlights that LISA can significantly reduce memory usage, making it possible to train large models on less powerful hardware.
In-depth insights#
LISA’s Memory Gains#
The research paper’s findings on LISA’s memory efficiency are noteworthy. LISA consistently reduces memory consumption compared to LoRA and even full parameter fine-tuning, a critical advantage for researchers with limited computational resources. This is achieved by a novel layerwise importance sampling method that selectively updates only the most crucial layers of the large language model (LLM), leaving others untouched. This targeted approach significantly reduces the activation memory footprint. The results highlight that LISA’s memory savings are not incidental but rather systematic across diverse model architectures and downstream tasks, suggesting its broader applicability and scalability. The paper’s experimental setup rigorously isolates LISA’s memory efficiency, showcasing its compatibility with commonly used large-scale training techniques. This makes LISA a strong contender as a parameter-efficient fine-tuning technique for LLMs, offering both improved performance and reduced resource demands.
Layerwise Importance#
The concept of ‘Layerwise Importance’ suggests a method for analyzing and potentially optimizing deep learning models by assessing the relative contribution of each layer. A core idea is that not all layers contribute equally to the model’s overall performance. Some layers might be more crucial for learning specific features or aspects of the data, while others might be less influential. This uneven contribution could be due to several factors, such as the inherent complexity of the data itself, the architecture of the network, or even the training process. Identifying these high-impact layers enables selective training or fine-tuning techniques, such as layer freezing or importance sampling, to improve efficiency and performance. For instance, focusing training efforts on these crucial layers could save considerable computational resources and reduce the risk of overfitting while maintaining accuracy. The challenge lies in developing robust methods for accurately quantifying layer-wise importance. This may require sophisticated techniques involving analyzing gradients, activations, or weight changes throughout training to identify layers that have a significant effect on the overall output. Investigating the implications for various model architectures and datasets is critical for validating the utility and limitations of such techniques.
LISA vs. LoRA#
The comparison of LISA and LoRA in the context of large language model fine-tuning reveals key distinctions. LISA (Layerwise Importance Sampled AdamW), unlike LoRA (Low-Rank Adaptation), leverages the observed skewed weight distribution across LLM layers during LoRA training. LISA capitalizes on this by selectively freezing most layers, updating only crucial layers identified by their weight norms; hence resulting in memory efficiency comparable to or exceeding LoRA. LISA demonstrates superior performance on several downstream tasks, outperforming LoRA in various benchmarks by a significant margin (10-35% improvement on MT-Bench). This performance advantage, coupled with its memory efficiency, positions LISA as a strong contender to LoRA for resource-constrained fine-tuning scenarios. LISA’s effectiveness is robust across different model sizes, ranging from 7B to 70B parameters, highlighting its scalability. While LoRA’s low-rank adaptation offers advantages, LISA’s layerwise importance sampling approach presents a compelling alternative, particularly in scenarios where memory is a limiting factor, showcasing the potential for more memory-efficient and effective LLM fine-tuning strategies.
LISA’s Ablation#
The ablation study for LISA, a layerwise importance sampling method for efficient large language model fine-tuning, systematically investigates the impact of key hyperparameters. The number of sampled layers (γ) significantly influences performance, with higher values generally improving results but at the cost of increased memory consumption. The sampling period (K), determining how frequently layers are re-evaluated, also demonstrates an optimal range, suggesting that too frequent or infrequent sampling hinders performance. The ablation study highlights the importance of carefully balancing these hyperparameters to optimize the trade-off between memory efficiency and downstream task performance. Crucially, experiments reveal that LISA’s efficacy stems from intelligently selecting which layers to update, rather than relying on uniformly random sampling, showcasing the method’s thoughtful design and capacity for achieving considerable performance gains.
Future of LISA#
The future of LISA (Layerwise Importance Sampling for AdamW) looks promising, particularly given its demonstrated efficiency gains over LoRA and even full parameter fine-tuning in several benchmarks. LISA’s key advantage lies in its memory efficiency, which allows for training larger models on less powerful hardware. However, further research is needed to fully understand the impact of layerwise sampling and optimize the sampling strategy. Exploring different sampling distributions, perhaps informed by analyzing layerwise importance scores beyond simple weight norms, could enhance performance further. Investigating LISA’s compatibility and performance within different LLM architectures beyond those tested is crucial. Integrating LISA with other parameter-efficient techniques, such as quantization, could lead to even greater efficiency gains. Finally, developing a theoretical framework to fully explain LISA’s effectiveness and guide the selection of optimal hyperparameters remains a key area for future work.
More visual insights#
More on figures
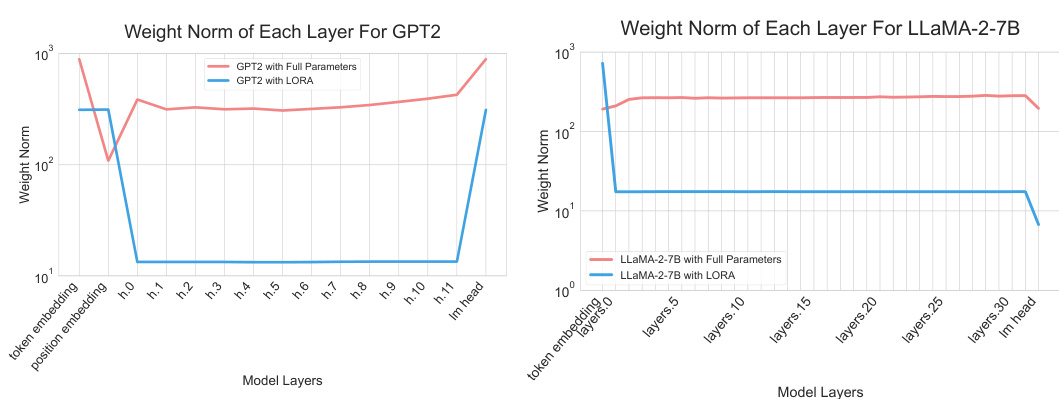
This figure shows the mean weight norms of each layer during training with LoRA and full parameter training for GPT-2 and LLaMA-2-7B models. The x-axis represents the layer, from the embedding layer to the final layer. The y-axis shows the mean weight norm of each layer. The figure highlights a key observation from the paper: LoRA training shows a skewed distribution of weight norms, with the embedding and output layers having significantly larger norms than the intermediate layers. This is in contrast to full parameter training, where the weight norm distribution is more even across layers.
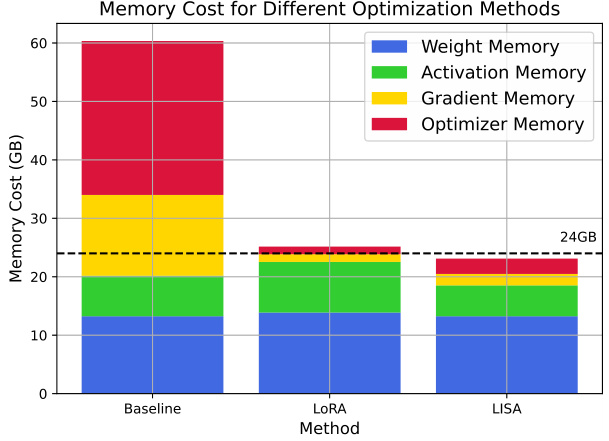
This figure compares the GPU memory consumption of different optimization methods for training the LLaMA-2-7B model with a batch size of 1. The methods compared are the baseline (full parameter training), LoRA, and the proposed LISA method. The chart is a stacked bar chart showing the breakdown of memory usage into four categories: Weight Memory, Activation Memory, Gradient Memory, and Optimizer Memory for each method. A horizontal dashed line indicates the 24GB memory capacity of a single GPU. The figure visually demonstrates that LISA achieves comparable memory efficiency to LoRA and significantly less memory usage compared to the baseline.
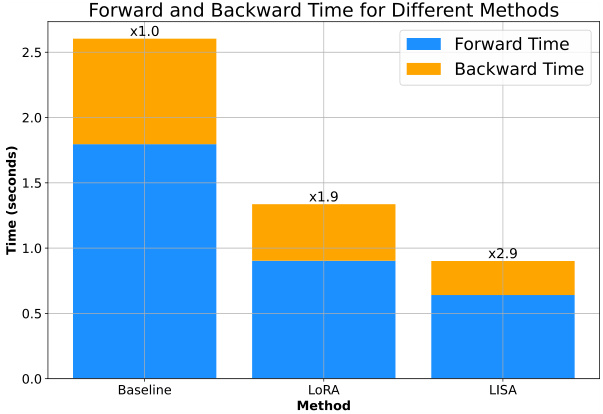
This figure shows a bar chart comparing the single-iteration time cost for three different optimization methods: Baseline (full parameter training), LoRA, and LISA. The chart is broken down into forward and backward pass times. LISA shows a significant reduction in the total iteration time (2.9 times faster than baseline), mostly due to less backward pass time, demonstrating its superior efficiency. The LoRA method also shows some speed improvement compared to the baseline method.

This figure compares image generation results using two different methods, LoRA and LISA, on two versions of the Stable Diffusion model. The top row shows images generated after 2 inference steps, while the bottom row shows images generated after 10 inference steps. The comparison highlights the difference in image quality and detail between LoRA and LISA, showcasing LISA’s ability to generate higher-quality images with more intricate details and sharper clarity, particularly evident in facial features and environmental textures, even with fewer inference steps.

This figure displays the training loss curves for four different language models (TinyLlama, GPT2-Small, Mistral-7B, and LLaMA-2-70B) using three different fine-tuning methods: LoRA, LISA, and full parameter fine-tuning. Each curve represents the average loss over multiple training steps, showing how the loss changes over time during training. The plots allow a comparison of the convergence speed and final loss achieved by each method for each model, highlighting the relative performance of LISA compared to LoRA and full parameter fine-tuning.
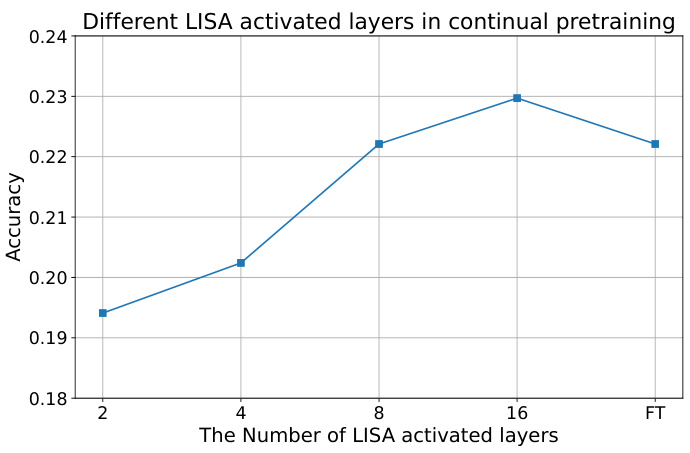
This figure shows the results of continual pre-training experiments using the LLaMA-2-7B model. The accuracy on the GSM8K test set is plotted against the number of activated layers in the LISA method. The results are compared to the accuracy achieved with full parameter training (FT). The graph demonstrates how increasing the number of activated layers in LISA generally improves accuracy, eventually surpassing the performance of full parameter training.
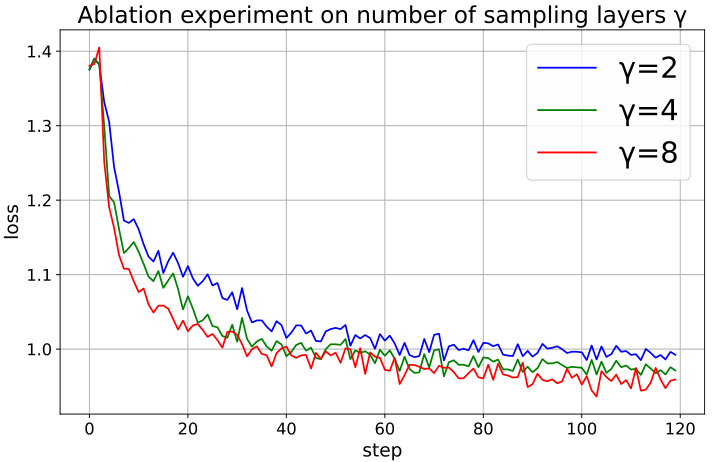
The figure shows the impact of varying the number of sampling layers (γ) on the training loss during the fine-tuning of a language model. Three different values of γ (2, 4, and 8) are compared, with each corresponding to a different line on the plot. The plot shows that a higher value of γ generally leads to a lower loss, indicating that more sampling layers lead to better model performance. However, the differences in loss are relatively small.
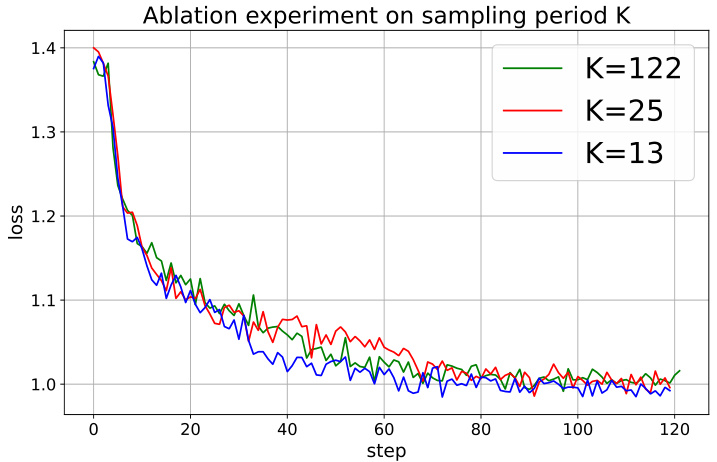
This figure shows the effects of varying the sampling period K (K=122, K=25, K=13) on the training loss for a 7B-sized model using the 52K-entry Alpaca-GPT4 dataset. The loss curves for different sampling periods are plotted against the number of training steps (0-122). While the loss curves vary initially, they show similar convergence behavior, suggesting that the optimal sampling period K for this model and dataset might be around 13.

This figure shows the results of an ablation study on the impact of randomness in layer selection during the training process using LISA. Three separate training runs were performed with different random seeds for selecting the layers to be updated. The plot displays the loss values over a series of training steps for each of the three runs. The purpose is to demonstrate the robustness and consistency of LISA’s performance even with different random layer selections.
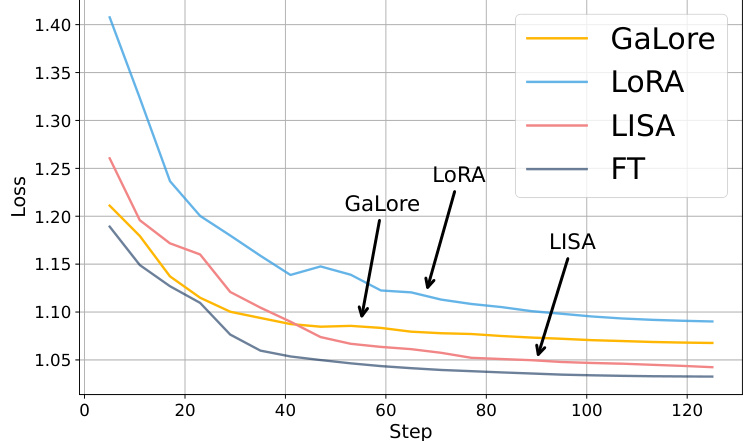
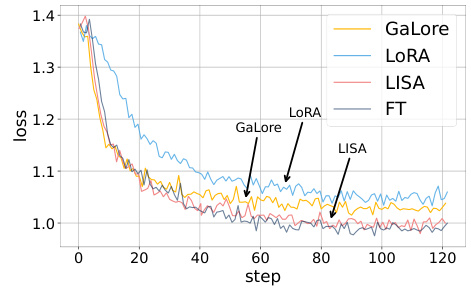
This figure compares the validation loss curves of four different fine-tuning methods: Full Parameter Fine-Tuning (FT), LoRA, GaLore, and the proposed LISA method, for the LLaMA-2-7B model trained on the Alpaca-GPT4 dataset. The x-axis represents the training steps, and the y-axis shows the validation loss. The arrows highlight key points in the curves, illustrating the relative performance and convergence behavior of each method. LISA demonstrates comparable or even better performance compared to other methods, with a potentially more stable convergence.
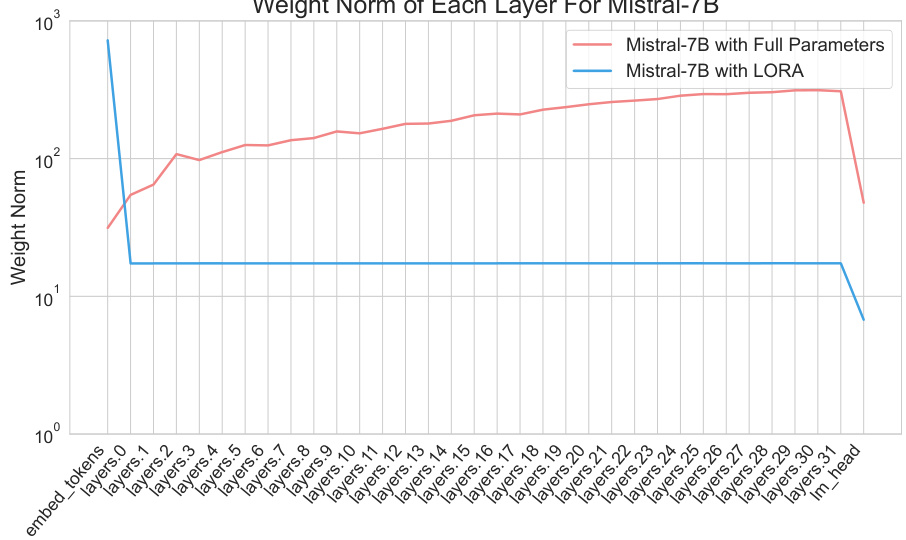
This figure shows the weight norms of different layers in the Mistral-7B model during training with LoRA and full parameter training. The x-axis represents the layer, starting from the embedding layer and ending at the linear layer. The y-axis represents the weight norm of that layer. The figure demonstrates a similar trend observed in other models (like Llama-2): with full parameter training the weight norms for most layers show similar values. With LoRA training however, the weight norms are significantly higher for the embedding layer and the last layer (lm_head). The observation that the weight norms are concentrated in the embedding and output layers when using LoRA is a key observation that motivates the LISA algorithm.
More on tables

This table presents the accuracy results of various fine-tuning methods (Vanilla, LoRA, GaLORE, LISA, and Full Fine-tuning) on three different benchmark datasets: MMLU (multitask language understanding), AGIEval (general abilities), and WinoGrande (commonsense reasoning). It demonstrates the performance of LISA compared to other methods across various tasks and model architectures.
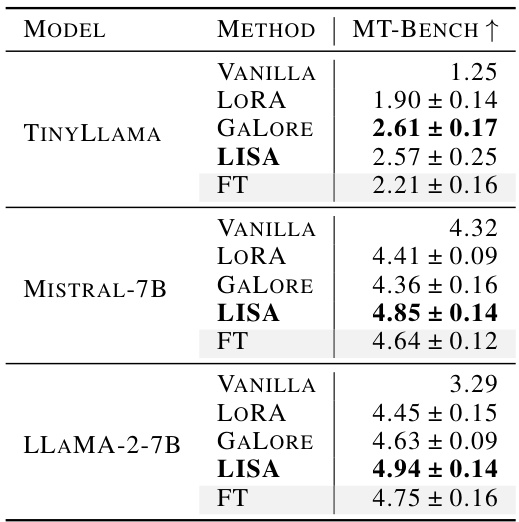
This table presents the results of different fine-tuning methods (Vanilla, LoRA, GaLore, LISA, and Full Parameter Training) on the MT-Bench benchmark for three different language models (TinyLlama, Mistral-7B, and LLaMA-2-7B). The MT-Bench score, which is a metric for evaluating the overall performance of a language model across a range of tasks, is reported for each method and model. The results show the effectiveness of LISA in outperforming other methods in terms of achieving higher MT-Bench scores.
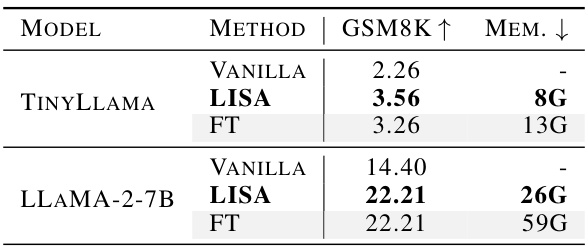
This table presents the results of continual pre-training experiments on the GSM8K dataset using different methods for two LLMs: TinyLlama and LLaMA-2-7B. The methods compared are Vanilla (no fine-tuning), LISA (the proposed method), and Full Fine-tuning (FT). The table shows the GSM8K accuracy scores and the peak GPU memory consumption (MEM.) for each model and method. The results highlight LISA’s ability to achieve competitive or even better performance than FT with significantly less memory usage.
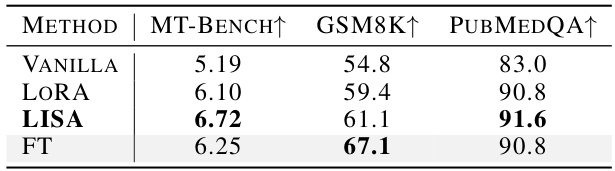
This table presents the performance comparison of four different fine-tuning methods (Vanilla, LoRA, LISA, and Full Parameter Training) on three benchmark datasets: MT-Bench, GSM8K, and PubMedQA. The results are presented for the LLaMA-2-70B model, showing the improvement achieved by LISA in terms of MT-Bench, GSM8K, and PubMedQA scores compared to the other methods. The scores represent the model’s accuracy or performance on each specific task.

This table presents the results of an ablation study on the LISA algorithm, investigating the effect of different hyperparameter combinations on the MT-Bench score. The study varied the number of sampling layers (γ) and the sampling period (K), while keeping the learning rate constant at 10-5. The results show how these hyperparameters influence the model’s performance. Specifically, it shows the MT-Bench score achieved for each combination across two different LLMs: TinyLlama and LLaMA-2-7B.
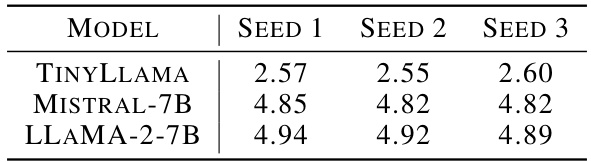
This table presents the results of the MT-Bench evaluation metric for three different random seeds used in the layer selection process. It demonstrates the robustness of the LISA method by showing consistent performance across different random seed initializations, indicating that the performance is not overly sensitive to the specific random seed used.
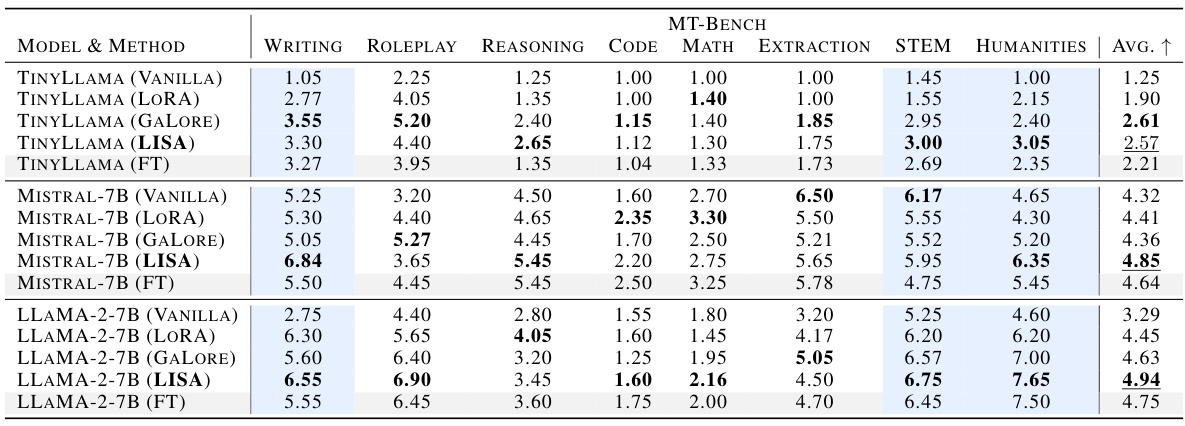
This table presents a comprehensive comparison of the performance of four different fine-tuning methods (Full Parameter Fine-Tuning (FT), Low-Rank Adaptation (LoRA), Gradient Low-Rank Projection (GaLore), and Layerwise Importance Sampling AdamW (LISA)) across a diverse range of tasks within the MT-Bench benchmark. The tasks cover various aspects of language understanding, including writing, roleplaying, reasoning, coding, math, extraction, STEM, and humanities. The table shows the average score for each method across these tasks, allowing for a direct comparison of their relative effectiveness in different domains.

This table presents the average MT-Bench scores across three different random seeds for the LLaMA-2-70B model. It compares the performance of three fine-tuning methods: Vanilla (baseline), LoRA, and LISA. The scores are broken down by task category (Writing, Roleplay, Reasoning, Code, Math, Extraction, STEM, Humanities) to allow for a more granular analysis of the model’s strengths and weaknesses under each fine-tuning method. The average score across all tasks is also provided for each method.
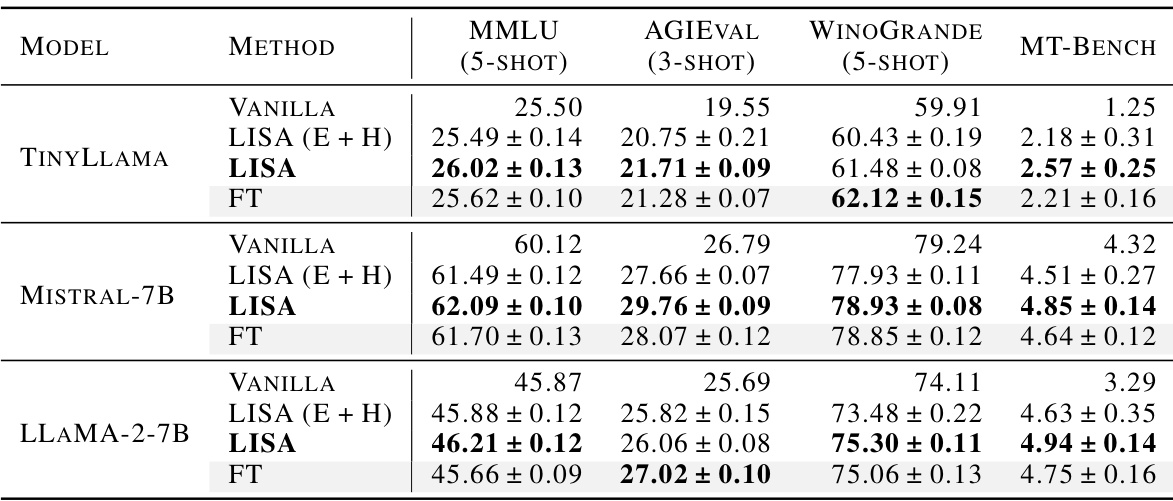
This table presents the performance comparison of various fine-tuning methods (Vanilla, LoRA, GaLORE, LISA, and Full Parameter Training) across three different benchmarks: MMLU, AGIEval, and Winogrande. Each benchmark assesses different aspects of language model capabilities, and the results are reported as accuracy scores with standard deviations. This allows for a comprehensive evaluation of the methods’ effectiveness across various tasks and provides insights into their relative strengths and weaknesses.

This table compares the peak GPU memory usage of different large language models (LLMs) under various fine-tuning methods. The models include GPT2-Small, TinyLlama, Mistral-7B, LLaMA-2-7B, and LLaMA-2-70B. Fine-tuning methods include vanilla training, LoRA with different rank sizes, and LISA with varying numbers of activated layers. The LISA configurations are denoted with ‘E’ (embedding layer), ‘H’ (head layer), and ‘2L’ (two additional layers). The table highlights how LISA achieves memory efficiency compared to other methods, especially for larger models. Model parallelism was used for the 70B model.
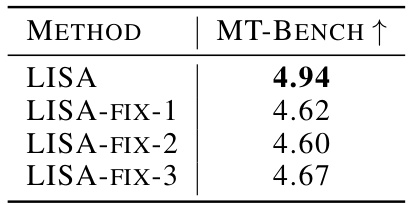
The table presents the results of an ablation study on the LLaMA-2-7B model to evaluate the impact of fixing the randomly selected layers during training. It shows that randomly selecting layers generally outperforms the fixed-layer approach. The results are presented with three different seeds for the random layer selection.
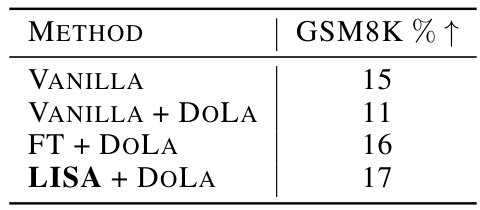
This table presents the GSM8K accuracy improvement percentage (%) for four different training methods on the LLaMA-2-7B model. These methods are: Vanilla (baseline), Vanilla with the early exiting strategy DoLA, Full Parameter Fine-Tuning (FT) with DoLA, and LISA with DoLA. The results show that incorporating LISA with DoLA yields the highest improvement in performance.
This table compares the peak GPU memory usage of different LLMs (GPT2-Small, TinyLlama, Mistral-7B, LLaMA-2-7B, and LLaMA-2-70B) under various fine-tuning methods: Vanilla (full parameter training), LoRA with different ranks, and LISA with different numbers of activated layers (embedding, head, and additional intermediate layers). It highlights how LISA can significantly reduce memory consumption compared to full parameter training and LoRA, especially for larger models.
This table compares the peak GPU memory usage for different large language models (LLMs) under various fine-tuning configurations. The models include GPT2-Small, TinyLlama, Mistral-7B, LLaMA-2-7B, and LLaMA-2-70B. Each model is evaluated under several configurations: Vanilla (full parameter training), LoRA (Low-Rank Adaptation) with different ranks (128, 256, 512), and LISA (Layerwise Importance Sampled AdamW) with varying numbers of activated layers (embedding and head only, embedding, head and 2 intermediate layers, embedding, head and 4 intermediate layers). The table shows that LISA generally requires less memory than LoRA and, in some cases, even less than full parameter training, demonstrating its memory efficiency.
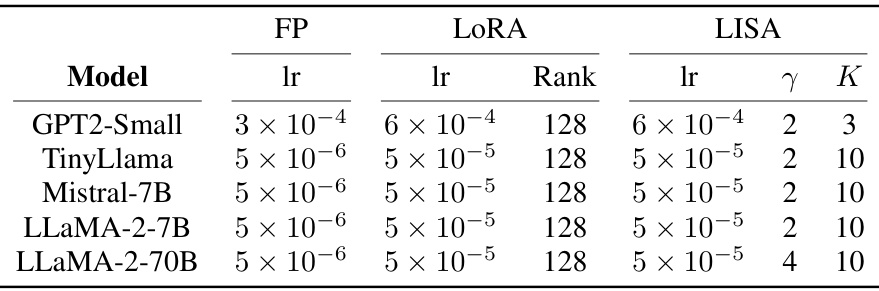
This table presents the hyperparameters used for each of the four fine-tuning methods (Full Parameter Training, LoRA, GaLore, and LISA) across five different language models (GPT2-Small, TinyLlama, Mistral-7B, LLaMA-2-7B, and LLaMA-2-70B). For each model and method, the table shows the learning rate (lr) used, as well as the rank (for LoRA) and the number of sampling layers (γ) and sampling period (K) (for LISA). These hyperparameters were determined through a hyperparameter search to identify the optimal settings for each method and model.
Full paper#