↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generative Flow Networks (GFlowNets) sample objects proportionally to a reward function, but often under-exploit high-reward objects due to limited training data. This leads to a discrepancy between the estimated flow and the actual reward. Existing methods try to address this by increasing the amount of training data.
The paper introduces a novel pessimistic backward policy (PBP-GFN) to improve GFlowNets’ performance. PBP-GFN maximizes the observed backward flow to better match the true reward. Experiments across diverse benchmarks demonstrate PBP-GFN enhances the discovery of high-reward objects, improves the accuracy of the learned Boltzmann distribution, and outperforms existing methods. This simple yet effective modification significantly improves GFlowNets’ ability to find desirable outcomes.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of GFlowNets, improving their ability to discover high-reward objects and enhancing their overall sampling performance. This directly impacts several fields, including molecular design and sequence generation, where finding optimal solutions is crucial. The proposed method also opens avenues for further research into improving the exploration-exploitation balance in generative models.
Visual Insights#

This figure illustrates how the conventional flow matching in GFlowNets may underestimate the high-reward objects due to insufficient observed trajectories. Panel (a) shows a simple grid-world environment to explain the concept. Panel (b) shows that conventional flow matching underestimates the high-reward object because the observed backward flow is low. Panel (c) demonstrates that the proposed method, PBP-GFN, successfully aligns the observed backward flow with the true reward, leading to a better estimation of high-reward objects.
In-depth insights#
Pessimistic GFNs#
Pessimistic GFlowNets (GFNs) represent a novel approach to address the under-exploitation of high-reward objects, a common limitation in standard GFN training. By maximizing observed backward flow, pessimistic GFNs aim to better align the learned flow with the true reward distribution, thereby improving the discovery of high-reward objects. This is achieved by modifying the backward policy to be more pessimistic, focusing on the observed, high-reward portion of the trajectory space. Unlike optimistic approaches that explore extensively, pessimistic GFNs prioritize exploitation, leading to a more accurate and efficient learning process, especially when dealing with limited data or high-dimensional spaces. However, this focus on exploitation might lead to a trade-off with exploration, potentially hindering the discovery of novel high-reward objects. Further research could investigate strategies to balance this exploitation-exploration trade-off, ensuring the discovery of both known high-reward objects and potentially unseen ones. The effectiveness of pessimistic GFNs has been demonstrated across diverse benchmarks, indicating its potential as a significant improvement over conventional GFN training methods.
Under-Exploitation Issue#
The paper identifies an under-exploitation issue in Generative Flow Networks (GFlowNets) where high-reward objects are under-sampled during training. This is primarily attributed to the reliance on observed trajectories, which may not fully capture the true reward distribution, leading to an inaccurate estimation of the flow. The core problem arises from the limited number of observed trajectories, resulting in an under-representation of high-reward objects in the backward flow, which consequently biases the forward policy towards low-reward objects. The authors highlight this as a critical limitation of conventional flow-matching objectives, where the forward flow’s tendency to align primarily with the observed backward flow, rather than the true reward function, restricts the discovery of high-reward states. This under-determination of the forward flow ultimately undermines the objective of sampling objects proportionally to their rewards. Therefore, the paper argues for a more robust and accurate representation of high-reward states during training, which would lead to an improved sampling performance.
PBP-GFN Algorithm#
The PBP-GFN algorithm tackles the under-exploitation problem in GFlowNets by implementing a pessimistic backward policy. This addresses the issue where GFlowNets, due to limited training trajectories, underrepresent high-reward objects. Instead of simply matching observed backward flow, PBP-GFN maximizes it, pushing the observed flow closer to the true reward. This clever approach enhances the discovery of high-reward objects while maintaining diversity. The algorithm’s effectiveness stems from its ability to align observed backward flow with true reward values, thereby improving the accuracy of the learned Boltzmann distribution. This is achieved by modifying the backward policy while preserving the asymptotic optimality, ensuring the algorithm remains theoretically sound. The pessimistic backward policy training involves maximizing the observed backward flow for observed trajectories, thus reducing the influence of the unobserved flow. Extensive benchmarks demonstrate its consistent outperformance of existing methods.
Empirical Validation#
An effective empirical validation section in a research paper should meticulously demonstrate the practical effectiveness of the proposed methodology. It should go beyond simply presenting results; it needs to provide a comprehensive analysis that addresses several key points. First, a clear description of the experimental setup is crucial, including datasets used, evaluation metrics, and any preprocessing steps. The selection of datasets should be justified, showcasing their relevance and representativeness of real-world scenarios. Furthermore, a thorough comparison against existing state-of-the-art methods is essential, providing a baseline for evaluating the novelty and improvement introduced by the proposed approach. The results section should present both quantitative and qualitative findings, employing clear visualizations such as graphs and tables to illustrate key trends and statistical significance of differences between methods. Finally, the discussion section should provide an in-depth analysis of the results, interpreting the findings in context and explaining any unexpected observations or limitations. Statistical significance testing should be explicitly mentioned and appropriately used to support any claims of superiority. Overall, a strong empirical validation section should exhibit both rigor and clarity, effectively convincing the reader of the methodology’s practical value and robustness.
Exploration/Exploit Tradeoff#
The exploration-exploitation trade-off is a central challenge in reinforcement learning, and the paper’s exploration of this trade-off within the context of GFlowNets is particularly insightful. The core problem is that the algorithm, while aiming for reward maximization, may under-exploit high-reward areas due to insufficient trajectory sampling. This leads to a mismatch between observed flow and true reward, hindering efficient learning. The proposed pessimistic backward policy directly addresses this by prioritizing the maximization of observed backward flow, thereby encouraging the exploration of high-reward areas even with limited data. However, this approach inherently biases toward exploitation, potentially limiting exploration of novel, potentially high-reward, areas of the state space. The paper acknowledges this limitation, suggesting further research into balancing this trade-off might involve techniques to enhance exploration while maintaining the algorithm’s exploitation efficiency. Further study could explore adaptive methods that dynamically adjust the exploration-exploitation balance based on the learning progress or characteristics of the problem domain. Ultimately, the effectiveness of the proposed methodology hinges upon finding the optimal balance between these two competing objectives.
More visual insights#
More on figures

This figure illustrates the under-exploitation problem in conventional flow matching and how the proposed pessimistic backward policy (PBP-GFN) addresses it. In (a), conventional flow matching, with limited observed trajectories, assigns higher probability to a lower-reward object because it has more observed backward flow. (b) shows that PBP-GFN corrects this by maximizing the observed backward flow, leading to a more accurate probability distribution aligned with the true rewards, thus resolving the under-exploitation problem.
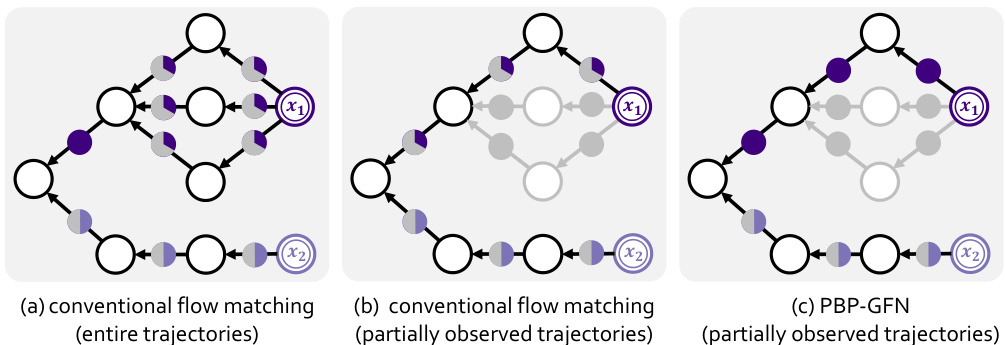
This figure shows how the proposed pessimistic backward policy (PBP-GFN) for GFlowNets addresses the under-exploitation problem. Panel (a) demonstrates that with complete trajectory information, the conventional flow matching correctly assigns probabilities proportional to the true reward. Panel (b) shows that with only partially observed trajectories, the conventional method underestimates the high-reward object due to insufficient backward flow. Panel (c) illustrates how PBP-GFN maximizes the observed backward flow, thereby aligning the observed flow with the true reward and improving the object sampling.

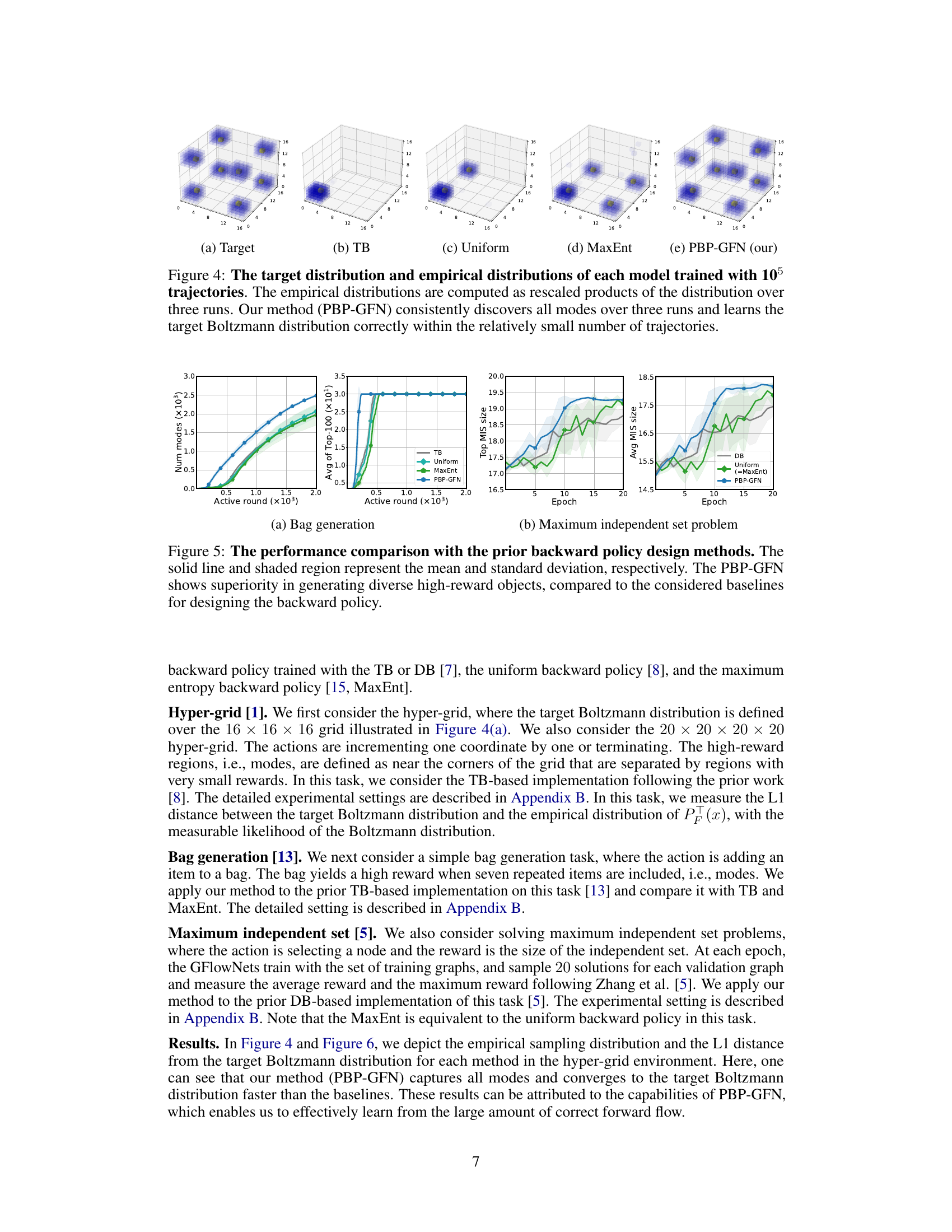
This figure compares the target Boltzmann distribution with the empirical distributions generated by five different models (TB, Uniform, MaxEnt, and PBP-GFN) after training with 100,000 trajectories. The visualization uses 3D density plots to show the distribution of objects in a 16x16x16 hypergrid. The results demonstrate that the proposed PBP-GFN method accurately learns the target distribution, unlike the other methods which show some discrepancies.

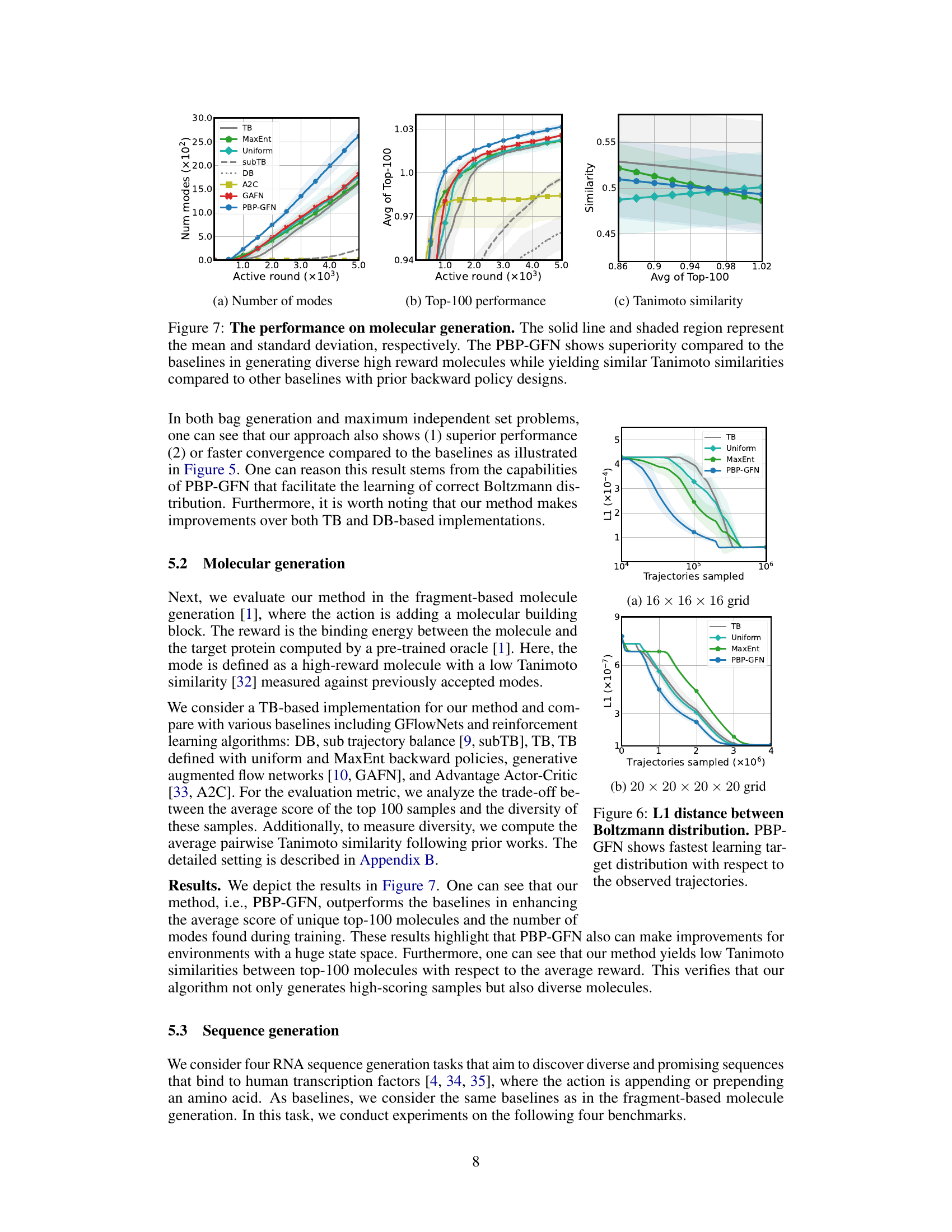
This figure compares the performance of PBP-GFN against baseline methods for backward policy design in two synthetic tasks: bag generation and maximum independent set problem. The plots show the number of high-reward objects generated and the average reward of the top 100 generated objects over training rounds or epochs. PBP-GFN consistently outperforms the baselines, demonstrating its effectiveness in generating diverse high-reward objects.

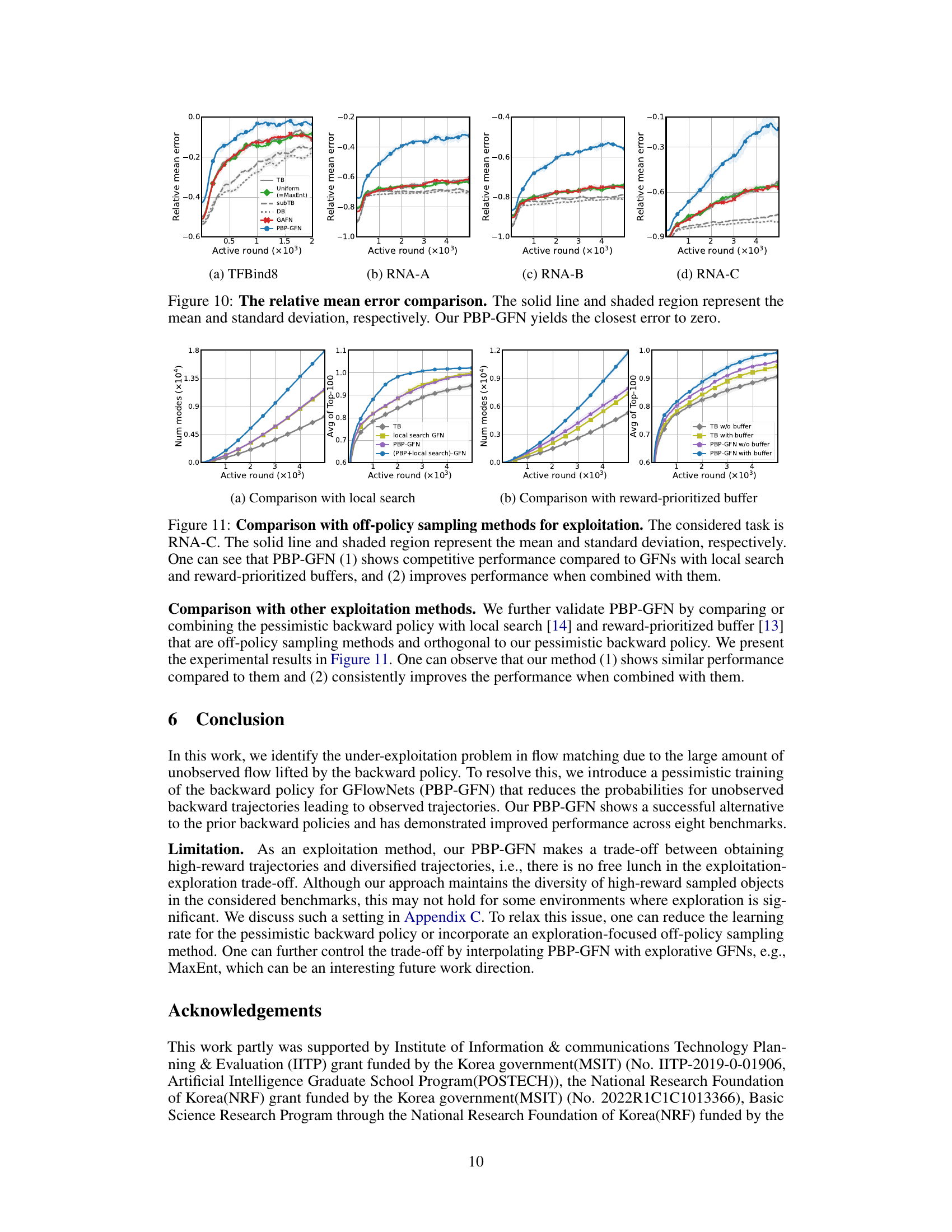
The figure compares the performance of PBP-GFN against other baselines for molecular generation. It shows PBP-GFN excels at generating diverse high-reward molecules while maintaining similar Tanimoto similarity scores to other methods. The plots illustrate the number of modes (high-reward molecules), the average top-100 performance, and the Tanimoto similarity, demonstrating the advantages of PBP-GFN in terms of diversity and reward.

This figure compares the target Boltzmann distribution with the empirical distributions generated by different models after training with 100,000 trajectories. The target distribution represents the ideal distribution the models aim to learn. The empirical distributions show how well each model approximates this target distribution. The results demonstrate that PBP-GFN effectively learns the target distribution, accurately capturing all high-probability regions (modes).

This figure compares the performance of PBP-GFN with other baseline methods for molecular generation. The results show that PBP-GFN achieves superior performance in terms of the number of high-reward molecules generated and the average top-100 performance, while maintaining comparable Tanimoto similarity scores, indicating a similar level of chemical diversity.

This figure compares the number of 2-Hamming ball modes discovered during training across different methods for RNA sequence generation. The x-axis represents the training progress (active rounds), and the y-axis represents the number of modes. PBP-GFN consistently discovers more modes than other methods, indicating improved diversity in the generated RNA sequences. Error bars (standard deviation) are included for each method, showing PBP-GFN’s consistent superiority.
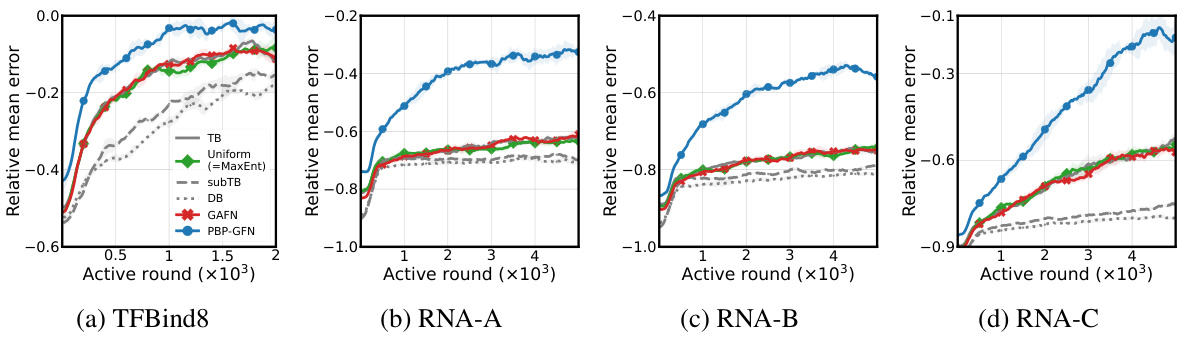
This figure compares the relative mean error of different methods for RNA sequence generation tasks across four benchmarks. The relative mean error measures the difference between the empirical distribution generated by each method and the target Boltzmann distribution. The results show that PBP-GFN consistently achieves the lowest relative mean error, indicating its superior performance in learning the target distribution.

The figure compares the performance of the proposed PBP-GFN method with existing methods for designing backward policies in GFlowNets. The y-axis shows metrics reflecting the ability of the model to generate high-reward objects. The x-axis represents the training progress. The results demonstrate that PBP-GFN consistently outperforms baselines in both generating high-reward objects and generating a diverse set of such objects.
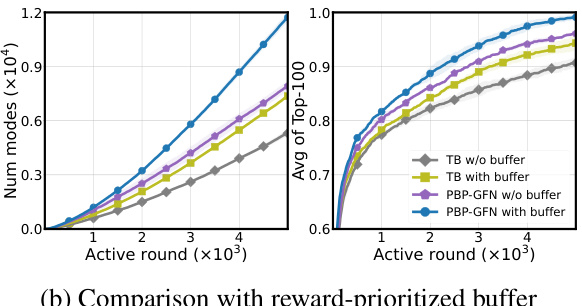
This figure compares the performance of the proposed PBP-GFN method against existing backward policy design methods (TB, DB, Uniform, MaxEnt) across two different tasks: bag generation and maximum independent set problem. The results illustrate that PBP-GFN consistently outperforms other methods in generating a diverse set of high-reward objects, demonstrating its effectiveness in addressing the under-exploitation problem of GFlowNets.

This figure illustrates how PBP-GFN addresses the under-exploitation problem in GFlowNets. Panel (a) shows that with complete trajectory observation, flow matching accurately reflects the reward distribution. Panel (b) demonstrates that with partial observation, conventional flow matching underestimates the reward of high-reward objects due to insufficient trajectory samples. Panel (c) shows that PBP-GFN improves the estimation by maximizing observed backward flow to better match the true reward, thus improving the selection of high-reward objects.
Full paper#