↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multimodal contrastive learning (MCL) methods struggle with feature suppression and shortcut learning because they treat all negative samples equally and neglect modality-specific information. This leads to suboptimal performance in downstream tasks. The focus on maximizing mutual information between views often ignores unique information.
The proposed method, QUEST, addresses these issues. It uses a novel framework that leverages quaternion vector spaces and orthogonal constraints to extract both shared and unique information effectively. A shared information-guided penalization mechanism prevents the over-influence of shared information during the optimization process. The experiments show that QUEST significantly outperforms existing MCL methods on various benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal contrastive learning. It addresses the limitations of existing methods by proposing a novel framework, QUEST, that effectively extracts both shared and unique information across modalities, leading to state-of-the-art performance. This opens new avenues for improving multimodal representation learning and tackling challenges like feature suppression and shortcut learning.
Visual Insights#

This figure shows the performance comparison of QUEST against other baselines on various image caption retrieval tasks using the CLIP model. Part (a) presents a bar chart visualizing the Recall@1 and RSUM values across different datasets, showcasing QUEST’s superior performance. Part (b) illustrates the quaternion embedding space created by QUEST. This space is designed to effectively separate shared and unique information, using constraints to pull shared representations closer, push unique representations further apart, and maintain orthogonality between shared and unique information.

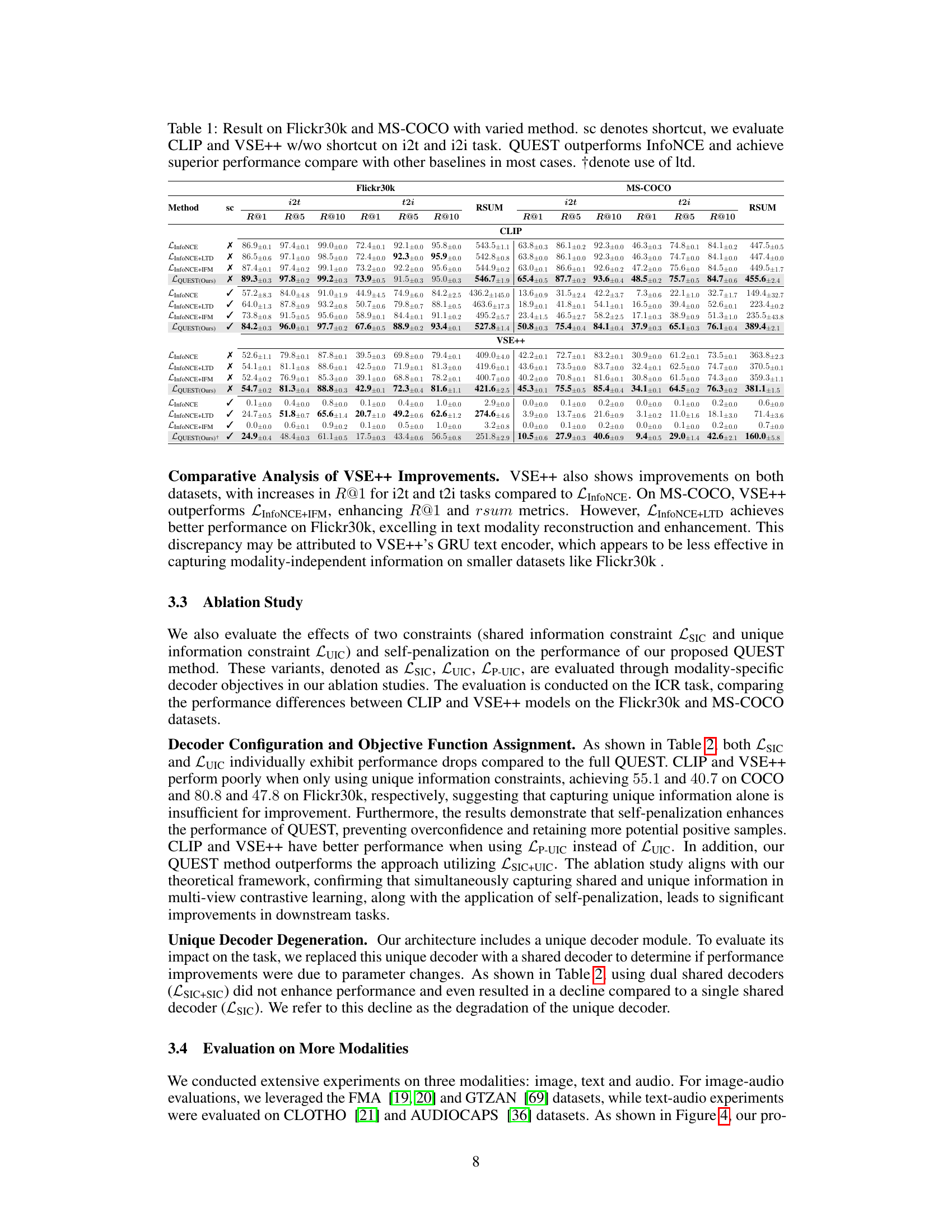
This table presents the performance comparison of different methods on image-text retrieval tasks using the Flickr30k and MS-COCO datasets. The methods compared include InfoNCE, InfoNCE with Latent Target Decoding (LTD), InfoNCE with Implicit Feature Modification (IFM), and the proposed QUEST method. The table shows the Recall@1 (R@1), Recall@5 (R@5), Recall@10 (R@10), and Recall Sum (RSUM) metrics for both image-to-text (i2t) and text-to-image (t2i) retrieval tasks. Results are presented for both scenarios with and without synthetic shortcuts (‘sc’ column) introduced to simulate easy-to-learn features. The table demonstrates that the QUEST method consistently outperforms the baseline methods across various metrics and scenarios.
In-depth insights#
Multimodal Contrastive Learning#
Multimodal contrastive learning (MCL) is a powerful technique for learning representations from multiple modalities, such as images and text. Its core idea is to learn representations that are invariant to the specific modality while maintaining discriminative information. MCL typically involves creating positive and negative pairs of multimodal data, training a model to pull positive pairs closer together in the embedding space, and push negative pairs farther apart. This approach leverages the power of contrastive learning to learn representations that capture shared information across modalities. However, traditional MCL methods often treat all negative samples equally, which can limit performance. Recent work has explored ways to improve MCL by incorporating constraints and self-penalization. For example, methods have been proposed to use orthogonal constraints to encourage the model to learn modality-specific information and self-penalization to prevent overfitting to shared information. These improvements help to address some of the limitations of traditional MCL approaches, leading to more robust and accurate multimodal representations. Further research is needed to investigate more sophisticated methods for extracting unique information across modalities and handle high-dimensional data effectively.
Quaternion Embeddings#
Employing quaternion embeddings in multimodal contrastive learning offers a compelling approach to disentangle shared and unique information within different modalities. Quaternions, as four-dimensional extensions of complex numbers, provide a richer representation space capable of encoding both shared and unique features simultaneously. This contrasts with traditional methods that often struggle to effectively balance these aspects, leading to suboptimal performance. By leveraging the properties of quaternions, such as their ability to represent rotations and orientations in four-dimensional space, the model can explicitly capture modality-specific information while maintaining alignment between shared representations. This is crucial for tasks where inter-modal relationships are complex, and simply maximizing mutual information between modalities is insufficient. The use of quaternion embeddings also allows for the incorporation of novel constraints and self-penalization techniques that further enhance the learning process and prevent shortcut learning. The resulting representations are more robust and generalizable, making them suitable for a wider range of downstream tasks and applications.
Shortcut Mitigation#
Shortcut mitigation in multimodal contrastive learning (MCL) focuses on preventing models from relying on easily learned, superficial correlations between modalities instead of deeper semantic understanding. Existing MCL approaches often fail to distinguish between genuinely shared information and spurious correlations, leading to suboptimal performance on downstream tasks. Effective mitigation strategies involve techniques that encourage the model to learn more robust and comprehensive representations. This can be achieved through careful data augmentation to reduce the impact of spurious correlations, constraining the model’s learning process to explicitly extract both shared and unique information, or by incorporating self-penalization mechanisms to discourage the model from excessively relying on easy shortcuts. Ultimately, the goal is to force the model to delve deeper into the data, extracting meaningful, task-relevant features rather than simple, easily exploitable patterns.
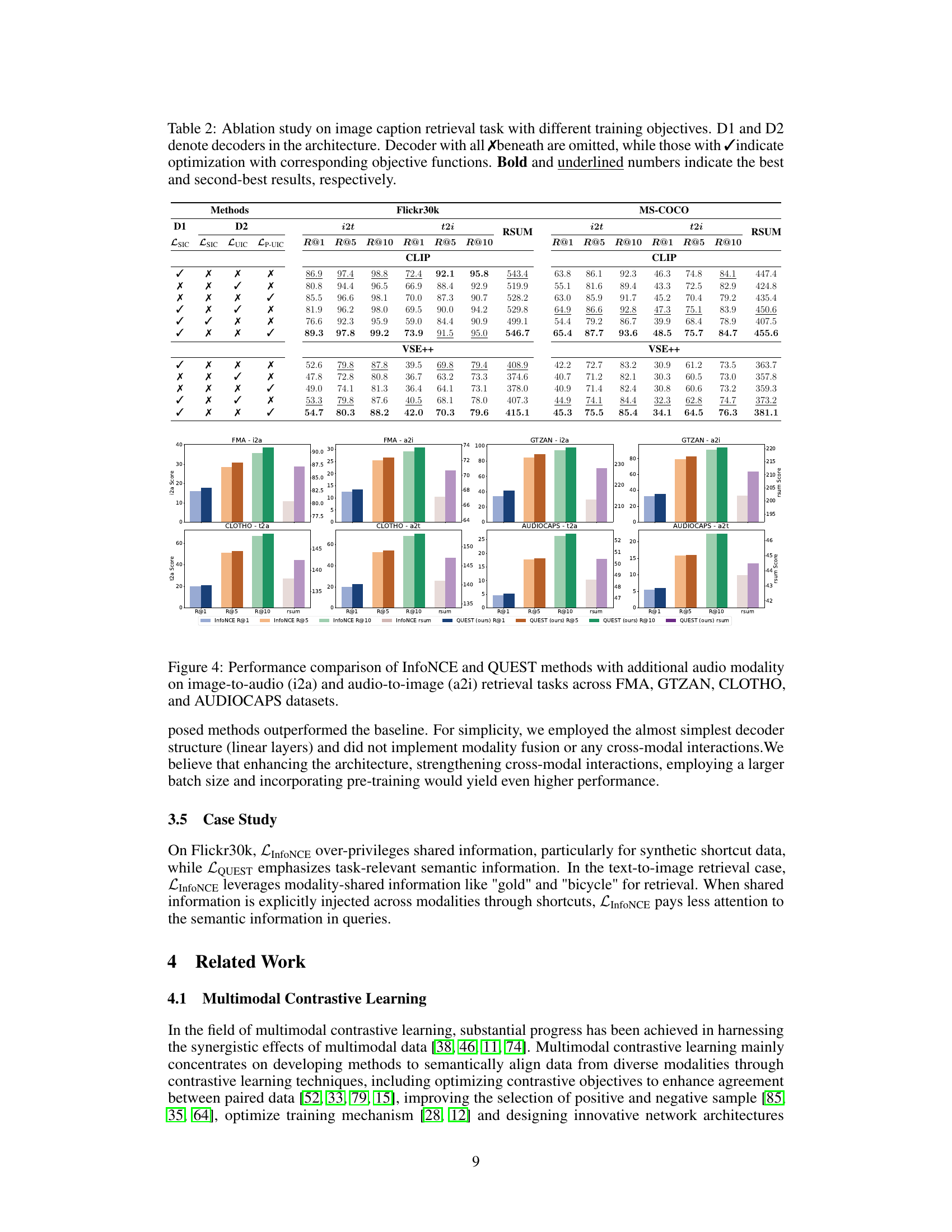
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of multimodal contrastive learning, this could involve removing decoders, constraints, or regularization techniques. By observing how performance changes, researchers can pinpoint crucial elements for effective multimodal representation learning. For example, removing a shared information constraint might reveal its impact on model ability to capture commonalities. Similarly, isolating the unique information constraint allows assessment of its effectiveness in preserving modality-specific details. Analyzing results from these experiments helps determine optimal model architecture and identify critical components that are essential for downstream task performance. Furthermore, ablation studies on self-penalization mechanisms illustrate their role in preventing the model from relying excessively on shared information and learning shortcuts, thereby promoting the learning of more robust and generalizable representations. Overall, a comprehensive ablation study provides a thorough understanding of the model’s inner workings and the relative importance of its constituent parts.
Future Directions#
The research paper’s ‘Future Directions’ section would ideally explore extending the model to handle even more modalities, perhaps incorporating audio or sensor data. A crucial area is developing more robust methods for high-dimensional data analysis, specifically addressing the limitations of cross-products in higher dimensions. The current approach’s reliance on pre-trained models for optimal unique information extraction could be improved by exploring self-supervised learning techniques to learn these features from scratch. Addressing the potential for bias and unfairness inherent in multimodal learning is a key ethical consideration requiring investigation and mitigation strategies. Finally, extending the framework to handle longer sequences and more complex tasks is necessary, as is more in-depth analysis of the trade-offs between shared and unique information extraction to optimize model performance and prevent over-reliance on shortcuts.
More visual insights#
More on figures

This figure illustrates the problem of feature suppression in multi-view contrastive learning. Before training with InfoNCE (left), there is a balance between shared and unique information for each modality. After training with InfoNCE (right), the model prioritizes maximizing shared information across modalities, leading to the suppression of unique, modality-specific information.
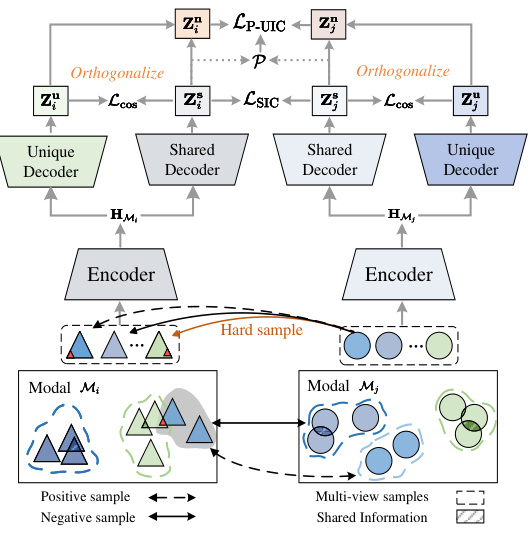
This figure illustrates the QUEST framework’s architecture. It shows how the model processes data from two modalities (Mi and Mj). Each modality has an encoder that extracts general features. These features are then passed to separate shared and unique decoders. The shared decoders focus on information common to both modalities, while the unique decoders extract modality-specific information. The framework uses constraints and self-penalization to optimize the extraction and integration of both shared and unique information, preventing the model from over-relying on easily learned shared information (shortcut learning) and ensuring that unique information is adequately represented. The figure also highlights the use of quaternion embedding space and orthogonal constraints to further improve performance.

This figure shows a comparison of the QUEST model’s performance against other baseline models (a), highlighting a significant performance improvement (97.95% on average). Part (b) illustrates the proposed quaternion embedding space which is designed to effectively separate and align shared and unique information from multiple modalities using constraints and self-penalization techniques. The visualization demonstrates how the constraints work to improve the separation of information.

Figure 1(a) shows the superior performance of QUEST (the proposed method) against existing baselines. This improvement is observed when using task-related unique information during training and evaluating the results on downstream tasks. Figure 1(b) illustrates how QUEST builds a quaternion embedding space. It uses constraints and self-penalization to better align both shared and unique representations from different modalities. The orthogonalization loss is applied to ensure that shared information does not overly affect the unique information.
More on tables
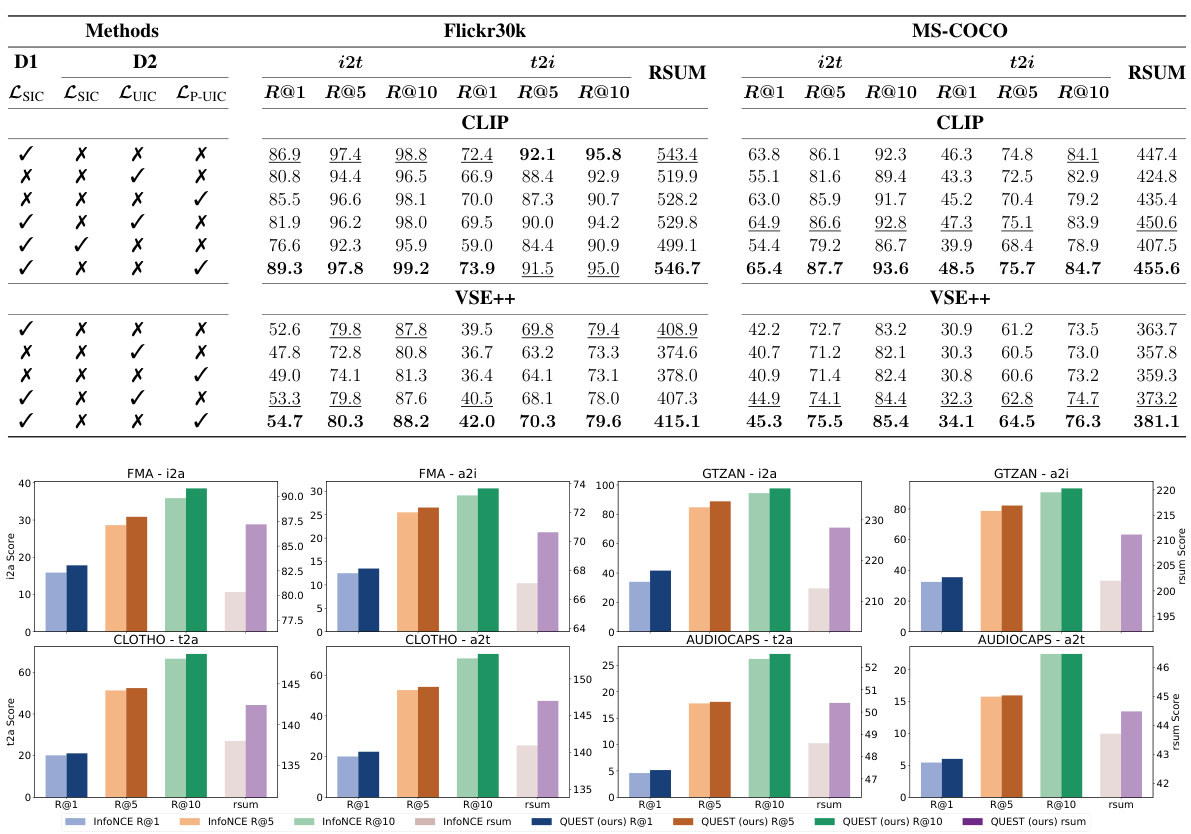
This table presents the performance comparison of different methods on image-text retrieval tasks using Flickr30k and MS-COCO datasets. The methods compared include InfoNCE, InfoNCE+LTD, InfoNCE+IFM, and the proposed QUEST method. Results are shown with and without synthetic shortcuts added to the data. The table shows Recall@1, Recall@5, Recall@10, and RSUM values for image-to-text (i2t) and text-to-image (t2i) tasks on both datasets. QUEST consistently outperforms other methods, particularly when mitigating shortcut learning.

This table presents the performance comparison of different models (InfoNCE, InfoNCE+LTD, InfoNCE+IFM, and QUEST) on image-to-text (i2t) and text-to-image (t2i) retrieval tasks using two datasets: Flickr30k and MS-COCO. The results show the Recall@1 (R@1), Recall@5 (R@5), Recall@10 (R@10), and Recall Sum (RSUM) metrics for each model and dataset, both with and without synthetic shortcuts added to the data. The table highlights that the proposed QUEST model consistently outperforms the baselines, demonstrating its effectiveness in multimodal contrastive learning.

This table presents the results of image-to-audio and audio-to-image retrieval experiments using two different datasets, FMA and GTZAN. For each dataset and retrieval task, it shows the performance of two methods: InfoNCE and QUEST. The performance is measured using Recall@1 (R@1), Recall@5 (R@5), Recall@10 (R@10), and the Recall sum (RSUM). The table compares the performance of the baseline InfoNCE method with the proposed QUEST method, demonstrating the improvement achieved by QUEST. This evaluation assesses the effectiveness of the proposed approach on two different audio datasets and different retrieval tasks.
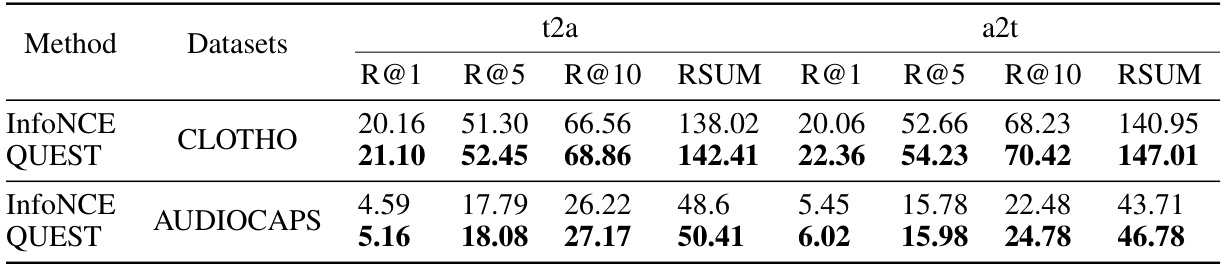
This table presents the performance of InfoNCE and QUEST methods on text-to-audio and audio-to-text retrieval tasks, using the CLOTHO and AUDIOCAPS datasets. The results are reported in terms of Recall@1, Recall@5, Recall@10, and RSUM (Recall Sum), providing a comprehensive evaluation of the retrieval accuracy for both methods and datasets.
Full paper#