TL;DR#
Many machine learning models predict patients’ health conditions from Electronic Health Records (EHRs). Multi-task learning (MTL) aims to improve prediction by jointly training models on related diseases, but current MTL methods heavily rely on human expertise for task grouping and model architecture design, which is time-consuming and suboptimal. This paper introduces the limitations of existing MTL approaches for EHR data analysis and explains the challenges of task grouping and architecture design for multi-task learning.
This research proposes AutoDP, an automated framework that tackles these challenges. AutoDP uses surrogate model-based optimization and a progressive sampling strategy to efficiently search for optimal task groupings and architectures simultaneously. Experiments show AutoDP significantly outperforms existing methods, demonstrating its effectiveness and efficiency in improving the performance of multi-task learning for EHR data. The findings highlight the potential of AutoML in healthcare for improving both accuracy and efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AutoDP, a novel automated framework for multi-task learning on electronic health records (EHRs). This addresses a critical need in the field by automating the design of both task grouping and model architectures, significantly improving prediction performance and reducing human intervention. Its use of surrogate model-based optimization and progressive sampling strategies makes it highly efficient and applicable to other domains. This opens up new avenues for research in AutoML and EHR analysis, impacting medical research and patient care. The framework’s open-source nature furthers its impact.
Visual Insights#

🔼 This figure provides a visual overview of the AutoDP framework, illustrating the different stages involved. Starting with data extraction from MIMIC-IV, it shows the multi-task learning (MTL) procedure, which includes searching for optimal task combinations and architectures. The surrogate model, progressive sampling, and greedy search methods are also highlighted, demonstrating how they contribute to finding the best configuration for multi-task disease prediction. The figure maps these steps to the relevant sections of the paper (Sections 3.1, 3.3, 3.4, and 3.5), allowing for easy cross-referencing.
read the caption
Figure 1: Overview of the proposed AutoDP
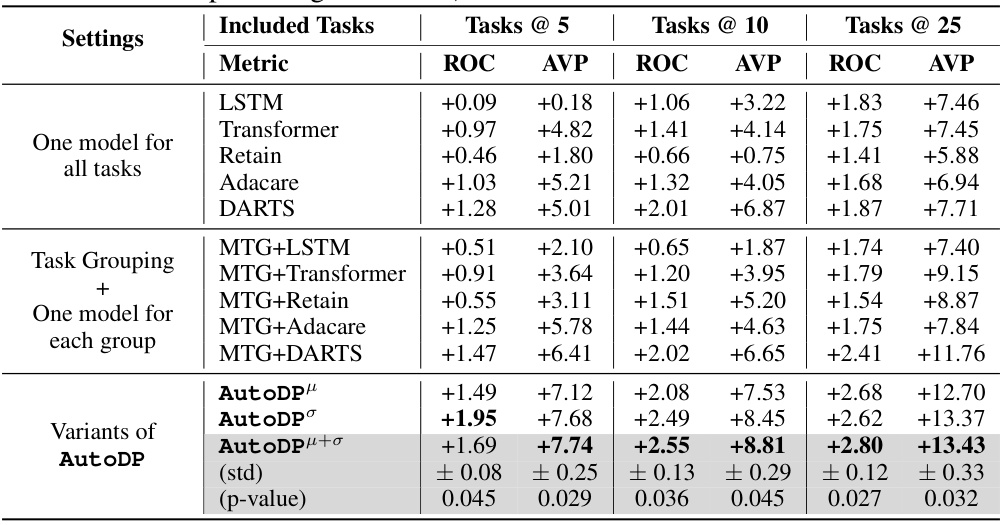
🔼 This table presents the performance comparison of different methods for multi-task learning on electronic health records (EHR). It compares several baselines including hand-crafted and automated methods with the proposed AutoDP framework. The table shows the averaged per-task gain in ROC and AVP metrics for three different settings: using the first 5, 10, and 25 tasks. Each setting includes different methods such as training one shared model for all tasks, task grouping with one model per group, and variations of AutoDP. The goal is to show the improved performance of AutoDP, especially when optimizing task grouping and model architectures.
read the caption
Table 1: Performance comparison in terms of averaged per-task gain over single task backbone (All results are in the form of percentage values %)
In-depth insights#
AutoDP Framework#
The AutoDP framework represents a novel approach to automated multi-task learning for joint disease prediction using Electronic Health Records (EHR). Its core innovation lies in the simultaneous optimization of both task grouping and model architecture. Unlike previous methods that relied on manual task grouping and hand-crafted architectures, AutoDP employs a data-driven approach to identify synergistic task combinations. This is achieved using surrogate model-based optimization, which efficiently searches a vast space of possible configurations. The framework incorporates a progressive sampling strategy, further enhancing efficiency by iteratively selecting and evaluating promising configurations. AutoDP’s end-to-end optimization significantly improves performance over existing methods, showcasing its potential to revolutionize EHR analysis and disease prediction. The key strength of AutoDP lies in its automation, which reduces reliance on human expertise and unlocks a greater potential for effective MTL applications in healthcare.
MTL Optimization#
Multi-task learning (MTL) optimization is a crucial area within machine learning research. It focuses on efficiently training models to perform multiple related tasks simultaneously. Effective MTL optimization requires careful consideration of task relationships. Poorly chosen task groupings can lead to negative transfer, where learning one task hinders performance in others. Conversely, well-selected tasks benefit from shared representations, resulting in improved efficiency and accuracy. Strategies such as automated task grouping and model architecture search are critical. These techniques aim to reduce human intervention in the design process, and to overcome the limitations of hand-crafted methods, which may not scale well to larger numbers of tasks. Furthermore, efficient optimization strategies are needed, given the vast search space inherent in exploring multiple task combinations and architectures. Surrogate model-based optimization, for example, can significantly reduce the computational cost of finding optimal configurations.
MIMIC-IV Results#
A hypothetical ‘MIMIC-IV Results’ section would ideally present a detailed analysis of the model’s performance on the MIMIC-IV dataset, a critical benchmark in healthcare machine learning. Expected content includes quantitative metrics such as AUC-ROC, AUPRC, precision, recall, F1-score, and accuracy, comparing the proposed multi-task learning (MTL) model against various baseline single-task and existing MTL approaches. The results should be stratified by individual disease or condition, allowing for a granular understanding of the model’s strengths and weaknesses in predicting specific health outcomes. Statistical significance testing (e.g., p-values) is crucial to establish that any observed performance differences are not due to chance. Importantly, the discussion should analyze the impact of the automated task grouping and architecture search implemented in the proposed AutoDP framework, showing how it improved prediction performance compared to manual methods or other automated approaches. Finally, the section must critically examine any limitations or potential biases inherent in the MIMIC-IV dataset or the experimental setup, providing context and nuances to the reported results. Presenting these findings clearly and concisely, with appropriate visualizations, is vital for establishing the paper’s contribution to the field.
Surrogate Modeling#
Surrogate modeling in this context appears to be a crucial technique for optimizing a complex, high-dimensional search space. The authors likely use a surrogate model, such as a neural network, to approximate the true objective function (MTL gain) because evaluating the true function directly is computationally expensive. This allows for efficient exploration of the vast space of possible task combinations and architectures for multi-task learning (MTL). The surrogate model, trained on a relatively small set of ground truth evaluations, enables the algorithm to rapidly assess the performance of different configurations, guiding the search process towards optimal or near-optimal solutions. The success of this approach hinges on the accuracy and efficiency of the surrogate model. The choice of architecture and training methodology for the surrogate are very important, impacting both the accuracy of predictions and the overall computational cost. A progressive sampling strategy is likely employed to iteratively refine the surrogate model, reducing the number of expensive ground truth evaluations needed.
Future Research#
The ‘Future Research’ section of this paper could explore several avenues. Extending AutoDP to handle diverse data modalities beyond EHRs (e.g., incorporating imaging, genomics, and claims data) would significantly enhance its real-world applicability. Addressing the dynamic nature of healthcare by adapting the model to new data and evolving tasks is crucial for practical deployment. Privacy concerns necessitate investigation into data processing pipelines for automated feature engineering to enhance patient data protection. The current framework’s limitation with heterogeneous datasets warrants further study. Addressing imbalanced datasets remains a challenge, so methods that mitigate this issue would improve model robustness. Finally, developing explainable AI techniques to understand AutoDP’s decision-making process would be essential for building trust and facilitating wider adoption in clinical settings.
More visual insights#
More on figures

🔼 This figure shows three histograms visualizing the distribution of per-task gains achieved by the AutoDP model across three different experimental settings: Task @ 5, Task @ 10, and Task @ 25. Each histogram represents a different number of tasks considered (5, 10, and 25, respectively), illustrating the range and frequency of performance improvements obtained for each individual task compared to single-task baselines. The x-axis represents the percentage gain in averaged precision, while the y-axis shows the frequency of tasks achieving a particular gain. The histograms illustrate the positive gains obtained across all tasks, highlighting the efficacy of the AutoDP framework in enhancing performance compared to single-task models.
read the caption
Figure 2: Histogram of task gains for AutoDP in terms of Averaged Precision.
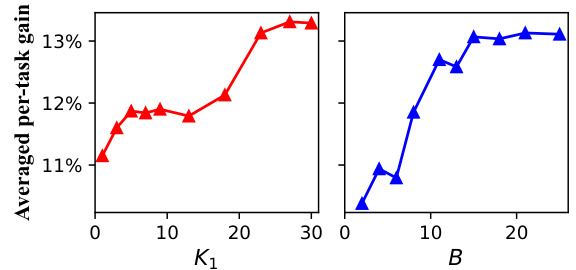
🔼 This figure analyzes the impact of two hyperparameters on the performance of the AutoDP model: K1, which represents the number of progressive sampling rounds during the surrogate model training, and B, which represents the budget of task groups in the greedy search. The left panel shows that increasing K1 leads to performance improvement, but the gains level off after around 25 rounds. The right panel shows that increasing B (budget for task groups) also yields improved performance that levels off after around 12 groups. This suggests that there are diminishing returns for further increases in either K1 or B, indicating good efficiency in the model’s hyperparameter tuning.
read the caption
Figure 3: Analysis for the number of progressive sampling rounds K1 and the budget of task groups B under the setting of Task @ 25.
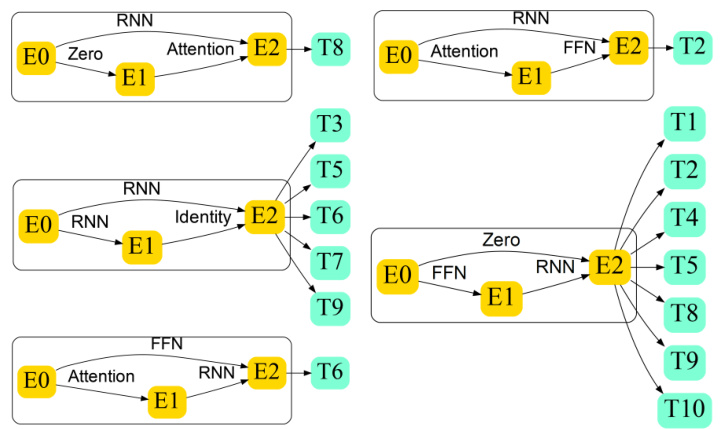
🔼 This figure provides a visual overview of the proposed AutoDP framework. It details the different stages of the framework, starting from data extraction and preprocessing to the final results. The framework consists of several key components: (1) Data Extraction: Extracting EHR time series data. (2) MTL Procedure: Implementing the multi-task learning procedure, including task combination (C) and architecture (A). (3) Progressive Sampling: Progressively sampling from the search space to train a surrogate model that estimates multi-task gains. (4) Surrogate Model: Building a neural network to estimate the MTL gains using the inputs of task combination (C) and architecture (A). (5) Greedy Search: A greedy search approach to efficiently find a near optimal solution for task grouping and architecture. The figure illustrates how the framework integrates these components to efficiently search for the optimal configuration of task grouping and architecture to maximize the multi-task performance gain.
read the caption
Figure 1: Overview of the proposed AutoDP
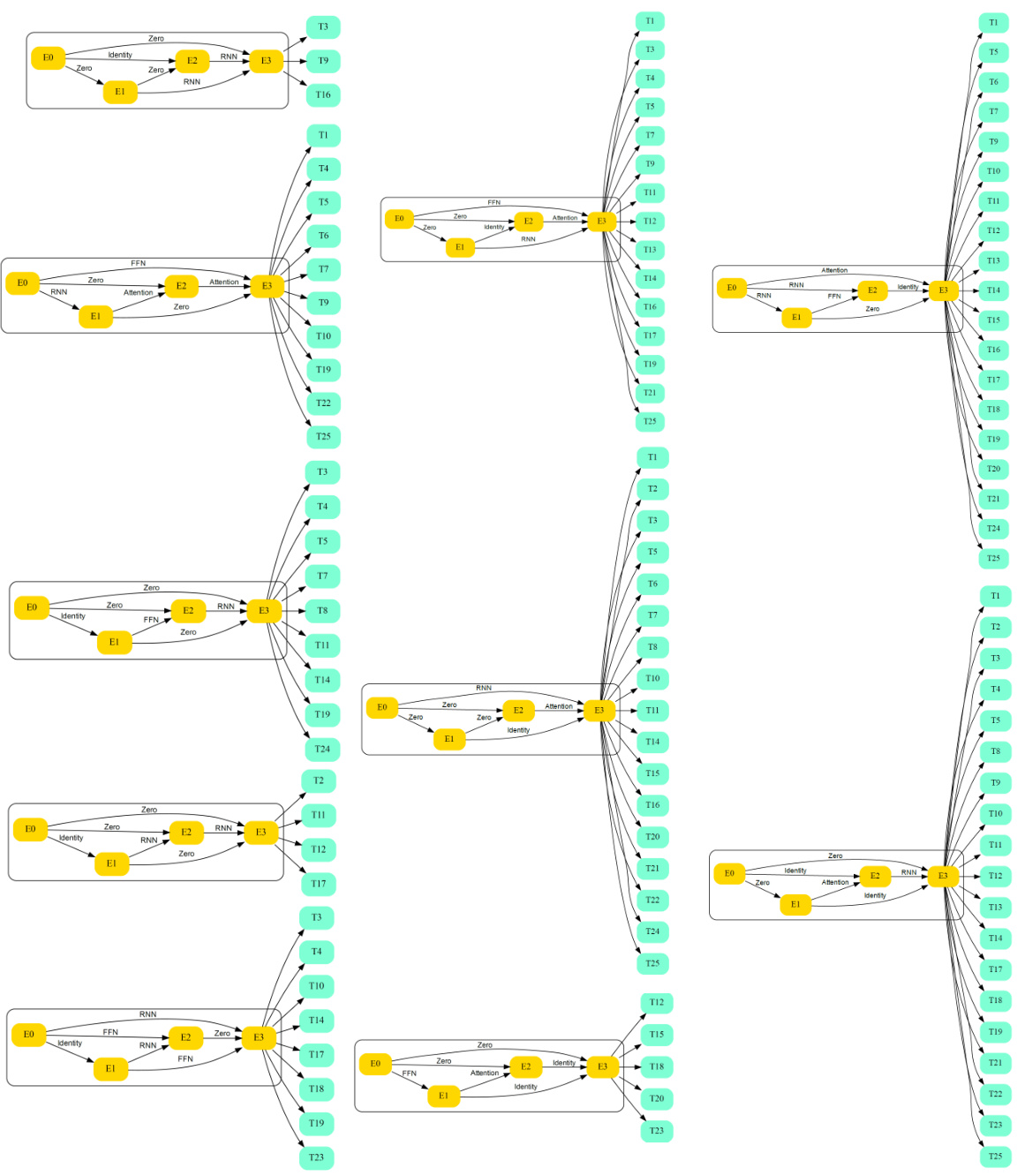
🔼 This figure provides a visual overview of the proposed AutoDP framework. It illustrates the various stages of the framework, including data extraction, multi-task learning procedures, progressive sampling, and greedy search. The flowchart highlights the interaction between these components in finding optimal task grouping and neural architectures. Specifically, it shows how intermediate results from each stage inform subsequent stages in an iterative process that culminates in the final results.
read the caption
Figure 1: Overview of the proposed AutoDP
More on tables
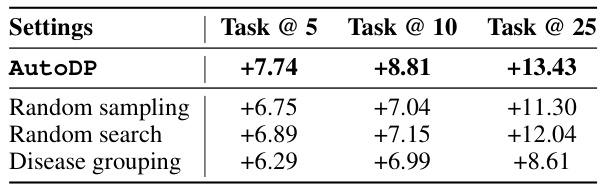
🔼 This table presents the ablation study results, showing the impact of removing key components from the AutoDP framework. It compares the averaged precision (AVP) performance of AutoDP against variations where progressive sampling, greedy search, or the automated task grouping are replaced with simpler alternatives. The results highlight the contribution of each component to the overall performance improvement.
read the caption
Table 2: Ablation results in terms of AVP.
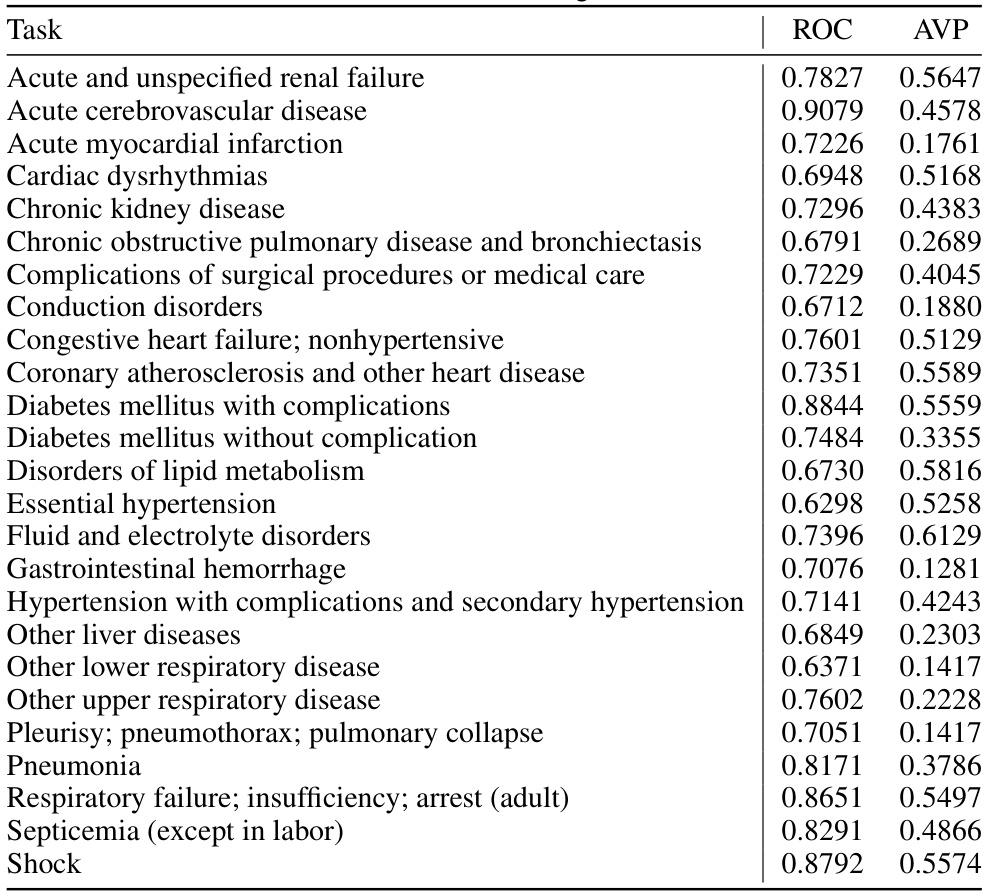
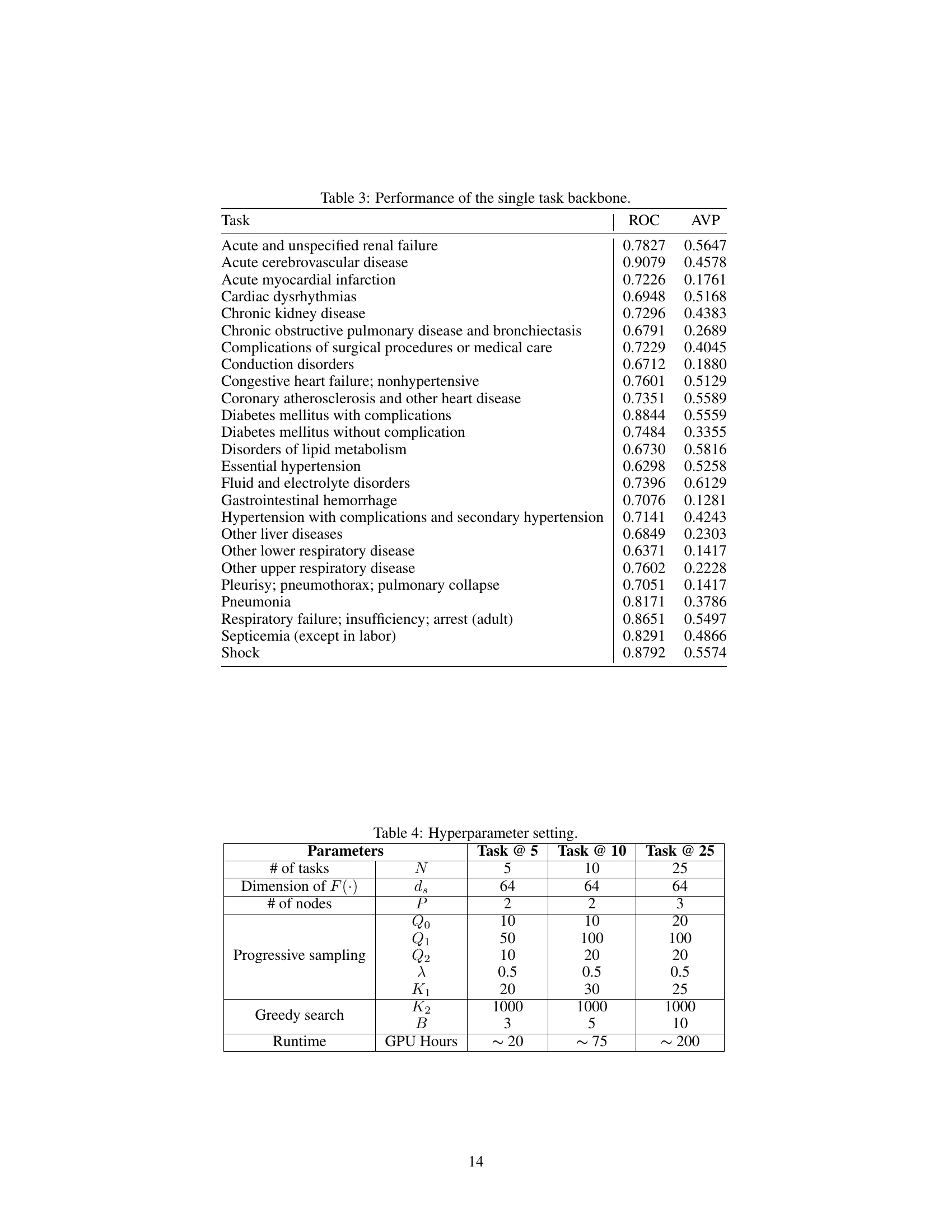
🔼 This table presents the performance of a single-task baseline model for each of the 25 prediction tasks. The metrics used to evaluate performance are the Area Under the Receiver Operating Characteristic curve (ROC) and the Averaged Precision (AVP). These metrics are commonly used in binary classification problems to assess the ability of a model to correctly identify positive cases among a set of samples. The results in this table show the baseline performance of a simple recurrent neural network (RNN) before any optimization techniques are applied. These results serve as a benchmark to compare against more advanced methods, like the automated multi-task learning framework proposed in the paper.
read the caption
Table 3: Performance of the single task backbone.
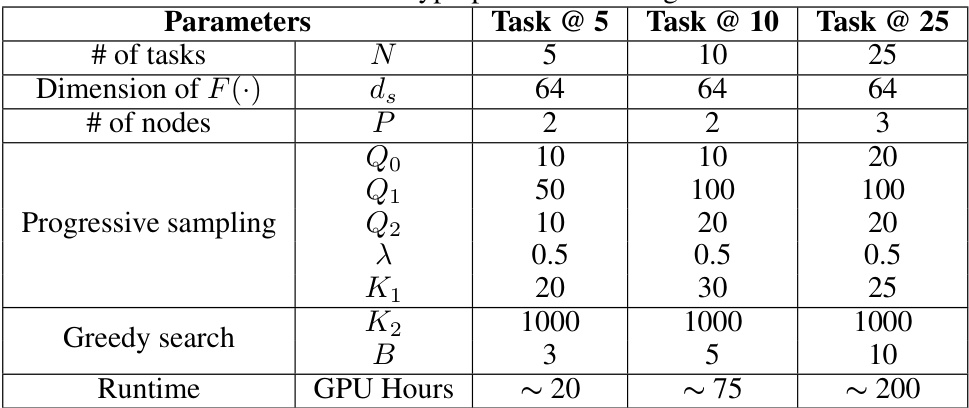
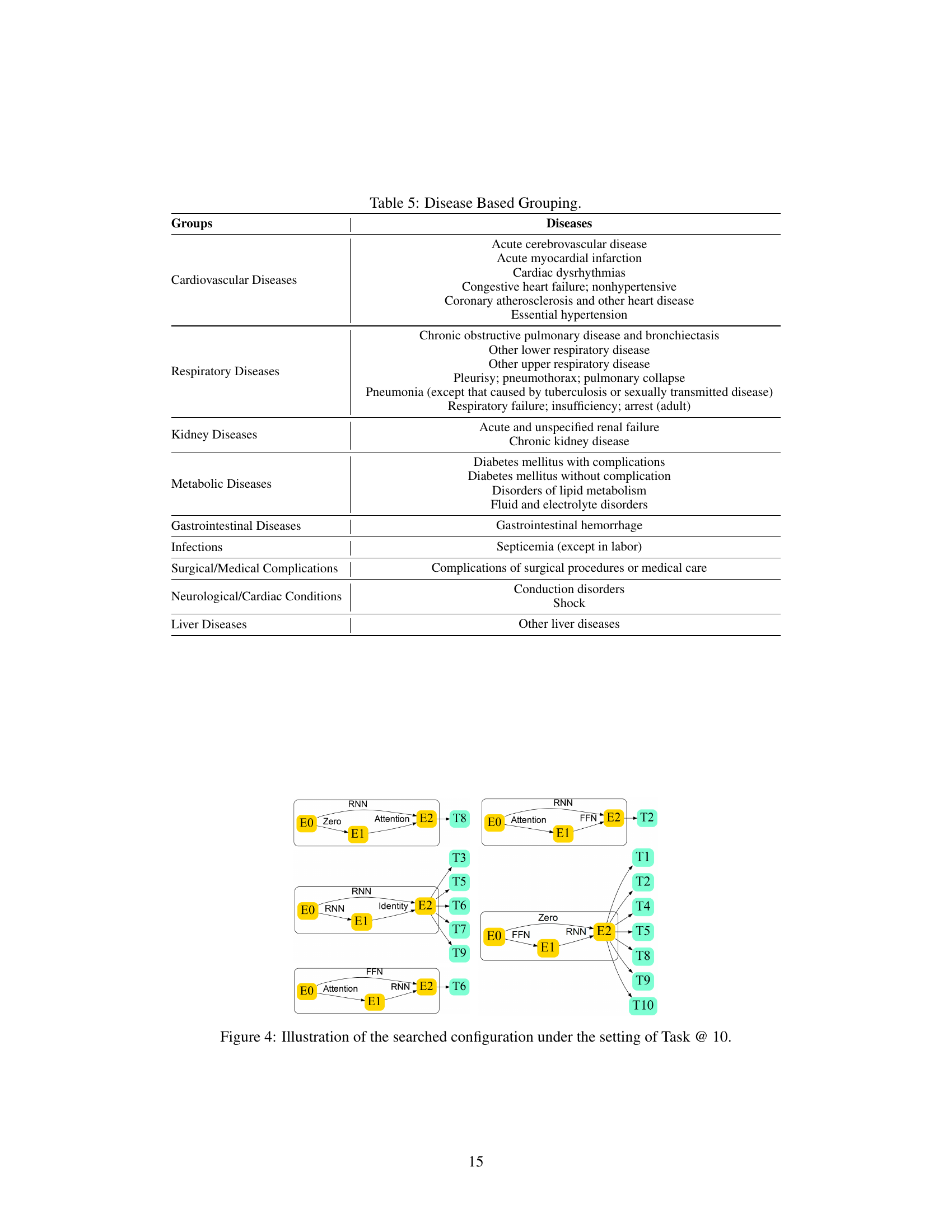
🔼 This table shows the hyperparameter settings used in the experiments for three different settings: Task @ 5, Task @ 10, and Task @ 25. The parameters include the number of tasks, the dimension of the feature vector in the surrogate model, the number of nodes in the DAG, parameters related to the progressive sampling strategy (number of initial samples, total number of samples selected during progressive sampling, number of top architectures selected, exploration-exploitation parameter, number of progressive sampling rounds), parameters related to the greedy search method (total iterations, budget for task combinations), and the approximate GPU hours required for each setting.
read the caption
Table 4: Hyperparameter setting.

🔼 This table shows how 25 prediction tasks are grouped based on medical knowledge using GPT-4. Each group contains related diseases. This grouping is used as a baseline to compare against the automated task grouping method developed in the paper.
read the caption
Table 5: Disease Based Grouping.
Full paper#