↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Estimating the 6D pose of articulated objects (position and orientation of each part) is challenging due to their complex structures and the problem of self-occlusion. Existing methods often struggle with computational cost and accuracy, especially at the category level (i.e., estimating pose for unseen objects within a category). This makes them unsuitable for real-time applications such as robotics.
This paper introduces EfficientCAPER, an end-to-end framework that addresses these limitations. EfficientCAPER uses a two-stage approach: first estimating the pose of the ‘free’ part (the main body), then using this information to canonicalize the input and estimate the pose of the remaining ‘constrained’ parts using joint states. The results demonstrate significant improvements in accuracy and efficiency compared to previous methods, with real-time performance on several datasets, including real-world scenarios. This work significantly advances category-level articulated pose estimation with a practical and effective method.
Key Takeaways#
Why does it matter?#
This paper is important because it presents EfficientCAPER, a novel end-to-end framework that significantly improves the speed and accuracy of category-level articulated object pose estimation. This is a crucial advancement, given the increasing demand for robust and efficient 6D pose estimation in various applications, particularly in robotics and augmented/virtual reality. The framework’s joint-centric approach, which leverages kinematic constraints and addresses self-occlusion issues, provides an efficient alternative to traditional methods, paving the way for further advancements in the field. The publicly available codebase will further accelerate research progress.
Visual Insights#

This figure illustrates the architecture of EfficientCAPER, which consists of two stages. Stage 1 estimates the pose of the free part of an articulated object using a HS-Encoder and decoupled rotation. Stage 2 canonicalizes the input point cloud and predicts per-part scale, segmentation, joint parameters, and joint states to recover the poses of the constrained parts. The figure shows the data flow through the network, highlighting the key components and their interactions.
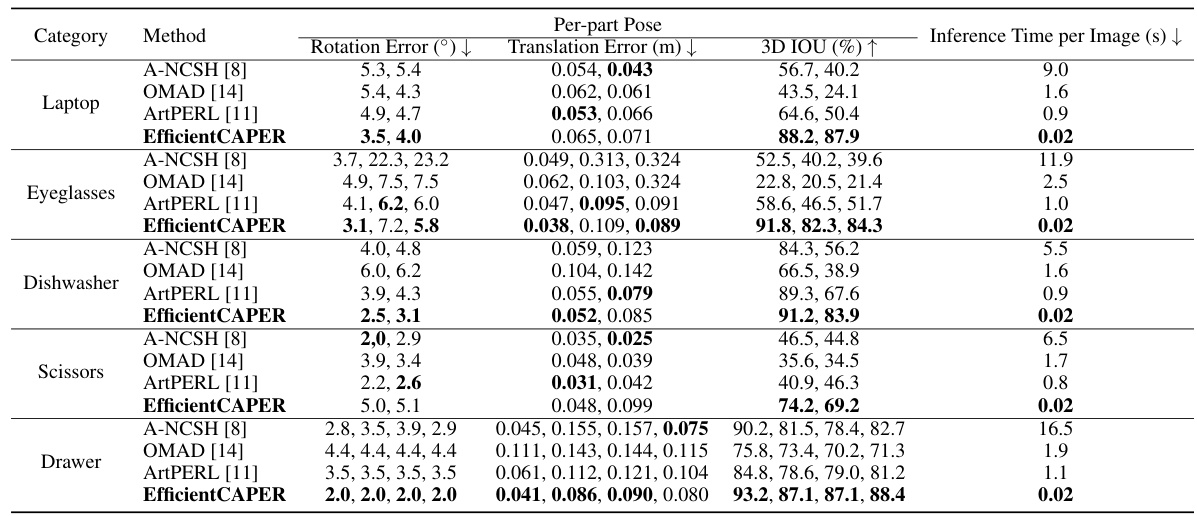
This table compares the performance of EfficientCAPER with three other methods (A-NCSH, OMAD, and ArtPERL) across five articulated object categories from the ArtImage dataset. The comparison is made using four metrics: rotation error, translation error, 3D IOU (Intersection over Union), and inference time per image. Lower rotation and translation errors, higher 3D IOU, and lower inference times indicate better performance. Each category contains a varying number of parts (2-4), reflecting the complexity of the articulated object.
In-depth insights#
Joint-centric Articulation#
The concept of “Joint-centric Articulation” in articulated object pose estimation offers a compelling alternative to traditional part-centric methods. Instead of independently estimating the pose of each rigid part, a joint-centric approach focuses on modeling the relationships between parts through their joints. This is advantageous because it explicitly incorporates kinematic constraints, leading to more physically plausible and accurate pose estimations, especially when dealing with self-occlusions or complex kinematic structures. The core idea is to represent the pose of each constrained part as a function of its corresponding joint state (angle or displacement) and joint parameters. This reduces the dimensionality of the problem and simplifies learning by enabling the network to focus on estimating joint parameters and states instead of each individual part’s 6D pose. The method is significantly more efficient and robust to noise or missing data as even partial observations of a single part can constrain the motion of others. The joint state representation is advantageous for cases of severe self-occlusion. Consequently, a joint-centric approach offers improved accuracy, efficiency, and generalization capacity over traditional techniques.
EfficientCAPER Pipeline#
The EfficientCAPER pipeline is a two-stage framework designed for fast and robust category-level articulated object pose estimation. Stage one focuses on estimating the pose of the free part of the object, using a decoupled rotation representation for efficiency and robustness to partial point cloud inputs. A hybrid feature extraction encoder processes the input to estimate translation and rotation. In stage two, the pipeline canonicalizes the input point cloud using the free part’s estimated pose, enhancing subsequent pose prediction of constrained parts. This stage leverages a joint-centric approach, predicting joint parameters and states directly, instead of relying on intermediate pose representations. This improves accuracy, especially when dealing with self-occlusions, and facilitates the use of kinematic constraints, making the overall framework highly efficient and generalizable to real-world scenarios.
Ablation Study Results#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a pose estimation model, this might involve removing parts of the network architecture (e.g., specific layers, modules), eliminating data augmentation techniques, or altering hyperparameters. Analyzing the results reveals the impact of each component on overall performance, such as accuracy, speed, and robustness to noise or occlusion. For example, removing a module designed for handling occlusions should lead to a decline in performance when dealing with occluded objects, highlighting its importance. Significant drops in performance after removing a component indicate its crucial role, while minimal changes might indicate redundancy. The results are crucial in understanding a model’s design choices and identifying potential areas for improvement or simplification.
Real-world Generalization#
Real-world generalization in the context of articulated object pose estimation is a crucial yet challenging aspect. A model’s ability to accurately estimate poses in uncontrolled, real-world environments, differing significantly from the controlled settings of synthetic datasets, is a key measure of its practical value. Robustness to factors like variations in lighting, occlusions, and background clutter is paramount. Success hinges on the model’s ability to extract relevant features that are invariant to these variations, while simultaneously handling the complex kinematic relationships inherent in articulated objects. The degree of generalization is usually evaluated through experiments on datasets containing real-world images or point clouds. Quantitative metrics like pose estimation accuracy (translation and rotation errors), and qualitative assessments, which assess visual correctness of estimated pose relative to ground truth data, are used to gauge success. Addressing limitations arising from domain shift between training and testing data is essential; techniques like domain adaptation or data augmentation strategies are often employed to improve performance in real-world settings. Ultimately, the goal is to achieve a system that is deployable in real-world applications, operating reliably and accurately in diverse and unpredictable scenarios.
Future Research#
Future research directions stemming from this work could explore several key areas. Extending the framework to handle more complex articulated objects with a greater number of parts and diverse kinematic structures is crucial. This would necessitate developing more sophisticated joint-centric representations and potentially incorporating more advanced techniques from robotics for modeling and inferring complex joint relationships. Addressing the impact of dynamic articulated objects is another key direction. The current framework focuses solely on static poses. Developing techniques capable of estimating poses in dynamic scenes would significantly broaden its applications, requiring the integration of temporal information and possibly techniques from video processing. Improving the robustness and efficiency of the algorithm remains an important ongoing challenge. Exploration of more efficient neural network architectures and optimization strategies could enhance processing speed and accuracy, especially for complex, real-world scenes. Lastly, investigating the algorithm’s performance with noise and occlusion requires further study. More extensive evaluations on larger, more varied datasets would further validate the generalizability and robustness of the proposed method.
More visual insights#
More on figures

This figure illustrates the two types of parts found in articulated objects: free parts and constrained parts. Free parts can move freely in three-dimensional space, unconstrained by joints. Constrained parts, on the other hand, can only move along specific axes defined by their corresponding joints (revolute or prismatic). The image visually shows a free part (a cube), a revolute joint (connecting a smaller cube to the larger cube), and a prismatic joint (sliding along a track). This distinction is key to the EfficientCAPER method, which models these parts separately to improve accuracy and efficiency in pose estimation.

This figure shows the architecture of the EfficientCAPER model, an end-to-end framework for category-level articulated object pose estimation. It consists of two stages. Stage 1 estimates the pose of the free part of the object using a HS-Encoder and decoupled rotation. Stage 2 canonicalizes the input point cloud and predicts per-part scale, segmentation, joint parameters, and joint states to recover the poses of the constrained parts. The figure visually depicts the flow of data through the network, highlighting key components and their interactions.
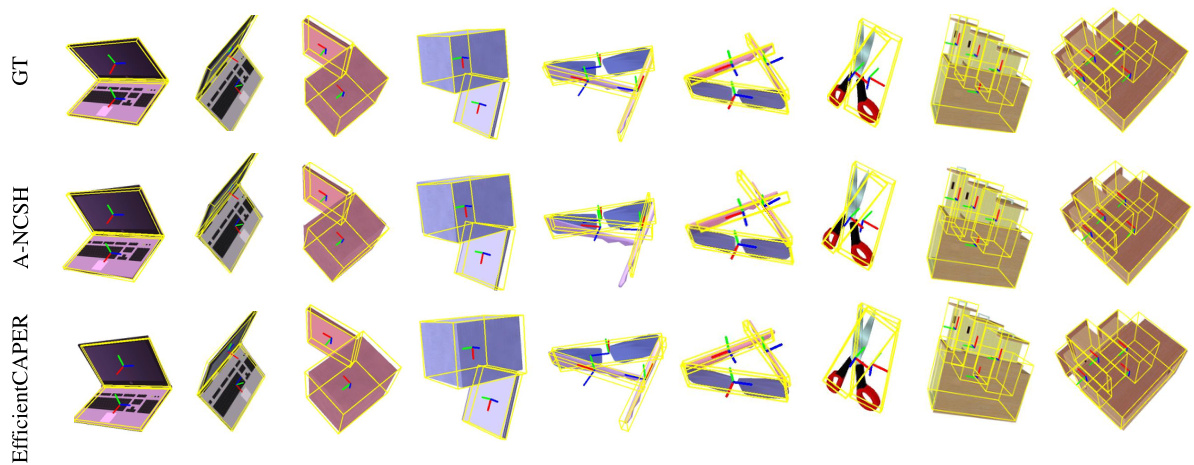
This figure shows qualitative results of the proposed EfficientCAPER method and compares it with the A-NCSH method on three different datasets: ArtImage, ReArtMix, and RobotArm. The top row displays results from the ArtImage dataset, which contains synthetic articulated objects. The bottom-left shows results from the semi-synthetic ReArtMix dataset, and the bottom-right shows results from the real-world RobotArm dataset. Each image displays the estimated 3D bounding box (yellow) for each part of the object and the ground truth bounding box (in other colors) for each corresponding part. The figure demonstrates the effectiveness of EfficientCAPER in accurately estimating the pose and 3D scale of various articulated objects across different scenarios, including synthetic and real-world environments, which showcases its generalization ability.

This figure shows qualitative results of the proposed EfficientCAPER method on three datasets: ArtImage, ReArtMix, and RobotArm. The top row displays results on ArtImage, showing successful pose estimation for various articulated objects in different configurations. The bottom left shows results on ReArtMix, a more challenging semi-synthetic dataset. The bottom right shows results on RobotArm, a real-world dataset with complex scenes and diverse object arrangements. The visualizations likely compare estimated poses (likely shown as 3D bounding boxes) with ground truth poses to illustrate the accuracy of the EfficientCAPER method.

This figure shows qualitative results of the proposed EfficientCAPER method on the RobotArm dataset. It displays multiple images of a robot arm in various poses, each with the estimated pose overlaid. The overlaid pose is shown via bounding boxes around the robot arm segments, and the results illustrate the accuracy of pose estimation for articulated objects. The different colors likely indicate different parts of the robot arm.
More on tables
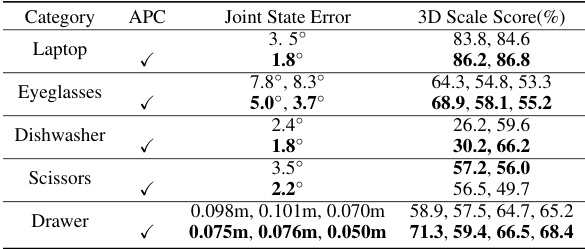
This table presents the ablation study result of the articulation pose canonicalization module on the ArtImage dataset. It shows the improvement in joint state error and 3D scale score (represented as 3D IoU) when using the canonicalization module compared to without using it. The results are shown for each object category (Laptop, Eyeglasses, Dishwasher, Scissors, Drawer). The inclusion of canonicalization leads to a significant reduction in joint state error and an improvement in 3D scale prediction accuracy.

This table presents the results of evaluating the EfficientCAPER model’s performance on the ‘Drawer’ category of the ArtImage dataset under varying levels of occlusion. It shows the mean rotation error (in degrees) and mean translation error (in meters) for three occlusion levels: 0%-40%, 40%-80%, and 80%-100%. The occlusion level is defined as the percentage of visible points compared to the total number of points in the part.
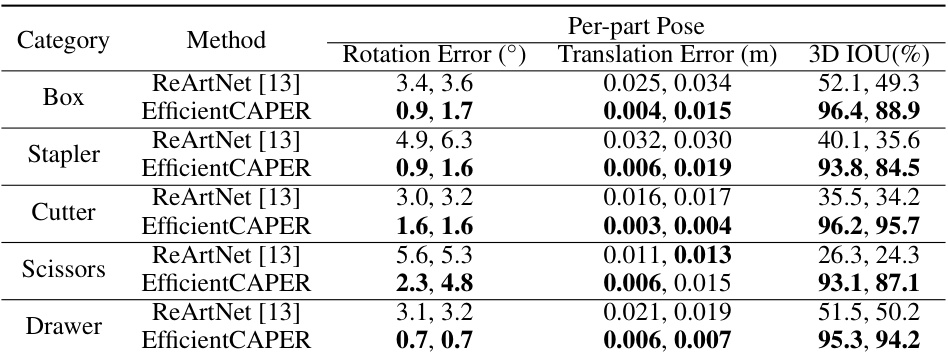
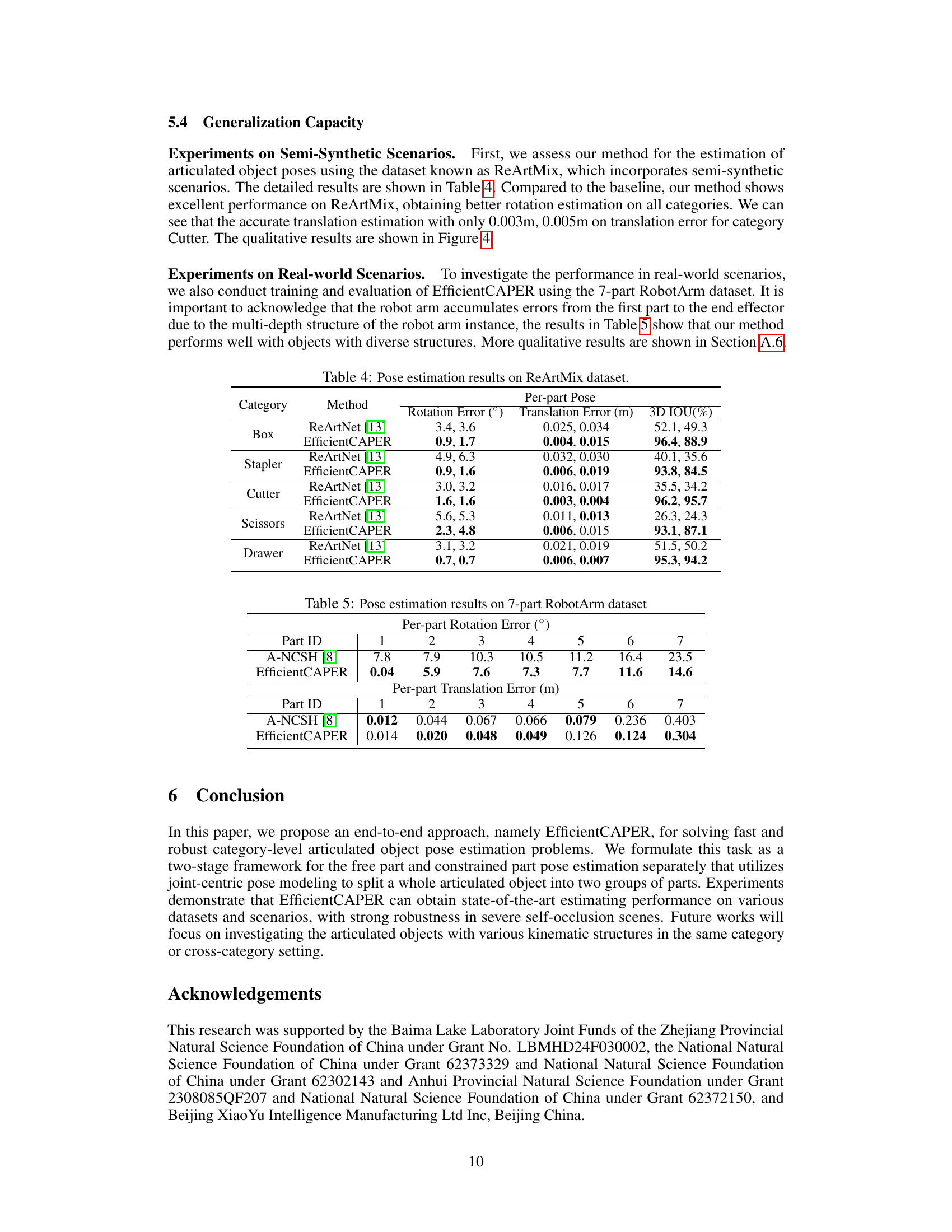
This table compares the performance of EfficientCAPER against ReArtNet [13] on the ReArtMix dataset. For each of five articulated object categories (Box, Stapler, Cutter, Scissors, Drawer), it shows the per-part rotation error (in degrees), translation error (in meters), and 3D Intersection over Union (IOU) scores. The results demonstrate EfficientCAPER’s significant improvement in accuracy across all metrics and categories compared to the baseline method.
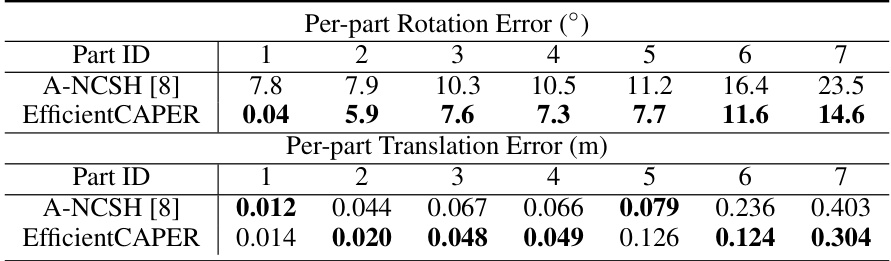
This table compares the performance of the proposed EfficientCAPER method and the A-NCSH baseline method on the 7-part RobotArm dataset. It presents the per-part rotation and translation errors for each of the seven parts of the robot arm. Lower values indicate better performance.
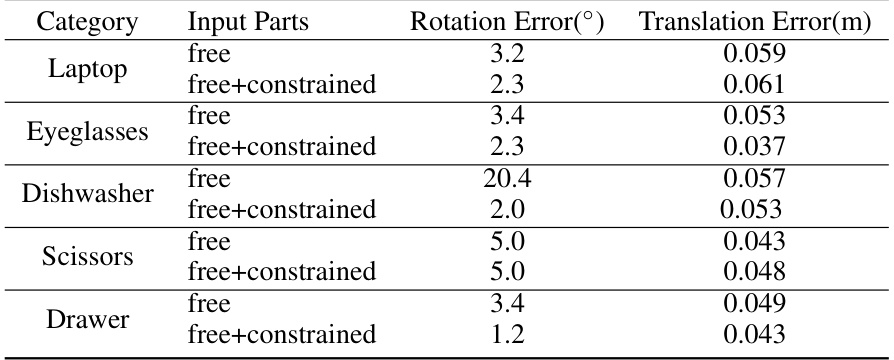
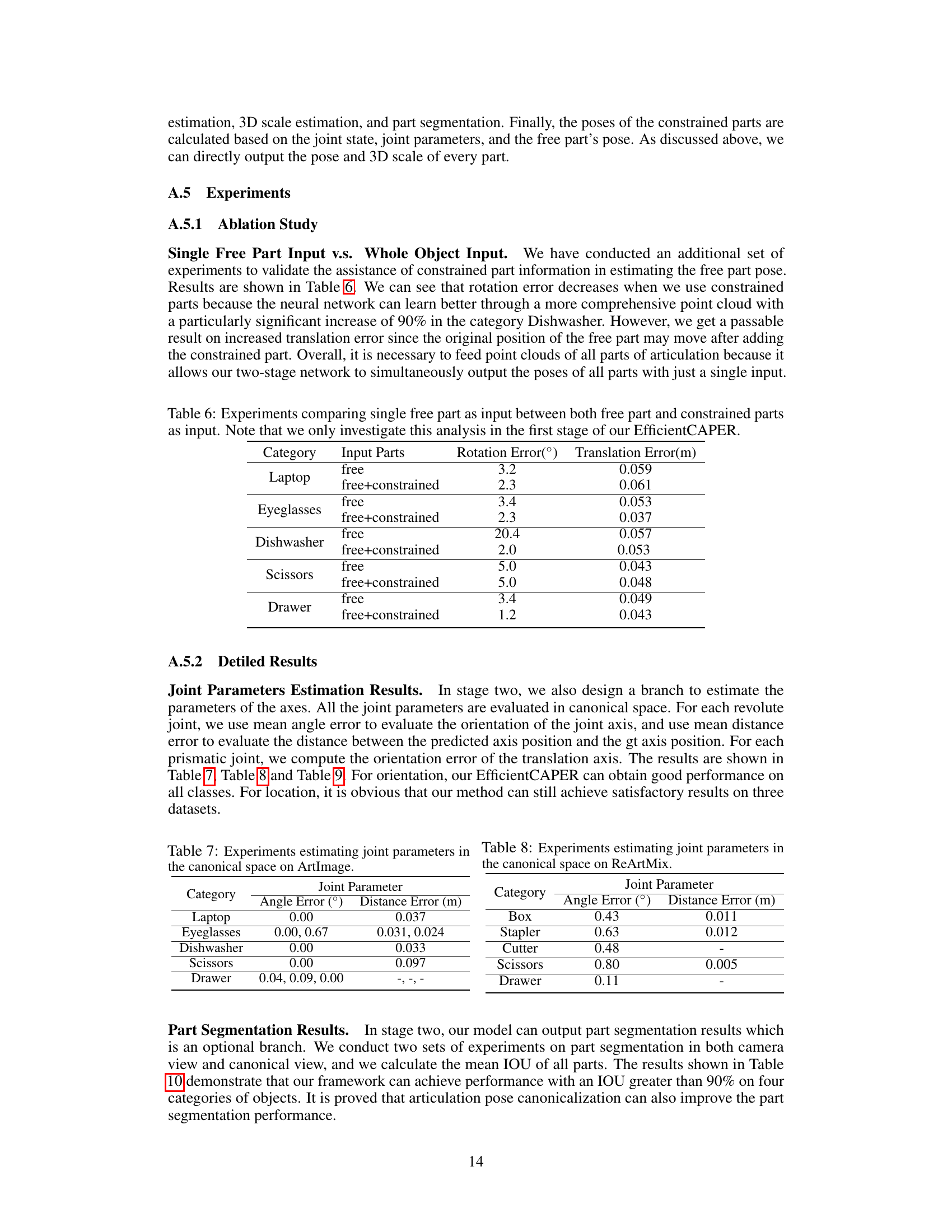
This table presents ablation study results comparing the performance of the EfficientCAPER model when using only the free part’s point cloud versus using the combined point cloud of the free part and constrained parts as input for the first stage of pose estimation. The goal is to show the effect of incorporating additional contextual information from constrained parts on the accuracy of free part pose estimation. The results are presented separately for rotation error (in degrees) and translation error (in meters) for five different object categories: Laptop, Eyeglasses, Dishwasher, Scissors, and Drawer.

This table presents the results of experiments evaluating the accuracy of the model in estimating joint parameters in the canonical space for the ArtImage dataset. It shows the angle error (in degrees) and distance error (in meters) for revolute joints and the orientation error for prismatic joints for different object categories.

This table presents the results of estimating joint parameters in the canonical space for the ReArtMix dataset. It shows the angle error (in degrees) and distance error (in meters) for each category of articulated object. Note that the Cutter and Drawer categories only have one type of joint, so the distance error is not applicable.

This table presents the results of estimating joint parameters in the canonical space for a 7-part RobotArm dataset. It shows the angle error (in degrees) and distance error (in meters) for each of the six joints (Joint ID 1 through 6). These metrics evaluate the accuracy of the model’s predictions for the orientation and position of the joint axes.
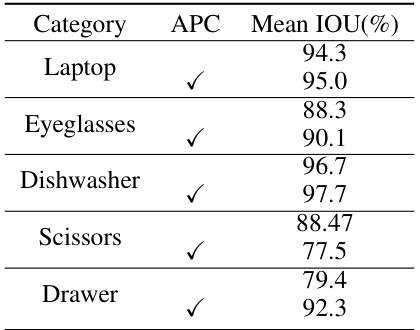
This table presents the results of part segmentation experiments, comparing performance with and without articulation pose canonicalization (APC). The mean Intersection over Union (IOU) is shown for each category (Laptop, Eyeglasses, Dishwasher, Scissors, Drawer) to demonstrate the impact of APC on segmentation accuracy. Higher IOU values indicate better segmentation.
Full paper#