↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The increasing prevalence of high-quality AI-generated images poses a significant challenge to machine learning research, particularly for online continual learning (CL). CL models are susceptible to performance degradation when trained on datasets contaminated with synthetic images because of issues such as lower entropy in synthetic data, and misalignment in the feature embedding space between synthetic and real data. These issues weren’t thoroughly understood until now, creating reliability problems for online CL research.
This paper investigates the negative impact of synthetic data on existing online CL algorithms, providing four key observations about the characteristics of synthetic data in continual learning scenarios. The authors then introduce a novel method called ESRM (Entropy Selection with Real-synthetic similarity Maximization) that effectively addresses the performance deterioration caused by synthetic data contamination. ESRM uses two key components: entropy selection and real-synthetic similarity maximization. Experiments show that ESRM significantly alleviates the negative effects of synthetic data, particularly when the level of contamination is high.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the growing concern of synthetic data contamination in online continual learning (CL). It reveals how synthetic images degrade CL model performance and proposes a novel method (ESRM) to mitigate this issue. This is highly relevant to researchers collecting datasets online, offering insights and solutions for improving the robustness and reliability of CL systems in real-world scenarios. The method itself, ESRM, introduces a novel approach to enhance the quality of data used for training.
Visual Insights#
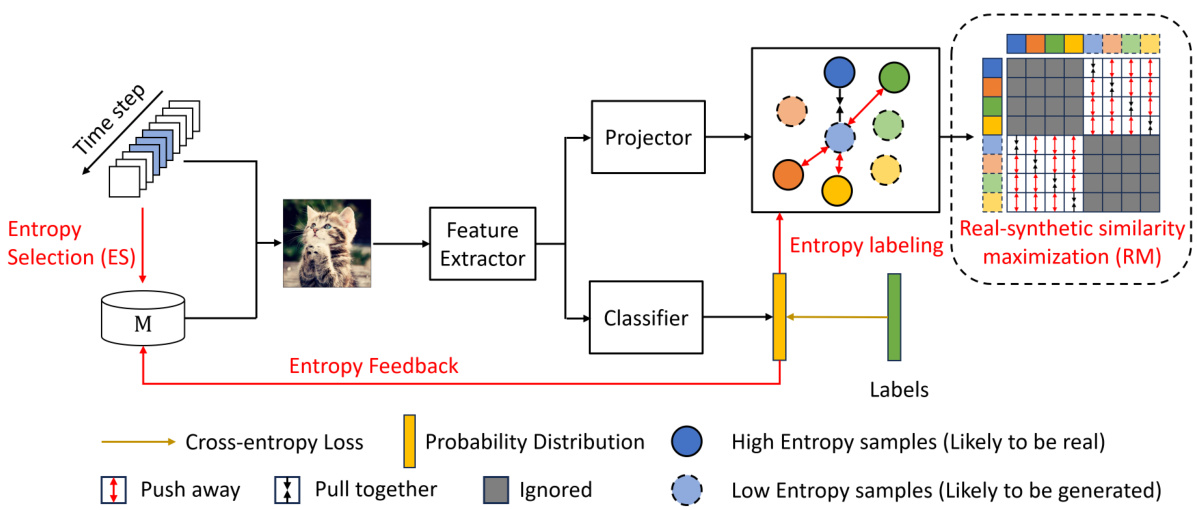
The figure illustrates the ESRM framework, which consists of two main components: Entropy Selection (ES) and Real-synthetic similarity Maximization (RM). ES is used to select high-quality real samples from the memory buffer based on the entropy, improving the performance of the model by reducing catastrophic forgetting. RM bridges the gap between real and synthetic data embeddings using contrastive learning, enhancing the performance of online continual learning. The framework uses entropy as a selection criterion, maximizing the mutual information between current and past representations.

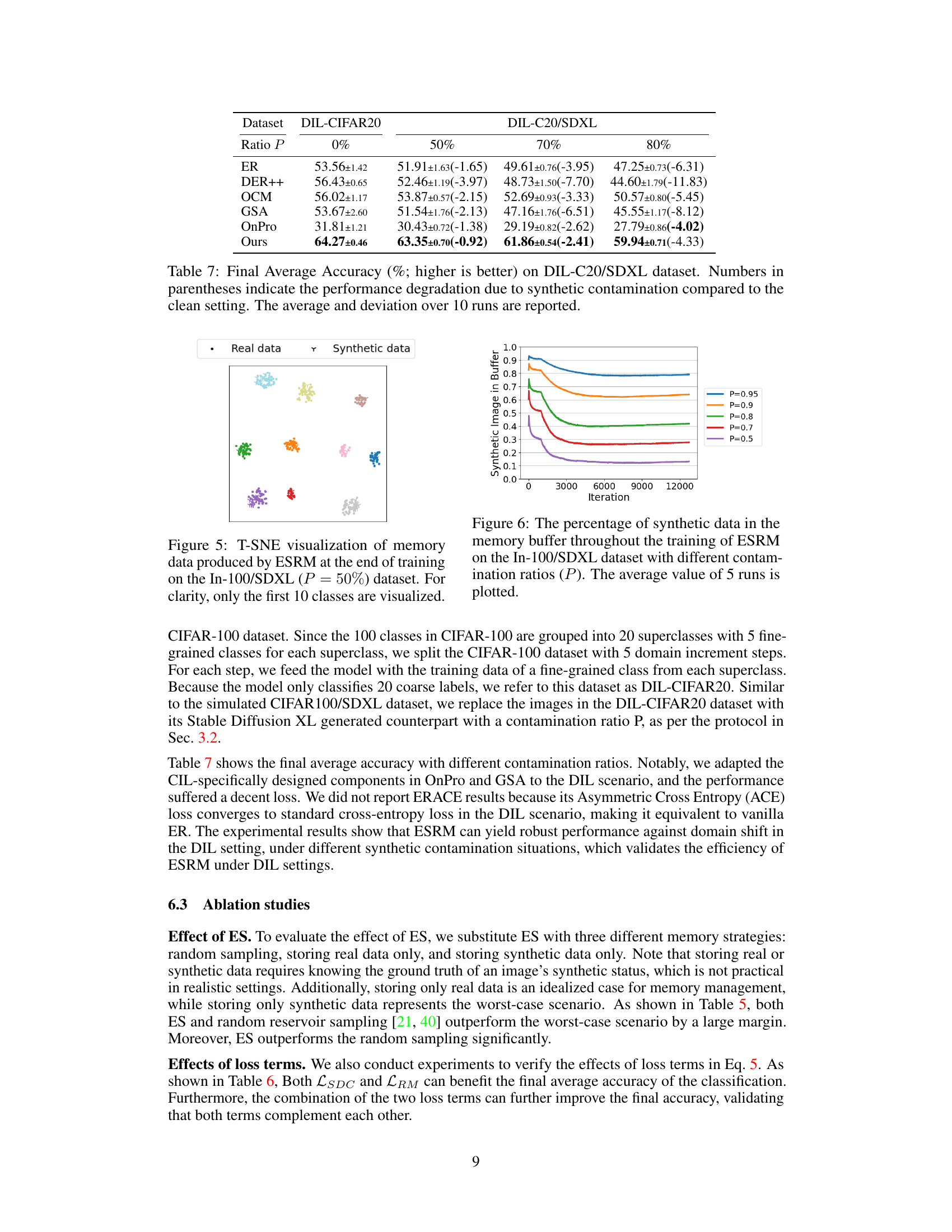
This table presents the performance of the Experience Replay (ER) method on the C100/SDXL dataset under different contamination ratios (P=70% and P=80%). It compares three memory strategies within ER: storing only real data, random sampling, and storing only synthetic data. The accuracy (Acc. ↑) is reported for each strategy and contamination level, demonstrating the impact of synthetic data contamination on the replay buffer and the overall model performance.
In-depth insights#
Synthetic Data Impact#
The impact of synthetic data on machine learning models, especially in online continual learning scenarios, is a significant concern. Synthetic data contamination can hinder the performance of existing online continual learning methods, leading to degraded accuracy and increased forgetting. This is because synthetic data often exhibits properties different from real-world data, such as lower entropy and different feature representations. The paper highlights the importance of addressing this issue and proposes a novel method, ESRM, to mitigate these negative effects. ESRM successfully reduces performance degradation by selecting more realistic samples and aligning feature embeddings between synthetic and real data. The research underscores the need for careful consideration of data quality in continual learning and for the development of robust techniques to handle synthetic data contamination. The findings have broad implications for future research, highlighting the potential threat of AI-generated image contamination to the integrity of online datasets and the performance of machine learning models trained on them. Future work should explore further methods for detecting synthetic data and develop more sophisticated techniques for handling its impact on continual learning. This includes investigating the effect of various types of synthetic data generation and exploring alternative strategies for mitigating the effects of contamination.
ESRM Framework#
The ESRM framework, designed to mitigate the negative effects of synthetic data contamination in online continual learning, cleverly combines two key components: Entropy Selection (ES) and Real-synthetic Similarity Maximization (RM). ES strategically manages the memory buffer by prioritizing real data samples based on their entropy, thus effectively reducing the impact of low-entropy synthetic images that often hinder learning. RM, utilizing a contrastive learning approach, addresses the embedding space misalignment between real and synthetic data, a critical issue identified in the paper as a source of performance degradation. By bridging this gap, RM ensures that the model learns more effectively from the entire dataset, synthetic and real. This combined strategy shows promise in improving the overall robustness and accuracy of online continual learning models against the increasing prevalence of synthetic data, highlighting the importance of understanding and mitigating the risks of contamination.
Online CL Effects#
The section ‘Online CL Effects’ would delve into how synthetic data contamination impacts online continual learning (CL) algorithms. It would likely show that existing online CL methods struggle when trained on datasets containing AI-generated images, experiencing performance degradation. The analysis would likely demonstrate this through empirical results across various online CL algorithms, highlighting specific vulnerabilities of these methods to this new form of data contamination. Key observations about how synthetic data differs from real data in terms of entropy and embedding space would likely be presented as evidence, explaining the performance issues. The study would also explore how the characteristics of synthetic data specifically impact the memory mechanisms used in many online CL techniques, leading to catastrophic forgetting or other accuracy problems. Overall, this section would establish a strong foundation for the need to address synthetic data contamination as a critical challenge in online CL research.
Synthetic Data Traits#
Synthetic data, while offering advantages like cost-effectiveness and control over data generation, presents unique challenges in machine learning. A crucial aspect is understanding the inherent traits of synthetic data, often differing from real-world data. Lower entropy is a common characteristic, implying less diversity and potentially easier classification compared to real data. This can manifest as better clustering in embedding space, leading to suboptimal model generalization. Another key trait is the potential misalignment in feature representations between synthetic and real data, hindering effective knowledge transfer and exacerbating catastrophic forgetting in continual learning scenarios. Bias amplification is also a concern, where synthetic data might inadvertently exacerbate pre-existing biases, impacting fairness and model robustness. Therefore, robust continual learning methods should account for these traits by incorporating strategies like entropy-based filtering, and focusing on creating more generalizable feature representations that bridge the gap between synthetic and real data.
Future Research#
Future research directions stemming from this work could explore several key areas. Extending the ESRM method to other online continual learning settings beyond CIL is crucial, such as task-incremental learning (TIL) or domain-incremental learning (DIL). Investigating the impact of diverse synthetic data generation methods (beyond the five used here) and varying levels of contamination is warranted, as is exploring how ESRM performs with different model architectures and memory buffer sizes. A critical area for future work is the development of robust synthetic data detection methods specifically tailored to online learning scenarios. Current detection methods may not be suitable for the streaming nature of data in online CL and may fail to distinguish between subtle differences between real and synthetic images under online continual learning settings. The study also suggests that a deeper understanding of the inherent characteristics of synthetic data, specifically in continual learning contexts, is needed. Further investigation into how these characteristics influence model bias and catastrophic forgetting can lead to new approaches for mitigating performance degradation. Finally, exploring the possibility of using synthetic data augmentation techniques, carefully chosen to avoid ESRM’s issues, could yield substantial improvements in online continual learning performance and robustness.
More visual insights#
More on figures
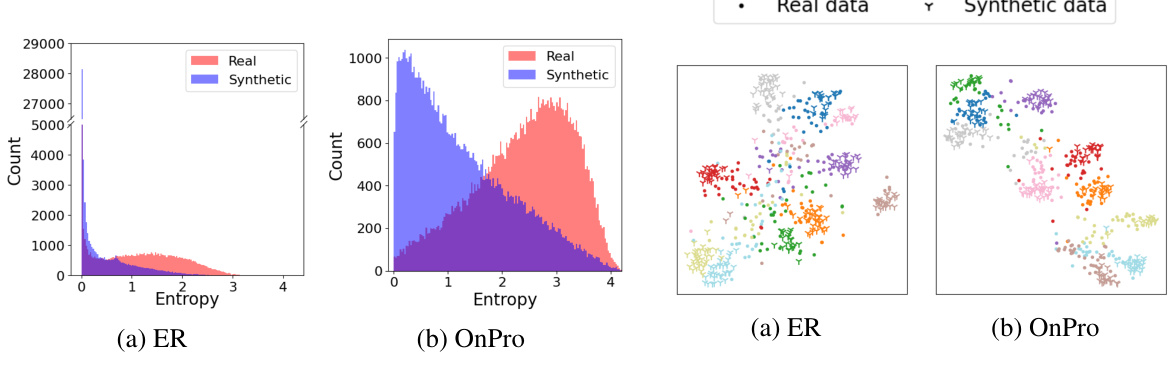
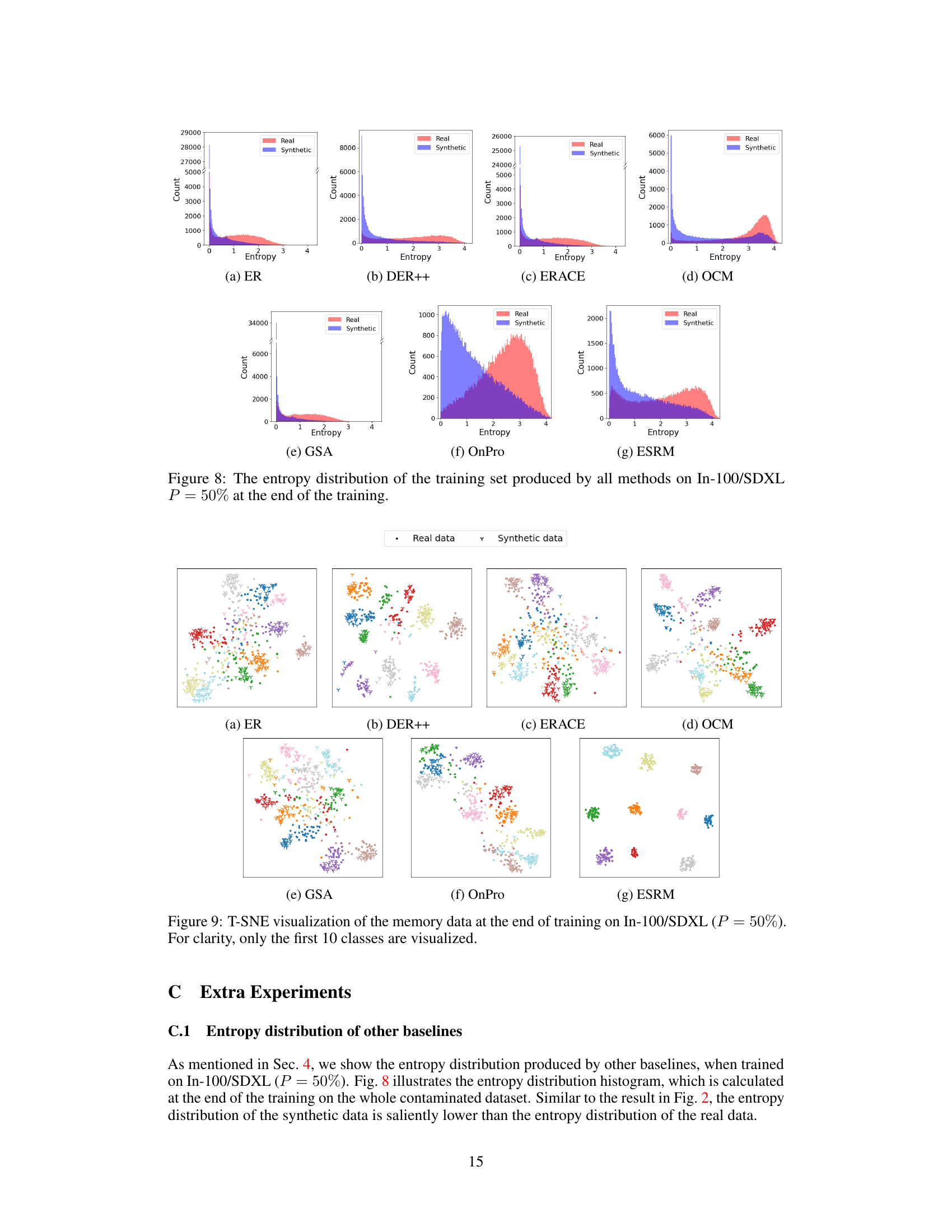
This figure displays the entropy distributions of training data generated by two online continual learning methods, ER and OnPro, when trained on a dataset (In-100/SDXL) with 50% synthetic data contamination. The histograms show a clear difference in entropy between real and synthetic data, with synthetic data exhibiting much lower entropy values. This observation is key to the proposed ESRM method, which uses entropy as a criterion for selecting more realistic samples.

This figure illustrates the steps involved in the Entropy Selection (ES) strategy used in the ESRM framework. ES manages the memory buffer by preferentially keeping samples with higher entropy (more likely to be real data). The four steps are: 1. Drop low entropy samples: Low-entropy samples (likely synthetic) from the incoming batch are dropped. 2. Random sampling: A random selection of high-entropy samples is made from the incoming batch to potentially fill the buffer. 3. Same class with lowest entropy: If a sample is selected, a sample from the same class as the newly selected sample with the lowest entropy from the buffer is identified to be replaced. 4. Replace: The selected low-entropy sample is replaced by a high-entropy sample from the current batch. This process ensures that the memory buffer maintains a balance between real and synthetic samples, prioritizing real data to improve the performance of the online continual learning model.
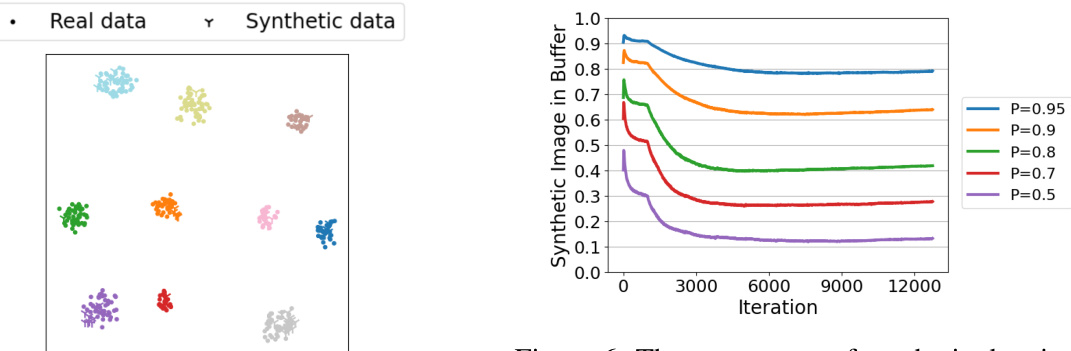
This figure shows how the proportion of synthetic images in the memory buffer of the ESRM model changes over the course of training. Different lines represent different levels of synthetic data contamination in the training dataset (indicated by the ratio P). As training progresses, the percentage of synthetic images in the buffer decreases, regardless of the initial contamination level. This demonstrates the effectiveness of the Entropy Selection (ES) component of the ESRM method in filtering out less useful synthetic samples.

This ROC curve shows the performance of ESRM in distinguishing real images from synthetic ones in the training dataset. The model uses the entropy of the predicted probability distribution to classify whether an image is real or synthetic. An AUC of 0.7098 indicates a moderate level of discrimination ability. The dotted line represents a random classifier, where the model has no ability to distinguish between real and synthetic images.

This figure shows the entropy distribution of training data for different online continual learning methods at the end of training on a dataset (In-100/SDXL) with 50% synthetic data contamination. Each subplot represents a different method (ER, DER++, ERACE, OCM, GSA, OnPro, and ESRM). For each method, two histograms are shown: one for real data and one for synthetic data. The x-axis represents entropy, and the y-axis represents the count of data samples with that entropy. The figure illustrates that the synthetic data generally has lower entropy than real data across all methods. This observation is central to the paper’s proposed method, ESRM, which uses entropy as a criterion to select more realistic samples during training.

This figure uses t-SNE to visualize the feature embeddings of the memory data from the In-100/SDXL dataset after training with 50% synthetic data contamination. It shows how the embeddings of real and synthetic data are clustered, highlighting a potential issue of misalignment that affects model performance. Only the first 10 classes are shown for clarity.

This figure shows a comparison of images of robins from two datasets: SDXL-In100 (synthetic data generated by Stable Diffusion XL) and the original ImageNet-100. The top row displays images from the synthetic dataset, while the bottom row shows images from the original dataset. The figure highlights the differences in image quality, diversity, and background complexity between the two datasets. The synthetic images exhibit a more consistent style, while the original images have a wider range of styles and backgrounds, suggesting a potential impact of synthetic data contamination on the quality of datasets used to train machine learning models.
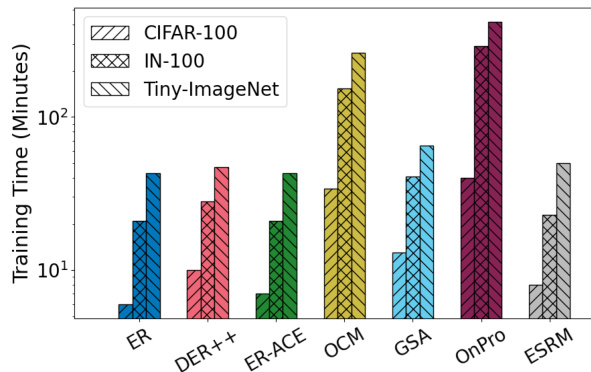
This figure shows the average training time of different online continual learning methods on three datasets: CIFAR-100, ImageNet-100, and TinyImageNet. The training times are plotted on a logarithmic scale for better readability, and the values are averages across 10 runs. The methods compared are ER, DER++, ER-ACE, OCM, GSA, OnPro, and ESRM, showcasing the computational efficiency differences between these approaches.

This figure shows the proposed ESRM framework which consists of two main components: Entropy Selection (ES) and Real-synthetic similarity Maximization (RM). ES is a buffer management strategy that uses entropy to select more real samples to reduce catastrophic forgetting caused by synthetic data contamination. RM uses contrastive learning to bridge the embedding gap between real and synthetic data. The diagram illustrates the data flow within ESRM, showing how entropy selection and real-synthetic similarity maximization are used to improve the performance of online continual learning models.
More on tables
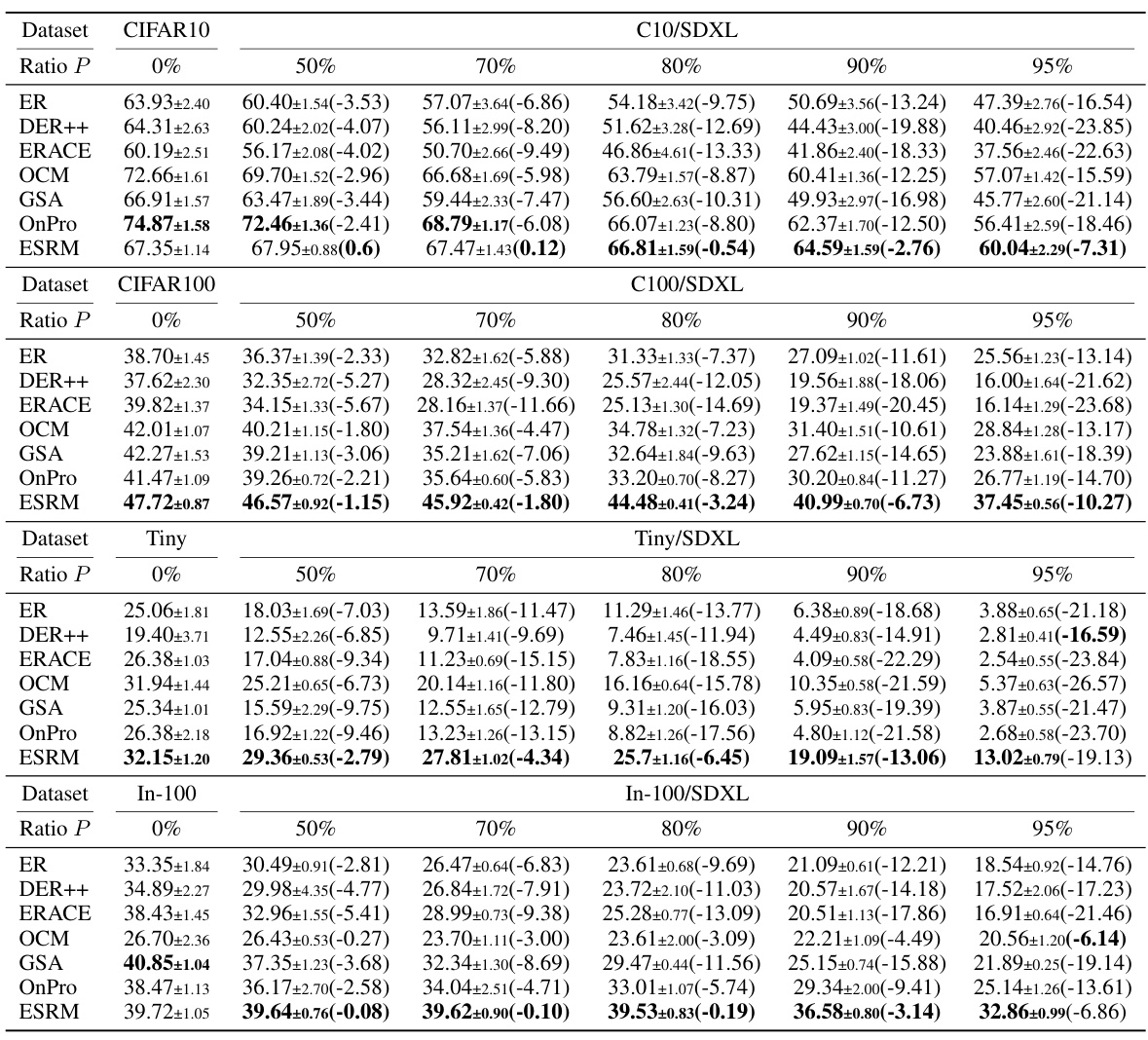
This table presents the average accuracy of six online continual learning methods (ER, DER++, ERACE, OCM, GSA, OnPro, and ESRM) across four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) under varying levels of synthetic data contamination. The accuracy is shown for different contamination ratios (0%, 50%, 70%, 80%, 90%, and 95%). The numbers in parentheses indicate the performance drop compared to the uncontaminated dataset. It demonstrates how synthetic data contamination impacts the performance of existing online continual learning methods, highlighting the effectiveness of the proposed ESRM method in mitigating the negative effects of contamination.
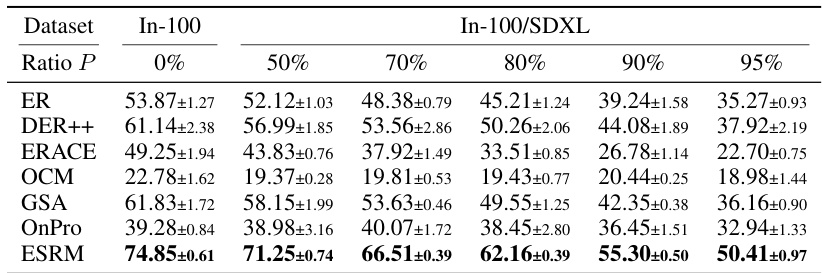
This table presents the average accuracy of six online continual learning methods (ER, DER++, ERACE, OCM, GSA, OnPro, and ESRM) across four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) under varying levels of synthetic data contamination. The results are shown for different contamination ratios (P), ranging from 0% to 95%, allowing for an analysis of how well each method resists the negative effects of synthetic data contamination on continual learning performance. Parenthetical values indicate the performance drop compared to the clean (0% contamination) scenario for each method.
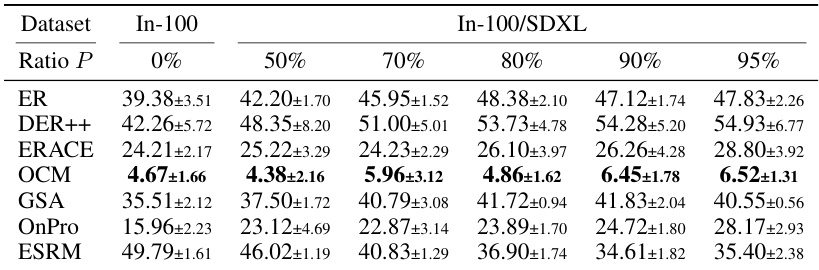
This table presents the average accuracy of six online continual learning methods on four datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) with varying levels of synthetic data contamination. The results show the impact of synthetic data contamination on model performance and demonstrate that the proposed ESRM method is more robust to this type of contamination.

This table presents the average accuracy of different continual learning methods on four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) with varying levels of synthetic data contamination. The results show the impact of synthetic data contamination on model performance, and the numbers in parentheses show the decrease in accuracy compared to using clean datasets. The table also specifies the number of runs performed for each experiment.
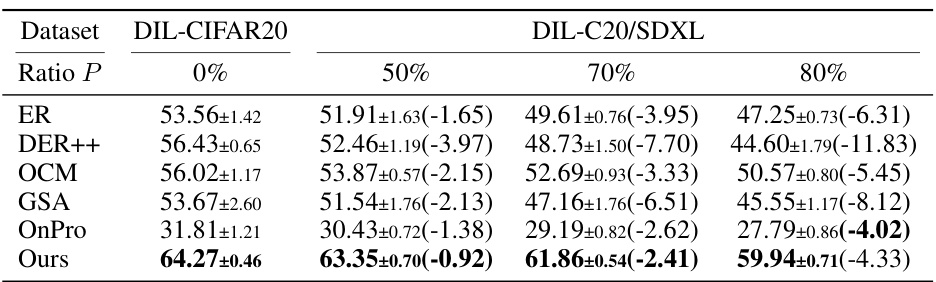
This table presents the average accuracy of six online continual learning methods (ER, DER++, ER-ACE, OCM, GSA, OnPro, and ESRM) on four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) with varying levels of synthetic data contamination (0%, 50%, 70%, 80%, 90%, and 95%). The numbers in parentheses show the decrease in accuracy due to contamination compared to the clean dataset. The results indicate the impact of synthetic data contamination on the performance of online continual learning methods and highlight the effectiveness of ESRM in mitigating this negative impact.
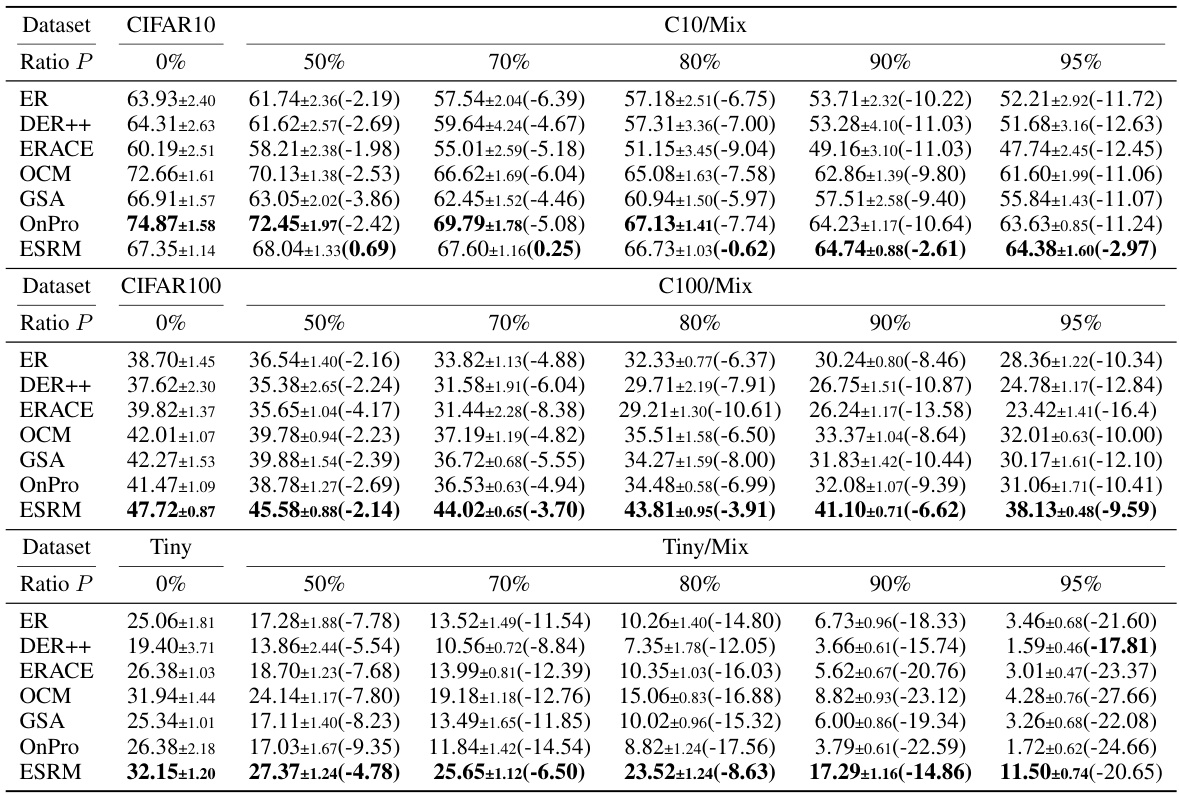
This table presents the average accuracy of six online continual learning methods (ER, DER++, ER-ACE, OCM, GSA, OnPro, and ESRM) across four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) under varying levels of synthetic data contamination (0%, 50%, 70%, 80%, 90%, and 95%). The results show the impact of synthetic data contamination on the performance of each method, with the numbers in parentheses indicating the performance drop relative to the clean dataset (0% contamination). The table highlights ESRM’s superior robustness to synthetic contamination.
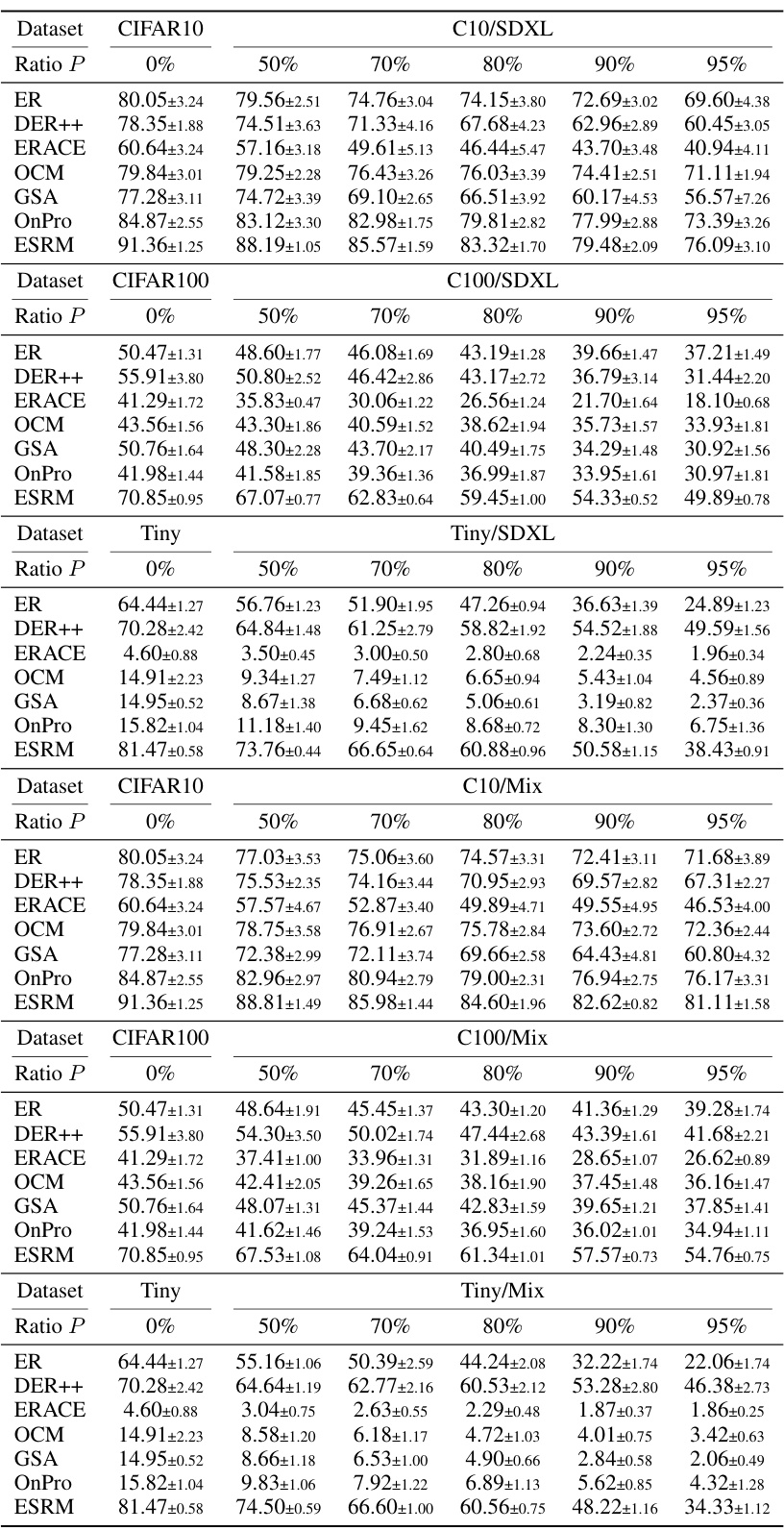
This table presents the average accuracy achieved by different continual learning methods (ER, DER++, ERACE, OCM, GSA, OnPro, and ESRM) on four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) with varying levels of synthetic data contamination (0%, 50%, 70%, 80%, 90%, 95%). The numbers in parentheses show the performance drop compared to the clean dataset (no contamination), illustrating the negative impact of synthetic data. The results are averaged over multiple runs, with a different number of runs for ImageNet-100.
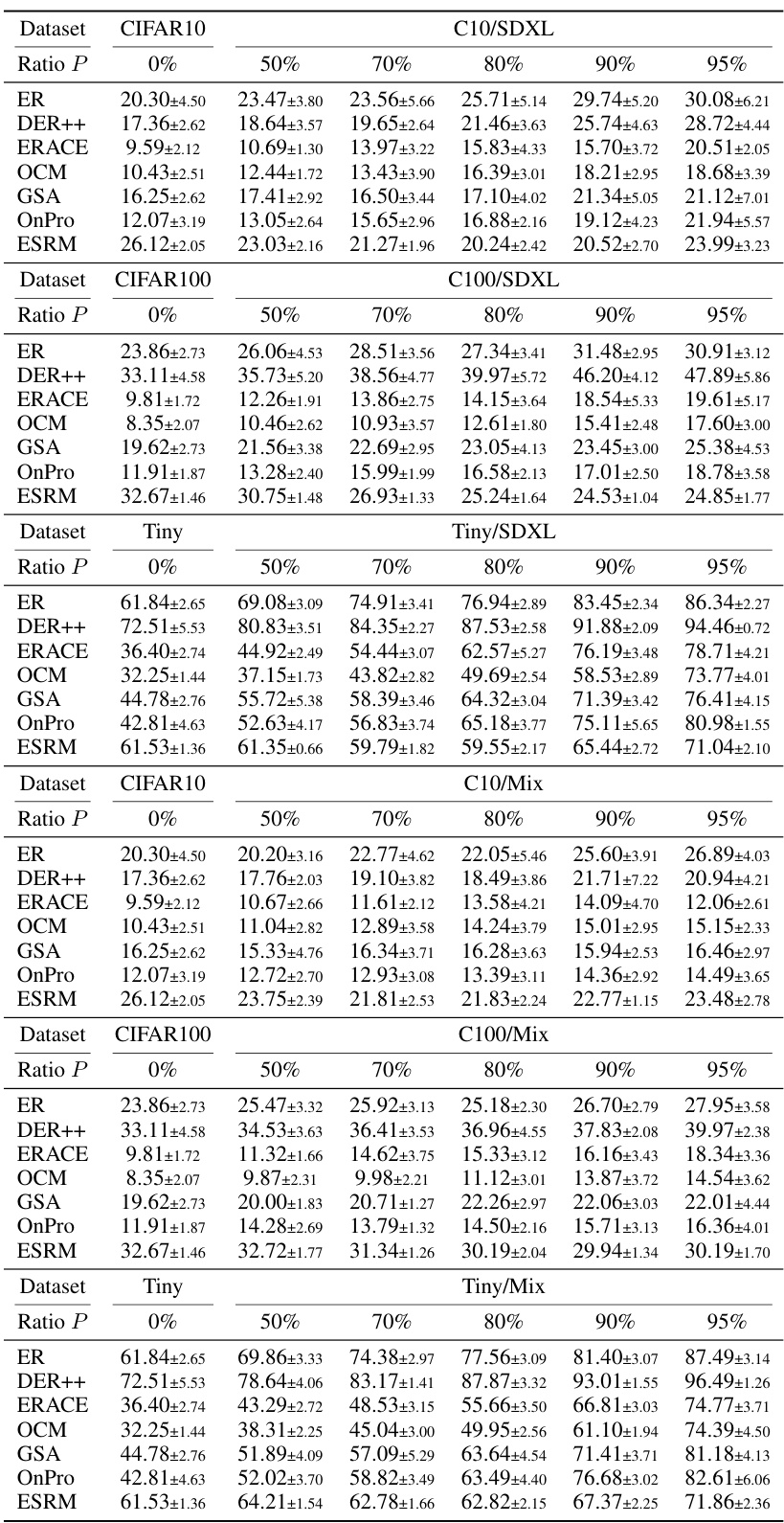
This table presents the average accuracy of six online continual learning methods across four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) with varying levels of synthetic data contamination. The results show how the accuracy of each method changes as the percentage of synthetic data increases from 0% to 95%. Numbers in parentheses show the performance drop compared to the uncontaminated dataset, indicating the negative effect of contamination.

This table presents the average accuracy achieved by six different online continual learning methods across four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) under varying levels of synthetic data contamination (0%, 50%, 70%, 80%, 90%, 95%). The results show how the accuracy of each method degrades as the percentage of synthetic data increases. The numbers in parentheses represent the decrease in accuracy compared to the clean (0% contamination) setting. The table highlights the impact of synthetic data contamination on the performance of different online continual learning algorithms and serves as a key result in evaluating the proposed method’s robustness.

This table presents the average accuracy achieved by different continual learning methods on four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) under varying levels of synthetic data contamination. The accuracy is shown for different contamination ratios (P = 0%, 50%, 70%, 80%, 90%, 95%). The numbers in parentheses represent the decrease in accuracy due to contamination, compared to the clean dataset (P=0%). The results highlight the impact of synthetic data contamination on continual learning performance. The number of experimental runs is specified for each dataset, with 5 for ImageNet-100 and 10 for other datasets.

This table presents the average accuracy achieved by different online continual learning methods on four benchmark datasets (CIFAR-10, CIFAR-100, TinyImageNet, and ImageNet-100) with varying levels of synthetic data contamination. The results show the impact of synthetic data contamination on the performance of these methods, indicating performance degradation as the contamination level increases. The table also highlights the relative performance of each method compared to its performance on clean datasets, providing a clear view of the negative influence of synthetic data contamination on online continual learning.
Full paper#