↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reconstructing 3D scenes from just a single image is a notoriously difficult task in computer vision. Existing methods often struggle with challenges like heavy occlusions and the lack of sufficient information in a 2D image to accurately reconstruct complex 3D shapes and their relationships. This leads to unrealistic or incomplete 3D models, limiting their usefulness in applications. This paper tackles this problem by employing a novel technique based on diffusion models.
Instead of directly predicting the 3D scene, this approach uses a diffusion model to gradually remove noise from an initially noisy representation of the scene, iteratively refining the 3D shapes and positions of objects. The key innovation is the incorporation of a generative scene prior that captures the relationships between objects, enabling a more globally consistent and realistic reconstruction. This approach significantly outperforms state-of-the-art methods, achieving higher accuracy in 3D scene reconstruction on benchmark datasets, showcasing its ability to produce realistic and detailed 3D models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to 3D scene reconstruction from a single image, a challenging problem in computer vision. Its use of diffusion models and a novel scene prior allows for more robust and accurate results than previous methods. This opens up new avenues of research in areas like augmented reality, robotics, and 3D content creation.
Visual Insights#

This figure illustrates the overall process of the proposed method. Given a single RGB image as input, the system first detects 2D bounding boxes of objects. Then, a 3D scene diffusion model jointly estimates the 3D poses and shapes of all objects within the scene, considering both individual object characteristics and their inter-object relationships. Finally, a shape decoding process generates a globally consistent 3D scene reconstruction.
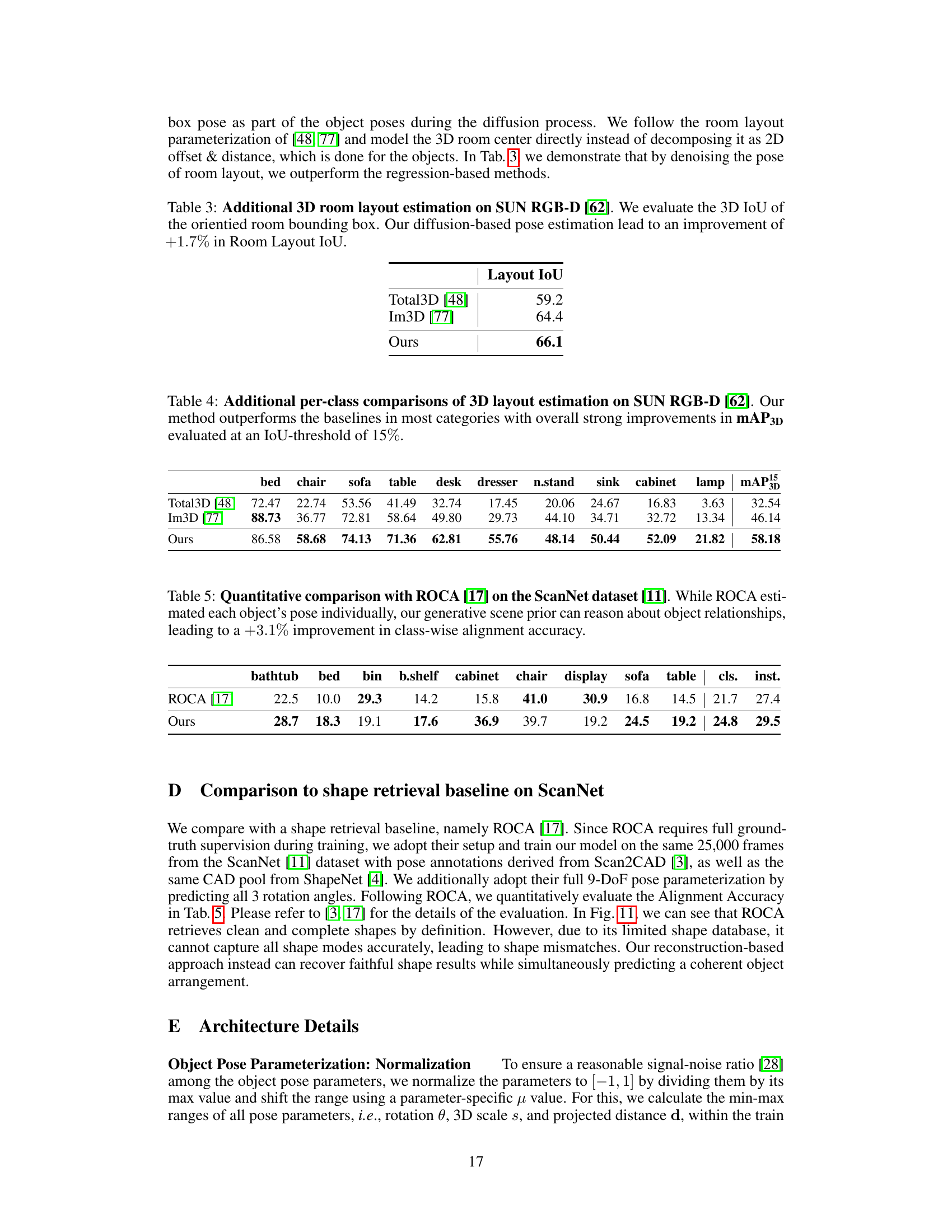
This table presents a quantitative comparison of the proposed 3D scene diffusion approach against state-of-the-art methods on two benchmark datasets: SUN RGB-D and Pix3D. For SUN RGB-D, it shows the Intersection over Union (IoU) for 3D bounding boxes, Average Precision (AP) at 15% IoU threshold, and a surface alignment loss (Lalign). For Pix3D, it displays the Chamfer distance (CD) and F-Score. The results demonstrate that the proposed method significantly outperforms the baselines across all metrics on both datasets.
In-depth insights#
Scene Diffusion Model#
A hypothetical ‘Scene Diffusion Model’ in the context of 3D reconstruction from a single RGB image would likely leverage diffusion models to generate coherent 3D scenes. This approach would likely involve a process where a noisy representation of the scene is progressively denoised using an image-conditioned diffusion process. The model would learn to capture intricate scene context and inter-object relationships, addressing the inherent ambiguity of single-view 3D reconstruction. Key innovations might include novel loss functions to enforce geometrical consistency and object plausibility even with limited ground truth data. The model architecture would likely utilize a hierarchical or multi-scale approach, processing image information at different resolutions to capture both fine details and global scene structure. The effective representation of scene geometry (e.g., point clouds, meshes, implicit surfaces) and object poses is crucial for successful implementation. A strong scene prior learned by the model is vital to producing realistic scene reconstructions, overcoming inherent ambiguities and data sparsity. This would necessitate a large-scale training dataset with diverse scene compositions and extensive annotation. Finally, the model’s performance would be evaluated on established benchmarks (e.g., SUN RGB-D, Pix3D) based on metrics assessing 3D scene reconstruction accuracy and realism.
Joint Pose & Shape#
The concept of “Joint Pose & Shape” in 3D scene reconstruction signifies a paradigm shift from independently estimating object poses and shapes to a unified, holistic approach. This integrated strategy acknowledges the inherent interdependence between an object’s 3D pose (location and orientation) and its 3D shape. Simultaneously inferring both pose and shape leads to more coherent and realistic scene reconstructions, mitigating issues like intersecting objects or implausible arrangements that plague traditional, decoupled methods. The advantages are significant. By considering the scene context and inter-object relationships during the joint estimation, the method can overcome challenges posed by occlusions and ambiguous depth cues in single-view reconstructions. A generative model is often employed to learn the coupled distribution of poses and shapes, further enhancing the accuracy and consistency of the final output. This approach also simplifies the optimization process, potentially avoiding the need for complex, multi-stage pipelines. Efficient loss functions are crucial for successful training within this framework, particularly when dealing with incomplete or noisy ground truth data which is common in real-world datasets. Overall, the “Joint Pose & Shape” approach represents a substantial advancement in the quest for high-fidelity 3D scene understanding from limited input data.
Surface Alignment Loss#
The proposed ‘Surface Alignment Loss’ tackles a crucial challenge in single-view 3D scene reconstruction: scarcity of full ground-truth annotations. Many public datasets lack complete depth information, hindering effective joint training of object pose and shape. This loss cleverly addresses this by leveraging an expressive intermediate shape representation which enables direct point sampling. Instead of relying on costly surface decoding, this allows for comparison between predicted and ground truth point clouds, using a 1-sided Chamfer Distance. This approach provides additional supervision, even with partial annotations, resulting in more globally consistent 3D scene reconstructions and improved accuracy in joint pose and shape estimation. The efficiency and effectiveness are particularly beneficial for training on datasets such as SUN RGB-D and Pix3D, demonstrating significant improvements in metrics like AP3D and F-Score.
Scene Prior’s Role#
The effectiveness of single-view 3D scene reconstruction heavily relies on a strong scene prior, which helps overcome the inherent ambiguity of the task. A well-designed scene prior should capture both the context of the entire scene and the relationships between individual objects. This allows the model to make more realistic predictions, avoiding the common issues of unrealistic object arrangements or intersecting geometries seen in previous works. The model learns a scene prior by conditioning on all objects simultaneously, allowing it to implicitly learn object relationships and spatial arrangements, thereby improving the accuracy of pose and shape estimation. Furthermore, an effective scene prior should be robust to noise and occlusions, common in real-world images, and should generalize well to unseen scenes and datasets. This robustness is crucial for achieving higher accuracy and better generalization in real-world scenarios. The proposed approach leverages a generative prior learned from the data, resulting in higher fidelity and improved scene reconstruction compared to methods that estimate object poses and shapes independently.
Future Work#
The research paper’s ‘Future Work’ section would ideally delve into several promising avenues. Expanding the model’s capabilities to handle unseen object categories is crucial, perhaps by integrating techniques like few-shot learning or zero-shot learning. Improving robustness to noisy or incomplete input (e.g., blurry images, significant occlusions) is another key area. This could involve incorporating more advanced image processing techniques or refining the model’s understanding of scene context. Addressing the computational cost of the diffusion model would make it more practical for real-world deployment, possibly through architectural optimizations or the exploration of alternative generative methods. Finally, exploring the potential of incorporating temporal information into the scene reconstruction would greatly enhance the model’s abilities and allow for more dynamic scene understanding.
More visual insights#
More on figures

This figure illustrates two key components of the proposed 3D scene reconstruction method: the scene prior and the surface alignment loss. The scene prior models the relationships between objects in the scene to improve reconstruction accuracy. The surface alignment loss uses point samples from intermediate shape predictions and ground truth depth maps to improve training, even with limited annotations.

This figure compares the 3D scene reconstruction results of three different methods: Total3D, Im3D, and the proposed method. The input RGB image is shown alongside the 3D reconstructions generated by each method. The figure highlights the superior quality and coherence of the proposed method’s 3D scene reconstructions compared to the baselines, which tend to produce noisy, incomplete, or spatially inconsistent results.

This figure compares the 3D scene reconstruction results of three different methods (Total3D, Im3D, and the proposed method) on the SUN RGB-D dataset. The input RGB images are shown alongside the 3D reconstructions generated by each method. The figure highlights that the proposed method produces more realistic and accurate 3D scene reconstructions compared to the baseline methods, particularly in terms of object arrangements and shape details. The baseline methods often suffer from intersecting objects or missing parts of objects due to inaccuracies in pose estimation and shape prediction, while the proposed method shows significantly improved results with more coherent scene structures and higher-quality object shapes.

This figure shows the results of running the model without any conditioning image. The model generates high-quality and diverse 3D models of various furniture items, demonstrating the model’s ability to learn a rich and varied representation of shapes in a scene without the guidance of a specific input image. This showcases the effectiveness of the learned scene prior in capturing the essence of indoor scenes.

This figure compares the results of three different methods for 3D scene reconstruction from a single RGB image on the SUN RGB-D dataset. The methods compared are Total3D, Im3D, and the authors’ proposed method. The figure shows that the authors’ method produces more accurate and realistic 3D scene reconstructions compared to the baselines, especially in terms of object arrangement and shape details. The baselines often produce noisy or incomplete shapes, intersecting objects, or misplaced objects. In contrast, the authors’ method is able to generate plausible object arrangements and high-quality shape reconstructions.
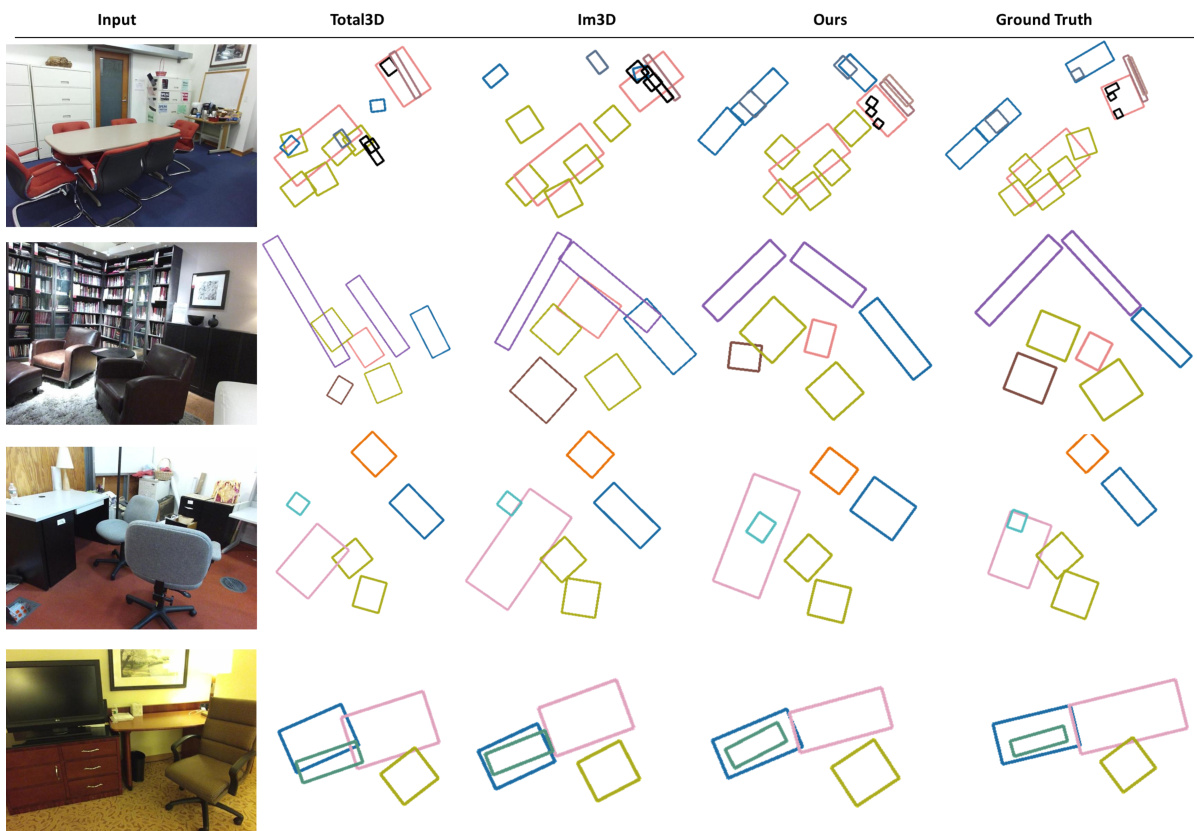
This figure compares the results of 3D scene reconstruction on the SUN RGB-D dataset using three different methods: Total3D, Im3D, and the proposed method. The input RGB image is shown alongside the 3D reconstructions generated by each method. The ground truth is also provided for comparison. The figure highlights that the proposed method generates more plausible and realistic 3D scene reconstructions than the baselines, which often suffer from noisy shapes, incomplete objects, and unrealistic object placements.

This figure compares the results of three different methods for 3D scene reconstruction from a single RGB image on the SUN RGB-D dataset. The input image is shown on the left. The other three columns show the results produced by Total3D, Im3D, and the authors’ proposed method. The figure illustrates that the authors’ method generates significantly more accurate and realistic 3D scene reconstructions compared to the baselines, avoiding issues like intersecting or floating objects.

This figure compares the 3D shape reconstruction results of the proposed method with those of InstPIFu on the Pix3D dataset. It shows that the proposed diffusion model produces high-quality shapes, unlike InstPIFu, which tends to produce noisy surfaces. The comparison highlights the superior shape reconstruction capabilities of the proposed approach, especially in terms of detail and accuracy in matching the ground truth shapes.

This figure illustrates the overall pipeline of the proposed method. It takes a single RGB image as input and produces a complete 3D reconstruction of the scene. The process involves jointly estimating the 3D poses and shapes of all the objects in the scene using a diffusion model. A novel generative scene prior is used to capture the scene context and inter-object relationships. An efficient surface alignment loss is employed to ensure accurate predictions. The figure shows an example of an indoor scene, an intermediate scene representation, and the resulting 3D scene reconstruction.

This figure compares the results of 3D scene reconstruction using the proposed diffusion-based method and a retrieval-based method (ROCA) on three different scenes from the ScanNet dataset. The input RGB images are shown on the left. The middle column displays reconstructions from ROCA, a retrieval-based approach that selects shapes from a database. The right column presents the results from the proposed diffusion model. The figure highlights that while ROCA struggles to find appropriate matches from its database (particularly evident in the desk example), the diffusion model generates more accurate and complete 3D reconstructions that better align with the input images.

This figure illustrates two key components of the proposed method: the scene prior and the surface alignment loss. The left side shows how the model considers the relationships between objects within a scene during the denoising process, improving scene coherence. The right side details the surface alignment loss, which uses point samples from intermediate shape predictions and ground truth depth maps to provide additional training supervision, especially useful when full ground truth is unavailable.
More on tables

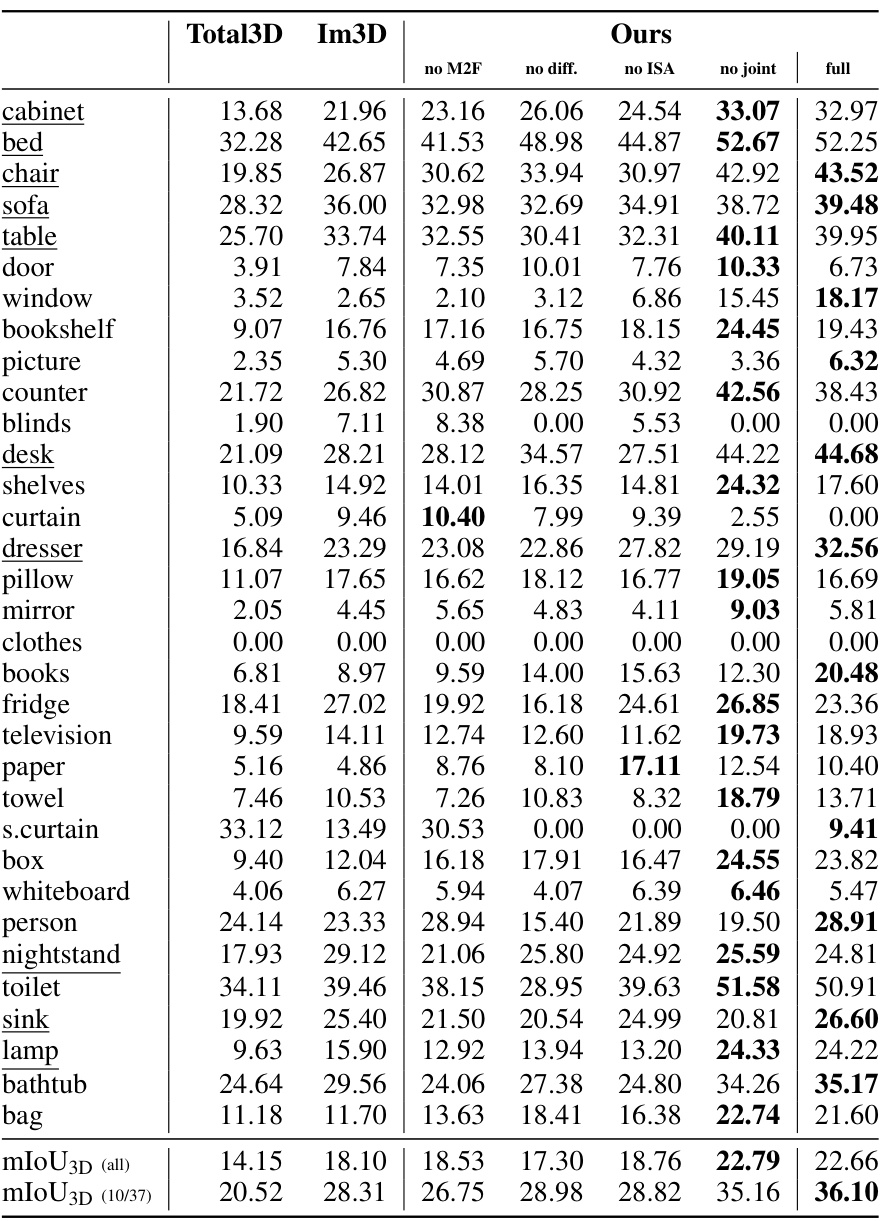
This table presents ablation study results, showing the impact of different design choices on the model’s performance. It demonstrates the individual and combined contributions of using a diffusion model, incorporating intra-scene attention (ISA), and jointly training pose and shape. The results quantify the improvements achieved by each component, highlighting the effectiveness of the overall approach.

This table compares the performance of three different methods for 3D room layout estimation on the SUN RGB-D dataset. The methods are Total3D [48], Im3D [77], and the authors’ proposed method. The metric used is the 3D Intersection over Union (IoU) of the oriented room bounding box. The authors’ method achieves a +1.7% improvement in Layout IoU compared to Im3D.

This table presents a quantitative comparison of the proposed 3D scene diffusion model against several state-of-the-art baselines on two benchmark datasets: SUN RGB-D and Pix3D. The left side shows results for 3D scene reconstruction on SUN RGB-D, evaluating Average Precision (AP) at an Intersection over Union (IoU) threshold of 15% and a novel surface alignment loss (Lalign). The right side shows results for 3D shape reconstruction on Pix3D, using Chamfer Distance (CD) and F-Score as evaluation metrics. The table demonstrates the superior performance of the proposed method on both datasets across these commonly used metrics.

This table compares the performance of the proposed method against ROCA [17] on the ScanNet dataset [11] in terms of class-wise alignment accuracy. The key finding is that the proposed method, by leveraging a generative scene prior that captures inter-object relationships, achieves a 3.1% improvement over ROCA, which estimates object poses individually. The table presents the quantitative results for each object category.

This table presents a quantitative comparison of the proposed 3D scene diffusion method against several state-of-the-art baselines on two benchmark datasets: SUN RGB-D and Pix3D. For SUN RGB-D, the metrics used are Average Precision (AP) at an Intersection over Union (IoU) threshold of 15% and a surface alignment loss (Lalign). For Pix3D, the metrics are Chamfer Distance (CD), and F-Score. The results demonstrate that the proposed method significantly outperforms the baselines on all metrics, highlighting its effectiveness in both 3D scene and shape reconstruction.

This table presents a quantitative comparison of the proposed 3D scene diffusion approach’s shape reconstruction performance against three state-of-the-art baselines (Total3D, Im3D, and InstPIFu) on the Pix3D dataset. The comparison is made using the F-Score metric, a common evaluation measure for 3D shape reconstruction tasks. The table breaks down the F-Score for each of the object categories in the Pix3D dataset, offering a detailed view of the method’s performance across different object types. The non-overlapping 3D model split from a previous work [37] ensures the results are not influenced by model overlap during training.
This table presents a quantitative comparison of the proposed 3D scene diffusion method against several state-of-the-art baselines on two benchmark datasets: SUN RGB-D and Pix3D. The metrics used for evaluation include Average Precision (AP), Intersection over Union (IoU), Chamfer Distance (CD), and F-Score. The results demonstrate significant improvements achieved by the proposed approach over existing methods in both 3D scene and shape reconstruction tasks.

This table presents a quantitative comparison of the proposed method against state-of-the-art methods for 3D shape reconstruction on the Pix3D dataset. It shows the F-score achieved for each object category (bed, bookcase, chair, desk, miscellaneous objects, sofa, table, tool, wardrobe) using a non-overlapping split of the dataset. The results demonstrate the effectiveness of the proposed method, showing either improvements or comparable performance compared to existing approaches.
Full paper#