↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision Transformers (ViTs) offer high accuracy in image recognition but are computationally expensive, hindering real-time performance on mobile devices. Existing optimization methods mainly focus on theoretical complexity reduction but often introduce additional overheads due to data transformations on mobile hardware. This paper introduces ECP-ViT, a novel framework that tackles this issue by employing a core-periphery principle inspired by brain networks. This principle guides self-attention in ViTs, focusing computation on crucial parts of the image and reducing data transformations.
ECP-ViT further incorporates hardware-friendly system optimizations, primarily focusing on eliminating costly data transformations (reshape and transpose operations). These algorithm-system co-optimizations are implemented through a compiler framework, leading to impressive speedups (4.6x to 26.9x) on mobile GPUs across different datasets (STL-10, CIFAR-100, TinyImageNet, and ImageNet). The results showcase a significant improvement in real-time performance without compromising accuracy, making ViTs more practical for mobile AI applications.
Key Takeaways#
Why does it matter?#
This paper is significant because it directly addresses the challenge of deploying computationally expensive Vision Transformers (ViTs) on mobile devices, a critical limitation for real-time AI applications. By introducing novel algorithm-system co-optimizations, including a hardware-friendly core-periphery guided self-attention mechanism and compiler-based optimizations, it achieves substantial speedups (4.6x to 26.9x) while maintaining high accuracy. This work opens new avenues for research in efficient transformer architectures and compiler optimizations for mobile AI.
Visual Insights#
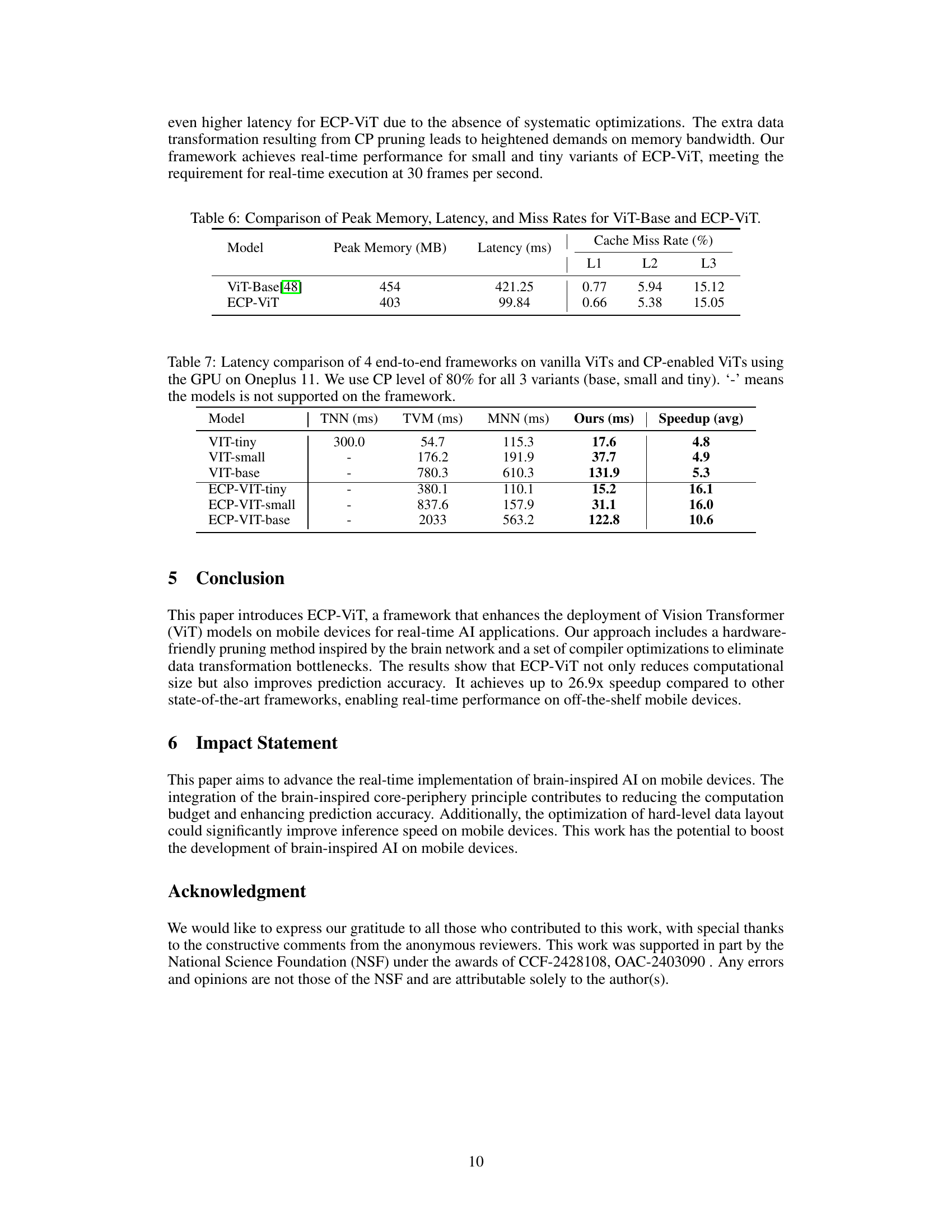
This figure compares various vision transformer models (including ECP-ViT) on ImageNet-1K dataset based on Top-1 accuracy, latency (measured on Oneplus 11), and multiply-accumulate operations (MACs). ECP-ViT-Base is highlighted for achieving the highest accuracy and significantly faster inference speed (6x faster than ViT-Base). The size of each circle visually represents the model’s MACs.

This table compares the performance of ViT and DeiT on a Oneplus 11 phone. It breaks down the execution time into layout transformation (e.g., transpose and reshape) and pure computation, and also shows the intermediate results in megabytes. The comparison highlights the significant overhead of layout transformations, especially in DeiT, which is crucial for understanding the performance differences on mobile devices.
In-depth insights#
ECP-ViT: Core-Periphery#
ECP-ViT leverages the core-periphery principle from brain networks to optimize Vision Transformers (ViTs) for mobile devices. This approach identifies and prioritizes crucial (core) network components responsible for high-level feature extraction, delegating less critical tasks to the periphery. By strategically pruning less important connections in the periphery, ECP-ViT achieves a substantial reduction in computational demands. The resulting sparse architecture dramatically improves real-time performance, achieving significant speedups compared to vanilla ViTs and other optimized transformers. Algorithm-system co-optimization, combining the core-periphery framework with targeted compiler optimizations, further minimizes the performance bottleneck associated with data transformation steps in pruned models. This integrated approach offers a significant enhancement in efficient ViT deployment on resource-constrained platforms such as smartphones.
Mobile ViT Acceleration#
Mobile ViT acceleration is a crucial area of research, focusing on adapting Vision Transformers (ViTs) for resource-constrained mobile devices. Key challenges include the high computational cost of self-attention and the large number of parameters in ViTs. Existing approaches often focus on reducing theoretical computational complexity through architectural modifications like local attention or model pruning. However, these methods often neglect practical performance limitations on mobile hardware, such as limited memory bandwidth and irregular data access patterns. Effective mobile ViT acceleration requires a holistic approach, encompassing architectural innovations, hardware-aware optimizations, and efficient software implementations. Algorithm-system co-optimization is vital, considering data layout selection to minimize memory access overheads and data transformations. Ultimately, the goal is to develop fast and accurate ViT models capable of real-time performance on mobile devices, enabling a wider range of AI-powered applications.
Compiler Optimizations#
Compiler optimizations are crucial for achieving real-time performance with Vision Transformers (ViTs) on mobile devices. The paper highlights the significant overhead introduced by data transformations (Reshape and Transpose) inherent in many ViT architectures. These transformations cause irregular memory access patterns that severely impact performance on mobile hardware’s limited bandwidth. The proposed approach employs a comprehensive set of compiler optimizations designed to completely eliminate these costly operations. This is achieved through a co-design strategy that considers both the algorithm and system levels, enabling a hardware-friendly core-periphery guided self-attention mechanism and flexible data layout selection. The optimizations go beyond basic operator fusion and constant folding, focusing instead on sophisticated techniques that reorganize tensor layouts to eliminate unnecessary reshaping and transposing, leading to considerable speedups. By carefully selecting data layouts during compilation, the system avoids explicit data transformations, improving memory access patterns and efficiency. This approach dramatically reduces execution time, effectively bridging the gap between the theoretical computational complexity reductions of pruned models and the actual realized speed improvements on resource-constrained mobile hardware. The effectiveness of these co-optimizations is validated through extensive benchmarking, demonstrating significant speedups compared to existing frameworks.
Data Layout Control#
Effective ‘Data Layout Control’ in deep learning, particularly on resource-constrained devices like mobile phones, is crucial for performance. Optimizing data layout minimizes data transfer overhead, a significant bottleneck in mobile hardware. Strategies like memory-friendly data structures and efficient tensor reorganizations are key to reducing latency. Compiler optimizations play a vital role, enabling the system to automatically generate optimal data layouts for specific hardware and operator sequences, eliminating manual transformations. A well-designed system would allow for flexible data layout selection based on the computational graph and hardware capabilities, dynamically adapting to maximize performance. Careful consideration of data access patterns is also essential; reducing irregular memory access through strategic data placement can drastically improve speed. Therefore, a holistic approach encompassing algorithm design, system optimizations, and compiler-level control is critical for achieving optimal ‘Data Layout Control’ in mobile deep learning.
Future Work: Enhancements#
A section on “Future Work: Enhancements” for a vision transformer (ViT) research paper could explore several promising directions. Improving efficiency on mobile devices remains crucial, perhaps through exploring novel pruning strategies beyond core-periphery methods, or by investigating alternative quantization techniques. Expanding the scope of applications is another key area; researchers could investigate the effectiveness of the proposed method on other tasks like object detection or video analysis. Addressing inherent limitations of the core-periphery approach itself warrants attention. A deeper analysis of its sensitivity to various image characteristics or dataset biases would strengthen the work. Finally, comparative studies against other state-of-the-art mobile-friendly ViT variants, under a more comprehensive set of benchmarks, are needed for robust evaluation. Investigating the integration with advanced compiler optimizations beyond those already implemented would be highly valuable. Furthermore, exploring the potential of algorithm-hardware co-design for even greater speedups would contribute significantly.
More visual insights#
More on figures
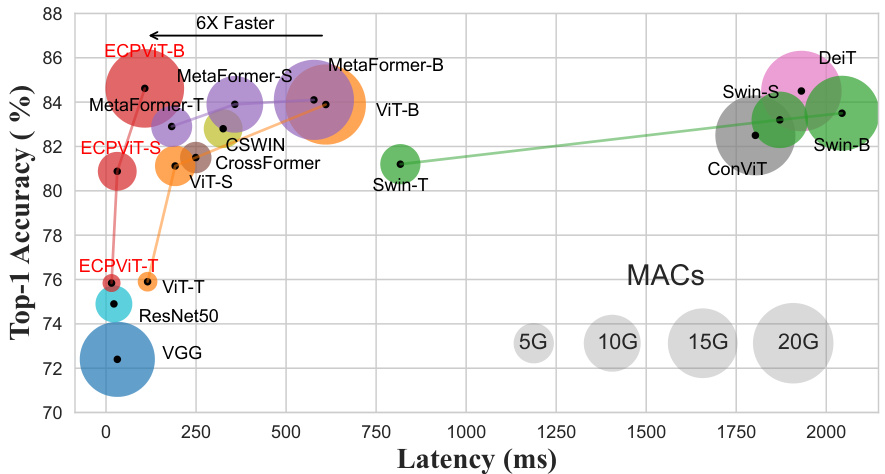
This figure illustrates the co-design framework of ECP-ViT, which consists of software-level and hardware-level designs. The software design shows how core-periphery graphs guide the self-attention mechanism in ECP-ViT, rescheduling interactions between patches and guiding the multiplication of query, key, and value matrices. The hardware design focuses on eliminating the slice and transpose reshape operations to improve efficiency. In essence, it explains how the algorithm and system are co-optimized for faster and more efficient processing on mobile devices.

This figure illustrates the computation flow of a standard Vision Transformer (ViT) attention module. It highlights the data layout transformations (Slice & Reshape and Transpose) involved in processing query (Q), key (K), and value (V) matrices. The red words indicate explicit data layout transformations that are computationally expensive. The figure shows how these transformations impact the overall efficiency and performance of the ViT model on mobile devices.

This figure shows different examples of core-periphery graphs with varying core ratios (0.1, 0.3, 0.5, and 1.0). The core ratio represents the proportion of core nodes to the total number of nodes in the graph. Each graph is visualized in two ways: as an adjacency matrix (showing connections between nodes) and a visual representation where core nodes are colored red and periphery nodes are black. As the core ratio increases, the number of connections (black areas in the matrix and visual representations) increases, demonstrating how the structure of the graph evolves with different core ratios. A core ratio of 1.0 represents a fully connected graph (a complete graph) without any pruned nodes.

This figure illustrates how the core-periphery principle is applied to the self-attention mechanism in the ECP-ViT model. The Query, Key, and Value matrices, fundamental components of self-attention, are divided into core and periphery parts. This partitioning, guided by the core-periphery graph, transforms the standard self-attention into a Core-Periphery (CP) attention mechanism. The figure visually represents this transformation, showcasing how the core and periphery components interact differently, leading to a more efficient computation.

This figure illustrates the data flow and layout transformations in a standard ViT attention module (left) and how ECP-ViT optimizes it (right). The left side shows the original ViT process, highlighting explicit data layout transformations (red) like Transpose and Reshape, which are computationally expensive on mobile devices. The middle panel illustrates the data layout transformation for fused attention (middle) and the right panel illustrates the efficient data access pattern of ECP-ViT (right). The ECP-ViT design reduces or eliminates these transformations by reorganizing computations and data flow to make the process more efficient for mobile hardware.

This figure compares the latency speedup achieved by the proposed ECP-ViT model against the MNN framework on a low-end Xiaomi 6 device. It shows speedup results for three different sizes of the ViT model (Base, Small, Tiny) and their corresponding ECP-ViT counterparts. The comparison highlights the performance gains of ECP-ViT across various model scales on less powerful mobile hardware.
More on tables
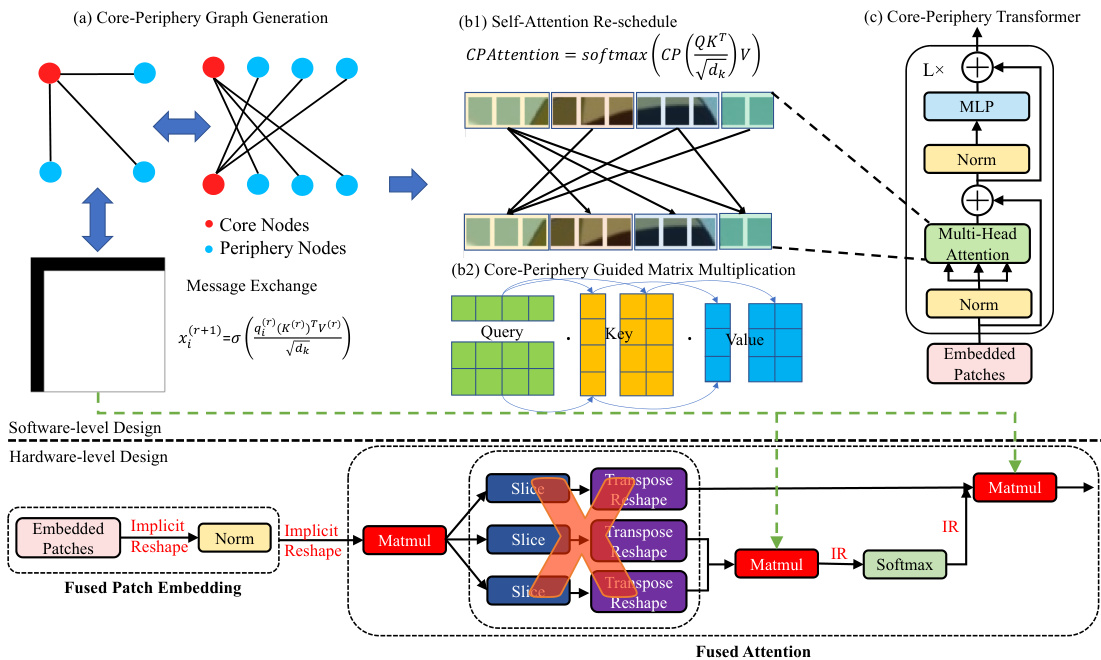
This table compares the performance of various vision transformer models on the ImageNet dataset. The models are compared based on their top-1 accuracy, the number of parameters, and the number of multiply-accumulate (MAC) operations. The ECP-ViT model is highlighted, showcasing its performance relative to other state-of-the-art models. Note that all models use pre-trained weights from ImageNet-21K, and the ECP-ViT results are for its optimal core ratio.

This table shows the Top-1 accuracy of ECP-ViT models (Tiny, Small, and Base) on the ImageNet dataset under various core ratios (from 0.1 to 1.0, where 1.0 represents the baseline ViT without pruning). The results illustrate the impact of the core-periphery guided self-attention mechanism on model accuracy as the core ratio (percentage of core nodes) changes.
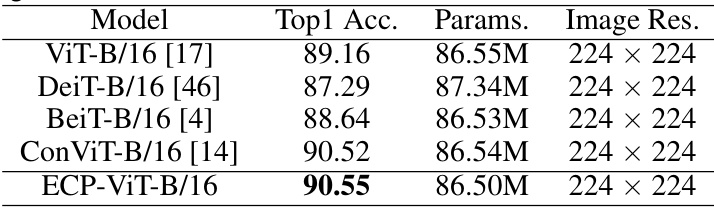
This table compares the Top-1 accuracy of ECP-ViT against other vision transformer (ViT) variants on the TinyImageNet dataset. It highlights ECP-ViT’s superior performance in terms of accuracy, showcasing the effectiveness of its core-periphery guided self-attention mechanism. The best result for ECP-ViT is reported based on different core ratios.

This table compares the Top-1 accuracy of vanilla ViT-S/16 and ECP-ViT-S/16 models on STL-10 and CIFAR-100 datasets. The ECP-ViT model shows improvement in accuracy over the vanilla ViT model, especially on STL-10 dataset.

This table compares the peak memory usage (in MB), latency (in ms), and cache miss rates (L1, L2, and L3) for both the original ViT-Base model and the proposed ECP-ViT model. It showcases the memory efficiency and speed improvements achieved by ECP-ViT compared to the baseline ViT-Base model.

This table compares the latency (in milliseconds) of four different deep learning frameworks (TNN, TVM, MNN, and the authors’ proposed framework) when running vanilla Vision Transformers (ViTs) and core-periphery guided ViTs (ECP-ViTs) on the GPU of a Oneplus 11 phone. The comparison highlights the speedup achieved by the authors’ framework, particularly for ECP-ViTs which demonstrate significant performance gains.
Full paper#