↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Accurately estimating pedestrian poses before vehicle collisions is crucial for improving pedestrian safety technologies, but existing human pose estimation models struggle with the unique and often obscured poses involved in these accidents. Furthermore, there’s a severe lack of real-world datasets capturing these critical moments. This paper highlights the challenges of training robust models due to the scarcity of appropriate datasets and the difficulty of obtaining high-quality 3D pose annotations for such specific actions.
To tackle these problems, the researchers created the Pedestrian-Vehicle Collision Pose (PVCP) dataset, a large-scale collection of pedestrian-vehicle accident videos with detailed pose annotations (2D, 3D, mesh). They then developed a novel network, PPSENet, designed to estimate pre-collision poses. This two-stage network effectively uses a pre-trained model to enhance accuracy, employs iterative regression to improve estimations, and introduces a pose class loss. Their results demonstrate improved accuracy over existing methods, highlighting the effectiveness of their approach and the importance of the PVCP dataset for future research. The availability of the code and data will undoubtedly accelerate the development of more robust pedestrian safety technologies.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on pedestrian safety, computer vision, and human pose estimation. It addresses a critical gap in existing datasets by providing a large-scale, high-quality dataset of pedestrian pre-collision poses gathered from dashcam footage. The development of a novel pose estimation network demonstrates the practical applicability of this data to enhance pedestrian safety technology. This research opens new avenues for improving the accuracy and robustness of pedestrian safety systems, ultimately saving lives.
Visual Insights#
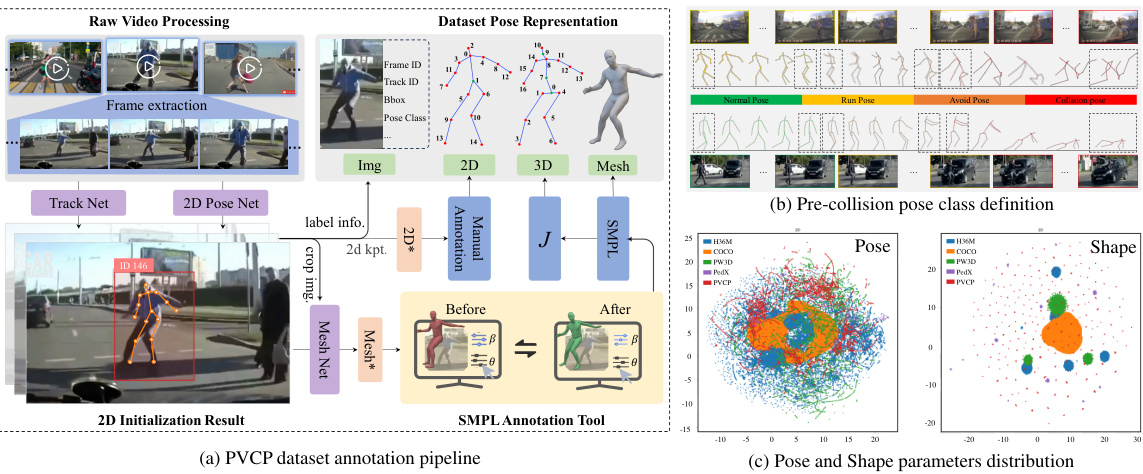
This figure illustrates the annotation pipeline for the Pedestrian-Vehicle Collision Pose (PVCP) dataset, showing the steps involved in obtaining the final annotations from raw videos. It also provides a visualization of the four pre-collision pose classes (normal, run, avoid, collision) that the dataset is categorized into and displays the distributions of pose and shape parameters in the dataset using UMAP dimensionality reduction, showing how different poses and shapes cluster together.
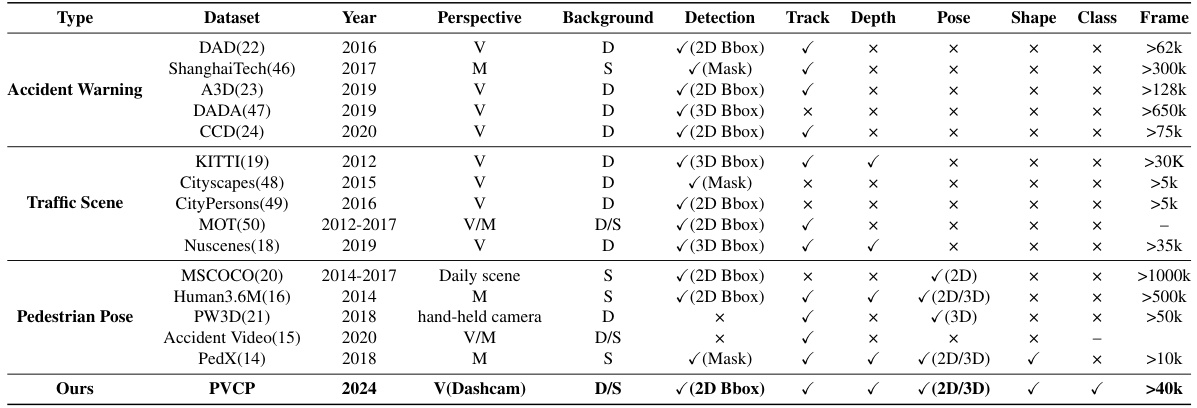
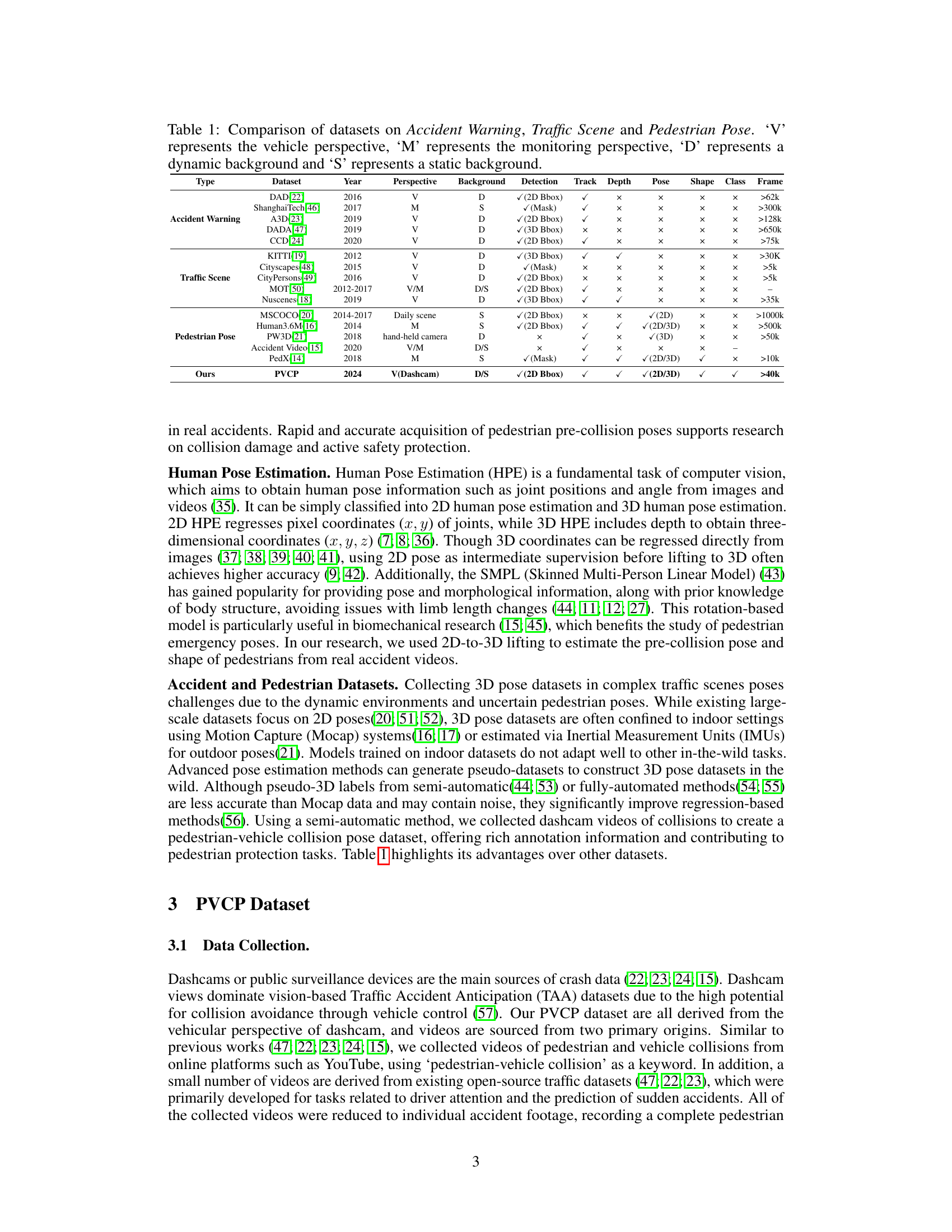
This table compares various datasets used for accident warning, traffic scene understanding, and pedestrian pose estimation. It highlights key differences in the year of publication, perspective (vehicle or monitoring), background type (dynamic or static), the types of detection provided (bounding boxes, masks), whether tracking and depth information is available, and if 2D or 3D pose and shape information are included. The table also notes the number of frames available in each dataset. This allows for a comprehensive comparison of the suitability of each dataset for pedestrian pre-collision pose estimation.
In-depth insights#
Dashcam Pose Dataset#
A Dashcam Pose Dataset offers a unique opportunity to advance research in pedestrian behavior analysis, particularly in pre-collision scenarios. Dashcam footage provides a realistic, in-situ view of pedestrian actions, unlike controlled lab settings or simulations. The data’s inherent challenges—variable lighting, occlusion, and dynamic backgrounds—mirror real-world conditions, forcing the development of robust and generalizable algorithms. A key benefit is the potential to improve pedestrian safety systems by training models on diverse accident scenarios. However, careful consideration of data privacy and ethical implications is paramount. Annotating dashcam data is inherently time-consuming and labor-intensive, requiring strategies for efficient and accurate labeling. The dataset’s value hinges on sufficient data volume and diversity, representing a wide range of pedestrian actions and environmental conditions to avoid biases. Finally, ensuring the dataset’s accessibility and longevity for researchers is crucial to maximize its impact on the field.
Pose Estimation Net#
A Pose Estimation Net, within the context of pedestrian pre-collision pose and shape estimation from dashcam footage, would likely involve a deep learning architecture designed to process visual input (images or video frames). Its core function would be to accurately locate and identify key body joints (2D pose estimation) of pedestrians in potentially challenging scenarios (e.g., occlusions, motion blur). A crucial aspect would be the network’s ability to handle the unique challenges presented by pre-collision poses; these are rarely seen in standard pose estimation datasets, thus requiring specialized training data or techniques like transfer learning or data augmentation. Furthermore, successful 3D pose estimation would probably require the network to incorporate depth information, either directly from the input (e.g., stereo vision) or indirectly through sophisticated lifting techniques that infer 3D structure from 2D projections. Finally, the network’s architecture should be tailored to process sequences of poses (for video inputs), perhaps incorporating temporal modeling techniques like recurrent neural networks (RNNs) or transformers to capture the dynamic nature of pedestrian movements leading up to a collision. Robustness is paramount, requiring careful attention to factors like lighting conditions, camera viewpoint variations, and differing pedestrian appearances.
Pre-Collision Pose#
The concept of “Pre-Collision Pose” in pedestrian-vehicle accidents is a crucial area of study for improving safety. Accurately estimating this pose, which refers to the pedestrian’s body configuration immediately before impact, significantly influences injury severity assessments. Current methods often rely on simplified models or manual estimations from accident images, both of which lack the precision and realism needed for detailed analysis. The development of large-scale datasets specifically capturing these dynamic and often obscured poses is essential for training robust computer vision models. Dashcam footage emerges as a valuable data source, overcoming limitations of traditional methods, and enabling researchers to leverage advanced techniques like deep learning for accurate pose estimation. However, challenges remain, including the complexity of real-world scenarios (occlusions, variable lighting, etc.) and the need for sophisticated algorithms that can handle these factors. The ability to reliably predict pre-collision poses could revolutionize pedestrian safety, from informing vehicle design to enabling real-time warnings.
Dataset Limitations#
The limited size of the Pedestrian-Vehicle Collision Pose (PVCP) dataset, while the first of its kind, is a major limitation. The 40K+ accident frames and 20K+ pose annotations, though substantial, are insufficient for robust training of deep learning models. This scarcity necessitates techniques such as pre-training on larger, more general human pose datasets to avoid overfitting. The semi-automatic annotation process, while efficient, introduces potential inaccuracies and biases. Furthermore, the data’s reliance on dashcam footage leads to inherent limitations. Dashcam perspectives might not always fully capture pedestrian poses or contextual information, potentially creating ambiguity. The dataset’s focus on traffic scenes introduces limitations in generalization to other environments. Lastly, although annotations are extensive, it lacks specific information such as real camera parameters, vehicle speeds, and precise pedestrian global positions, all of which would improve the accuracy and robustness of pose estimation models.
Future Research#
The paper’s ‘Future Work’ section suggests several promising avenues for enhancing pedestrian pre-collision pose estimation. Improving one-stage methods that directly estimate 3D meshes from images is a key area, as current two-stage approaches suffer error propagation from the initial 2D pose estimation. Incorporating additional modalities, such as LiDAR data or vehicle sensor information, would likely improve accuracy and robustness, especially in complex, real-world scenarios. Addressing limitations in the current dataset is also crucial; expanding the dataset to include more diverse scenarios, pedestrian actions, and environmental conditions will be vital. Further, developing real-time pose estimation methods is essential for practical application in active safety systems. Finally, refining the pose classification to better reflect the nuances of pre-collision behavior and integrating the findings into accident reconstruction software will complete the workflow.
More visual insights#
More on figures
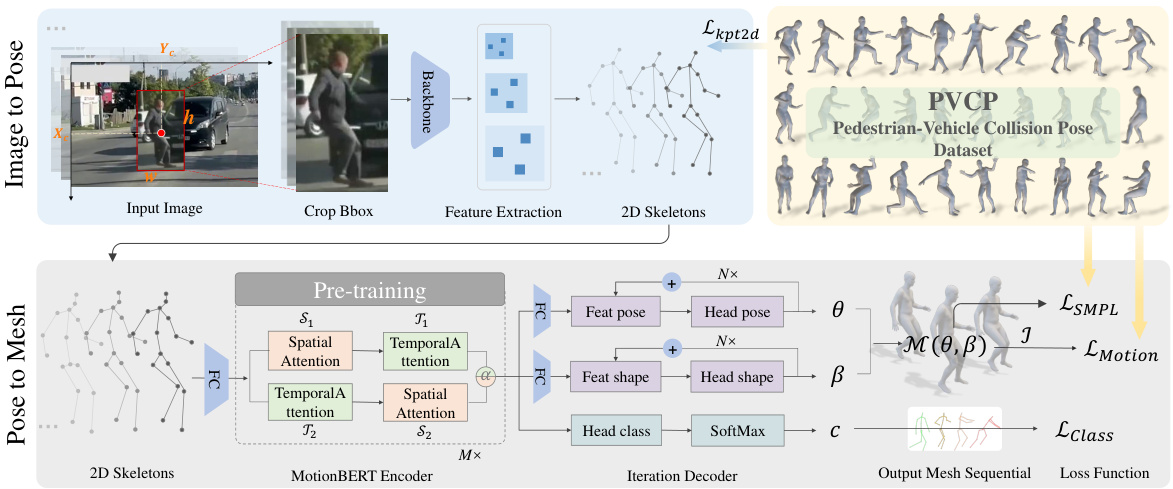
This figure presents a detailed illustration of the PPSENet architecture, a two-stage network designed for pedestrian pre-collision pose and shape estimation. The first stage, ITP (Image to Pose), takes an input image, crops a bounding box around the pedestrian, extracts features using a backbone network, and outputs 2D skeleton information. The second stage, PTM (Pose to Mesh), takes this 2D pose sequence as input, utilizes a pre-trained MotionBERT encoder to capture human pose priors, and employs an iterative regression decoder to produce 3D mesh sequences. The network incorporates spatial and temporal attention mechanisms to better handle dynamic backgrounds and occlusions. Finally, a collision pose class loss is introduced to further refine the accuracy of the pose estimation. The overall structure showcases the network’s workflow from image input to the final output of estimated 3D mesh, which represents the pedestrian’s pre-collision pose and shape sequence.

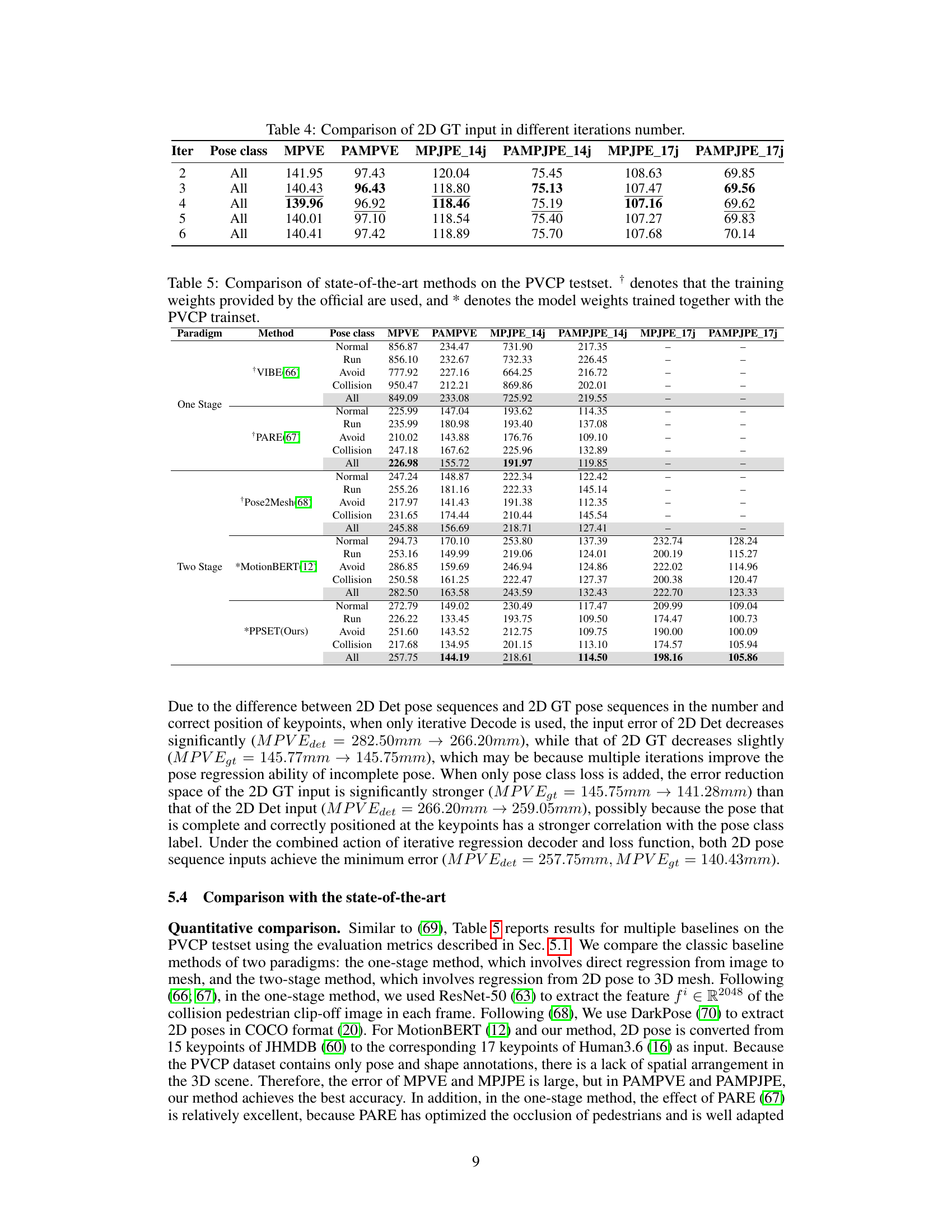
This figure shows a qualitative comparison of the proposed method with state-of-the-art (SOTA) methods on the PVCP test dataset. The left side compares the results of VIBE, PARE, Pose2Mesh, and MotionBERT with the proposed method. The right side shows output examples of the proposed method. The comparison focuses on the accuracy and realism of the estimated 3D pedestrian poses, especially for complex poses in challenging situations.

This figure shows the annotation pipeline for the PVCP dataset, the definition of pre-collision pose classes with different colors representing different poses, and the distribution of pose and shape parameters using UMAP for dimensionality reduction. The annotation pipeline illustrates the steps involved in creating the dataset, starting from raw video processing, using pose estimation and shape estimation networks, and manual correction to create final 2D, 3D, and mesh annotations. The pose class definitions show four categories: Normal, Run, Avoid, and Collision poses. The pose and shape distribution helps to visualize the characteristics of the data, showing how the pose parameters and shape parameters cluster together, and helps provide a sense of dataset balance across the different pose classes and shapes.

This figure shows the interface of the SMPL Annotation Tool used to annotate the 3D mesh of pedestrians. The left side shows the mesh before manual adjustment, while the right side shows the adjusted mesh, demonstrating the alignment of the 3D model to the image contours. The tools allow users to finely adjust pose parameters (such as rotation and shape), expression and position to precisely match the mesh to the pedestrian’s appearance in the image. This tool enables accurate generation of the ground truth pose annotations.

This figure compares the PVCP dataset with other human pose datasets such as MSCOCO, Human3.6M, PW3D, and PedX. The visualization highlights the differences in the types of scenes, actions, and backgrounds present in each dataset. PVCP focuses on pre-collision pedestrian poses in dynamic traffic environments, while the other datasets showcase more varied, typically calmer scenarios (indoor or outdoor daily activities). The goal of this visual comparison is to emphasize the uniqueness and value of PVCP for researching pedestrian pre-collision poses and improving safety systems.
This figure details the PVCP dataset annotation process, pose class definitions, and the distribution of pose and shape parameters. (a) shows the pipeline from raw video to the final annotated data, including stages like frame extraction, initial pose estimation, manual correction, and SMPL annotation. (b) illustrates the four pose classes defined in the dataset: Normal, Run, Avoid, and Collision, each represented by a distinct color. (c) visually represents the distribution of pose and shape parameters within the dataset using UMAP for dimensionality reduction, showcasing the diversity of poses.
More on tables
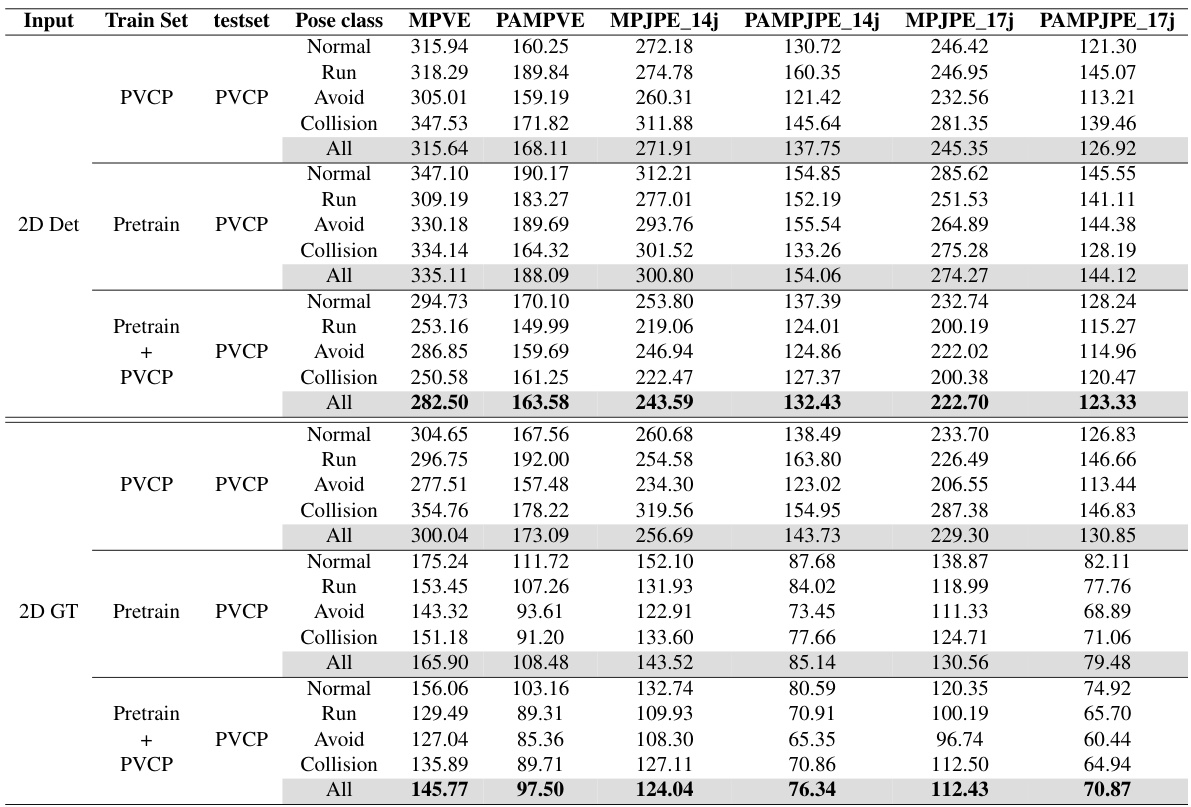
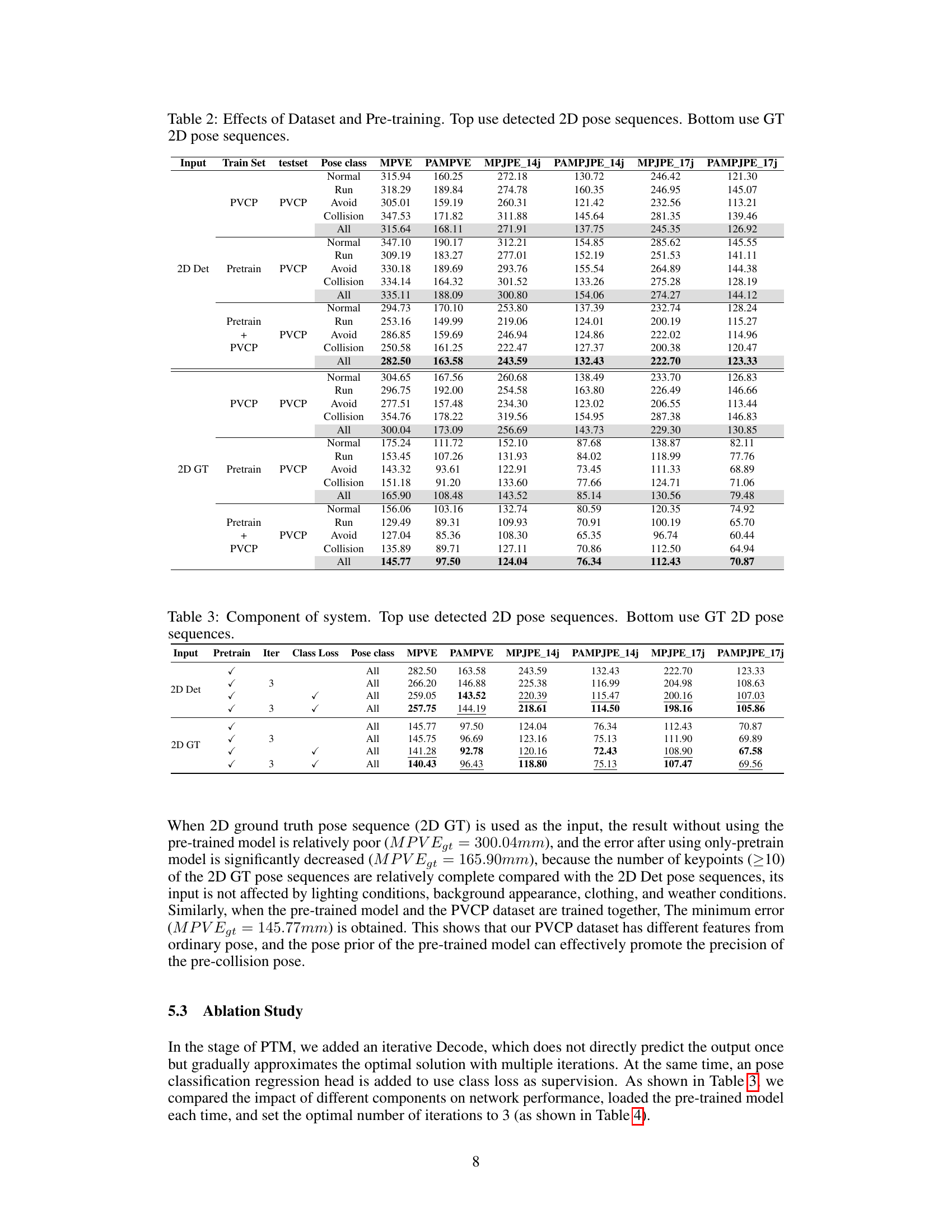
This table presents the results of experiments evaluating the effects of using different training datasets and pre-training strategies on the accuracy of pedestrian pre-collision pose estimation. It compares the performance of models trained on the PVCP dataset alone, a pre-trained model alone, and a combination of both. The results are broken down by pose class (Normal, Run, Avoid, Collision) and overall (All) for models using either detected 2D pose sequences or ground truth 2D pose sequences as input. The metrics used are MPVE, PAMPVE, MPJPE_14j, PAMPJPE_14j, MPJPE_17j and PAMPJPE_17j, all measuring the error in 3D pose estimation. The table helps demonstrate the impact of dataset size and pre-training on model performance in this challenging task.
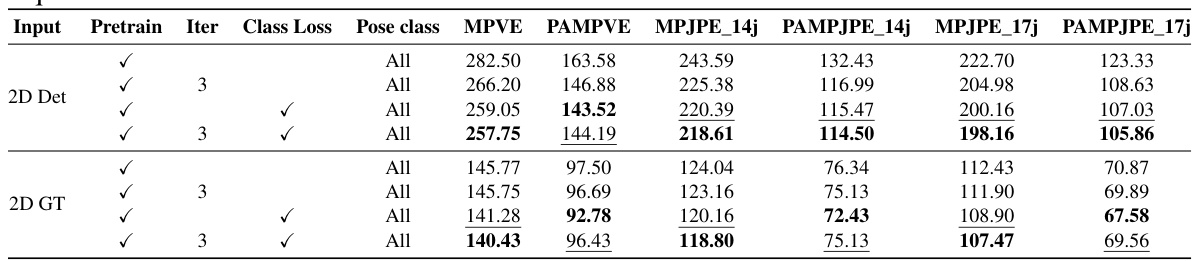
This table presents the results of experiments comparing different training setups for the pedestrian pre-collision pose estimation model. It shows the effect of using either the PVCP dataset alone or in combination with pre-training on a larger dataset. The results are broken down by pose class (Normal, Run, Avoid, Collision) and overall (All), and show metrics (MPVE, PAMPVE, MPJPE_14j, PAMPJPE_14j, MPJPE_17j, PAMPJPE_17j) for both detected and ground truth 2D pose sequences.

This table shows the effect of varying the number of iterations in the iterative decoding process of the Pose to Mesh (PTM) stage of the PPSENet model. Using ground truth 2D pose data as input, different iteration numbers (2 to 6) were tested, and the results (MPVE, PAMPVE, MPJPE_14j, PAMPJPE_14j, MPJPE_17j, PAMPJPE_17j) are reported for each iteration. The table aims to determine the optimal number of iterations for the best model performance.
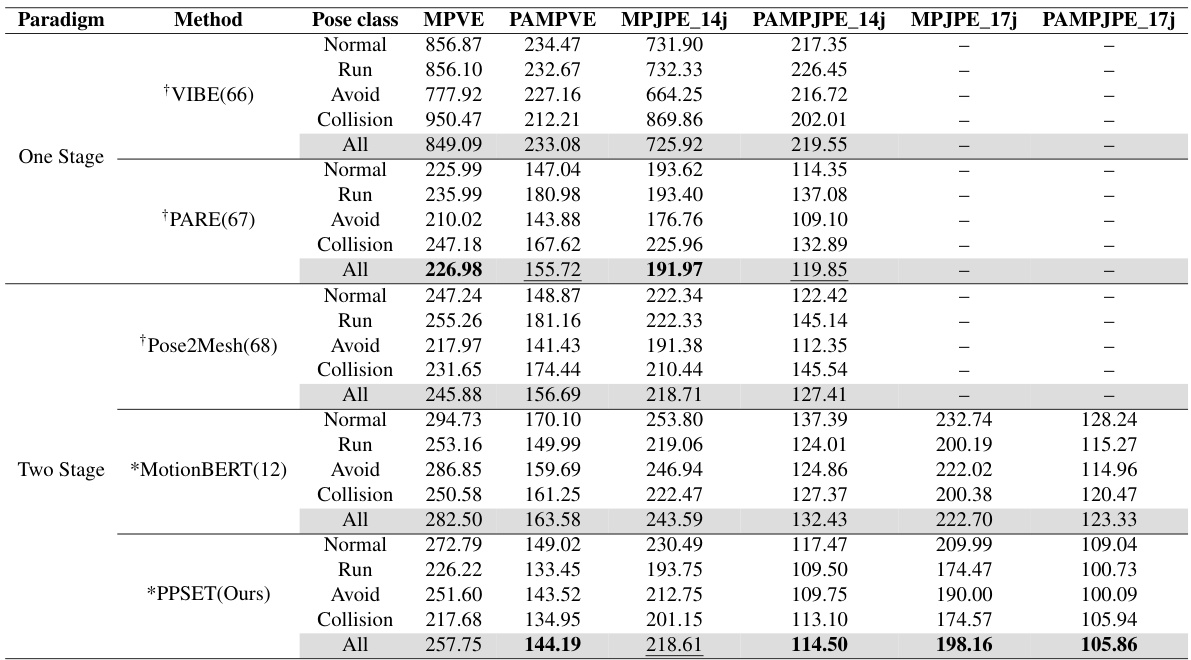
This table presents the results of experiments comparing different training setups for the pedestrian pre-collision pose estimation model. It shows the impact of using either the PVCP dataset alone, a pre-trained model alone, or both combined. The results are further broken down by the type of input used (detected 2D poses or ground truth 2D poses) and by the pre-collision pose category (Normal, Run, Avoid, Collision, and All). The metrics used for evaluation are MPVE, PAMPVE, MPJPE_14j, PAMPJPE_14j, MPJPE_17j, and PAMPJPE_17j.

This table presents the accuracy of the Image to Pose (ITP) network for each of the seven joints (Head, Shoulder, Elbow, Wrist, Hip, Knee, and Ankle) and the mean accuracy across all joints. The accuracy is measured using the Percentage of Correct Keypoints (PCK) metric, which indicates the percentage of correctly detected keypoints. The results show the ITP network’s performance on the test set, revealing relatively lower accuracy for the Ankle joint due to frequent occlusions during collisions.

This table presents the results of pedestrian pre-collision pose estimation experiments using different training datasets and methods. It compares the performance of models trained using only the PVCP dataset, a pre-trained model, and a combination of both. The top half shows results using detected 2D pose sequences as input, and the bottom half shows results using ground truth (GT) 2D pose sequences. Multiple metrics (MPVE, PAMPVE, MPJPE_14j, PAMPJPE_14j, MPJPE_17j, PAMPJPE_17j) are used to evaluate the accuracy of 3D pose and shape estimation for different pose classes (Normal, Run, Avoid, Collision) and overall.

This table presents the results of experiments comparing the effects of using different training datasets and pre-training models on the accuracy of pedestrian pre-collision pose estimation. The top half shows results using detected 2D pose sequences as input to the model, while the bottom half uses ground truth (GT) 2D pose sequences. The table allows comparison of performance metrics across different pose classes (Normal, Run, Avoid, Collision) and the overall performance (All). This allows for the assessment of the relative contributions of the PVCP dataset and pre-training to the model’s performance.

This table presents the results of pedestrian pre-collision pose estimation experiments comparing different training setups. It shows the impact of using the PVCP dataset alone versus using a pre-trained model and fine-tuning on PVCP. The metrics used to evaluate performance are MPVE, PAMPVE, MPJPE_14j, PAMPJPE_14j, MPJPE_17j, and PAMPJPE_17j. The table is divided into sections based on the training set used (PVCP, pre-trained, or both) and the input data type (detected 2D poses or ground truth 2D poses). Each section displays the results for different pose classes (Normal, Run, Avoid, Collision) as well as an overall average for all poses.
Full paper#