↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement learning (RL) often struggles with reward specification, especially in robotics. Existing methods using Optimal Transport (OT) to learn rewards from expert demonstrations often ignore temporal order, leading to noisy reward signals and inefficient learning. This limits RL’s real-world applicability due to the difficulty and cost of manual reward design.
This paper introduces Temporal Optimal Transport (TemporalOT), a new method that addresses the limitations of existing OT-based reward approaches. By incorporating temporal order information using context embeddings and a masking mechanism, TemporalOT generates a more accurate and informative proxy reward, leading to improved policy learning. Experiments on Meta-World benchmark tasks demonstrated TemporalOT’s superior performance compared to existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is significant because it tackles the challenge of reward specification in robot reinforcement learning, a crucial bottleneck in real-world applications. By introducing Temporal Optimal Transport, it improves reward signal accuracy and learning efficiency, potentially accelerating progress in robotics and other RL domains. The proposed method is especially valuable for scenarios with limited expert demonstrations, a common constraint in real-world robotics. Further research could explore diverse applications and refinements of this approach.
Visual Insights#

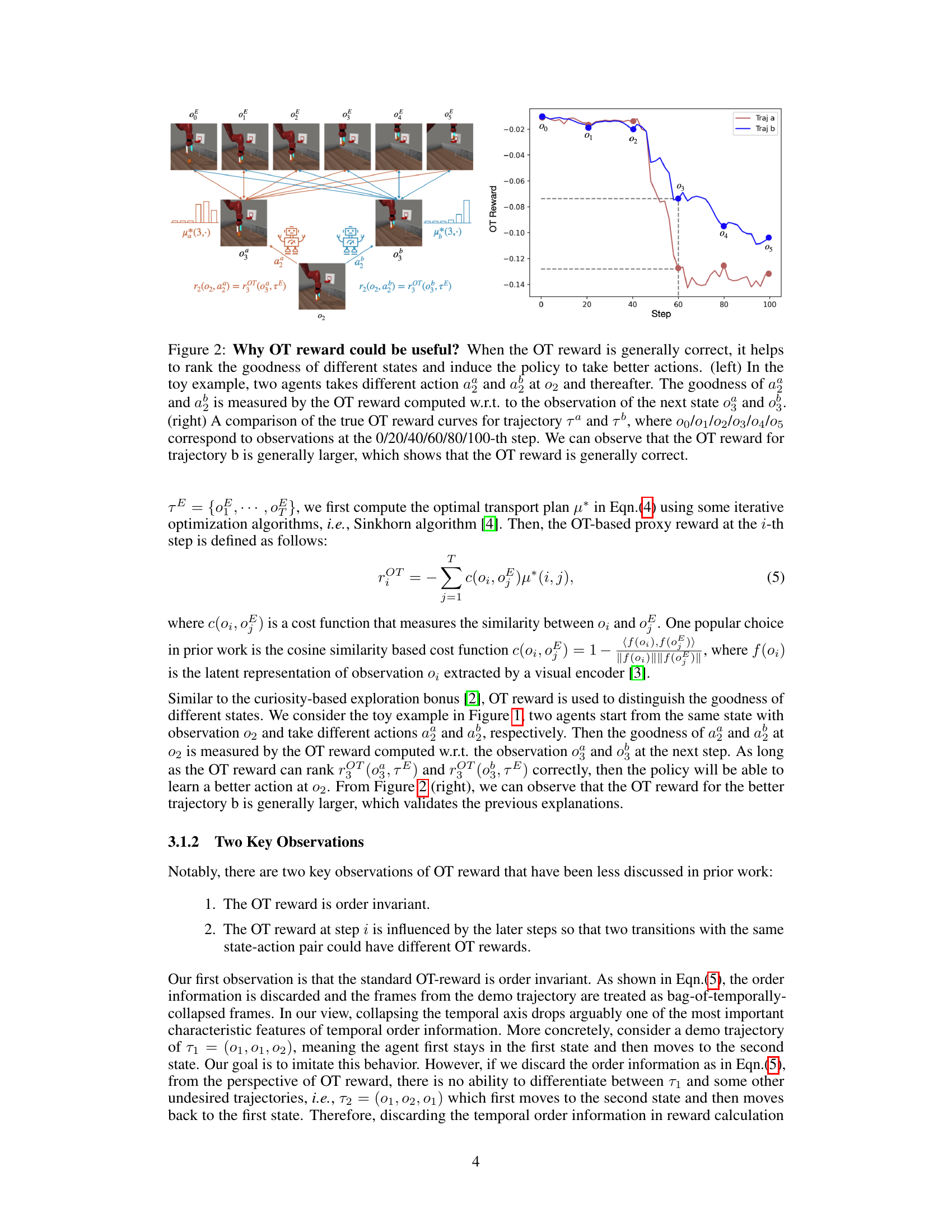
This figure illustrates how the Optimal Transport (OT)-based reward is calculated in Reinforcement Learning (RL). Two agent trajectories are compared to an expert trajectory. Even with identical initial state-action pairs, differences in subsequent actions lead to different OT rewards, highlighting the method’s sensitivity to the entire trajectory and not just individual state-action pairs. This difference is crucial to the TemporalOT method’s goal of incorporating temporal context.

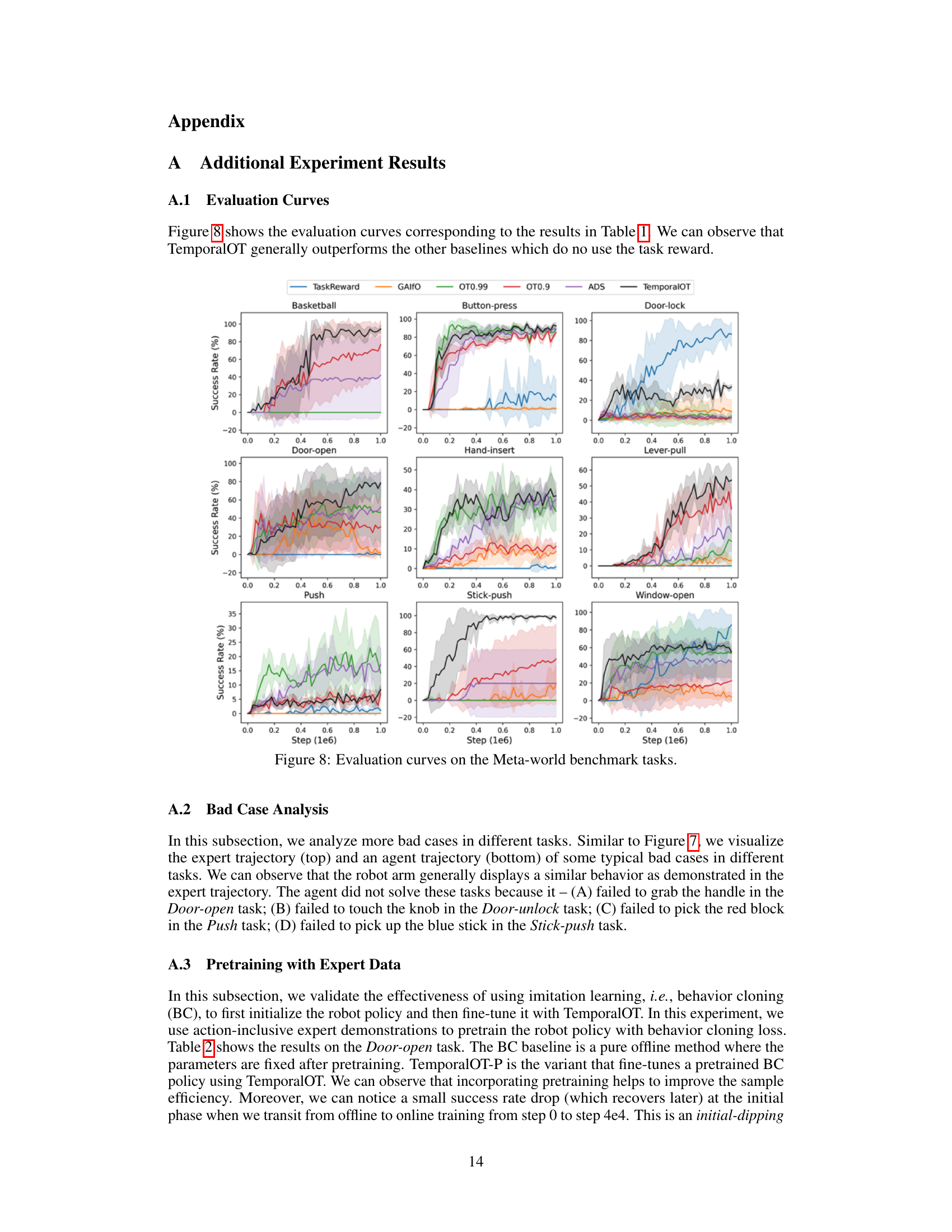
This table presents the success rates achieved by different methods on various tasks within the Meta-world benchmark. The methods include TaskReward (using the ground truth reward), Behavior Cloning (BC), Generative Adversarial Imitation Learning (GAIfO), Optimal Transport reward with different discount factors (OT0.99 and OT0.9), Adaptive Discount Scheduling (ADS), and the proposed TemporalOT method. The results highlight the performance improvements of the TemporalOT method compared to existing approaches, particularly in achieving higher success rates without relying on ground truth rewards. Success rates are expressed as mean (standard deviation).
In-depth insights#
TemporalOT Reward#
The proposed Temporal Optimal Transport (TemporalOT) reward method is a significant advancement in robot policy learning from demonstrations. It directly addresses a crucial weakness of existing OT-based reward methods: their invariance to temporal order. By incorporating temporal order information via context embeddings and a masking mechanism, TemporalOT generates a significantly more accurate proxy reward. This results in improved policy learning, as demonstrated by experiments. The use of context embeddings refines the cost function by considering neighboring observations, enhancing accuracy, while the masking mechanism focuses the reward on temporally relevant segments, reducing noise. The effectiveness of both components is validated through ablation studies. TemporalOT’s superior performance over existing state-of-the-art (SOTA) methods underscores the importance of considering temporal dynamics when constructing proxy rewards for imitation learning. Future work could explore more sophisticated masking strategies and extensions to handle various data modalities.
OT Reward Limits#
The heading ‘OT Reward Limits’ suggests an analysis of the shortcomings inherent in using Optimal Transport (OT) to generate reward functions in reinforcement learning. A thoughtful exploration would likely cover two main aspects: temporal limitations and representational limitations. Temporal limitations arise because standard OT methods are insensitive to the temporal ordering of events within a trajectory. This invariance to temporal dynamics can lead to inaccurate or misleading reward signals, hindering the learning process. Representational limitations, on the other hand, relate to how well the chosen cost function in the OT framework captures the relevant aspects of the task. If the representation used to compare agent and expert trajectories is inadequate, the OT-based reward may fail to distinguish between successful and unsuccessful actions, ultimately limiting the effectiveness of the approach. Therefore, a discussion of ‘OT Reward Limits’ necessitates an in-depth consideration of these representational and temporal constraints, suggesting potential solutions and improvements could involve incorporating temporal context, using more informative representations, and exploring more sophisticated cost functions beyond simple distance metrics.
Contextual Cost#
The concept of “Contextual Cost” in a machine learning model, particularly within the context of reinforcement learning, suggests a cost function that’s not solely based on immediate state-action pairs but also incorporates surrounding context. This contextual information could significantly enrich the learning process by providing a more nuanced understanding of the task’s dynamics. Instead of evaluating an action’s cost in isolation, a contextual cost considers the broader temporal and spatial context, such as preceding actions, future goals, and environmental factors. This approach is particularly beneficial in scenarios with complex state spaces and partial observability, where a simple cost function might lead to suboptimal policies. By weighting the cost based on relevant context, the model can learn more robust and efficient behaviors that better adapt to complex situations. Effective implementation requires careful selection of contextual features and appropriate weighting mechanisms. An ill-defined contextual cost could add noise or complexity without improving performance. The choice of features depends on the task, and careful design and experimental validation are crucial to ensure that the contextual information indeed contributes positively to learning. The added complexity of contextual costs might impact computational efficiency, requiring careful consideration of the trade-off between accuracy and computational resources. The benefits of a contextual cost are especially significant when dealing with ambiguous or noisy reward signals. In such cases, the contextual information can help disambiguate the desired behavior and provide a more stable learning signal.
Meta-world Results#
A hypothetical ‘Meta-world Results’ section would likely present quantitative evaluations of a reinforcement learning (RL) agent’s performance across various Meta-World benchmark tasks. Key metrics would include success rates, showing the percentage of successful task completions, possibly broken down by individual task or categorized by difficulty. Average success rates across all tasks would provide an overall performance summary. Additionally, the results might include learning curves, illustrating the agent’s performance improvement over training iterations, demonstrating sample efficiency. Comparing these results against other state-of-the-art (SOTA) methods would highlight the proposed approach’s strengths and weaknesses. Ablation studies, systematically removing components of the proposed method, would reveal each component’s contribution to overall performance. Finally, the discussion should acknowledge limitations, such as sensitivity to hyperparameter settings or reliance on the quality of expert demonstrations. Visualizations or tables should present these results clearly and concisely, facilitating easy interpretation and comparison.
Future Work#
Future research directions stemming from this work on robot policy learning with Temporal Optimal Transport reward could explore several promising avenues. Extending the method to handle more complex scenarios, such as those with partial observability or longer temporal dependencies, is crucial for real-world applicability. Investigating alternative cost functions within the Optimal Transport framework could enhance robustness and accuracy. Incorporating other modalities, like tactile or force sensors, in addition to visual data, would provide a more comprehensive understanding of the robot’s interaction with its environment, leading to improved policy learning. A thorough comparative analysis against a broader range of imitation learning techniques, including those leveraging different reward shaping strategies or model-based approaches, is needed to establish the proposed method’s true strengths and limitations. Addressing the sample complexity remains a key challenge for reinforcement learning. Further exploration of efficient data augmentation strategies, or the potential of transfer learning across tasks, could significantly boost the overall performance. Finally, developing robust safety mechanisms is vital before deployment in real-world scenarios, especially given the potential for unintended behavior arising from limited or biased expert demonstrations.
More visual insights#
More on figures

This figure demonstrates how the Optimal Transport (OT) reward helps in reinforcement learning. The left panel shows a simplified example with two agents taking different actions, resulting in different OT rewards. The right panel displays a graph illustrating the OT reward over time for two different trajectories. The higher OT reward for one trajectory indicates its superiority, showcasing how OT reward effectively ranks state-action pairs, guiding the learning process to select better actions.

This figure illustrates the TemporalOT method’s pipeline. The left side shows how a group-wise cosine similarity, calculated by averaging the cosine similarity between observations within a context window, is used to create a more accurate cost matrix for optimal transport. The right side demonstrates the use of a temporal mask to focus the OT reward calculation on a narrower time window, reducing the influence of temporally distant observations and improving the quality of the reward signal. This is a key improvement over traditional OT-based reward methods which ignore temporal context.
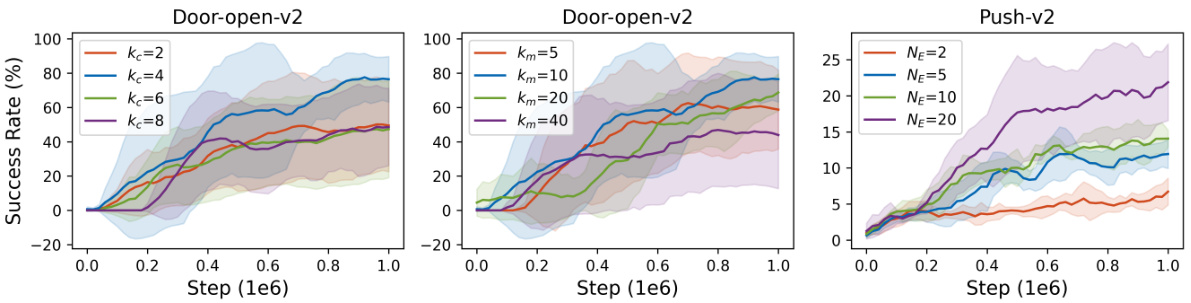
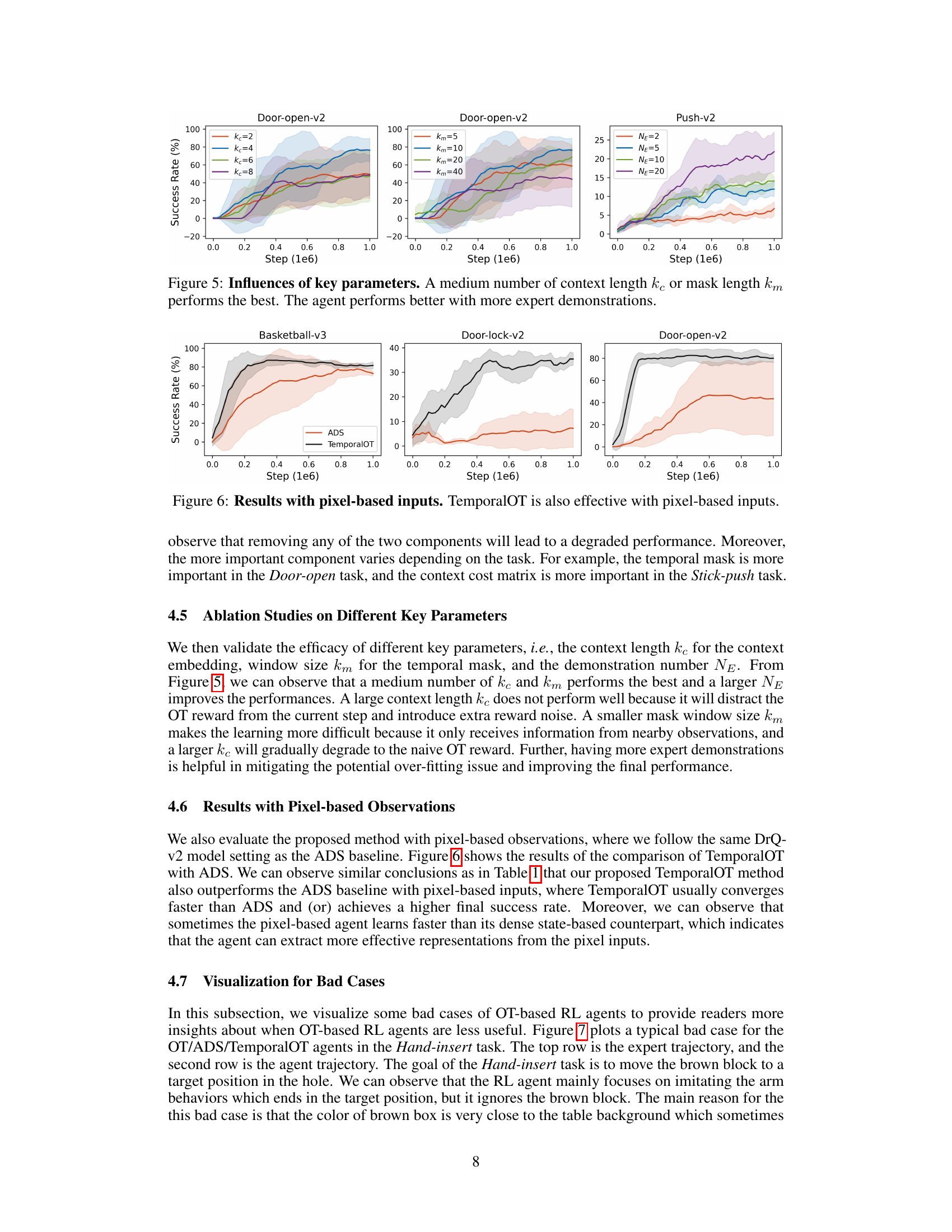
This figure presents the ablation study on the influence of key parameters in the TemporalOT model. The study varied the context length (𝑘𝑐) and mask length (𝑘𝑚) parameters to observe their impact on the model’s performance. The results show that a medium value for both 𝑘𝑐 and 𝑘𝑚 leads to the best performance. The number of expert demonstrations (𝑁𝐸) also had a positive effect, with more demonstrations leading to better results.

This figure displays ablation studies on the proposed TemporalOT method. It shows the success rate curves for three different configurations of the model: using both the context embedding-based cost matrix and the temporal mask (TemporalOT), using only the context embedding-based cost matrix (no-mask), and using only the temporal mask (no-context). The results demonstrate that both proposed components are beneficial to the overall performance and contribute to improved performance compared to using either component alone.

This figure shows a comparison between an expert trajectory and the trajectory of an agent trained using the proposed TemporalOT method. The expert successfully grasps a brown block and places it into a designated hole. However, the agent imitates only the arm movement from the expert trajectory and fails to grasp the block. This illustrates a failure case for the method, highlighting potential issues where subtle details are missed during training, particularly when a pretrained visual encoder struggles to capture subtle information. The caption notes additional examples are available in Appendix A.2.
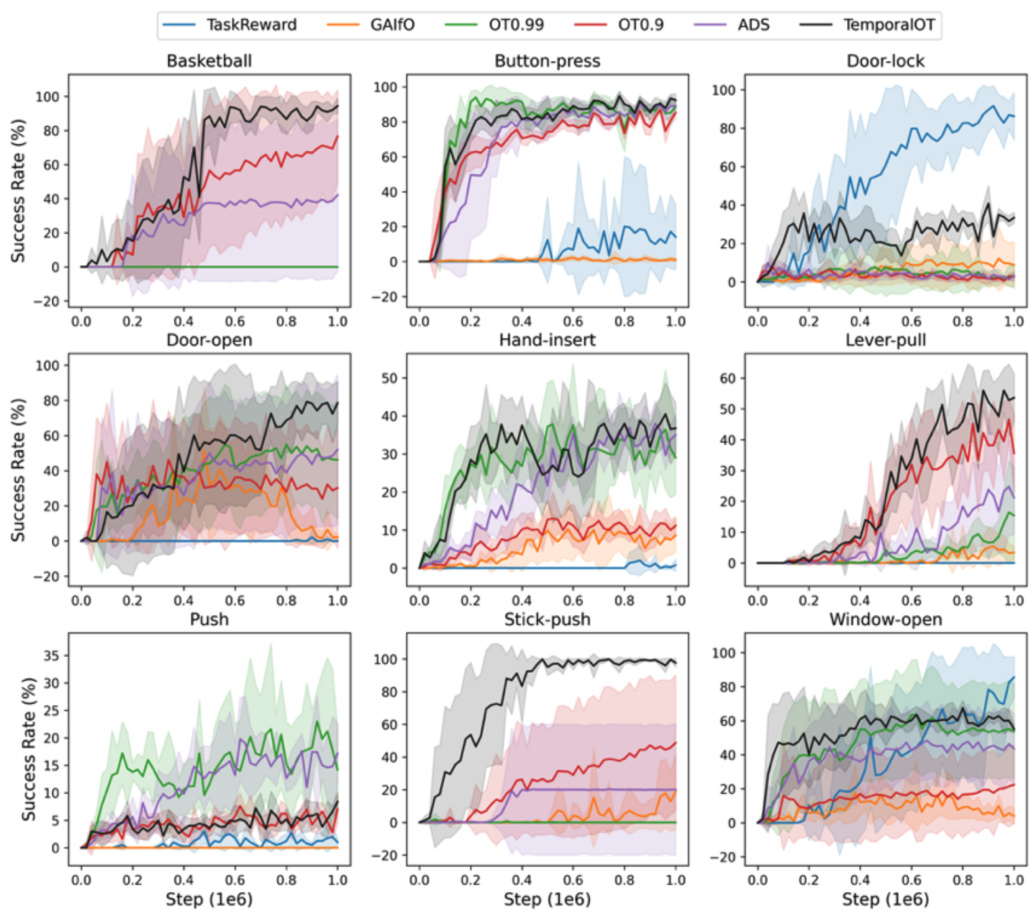
This figure presents the success rate curves for nine Meta-world benchmark tasks across different algorithms: TaskReward, GAIFO, OT0.99, OT0.9, ADS, and TemporalOT. Each curve represents the average success rate across multiple random seeds, and shaded areas show the standard deviations. The graph visually compares the performance of the proposed TemporalOT method against existing baselines over time (training steps). It allows for a direct comparison of how quickly and effectively each algorithm learns to successfully complete each task.

This figure illustrates the two main improvements in the Temporal Optimal Transport (TemporalOT) method. The left side shows how a group-wise cosine similarity is used to improve the accuracy of the cost matrix, compared to the pairwise cosine similarity used in previous methods. The right side illustrates the use of a temporal mask to improve the focus of the OT reward, preventing distractions from observations that are too far in the past or future.
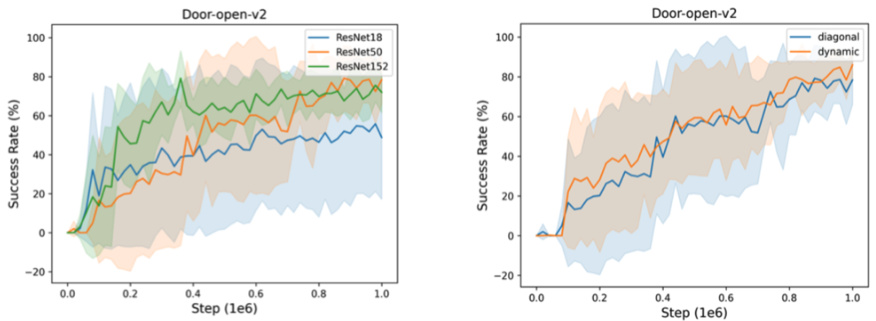
This figure presents the ablation study results for different visual encoders (ResNet18, ResNet50, ResNet152) and different mask designs (diagonal and dynamic). The left panel shows that ResNet50 and ResNet152 achieve similar performance, while ResNet18 underperforms, indicating the importance of a sufficiently powerful visual encoder for extracting relevant features. The right panel compares the performance of using a diagonal temporal mask (as in the main method) versus a dynamic temporal mask. The dynamic mask, which adapts to the specific trajectory, provides a slight performance improvement.
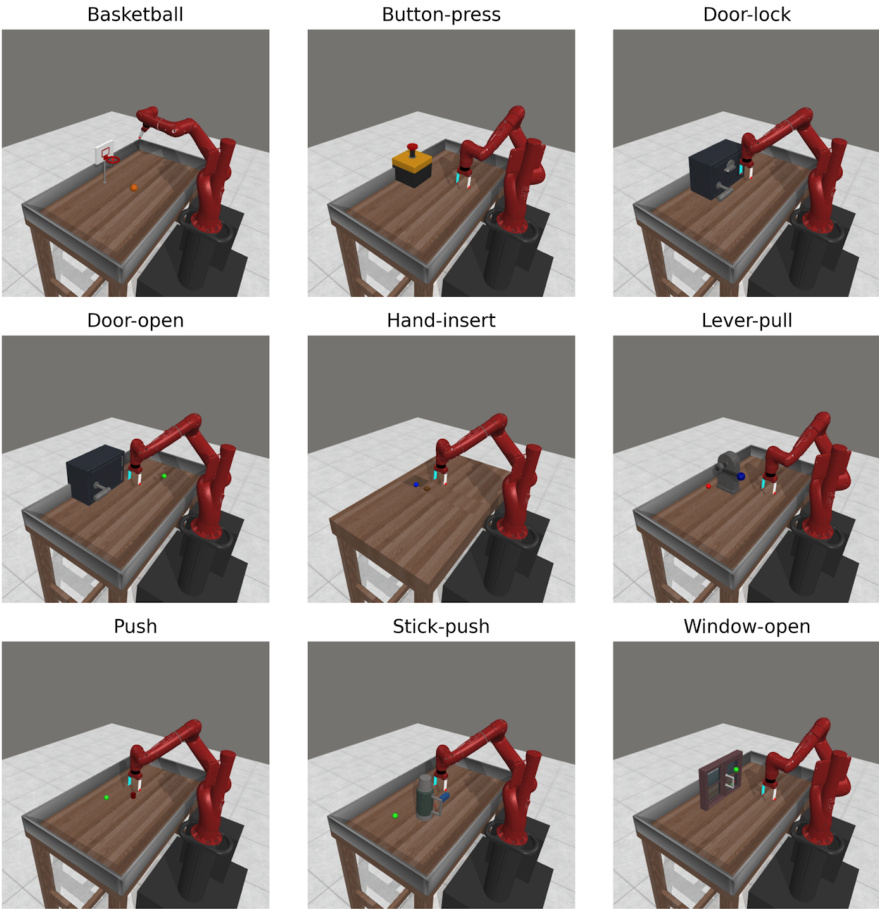
This figure shows screenshots of the nine Meta-world tasks used in the paper’s experiments. Each image depicts a robotic arm in a simulated environment, ready to perform a specific manipulation task. The tasks are: Basketball, Button-press, Door-lock, Door-open, Hand-insert, Lever-pull, Push, Stick-push, and Window-open. The screenshots illustrate the diversity of manipulation skills tested in the experiments.
More on tables

This table presents the ablation study results on the effectiveness of using imitation learning (behavior cloning, BC) to pre-train the robot policy before fine-tuning with TemporalOT. It compares the success rate (%) of three methods: BC (pure offline behavior cloning), TemporalOT (online Temporal Optimal Transport RL), and TemporalOT-P (online Temporal Optimal Transport RL with pre-training). The success rate is measured at different training steps (0, 2e4, 4e4, 6e4, 8e4, 1e5, 5e5, 1e6), showing the improvement in sample efficiency provided by the pretraining step.
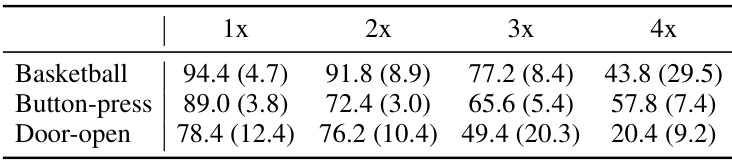
This table shows the success rates for different tasks (Basketball, Button-press, Door-open) when training with expert demonstrations at different speeds (1x, 2x, 3x, 4x). The numbers in parentheses represent the standard deviation. The results demonstrate how the performance is affected when the expert demonstrations are sped up or slowed down, indicating the influence of temporal consistency on model performance.

This table presents the success rates achieved by different methods on various tasks within the Meta-world benchmark. The methods compared include TaskReward (using the ground truth reward), BC (Behavior Cloning), GAIFO (Generative Adversarial Imitation from Observation), OT (Optimal Transport reward with discount factor 0.99), OT (Optimal Transport reward with discount factor 0.9), ADS (Adaptive Discount Scheduling), and TemporalOT (the proposed method). Success rate is the percentage of successful trials out of 100 attempts. The results show TemporalOT outperforms other baselines in most tasks without using the ground truth reward.
Full paper#