↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large vision-language models (LVLMs) often struggle with up-to-date information due to infrequent updates. This paper addresses this limitation by proposing a novel framework, SearchLVLMs. The core problem is that LVLMs are trained on massive datasets that cannot be constantly updated. This makes them unable to answer questions requiring information generated after their training. The challenge is to incorporate new information without retraining the entire model which is computationally expensive and time-consuming.
SearchLVLMs tackles this challenge by using a hierarchical filtering model to efficiently retrieve and filter relevant information from the internet, specifically focusing on visual question answering (VQA). The model first filters websites based on titles and snippets, then selects the most informative content segments from the chosen websites. This filtered information is then used to prompt the LVLM, improving its ability to answer questions about recent events. The paper also introduces a new dataset, UDK-VQA, specifically designed for testing models on up-to-date knowledge which further enhances the value of this work.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large vision-language models (LVLMs) and retrieval-augmented generation (RAG). It introduces a novel framework to tackle the limitations of LVLMs in handling up-to-date information, bridging the gap between static LVLMs and dynamic internet knowledge. The proposed framework and dataset are valuable resources, opening avenues for further investigation in improving LVLMs’ capabilities to process real-time information.
Visual Insights#
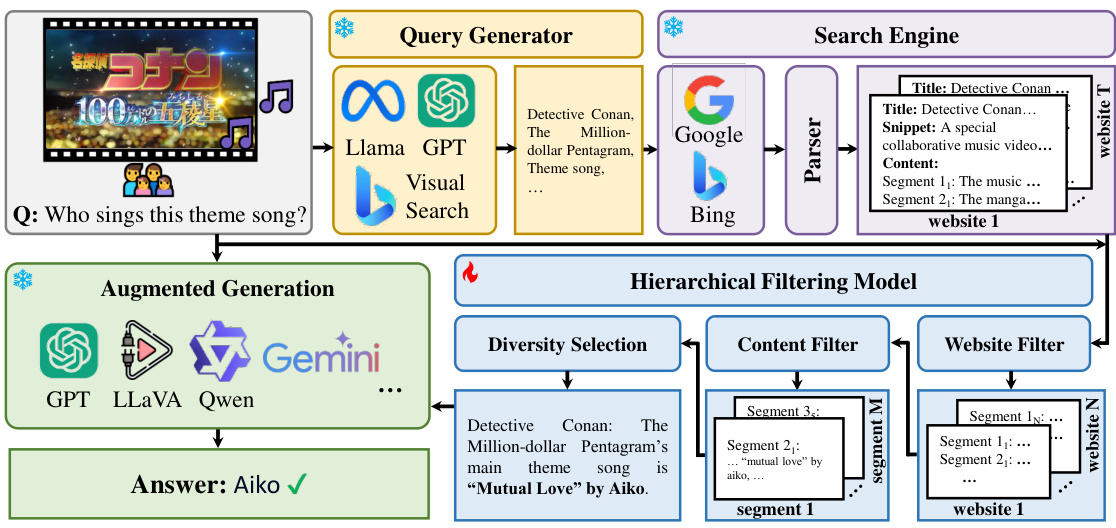
This figure illustrates the SearchLVLMs framework, designed to equip Large Vision-Language Models (LVLMs) with access to current internet knowledge. The framework starts with a Query Generator that extracts relevant search terms from a question about an image. These terms are fed into search engines (Google and Bing), and the results are parsed to extract website titles, snippets, and content. A Hierarchical Filtering Model, consisting of a Website Filter and a Content Filter, then processes this information to select the most relevant content. This filtered content is finally used to augment the LVLMs (like GPT, Llama, and Gemini) for improved answer generation. The example shown involves answering a question about the singer of a theme song using visual information and internet search.
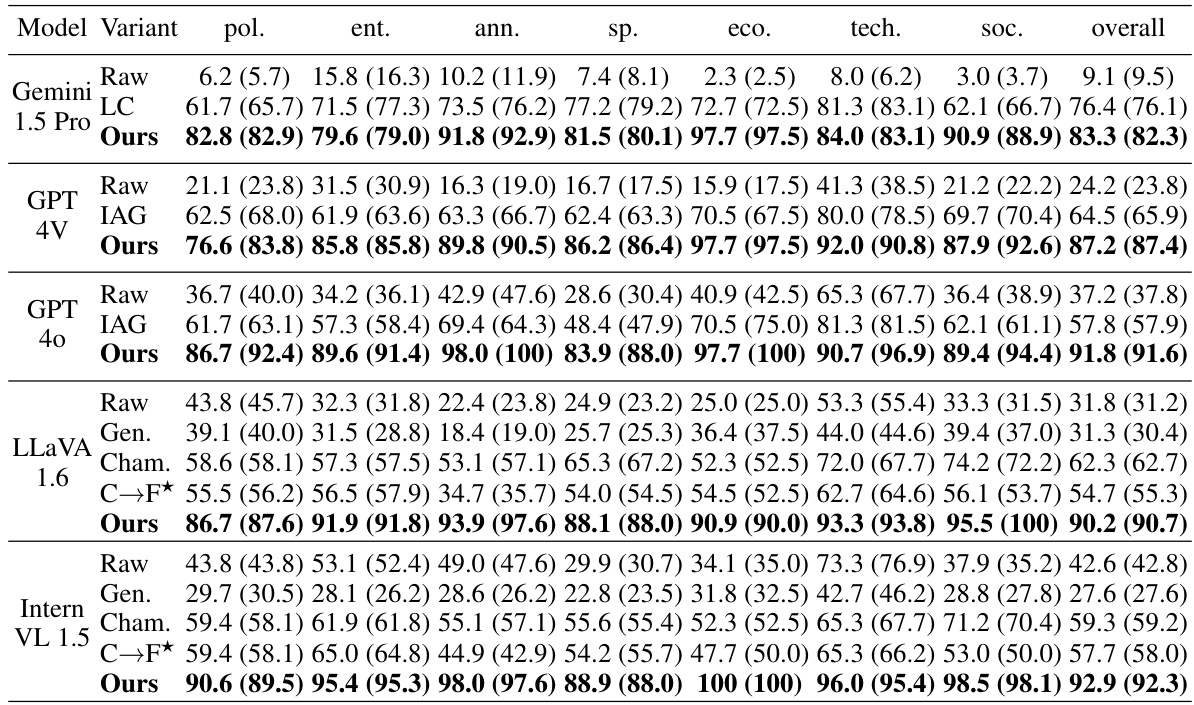
This table compares the performance of various Large Vision-Language Models (LVLMs) on the UDK-VQA dataset. It shows a comparison of raw model performance, models with internet-augmented generation (IAG), models with long contexts, and models using the proposed SearchLVLMs framework. The results are broken down by category and overall accuracy, highlighting the improvements achieved by incorporating the SearchLVLMs framework.
In-depth insights#
IAG Framework#
An IAG (Internet-Augmented Generation) framework enhances large vision-language models (LVLMs) by incorporating real-time internet searches. This addresses LVLMs’ limitations in accessing up-to-date information, a crucial aspect for accurate and relevant responses. The framework likely involves several key components: a query generation module to formulate effective search queries; a search engine interface to retrieve relevant web pages; a filtering mechanism to select the most pertinent content from potentially large amounts of retrieved text; and finally, an integration module to feed this filtered content to the LVLMs for improved response generation. The effectiveness of the framework hinges on the efficacy of the filtering stage, as irrelevant or low-quality information can degrade LVLMs’ performance. A hierarchical filtering model, trained on relevant data, is likely employed for efficient and accurate content selection. The success of such a framework depends heavily on efficient query design to target relevant information and robust filtering to handle noise and irrelevant content. Furthermore, integration with diverse LVLMs requires consideration of varying input formats and prompt structures. The overall architecture must be designed for speed and efficiency, particularly given the need for real-time web access. This IAG framework represents a significant advance in augmenting LVLM capabilities and increasing their usefulness in real-world applications.
UDK-VQA Dataset#
The UDK-VQA dataset, a crucial component of the SearchLVLMs framework, addresses the limitations of existing large vision-language models (LVLMs) by focusing on up-to-date knowledge. Instead of relying on static datasets, UDK-VQA is dynamically generated using a novel pipeline. This pipeline leverages current news and search trends to create visual question answering (VQA) pairs relevant to recent events, ensuring the dataset’s timeliness. The automatic generation process involves several steps: identifying trending topics, scraping relevant news, segmenting content, generating VQA pairs using LLMs, and associating images. This automated approach is highly innovative and is key to UDK-VQA’s relevance. A multi-model voting mechanism is employed to label the data, contributing to a more robust training set for the hierarchical filtering model within the SearchLVLMs framework. The dataset’s structure includes training and test sets, with the test set further refined via manual screening to ensure accuracy and relevance. The UDK-VQA dataset is a significant contribution because it directly tackles the challenge of keeping LVLMs current, enabling a more practical and effective framework.
Hierarchical Filtering#
Hierarchical filtering, in the context of augmenting large vision-language models (LVLMs) with up-to-date internet knowledge, is a crucial mechanism for efficiently managing the vast amount of information retrieved from web searches. It addresses the challenge of LVLMs struggling with long context inputs, by employing a two-step process. First, a website filter screens retrieved websites based on titles and snippets, prioritizing those most relevant to the query. Second, a content filter further refines the information by selecting the most helpful segments within the chosen websites. This hierarchical approach not only improves efficiency but also enhances accuracy by focusing the LVLMs on the most pertinent information, leading to better responses to questions requiring current knowledge. The effectiveness of this filtering is directly tied to the quality of the training data, which should include relevance scores for both websites and content segments, necessitating careful dataset construction to accurately reflect the usefulness of various sources.
Ablation Studies#
Ablation studies systematically assess the contribution of individual components within a complex system. In the context of a research paper, this involves removing or altering parts of a model or method to understand their impact on overall performance. Thoughtful design of ablation experiments is crucial, carefully selecting which aspects to remove and considering potential interactions. For instance, if a model uses multiple modules, successively removing each module reveals its isolated effect and the extent of its contribution to the final result. The results highlight the relative importance of each component, and can guide future model development. A well-conducted ablation study, therefore, provides insights into the model’s strengths and weaknesses and offers valuable information for future improvements and refinements. Analyzing the results can inform decisions about architectural modifications, or whether to incorporate alternative methods or techniques to achieve better results. The thoroughness of the ablation study and the clarity with which the results are explained directly impact the paper’s overall value and credibility.
Future Work#
Future work in this research could explore several promising directions. Improving the hierarchical filtering model is crucial; exploring more advanced techniques like transformer-based models or incorporating external knowledge graphs could significantly enhance its accuracy and efficiency. Expanding the dataset is another key area; including more diverse visual data types and question categories would make the framework more robust and widely applicable. Additionally, research into more sophisticated query generation methods is necessary; leveraging techniques like few-shot prompting or reinforcement learning to produce more targeted and effective queries for diverse search engines would improve the system’s overall performance. Finally, investigating the potential of multi-modal reasoning models that integrate vision and language more seamlessly could unlock more advanced capabilities. These improvements could lead to a more accurate and efficient framework, broadening its applicability across various domains and LVLMs.
More visual insights#
More on figures

This figure illustrates the pipeline for automatically generating news-related visual question answering (VQA) samples for the UDK-VQA dataset. It begins with query collection from Google Daily Search Trends and manual sources. These queries are used to search for and parse relevant news articles using Google and Bing. The text is segmented, and GPT-3.5 generates question-answer pairs, an entity is extracted and replaced with its hypernym to create VQA questions. Bing Image Search finds images, and clustering reduces outliers. Finally, a multi-model voting mechanism assigns pseudo-scores for training the filtering model. Manual screening creates the test set, ensuring data quality and avoiding training-test overlap. Queries from different time periods generate samples from different periods, preventing data leakage.

This figure illustrates the SearchLVLMs framework. It shows the process of using a query generator to extract queries from a question and image, then using a search engine to find relevant websites. A hierarchical filtering model is used to efficiently select the most helpful content from these websites. Finally, this filtered content is used to prompt large vision-language models (LVLMs) for augmented generation, enhancing their ability to answer questions using up-to-date knowledge.

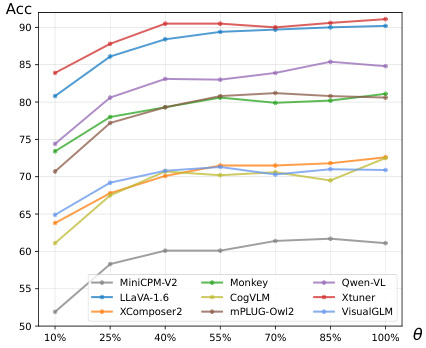
This radar chart visualizes the performance of different Large Vision-Language Models (LVLMs) when using various methods for generating pseudo-scores during the training of a hierarchical filtering model. The models are arranged around the perimeter, with their accuracy scores represented by the radial distance from the center. The different pseudo-score generation methods are represented by different colored lines. The chart allows for a comparison of model performance across different pseudo-score strategies, showing which models benefit most from each approach. The shaded area represents the range of accuracy achieved by various models using each method.

This figure shows examples of training and test samples used in the UDK-VQA dataset. The training samples (a) demonstrate the question-answer pairs generated, showing a title, snippet, and selected segment from the news articles for training the hierarchical filtering model. The test samples (b) showcase examples of how questions are constructed and presented along with their answers, which include both correct and incorrect options. Part (c) provides a statistical breakdown of categories in the UDK-VQA test set, visualizing the distribution of various news categories, such as entertainment, politics, sports, and technology.
This figure visualizes examples of training and test samples used in the UDK-VQA dataset, highlighting the diversity of questions and images. It also shows the distribution of categories in the test set, indicating the balance and representativeness of the dataset.

This figure shows the overall pipeline for automatically generating news-related VQA samples for the UDK-VQA dataset. It details the steps involved, starting with query collection from Google Daily Search Trends and manual searches, followed by question generation using GPT-3.5, image retrieval and clustering using Bing Image Search, pseudo-score generation using multiple LVLMs, and finally manual screening for test set quality assurance. The pipeline aims to create VQA samples that require both visual and textual understanding of up-to-date information.
More on tables
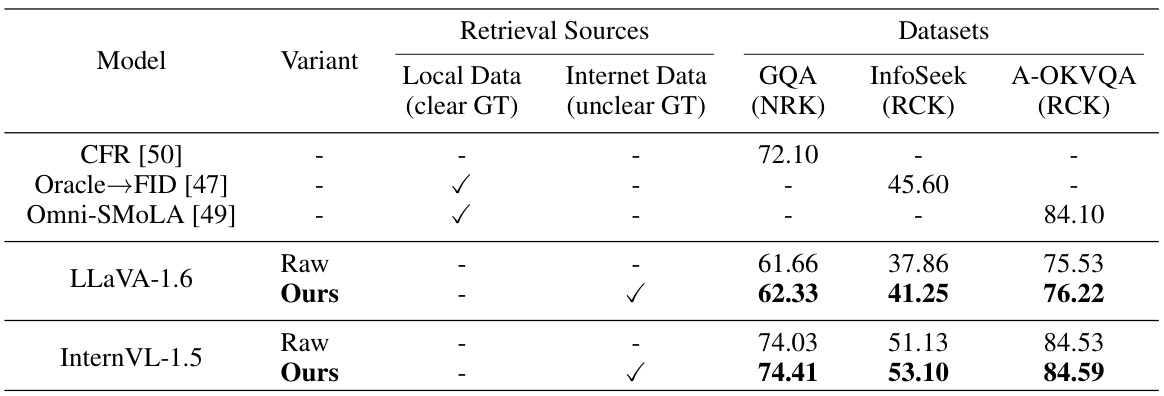
This table compares the performance of different Large Vision-Language Models (LVLMs) on three different datasets: GQA, InfoSeek, and A-OKVQA. The datasets are categorized based on whether they rely on external knowledge (NRK - No external knowledge, RCK - Rely on commonsense knowledge). The table shows the performance of each model with and without the proposed SearchLVLMs framework. It helps demonstrate the framework’s generalizability beyond up-to-date knowledge.

This table presents the ablation study results evaluating the impact of different components of the SearchLVLMs framework on the UDK-VQA dataset. It shows the performance gains achieved by incorporating each component, comparing against a baseline (Raw) and other simplified IAG methods. The components analyzed include the hierarchical filtering model (using different LLMs), the question query generator (with various methods such as NER, LLAMA3, GPT-3.5), and the image query generator (using Bing Visual Search). The table highlights the effectiveness of each component and demonstrates the synergistic effect of combining them within the proposed framework.
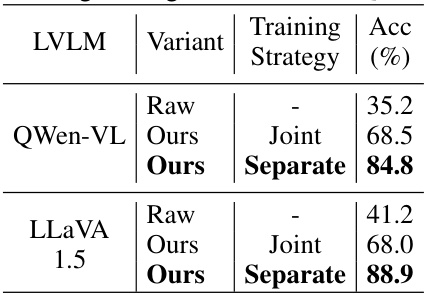
This table presents the results of experiments conducted to evaluate different training strategies for the hierarchical filtering model within the SearchLVLMs framework. It compares the performance of using a joint training strategy (training the LVLMs and the hierarchical filtering model simultaneously) versus a separate training strategy (training the hierarchical filtering model independently, with the LVLMs fixed). The table shows that separate training yields significantly better results in terms of accuracy for both the Qwen-VL and LLaVA-1.5 models.

This table presents the results of experiments on snippet completeness. It compares the performance of three different strategies for handling incomplete website snippets: using all snippets (Raw), discarding incomplete snippets (Discard), and using a mixture of complete and incomplete snippets (Mixture). The table shows that discarding incomplete snippets leads to a significant performance loss, while using a mixture of complete and incomplete snippets yields results close to using all snippets.
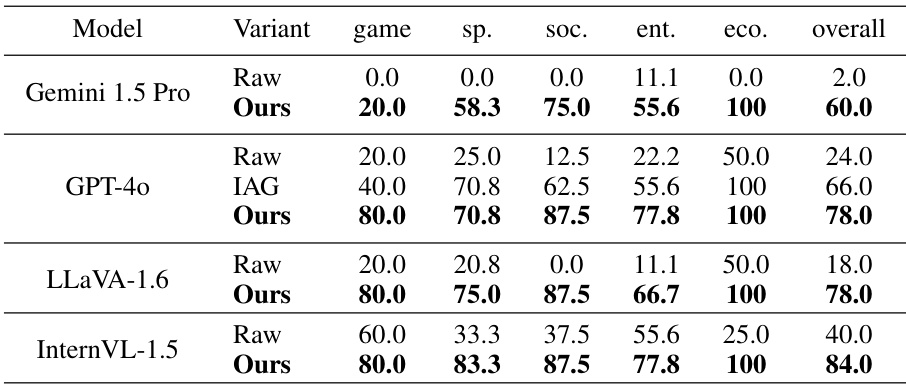
This table compares the performance of several state-of-the-art Large Vision-Language Models (LVLMs) on the UDK-VQA-20240905 dataset. It shows the accuracy of each model (Raw, IAG, and Ours variants) across different categories (game, sports, society, entertainment, economy), as well as the overall accuracy. The ‘Ours’ variant represents the performance of the models when integrated with the proposed SearchLVLMs framework.
Full paper#