↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Fine-tuning large language models (LLMs) is crucial for enhancing their capabilities, but existing methods face limitations. Full fine-tuning is computationally expensive, while parameter-efficient techniques often compromise performance or scalability. This creates a need for more efficient and effective fine-tuning approaches that balance performance, training speed, and deployment practicality.
This paper presents S2FT, a novel fine-tuning method that addresses these challenges. S2FT achieves state-of-the-art results by strategically selecting and updating a small subset of parameters within LLMs’ coupled structures. This approach enables dense computation on only the selected parameters, leading to substantial improvements in training efficiency and inference speed compared to existing methods. The theoretical analysis and empirical results demonstrate S2FT’s strong generalization capabilities and its effectiveness in reducing memory and latency during training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) because it introduces a novel fine-tuning method that significantly improves efficiency and scalability. S2FT offers a practical solution to the challenges of full fine-tuning, which is computationally expensive and prone to overfitting. By providing a more efficient and effective approach, this research opens up new possibilities for training and deploying LLMs on resource-constrained devices and scaling up LLM applications. The theoretical analysis further contributes to a deeper understanding of the generalization capabilities of sparse fine-tuning methods.
Visual Insights#
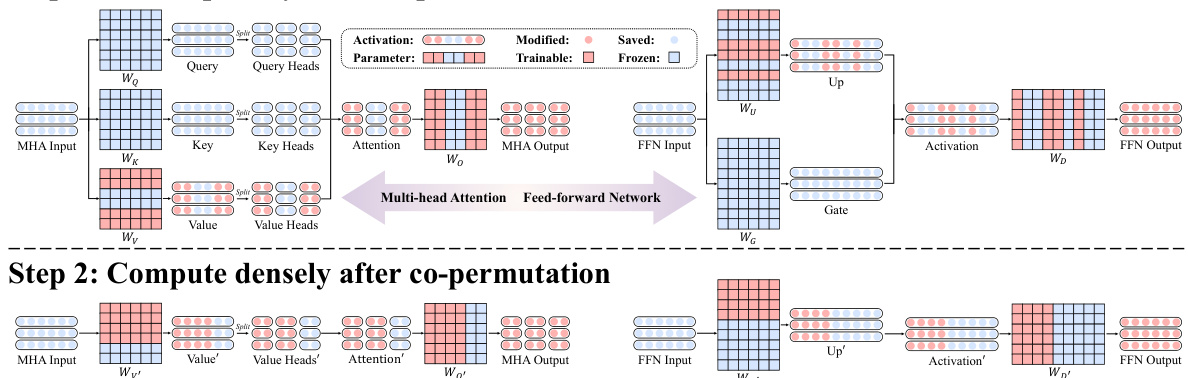
This figure illustrates the two main steps of the S2FT (Structured Sparse Fine-Tuning) method. Step 1 shows the sparse selection of attention heads and FFN channels within the Transformer blocks. Specific heads and channels are chosen, while others are frozen. The weight matrices are then co-permuted to create dense submatrices for efficient computation. Step 2 highlights how dense computations are performed only on these selected components after the co-permutation, which improves efficiency and scalability. The figure emphasizes the concept of ‘selecting sparsely and computing densely’ which is central to the S2FT approach.

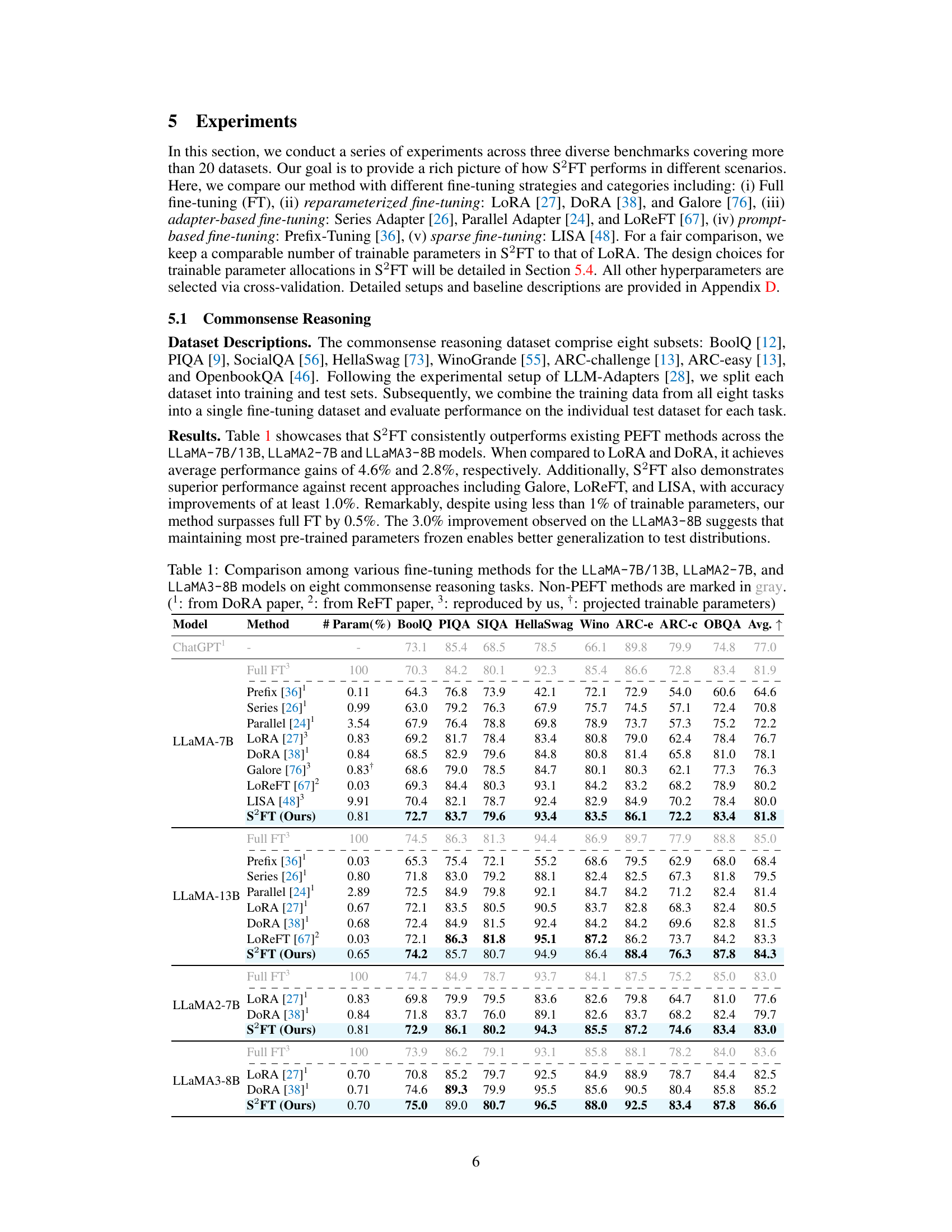
This table compares the performance of various fine-tuning methods (full fine-tuning, LoRA, DORA, Galore, LoReFT, LISA, and S2FT) on eight commonsense reasoning tasks using three different LLaMA models (LLaMA-7B, LLaMA-13B, LLaMA2-7B, and LLaMA3-8B). The table shows the percentage of parameters used for each method, and the accuracy achieved on each task. Non-PEFT methods are highlighted in gray to distinguish them from parameter-efficient methods.
In-depth insights#
Sparse Tuning#
Sparse tuning in large language models (LLMs) focuses on updating only a small subset of the model’s parameters during fine-tuning, instead of retraining the entire model. This approach offers several key advantages: reduced computational cost, lower memory footprint, and improved generalization by mitigating catastrophic forgetting. However, the unstructured nature of some sparse tuning methods can hinder computational efficiency. Structured sparse tuning methods address this by carefully selecting parameters based on the inherent structure of the model, allowing for efficient dense computations during both training and inference. Different strategies exist for selecting which parameters to sparsely tune, each with its own trade-offs. Random selection, while simple, may not always identify the most beneficial parameters. Conversely, more sophisticated methods may introduce overhead. Ultimately, the effectiveness of sparse tuning hinges on the careful balance between the degree of sparsity (number of parameters updated) and performance on the downstream task. Future research could explore more sophisticated selection strategies and investigate its application to other model architectures beyond transformers.
S2FT: Method#
The core of the S2FT method lies in its novel approach to sparse fine-tuning, which it achieves by strategically combining sparse selection with dense computation. Structured sparsity is the key; instead of randomly selecting parameters for updating, S2FT identifies inherent coupled structures within LLMs (like those in Multi-Head Attention and Feed-Forward Networks) and then selectively updates parameters within these structures. This ensures that the selected components are densely connected, avoiding the computational inefficiencies typical of unstructured sparse methods. After sparse selection of attention heads and channels, co-permutation of weight matrices is used to form dense submatrices. In this way, the model retains a dense submatrix calculation, maintaining efficiency and enhancing generalization. The method also incorporates a partial back-propagation algorithm, further enhancing training efficiency and reducing memory footprint. The result is a method that achieves state-of-the-art performance in terms of accuracy, training speed, and inference scalability, surpassing both traditional full fine-tuning and other parameter-efficient methods. This makes S2FT a strong candidate for efficient and scalable LLM fine-tuning in various applications.
Generalization#
The concept of generalization in machine learning, specifically within the context of large language models (LLMs), is crucial. It refers to a model’s ability to perform well on unseen data after being trained on a specific dataset. The paper highlights the importance of generalization in LLM fine-tuning. Poor generalization, or overfitting, is a common problem where the model performs well on the training data but poorly on new, unseen data. The authors propose that sparse fine-tuning methods, particularly their novel Structured Sparse Fine-Tuning (S2FT), offer superior generalization capabilities compared to other techniques like full fine-tuning or Low-Rank Adaptation (LoRA). This is because S2FT strategically selects a small subset of parameters to update, preventing overfitting and catastrophic forgetting (where the model forgets pre-trained knowledge). Empirical results demonstrate that S2FT achieves state-of-the-art performance on various downstream tasks, showcasing its strong generalization abilities. The superior generalization is attributed to the structured sparsity of S2FT, which allows for more efficient and effective knowledge transfer from the pre-trained model to the fine-tuned model.
Efficiency Gains#
Analyzing efficiency gains in large language model (LLM) fine-tuning is crucial. Parameter-efficient fine-tuning (PEFT) methods like the one described offer improvements over full fine-tuning by reducing the number of updated parameters. This leads to decreased memory consumption and faster training times. The method’s success stems from its strategy of sparse selection and dense computation: identifying crucial model components to update, thus avoiding redundant calculations. Specific algorithmic choices, like a partial back-propagation algorithm, further optimize training efficiency. The reported memory reduction (up to 3x) and latency improvement (1.5-2.7x) compared to full fine-tuning, and also better than other PEFT methods, demonstrate significant efficiency gains. However, careful consideration of the trade-offs between the number of trainable parameters and performance is necessary for practical applications.
Future Work#
Future research directions stemming from this Structured Sparse Fine-Tuning (S2FT) method are plentiful. Extending S2FT’s applicability beyond LLMs to other architectures like CNNs and RNNs is crucial, as it would broaden the method’s impact and utility. Exploring diverse selection strategies beyond random selection to discover optimal fine-tuning protocols is another key area. Furthermore, developing a practical and efficient serving system for S2FT is essential to realize its full potential in large-scale deployment scenarios. Investigating S2FT’s performance on a wider range of tasks and datasets beyond those in the current study is necessary to establish its robustness and generalizability. Finally, theoretical analysis should delve deeper into understanding why S2FT achieves superior generalization compared to other methods, possibly exploring connections to regularization techniques or distribution shift resilience.
More visual insights#
More on figures

This figure compares the performance of three different fine-tuning methods (SpFT, LoRA, and Full FT) on various mathematical reasoning tasks, using varying ratios of trainable parameters. It shows training loss, accuracy on near out-of-distribution (OOD) easy and hard tasks, and far OOD accuracy. The results demonstrate that SpFT excels at generalization, achieving lower training loss and higher far OOD accuracy compared to LoRA and Full FT. Full FT excels at memorization, but this comes at the cost of reduced generalization. The results support the hypothesis that SpFT strikes a better balance between memorization and generalization.

This figure illustrates the concept of ‘coupled structures’ within LLMs (Large Language Models). It shows how model weights (W1 and W2) are interconnected through intermediate activations (represented by circles). The left side demonstrates a basic structure, while the right side shows a residual structure. The highlighted weights represent those that need to be permuted simultaneously during the S2FT (Structured Sparse Fine-Tuning) process. The permutation preserves the original output of the structure while strategically selecting a sparse subset for training, enabling dense computation only for selected components. This is crucial for improving efficiency in fine-tuning LLMs, as only a fraction of parameters needs to be trained.

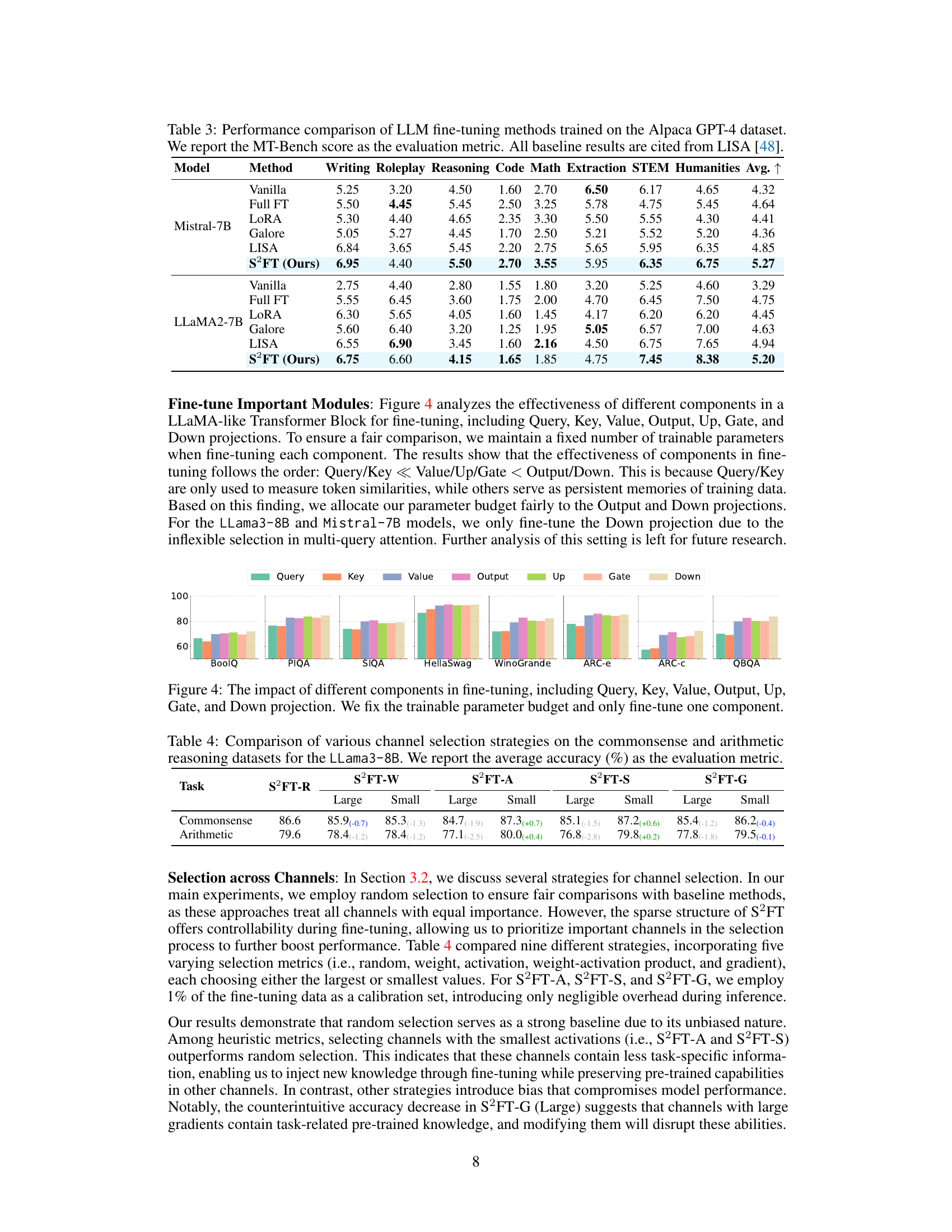
This figure shows the impact of fine-tuning different components of a transformer block on the performance of commonsense reasoning tasks. The components tested are Query, Key, Value, Output, Up, Gate, and Down projections. Each bar represents the average accuracy on eight different commonsense reasoning datasets when only one of these components is fine-tuned while holding the rest constant. The number of trainable parameters was kept constant across the experiments to ensure a fair comparison. The results indicate varying effectiveness depending on the components that are fine-tuned.
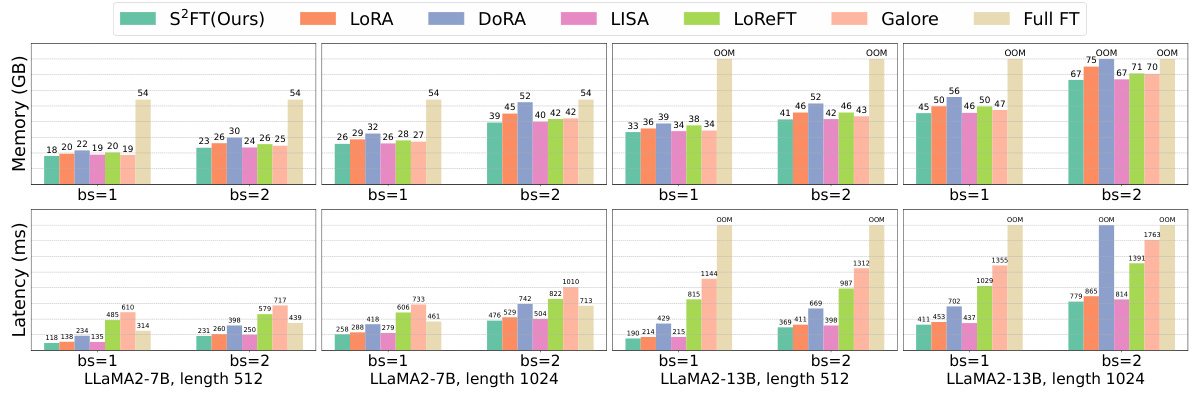
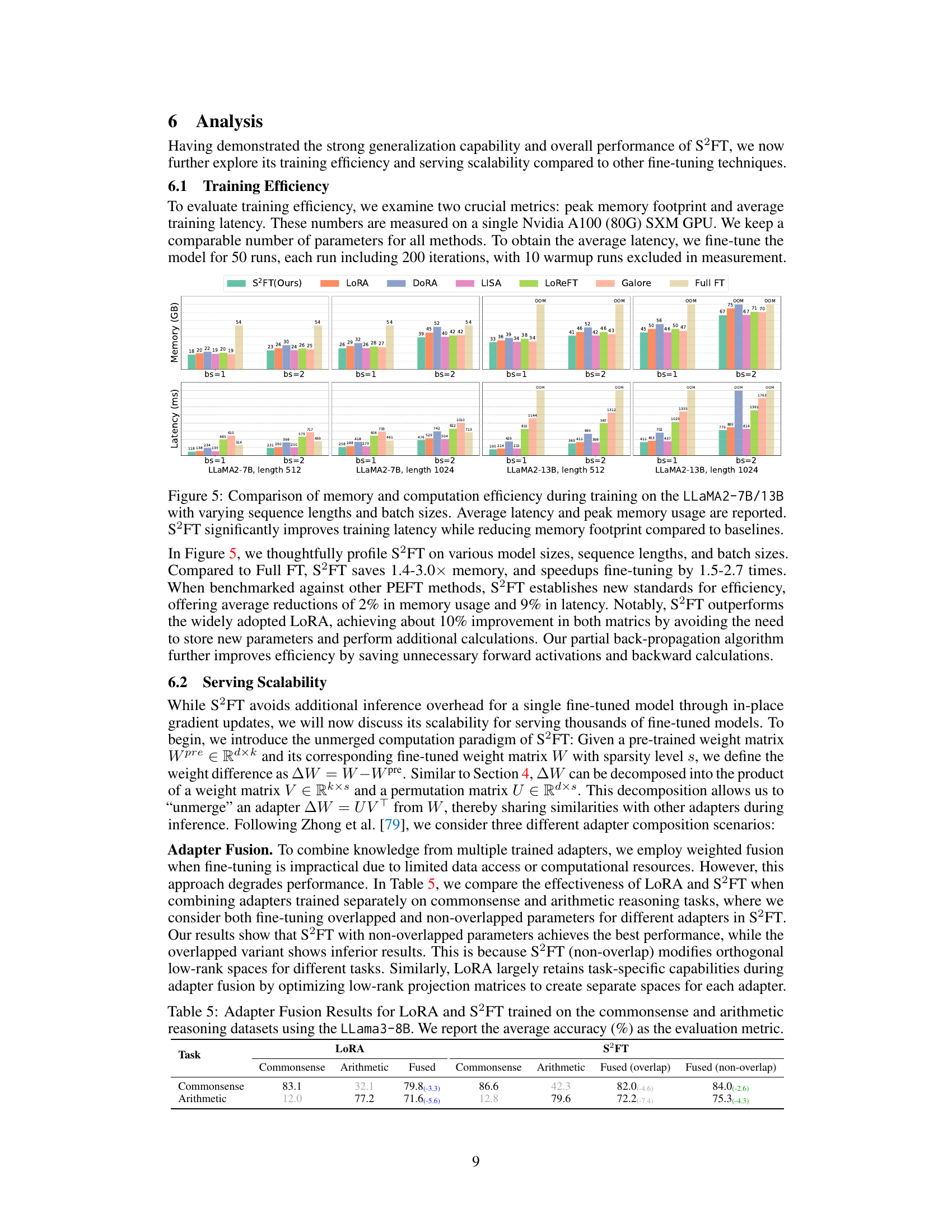
This figure compares the training efficiency (memory usage and latency) of S2FT with other fine-tuning methods (LoRA, DORA, LISA, LoReFT, Galore, Full FT) across different model sizes (LLaMA2-7B, LLaMA2-13B), sequence lengths (512, 1024), and batch sizes (1, 2). S2FT shows significant improvements in both memory usage and training speed compared to the other methods.
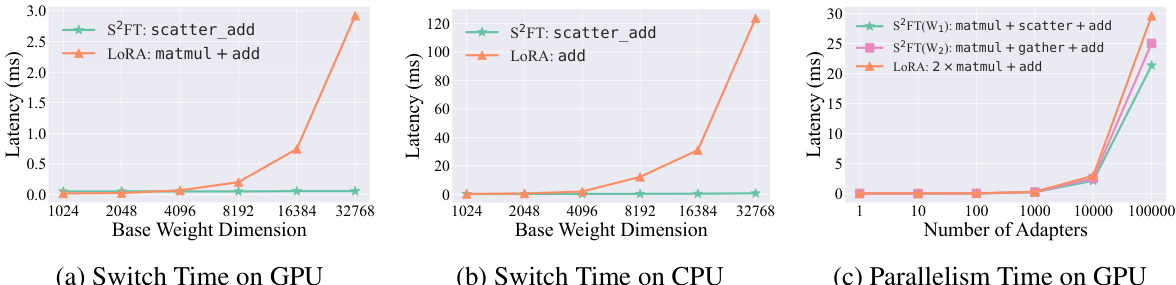
This figure compares the latency of adapter switching and parallel processing for S2FT and LoRA on a single linear layer. It shows three graphs: (a) shows the switch time on GPU, (b) shows the switch time on CPU, and (c) shows the parallelism time on GPU. In all cases, S2FT demonstrates improved scalability and efficiency, particularly in terms of parallelism on the GPU, where it achieves a 22% reduction in latency compared to LoRA.
More on tables

This table compares the performance of various fine-tuning methods (Full FT, Prefix-Tuning, Series Adapter, Parallel Adapter, LoRA, DoRA, and S2FT) across different language models (LLaMA-7B, LLaMA-13B, LLaMA2-7B, and LLaMA3-8B) on seven math reasoning tasks. The table shows the percentage of parameters used by each method, and the accuracy achieved on each task. Non-PEFT methods are highlighted in gray for easy comparison.

This table compares the performance of various LLM fine-tuning methods (Vanilla, Full FT, LoRA, Galore, LISA, and S2FT) on the Alpaca GPT-4 dataset, using the MT-Bench score as the evaluation metric. The table shows the average scores across eight different aspects of the MT-Bench benchmark (Writing, Roleplay, Reasoning, Code, Math, Extraction, STEM, and Humanities) for both the Mistral-7B and LLaMA2-7B models. It highlights the relative performance improvements of S2FT compared to existing methods.

This table compares different channel selection strategies within the S2FT method for Llama3-8B model on commonsense and arithmetic reasoning tasks. It shows the average accuracy achieved by using different selection methods (S2FT-R, S2FT-W, S2FT-A, S2FT-S, S2FT-G) with both large and small subsets of channels. The numbers in parentheses indicate the performance difference compared to the baseline method (S2FT-R).

This table compares the performance of LoRA and S2FT when combining adapters trained separately on commonsense and arithmetic reasoning tasks. It shows the accuracy for each task (Commonsense and Arithmetic) when using LoRA, and for S2FT with both overlapped and non-overlapped parameters. The numbers in parentheses represent the performance difference compared to the fused model.

This table details the hyperparameter settings used for training the S2FT model on three different tasks: Commonsense Reasoning, Arithmetic Reasoning, and Instruction Following. For each task, it specifies the optimizer used (AdamW), the learning rate (LR), the learning rate scheduler (linear or cosine), the batch size, the number of warmup steps, and the number of epochs.
Full paper#