TL;DR#
Federated learning (FL) trains global models while protecting client data privacy; however, most methods assume labeled data, which isn’t always true. Federated semi-supervised learning (FSSL) tackles this issue when only the server has a small amount of labeled data. However, FSSL typically underperforms compared to centralized semi-supervised learning (SSL), especially with scarce labeled data, due to ‘confirmation bias’ - a tendency to overfit to easy-to-learn samples.
To address this, the paper introduces (FL)², a novel FSSL training method. (FL)² employs client-specific adaptive thresholding to dynamically adjust pseudo-label confidence thresholds during training, mitigating confirmation bias. It also incorporates sharpness-aware consistency regularization to enhance model generalization and learning status-aware aggregation to optimize model updates from clients. Experiments demonstrate that (FL)² significantly outperforms existing FSSL methods across various datasets and limited labeled data scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and semi-supervised learning. It directly addresses the significant performance gap between centralized and federated semi-supervised learning, particularly when labeled data is scarce. The proposed (FL)² method offers a novel approach to improve accuracy and efficiency, opening new avenues for research and development in these critical areas. Its findings challenge existing assumptions in FSSL and provide valuable insights for future research, particularly in scenarios with limited labeled data, a common real-world challenge.
Visual Insights#
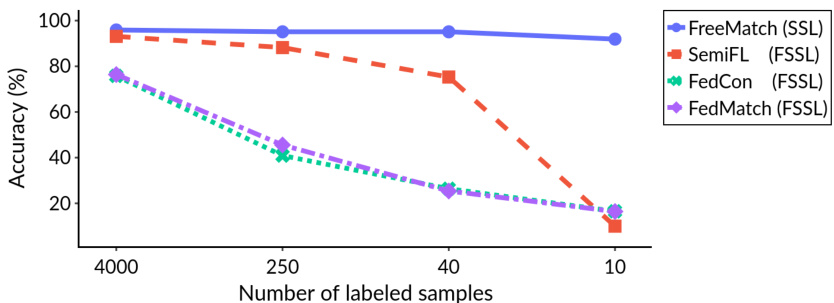
🔼 This figure compares the performance of centralized semi-supervised learning (SSL) and federated semi-supervised learning (FSSL) methods on the CIFAR-10 dataset with varying amounts of labeled data. It shows that as the number of labeled samples decreases, the performance gap between SSL and FSSL widens considerably. This highlights the challenge addressed by the proposed (FL)² method in the paper, which aims to bridge this performance gap in low-label scenarios.
read the caption
Figure 1: Comparison of SSL and FSSL algorithms on CIFAR-10 with varying numbers of labeled samples, where FreeMatch [19] represents SSL, and SemiFL [8], FedCon [9], and FedMatch [7] represent FSSL.
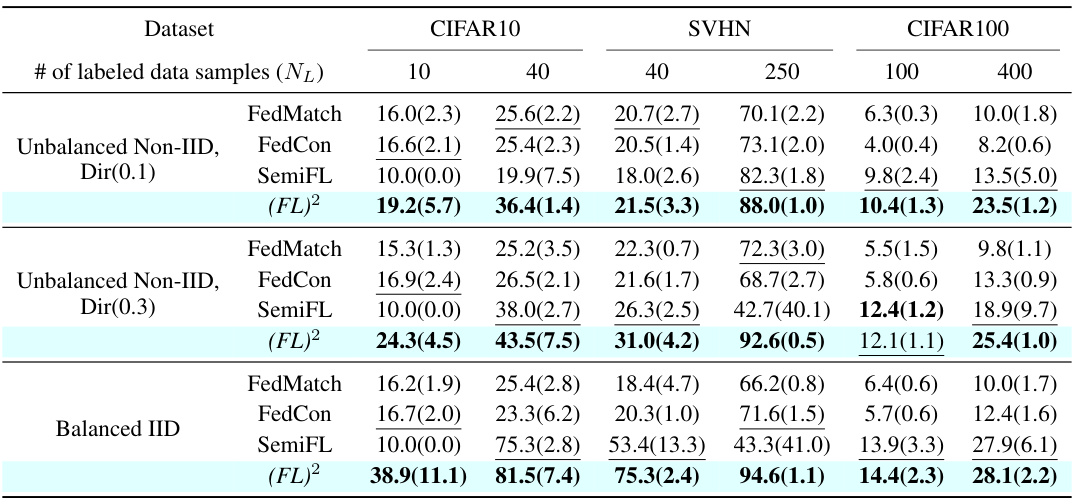
🔼 This table compares the performance of the proposed (FL)² method against three other state-of-the-art Federated Semi-Supervised Learning (FSSL) methods: FedMatch, FedCon, and SemiFL. The comparison is done across three datasets (CIFAR10, SVHN, CIFAR100) under various data distribution settings (balanced IID, unbalanced non-IID with Dir(0.1) and Dir(0.3)), and with varying amounts of labeled data at the server (10, 40, 40, 250, 100, 400). The table reports the average accuracy and standard deviation across three independent runs for each configuration. Bold values highlight the best performance, and underlined values indicate the second-best performance for each setting. This table demonstrates (FL)²’s superior performance, particularly when labeled data is scarce.
read the caption
Table 1: Evaluation of (FL)² compared with existing FSSL methods. We report the average accuracy(%) and standard deviation across three runs with different random seeds. (FL)² shows significant performance improvements over existing methods across different settings. Bold indicates the best result and underline indicates the second-best result.
In-depth insights#
FSSL Challenges#
Federated Semi-Supervised Learning (FSSL) faces significant challenges stemming from the inherent complexities of both federated learning and semi-supervised learning. Data heterogeneity across clients poses a major hurdle, as clients may possess vastly different data distributions and labeling characteristics, hindering the effective aggregation of local models. The scarcity of labeled data, often confined to the server, exacerbates the challenges of model training. The confirmation bias becomes a critical issue in FSSL, since local models trained on limited labeled data tend to overfit and generalize poorly. Moreover, communication efficiency is of paramount importance in FSSL, because transmitting large models between numerous clients and the server can be expensive and time-consuming. Finally, privacy concerns need careful handling to ensure that client data remains protected during model training and aggregation. Addressing these FSSL challenges requires innovative techniques focused on data harmonization, robust model training in data-scarce settings, mitigating biases, and employing efficient communication strategies.
(FL)² Framework#
The ‘(FL)² Framework’ presented appears to be a novel approach to Federated Semi-Supervised Learning (FSSL), designed to address the limitations of existing FSSL methods. It tackles the core issue of confirmation bias, which arises from limited labeled data and multiple local training epochs. The framework’s key innovations lie in its use of client-specific adaptive thresholding for pseudo-labeling, sharpness-aware consistency regularization to improve model generalization, and learning status-aware aggregation to weigh client updates more effectively. These combined strategies aim to bridge the performance gap between FSSL and centralized SSL, particularly beneficial in scenarios with scarce labeled data. The framework’s effectiveness is supported by empirical results showcasing significant performance improvements across multiple datasets and settings.
Adaptive Thresholds#
Adaptive thresholding, in the context of semi-supervised learning, is a crucial technique for selecting high-confidence pseudo-labels. Instead of using a fixed threshold, which can lead to confirmation bias and suboptimal model performance, adaptive methods adjust the threshold dynamically based on various factors, such as the model’s learning progress or the characteristics of the data. This dynamic adjustment is key because, during initial training phases, a more lenient threshold allows the inclusion of more data points, facilitating faster learning, while later on, a stricter threshold minimizes the inclusion of noisy pseudo-labels, hence improving the model’s overall generalization capabilities. Client-specific adaptive thresholding, as explored in many federated learning contexts, takes this concept a step further by personalizing the threshold for each client. This approach addresses the challenge of non-identical data distributions across clients and allows for more effective pseudo-labeling, bridging the performance gap between federated and centralized semi-supervised learning. The effectiveness of this approach hinges on the careful design of the adaptive mechanism itself, as poorly designed mechanisms may not effectively prevent confirmation bias and may even lead to performance degradation.
SAM Modification#
The heading ‘SAM Modification’ suggests an adaptation of Sharpness-Aware Minimization (SAM), a training technique aiming for flatter minima to improve model generalization. A naive application of SAM in federated semi-supervised learning (FSSL) might prove suboptimal, as it could generalize both correct and incorrect pseudo-labeled data. Therefore, a key insight would be how the modification addresses this limitation. A potential approach would involve carefully selecting high-confidence pseudo-labels for applying SAM, thus mitigating the propagation of errors from incorrectly labeled samples. This modification could also involve adjusting SAM’s hyperparameters based on the clients’ learning progress or data characteristics, adapting to the specific challenges of FSSL. Another possible approach could be combining SAM with consistency regularization to enforce consistency between the model’s predictions on original and perturbed inputs. Ultimately, the success of the SAM modification hinges on its ability to effectively reduce confirmation bias and improve the generalization performance of the FSSL model, particularly in scenarios with limited labeled data.
Future of FSSL#
The future of Federated Semi-Supervised Learning (FSSL) is bright, driven by the need for privacy-preserving, data-efficient machine learning. Addressing the label scarcity problem remains central; future research should explore more sophisticated methods for pseudo-labeling and consistency regularization. Improving the efficiency of aggregation algorithms in heterogeneous networks is crucial, potentially through advanced techniques like personalized federated learning or adaptive weighting. Addressing confirmation bias and client drift remains important, perhaps through techniques that dynamically adjust hyperparameters based on client-specific characteristics or learning progress. Moreover, exploring new theoretical frameworks that better model the complexities of FSSL will enhance our understanding and pave the way for more robust and reliable algorithms. Finally, integrating FSSL with other emerging paradigms, such as transfer learning, meta-learning, or reinforcement learning, could unlock further advancements and expand the applicability of FSSL to a wider range of domains.
More visual insights#
More on figures

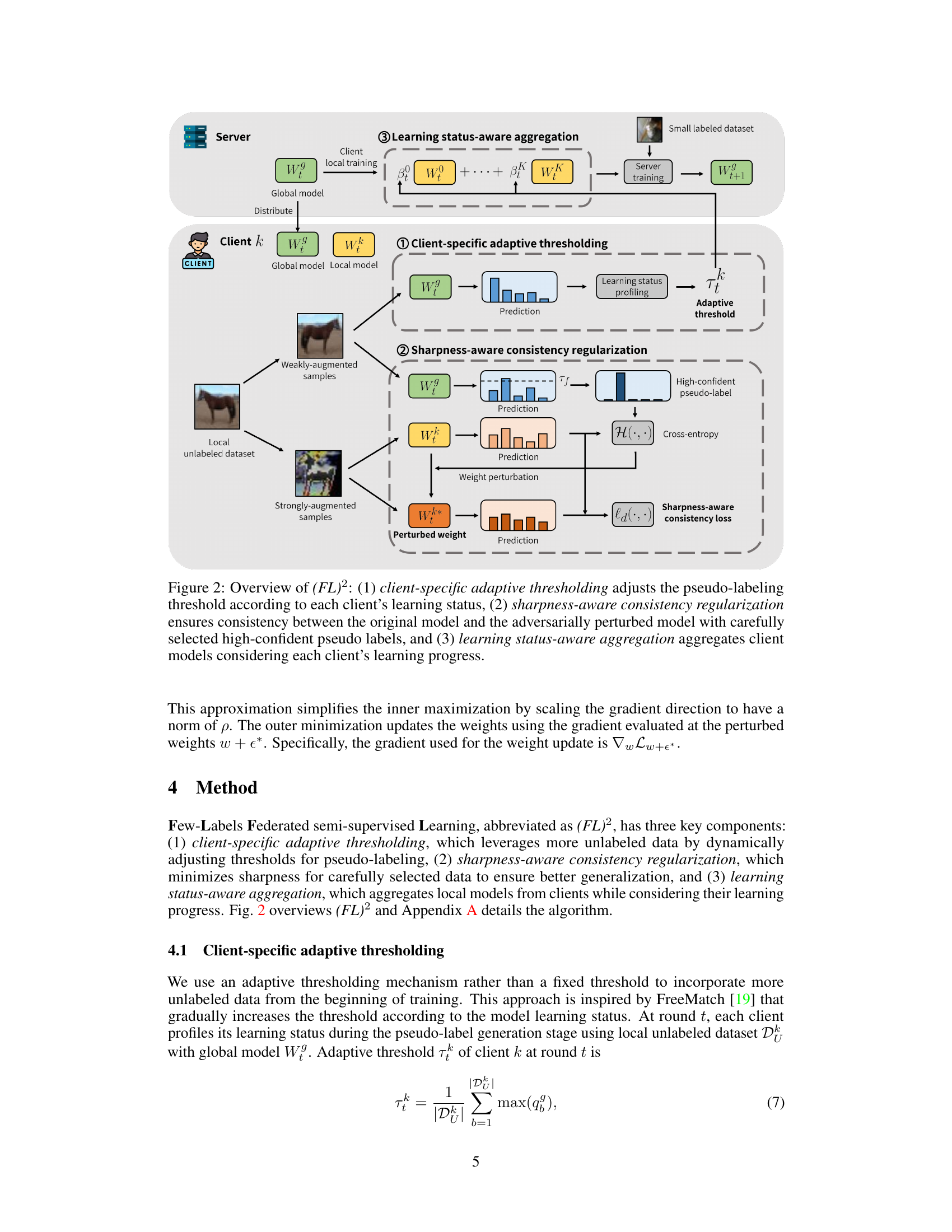
🔼 This figure illustrates the three main components of the proposed (FL)² algorithm. It shows how client-specific adaptive thresholding dynamically adjusts the threshold for pseudo-labeling based on each client’s learning progress. It also demonstrates how sharpness-aware consistency regularization is used to ensure consistency between the original and adversarially perturbed model outputs, focusing on high-confidence pseudo-labels. Finally, it shows how learning status-aware aggregation weights the contributions of different clients to the global model update based on their individual learning progress.
read the caption
Figure 2: Overview of (FL)²: (1) client-specific adaptive thresholding adjusts the pseudo-labeling threshold according to each client's learning status, (2) sharpness-aware consistency regularization ensures consistency between the original model and the adversarially perturbed model with carefully selected high-confident pseudo labels, and (3) learning status-aware aggregation aggregates client models considering each client's learning progress.
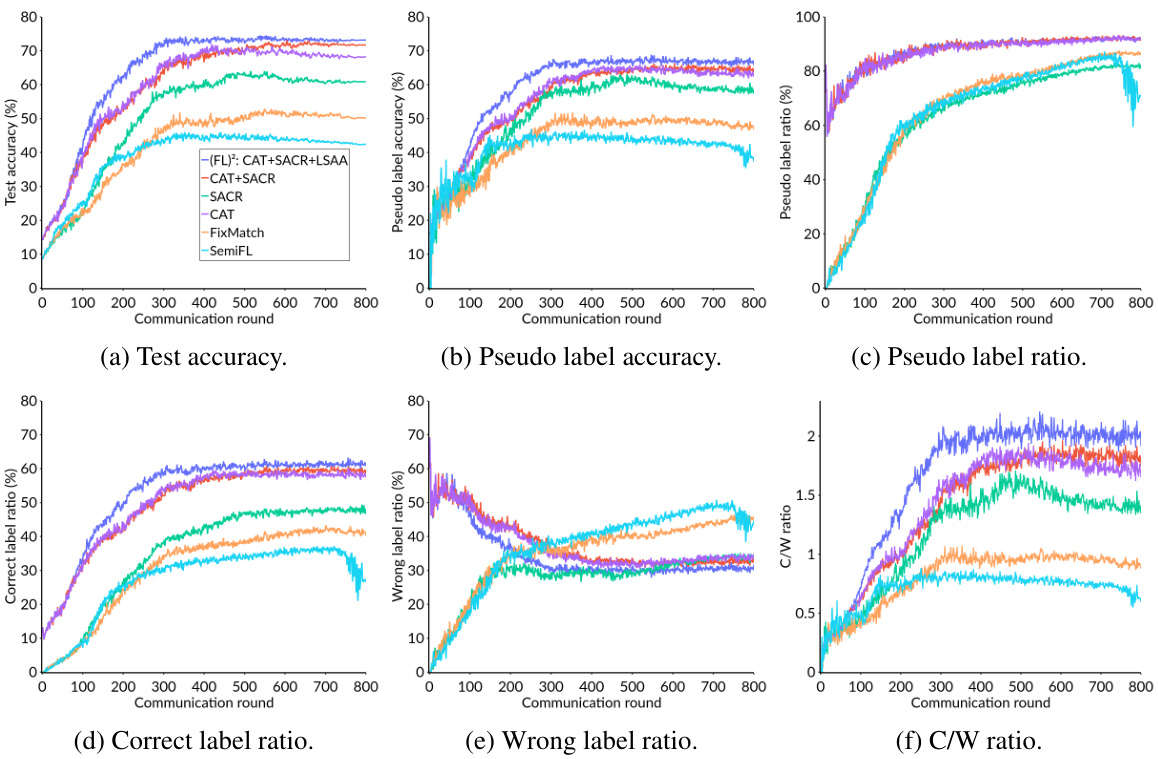
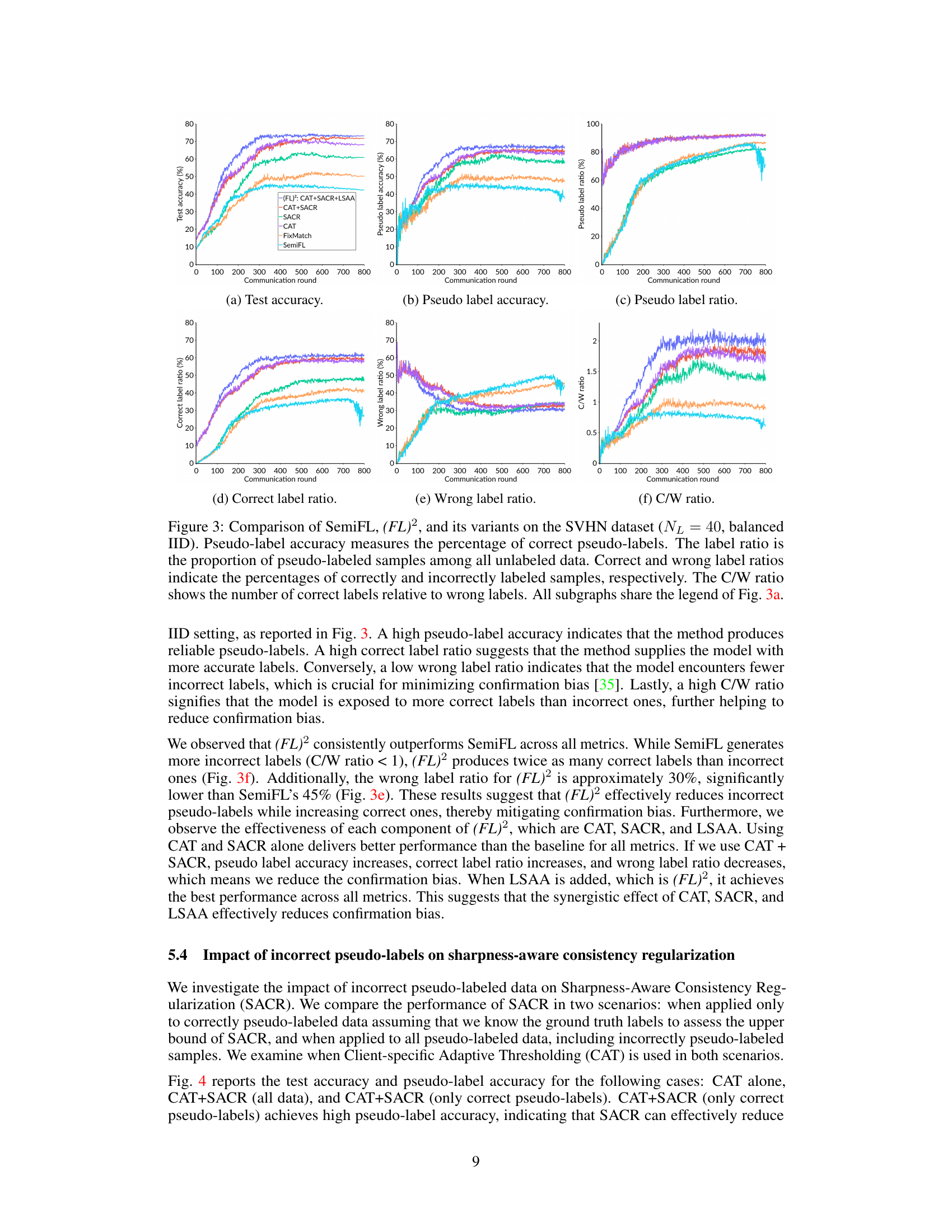
🔼 This figure compares the performance of SemiFL and (FL)² along with its variants (CAT, SACR, CAT+SACR) on the SVHN dataset. It uses six subplots to show the test accuracy, pseudo-label accuracy, pseudo-label ratio, correct label ratio, wrong label ratio, and the ratio of correct to wrong labels (C/W ratio) over the course of 800 communication rounds. The comparison highlights the effectiveness of the different components of (FL)² in mitigating confirmation bias and improving model performance, particularly when dealing with limited labeled data.
read the caption
Figure 3: Comparison of SemiFL, (FL)², and its variants on the SVHN dataset (N₁ = 40, balanced IID). Pseudo-label accuracy measures the percentage of correct pseudo-labels. The label ratio is the proportion of pseudo-labeled samples among all unlabeled data. Correct and wrong label ratios indicate the percentages of correctly and incorrectly labeled samples, respectively. The C/W ratio shows the number of correct labels relative to wrong labels. All subgraphs share the legend of Fig. 3a.
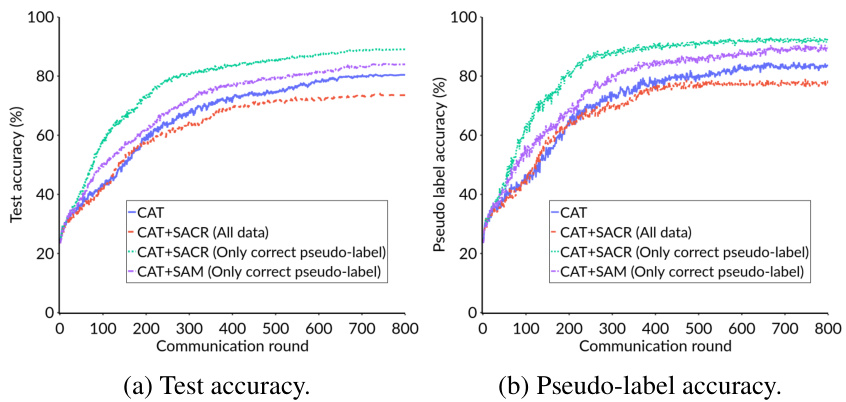
🔼 This figure shows the impact of applying Sharpness-Aware Consistency Regularization (SACR) to all pseudo-labels versus only correctly labeled pseudo-labels. The experiment is performed on the CIFAR-10 dataset with 40 labels, using a balanced IID setting. The results show that applying SACR only to correctly labeled data improves performance. In contrast, applying SACR to all data, including incorrect labels, leads to a decrease in performance. Furthermore, SACR outperforms the standard SAM objective, highlighting its effectiveness for improving generalization in semi-supervised learning.
read the caption
Figure 4: Test accuracy and pseudo-label accuracy on the CIFAR10 dataset with 40 labels, balanced IID setting. Client-specific Adaptive Thresholding (CAT) is used as the baseline. Applying Sharpness-aware Consistency Regularization (SACR) to all data, including wrongly pseudo-labeled data, degrades performance than using only CAT, while applying SACR to correctly labeled data improves performance. SACR also outperforms the standard SAM objective (CAT+SAM).
More on tables

🔼 This table shows the contribution of each component of the proposed (FL)² algorithm on the SVHN dataset. It starts with the baseline FixMatch + FedAvg, then adds components one by one (SACR, CAT, LSAA) to show how much each component improves the accuracy. The final row shows the accuracy of the full (FL)² algorithm, which combines all three components.
read the caption
Table 2: Contribution of each component of (FL)2 on the SVHN dataset (N₁ = 40, balanced IID). By applying Client-specific Adaptive Thresholding (CAT) and Sharpness-Aware Consistency Regularization (SACR) to the baseline (FixMatch + FedAvg), performance is boosted. The combination of CAT and SACR further improves the accuracy. Incorporating Learning Status-Aware Aggregation (LSAA) leads to the best performance, finally achieving (FL)2. The result demonstrates the importance of each component in (FL)2.
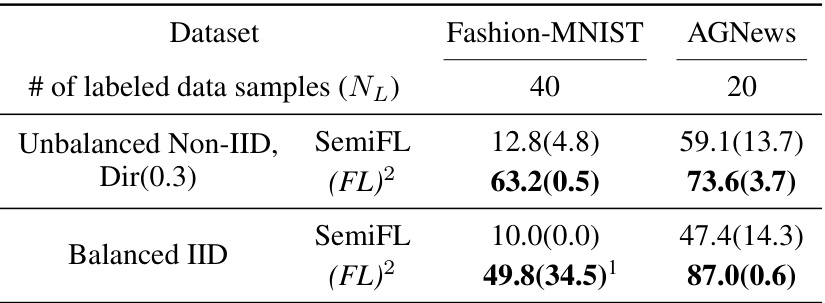
🔼 This table presents additional experimental results obtained by applying the proposed (FL)² method and comparing it against SemiFL on two different datasets, namely Fashion-MNIST and AGNews. It shows average accuracy and standard deviation over three independent runs for each method under different data distribution settings (Unbalanced Non-IID and Balanced IID). The number of labeled samples used in training also varies between the datasets.
read the caption
Table 3: More evaluation results of (FL)² compared with SemiFL on Fashion-MNIST and AGNews dataset. We report the average accuracy(%) and standard deviation across three runs with different random seeds.
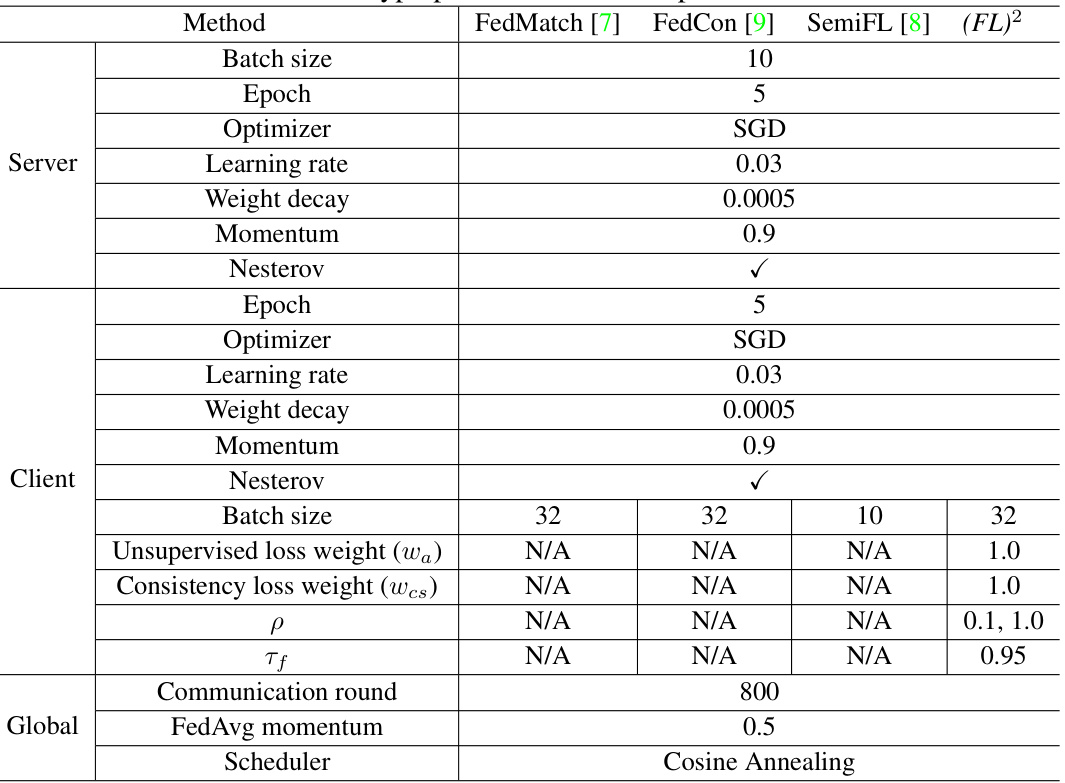
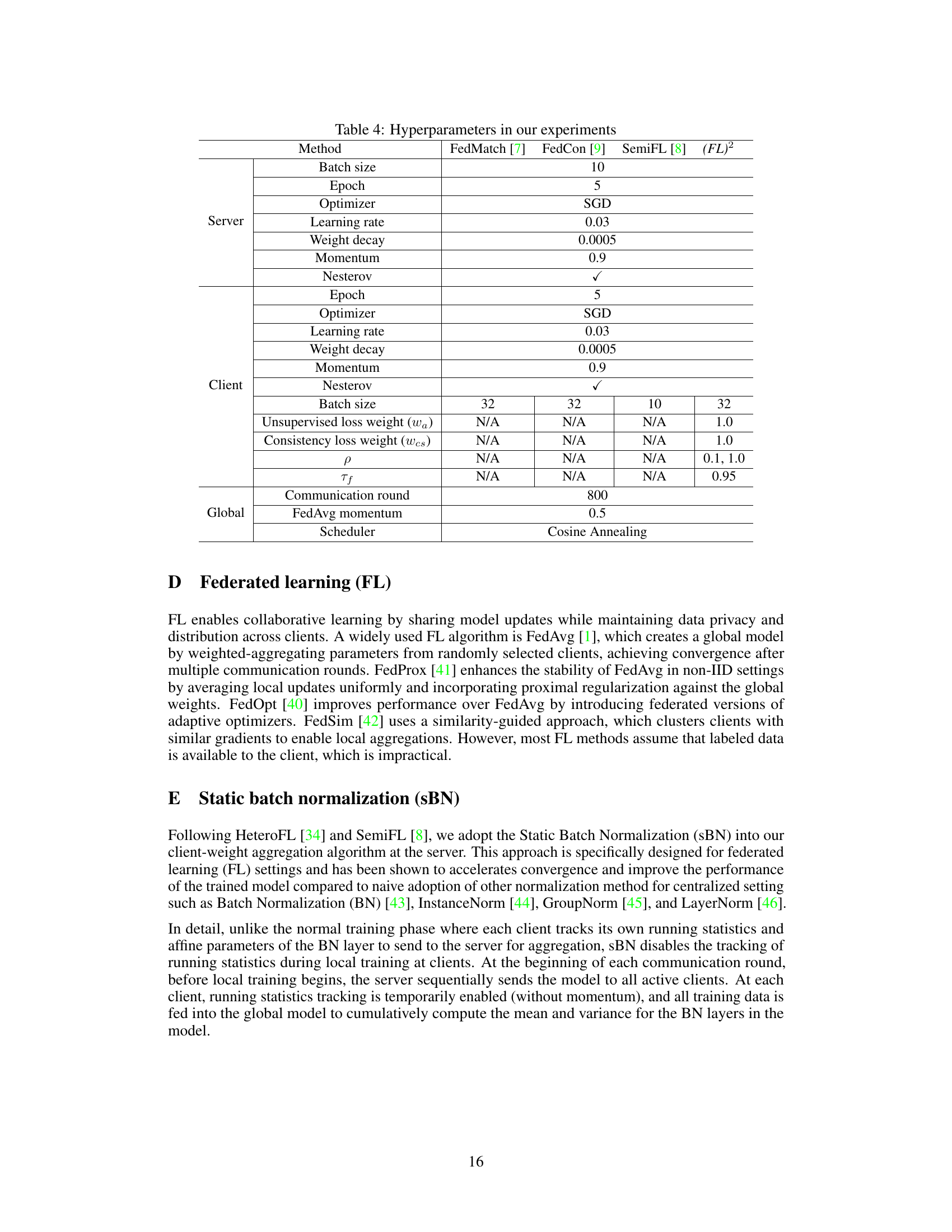
🔼 This table lists the hyperparameters used in the experiments conducted in the paper. It shows the settings used for different aspects of the training process across four different methods: FedMatch, FedCon, SemiFL, and the proposed (FL)² method. The hyperparameters are categorized by their role: Server settings, Client settings, and Global settings. The settings include batch size, number of epochs, optimizer type, learning rate, weight decay, momentum, and other parameters specific to each method, such as loss weight parameters for (FL)².
read the caption
Table 4: Hyperparameters in our experiments
Full paper#