↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current human pose estimation methods struggle with occlusions and objects within bounding boxes, leading to inaccurate estimations, particularly in dynamic scenes like sports. These methods rely on including these objects in larger bounding boxes, introducing extra noise and hindering performance.
To address this, TokenCLIPose uses a multimodal approach integrating image and text information. It only estimates keypoints inside the bounding box, treating objects as “unseen,” but uses language models to provide context for these unseen areas. This method leads to significant improvements in accuracy, tested on ice hockey, lacrosse and CrowdPose datasets, showing better performance in scenarios with occlusions and human-object interactions. The development of novel datasets also helps future researchers
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to human pose estimation that significantly improves accuracy, especially in challenging scenarios with occlusions and complex interactions with objects. It addresses limitations of existing top-down methods and paves the way for more accurate and robust pose estimation in various applications, especially those involving human-object interactions, such as sports analysis and augmented/virtual reality. The introduction of new datasets and techniques also stimulates further research in this domain.
Visual Insights#

This figure compares the performance of existing pose estimation networks (HRNet) with the proposed TokenCLIPose method. Panel (a) shows a qualitative comparison of pose estimations on ice hockey images; TokenCLIPose better captures the pose, particularly the position of the hockey stick (which is considered an ’extension’ in the paper). Panel (b) visualizes t-SNE embeddings of keypoint prompts, highlighting how TokenCLIPose maintains better spatial relationships between upper and lower body keypoints than HRNet.
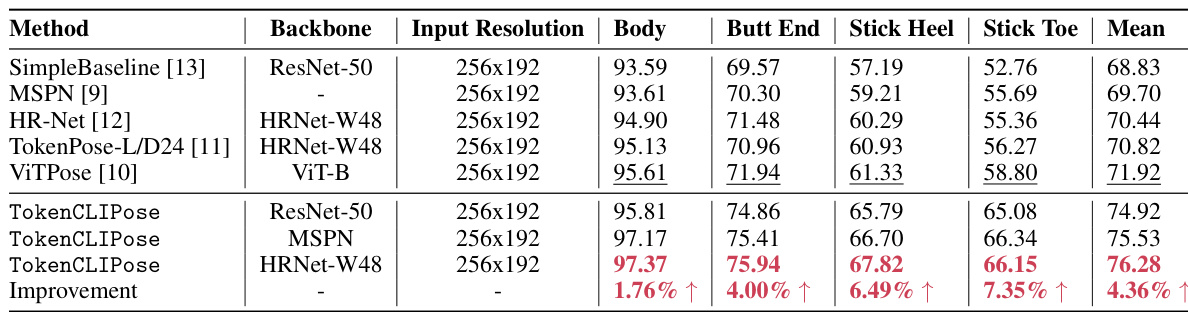
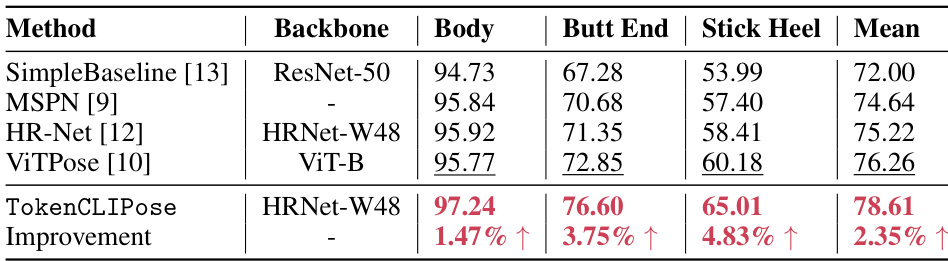
This table compares the performance of the proposed TokenCLIPose method with several state-of-the-art (SOTA) methods on an ice hockey dataset. The evaluation metric is Percentage of Correct Keypoints (PCKh) at a threshold of 0.5. The table shows the performance of each method on different keypoint categories: Body (human body keypoints), Butt End, Stick Heel, Stick Toe (all related to the hockey stick). The mean PCKh score across all categories is also reported. Bold values indicate the best performance for each category, while underlined values represent the best existing performance before the current work. The improvement achieved by TokenCLIPose compared to the best existing method is shown at the bottom.
In-depth insights#
Language Priors#
The concept of ‘Language Priors’ in the context of pose estimation is intriguing. It leverages the power of pre-trained vision-language models (VLMs) to incorporate semantic information about keypoints, even those outside the bounding box. This is crucial because traditional methods often struggle with occlusions and cluttered backgrounds. By using language to represent keypoints, the model gains access to rich contextual information. This allows the model to effectively “see” beyond the limitations of the cropped image, predicting the locations of unseen keypoints more accurately. The key advantage is that language models capture global relationships between keypoints, unlike previous methods that focused primarily on local features. This global understanding greatly improves pose estimation accuracy, particularly in scenarios with significant occlusions or complex interactions between the human subject and other objects in the scene.
Multimodal Fusion#
Multimodal fusion, in the context of this research paper, likely involves combining visual data (images) with textual data (language descriptions) to enhance human pose estimation. The core idea is that integrating visual information with semantic information from text improves the model’s understanding of complex scenarios. Specifically, language priors could help resolve ambiguities arising from occlusions or cluttered backgrounds, improving accuracy even when key body parts are not fully visible. This fusion likely occurs through a shared embedding space or a late fusion approach where the individual modalities are processed independently and combined at a later stage. The success hinges on the model’s ability to effectively learn joint representations that capture both spatial relationships from images and contextual information from text. However, challenges remain in achieving optimal fusion, as text embeddings may not always perfectly align with visual features, requiring careful design of the fusion architecture and training process. Ultimately, successful multimodal fusion here would demonstrate a robust system capable of outperforming unimodal methods, especially in challenging real-world scenarios.
Zero-Shot Transfer#
Zero-shot transfer, in the context of this research paper, is a crucial capability that demonstrates the model’s ability to generalize to unseen data without any explicit training. The success of zero-shot transfer hinges on the model’s ability to learn transferable features and representations during training. This is particularly impressive when applied to a new dataset like the Lacrosse dataset, which features different visual characteristics from the dataset used for training. This implies that the model has learned not just to recognize specific patterns within the training data but more generalizable rules about pose estimation that it can apply to new domains. The paper highlights the superior zero-shot performance on the Lacrosse dataset as evidence of the model’s robust learning. The strength of the zero-shot transfer further validates the effectiveness of the proposed multimodal approach, which uses language priors to supplement visual information. This suggests that the linguistic context provides valuable information that helps the model generalize beyond what can be learned solely from images. The significance of this capability lies in its potential for broader applications where training data might be limited or expensive to obtain.
Occlusion Handling#
Occlusion handling in human pose estimation is a critical challenge, as it directly impacts the accuracy and robustness of the system. Approaches for addressing occlusion vary, from explicitly modeling occluded parts using techniques like inpainting or generative models to developing occlusion-aware loss functions that down-weight the contribution of occluded keypoints during training. Contextual information, such as the relative positions of visible keypoints or the presence of surrounding objects, can be leveraged to infer the locations of occluded parts. Multimodal approaches, incorporating visual and textual data, offer another promising avenue. Finally, the dataset itself plays a key role; datasets with sufficient samples of occluded poses are essential for training robust and accurate models. The choice of occlusion handling strategy often involves a trade-off between computational complexity and performance gains, highlighting the need for careful consideration based on specific application requirements and available resources.
Future Extensions#
The heading ‘Future Extensions’ suggests avenues for future research building upon the current work. A key area would be exploring diverse datasets beyond the ones used, expanding to more complex scenarios with significant occlusion or highly dynamic movement. This would necessitate developing more robust methods to handle these challenges. Improving the model’s efficiency and scalability is crucial. The current approach could be optimized for faster processing and reduced computational cost, particularly considering real-time applications. Integrating additional modalities, such as depth information or inertial sensor data, is another promising direction. Combining multiple data streams could refine pose estimation accuracy and enhance robustness. Finally, exploring zero-shot generalization capabilities across vastly different action types, sporting disciplines, and even human-object interactions beyond the hockey stick represents a significant and challenging area of future research. Success in this area would significantly expand the applicability of this technology.
More visual insights#
More on figures
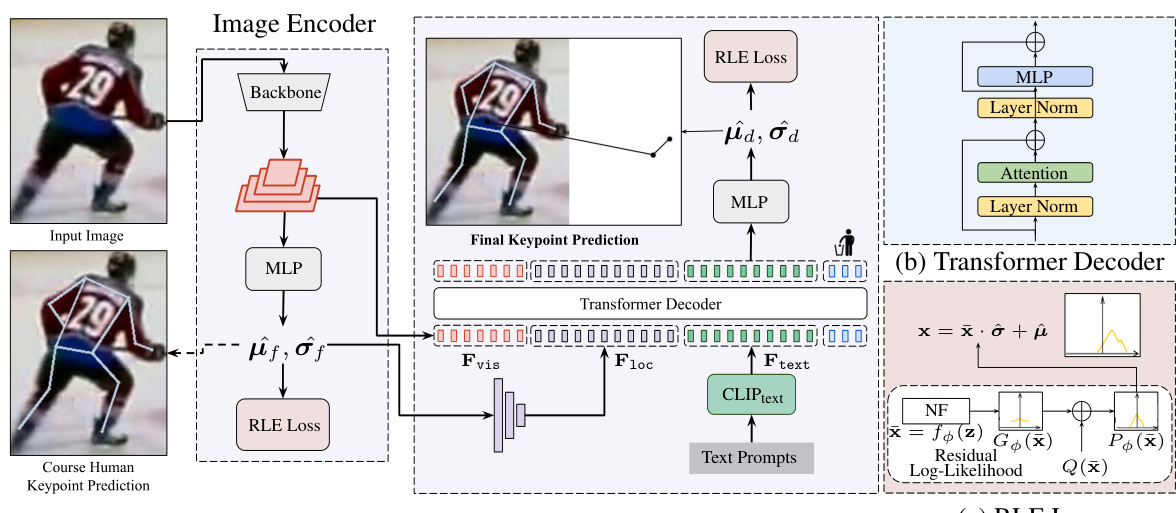
This figure illustrates the architecture of the TokenCLIPose model. It shows a pipeline where an image encoder extracts features from the input image, which are then used to generate coarse human keypoint predictions. A text-based keypoint encoder extracts keypoint-specific text tokens (using Vision Language Models). These features, along with the coarse keypoint locations, are combined and fed to a transformer decoder. This decoder outputs the final 2D keypoint predictions, which are then used with the RLE (Run-Length Encoding) loss to train the model. This shows how the model integrates both image and text information to improve the accuracy of keypoint predictions, particularly for those keypoints outside the bounding box.
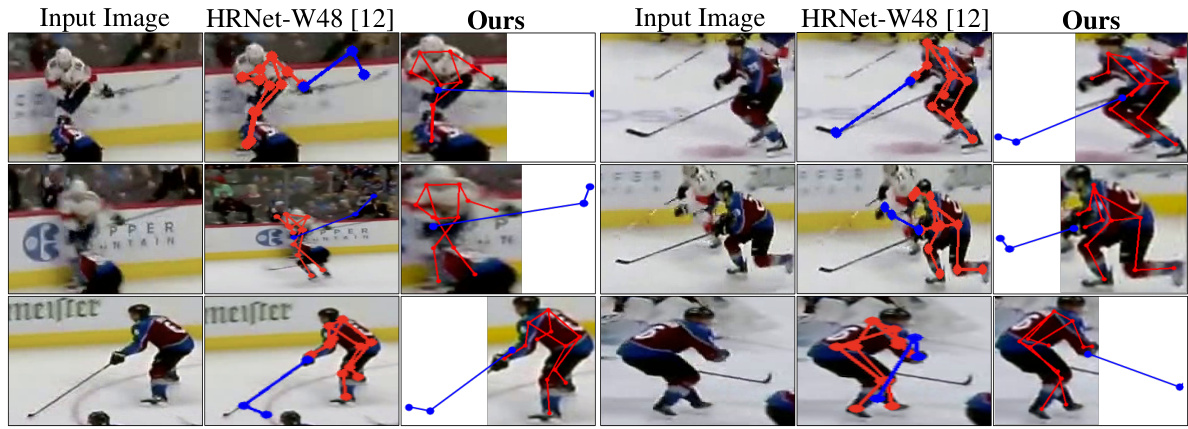
This figure shows a qualitative comparison of the proposed TokenCLIPose method against the HRNet-W48 baseline. The comparison is performed on the ice hockey dataset, highlighting the superior performance of TokenCLIPose in accurately predicting keypoints, particularly in challenging scenarios such as those involving motion blur and occlusion. The images demonstrate that TokenCLIPose more accurately captures the pose of the hockey players and sticks even when there is significant motion blur and occlusion compared to the baseline HRNet-W48.

This figure shows qualitative results of the TokenCLIPose model on the CrowdPose dataset. It visually demonstrates the model’s ability to accurately predict human poses, even in challenging scenarios with significant occlusions and complex interactions. Each image shows a person in various poses and activities with the predicted keypoints overlaid in red. The accuracy and detail of the predicted keypoints highlight the effectiveness of the proposed TokenCLIPose approach in handling complex real-world scenarios.
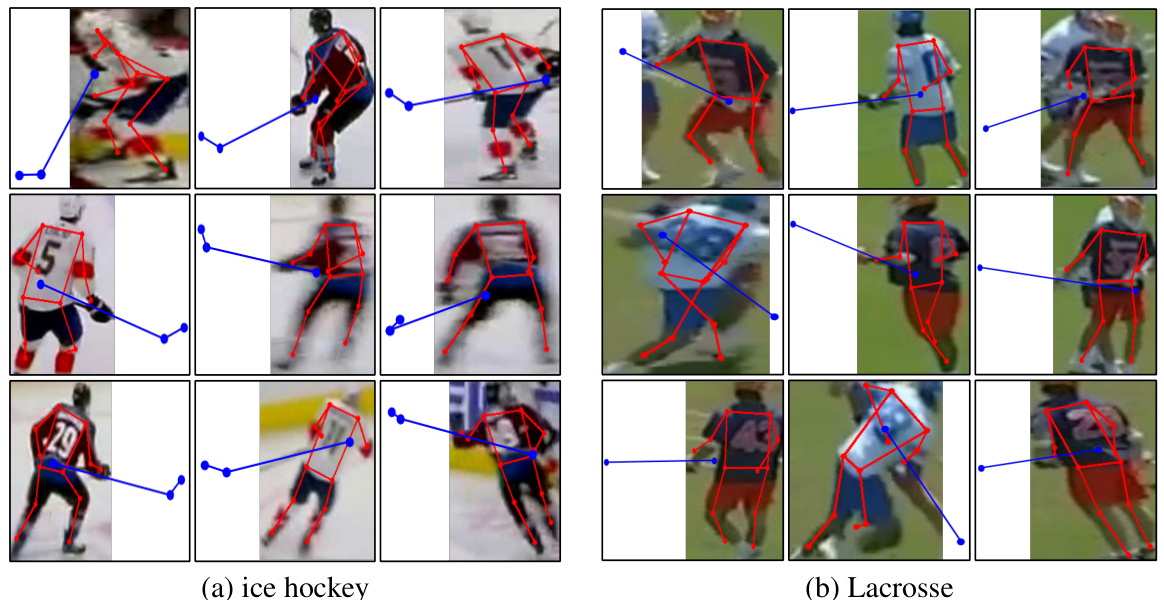
This figure shows qualitative results of the proposed TokenCLIPose method for extension pose estimation on ice hockey and Lacrosse datasets. The key aspect highlighted is the prediction of keypoints (pose) of the hockey stick and Lacrosse stick, which extend beyond the cropped image bounding box. The images showcase the accuracy of the model in estimating the pose of these extensions, even when parts of the extension are outside the area typically used for pose estimation. This demonstrates the model’s ability to effectively ‘see beyond the crop’ and leverage context even for unseen keypoints.
More on tables
This table compares the performance of TokenCLIPose with state-of-the-art (SOTA) methods on a Lacrosse dataset using the Percentage of Correct Keypoints (PCKh) metric at a threshold of 0.5. The comparison is done using a zero-shot transfer approach, meaning the model trained on the ice hockey dataset was directly evaluated on the Lacrosse dataset without any further training or fine-tuning. The table shows the PCKh scores for different body parts (Body, Butt End, Stick Heel) and the mean across all parts. The improvement achieved by TokenCLIPose over other methods is also highlighted.
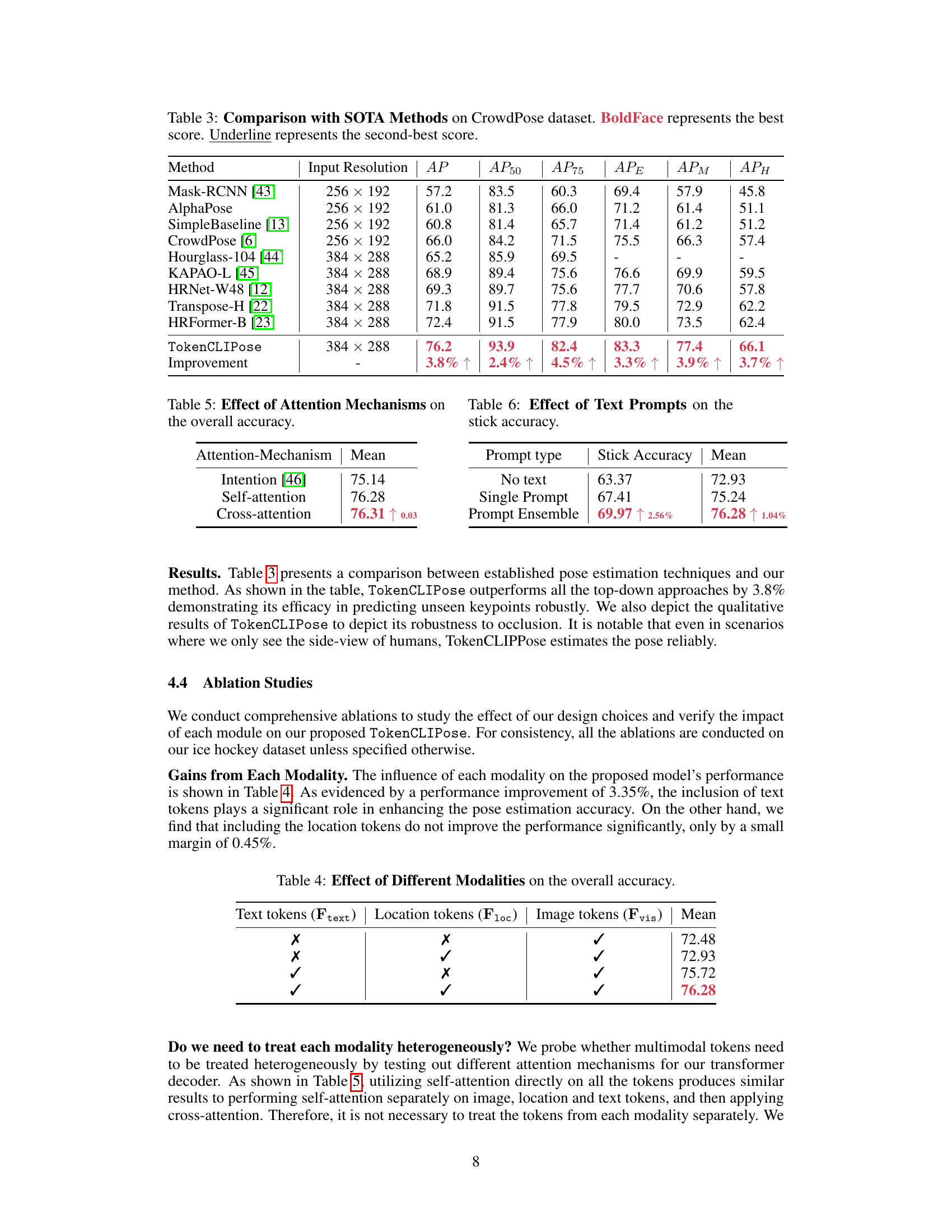
This table compares the performance of the proposed TokenCLIPose method with several state-of-the-art (SOTA) methods on the CrowdPose dataset. The evaluation metric used is Average Precision (AP), along with its variations at different thresholds (AP50, AP75, APE, APM, APH). Boldface indicates the best performing method for each metric, and underlined values highlight the second-best performance. The ‘Improvement’ row shows the percentage improvement of TokenCLIPose over the best SOTA method for each metric.
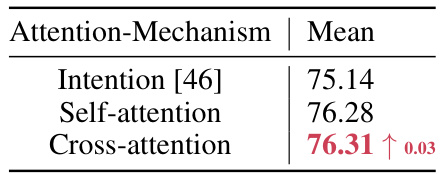
This table presents the results of an ablation study on different attention mechanisms used in the TokenCLIPose model. The study compares the performance of three different attention mechanisms: Intention [46], Self-attention, and Cross-attention. The results show that the Cross-attention mechanism achieves the highest overall accuracy, with a slight improvement over the Self-attention mechanism.

This table shows the results of an ablation study on the impact of different text prompt strategies on the accuracy of stick keypoint prediction in an ice hockey dataset. Three conditions are compared: no text prompt, a single text prompt, and an ensemble of text prompts. The ‘Stick Accuracy’ column reports the performance metric specifically for stick keypoints, while the ‘Mean’ column shows the average performance across all keypoints. The results demonstrate the positive effect of adding text prompts and the benefit of using an ensemble of prompts for improved accuracy.
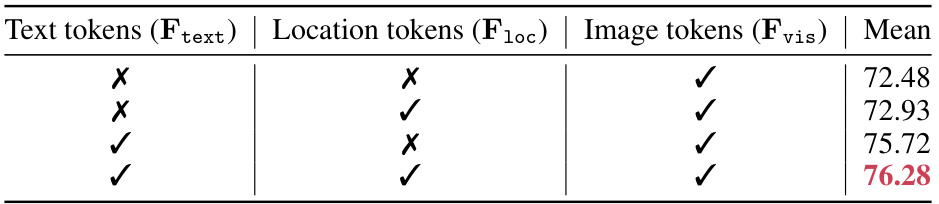
This table presents the ablation study of the proposed TokenCLIPose model by removing different modalities one by one to analyze the impact of each modality. It shows that including text tokens significantly improves the accuracy by 3.35%, while location tokens have only a minimal impact (0.45%).

This table compares the model’s performance using bounding boxes from the Faster-RCNN object detector versus ground truth bounding boxes. It shows a small improvement in accuracy (2.47%) when using ground truth bounding boxes, suggesting that the model is fairly robust to the quality of the bounding box input.

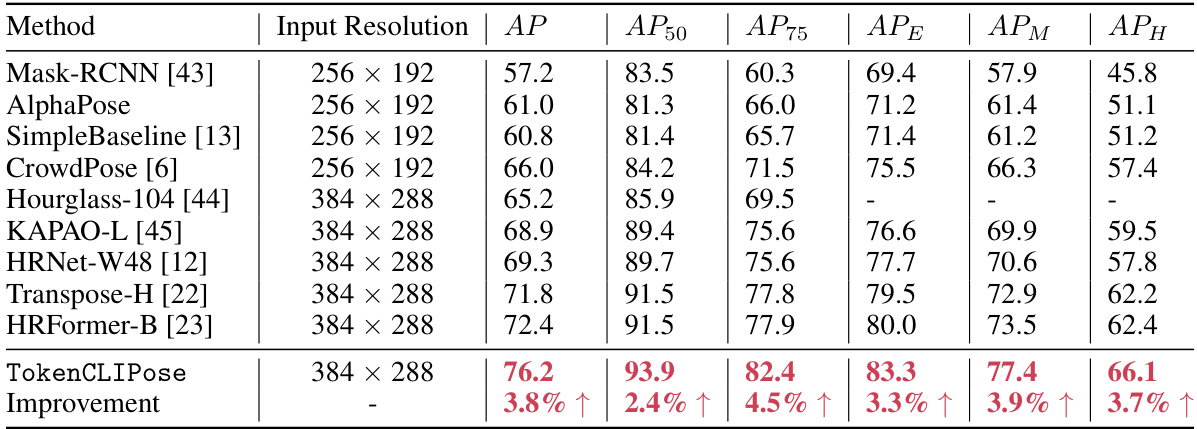
This table compares the performance of the proposed TokenCLIPose method with other state-of-the-art (SOTA) methods on the CrowdPose dataset. The metrics used for comparison are Average Precision (AP) and its variants at different intersection over union (IoU) thresholds (AP50, AP75). It also includes AP_E (Average Precision for easy examples), AP_M (Average Precision for medium examples), and AP_H (Average Precision for hard examples). The table highlights TokenCLIPose’s superior performance over other methods, demonstrating its effectiveness in human pose estimation.
Full paper#