↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current personalized retrieval and segmentation methods struggle when multiple similar objects are present. Supervised methods require extensive labeled data, while self-supervised methods often fail to identify the specific instance. This paper explores using text-to-image diffusion models to overcome these issues.
The proposed method, Personalized Diffusion Features Matching (PDM), uses intermediate features from pre-trained text-to-image models to create personalized feature maps for both appearance and semantics. PDM outperforms other methods in benchmarks, highlighting its ability to accurately handle multiple similar instances. New, more challenging benchmarks are also proposed. PDM offers a novel zero-shot approach that avoids the need for extensive training data, making it more practical for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in personalized retrieval and segmentation due to its novel approach using diffusion models. It addresses the limitations of existing methods by achieving superior performance on benchmark datasets and introducing new, more realistic evaluation benchmarks. This work opens up new avenues for research by demonstrating the potential of leveraging intermediate features from pre-trained text-to-image diffusion models for various instance-related tasks.
Visual Insights#

This figure shows examples of personalized segmentation. The task is to segment a specific object (e.g., a dog, a van, or a cat) in a new image, even if there are other similar objects present. The authors’ method successfully identifies the target instance, unlike other methods (DINOv2 and PerSAM) that either capture visually or semantically similar objects. Red indicates incorrect segmentation, while green indicates correct segmentation.
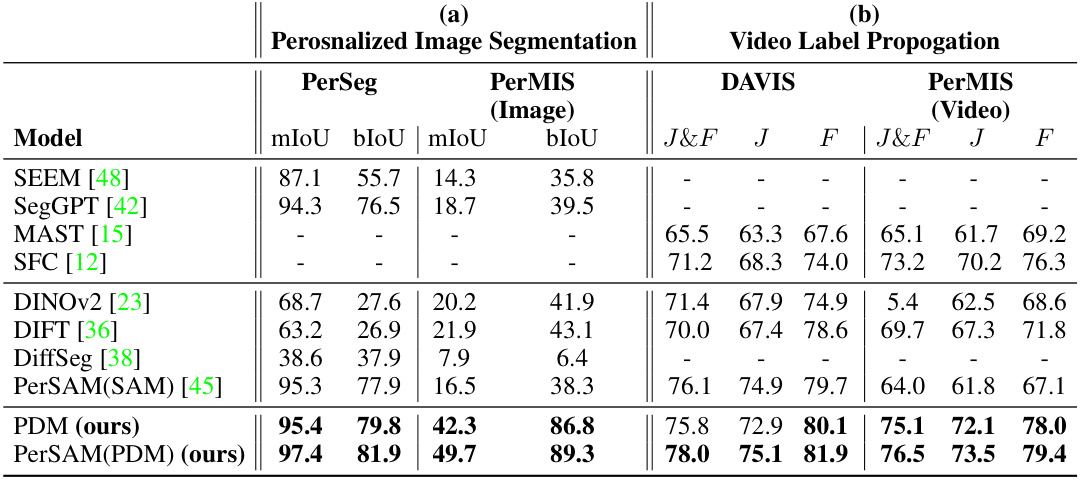
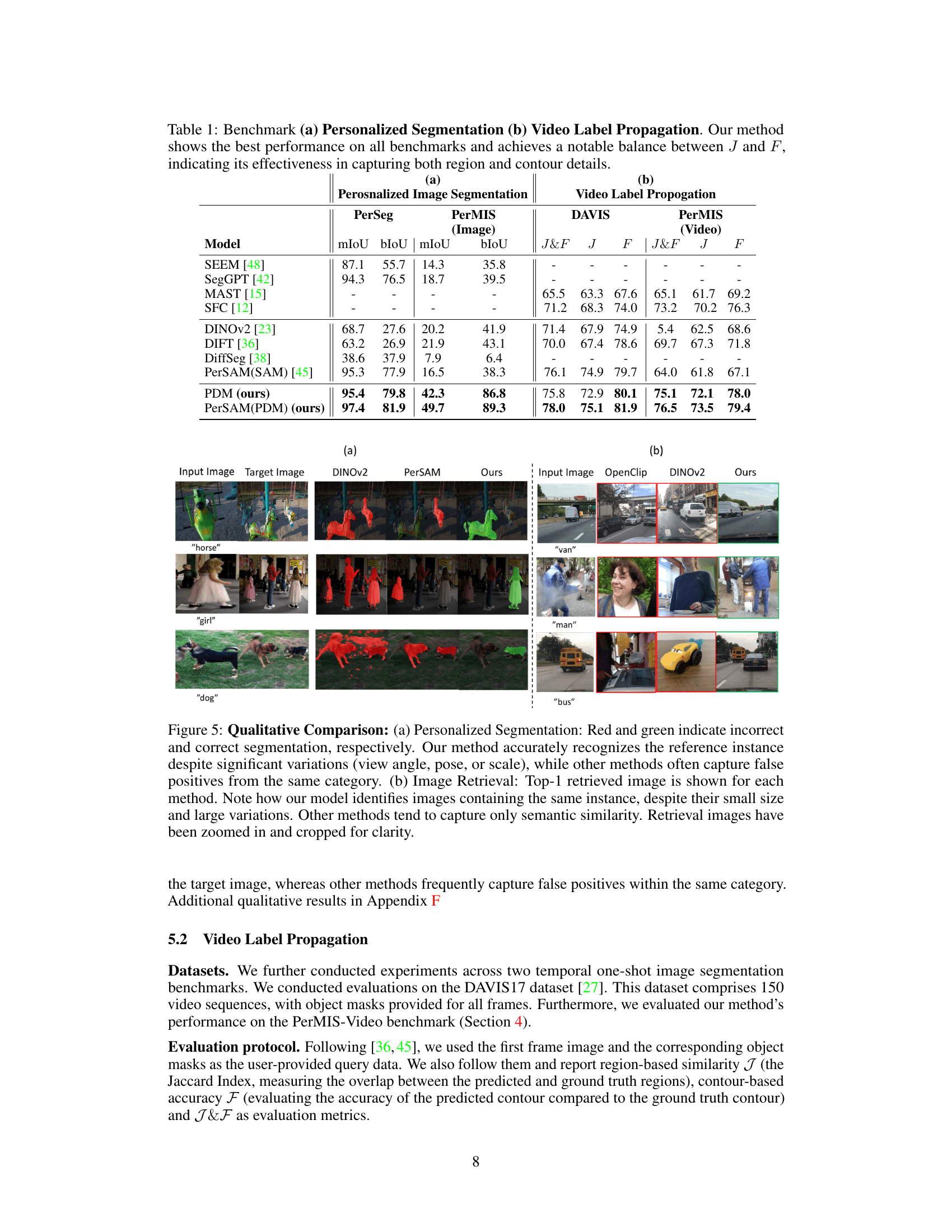
This table presents the quantitative results of the proposed method (PDM) and other baseline methods on two tasks: personalized image segmentation and video label propagation. The personalized image segmentation results are shown for two datasets, PerSeg and PerMIS (image). Video label propagation results are shown for DAVIS and PerMIS (video). Metrics used vary depending on the task and include mIoU, bIoU, J, F, and J&F. The table demonstrates PDM’s superior performance compared to other methods in both tasks.
In-depth insights#
Diffusion Feature#
The concept of “Diffusion Features” in the context of a research paper likely refers to extracting meaningful representations from the intermediate layers of a pre-trained diffusion model used for image generation or related tasks. These models, such as Stable Diffusion, generate images by iteratively refining noise. Intermediate layers capture distinct aspects of the image generation process such as low-level textural details or higher-level semantic understanding. The innovation lies in leveraging these intermediate representations, which are usually discarded, as features for downstream tasks. This approach offers the advantage of personalization without requiring further training, allowing the model to adapt to specific instances or objects without modifying the underlying weights. By using these features, tasks like personalized retrieval or segmentation can be achieved via feature matching techniques which are based on similarity calculations between feature maps representing the reference and target objects. This approach may demonstrate superior performance to other methods that may rely on simpler image features because the diffusion features capture richer information about both the visual appearance and underlying semantic concepts of the objects.
Personalized Retrieval#
Personalized retrieval, a core focus of the research paper, tackles the challenge of efficiently identifying specific instances within a vast dataset based on a reference image. The key innovation lies in leveraging intermediate features from pre-trained text-to-image diffusion models. This approach bypasses the need for extensive labeled training data, a significant advantage over traditional supervised methods. The method effectively fuses semantic and appearance cues, enabling accurate retrieval even when multiple similar objects are present, a common weakness of existing techniques. The paper highlights the limitations of current benchmarks, often featuring only single instances or objects from different categories. A new benchmark, personalized multi-instance retrieval (PerMIR), is proposed to address this deficiency, introducing a more realistic scenario with multiple similar instances. Results show that this personalized retrieval method outperforms both self-supervised and even supervised methods on standard benchmarks, achieving a significant performance boost when integrated with other models. The success underscores the potential of diffusion models for personalized information retrieval applications.
Zero-Shot Seg#
Zero-shot segmentation aims to segment objects in an image without using any labeled data specific to the target object classes. This is a significant challenge in computer vision, as it requires the model to generalize from its training data to unseen classes. A successful zero-shot segmentation model leverages a combination of techniques. These often include strong feature extractors (such as pre-trained vision transformers) that capture rich representations of the visual input, and clever mechanisms to bridge the gap between the available knowledge (e.g., class descriptions or examples from related classes) and the need to identify and segment the novel object. The core challenge is to transfer knowledge effectively, ensuring the model can robustly segment objects even under considerable visual variation and with limited or no direct training examples for the specific object class. This is an active area of research, and various approaches using prompt engineering, few-shot learning, or self-supervised learning methods are being investigated to improve the performance and generalization capabilities of zero-shot segmentation systems. The ultimate goal is to create systems that are both accurate and versatile, allowing for seamless segmentation of any object presented, regardless of whether it was seen during training.
Benchmark Datasets#
The effectiveness of personalized retrieval and segmentation models hinges significantly on the quality and characteristics of benchmark datasets. Existing datasets often fall short, frequently featuring single instances per image or objects from diverse classes, thus simplifying evaluation and potentially biasing results toward semantic-based methods. This limitation hinders a fair assessment of instance-level approaches. A crucial contribution is the introduction of novel benchmarks, which deliberately incorporate multiple instances of the same object class within images. This design choice increases difficulty and better reflects real-world scenarios, enabling a more robust and meaningful comparison of algorithms. By addressing the deficiencies of existing datasets, these new benchmarks pave the way for more accurate evaluation and accelerated advancement in personalized retrieval and segmentation.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In this context, an ablation study of a personalized retrieval and segmentation model using diffusion features might involve removing either the appearance or semantic feature component, observing the impact on performance metrics. By isolating the effect of each component, researchers can determine the relative importance of appearance versus semantic information in achieving accurate results. Furthermore, an ablation study could investigate the impact of different diffusion model layers or specific model blocks, showing whether certain layers are more crucial for extracting the desired instance features. It may also explore different feature fusion techniques, comparing simple averaging to more sophisticated methods to ascertain the impact on personalization accuracy. The overall goal is to understand which features are essential for successful personalization, justifying the model’s design choices and potentially informing future improvements. Finally, ablation experiments on variations of the dataset could highlight vulnerabilities stemming from limitations in the dataset’s image characteristics or instance properties.
More visual insights#
More on figures

This figure visualizes the features extracted from a pre-trained text-to-image diffusion model. (a) shows a Principal Component Analysis (PCA) of features from the self-attention block of the U-Net at different diffusion timesteps, demonstrating that features with similar colors and textures cluster together. (b) shows the cross-attention map generated using the prompt ‘dog’, highlighting the regions corresponding to dogs in the image.

This figure illustrates the Personalized Diffusion Features Matching (PDM) approach. PDM uses features extracted from a reference image and a target image to perform personalized retrieval and segmentation. It combines appearance and semantic cues. Appearance similarity is calculated using a dot product between cropped foreground features from the reference and target image feature maps. Semantic similarity uses the dot product of the class name token and the target semantic feature map. These two similarities are combined using average pooling to create a final similarity map used for retrieval and segmentation.

This figure showcases examples from different datasets used for personalized retrieval and segmentation tasks. It highlights a key difference between existing benchmarks (ROxford, DAVIS, PerSeg) and the proposed PerMIR benchmark. The existing benchmarks primarily contain images with either a single instance of an object or multiple instances of different object classes. In contrast, the proposed PerMIR benchmark includes images with multiple instances of the same object class, making the task of personalized retrieval and segmentation more challenging and realistic.

This figure provides a qualitative comparison of the proposed method (PDM) against other methods for personalized segmentation and retrieval. The left side shows that PDM accurately segments the target object even with variations in pose and view, unlike other methods which often incorrectly segment similar objects. The right side demonstrates PDM’s ability to retrieve images containing the identical target object, even with size and variation differences, surpassing other methods that primarily capture semantic similarities.

This figure illustrates the Personalized Diffusion Features Matching (PDM) approach. PDM uses a combination of semantic and appearance features extracted from both reference and target images to achieve zero-shot personalized retrieval and segmentation. The process involves calculating appearance similarity (using a dot product of cropped features), semantic similarity (using a class name token and semantic feature map), and then combining these maps via average pooling to create a final similarity map that localizes the target object precisely. The figure highlights that even if both appearance and semantic maps show multiple similar instances, the combination leads to the correct identification of a single specific instance.

This figure shows examples from different personalized retrieval and segmentation benchmarks. Existing benchmarks typically show either a single instance of an object or multiple instances of objects from different classes. The authors highlight that this makes the task easier than real-world scenarios. They then introduce their own benchmarks (PerMIR and PerMIS), which include multiple instances of the same object class within a single image to increase the difficulty and realism of the task. This makes it more challenging to distinguish between similar instances using only semantic features, necessitating the use of personalized features.

This figure compares the performance of the proposed method (PDM) against other state-of-the-art methods for personalized segmentation and retrieval. The top row shows examples where the PDM successfully identifies and segments the target object despite variations in view, pose, or scale. Other methods often fail, identifying similar but incorrect objects. The bottom row demonstrates the superior instance retrieval capability of PDM, identifying images with the same object as the query even if the size and appearance differ significantly. Other methods struggle with this task, often relying on semantic similarity rather than exact instance identification.
More on tables
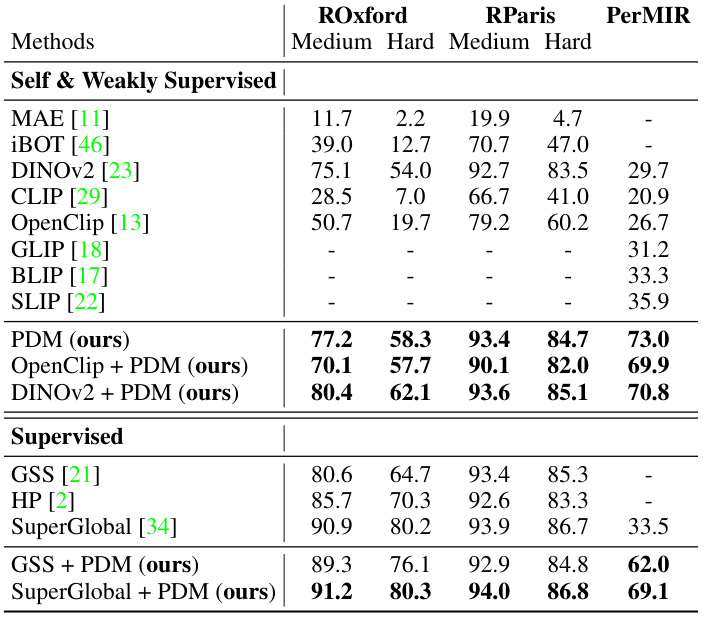
This table presents a comparison of the mean average precision (mAP) for personalized retrieval across several benchmarks. It compares the performance of the proposed Personalized Diffusion Features Matching (PDM) method against various state-of-the-art methods categorized into self-supervised, weakly supervised, and supervised approaches. The table highlights PDM’s superior performance and demonstrates that incorporating PDM features into other methods can also lead to performance improvements.

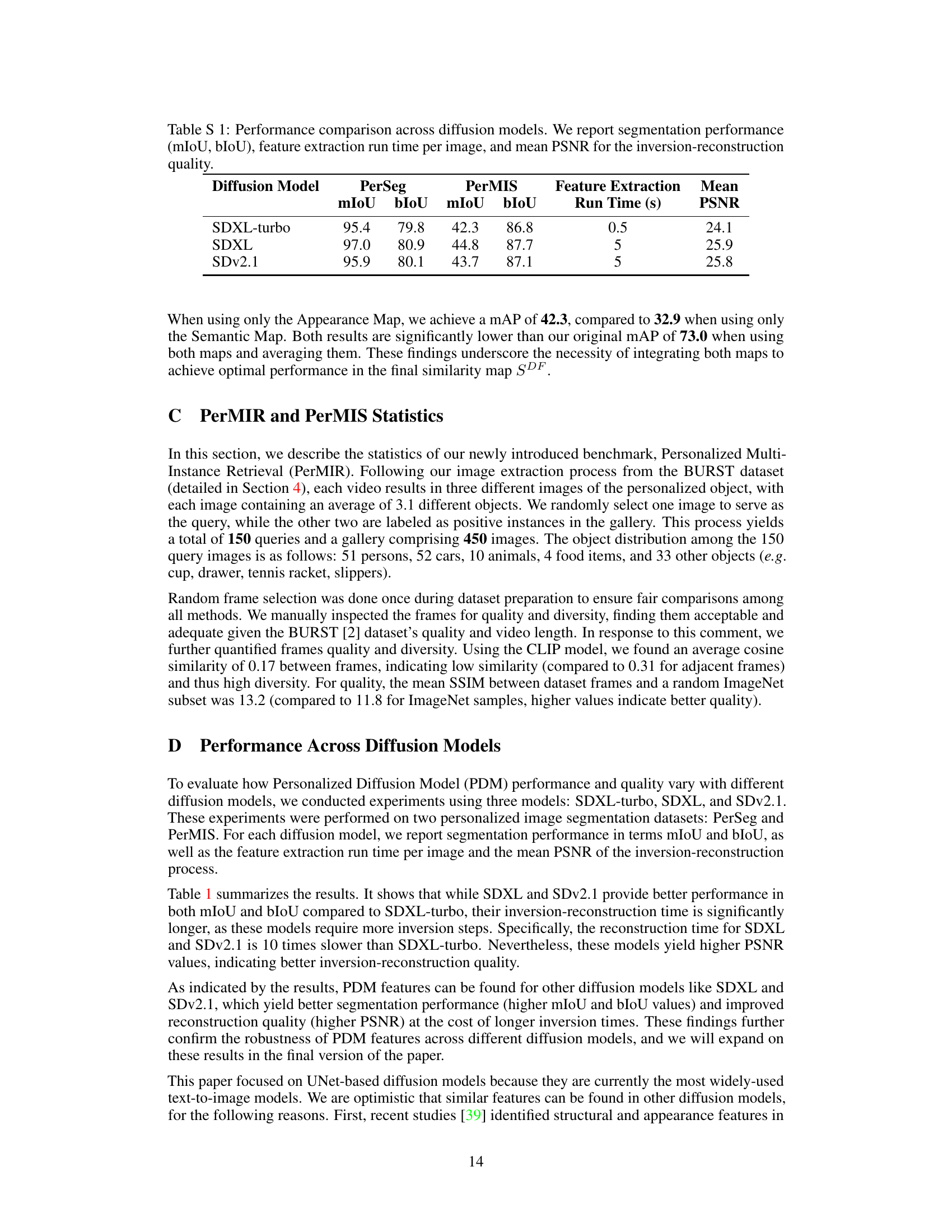
This table compares the performance of three different diffusion models (SDXL-turbo, SDXL, and SDv2.1) on two personalized image segmentation datasets (PerSeg and PerMIS). For each model, it reports the mean Intersection over Union (mIoU) and boundary IoU (bIoU) scores, the time taken for feature extraction per image, and the mean Peak Signal-to-Noise Ratio (PSNR) which measures the quality of the image reconstruction after the inversion process.

This table presents a comparison of the performance achieved using two different methods for combining appearance and semantic features: simple feature averaging (as used in the main paper) and weighted averaging (optimized using a training set). The results are shown for two datasets: ROxford-Hard (a standard benchmark dataset for image retrieval) and PerMIR (a new benchmark dataset introduced in this paper which includes multiple instances of the same object class). The weighted averaging approach significantly outperforms the simple averaging approach on both datasets, demonstrating the potential benefits of using more sophisticated methods for feature fusion, particularly when a training set is available.
Full paper#