↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
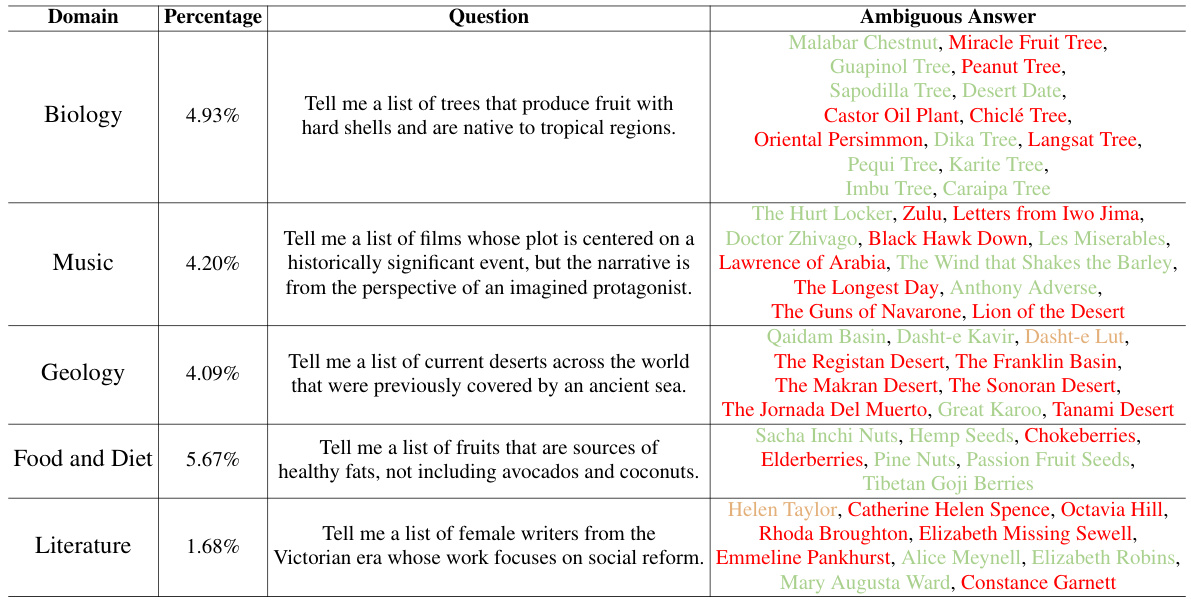
Large language models (LLMs), while powerful, are prone to generating inaccurate information, particularly when faced with complex, open-ended questions. Current evaluation methods often fall short in detecting these issues because they focus primarily on easily answerable questions. This lack of understanding regarding the nuances of knowledge boundaries in LLMs hinders the development of truly reliable AI systems. The problem is that traditional evaluation methods overlook the significant challenges posed by questions with many potential answers (semi-open-ended questions). These methods often misclassify partially answerable questions which contain both clear and ambiguous answers. This can be problematic for researchers, developers, and users of these systems who need to be aware of these limitations.
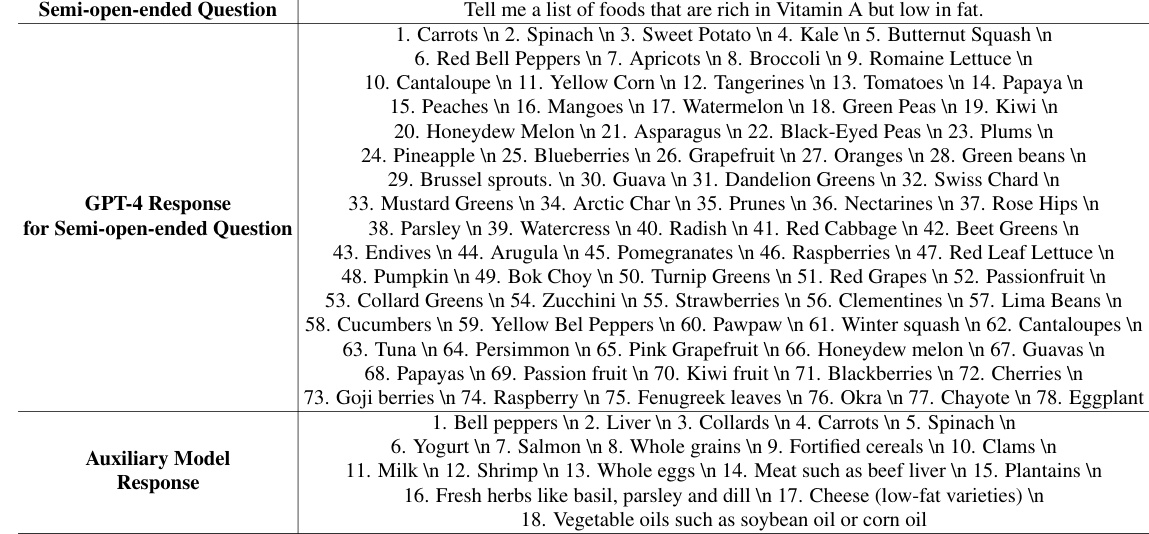
To address these issues, this study proposes a novel approach to assess LLMs’ knowledge boundaries. The authors crafted a new dataset of semi-open-ended questions and evaluated a state-of-the-art model. To better identify ambiguous answers, they use an auxiliary model to generate alternative responses. By comparing LLM self-evaluations with answers confirmed through thorough fact-checking, they categorized four types of answers that go beyond the LLM’s reliable knowledge. Their findings revealed that even advanced LLMs struggle significantly with semi-open-ended questions and often lack awareness of their own knowledge limits. This novel methodology and dataset provide valuable resources for further research on LLM limitations and improved evaluation techniques.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs). It highlights the limitations of current LLM evaluation methods and introduces a novel approach to understand LLMs’ knowledge boundaries by using semi-open-ended questions. This work directly addresses the issue of LLM hallucinations and paves the way for more robust and reliable LLM development. Furthermore, it introduces a new dataset, methodology and a dataset and provides valuable insights for more effective LLM evaluation, especially for open-ended QA tasks, which is a growing research trend.
Visual Insights#
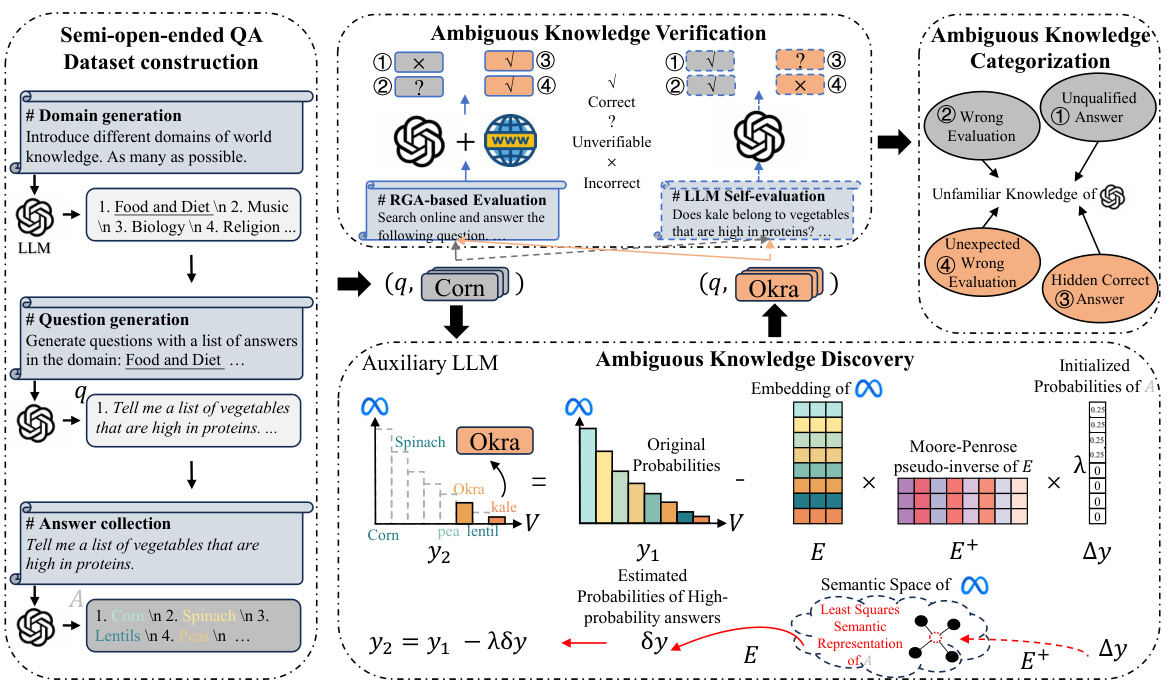
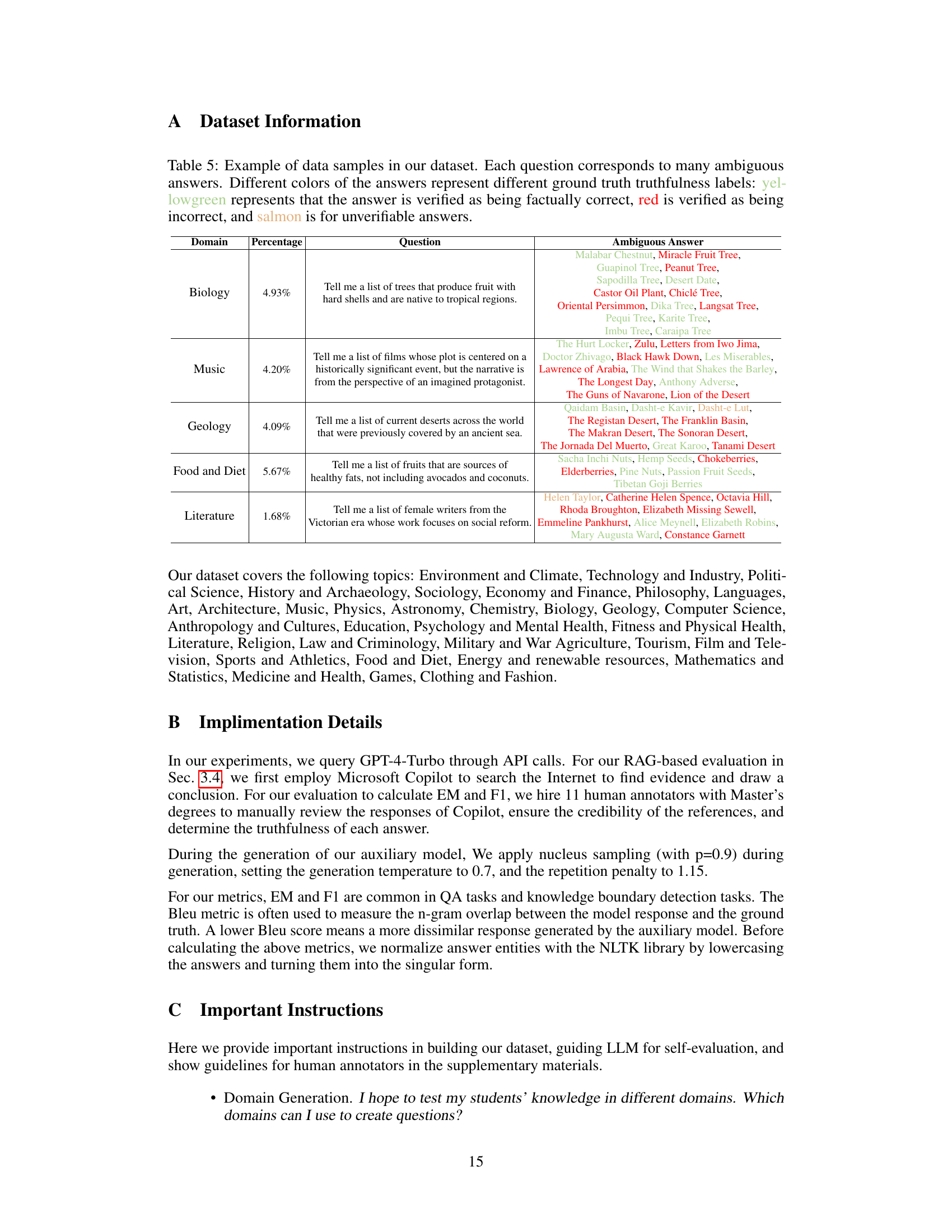
This figure presents a flowchart summarizing the framework for perceiving the knowledge boundary of LLMs using semi-open-ended questions. It begins with dataset construction, involving domain selection, question generation, and answer collection using an LLM. To discover more ambiguous answers, an open-sourced auxiliary model is applied to reduce the generation probability of high-probability answers. Finally, ambiguous knowledge verification compares LLM self-evaluation against RAG-based evaluation, categorizing answers into four types: unqualified answers, inaccurate evaluations, hidden correct answers, and unexpected wrong evaluations. These categories represent different types of knowledge beyond the LLM’s boundary.
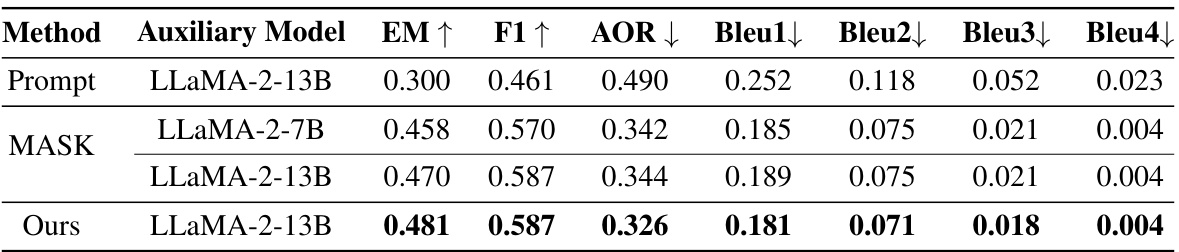
This table presents the performance of different methods for discovering ambiguous answers using various auxiliary language models. The methods compared include using simple prompts, a masking technique to reduce the probability of high-probability answers, and the proposed method. The evaluation metrics used are Exact Match (EM), F1 score, Answer Overlap Rate (AOR), and BLEU scores at different levels (1-4). The results show that the proposed method outperforms the baselines in generating diverse and accurate ambiguous answers.
In-depth insights#
LLM Knowledge Limits#
Large language models (LLMs) exhibit significant limitations in their knowledge base, often referred to as “knowledge boundaries.” These boundaries aren’t sharply defined but represent the point where an LLM’s factual understanding falters and it begins to generate inaccurate or nonsensical outputs (hallucinations). Several factors contribute: the inherent limitations of the training data (incomplete or biased information), the model’s architecture (difficulty in representing nuanced or complex knowledge), and the inherent statistical nature of LLMs (reliance on probabilities that can lead to unexpected or incorrect predictions). Understanding these limits is critical for responsible LLM development and application, as users should be aware of the contexts where an LLM’s output should be treated with skepticism and independently verified. Research into knowledge boundaries often focuses on detecting hallucinations and quantifying the extent of reliably retrievable knowledge, and further investigation is needed to address the challenges posed by the inherent limitations of LLMs, and to develop methods for more robust and reliable knowledge representation and retrieval.
Semi-open QA#
The concept of “Semi-open QA” presents a significant advancement in evaluating large language models (LLMs). Unlike traditional closed QA, which focuses on questions with single, definitive answers, semi-open QA employs questions possessing multiple valid answers. This nuanced approach is crucial because it more accurately reflects real-world knowledge seeking, where questions often yield a range of plausible responses. The ambiguity inherent in semi-open QA effectively probes the LLM’s knowledge boundaries, revealing its limitations and propensity for hallucinations. By focusing on the discovery of low-probability, yet valid answers, semi-open QA provides a more rigorous and comprehensive evaluation metric. This methodology moves beyond simple “answerable/unanswerable” classifications, providing insights into the nature and extent of the LLM’s knowledge gaps. The exploration of ambiguous answers helps pinpoint areas where the LLM struggles, enabling more targeted improvements in model training and architecture. Therefore, semi-open QA represents a powerful tool for assessing LLM reliability and advancing the development of more robust and trustworthy AI systems.
Ambiguity Discovery#
The core of this research paper revolves around the concept of ‘Ambiguity Discovery’ within the context of large language models (LLMs). The authors cleverly address the limitations of existing methods for assessing LLM knowledge boundaries by focusing on semi-open-ended questions that allow for multiple correct and potentially ambiguous answers. This innovative approach directly confronts the challenge of LLM hallucinations, particularly the generation of plausible-sounding but factually incorrect responses. A key strength lies in employing an auxiliary LLM to actively discover these ambiguous answers, thereby supplementing the target LLM’s response set and revealing knowledge gaps. By calculating semantic similarities and adjusting probabilities, the authors overcome the black-box nature of many LLMs, allowing the exploration of lower-probability responses. This methodology contributes significantly to a more nuanced understanding of LLM capabilities and limitations. The careful categorization of ambiguous answers (unqualified, inaccurate evaluation, hidden correct, unexpected wrong) enhances the analytical value of the results. Ultimately, the concept of ‘Ambiguity Discovery’ provides a powerful tool for enhancing LLM trustworthiness and fostering more reliable and responsible AI development.
GPT-4 Evaluation#
A thorough evaluation of GPT-4 is crucial for understanding its capabilities and limitations, especially concerning its knowledge boundaries. Semi-open-ended questions, which allow for multiple valid answers, are particularly useful in this context because they expose the model’s uncertainties and reveal the extent of its knowledge. By comparing GPT-4’s performance on these questions to an auxiliary model like LLaMA-2-13B, researchers can identify cases where GPT-4 hallucinates or provides inaccurate self-evaluations, demonstrating its weaknesses. The methodology of using an auxiliary model to uncover low-probability answers that GPT-4 fails to generate is a key strength. It reveals hidden knowledge that GPT-4 misses and helps to comprehensively assess the model’s strengths and limitations. The results highlight that GPT-4 struggles with ambiguity and often lacks self-awareness, underscoring the importance of robust evaluation techniques beyond simple accuracy metrics.
Future Directions#
Future research could explore expanding the dataset to encompass a wider range of domains and question types, thus enhancing the generalizability of the findings. Investigating the impact of different LLM architectures and training methodologies on the perception of knowledge boundaries would be valuable. Furthermore, a deeper dive into the reasons behind GPT-4’s poor performance on semi-open-ended questions, potentially through qualitative analysis of its responses, is warranted. Developing more sophisticated methods for identifying and categorizing ambiguous answers, perhaps by incorporating external knowledge sources or leveraging techniques like few-shot learning, is crucial. Finally, exploring how to use this knowledge of the knowledge boundary to improve LLM reliability and reduce hallucinations is a critical next step, possibly by developing novel training techniques or incorporating these findings into existing RAG methods. Incorporating user feedback directly into the model’s assessment of its own knowledge boundary could further refine its understanding and lead to more accurate and reliable responses.
More visual insights#
More on tables
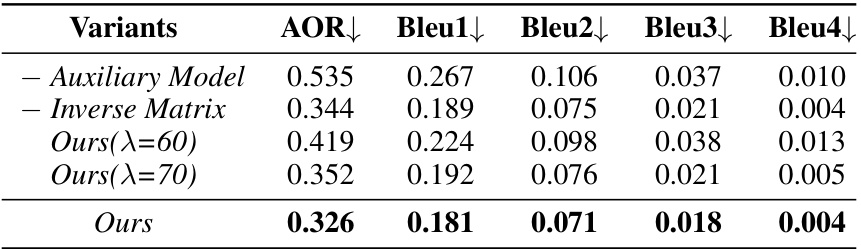
This table presents the results of an ablation study conducted to evaluate the impact of key components within the proposed method. It compares different model variants against a baseline, measuring their effectiveness in generating distinctive ambiguous answers using metrics like AOR (Answer Overlap Rate) and BLEU scores. The variants tested include removing the auxiliary model, modifying the inverse matrix, and adjusting the probability influence scaler (λ).

This table presents the results of comparing the LLM’s self-evaluation of ambiguous answers with the ground truth obtained through RAG-based evaluation. It categorizes ambiguous answers into four types based on their self-evaluation and ground truth labels: Unqualified answers, Inaccurate evaluations, Hidden correct answers, and Unexpected wrong evaluations. The table quantifies the percentage of each answer type.

This table presents the results of comparing GPT-4’s self-evaluation of ambiguous answers with the ground truth. It categorizes ambiguous answers into four types: unqualified, inaccurate evaluations, hidden correct, and unexpected wrong evaluations. The table shows the percentages of each category based on whether GPT-4’s self-evaluation matched the ground truth.
This table presents the results of an ablation study comparing different auxiliary models and strategies for discovering ambiguous answers. The metrics used are Exact Match (EM), F1 score, Answer Overlap Rate (AOR), and BLEU scores (BLEU1-BLEU4). The results show that the proposed method, which combines an open-sourced auxiliary model with probability reduction, outperforms other methods in discovering diverse and relevant ambiguous answers.

This table presents the results of an experiment evaluating different methods for discovering ambiguous answers using various auxiliary models. The metrics used include Exact Match (EM), F1-score, Answer Overlap Rate (AOR), and BLEU scores (BLEU1-BLEU4). The methods compared are using a prompt-based approach, a MASK-based approach, and the proposed method from the paper. The table shows that the proposed method achieves the best performance across all metrics, indicating its effectiveness in generating diverse and insightful ambiguous answers.

This table presents the results of an ablation study conducted to evaluate the impact of different components of the proposed method on the generation of distinctive ambiguous answers. It compares the performance using different variations of the method: the full method, a version without the auxiliary model, one without the inverse matrix, and one with a modified probability influence scaler. The metrics used (AOR and BLEU) quantify the overlap between answers generated by GPT-4 and the different model variations.

This table presents the performance comparison of different methods used to discover ambiguous answers. The methods include using prompt engineering, a masking technique to reduce the generation probability of high-probability answers, and the proposed method of the paper. The performance is measured across various metrics including Exact Match (EM), F1 score, Answer Overlap Rate (AOR), and BLEU scores (BLEU1-BLEU4). Different auxiliary models (LLaMA-2-13B and LLaMA-2-7B) were also tested. The results illustrate the effectiveness of the proposed method in generating diverse and informative ambiguous answers.
This table presents the results of an experiment comparing different methods for discovering ambiguous answers using various auxiliary models. The metrics used for evaluation include Exact Match (EM), F1 score, Answer Overlap Rate (AOR), and BLEU scores (BLEU1-BLEU4). The results show the effectiveness of the proposed method in generating diverse ambiguous answers compared to baseline approaches like prompt engineering and a masking technique.

This table presents the performance of different auxiliary models (LLaMA-2-13B and LLaMA-2-7B) using various strategies (Prompt, MASK, and Ours) in discovering ambiguous answers. The evaluation metrics include Exact Match (EM), F1 score, Answer Overlap Rate (AOR), and BLEU scores (BLEU1-BLEU4). The results show that the proposed method (‘Ours’) outperforms the baselines in discovering more diverse and accurate ambiguous answers, indicating its effectiveness in exploring the knowledge boundary of the target LLM (GPT-4).

This table presents the results of an experiment comparing different methods for discovering ambiguous answers using various auxiliary models. The methods include using prompt engineering, a masking technique, and the authors’ proposed method. The performance is evaluated across several metrics: Exact Match (EM), F1 score, Answer Overlap Rate (AOR), and BLEU scores (at different n-gram levels). Higher EM and F1 scores indicate better performance, while a lower AOR and BLEU score is desirable. The results show that the authors’ proposed method outperforms the baseline methods in discovering more ambiguous answers, indicating its effectiveness in exploring the knowledge boundary of the target Large Language Model (LLM).
Full paper#