↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Creating realistic 3D scene representations from a limited number of images (few-shot novel view synthesis) is a challenging problem in computer vision. Existing methods often struggle with sparse data, leading to inaccurate or incomplete scene reconstructions. The challenge is further amplified when dealing with unstructured scene representations, as commonly seen in Gaussian Splatting methods. These methods tend to overfit to available data resulting in poor rendering performance for previously unseen viewpoints.
This paper introduces FewViewGS, a novel approach that overcomes these limitations. FewViewGS uses a multi-stage training strategy with matching-based consistency constraints imposed on novel views. This means the model learns to render novel views that are coherent with the existing views by leveraging geometric and semantic information. In addition, FewViewGS introduces a locality preserving regularization for 3D Gaussians, improving the accuracy and reducing artifacts in the rendered novel views. Experiments demonstrate that FewViewGS achieves competitive or better results compared to state-of-the-art methods, particularly in low-data scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances the state-of-the-art in few-shot novel view synthesis. By introducing a novel multi-stage training scheme and a locality-preserving regularization, the researchers demonstrate competitive or superior performance compared to existing methods. This opens up new avenues for research in creating high-quality 3D scene representations from limited data, which is highly relevant to various applications like VR/AR, robotics, and autonomous navigation. The improved efficiency and robustness of the proposed method also hold significant implications for real-time applications.
Visual Insights#

This figure illustrates the FewViewGS pipeline, a multi-stage training approach for novel view synthesis. It shows three stages: pre-training (using only known views), intermediate (introducing correspondence-driven losses for novel views sampled between known views), and tuning (fine-tuning on known views). The pre-training and tuning stages focus on optimizing Gaussians using color re-rendering loss and regularization. The intermediate stage leverages correspondences between known views to project and render virtual views, using color, geometry, and semantic losses to enforce consistency between known and novel views.
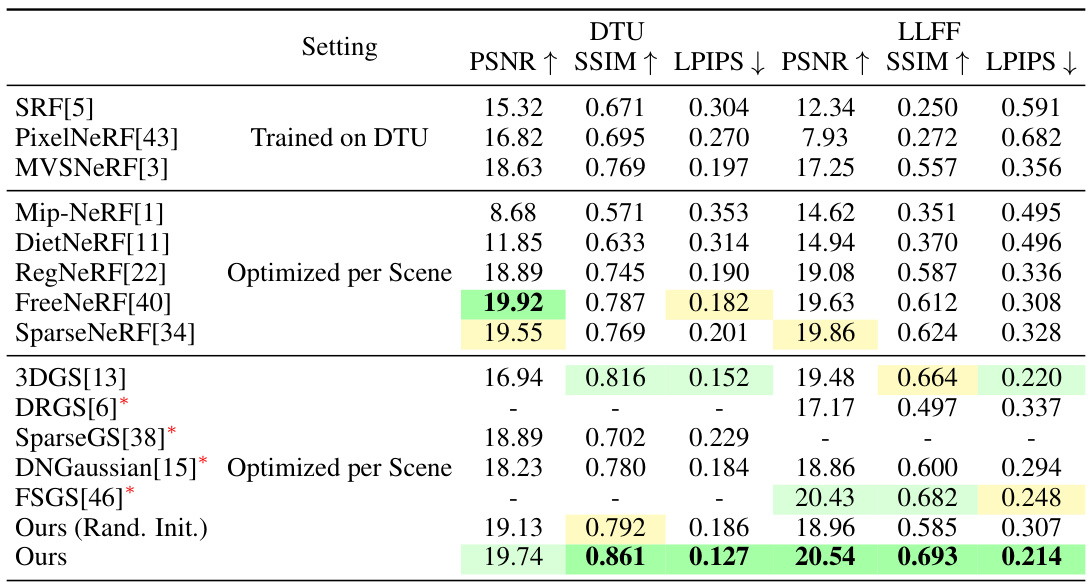
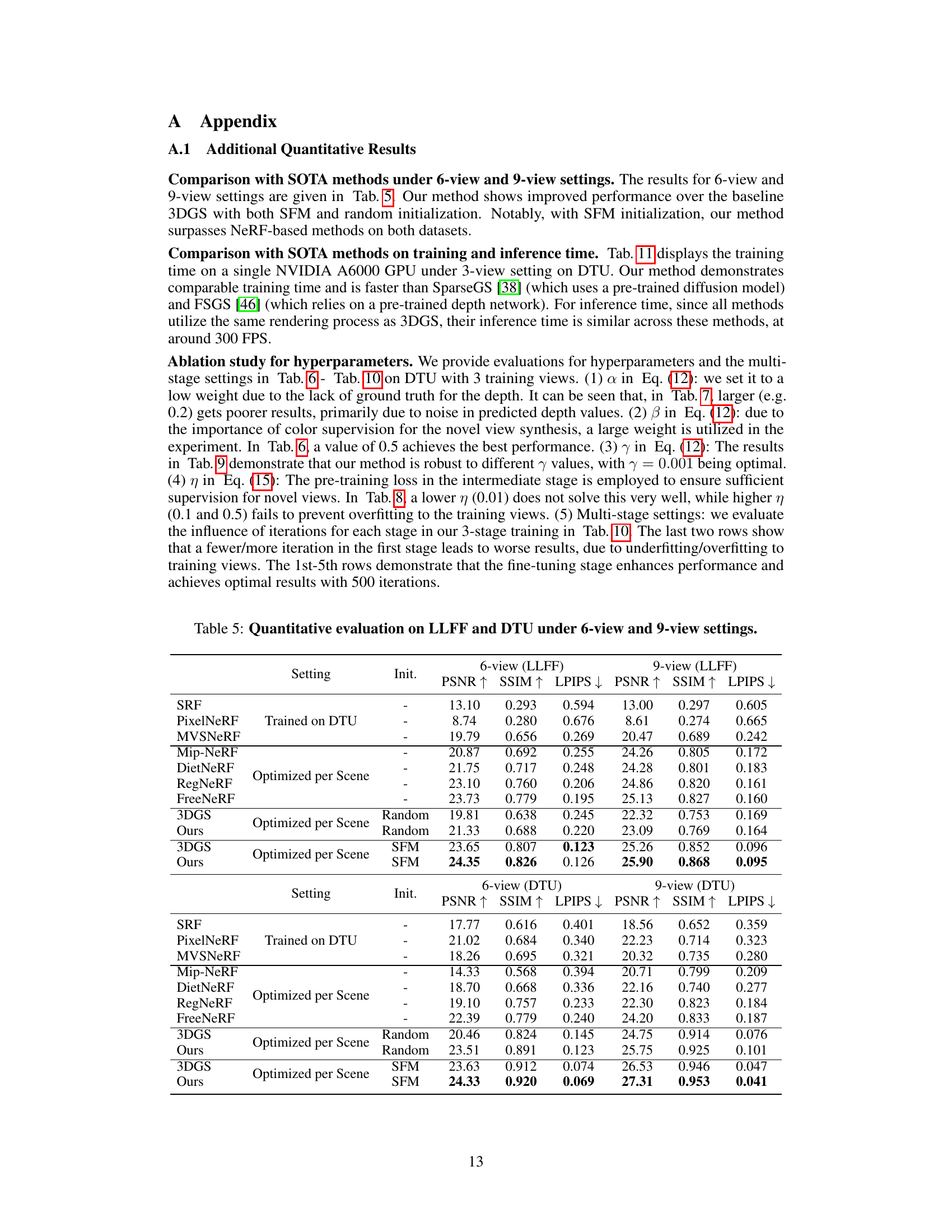
This table presents a quantitative comparison of the proposed FewViewGS method against other state-of-the-art techniques for novel view synthesis using only three training views on the DTU and LLFF datasets. The comparison includes several metrics such as PSNR, SSIM, and LPIPS, to evaluate the quality of generated novel views. The table highlights the superior performance of FewViewGS compared to other methods, especially those optimized per scene.
In-depth insights#
Few-Shot View Synth#
Few-shot view synthesis tackles the challenge of reconstructing 3D scenes and generating novel views from limited input images. This is a significant departure from traditional methods that require extensive datasets. The core difficulty lies in effectively learning a robust 3D representation from sparse data, avoiding overfitting and producing high-quality novel views. Successful approaches often incorporate techniques such as multi-stage training, regularization strategies (e.g., depth or semantic consistency losses), and clever data augmentation schemes. The trade-off between rendering quality, computational efficiency, and the number of training views remains a key area of active research, with ongoing efforts to push the boundaries of what’s achievable in low-data regimes. Prior work demonstrates that leveraging multi-view geometry and exploiting image correspondences can significantly improve results, especially in dealing with regions not observed directly in the training images. Future work will likely explore improved 3D representations, more sophisticated regularization methods, and ways to leverage other forms of weak supervision, such as semantic labels or depth cues.
Multi-Stage Training#
The proposed multi-stage training strategy is a key innovation, addressing the challenges of few-shot novel view synthesis. The initial pre-training stage leverages only the available training views to establish a foundational scene representation, preventing overfitting to sparse data. This is followed by an intermediate stage focused on novel view consistency. Here, geometric constraints, derived from image matching, are used to supervise the synthesis of novel views, ensuring coherence with the known views. Finally, a tuning stage refines the model with further optimization using only the initial known views, balancing knowledge transfer and preventing overfitting to novel views. This phased approach facilitates seamless knowledge propagation, enabling the model to generate high-quality novel views with limited training data. The strategy’s effectiveness is clearly demonstrated by the experimental results, showcasing its superior performance compared to other single-stage training methods.
Gaussian Splatting#
Gaussian splatting is a novel technique in 3D scene representation that leverages the efficiency and accuracy of Gaussian distributions. Instead of using complex neural networks, it represents a scene using a collection of 3D Gaussians, each with properties like position, covariance, opacity, and color. This explicit representation offers significant advantages in terms of rendering speed and training efficiency, making it particularly well-suited for real-time applications and scenarios with limited computational resources. However, the method’s performance can degrade significantly when the input data is sparse, which limits its applicability to few-shot novel view synthesis tasks. Researchers are actively exploring methods to mitigate this limitation, including multi-stage training and the incorporation of consistency constraints to improve rendering quality under data scarcity. The unstructured nature of the Gaussian splatting representation also presents challenges for effective regularization and artifact removal. Addressing these challenges will be crucial to further improve the robustness and versatility of Gaussian splatting for various 3D computer graphics applications.
Novel View Matching#
Novel view matching, in the context of 3D scene reconstruction from sparse views, is a crucial technique to improve the accuracy and consistency of novel view synthesis. It addresses the challenge of generating realistic images from viewpoints not present in the training data by establishing correspondences between known views and newly synthesized views. The core idea is to leverage existing image pairs to guide the creation of intermediate views, enforcing consistency constraints on color, geometry, and even semantic information. This approach differs significantly from methods relying on depth estimation or diffusion models, which often struggle with sparse input. By employing feature matching techniques, the method robustly warps corresponding pixels from known views onto randomly sampled novel viewpoints. This approach mitigates issues stemming from inaccuracies in depth estimation or the limitations of diffusion models. This warping process, combined with loss functions that penalize inconsistencies, enforces coherence, resulting in visually plausible novel views. The success of novel view matching hinges on the effectiveness of the feature matching algorithm and the robustness of the warping process to handle any noise or inaccuracies in the input data.
Locality Regularization#
Locality regularization, in the context of 3D Gaussian splatting for novel view synthesis, addresses the issue of rendering artifacts arising from the sparsity of input images. Standard photometric losses fail to enforce smoothness in local color variations, particularly problematic with limited data. This technique works by penalizing deviations of a Gaussian’s color from the colors of its nearest neighbors in 3D space. The penalty is weighted by a distance function, decreasing influence as spatial distance grows. This preserves local color structure, effectively removing artifacts by ensuring smooth transitions between regions of the scene, especially beneficial in sparse scenarios where overfitting is a major concern. The method enhances the visual quality of novel views by preventing discontinuities and ensuring a more coherent rendering, ultimately improving the overall realism of the synthesized images.
More visual insights#
More on figures

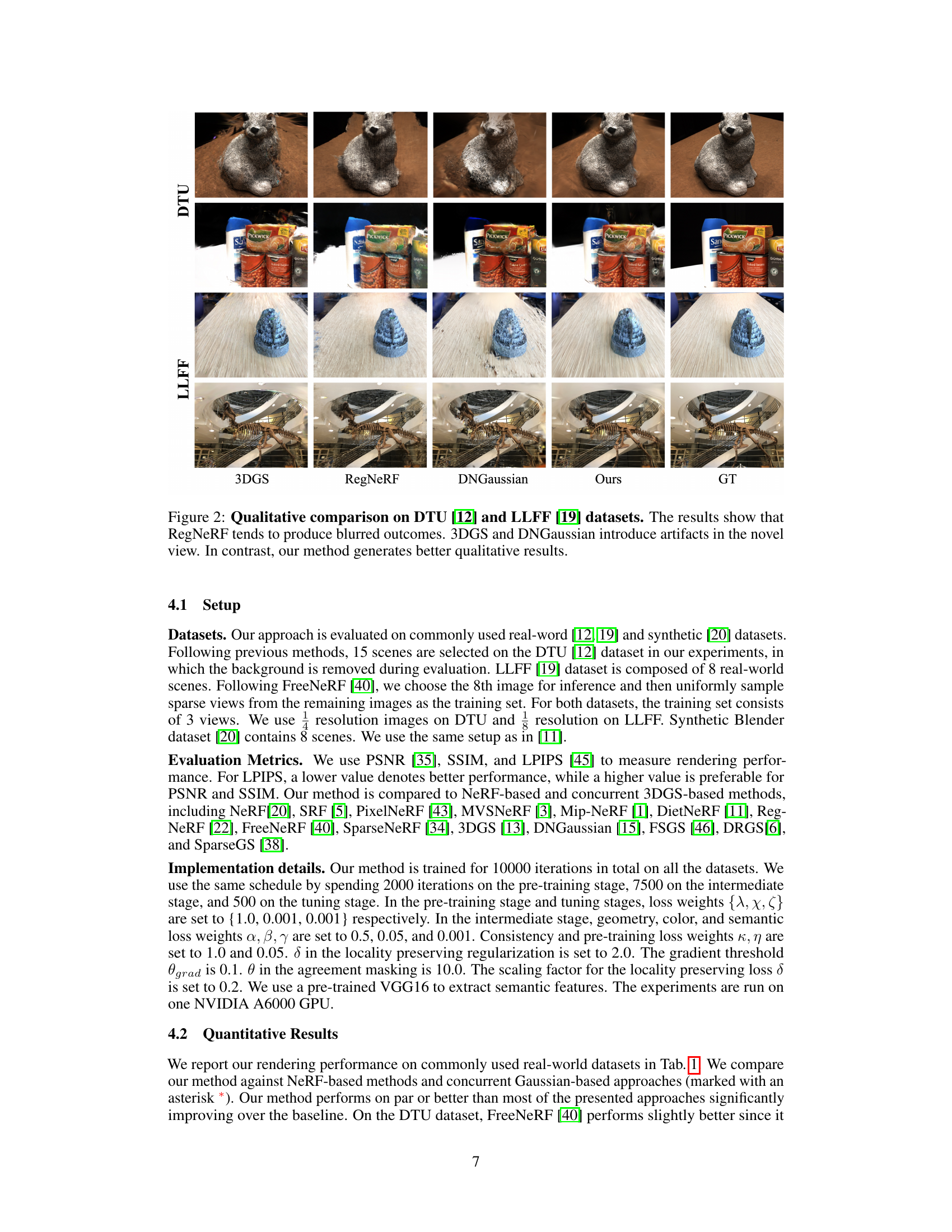
This figure displays a qualitative comparison of novel view synthesis results on the DTU and LLFF datasets using four different methods: 3DGS, RegNeRF, DNGaussian, and the proposed FewViewGS method. Ground truth images are also shown for comparison. The results illustrate that FewViewGS produces sharper, more artifact-free images compared to the other methods, especially in challenging scenarios where other methods lead to blurred or distorted outputs.

This figure shows a qualitative comparison of novel view synthesis results on the DTU and LLFF datasets using different methods: 3DGS, RegNeRF, DNGaussian, and the proposed FewViewGS method. The results highlight that FewViewGS produces sharper, more artifact-free images compared to the other methods, particularly in areas with less supervision.

This figure illustrates the multi-stage training process of the FewViewGS method. It shows three stages: pre-training, intermediate, and tuning. The pre-training and tuning stages optimize 3D Gaussians using only known views, focusing on color re-rendering loss and regularization. The intermediate stage leverages correspondences between training image pairs, warping them to novel views sampled between them. This stage applies color, geometry, and semantic losses to ensure consistency between novel and known views.

This figure compares the qualitative results of novel view synthesis on the DTU and LLFF datasets using different methods, including RegNeRF, 3DGS, DNGaussian, and the proposed FewViewGS method. It highlights that FewViewGS produces sharper and more artifact-free results than the other methods, addressing the limitations of RegNeRF’s blurriness and artifacts in 3DGS and DNGaussian, especially in novel view generation.

This figure shows the qualitative comparison of novel view synthesis results using different combinations of loss functions. The first image shows results from the baseline 3D Gaussian Splatting (3DGS). Subsequent images show the improvements achieved by adding geometric consistency loss, then color consistency loss, and finally semantic consistency loss. The last image shows the ground truth. The improvements in visual quality are evident as more loss terms are incorporated, demonstrating the effectiveness of the multi-view consistency constraint in enhancing the realism and coherence of the synthesized novel views.

This figure compares the visual results of novel view synthesis using different feature networks for semantic loss in FewViewGS. It demonstrates the impact of the choice of feature extractor on the final image quality, showing results with CLIP, DINOv2, and VGG16 features, and comparing these to the ground truth (GT) and the baseline 3DGS method.

This figure compares the performance of two feature matching algorithms, RoMa and SIFT, in finding correspondences between two images of similar objects (Image 1 and Image 2). RoMa demonstrates superior matching capabilities with more accurate and numerous correspondences highlighted in red lines, compared to SIFT, which shows significantly fewer and less precise matches. This difference in matching quality directly affects the subsequent novel view synthesis process. The more accurate matches provided by RoMa contribute to improved visual coherence and reduce artifacts in the final rendered novel view.

This figure shows an ablation study on feature matching. The leftmost image shows the results using 3DGS without feature matching. The next two images show the results with feature matching, with the middle image showing results when using only single-view correspondences (i.e., no multi-view consistency). The rightmost image shows the ground truth. The results show that feature matching greatly improves the results, with multi-view consistency further improving the results. This demonstrates the importance of feature matching and multi-view consistency for accurate novel view synthesis.

This figure shows a comparison of novel view synthesis results using single-stage training versus multi-stage training, highlighting the improvements achieved by enforcing multi-view consistency constraints in the multi-stage approach. The single-stage training leads to blurry results, especially noticeable in the Smurf and grocery scenes, indicating issues with depth and view consistency. In contrast, the multi-stage training produces sharper, more realistic novel views, demonstrating the effectiveness of the proposed method in handling few-shot scenarios. The ground truth (GT) images are provided for reference.
More on tables
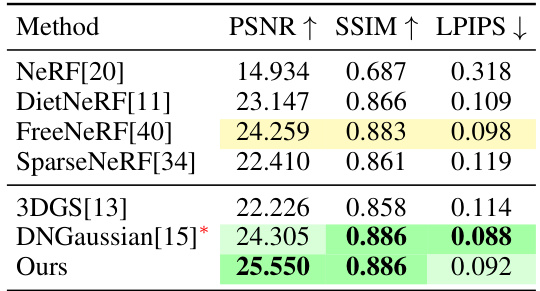
This table presents a quantitative comparison of the proposed FewViewGS method against other state-of-the-art novel view synthesis methods on the Blender synthetic dataset. The evaluation uses 8 training views and reports PSNR, SSIM, and LPIPS scores, demonstrating the superior performance of FewViewGS.

This table presents the ablation study performed on the DTU dataset using 3 training views. It systematically evaluates the impact of different components of the FewViewGS model on the final performance metrics (PSNR, SSIM, LPIPS). Each row represents a different configuration, showing the results with and without various components like Llocality (locality-preserving regularization), Lgeom (geometry loss), Lcolor (color loss), Lsem (semantic loss), and different feature extraction backbones for Lsem, as well as with and without the minimum operation in the consistency loss calculation and single-stage vs multi-stage training. Row xiv shows the final model’s performance with all components included.
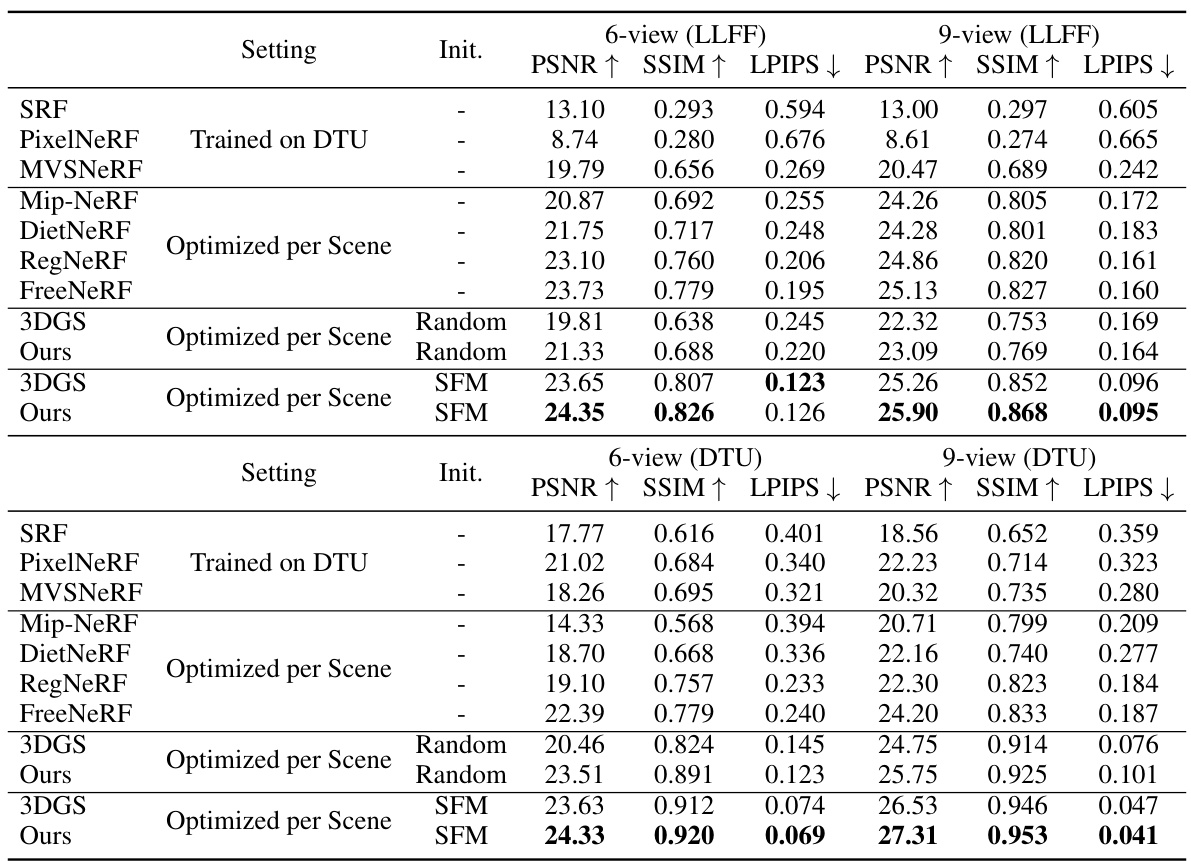
This table presents a quantitative comparison of the proposed FewViewGS method against several state-of-the-art (SOTA) novel view synthesis methods on the DTU and LLFF datasets. The evaluation is performed using 3 training views for all methods. The table shows PSNR, SSIM, and LPIPS scores for each method on each dataset, enabling a direct comparison of rendering quality. Concurrent works are indicated with an asterisk.

This ablation study analyzes the impact of each component of the proposed FewViewGS method on the DTU dataset using 3 training views. It examines the contribution of the locality preserving regularization, the novel view consistency loss (broken down into its geometric, color, and semantic components), the choice of feature network for the semantic loss, the use of the min operation within the consistency loss, the use of a multi-stage training scheme versus a single-stage scheme, and the use of feature matching versus no feature matching. The results show the relative improvement in PSNR, SSIM, and LPIPS for each variation.

This table presents a quantitative comparison of the proposed FewViewGS method against state-of-the-art techniques for novel view synthesis using only three training views on the DTU and LLFF datasets. The metrics used to assess the performance are PSNR, SSIM, and LPIPS. Higher PSNR and SSIM values indicate better performance, while a lower LPIPS value is preferred. The table includes results from various methods, both NeRF-based and 3D Gaussian Splatting-based, highlighting FewViewGS’s competitive performance.
Full paper#