TL;DR#
Human-Object Interaction (HOI) detection is crucial for visual scene understanding, but existing methods often struggle with compositional reasoning and limited generalization abilities. Many models trained on text-image pairs neglect mid/low-level visual cues, hindering their performance on complex interactions. This often leads to difficulties in discovering new interactions and handling long-tailed distributions. These issues arise from the challenge of correctly inferring semantics and locations of entities and comprehending the events between them.
This paper introduces DIFFUSIONHOI, a new approach that tackles these challenges by integrating large relation-driven diffusion models. Instead of relying solely on high-level text-image alignment, DIFFUSIONHOI leverages the generative capabilities of diffusion models to learn relationships between humans and objects. It utilizes an inversion-based strategy to extract and encode relationship patterns from images, providing a more holistic and nuanced representation of the interaction. This leads to significant improvements in accuracy and generalization, especially on zero-shot tasks, and outperforms previous state-of-the-art methods on multiple benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it demonstrates the effectiveness of incorporating large relation-driven diffusion models into human-object interaction (HOI) detection. It addresses the limitations of existing methods that struggle with compositional reasoning and mid/low-level visual cues by leveraging diffusion models’ ability to generate images depicting specific interactions, achieving state-of-the-art performance on various benchmarks. This opens up new avenues for research in visual relationship understanding and zero-shot HOI detection, leading to more robust and generalizable visual scene understanding systems.
Visual Insights#
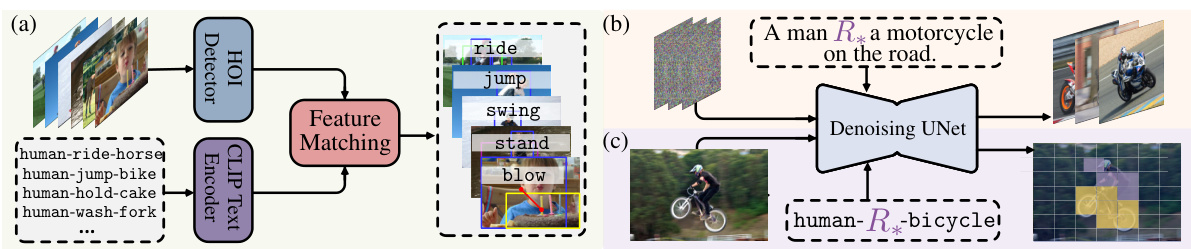
🔼 This figure illustrates three different approaches to Human-Object Interaction (HOI) detection. (a) shows existing methods that rely solely on linguistic knowledge, using a text encoder and a detector. (b) depicts the proposed method, DIFFUSIONHOI, which leverages text-to-image diffusion models to generate images based on text prompts, transferring knowledge from the diffusion model to the HOI detector. This includes using the relation between the human and object in the text prompt. (c) illustrates the feature extraction component of DIFFUSIONHOI, which uses the diffusion model to extract features specific to the interaction, conditioned by the relation embeddings. This conditioned feature extraction further assists in HOI detection. The figure highlights the difference between previous methods that utilize linguistic knowledge alone and the proposed method that integrates image generation and conditioned feature extraction capabilities of diffusion models for improved performance and knowledge transfer.
read the caption
Figure 1: Existing solutions utilize mere linguistic knowledge (a). Our solution utilizes both text-prompt image generation (b) and conditioned feature extraction (c) abilities of diffusion models for knowledge transfer.

🔼 This table presents a comparison of the performance of various state-of-the-art methods and the proposed DIFFUSIONHOI model on two benchmark datasets for Human-Object Interaction (HOI) detection: HICO-DET and V-COCO. The results are broken down by different metrics (Full, Rare, Non-Rare, Known Object) to provide a comprehensive evaluation of the models’ capabilities in handling various aspects of the HOI detection task. The table shows that DIFFUSIONHOI achieves superior performance compared to existing methods across various metrics and datasets.
read the caption
Table 1: Quantitative results for regular HOI detection on HICO-DET [20] and V-COCO [21].
In-depth insights#
DiffusionHOI: Overview#
DiffusionHOI presents a novel approach to human-object interaction (HOI) detection, leveraging the power of large relation-driven diffusion models. Unlike traditional methods relying solely on visual-linguistic models, DiffusionHOI effectively incorporates mid- and low-level visual cues, enhancing compositional reasoning. The core idea involves using an inversion-based strategy to learn relation patterns between humans and objects, subsequently employing these embeddings as textual prompts to guide diffusion models. This process results in generated images that explicitly depict specific interactions, facilitating the extraction of HOI-relevant features. A key advantage is the model’s ability to handle novel concepts, exhibiting strong zero-shot capabilities. Further, DIFFUSIONHOI employs a relation-centric contrastive learning approach to improve the understanding of relational semantics, ultimately improving overall performance and offering a robust framework for HOI detection. The method demonstrates superior results compared to existing state-of-the-art approaches across various benchmarks and experimental settings.
Relation-Driven Learning#
Relation-driven learning, in the context of a research paper on human-object interaction (HOI) detection, likely focuses on improving the model’s ability to understand and represent relationships between humans and objects within an image. This goes beyond simply detecting individual entities; it aims to capture the nuanced interactions, actions, and contexts. The core idea revolves around learning rich, meaningful representations of these relationships, possibly through dedicated relation embedding vectors or advanced attention mechanisms that prioritize relational information. A key aspect could be disentangling object and relation features to facilitate more accurate and robust interaction understanding, potentially using techniques like cycle consistency training or contrastive learning focused on the relational aspects. This approach addresses common limitations of HOI detection models—difficulty handling novel or unseen interactions—by encouraging the model to learn generalizable relational patterns. The effectiveness is likely evaluated by the model’s performance on diverse benchmark datasets, especially those emphasizing zero-shot or few-shot learning settings.
HOI Knowledge Transfer#
The heading ‘HOI Knowledge Transfer’ suggests a crucial aspect of leveraging pre-trained models for human-object interaction (HOI) detection. The core idea revolves around effectively transferring knowledge learned by a large-scale pre-trained model (likely a visual-linguistic model like CLIP or a diffusion model) to a new, more specialized HOI detection model. This transfer avoids the need for extensive training from scratch, significantly reducing computational costs and data requirements. A key challenge lies in adapting the general knowledge of the pre-trained model to the specific nuances of HOI recognition, which involves understanding not only objects and humans individually but also their complex interactions. The method of knowledge transfer could involve techniques like feature extraction from intermediate layers of the pre-trained model, using these features to initialize or guide training of the HOI detector, or perhaps employing techniques like prompt engineering to steer the pre-trained model towards generating HOI-relevant information. Success hinges on resolving the inherent domain gap between general image understanding and the fine-grained details of human actions and object relations needed for HOI. The effectiveness would depend heavily on the chosen pre-trained model’s architecture and the chosen knowledge transfer method. A successful approach will likely lead to improved performance, particularly in zero-shot or low-data scenarios where fully training a model is infeasible.
Zero-Shot HOI#
Zero-shot human-object interaction (HOI) detection presents a significant challenge in computer vision, aiming to recognize interactions between humans and objects without prior training examples of those specific interactions. This necessitates models capable of generalizing from seen interactions to unseen ones. A successful zero-shot HOI system must leverage transferable knowledge from existing data to reason about novel combinations of humans, actions, and objects. This can involve approaches such as leveraging visual-linguistic models to embed semantic understanding of the interactions or employing compositional reasoning to combine knowledge of individual components into a prediction for the unseen interaction. Key challenges include the long-tailed distribution of HOI data, with some interactions occurring far less frequently than others, impacting model training and evaluation. Another critical aspect is effectively capturing spatial relationships between humans and objects, which is crucial for correct interaction understanding. Robust evaluation metrics are vital, accurately assessing performance on unseen interactions compared to established baselines. Finally, advancements in zero-shot HOI often intertwine with research on other areas, such as knowledge transfer, compositional reasoning, and long-tailed learning. Therefore, progress in zero-shot HOI detection is closely linked to broader developments within the field of computer vision.
Limitations & Future#
The research paper’s ‘Limitations & Future’ section would ideally delve into several key aspects. Limitations might include the dataset size, impacting the model’s generalizability, especially to rare or unseen interactions. The computational cost of using diffusion models could also be a significant limitation, potentially hindering real-time applications. Furthermore, the study should acknowledge any potential biases present in the training data that might affect the model’s objectivity. Finally, any assumptions made during model development, such as the independence of human and object features, could be discussed. Concerning future work, the authors could explore alternative model architectures to improve efficiency or investigate approaches to handle noisy or incomplete data. Improving the dataset’s diversity and size would significantly benefit the model’s robustness. Adapting the model for other modalities (e.g., video) would greatly extend its applications. Addressing the ethical considerations of applying this technology to potentially sensitive contexts is crucial. Addressing limitations and outlining promising avenues for future research will strengthen the paper’s impact and credibility.
More visual insights#
More on figures

🔼 This figure illustrates two key learning strategies employed in DIFFUSIONHOI for relation modeling. The left panel depicts the disentanglement-based cycle-consistency learning, where the goal is to reconstruct the human-object interaction latent from its components (human-action and object) using learnable relation embeddings as text prompts. This process helps in focusing on relationships rather than individual objects. The right panel showcases the relation-centric contrastive learning, which leverages relation embeddings to enhance the understanding of high-level relational semantics by contrasting similar and dissimilar interactions.
read the caption
Figure 2: (Left) Disentanglement-based cycle-consistency learning. (Right) Relation-centric contrastive learning. As such, it enables image generation w.r.t. target concepts in diverse scenes by using the learned embedding v to replace the tokenized placeholder S in text prompts.

🔼 This figure illustrates the architecture of the DIFFUSIONHOI model, showing the flow of information from image input to HOI detection output. The model leverages a pre-trained diffusion model (Denoising UNet) for feature extraction, conditioning on relation embeddings and object information from CLIP. These features are then processed by an HOI decoder (DHOI) to predict human-object interactions and by an instance decoder (Dins) for human and object detection. The relation embeddings are continuously updated during training through a cycle-consistency loss and a relation-centric contrastive loss. The figure highlights the key components of the model: the visual encoder, the diffusion model, the HOI decoder, the instance decoder, and the online update mechanism for relation embeddings.
read the caption
Figure 3: The overall pipeline of DIFFUSIONHOI. See §3.4 for details.

🔼 This figure illustrates the two main components of the proposed inversion-based HOI modeling approach. The left panel shows the cycle-consistency learning strategy used to disentangle human-action and object representations from the HOI latent, reconstructing it with relation embeddings used as textual prompts. The right panel details the relation-centric contrastive learning method used to improve the learning of relation embeddings.
read the caption
Figure 2: (Left) Disentanglement-based cycle-consistency learning. (Right) Relation-centric contrastive learning. As such, it enables image generation w.r.t. target concepts in diverse scenes by using the learned embedding v to replace the tokenized placeholder S in text prompts.
🔼 This figure illustrates two learning strategies used in the DIFFUSIONHOI model. The left panel shows the disentanglement-based cycle-consistency learning, where the HOI latent is decomposed into human-action and object components, then reconstructed from a relation latent guided by relation embeddings. The right panel shows the relation-centric contrastive learning, which uses relation embeddings to create positive and negative samples for enhancing the awareness of high-level relational semantics. These two strategies work together to improve relation modeling and enable the generation of images depicting specific interactions.
read the caption
Figure 2: (Left) Disentanglement-based cycle-consistency learning. (Right) Relation-centric contrastive learning. As such, it enables image generation w.r.t. target concepts in diverse scenes by using the learned embedding v to replace the tokenized placeholder S in text prompts.
More on tables
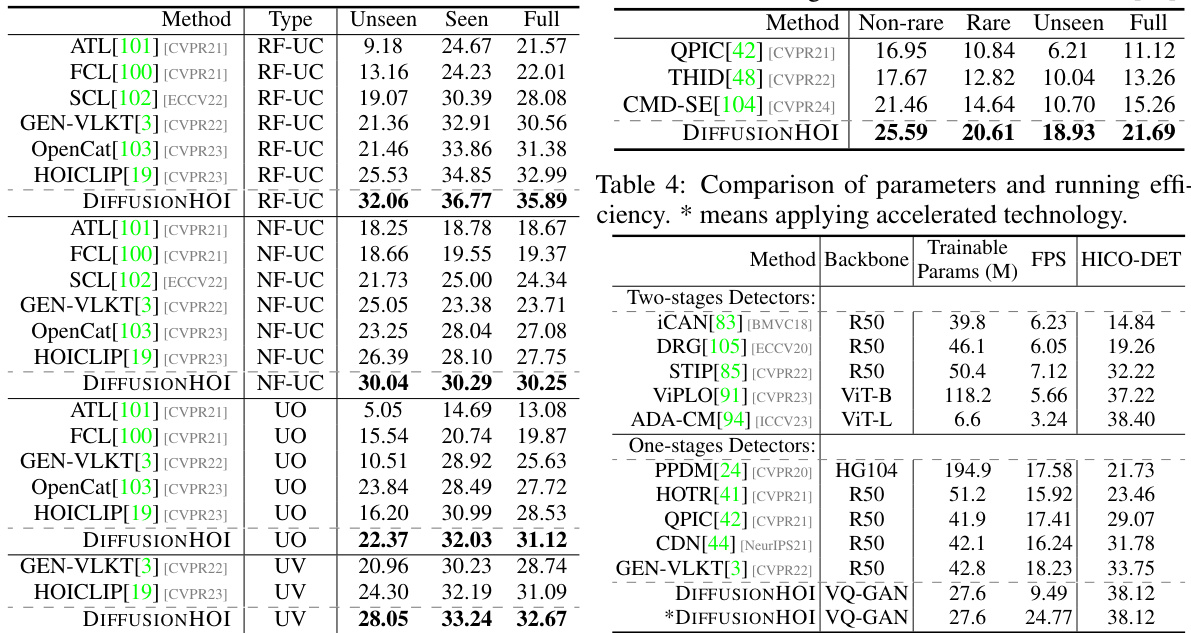
🔼 This table presents a comparison of the performance of various methods on two benchmark datasets for human-object interaction (HOI) detection: HICO-DET and V-COCO. It shows the mean Average Precision (mAP) scores achieved by each method under different evaluation settings (Full, Rare, Non-Rare, Known Object) to assess the performance on different subsets of the data and object categories. The table includes the backbone network used by each method, indicating the architecture and the pre-trained model used, if any. This provides insight into the effectiveness of different approaches for the challenging task of HOI detection.
read the caption
Table 1: Quantitative results for regular HOI detection on HICO-DET [20] and V-COCO [21].

🔼 This table presents the ablation study on the impact of different conditioning inputs for relation-inspired HOI detection. It compares the performance (mAP) on the HICO-DET dataset under both default and RF-UC (Rare First Unseen Combination) settings. The rows show the results with no additional conditioning, textual descriptions, relation embeddings, and finally, the complete DIFFUSIONHOI model using relation embeddings. The results demonstrate the significant contribution of relation embeddings to improving the performance, especially in the more challenging zero-shot scenario represented by RF-UC.
read the caption
Table 6: Analysis of conditioning input for relation-inspired HOI detection on HICO-DET[20].
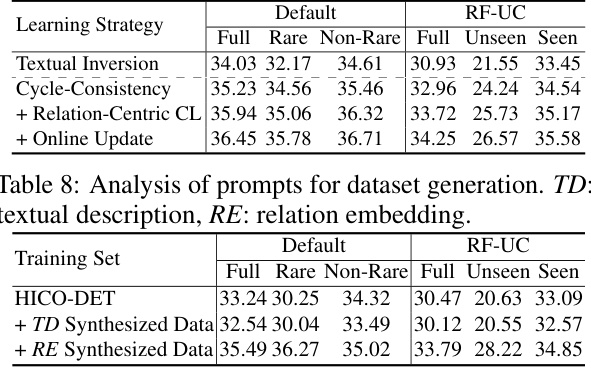
🔼 This table presents the results of experiments conducted to analyze the impact of different types of prompts used for generating synthesized data on the performance of the HOI detection model. It compares the performance using only textual descriptions (TD) against relation embeddings (RE) and explores the effects of combining both methods. The results are broken down by the evaluation metrics (Full, Rare, Non-Rare) for both default and rare first unseen combination scenarios (RF-UC).
read the caption
Table 8: Analysis of prompts for dataset generation. TD: textual description, RE: relation embedding.

🔼 This table compares the total training time on the HICO-DET dataset for several state-of-the-art methods and DIFFUSIONHOI. The methods are compared across the total training time required in hours.
read the caption
Table 9: Comparison of total training time on HICO-DET[20].
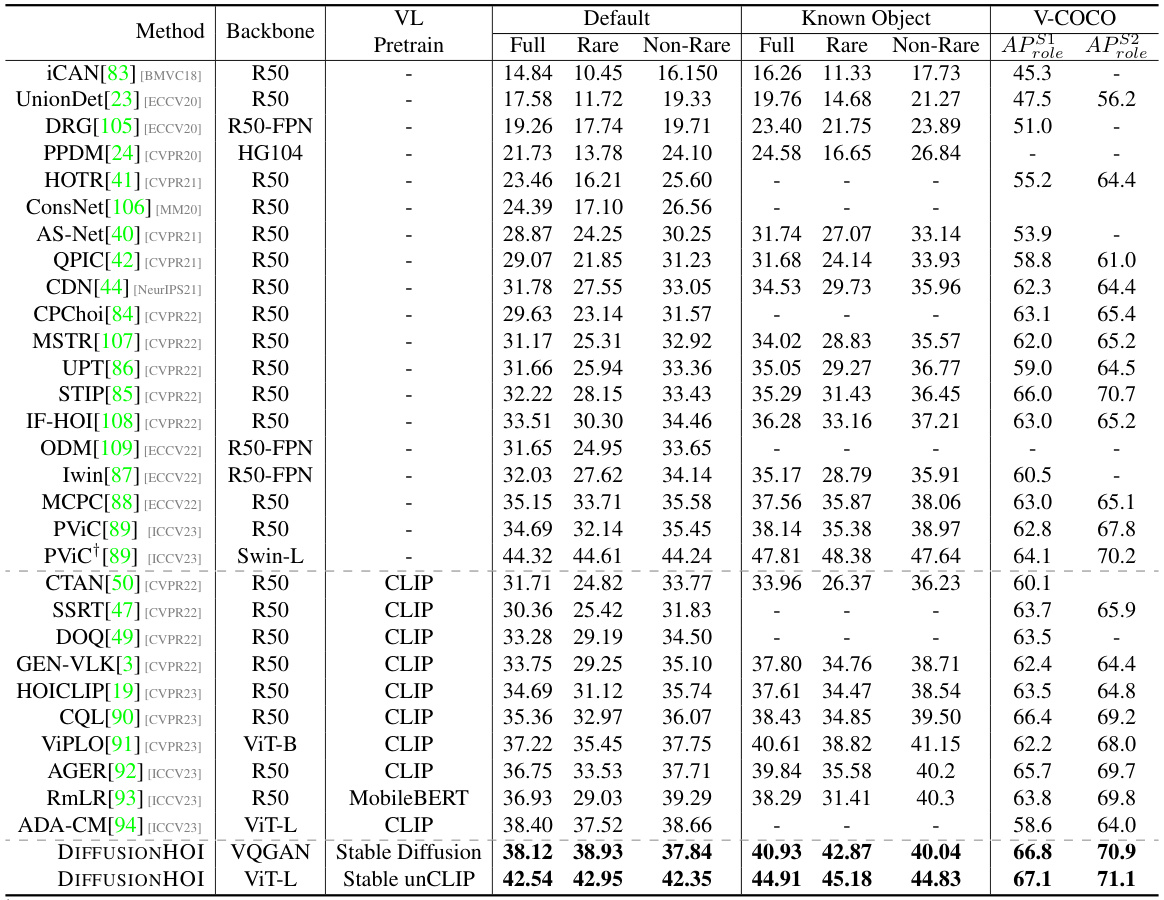
🔼 This table presents a quantitative comparison of the proposed DIFFUSIONHOI model with other state-of-the-art methods for Human-Object Interaction (HOI) detection on two benchmark datasets: HICO-DET and V-COCO. The results are broken down by several metrics, including overall performance (Full), performance on rare interactions (Rare), and performance on non-rare interactions (Non-Rare). The table also shows results for two different scenarios in the V-COCO dataset and allows for an assessment of the relative strengths and weaknesses of each method.
read the caption
Table 1: Quantitative results for regular HOI detection on HICO-DET [20] and V-COCO [21].
Full paper#



















