↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many recent methods use LLMs for planning, but they often ignore crucial properties like soundness and completeness, leading to inefficient and inaccurate results. These methods often rely on numerous LLM calls, which is expensive and environmentally unfriendly.
This paper proposes a more efficient and responsible approach called “Thought of Search.” Instead of directly using LLMs for every search step, it leverages LLMs to generate Python code for core search components (successor generation and goal test). This approach dramatically reduces the number of LLM calls while maintaining both soundness and completeness, resulting in significantly higher accuracy and efficiency across several search problems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of efficiency and responsibility in using large language models (LLMs) for planning. It challenges the current trend of computationally expensive and incomplete LLM-based planning methods, offering a novel approach that prioritizes soundness, completeness, and efficiency. This work is important for researchers seeking to develop more responsible and effective LLM-based applications.
Visual Insights#
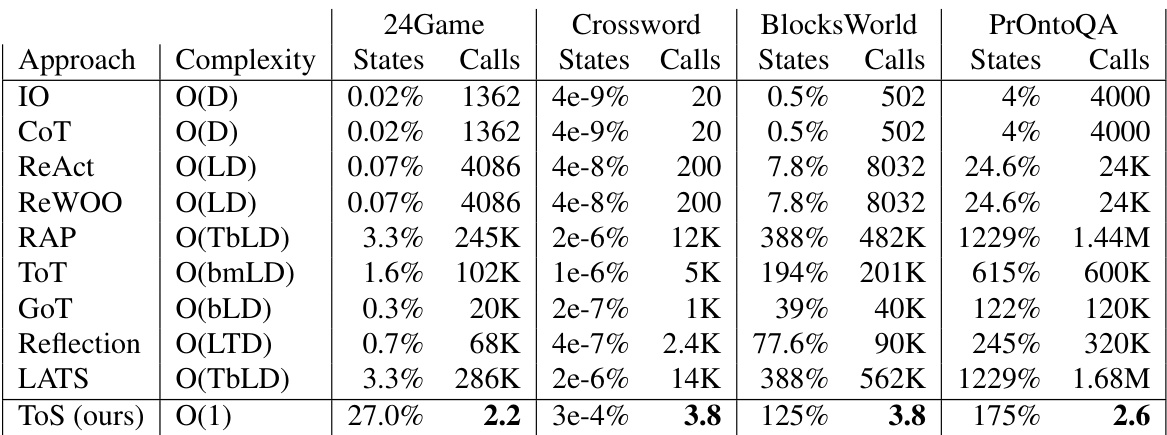
This table compares different planning approaches using LLMs across four datasets (24 Game, Crossword, Blocks World, PrOntoQA). For each approach, it shows the time complexity, the percentage of states explored, the number of LLM calls needed, and the total number of states in the datasets. The table highlights the efficiency gains of the proposed method, ‘Tree of Thoughts’ which significantly reduces the number of LLM calls required while maintaining accuracy.
Full paper#