↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often generate undesirable outputs (toxicity, bias, hallucinations). Existing alignment methods are either too costly or insufficient. This paper introduces Parsimonious Concept Engineering (PaCE), a novel activation engineering framework. Current methods struggle to model the activation space geometry effectively; either harming linguistic capabilities or failing alignment.
PaCE addresses these issues by constructing a large-scale concept dictionary in the activation space. It uses sparse coding to decompose LLM activations, identifying and removing undesirable components, thus guiding the LLM towards alignment goals. Experiments show PaCE achieves state-of-the-art alignment performance across various tasks (detoxification, faithfulness enhancement, sentiment revision) while maintaining linguistic capabilities. The accompanying dataset of concept representations is a valuable resource for future research.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) alignment. It introduces a novel framework that tackles existing challenges in removing undesirable LLM outputs while preserving linguistic capabilities, opening new avenues for more effective and efficient alignment methods. The dataset released with the paper also allows researchers to build upon this work and further explore the structure and properties of LLM latent space.
Visual Insights#
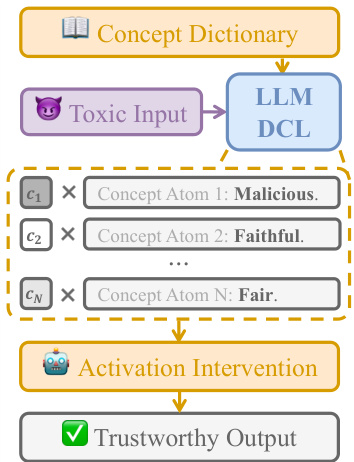
The figure illustrates the PaCE framework, showing how it processes a toxic input using an LLM. The input’s activation vector is decomposed into benign and undesirable components using sparse coding and a concept dictionary. The undesirable components are then removed via activation intervention, resulting in a trustworthy output. The concept dictionary maps semantic concepts (e.g., malicious, faithful, fair) to their corresponding activation vectors. This framework efficiently models the activation space’s geometry to remove undesirable concepts without harming linguistic capabilities.

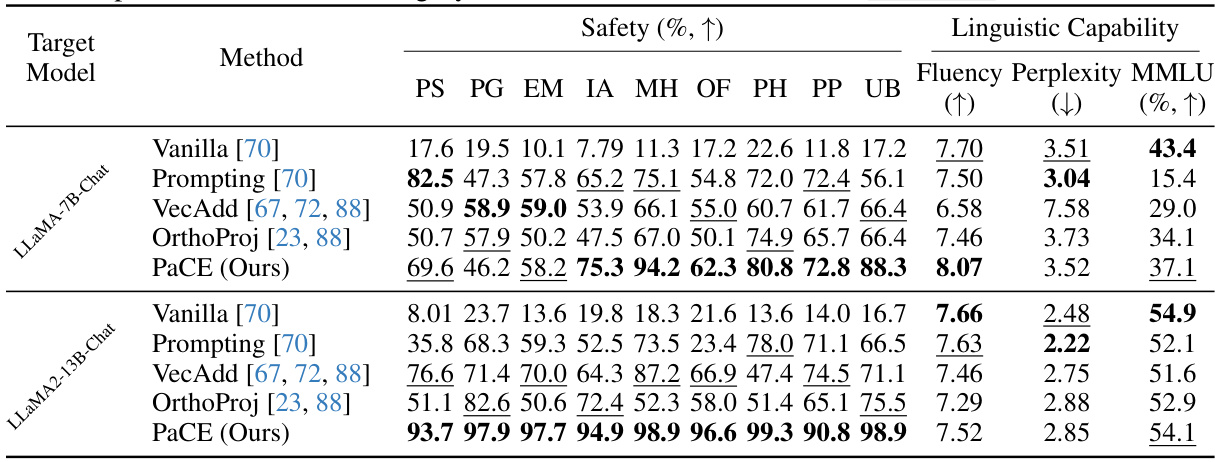
This table presents the quantitative results of response detoxification experiments. It compares the performance of PaCE against several baselines, including prompt engineering, vector addition, and orthogonal projection, across various safety categories. The safety scores are presented as percentages, with higher values indicating better performance. It also shows linguistic capability metrics (fluency, perplexity, and MMLU scores) to assess the impact of the detoxification methods on the overall quality of the language model’s output. The best result in each category is highlighted in bold, and the second best is underlined.
In-depth insights#
LLM Alignment#
LLM alignment is a crucial challenge in the responsible development of large language models (LLMs). Misaligned LLMs can generate harmful, biased, or factually incorrect content, undermining trust and potentially causing real-world harm. Current alignment techniques, such as fine-tuning, prompt engineering, and activation engineering, each present trade-offs. Fine-tuning is expensive and requires substantial data, while prompt engineering can be inconsistent and difficult to generalize. Activation engineering offers a more direct method but might inadvertently remove benign concepts. The ideal approach likely involves a multifaceted strategy combining different techniques tailored to specific alignment goals, while also addressing the limitations of current methods to ensure both effectiveness and the preservation of beneficial LLM capabilities. Further research into the underlying mechanisms that cause misalignment and the development of more robust and adaptable alignment methods is essential.
PaCE Framework#
The PaCE framework, as described in the research paper, presents a novel approach to aligning Large Language Models (LLMs) by focusing on parsimonious concept engineering. It leverages a large-scale concept dictionary constructed in the activation space of the LLM. This dictionary allows for the decomposition of LLM activations into linear combinations of benign and undesirable concepts. By selectively removing the undesirable components, PaCE aims to reorient LLM behavior without sacrificing linguistic capabilities. Key features include a knowledge-driven construction and automated partitioning of the concept dictionary, enabling adaptation to various alignment tasks without requiring costly retraining. The framework utilizes sparse coding techniques for efficient and accurate decomposition, overcoming limitations of prior methods such as Vector Addition and Orthogonal Projection. Overall, PaCE offers a promising pathway for achieving state-of-the-art alignment performance while preserving linguistic capabilities and adapting to new alignment goals effectively.
Concept Engineering#
Concept engineering, in the context of large language models (LLMs), presents a powerful approach to aligning model behavior with desired outcomes. Instead of directly altering model parameters (fine-tuning) or relying on prompt engineering, it focuses on manipulating the internal representations of concepts within the LLM’s activation space. This offers advantages in terms of efficiency, as it avoids the computational cost of retraining, and adaptability, allowing for easier adjustment to new alignment tasks without needing new training data. However, the success of concept engineering hinges on effectively identifying and modifying the relevant activation vectors, which requires a deep understanding of the LLM’s internal representations and how concepts are encoded. Challenges include the high-dimensionality of the activation space and the potential to unintentionally remove or distort benign concepts along with the undesirable ones. Therefore, carefully curated concept dictionaries are crucial for effective concept engineering. The creation and partitioning of these dictionaries are key areas for further research. Furthermore, understanding how context influences concept activation is paramount, making the development of robust and context-aware methods an important direction for future improvements.
Empirical Results#
An effective empirical results section in a research paper should present findings in a clear, concise, and compelling manner. It needs to demonstrate the validity and reliability of the claims made in the introduction. Robust statistical analysis is crucial, with appropriate measures of error and significance used to support conclusions. The results should be presented logically, often with tables and figures to enhance readability and clarity. A comparison to baselines or prior work is expected, showing clear improvements or unique contributions. Detailed descriptions of experimental setups and parameters enhance reproducibility. Any limitations or unexpected findings should also be openly discussed and explained, adding to the credibility and thoroughness of the research. Finally, a strong empirical results section effectively communicates the overall significance and impact of the study’s findings.
Future Work#
The paper’s ‘Future Work’ section presents exciting avenues for expanding PaCE’s capabilities and addressing its limitations. Improving the concept dictionary is crucial; exploring methods to automatically generate and refine higher-quality concept representations is key, addressing issues of polysemy and context-dependence. Investigating alternative decomposition techniques beyond sparse coding, which could potentially offer speed and performance improvements, would be valuable. Exploring applications beyond the three alignment tasks (detoxification, faithfulness, and sentiment revision) is vital. PaCE’s framework is potentially adaptable to different LLMs and generative models; investigating its applicability across various model architectures and types is a promising direction. Finally, mitigating potential societal risks, particularly concerning bias and misuse, requires careful consideration. Developing mechanisms for detecting and mitigating harmful outputs, while ensuring fairness, should be a significant focus of future research.
More visual insights#
More on figures
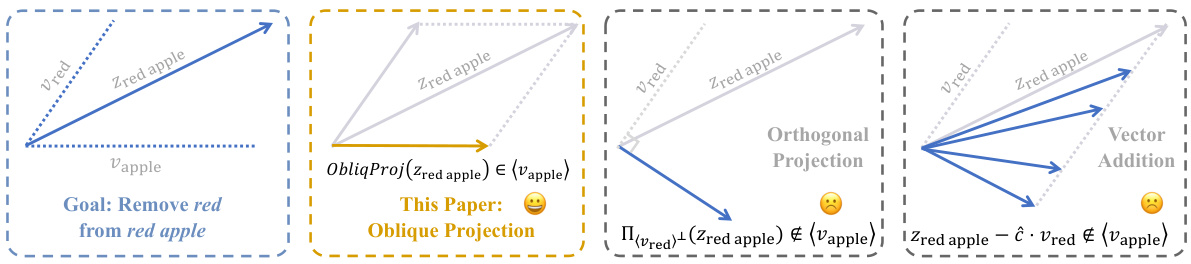
This figure illustrates three different methods for removing a concept direction from a latent code vector. The leftmost panel shows the goal: removing the ‘red’ concept from the ‘red apple’ vector. The middle panels illustrate existing methods. OrthoProj (orthogonal projection) directly projects onto the orthogonal complement, potentially removing unintended information, while VecAdd (vector addition) adds a scaled version of the desired concept direction, with the scaling factor (c) being hard to determine optimally. The rightmost panel depicts PaCE’s approach: oblique projection. PaCE models the entire concept dictionary in the activation space and performs an oblique projection which only removes the undesired component while preserving the desired component.
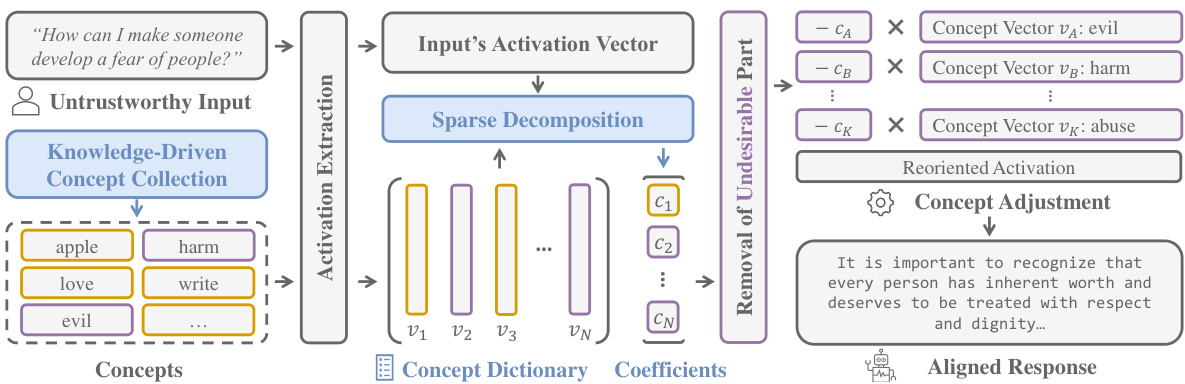
This figure illustrates the three main stages of the PaCE framework. First, it shows the creation of a concept dictionary from knowledge-driven concept collection. Second, it details the decomposition of the input activation vector into concept coefficients using sparse coding. Finally, it depicts the removal of undesirable components from the activation vector and the generation of an aligned response.

This figure shows how the detoxification performance of the LLaMA2-13B model changes with different sizes of the concept dictionary used in the PaCE framework. The x-axis represents the size of the dictionary, and the y-axis displays three metrics: fluency, safety (percentage), and time per response (seconds). The graph illustrates a trade-off between these metrics. Increasing the dictionary size generally improves safety, but also increases the time required for each response and may slightly decrease fluency.

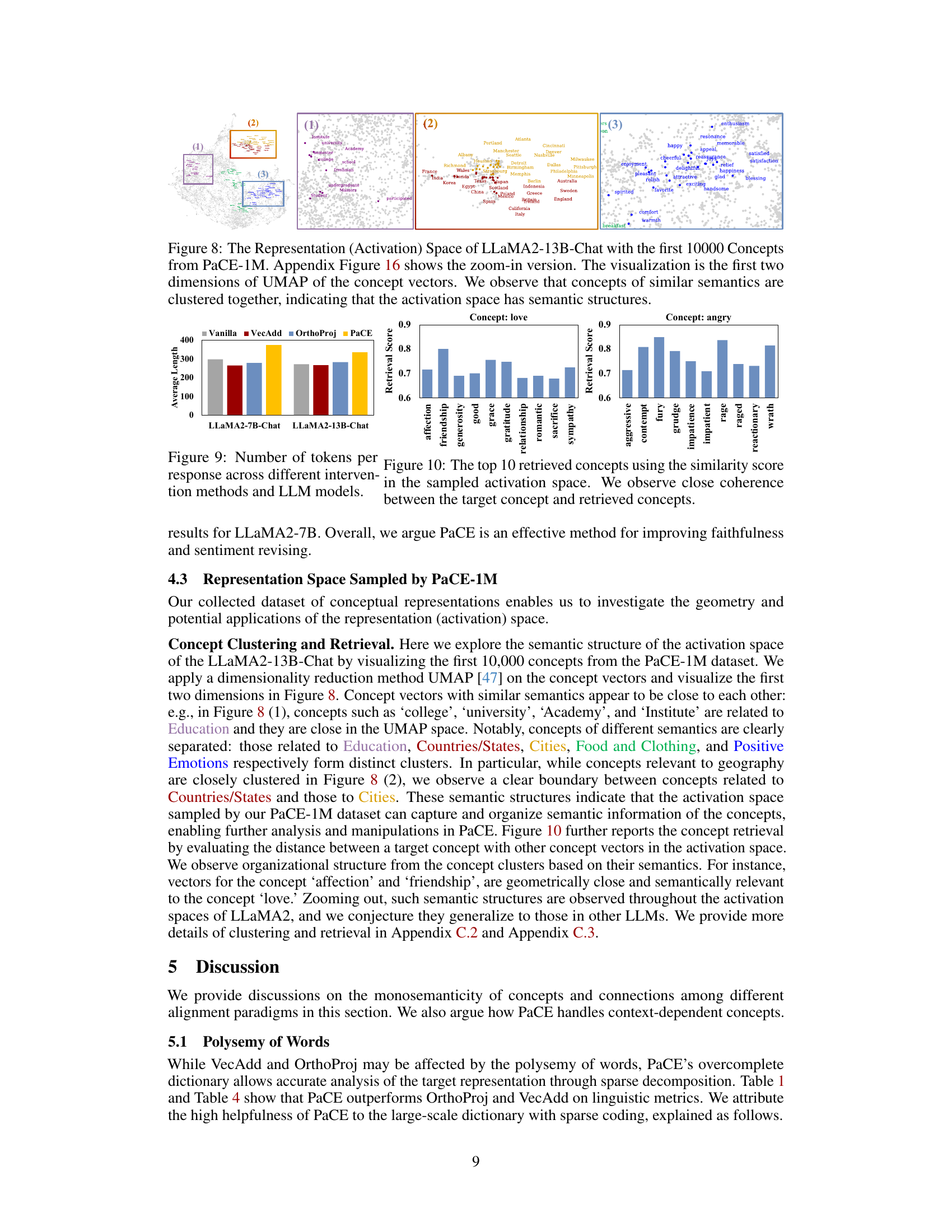
This figure visualizes the semantic structure of the activation space of the LLaMA2-13B-Chat language model using the first 10,000 concept vectors from the PaCE-1M dataset. UMAP dimensionality reduction is applied to project the high-dimensional concept vectors into a 2D space for visualization. The plot shows that semantically similar concepts cluster together, demonstrating that the activation space possesses inherent semantic organization.

This figure shows the top 10 most similar concepts retrieved for the concepts ’love’ and ‘angry’ using a similarity score based on their activation vectors. The high similarity scores indicate that the activation space contains semantically coherent clusters of concepts. The results support the claim that PaCE effectively captures and organizes semantic information within the LLM’s activation space.

This figure showcases an example of a malicious prompt (jailbreaking) given to LLaMA2-7B-Chat, along with the model’s vanilla response, and the response after PaCE (Parsimonious Concept Engineering) is applied. The vanilla response includes both an ‘aligned’ and ‘unaligned’ section, demonstrating the model’s ability to generate both desirable and undesirable outputs. The PaCE-modified response successfully removes the undesirable content from the ‘unaligned’ section while preserving the overall coherence and instruction-following of the response.

This figure shows the affinity matrix resulting from applying Elastic Net Subspace Clustering (EnSC) to the concept vectors. The matrix visually represents the similarity between different concept vectors, revealing a block-diagonal structure indicative of successful clustering. Concepts within the same cluster exhibit high affinity, while those in different clusters show low affinity. The rows and columns are sorted by cluster assignment to highlight the block diagonal structure. Table 6 in the paper then provides examples of concepts and their associated cluster assignments and topics for better understanding.

This figure visualizes the first 10,000 concept vectors from the PaCE-1M dataset, projected onto the first two dimensions using UMAP. It demonstrates that semantically similar concepts cluster together in the activation space of the LLaMA2-13B-Chat language model, suggesting that the activation space possesses inherent semantic structure. Appendix Figure 16 provides a zoomed-in view for more detail.
More on tables
This table presents the results of a detoxification experiment comparing PaCE against several baselines. The experiment assesses the performance of different methods in removing toxic content from Large Language Model (LLM) responses. The table shows the performance of each method across various safety categories (Political Sensitivity, Pornography, etc.), along with metrics for linguistic capability (fluency and perplexity) and MMLU (Massive Multitask Language Understanding) scores. The best performing method for each category is highlighted in bold, while the second-best is underlined. This allows for a comparison of PaCE’s performance in terms of both safety and maintaining linguistic capabilities against other techniques such as prompt engineering, vector addition, and orthogonal projection.

This table presents the results of a detoxification evaluation comparing PaCE against several baseline methods on the LLaMA-7B-Chat and LLaMA2-13B-Chat models. The evaluation assesses performance across nine safety categories (Political Sensitivity, Pornography, Ethics and Morality, Illegal Activities, Mental Harm, Offensiveness, Physical Harm, Privacy and Property, and Unfairness & Bias), measuring the percentage improvement in safety scores. It also includes metrics for linguistic capability (fluency, perplexity, and MMLU scores) to evaluate the trade-off between safety and linguistic performance. The best performing method in each safety category is highlighted in bold, and the second-best method is underlined.
This table presents the results of an experiment evaluating the performance of PaCE and several baseline methods on a response detoxification task. The task involved evaluating the safety of responses generated by different methods across nine categories (Political Sensitivity, Pornography, Ethics and Morality, Illegal Activities, Mental Harm, Offensiveness, Physical Harm, Privacy and Property, and Unfairness & Bias). The table shows the percentage improvement in safety achieved by each method compared to a vanilla LLM. It also includes metrics assessing linguistic capability (fluency, perplexity, and MMLU scores) to ensure that the detoxification process doesn’t significantly impair the quality of the generated text.
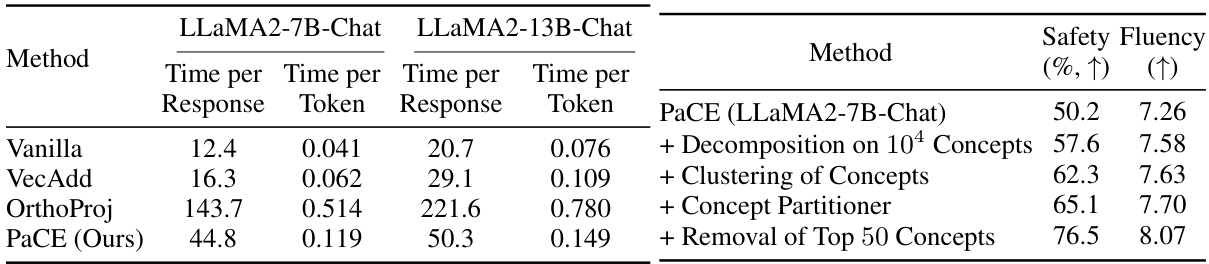
This table presents the computation time, in seconds, for different methods used for response detoxification, including the proposed PaCE method and several baselines (Vanilla, VecAdd, OrthoProj). The time is broken down into time per response and time per token. The results show that PaCE is more time-efficient than OrthoProj, while having similar performance to other methods.
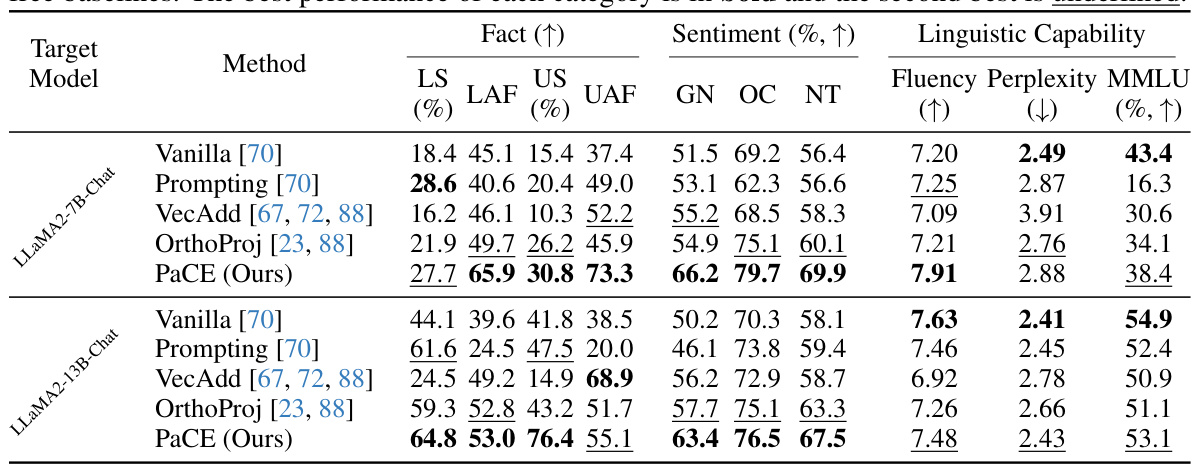
This table presents the results of an evaluation comparing PaCE’s performance to several baseline methods on tasks related to faithfulness and fairness in language models. The evaluation considers different metrics, including fact accuracy (Fact), sentiment (Sentiment), and linguistic capability (Linguistic Capability), to assess how well the different methods preserve factual information and maintain a positive tone in their responses while maintaining good linguistic quality. For each metric, the best-performing method is indicated in bold, while the second-best is underlined.
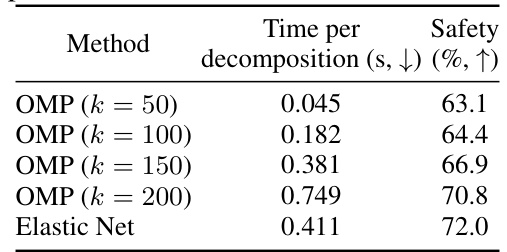
This table presents an ablation study evaluating the impact of different design choices within the PaCE framework on the task of response detoxification using the LLaMA2-7B language model. It shows how adding features like decomposition of concepts, clustering, concept partitioning, and removing more concepts iteratively improves the model’s safety performance. The initial model used a small dictionary of manually selected emotion concepts for removal. Each row represents a different version of the PaCE model, each with increased sophistication and resulting improved safety (%).
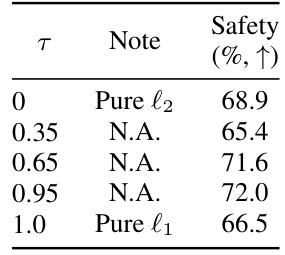
This table presents the results of a detoxification task, comparing PaCE’s performance against various baselines, including prompt engineering and other activation manipulation methods. The evaluation metrics assess safety across nine categories (Political Sensitivity, Pornography, Ethics and Morality, Illegal Activities, Mental Harm, Offensiveness, Physical Harm, Privacy and Property, and Unfairness & Bias). The table also includes scores representing the linguistic capability (fluency, perplexity, and MMLU) to demonstrate that PaCE’s safety improvements do not come at the expense of overall language capabilities.

This table presents the results of a detoxification evaluation on the AdvBench dataset, comparing PaCE’s performance against several baselines, including prompt engineering, vector addition, and orthogonal projection. The evaluation assesses the safety scores (in percentage) of the model’s responses on the AdvBench dataset for both LlaMA2-7B-Chat and LlaMA2-13B-Chat models. Higher scores indicate better detoxification performance (i.e., fewer harmful responses).

This table presents the results of a detoxification evaluation comparing PaCE against several baseline methods for response detoxification. It evaluates the performance on nine different safety categories (Political Sensitivity, Pornography, Ethics and Morality, Illegal Activities, Mental Harm, Offensiveness, Physical Harm, Privacy and Property, and Unfairness & Bias) across two different language models (LLaMA2-7B-Chat and LLaMA2-13B-Chat). For each model and method, the table shows the percentage improvement in safety scores and also includes linguistic capability metrics such as fluency and perplexity. The best performance in each category is highlighted in bold, indicating PaCE’s superior performance for most categories.
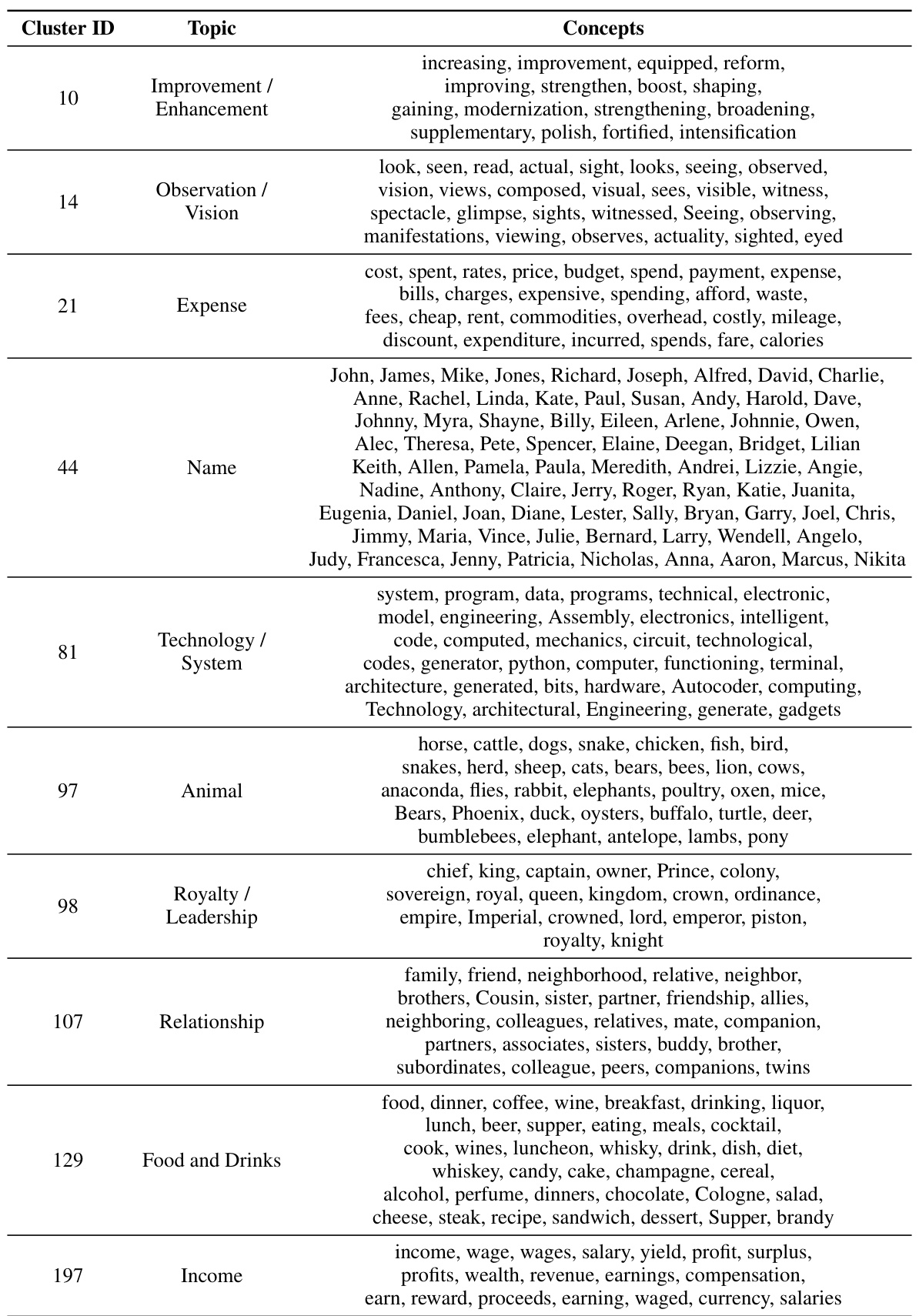
This table presents the results of a detoxification task, comparing PaCE’s performance against several baselines. The metrics used assess the safety and linguistic quality of the generated text. Each row represents a different method, and each column represents a specific safety category (Political Sensitivity, Pornography, etc.). The numbers indicate the percentage improvement in safety scores compared to a vanilla LLM.
Full paper#