↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large vision models, while powerful, often struggle with low confidence when fine-tuned on limited data (few-shot learning). This significantly limits their use in real-world applications where trust and reliability are paramount. Existing parameter-efficient fine-tuning (PEFT) methods, while improving efficiency, exacerbate this under-confidence.
The researchers introduce Bayesian-PEFT, a novel framework that tackles this problem head-on. It uses two key Bayesian components: base rate adjustment to boost confidence and a diversity-inducing evidential ensemble to ensure robust performance. Results across multiple datasets showcase a dramatic improvement in both accuracy and calibration, demonstrating the effectiveness of Bayesian-PEFT for building more reliable and trustworthy AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on parameter-efficient fine-tuning of large vision models and uncertainty quantification. It addresses the critical under-confidence issue in few-shot learning, offering a novel Bayesian approach (Bayesian-PEFT) that significantly improves both prediction accuracy and calibration. The findings are broadly applicable across various datasets and PEFT techniques, opening new avenues for reliable and trustworthy AI applications.
Visual Insights#

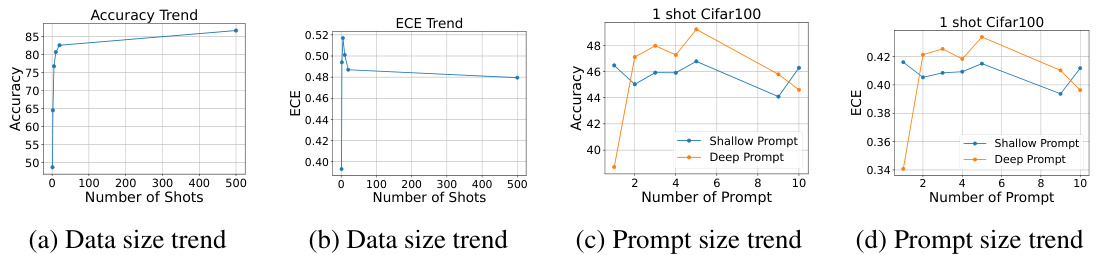
This figure compares the accuracy and expected calibration error (ECE) of various parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset for few-shot (1-20 shot) adaptation. It demonstrates that while PEFT methods achieve high accuracy, they often suffer from poor calibration (high ECE), especially in low-shot learning scenarios. The figure highlights the under-confidence problem where models are often too hesitant to make confident predictions, even when they are accurate. Bayesian-PEFT, a new method proposed in the paper, aims to address this issue.
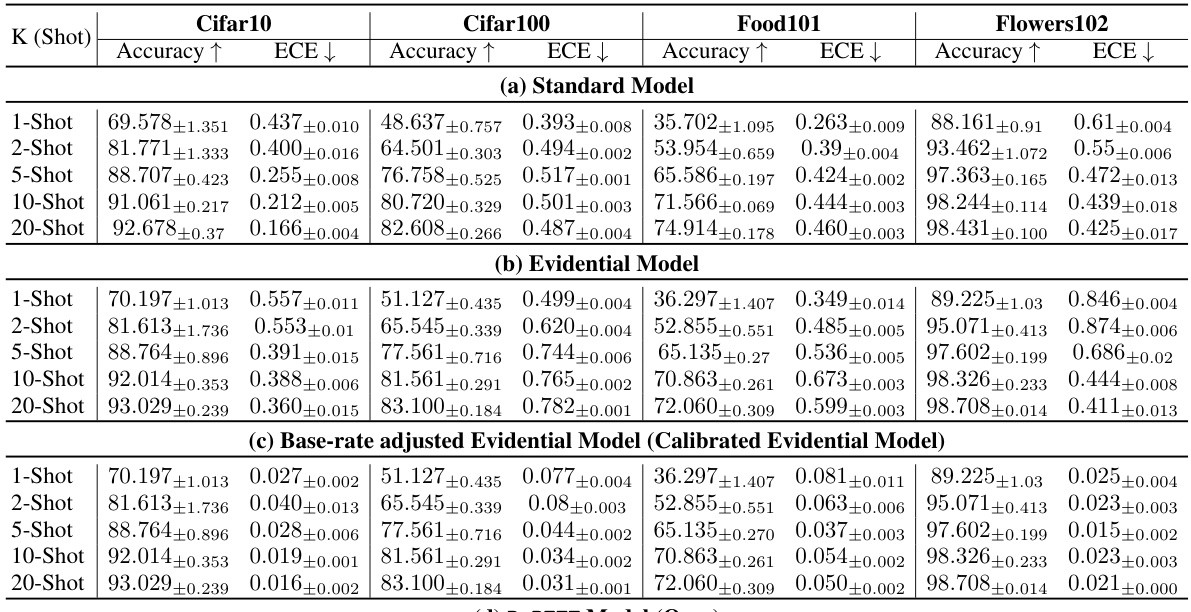
This table presents the prediction accuracy and expected calibration error (ECE) for different few-shot learning scenarios across four benchmark datasets (Cifar10, Cifar100, Food101, Flowers102). The results are broken down by the number of shots (1, 2, 5, 10, 20) and show the performance of four model types: a standard model, an evidential model, a calibrated evidential model (base-rate adjusted), and the proposed Bayesian-PEFT model. This allows for a comparison of the calibration and accuracy improvements achieved by each method.
In-depth insights#
Bayesian PEFT#
Bayesian Parameter-Efficient Fine-Tuning (Bayesian PEFT) is a novel approach that enhances the performance of standard PEFT methods by incorporating Bayesian principles. It directly addresses the under-confidence issue commonly observed in PEFT-adapted foundation models, especially in low-data regimes. This is achieved through two key components: base rate adjustment which strengthens the prior belief based on pre-training knowledge, boosting confidence in predictions; and the construction of a diversity-inducing evidential ensemble, which leverages belief regularization to ensure diverse ensemble members and improve reliability. The combination of these components provides well-calibrated uncertainty quantification, crucial for trustworthy predictions in high-stakes applications. The theoretical analysis underpinning Bayesian PEFT establishes its reliability and accuracy, validated empirically across diverse datasets and few-shot learning scenarios. Its superior performance relative to standard PEFT and post-hoc calibration methods highlights its potential as a significant advancement in efficient and reliable model adaptation.
Underconfidence Issue#
The research paper highlights a critical “underconfidence issue” in parameter-efficient fine-tuning (PEFT) of large vision foundation models. Adapted models, while achieving high accuracy in few-shot learning scenarios, exhibit surprisingly low confidence in their predictions. This underconfidence, measured by high Expected Calibration Error (ECE) scores, significantly limits the models’ reliability and applicability, especially in high-stakes decision-making. The root cause is identified as the rich prior knowledge from pre-training overshadowing the limited knowledge gained during few-shot adaptation. This leads to overly conservative predictions, hindering confident decision-making. The paper proposes a novel Bayesian-PEFT framework to address this, integrating PEFT with Bayesian components to strengthen prior beliefs and build a diverse evidential ensemble, ultimately improving both prediction accuracy and calibration.
Base Rate Adj#
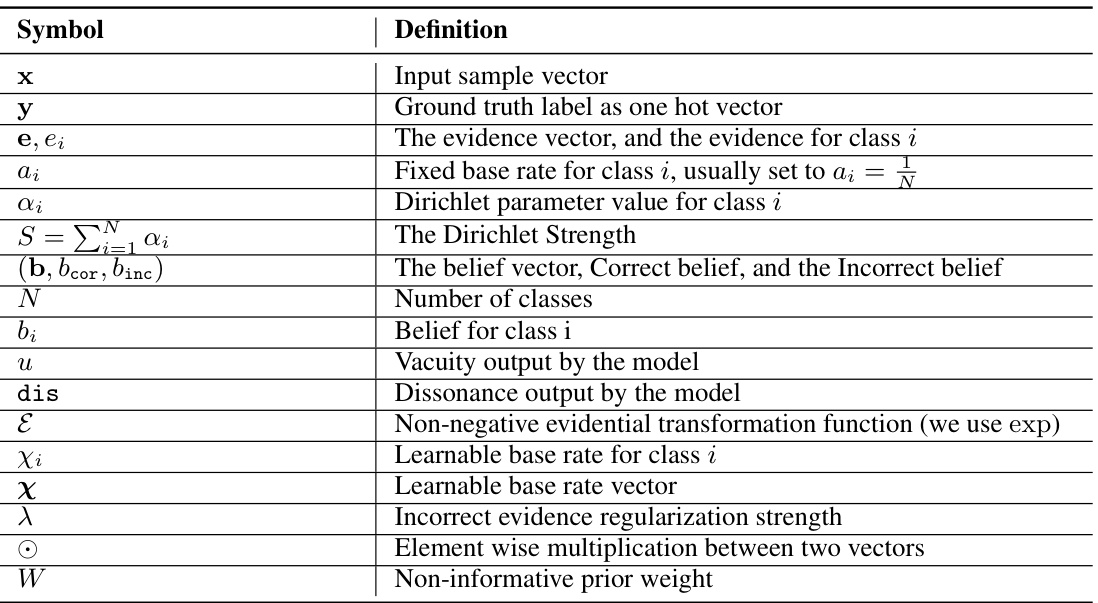
The heading ‘Base Rate Adj,’ likely refers to a method adjusting base rates within a Bayesian framework. This is crucial because foundation models often show underconfidence, especially in few-shot scenarios. By adjusting base rates, the model’s prior belief (knowledge from pre-training) is strengthened, leading to more confident predictions without sacrificing accuracy. The adjustment strategy likely involves modifying Dirichlet parameters, balancing prior knowledge with limited new data. The theoretical justification would involve showing that base rate adjustments maintain prediction accuracy while increasing confidence, perhaps by widening the gap between belief assigned to the true class versus others. This technique directly addresses the core issue of overly cautious predictions arising from the clash between massive pre-training and limited fine-tuning data.
Evidential Ensemble#
An evidential ensemble in the context of machine learning leverages the principles of evidential reasoning to combine predictions from multiple models. Unlike traditional ensembles that simply average predictions, an evidential ensemble explicitly models uncertainty associated with each prediction. Each model provides not only a prediction but also a measure of its confidence (belief) in that prediction. The ensemble then integrates these beliefs using the rules of subjective logic or similar frameworks, leading to a final prediction that reflects the collective evidence from all models. This approach is particularly useful when dealing with diverse and potentially conflicting information or scenarios where individual models may be highly uncertain. The resulting prediction provides a more robust and calibrated estimate, along with a quantifiable measure of overall uncertainty. The use of evidential theory makes this method powerful because it allows for representing different sources of uncertainty and combining evidence from diverse models while handling inconsistencies effectively. Moreover, evidential ensembles are inherently more reliable in situations where few-shot learning or challenging data conditions lead to significant uncertainty in individual model predictions.
Future Works#
Future research could explore several promising avenues. Extending Bayesian-PEFT to other PEFT methods beyond the ones tested (VPT, Adapter, Bias) is crucial to establish its broader applicability and effectiveness. Investigating the impact of different backbone architectures and pre-training strategies on Bayesian-PEFT’s performance would provide valuable insights. Developing more sophisticated methods for base rate adjustment and diversity-inducing evidential ensemble techniques could further improve the model’s calibration and uncertainty quantification. It’s also important to evaluate B-PEFT on larger, more complex datasets and real-world applications to assess its robustness and scalability. Finally, examining the use of B-PEFT with self-supervised pre-trained models and exploring the interaction of model uncertainty with out-of-distribution detection are exciting directions for future research.
More visual insights#
More on figures

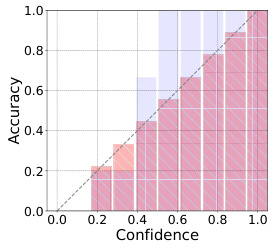
The figure shows reliability diagrams for four different parameter-efficient fine-tuning (PEFT) methods on the 1-shot CIFAR100 dataset. The x-axis represents the model’s confidence, and the y-axis represents the accuracy. The ideal performance is a diagonal line. The plots for VPT, Adapter, and Bias show that these models are severely underconfident, making predictions with low confidence even when they are relatively accurate. In contrast, the plot for B-PEFT shows that the proposed Bayesian-PEFT method significantly improves the calibration, producing much more confident predictions and reducing the expected calibration error (ECE) by nearly an order of magnitude.
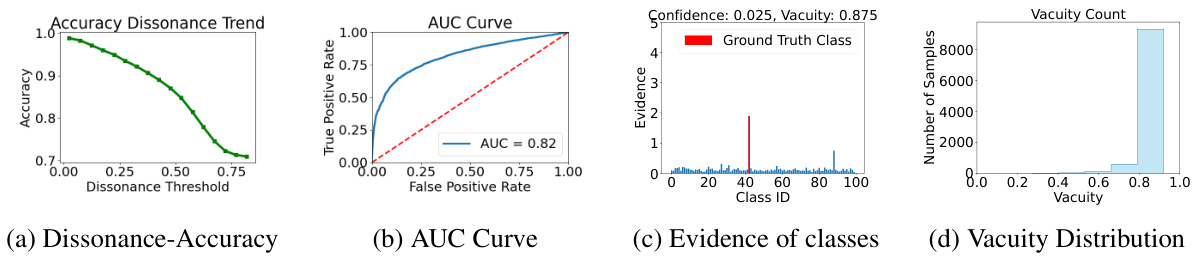
This figure presents the results of applying the proposed method to the Cifar10 dataset using a 1-shot learning approach. It consists of four sub-figures: (a) shows the relationship between accuracy and dissonance, demonstrating the model’s accuracy despite low confidence; (b) shows the AUC curve, indicating good discrimination ability; (c) visualizes the evidence distribution for a sample, highlighting the low evidence assigned to most classes; and (d) shows the vacuity distribution, confirming the model’s under-confidence. These plots illustrate the under-confident behavior of existing methods even when achieving relatively high accuracy.

This figure shows the schematic diagram (a) and graphical model (b) of the proposed Bayesian Parameter Efficient Fine-Tuning (B-PEFT) framework. The schematic diagram illustrates the process of using an ensemble of evidential models to generate predictions, incorporating base-rate adjustment and diversity-inducing evidential ensemble techniques. The graphical model provides a visual representation of the probabilistic relationships between the input, latent variables, and the output predictions, using Dirichlet distributions and multinomial likelihoods.
This figure shows a schematic diagram and a graphical model of the proposed Bayesian Parameter Efficient Fine-Tuning (B-PEFT) framework. The schematic diagram (a) illustrates the process of input, base rate adjustment for each ensemble, predictions from the ensemble, and finally, accuracy and Expected Calibration Error (ECE). The graphical model (b) presents a more detailed representation of the Bayesian modeling, with the observed variable, latent variables, and how multiple ensembles are combined to reach a final prediction. This framework uses evidential learning and integrates state-of-the-art parameter-efficient fine-tuning techniques with two Bayesian components to improve prediction accuracy and calibration under challenging few-shot learning settings.
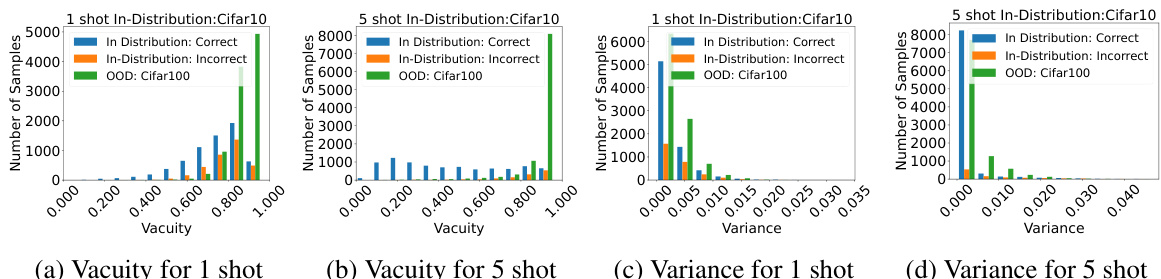
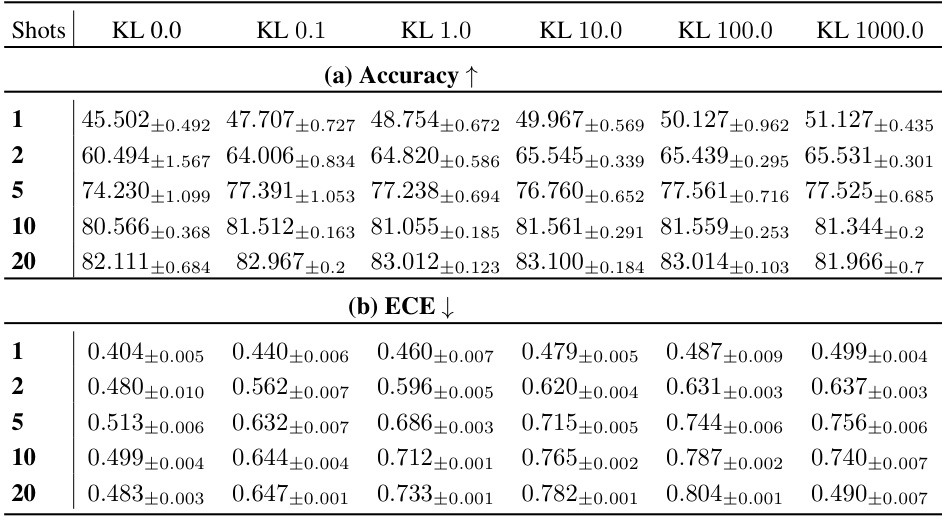
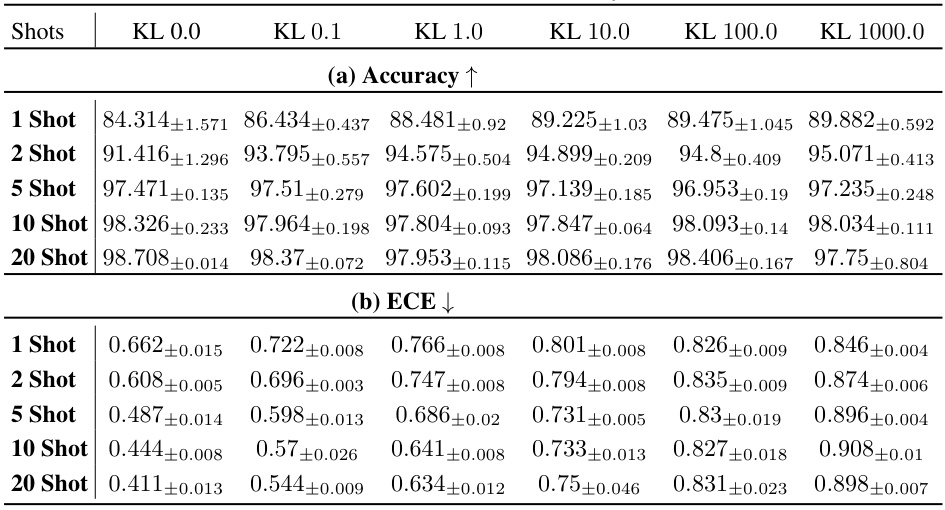
This figure visualizes the vacuity and variance distributions for in-distribution (CIFAR-10) and out-of-distribution (CIFAR-100) data samples, considering both 1-shot and 5-shot scenarios. The plots illustrate how the model’s uncertainty, represented by vacuity and variance, changes depending on whether the sample is in-distribution or out-of-distribution and the number of shots used for training.

This figure illustrates the Bayesian model averaging process for building a diversity-inducing evidential ensemble in the B-PEFT framework. The schematic diagram (a) shows the overall process, while the graphical model (b) visually represents the relationships between variables such as observed variables, latent variables, ensemble predictions, accuracy, and expected calibration error (ECE).

This figure shows the results of a 1-shot Cifar10 experiment, demonstrating the relationship between dissonance and accuracy, the distribution of evidence for classes, and vacuity distribution. It highlights the model’s under-confidence despite accurate predictions, attributing this to insufficient evidence allocation and underestimation of prior knowledge from pre-training.

The figure shows the accuracy and Expected Calibration Error (ECE) on CIFAR100 dataset for different Parameter-Efficient Fine-Tuning (PEFT) methods in few-shot adaptation. It demonstrates that although PEFT methods achieve high accuracy, they produce under-confident predictions, especially in low-shot settings. The Bayesian-PEFT method significantly improves calibration performance.

This figure compares the accuracy and expected calibration error (ECE) of various parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset for few-shot adaptation scenarios (1-20 shots). It highlights the trade-off between accuracy and calibration, showcasing how some methods achieve high accuracy but poor calibration (high ECE), indicating under-confidence in predictions. Bayesian-PEFT is shown to outperform other methods in both accuracy and calibration.

This figure shows the accuracy and expected calibration error (ECE) for different parameter-efficient fine-tuning (PEFT) methods on the CIFAR-100 dataset for few-shot adaptation. It demonstrates that while PEFT methods achieve high accuracy, they often suffer from poor calibration (high ECE), especially in low-shot learning scenarios. The figure highlights the under-confidence issue that is a significant problem with PEFT methods.

The figure shows the accuracy and expected calibration error (ECE) for various parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset using few-shot adaptation. It demonstrates that while PEFT methods achieve high accuracy, they often suffer from poor calibration (high ECE), especially in low-shot learning scenarios. The plot highlights the under-confidence problem where the model is accurate but assigns low confidence to its predictions. Bayesian-PEFT is shown to significantly improve calibration.
This figure compares the accuracy and expected calibration error (ECE) of various parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset for few-shot adaptation. It shows that while PEFT methods generally improve accuracy, they often result in poorly calibrated models, especially in low-shot scenarios. The Bayesian-PEFT method is highlighted for its superior performance. The x-axis represents the accuracy, while the y-axis represents the ECE. Lower ECE indicates better calibration.

This figure compares the accuracy and expected calibration error (ECE) of various parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset for few-shot adaptation. It demonstrates that while PEFT methods achieve high accuracy, they often suffer from poor calibration, especially in low-shot scenarios. Bayesian-PEFT is shown to significantly improve calibration while maintaining high accuracy. The x-axis represents accuracy, and the y-axis represents ECE. Lower ECE indicates better calibration.
This figure compares the accuracy and expected calibration error (ECE) of various parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset for few-shot adaptation. It shows that while most methods achieve high accuracy, they suffer from poor calibration (high ECE), indicating underconfidence in their predictions. The proposed Bayesian-PEFT method is highlighted for its superior calibration performance.

The figure shows the accuracy and expected calibration error (ECE) of different parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset for few-shot adaptation. It demonstrates that while PEFT methods achieve high accuracy, they also suffer from under-confidence issues, particularly in low-shot learning scenarios. The Bayesian-PEFT method is shown to significantly improve calibration.

This figure shows a comparison of the accuracy and Expected Calibration Error (ECE) achieved by various parameter-efficient fine-tuning (PEFT) methods on the CIFAR100 dataset for few-shot adaptation. It illustrates that while all PEFT methods improve accuracy, especially as the number of shots increases, they significantly underperform in terms of calibration. Bayesian-PEFT is shown to greatly improve calibration.
More on tables

This table presents the prediction accuracy and Expected Calibration Error (ECE) for different few-shot learning scenarios across four datasets (Cifar10, Cifar100, Food101, Flowers102). Results are shown for a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed B-PEFT model. The number of shots (K) varies from 1 to 20, demonstrating the performance across different adaptation levels.
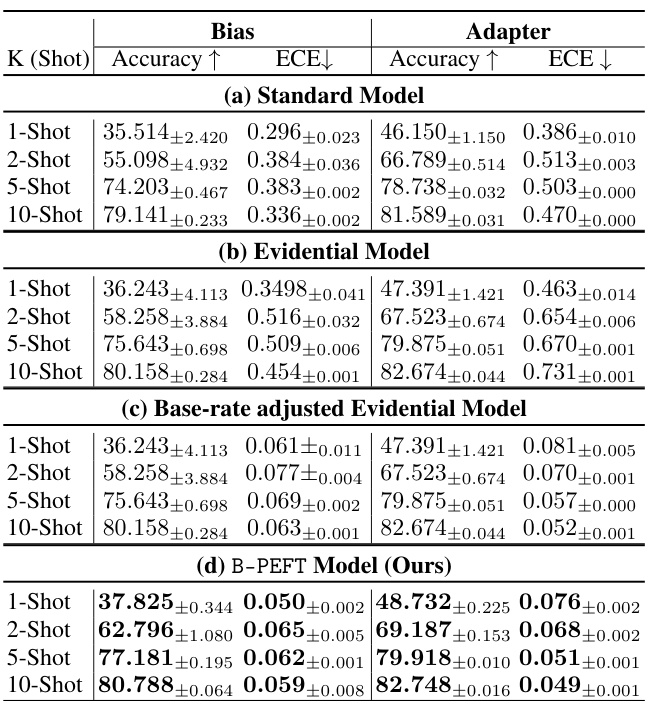
This table presents the prediction accuracy and expected calibration error (ECE) for different few-shot learning scenarios across four datasets (Cifar10, Cifar100, Food101, Flowers102). Results are shown for a standard model, an evidential model, a base-rate adjusted evidential model, and the proposed Bayesian-PEFT model. The table compares the performance of different models under various shot settings (1-shot, 2-shot, 5-shot, 10-shot, 20-shot), highlighting the impact of the proposed Bayesian framework on improving both accuracy and calibration.
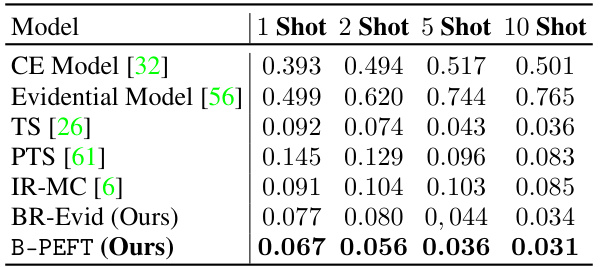
This table presents the prediction accuracy and expected calibration error (ECE) for different few-shot learning scenarios using various models. It compares the performance of a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed Bayesian-PEFT (B-PEFT) model. The results are shown for different datasets (Cifar10, Cifar100, Food101, Flowers102) and varying numbers of shots (1, 2, 5, 10, 20). It demonstrates the improved calibration performance of the Bayesian-PEFT model across different settings.
This table presents a comparison of prediction accuracy and Expected Calibration Error (ECE) across various few-shot learning scenarios (1-shot, 2-shot, 5-shot, 10-shot, and 20-shot) and four different datasets (Cifar10, Cifar100, Food101, and Flowers102). The results are broken down for four model types: the standard model (baseline), an evidential model, a calibrated evidential model (with base-rate adjustment), and the proposed Bayesian-PEFT model. The table illustrates the effectiveness of Bayesian-PEFT in achieving significantly higher accuracy and substantially lower ECE (better calibration) across all datasets and shot scenarios compared to other methods.

This table shows the prediction accuracy and expected calibration error (ECE) for different few-shot learning settings (1-shot, 2-shot, 5-shot, 10-shot, and 20-shot) across four datasets (Cifar10, Cifar100, Food101, and Flowers102). The results are presented for a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed B-PEFT model. This allows for a comparison of the performance and calibration of different models under various few-shot scenarios.

This table presents the prediction accuracy and expected calibration error (ECE) of different models on various few-shot adaptation tasks. It compares the performance of a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed Bayesian-PEFT model (B-PEFT). Results are shown for four datasets (Cifar10, Cifar100, Food101, Flowers102) and various shot settings (1-shot, 2-shot, 5-shot, 10-shot, 20-shot). The table highlights the improved calibration and accuracy achieved by the Bayesian-PEFT model.
This table presents a comparison of prediction accuracy and Expected Calibration Error (ECE) across different few-shot learning scenarios (1-shot to 20-shot) using various models. The models include a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed Bayesian-PEFT model. The results are shown for four different datasets: Cifar10, Cifar100, Food101, and Flowers102. This allows for a comprehensive evaluation of the different models under various data conditions and training regimes, highlighting the effectiveness of Bayesian-PEFT in improving both accuracy and calibration.
This table presents a comparison of prediction accuracy and expected calibration error (ECE) across four datasets (Cifar10, Cifar100, Food101, Flowers102) and different numbers of training shots (1, 2, 5, 10, 20) for various models: a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed B-PEFT model. It demonstrates the impact of the proposed Bayesian adjustments on improving both accuracy and calibration, particularly in few-shot scenarios.
This table presents the prediction accuracy and expected calibration error (ECE) for different few-shot learning settings (1-shot, 2-shot, 5-shot, 10-shot, 20-shot) across four datasets (CIFAR-10, CIFAR-100, Food101, Flowers102). It compares the performance of four different models: a standard model, an evidential model, a base-rate adjusted evidential model, and the proposed B-PEFT model. The results show the effect of different model architectures and calibration techniques on both prediction accuracy and uncertainty calibration.

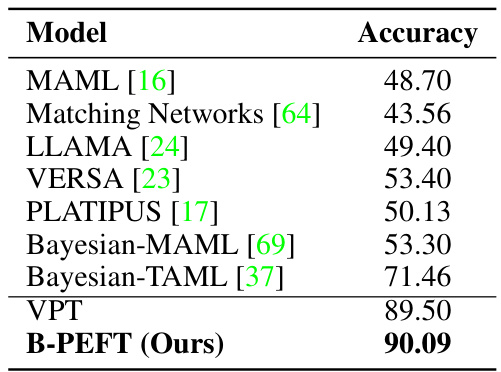
This table compares the accuracy of the proposed B-PEFT model against other meta-learning models on a 5-way 1-shot mini-ImageNet few-shot learning task. It demonstrates the superior performance of B-PEFT compared to existing meta-learning approaches.

This table presents a comparison of prediction accuracy and Expected Calibration Error (ECE) across four different datasets (Cifar10, Cifar100, Food101, Flowers102) and five different shot settings (1, 2, 5, 10, 20 shots). It compares the performance of four different model types: a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed Bayesian-PEFT model. The results show the impact of different model approaches and the effectiveness of the proposed Bayesian-PEFT model in improving both accuracy and calibration.
This table presents the prediction accuracy and Expected Calibration Error (ECE) for different few-shot learning scenarios across four datasets (Cifar10, Cifar100, Food101, Flowers102). The results are shown for a standard model, an evidential model, a calibrated evidential model (with base rate adjustment), and the proposed Bayesian-PEFT (B-PEFT) model. Different shot sizes (1, 2, 5, 10, 20) are compared, illustrating the performance of each model under various data limitations.
This table presents a comparison of prediction accuracy and Expected Calibration Error (ECE) across different few-shot learning settings and methods. The results are shown for four datasets (Cifar10, Cifar100, Food101, Flowers102) and across varying numbers of shots (1, 2, 5, 10, 20). It compares the performance of a standard model, an evidential model, a base-rate adjusted evidential model, and the proposed Bayesian-PEFT model. The table shows that Bayesian-PEFT consistently outperforms the other methods across all datasets and settings, achieving higher accuracy and lower ECE.
This table presents the prediction accuracy and expected calibration error (ECE) for different models on four datasets (Cifar10, Cifar100, Food101, Flowers102) under various few-shot learning settings (1, 2, 5, 10, and 20 shots). It compares the performance of a standard model, an evidential model, a calibrated evidential model, and the proposed B-PEFT model. The results show the impact of different approaches on prediction accuracy and calibration, highlighting the effectiveness of B-PEFT in improving both metrics, especially under challenging few-shot scenarios.
Full paper#