↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large pre-trained models (PTMs) offer powerful zero-shot classification but often include unnecessary classes that degrade overall accuracy. Existing solutions assume ‘white-box’ access, requiring model parameters and gradients; this is impractical for commercially sensitive or socially responsible PTMs. The ‘Black-Box Forgetting’ problem thus emerges, as selective forgetting without model internal information is needed.
This paper introduces a novel approach to solve the black-box forgetting problem by tuning the input text prompt. To handle the high dimensionality of prompt optimization, a latent context sharing (LCS) method is proposed, which introduces common low-dimensional latent components among multiple tokens for the prompt. Using derivative-free optimization, the method efficiently enhances forgetting performance on benchmark datasets. The proposed solution offers a significant step toward practical and ethical use of large-scale PTMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the significant challenge of selective forgetting in large black-box pre-trained models (PTMs), a critical limitation in deploying such models for real-world applications where processing all object classes is unnecessary. The proposed approach provides a practical and effective solution for selective forgetting without needing model internals, opening new avenues for research into PTM optimization and responsible AI.
Visual Insights#

This figure illustrates the Black-Box Forgetting framework. It shows how the model uses a learnable text prompt to selectively reduce the accuracy of specified classes while maintaining accuracy for others. The process involves computing class confidence scores based on image and text embeddings, then optimizing two loss functions: entropy maximization for classes to be forgotten and cross-entropy minimization for classes to be memorized. Derivative-free optimization (CMA-ES) is used because model gradients are unavailable in black-box settings. Latent Context Sharing (LCS) is employed to reduce the complexity of high-dimensional optimization.
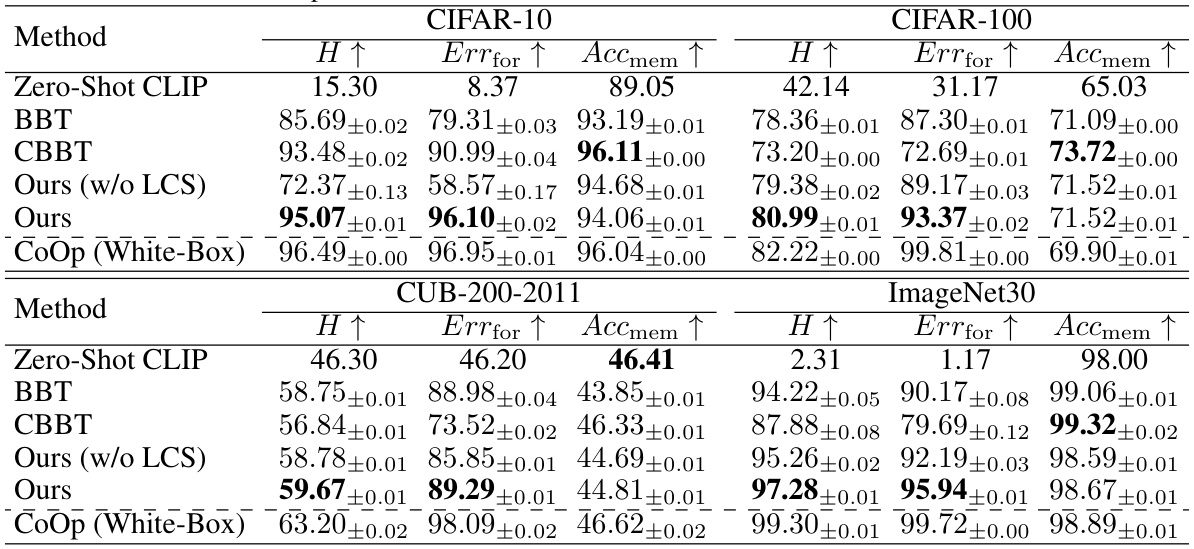
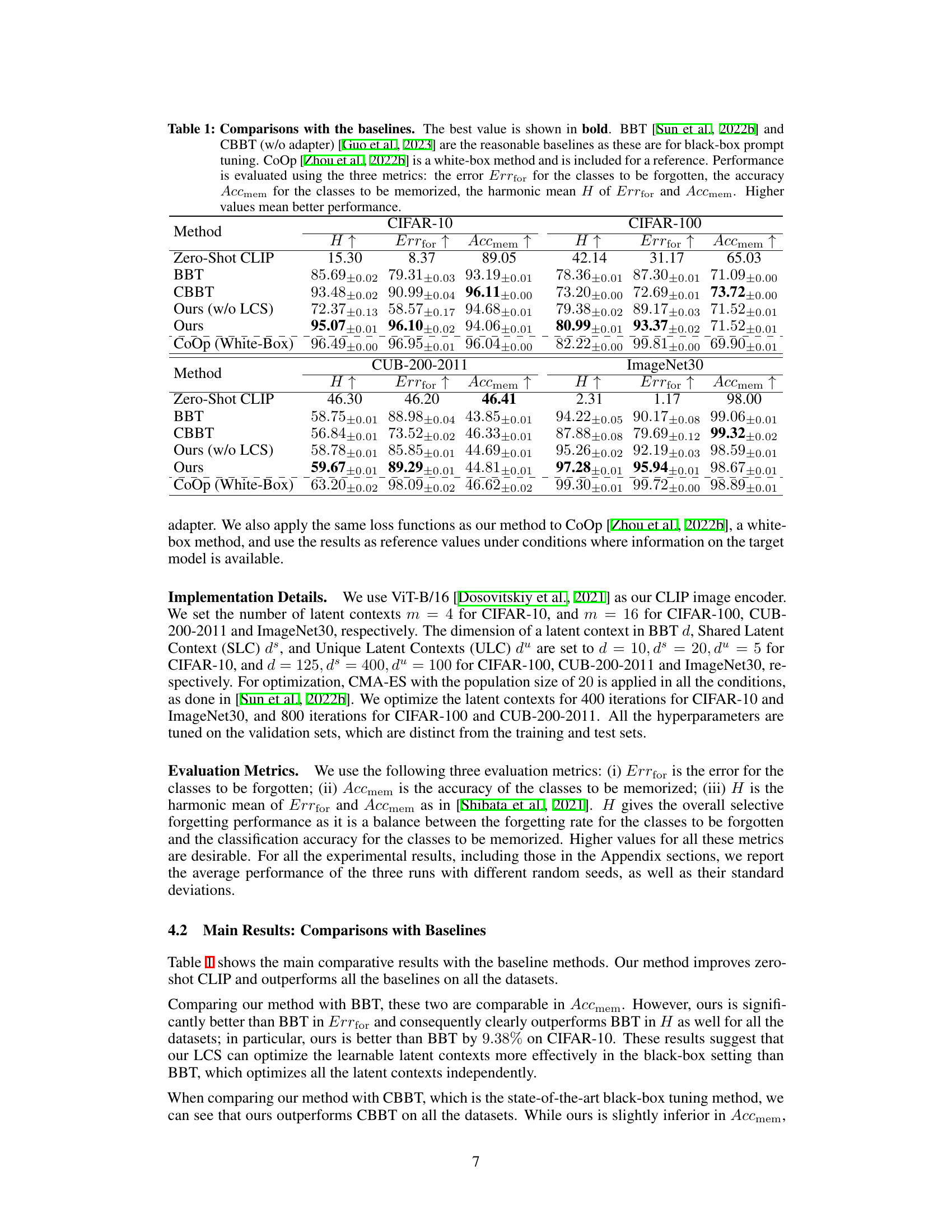
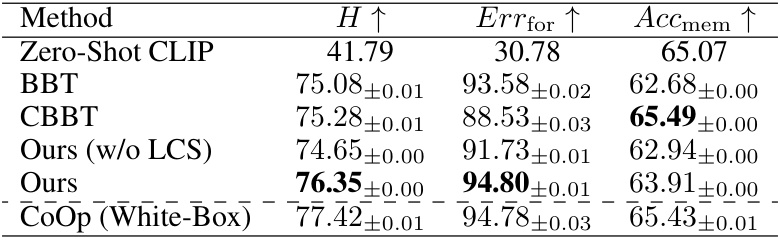
This table compares the proposed Black-Box Forgetting method with several baselines across four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP (no tuning), BBT (Black-Box Tuning), and CBBT (Collaborative Black-Box Tuning, without the visual adapter). CoOp (a white-box method) serves as a performance upper bound. The comparison uses three metrics:
Errfor(error rate for forgotten classes),Accmem(accuracy for memorized classes), andH(harmonic mean ofErrforandAccmem). Higher values indicate better performance. The table shows that the proposed method generally outperforms the baselines in terms of the harmonic mean (H) across all datasets.
In-depth insights#
Black-Box Forgetting#
The concept of “Black-Box Forgetting” presents a compelling challenge in the field of machine learning. It tackles the problem of selectively removing knowledge from large pre-trained models (PTMs) where the internal workings are opaque (“black box”). This is crucial because PTMs often retain information about unnecessary classes, degrading overall accuracy and efficiency. The difficulty lies in achieving selective forgetting without access to the model’s internal parameters or gradients, requiring novel optimization techniques. The proposed solution might involve manipulating input prompts to subtly alter the model’s behavior, making it less accurate for specific classes. This approach raises questions about the effectiveness of derivative-free optimization in high-dimensional spaces and the potential need for innovative prompt engineering strategies. Achieving high forgetting performance while preserving accuracy for other classes remains a significant hurdle. The implications for deploying and maintaining PTMs in real-world applications, especially those concerning privacy and security, are far-reaching. Future work might explore more sophisticated prompt designs and more efficient derivative-free optimization methods to address this limitation.
Derivative-Free Opt.#
The heading ‘Derivative-Free Optimization’ highlights a crucial aspect of the research: addressing the challenge of optimizing a black-box model. Traditional gradient-based optimization methods are inapplicable because the model’s internal workings and gradients are unavailable. The researchers’ decision to use derivative-free methods like CMA-ES (Covariance Matrix Adaptation Evolution Strategy) is a key strength, as it allows for model-agnostic optimization. However, derivative-free optimization is computationally expensive and struggles with high dimensionality, thus necessitating the introduction of Latent Context Sharing (LCS) to reduce the optimization space. This clever workaround demonstrates an understanding of the tradeoffs involved in selecting such a method and showcases ingenuity in overcoming a major constraint presented by the black-box nature of the pre-trained models. The choice of CMA-ES along with LCS is a strategic decision that balances optimization efficacy with computational feasibility in a high-dimensional space, reflecting a sophisticated approach to the problem.
Latent Context Share#
The concept of “Latent Context Sharing” presents a novel approach to optimizing high-dimensional input prompts in black-box models. By introducing low-dimensional latent components, it mitigates the computational challenges of derivative-free optimization methods, such as CMA-ES, which are commonly used when model gradients are unavailable. The method’s effectiveness stems from its ability to capture semantic correlations between tokens within the prompt, improving both the efficiency and effectiveness of prompt tuning. This allows for a more robust and efficient way to influence the model’s output without needing internal model parameters or gradients, offering a powerful tool for tasks such as selective forgetting in black-box vision-language models. The technique elegantly balances the need for high forgetting performance with the limitations imposed by black-box constraints. It’s a significant advancement in the field of derivative-free optimization for high-dimensional problems, especially in the context of black-box model manipulation.
Zero-Shot Forgetting#
Zero-shot forgetting, a novel concept in machine learning, focuses on selectively removing a model’s ability to recognize specific classes without retraining. This is particularly useful when dealing with large pre-trained models (PTMs) where retraining is computationally expensive and may negatively affect performance on other classes. The core challenge lies in achieving this without access to the model’s internal parameters or gradients, making it a ‘black-box’ problem. Approaches may involve manipulating input prompts or employing derivative-free optimization techniques. A key advantage is that it can avoid catastrophic forgetting, where learning new tasks causes a model to lose knowledge of previously learned ones. Success in zero-shot forgetting is significant because it enables efficient adaptation of PTMs to specific downstream applications while minimizing performance degradation.
Future Research#
Future research directions stemming from this Black-Box Forgetting work could explore several promising avenues. Extending the methodology to other black-box models, beyond CLIP, is crucial to demonstrate broader applicability and robustness. This includes investigating the effectiveness of latent context sharing across diverse architectures and modalities. Another key area is improving the efficiency of the derivative-free optimization process. While CMA-ES works, more efficient algorithms tailored to this specific problem, potentially leveraging gradient-free optimization techniques, would significantly enhance scalability. The impact of prompt engineering techniques on forgetting performance also warrants further exploration. Could advanced prompt designs achieve superior forgetting accuracy with fewer optimization steps? Finally, a thorough investigation into the robustness of the method under different data distributions and noise conditions is necessary. The influence of data scarcity, class imbalance, and the presence of adversarial examples remains an open question. Addressing these limitations would solidify the practical impact and expand the potential for this approach in real-world applications.
More visual insights#
More on figures
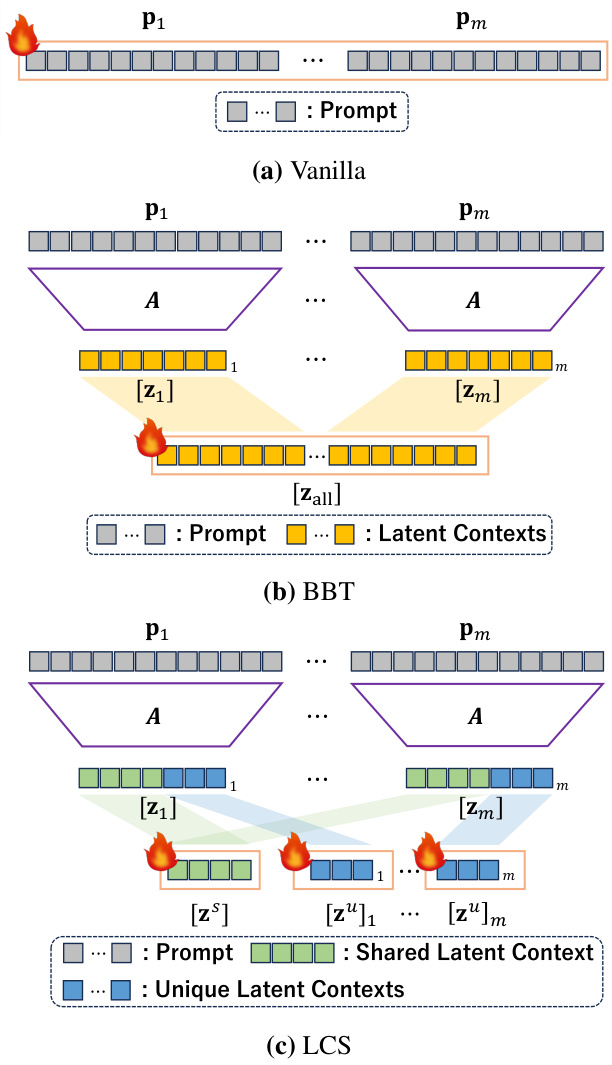
This figure illustrates the Black-Box Forgetting framework. It shows how the system uses a pre-trained vision-language model (like CLIP) to estimate class confidence. This confidence is then used in two loss functions: one to maximize entropy for classes to be forgotten (reducing accuracy), and one to minimize cross-entropy for classes to be remembered (maintaining accuracy). Because the model is a black box, derivative-free optimization (CMA-ES) is used to optimize the input prompt. Latent Context Sharing (LCS) is employed to reduce the dimensionality of the optimization problem.

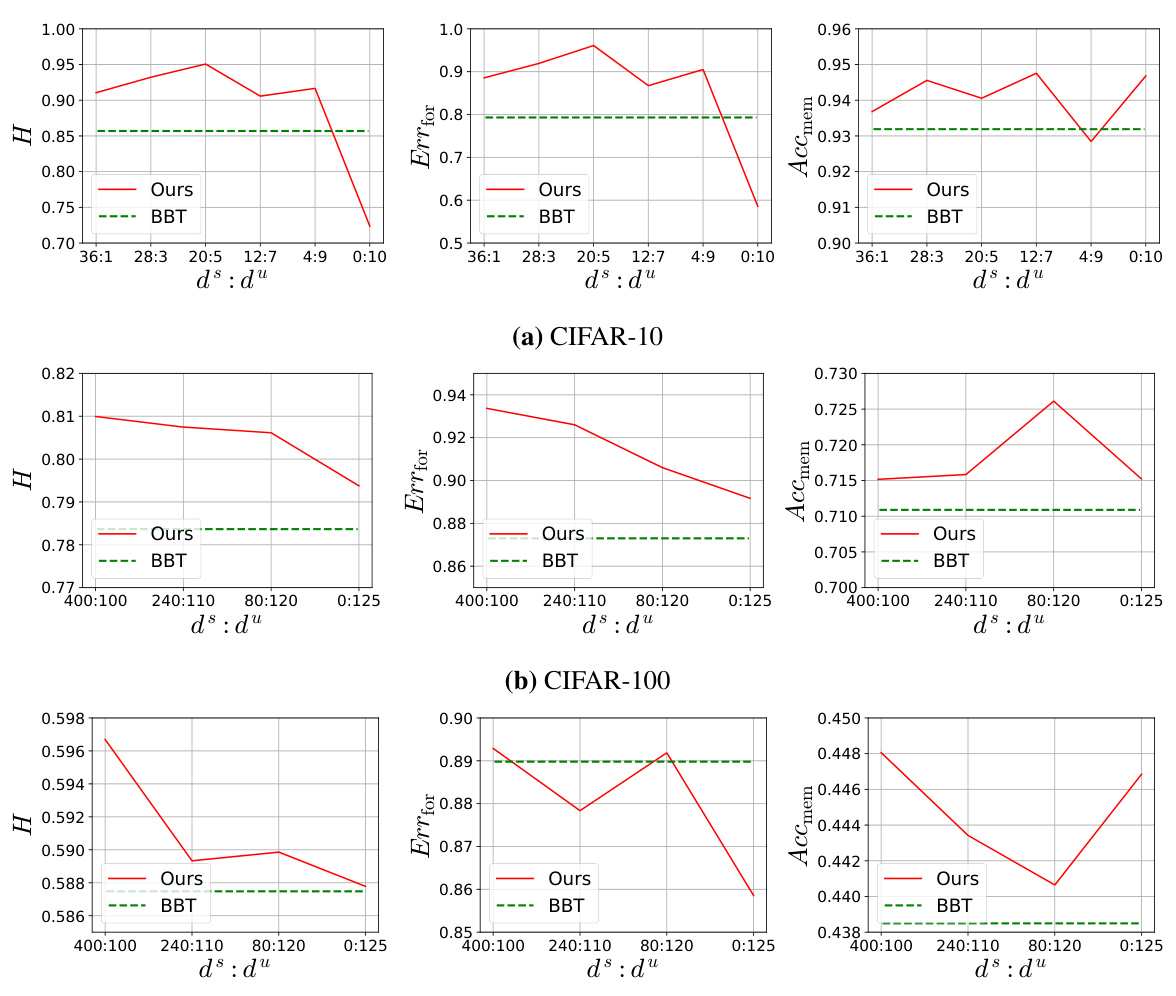
This figure shows how the performance of the proposed method and the baseline method (BBT) changes with the number of latent contexts. The x-axis represents the number of latent contexts (m), and the y-axis shows the performance metrics (H, Err_for, Acc_mem). The results indicate that the proposed method maintains relatively stable performance across a wide range of m values, while the BBT method’s performance is more sensitive to changes in m.
This figure illustrates the Black-Box Forgetting framework. It shows how the confidence scores for each class are calculated using a pre-trained vision-language model (like CLIP) and how these scores are used to define loss functions. For classes to be forgotten, entropy maximization is used to reduce accuracy, while for classes to be remembered, cross-entropy minimization maintains accuracy. The framework uses CMA-ES, a derivative-free optimization method, to optimize the text prompt, and employs Latent Context Sharing (LCS) to reduce the complexity of high-dimensional optimization.
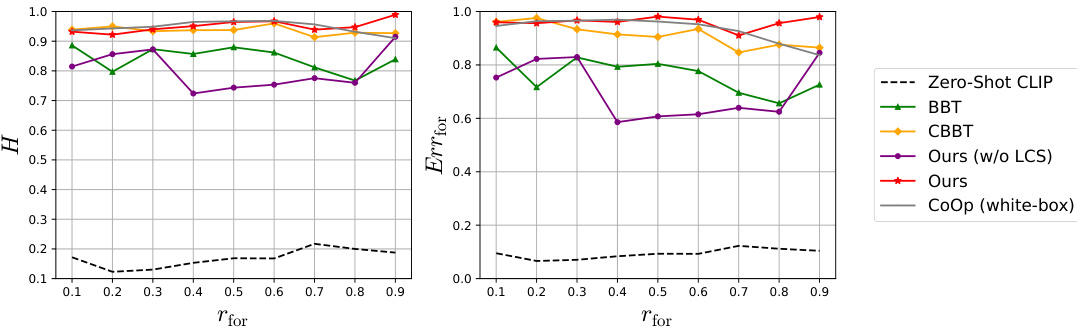
This figure shows the impact of the number of latent contexts (m) on the performance of both BBT and the proposed method. The x-axis represents the number of latent contexts, while the y-axis shows the three evaluation metrics: H (harmonic mean of forgetting and memorization accuracy), Err_for (error rate for forgotten classes), and Acc_mem (accuracy for memorized classes). The figure demonstrates that the proposed method maintains relatively stable performance across a range of m values, unlike BBT, which shows significant performance fluctuations.
More on tables
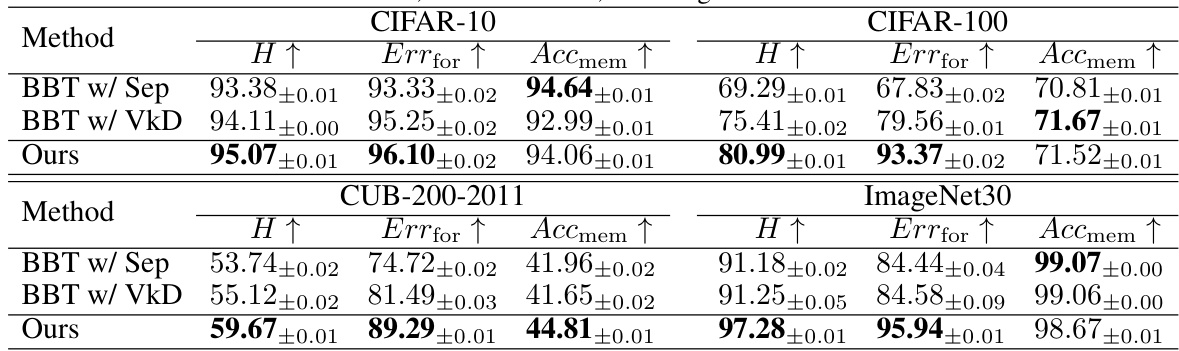
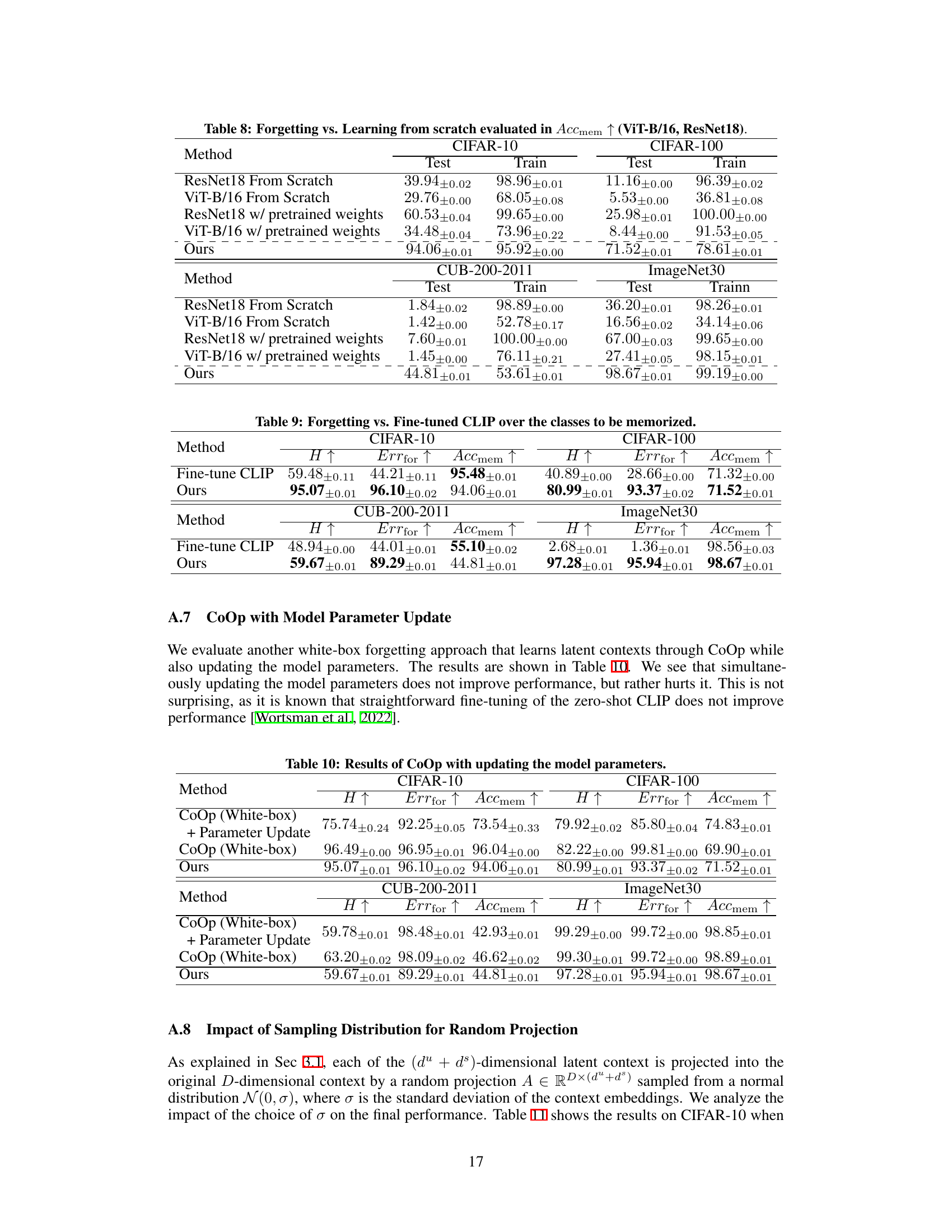
This table compares the performance of the proposed Black-Box Forgetting method against several baselines on four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP, Black-Box Tuning (BBT), and Collaborative Black-Box Tuning (CBBT), along with a white-box method (CoOp) for comparison. The table reports three metrics: the error rate for forgotten classes (Errfor), the accuracy for memorized classes (Accmem), and the harmonic mean (H) of these two metrics, higher values indicating better performance. The results demonstrate the superiority of the proposed method in selective forgetting while maintaining good accuracy for the remaining classes.
This table compares the proposed Black-Box Forgetting method’s performance against several baseline methods across four datasets. It shows the error rate for forgotten classes (Errfor), accuracy for memorized classes (Accmem), and the harmonic mean (H) of these two metrics. Higher values are better, indicating more effective forgetting while preserving accuracy for the intended classes.

This table compares the performance of the proposed Black-Box Forgetting method against several baselines on four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP, Black-Box Tuning (BBT), Collaborative Black-Box Tuning (CBBT), and a white-box method (CoOp) for comparison. Performance is measured using three metrics: Errfor (error rate for forgotten classes), Accmem (accuracy for memorized classes), and H (harmonic mean of Errfor and Accmem). Higher values indicate better performance. The table shows that the proposed method generally outperforms the baselines.

This table compares the proposed Black-Box Forgetting method against several baselines on four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP, Black-Box Tuning (BBT), and Collaborative Black-Box Tuning (CBBT) as well as a white-box method (CoOp) for comparison. Performance is assessed using three metrics: error rate for forgotten classes (Errfor), accuracy for memorized classes (Accmem), and the harmonic mean (H) of Errfor and Accmem. Higher values for all metrics indicate better performance. The table shows that the proposed method generally outperforms the baselines, particularly in terms of the harmonic mean (H).

This table compares the performance of the proposed Black-Box Forgetting method against several baseline methods (BBT, CBBT, and CoOp) and the Zero-Shot CLIP on four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The comparison is based on three metrics: Errfor (error rate for forgotten classes), Accmem (accuracy for memorized classes), and H (harmonic mean of Errfor and Accmem). Higher values indicate better performance. The table highlights the superior performance of the proposed method, especially in terms of the harmonic mean H, showing a significant improvement over existing methods in achieving selective forgetting while preserving accuracy for the intended classes.

This table compares the performance of two approaches: one using only the few-shot approach for classes with training samples (Ours), and another combining few-shot approach for classes with samples and zero-shot approach for classes without samples (Ours + C-Emb.). The results show that combining the two approaches can improve performance in terms of harmonic mean (H), error for classes to be forgotten (Errfor), and accuracy for memorized classes (Accmem).
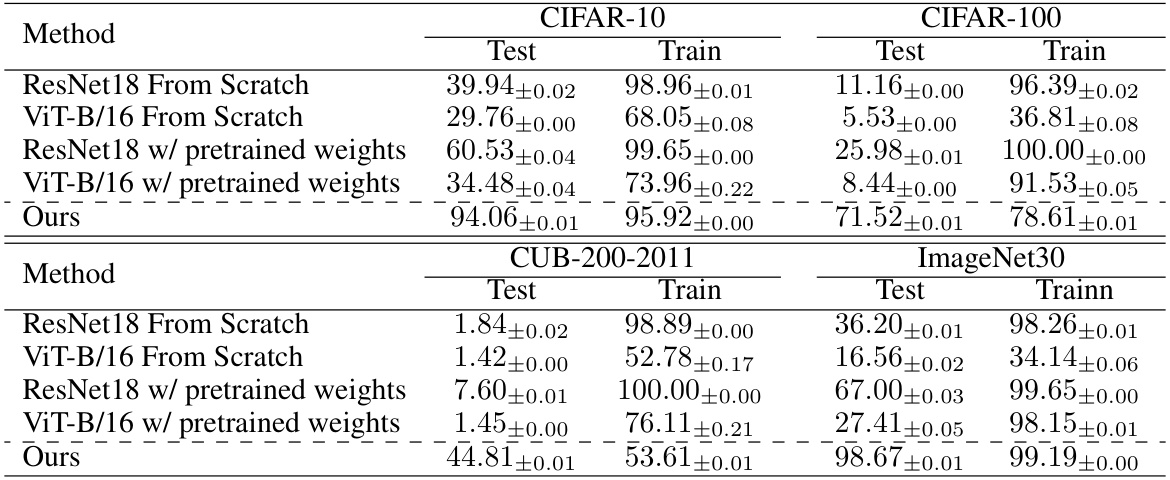
This table compares the performance of the proposed Black-Box Forgetting method against several baselines on four image classification datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP, BBT (Black-Box Tuning), and CBBT (Collaborative Black-Box Tuning without visual adapter), along with a white-box method, CoOp, for comparison. The table shows the error rate (Errfor) for forgotten classes, the accuracy (Accmem) for memorized classes, and the harmonic mean (H) of these two metrics for each method and dataset. Higher values indicate better performance.

This table compares the performance of the proposed Black-Box Forgetting method against several baselines on four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP, Black-Box Tuning (BBT), and Collaborative Black-Box Tuning (CBBT), along with a white-box method (CoOp) for comparison. Performance is assessed using three metrics: error rate for forgotten classes (Errfor), accuracy for memorized classes (Accmem), and the harmonic mean of these two (H). Higher values indicate better performance.

This table compares the performance of the proposed Black-Box Forgetting method against several baselines on four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP, Black-Box Tuning (BBT), and Collaborative Black-box Tuning (CBBT), representing different approaches to prompt tuning for black-box models. A white-box method (CoOp) is also included for comparison. Performance is measured using three metrics: error rate for forgotten classes (Errfor), accuracy for memorized classes (Accmem), and the harmonic mean (H) of these two. Higher values for all metrics indicate better performance. The table highlights the superior performance of the proposed method across all datasets and metrics.

This table compares the proposed Black-Box Forgetting method to several baselines across four different datasets. The baselines include zero-shot CLIP, BBT, and CBBT (without the adapter), which are all suitable for black-box prompt tuning. CoOp (a white-box method) is also included for comparison. Performance is measured using three metrics: the error rate for forgotten classes (Errfor), the accuracy for memorized classes (Accmem), and the harmonic mean (H) of these two. Higher values indicate better performance.
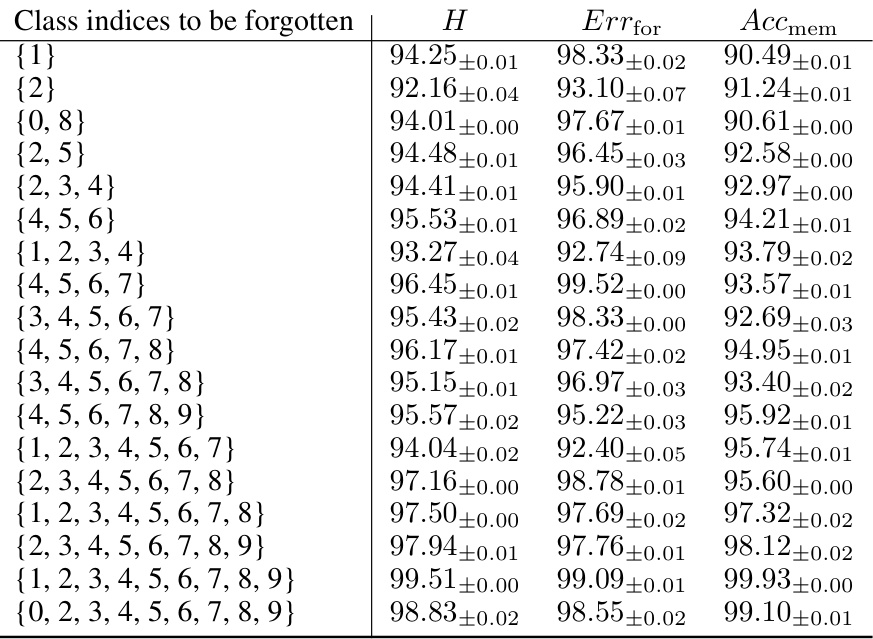
This table compares the performance of the proposed Black-Box Forgetting method against several baselines on four benchmark datasets (CIFAR-10, CIFAR-100, CUB-200-2011, and ImageNet30). The baselines include zero-shot CLIP, BBT (Black-Box Tuning), and CBBT (Collaborative Black-Box Tuning) representing different prompt tuning techniques. CoOp (a white-box method) serves as a performance upper bound. The table reports three metrics for each method and dataset: Errfor (error rate for forgotten classes), Accmem (accuracy for memorized classes), and H (harmonic mean of Errfor and Accmem). Higher values indicate better performance. The results demonstrate that the proposed method outperforms the baselines, indicating its effectiveness in selectively forgetting specified classes while maintaining accuracy for others.
Full paper#