↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current human video generation struggles with producing realistic conversational videos that simultaneously capture frequent hand gestures and nuanced facial expressions. Most methods focus on either facial animation or full-body motion, lacking the detail and integration needed for natural-looking conversations. This inability to generate high-fidelity conversational videos limits the use of digital humans in various applications.
ShowMaker tackles this problem with a novel framework that employs a dual-stream diffusion model. Two key components – the Key Point-based Fine-grained Hand Modeling and Face Recapture modules – enhance the generation of hands and faces respectively, improving realism. Extensive quantitative and qualitative results demonstrate ShowMaker’s superior visual quality and temporal consistency compared to existing methods. This suggests significant progress in generating high-fidelity 2D human videos for use in interactive applications and content creation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents ShowMaker, a novel framework for generating high-fidelity 2D human videos, addressing limitations in existing methods. Its focus on fine-grained modeling of crucial local regions (hands and face), along with the use of 2D key points as input, makes it a valuable contribution to the field of digital human technology. This could be very useful to researchers interested in generating high-fidelity videos with realistic human expressions. ShowMaker opens new avenues for research in areas like animation, virtual reality, and film. It is also significant in improving the quality and realism of conversational avatars.
Visual Insights#
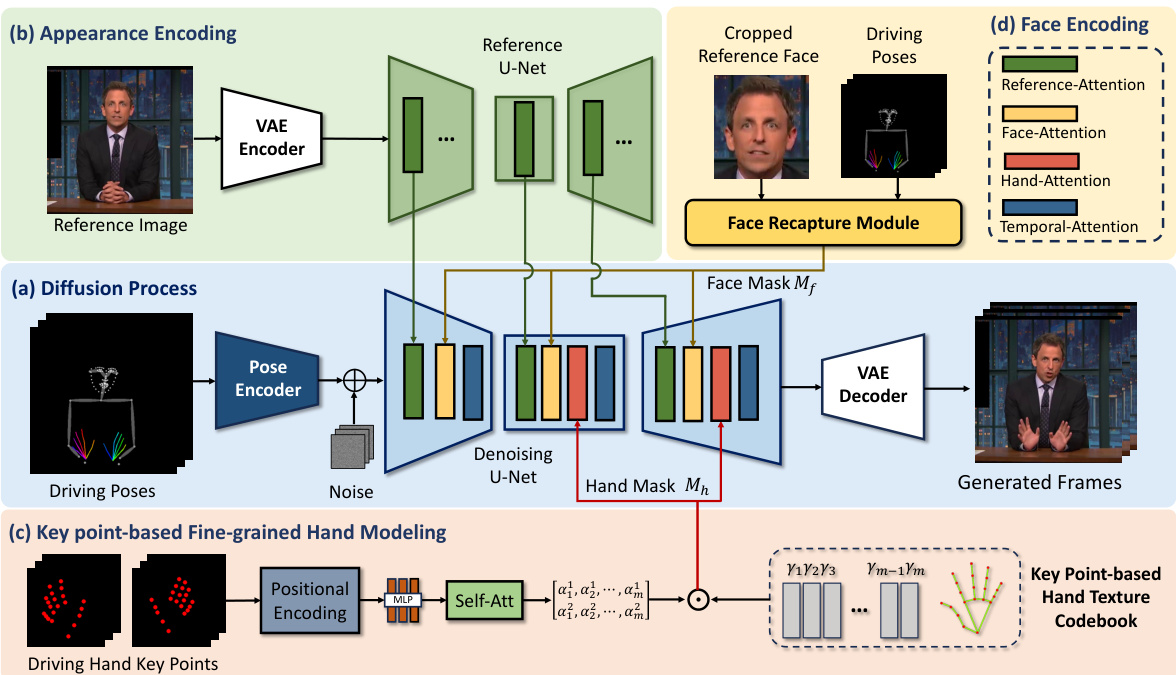
This figure provides a high-level overview of the ShowMaker framework, a dual-stream model using a Reference U-Net for appearance encoding and a Denoising U-Net for diffusion processing. It highlights two key components: a Key Point-based Fine-grained Hand Modeling module and a Face Recapture module, which are designed to enhance the quality of generated hand and facial regions. The overall process takes a reference image and driving poses as input and generates a high-fidelity conversational video.
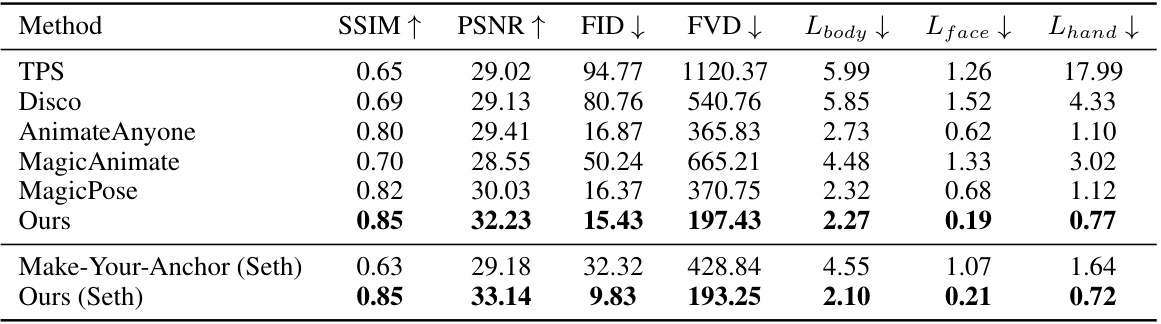
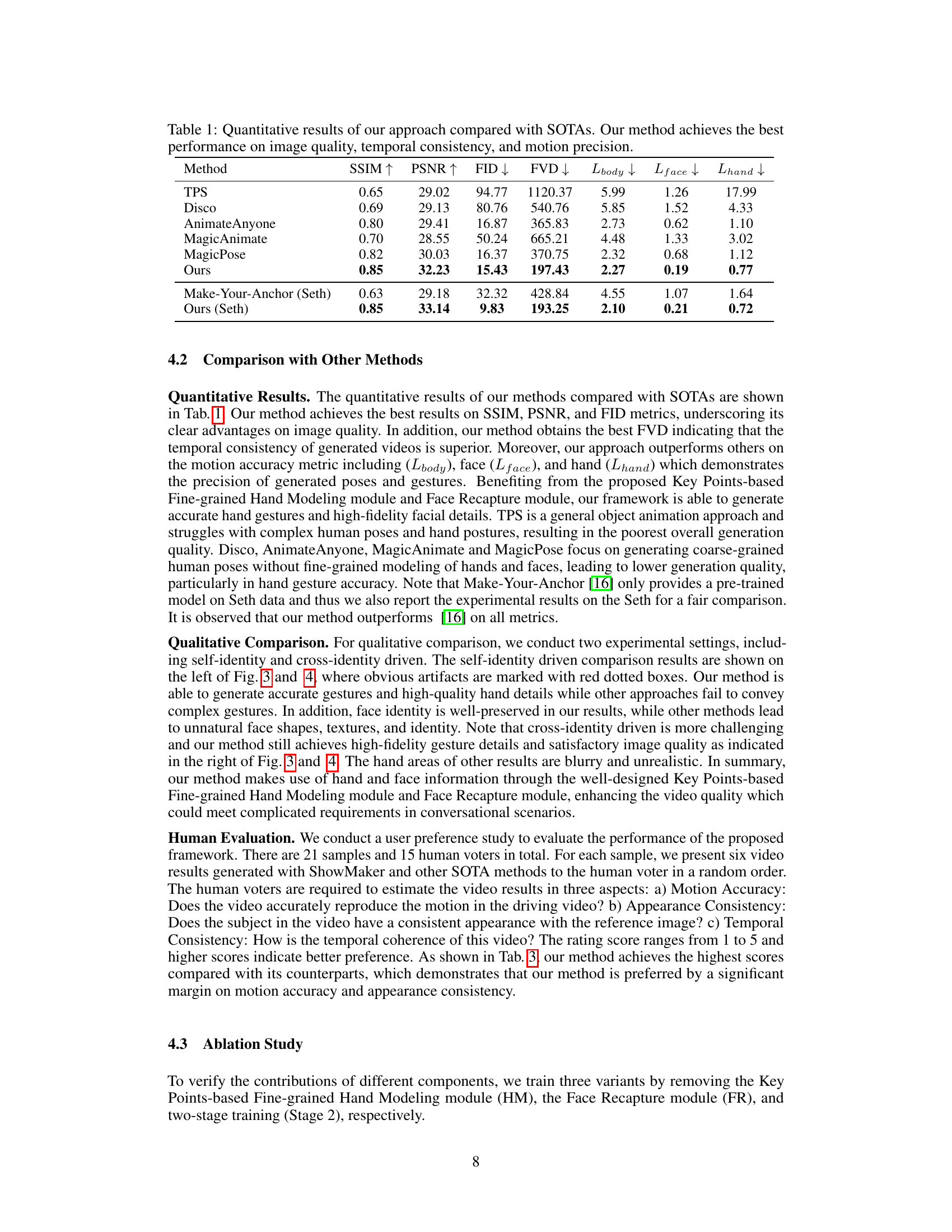
This table presents a quantitative comparison of the proposed ShowMaker model against several state-of-the-art (SOTA) methods for 2D human video generation. The comparison uses several metrics to evaluate the performance, including SSIM (Structural Similarity Index) and PSNR (Peak Signal-to-Noise Ratio) for image quality, FID (Fréchet Inception Distance) and FVD (Fréchet Video Distance) for video quality and temporal consistency, and three separate metrics (Lbody, Lface, Lhand) for the accuracy of body, face and hand motion respectively. The results demonstrate ShowMaker’s superiority across all aspects of 2D human video generation.
In-depth insights#
Fine-grained Diffusion#
Fine-grained diffusion models represent a significant advancement in generative modeling, offering enhanced control and fidelity compared to their coarser-grained counterparts. Instead of treating an image as a holistic entity, fine-grained diffusion operates at a more granular level, often focusing on specific regions or features. This allows for more precise manipulation and generation of details, such as individual hairs, facial wrinkles, or intricate textures in clothing. The approach often involves multi-scale or hierarchical diffusion processes, where lower-level details are refined before being incorporated into higher-level structures. This strategy is particularly beneficial for generating realistic images of complex scenes or objects, requiring fine-level detail and accurate representation. Applications span various domains, including image generation, video synthesis, and 3D modeling, where high fidelity and control are critical. Despite the potential for greater realism, challenges remain, including increased computational cost and the potential for artifacts in fine-detail generation. Future work likely involves exploring more efficient architectures and refined training techniques to overcome these challenges and unlock the full potential of fine-grained diffusion models.
Dual-Stream Approach#
A dual-stream approach in a deep learning context typically involves processing input data through two separate, parallel pathways before integrating their outputs. This strategy is frequently used in tasks like video generation or human pose estimation, where the input might contain both spatial (image frames) and temporal (motion sequence) information. One stream might focus on appearance, extracting visual features from images, while another stream processes motion data, analyzing temporal dynamics like keypoints or optical flow. This parallel processing allows the model to capture richer, more nuanced representations of the input, leveraging the strengths of different architectural components. The individual streams can incorporate distinct network architectures such as convolutional neural networks (CNNs) for spatial data and recurrent neural networks (RNNs) or transformers for temporal data. Subsequent fusion of stream outputs enables the model to effectively combine appearance and motion information, generating more coherent and realistic outputs. For example, in video generation, one stream could generate realistic faces while the other generates realistic motion, with the output streams combined for final video synthesis. Effective fusion mechanisms are vital to the success of dual-stream approaches, necessitating careful design to avoid information loss or interference between the two streams. This could involve attention mechanisms, concatenation, or more sophisticated integration strategies.
Hand & Face Modeling#
High-fidelity 2D human video generation, particularly for conversational scenarios, presents significant challenges in modeling fine details such as hands and faces. Accurate hand modeling is difficult due to sparse motion guidance from 2D keypoints. Methods often struggle to generate realistic hand textures and shapes. ShowMaker addresses this with a novel Key Point-based Fine-grained Hand Modeling module, which amplifies positional information from raw hand keypoints. This approach constructs a keypoint-based codebook to enhance hand structure guidance and leverage resolution-independent representations for robust hand synthesis. In addition, ShowMaker employs a Face Recapture module to restore richer facial details and preserve identity. This module leverages multi-level encoding to capture facial textures and global identity features, mitigating identity degradation issues common in cross-identity animation. These modules, combined with a dual-stream diffusion model, achieve superior visual quality and temporal consistency in generated videos.
Identity Preservation#
Identity preservation in AI-generated human videos is a significant challenge. Existing methods often struggle to maintain consistent identity across different poses and expressions, leading to variations that detract from realism. A key problem lies in the entanglement of identity features with other factors like pose and texture. Simply using a fixed reference image can be insufficient when dynamic factors change the visual appearance drastically. Effective identity preservation requires techniques that disentangle identity from pose and expression and robustly encode identity information into a latent space representation. This could involve techniques like separating texture and structural features, using generative models capable of controlling identity explicitly, or developing innovative encoding schemes which preserve identity even with significant changes in pose or lighting. Furthermore, the use of 3D models might offer superior identity preservation capabilities compared to solely using 2D input data because 3D models capture more complete information regarding the structure and shape of the face, making identity separation easier. Ultimately, the success of identity preservation hinges on careful attention to the encoding and decoding processes, ensuring that identity remains a robust and disentangled feature throughout the generation pipeline.
Future Enhancements#
The ‘Future Enhancements’ section of a research paper offers a valuable opportunity to explore potential improvements and extensions of the current work. Expanding the dataset’s diversity is crucial for enhancing generalizability and robustness, particularly addressing limitations in current demographic representation or scenario coverage. Further research could explore integrating multimodal inputs (audio, depth, etc.) for richer contextual information and improved accuracy. Improving the model’s efficiency via architectural optimizations or using more computationally efficient training methods could significantly reduce resource requirements and enhance practicality. Finally, investigating the ethical implications of the technology and developing robust safeguards against potential misuse is critical for responsible innovation. This might include exploring techniques for detecting and mitigating deepfakes or developing methods for preserving user privacy and identity. Addressing these future enhancements will pave the way for more effective, reliable, and ethical advancements in the field.
More visual insights#
More on figures
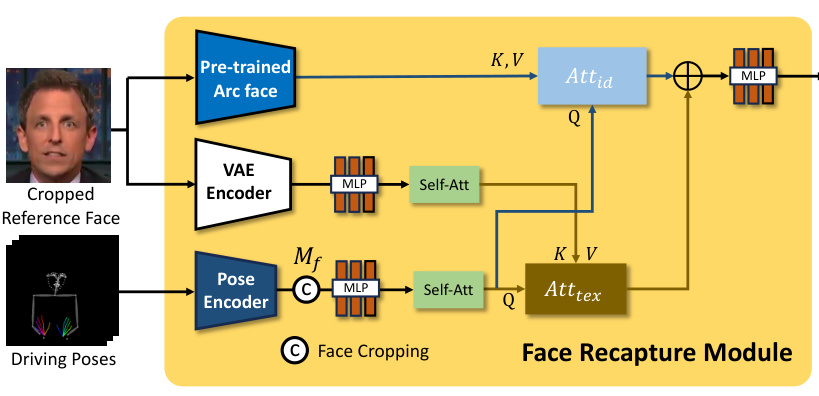
The Face Recapture module enhances the face area of the generated image by considering both texture details and global identity. First, a face detection model crops and aligns the face from the reference image. Then, a pre-trained VAE Encoder and face recognition model (ArcFace) extract the facial texture feature (Ftex) and global identity feature (Fid), respectively. For the facial texture feature, a Multilayer Perceptron (MLP) and a self-attention layer enhance the feature. Similarly, the driving pose’s facial pose information is also enhanced using MLP and self-attention. Finally, two cross-attention blocks merge the enhanced texture feature and identity feature with the enhanced facial pose information to obtain comprehensive face information (Gf). This comprehensive information is then fed into the face attention layer in the Denoising U-Net to improve the quality of the generated faces.
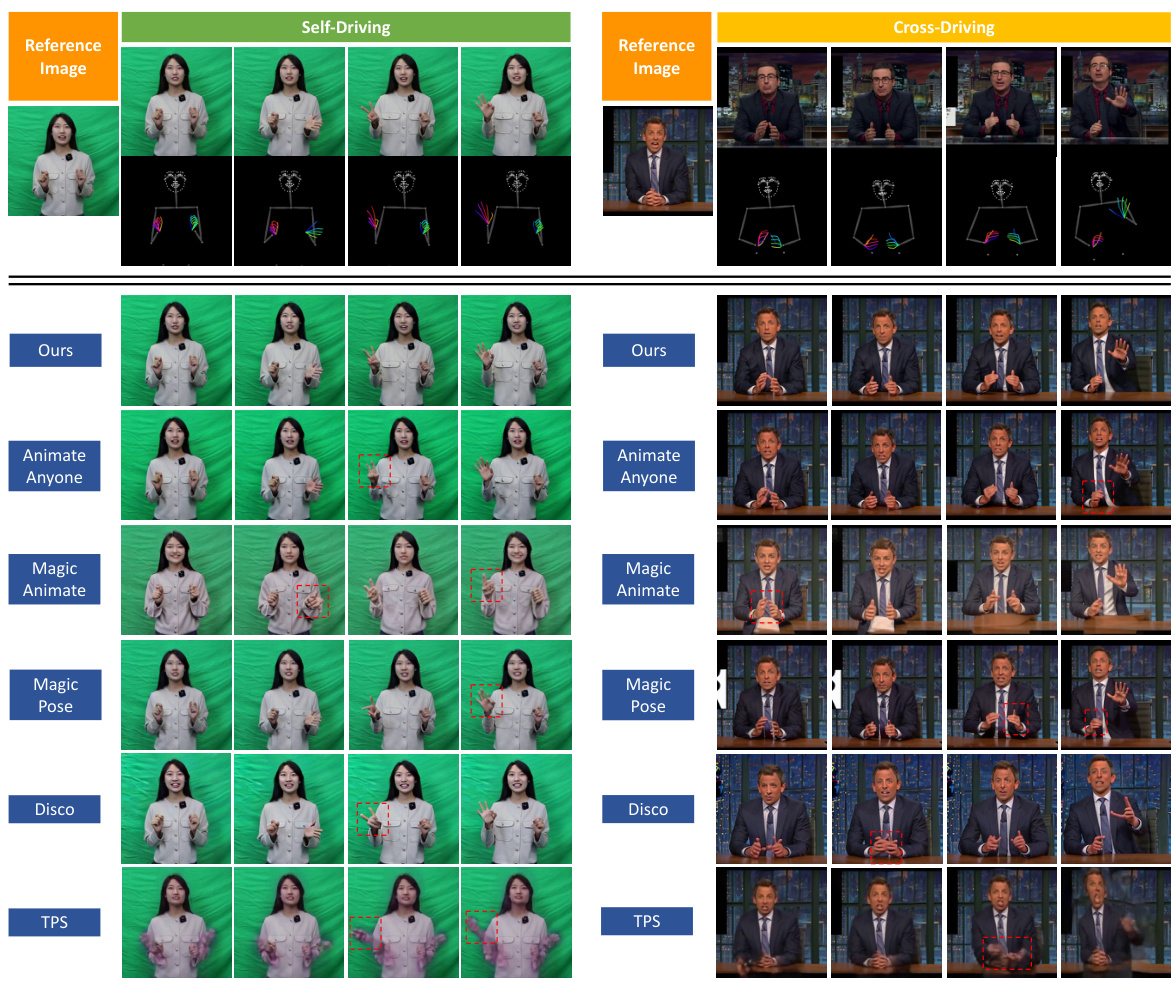
This figure displays a qualitative comparison of the proposed ShowMaker model against other state-of-the-art methods (AnimateAnyone, MagicAnimate, MagicPose, Disco, TPS) in both self-driving (using the same identity for reference and driving video) and cross-driving (using different identities) settings. The results showcase the superior performance of ShowMaker in generating high-fidelity videos with detailed hand gestures and facial expressions. The red boxes in certain images highlight areas where competing methods show artifacts or inaccuracies in hand or face details. ShowMaker consistently produces cleaner, more realistic results.

This figure displays a qualitative comparison of the proposed ShowMaker method with other state-of-the-art methods for 2D human video generation. It shows results for both self-driving (where the driving video features the same person as the reference image) and cross-driving (where the driving video features a different person than the reference image). The results illustrate that ShowMaker produces high-fidelity results with accurate gestures, superior image quality, and good consistency across both driving conditions. It directly compares generated video frames from ShowMaker to those from AnimateAnyone, MagicAnimate, MagicPose, Disco, and TPS across the self and cross-driving scenarios.

This figure shows a qualitative comparison of the results obtained using the full ShowMaker model against those obtained by removing either the Key Point-based Fine-grained Hand Modeling module, the Face Recapture module, or both. The top row shows hand gestures, highlighting the improved realism and detail when the Hand Modeling module is included. The bottom row shows facial expressions and details, illustrating the superior quality achieved with the Face Recapture module. The differences clearly demonstrate the significant contributions of both components to the overall high-fidelity video synthesis.
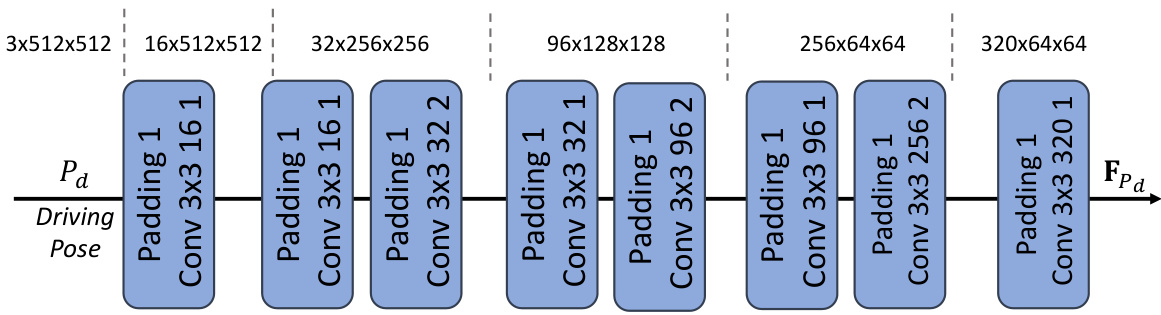
This figure presents a high-level overview of the ShowMaker framework, a dual-stream generative model for creating high-fidelity 2D human videos. The framework takes a reference image and driving poses as input and utilizes a Reference U-Net for appearance encoding and a Denoising U-Net for diffusion processing. Two novel modules, the Key Point-based Fine-grained Hand Modeling module and the Face Recapture module, are integrated to improve the quality of the generated videos, particularly in the hands and face regions.

This figure shows the ablation study results of the Key Point-based Fine-grained Hand Modeling module. It compares the generated hand images using four different methods: Vanilla (without the module), Hand image (using cropped hand images as input), w/o positional encoding (excluding positional encoding from the module), and Ours (using the full Key Point-based Fine-grained Hand Modeling module). The visual difference in hand details and quality demonstrates the effectiveness of each component in the proposed module.

This figure shows example video frames generated by the ShowMaker model. It demonstrates the temporal consistency of the generated videos by showing three frames (Frame 1, Frame 5, Frame 9) from two different video sequences. The consistency in the person’s appearance and movement between the frames highlights the model’s ability to maintain temporal coherence.
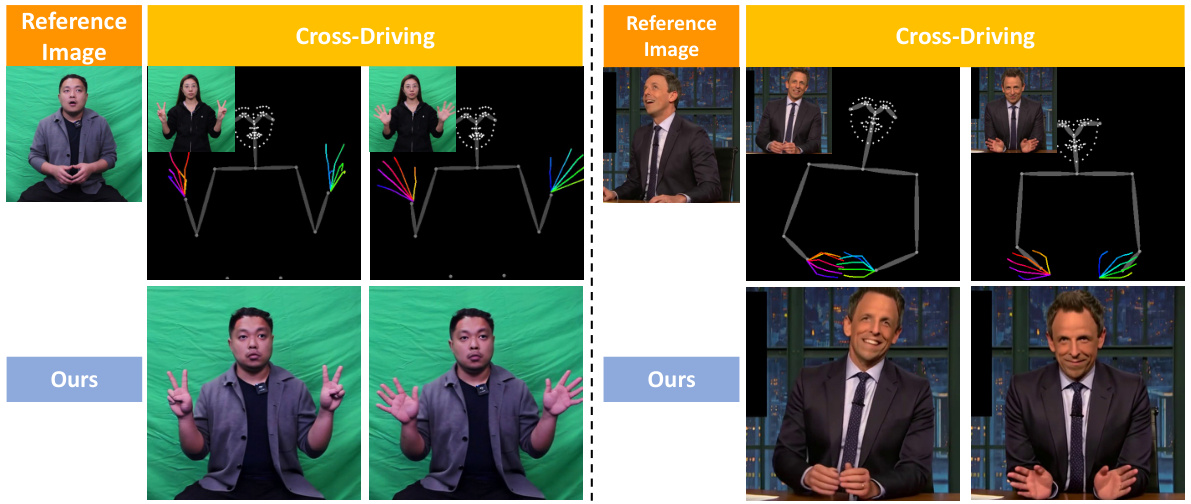
This figure showcases qualitative results comparing the proposed ShowMaker model with other state-of-the-art methods for 2D human video generation. Two scenarios are illustrated: self-driving (where the driving and reference videos are from the same person) and cross-driving (where the driving and reference videos are from different people). The figure demonstrates ShowMaker’s superiority in generating videos with high-fidelity gesture details and good image quality in both scenarios, contrasting it with artifacts and lower fidelity found in other approaches.
More on tables

This table presents the ablation study results by removing different components in the proposed ShowMaker framework. The metrics used are FVD (Fréchet Video Distance), Lface (mean Euclidean distance between face keypoints), and Lhand (mean Euclidean distance between hand keypoints). Removing the Key Point-based Fine-grained Hand Modeling module (HM) increases the FVD and Lhand. Removing the Face Recapture module (FR) increases Lface. Omitting the two-stage training significantly increases the FVD. The results demonstrate the effectiveness of each component in improving the overall performance of the model.

This table presents a quantitative comparison of the proposed ShowMaker method against several state-of-the-art (SOTA) approaches for 2D human video generation. The comparison uses several metrics to evaluate different aspects of video generation quality. SSIM and PSNR measure image quality; FID and FVD assess the quality and temporal consistency of the generated videos; and Lbody, Lface, and Lhand quantify the accuracy of body, face, and hand motion in the generated videos. The results demonstrate that ShowMaker outperforms the SOTA methods across all metrics, particularly in terms of motion accuracy and temporal consistency.
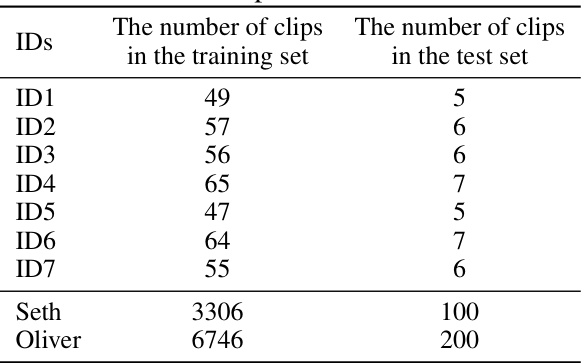
This table shows the number of video clips used for training and testing in the ShowMaker experiment. Seven indoor datasets (ID1-ID7) and two talkshow datasets (Seth and Oliver) were used. The table indicates that the training and testing sets are mutually exclusive and do not share any overlapping data.
Full paper#