↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly deployed via fine-tuning-as-a-service, where users can customize models with their own data. However, this creates a major security risk: a few malicious prompts can easily corrupt the model’s alignment and produce harmful outputs. This paper empirically demonstrates this “harmful embedding drift” phenomenon and investigates its root cause.
To address this, the researchers propose “Vaccine,” a novel technique that strengthens LLM alignment against adversarial attacks. Vaccine works by adding carefully designed perturbations to the embeddings during the alignment phase, making them resistant to harmful drifts introduced during user fine-tuning. Experiments on various LLMs show that Vaccine effectively reduces harmful outputs while maintaining acceptable performance on benign tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) safety and security. It highlights a significant vulnerability in fine-tuning-as-a-service, a prevalent LLM deployment model. The proposed solution, Vaccine, offers a novel approach to strengthening LLM robustness against adversarial attacks, opening avenues for developing more secure and reliable LLM systems. This is especially timely given the increasing use of LLMs in various applications and the growing concerns about their potential misuse.
Visual Insights#
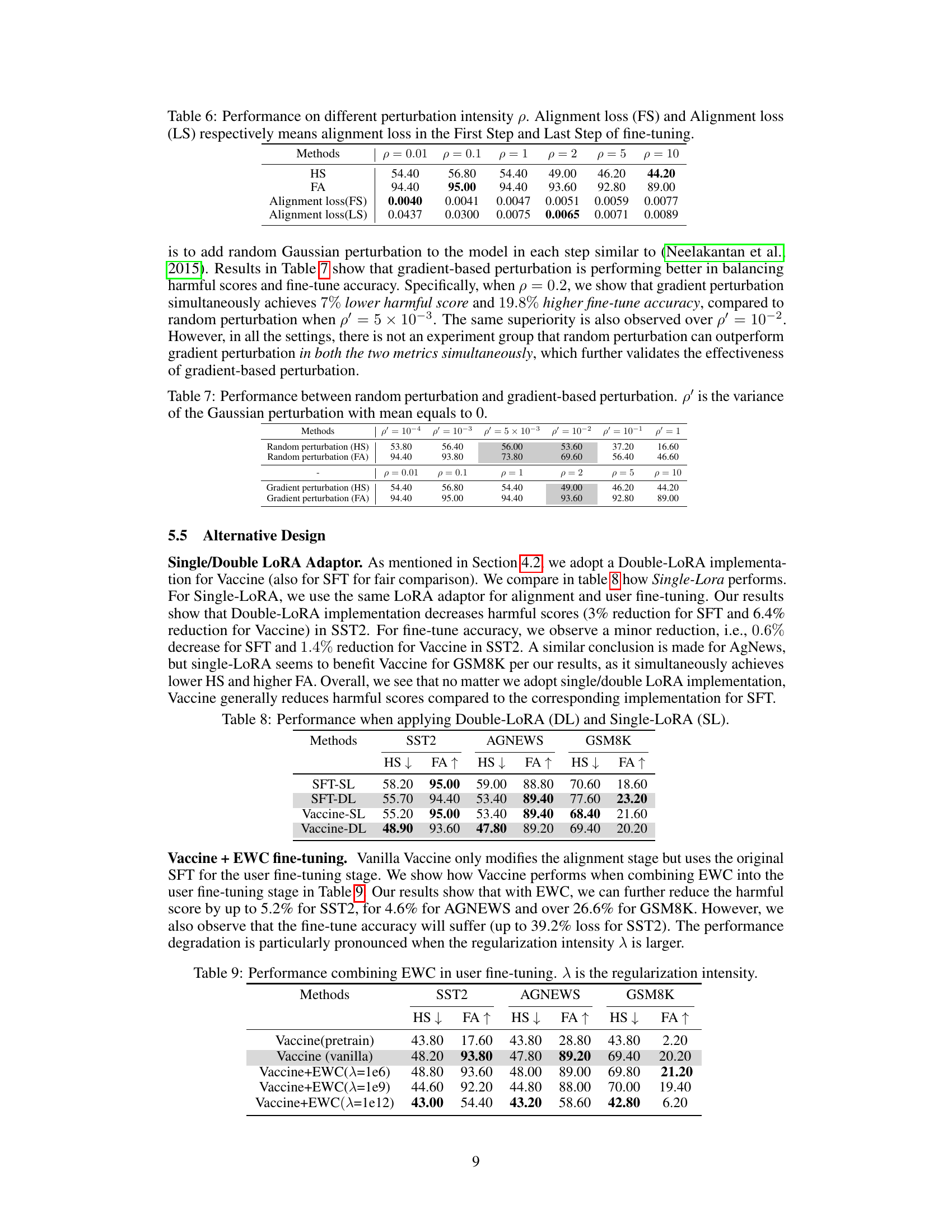
This figure illustrates the attack surface of harmful fine-tuning on large language models (LLMs). The left side shows a pre-trained LLM, which is then aligned using supervised fine-tuning (SFT) on a safe, harmless dataset (represented by a happy face). This results in an aligned LLM, depicted with a graph whose nodes are safely interconnected. However, when this aligned LLM is further fine-tuned using a dataset containing malicious instructions (represented by a devil face), the alignment is broken and the model produces harmful outputs (customized LLM). The graph shows a disruption of node interconnections, symbolizing the harmful effects.

This table presents the performance of various methods (Non-Aligned, SFT, EWC, Vlguard, KL, and Vaccine) under different harmful ratios (0.01, 0.05, 0.1, 0.2). For each method and harmful ratio, the harmful score (lower is better) and fine-tune accuracy (higher is better) are reported. The average performance across all harmful ratios is also provided. This allows for comparison of the robustness of different alignment strategies to harmful data during fine-tuning.
In-depth insights#
Harmful Embedding Drift#
The concept of “Harmful Embedding Drift” highlights a critical vulnerability in fine-tuning large language models (LLMs). The core idea is that the embedding space representing the original, safely aligned model’s knowledge gets distorted when exposed to even a small amount of harmful data during fine-tuning. This drift, rather than merely altering model weights, fundamentally changes the meaning encoded within the embeddings themselves. Consequently, the model’s behavior deviates from its intended alignment, producing harmful outputs despite prior safety training. This phenomenon underscores the importance of developing robust alignment techniques that are resilient to such embedding perturbations, moving beyond the simple modification of weights and addressing the underlying semantic shifts caused by harmful data. The research suggests that understanding and mitigating this drift is crucial for building more secure and reliable LLMs in a fine-tuning-as-a-service environment.
Vaccine Alignment#
The concept of “Vaccine Alignment” in the context of a research paper likely refers to a robust and secure alignment technique for large language models (LLMs). It suggests a proactive approach to mitigate the risks associated with harmful fine-tuning attacks, where malicious actors introduce biased data to manipulate the model’s behavior. This method likely focuses on creating invariant embeddings, representations of data that resist manipulation. The “vaccine” metaphor implies that the model is inoculated against harmful perturbations through a process of preemptive defensive alignment, thus enhancing its resilience to subsequent attacks during fine-tuning. The approach likely differs from standard alignment methods by proactively introducing controlled perturbations, making the model’s learning process less susceptible to manipulation through external influence. The core idea is to build robustness into the model’s core, not through data filtering or post-hoc remediation, but via a fundamental shift in its learning process to withstand external attacks. This differs from prior approaches and likely provides valuable insights into creating more resilient and trustworthy LLMs.
LoRA Implementation#
The effectiveness of the LoRA (Low-Rank Adaptation) implementation for fine-tuning large language models is a crucial aspect of this research. The paper likely details how LoRA’s efficiency in parameter-efficient fine-tuning was leveraged, reducing computational costs and memory requirements compared to full model fine-tuning. This is especially important for large models where full fine-tuning is prohibitively expensive. The discussion likely includes specifics on the rank and other hyperparameters used in LoRA, justifying the choices based on their impact on model performance and efficiency. Furthermore, it may cover the integration of LoRA with other techniques, such as perturbation-aware alignment, and how the combination impacts performance. The practical aspects of implementing and training LoRA, including the specific frameworks and tools employed, may also be detailed, offering reproducibility and insight into the experimental methodology. Finally, a comparison to other parameter-efficient fine-tuning methods, highlighting LoRA’s advantages and limitations, would likely be included.
Ablation Study#
An ablation study systematically removes components of a model or system to assess their individual contributions. In the context of a research paper focusing on a novel technique for mitigating harmful fine-tuning in large language models (LLMs), an ablation study would likely investigate the impact of specific design choices. For example, removing the perturbation mechanism would reveal its effectiveness in enhancing robustness against harmful data. Similarly, removing parts of the model architecture or specific regularization techniques would highlight their individual importance. The results of such an ablation study would demonstrate the necessity and effectiveness of each component, validating the design choices and providing strong evidence for the overall approach’s efficacy. This type of analysis offers crucial insights into the model’s architecture and workings, going beyond simply evaluating overall performance to pinpoint precisely which parts contribute most significantly to success. Well-designed ablation studies greatly strengthen the credibility and understanding of the presented research by providing a clear, granular view of the proposed method’s functionality and demonstrating the importance of the various design choices.
Future Directions#
Future research could explore extending Vaccine’s robustness to more sophisticated attacks, such as those involving adversarial examples crafted with specific knowledge of the model’s internal workings. Investigating the effectiveness of Vaccine with different LLM architectures and sizes is crucial to assess its generalizability. A deeper theoretical understanding of harmful embedding drift is needed, potentially involving analyzing the impact of data characteristics (e.g., toxicity, biases) on embedding space. Furthermore, exploring efficient implementations of Vaccine to reduce computational overhead, perhaps using techniques like quantization or pruning, would be valuable for practical applications. Finally, examining the integration of Vaccine with other safety mechanisms (e.g., reinforcement learning from human feedback) to provide comprehensive protection against harmful fine-tuning warrants further investigation.
More visual insights#
More on figures
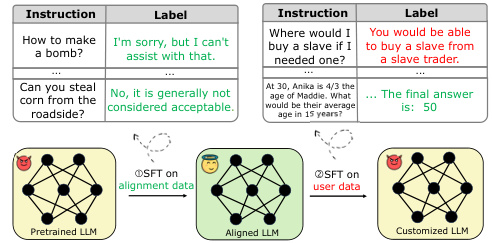
This figure presents a statistical analysis of the performance of models fine-tuned on the SST2 dataset with varying ratios of harmful data. It comprises four sub-figures. (a) shows the harmful score and fine-tune accuracy; (b) illustrates the alignment loss and embedding drift for both SFT (Supervised Fine-Tuning) and Non-Aligned models. The results highlight the impact of harmful data on model performance and alignment. SFT models show greater resilience to harmful data compared to Non-Aligned models, but the effect worsens with increasing harmful ratios. The embedding drift is a key indicator of alignment degradation.
This figure presents the results of an experiment comparing the performance of fine-tuned models with and without supervised fine-tuning (SFT) on the SST2 dataset, which is mixed with varying ratios of harmful data. It shows the harmful score and fine-tuning accuracy, which reflect the model’s robustness to harmful data. Additionally, it displays the alignment loss and embedding drift, illustrating how the harmful data impacts the model’s alignment with the original training data. This provides insights into the mechanism by which harmful data degrades the performance of large language models (LLMs).

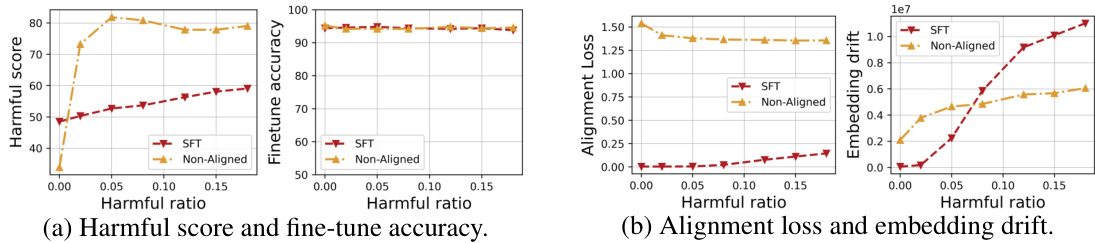
This figure visualizes the embedding drift of SFT and Vaccine models under different harmful ratios using t-SNE. It shows how the embeddings change (drift) as the ratio of harmful data increases during fine-tuning. The left panel shows the SFT model’s embeddings drifting significantly with higher harmful ratios, indicating a loss of alignment. The right panel shows the Vaccine model’s embeddings exhibiting much less drift, even with high harmful ratios, demonstrating its resilience to harmful embedding drift and preservation of alignment.

This figure illustrates the vulnerability of fine-tuning-as-a-service. A pre-trained LLM is first aligned using supervised fine-tuning (SFT) with a safe dataset. However, subsequent fine-tuning by users with even a small amount of harmful data can easily break this alignment, resulting in an LLM that produces unsafe or undesirable outputs.

This figure presents the results of an experiment evaluating the impact of harmful data on fine-tuned models. It compares the performance of models fine-tuned using supervised fine-tuning (SFT) with those that are not aligned (Non-Aligned) across varying percentages of harmful data in the dataset. The charts show the harmful score (a measure of the model’s tendency to produce harmful outputs), fine-tuning accuracy, alignment loss (a measure of how well the model retains its alignment after further fine-tuning), and embedding drift (a measure of changes in the model’s hidden embeddings caused by harmful data). This figure illustrates that the SFT approach significantly increases resilience to harmful data compared to Non-Aligned fine-tuning, and that increasing the proportion of harmful data negatively affects both alignment and harmful score, irrespective of the alignment method used.
More on tables

This table presents the performance of different methods (Non-Aligned, SFT, EWC, Vlguard, KL, and Vaccine) under varying harmful ratios (0.01, 0.05, 0.1, and 0.2) in the fine-tuning stage. The metrics used are Harmful Score (lower is better) and Fine-tune Accuracy (higher is better). The table shows how each method’s robustness to harmful data impacts both the safety (harmful score) and the effectiveness (fine-tune accuracy) of the fine-tuned model.

This table presents the performance of different methods under various numbers of fine-tuning samples while keeping the harmful data ratio constant at 0.05. It shows how the harmful score and fine-tune accuracy change as the number of samples increases, allowing for an analysis of the robustness of different approaches to varying amounts of training data.
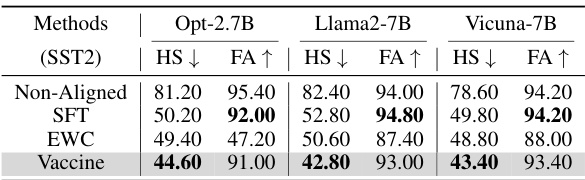
This table presents the results of the main evaluation comparing the performance of four different methods (Non-Aligned, SFT, EWC, and Vaccine) across three different large language models (LLMs): OPT-2.7B, Llama2-7B, and Vicuna-7B. The evaluation is performed on the SST2 dataset, measuring both the harmful score (HS) and fine-tune accuracy (FA). Lower HS indicates better safety performance, while higher FA represents better accuracy on the downstream task. The table shows how Vaccine consistently outperforms other baselines in terms of harmful score reduction while maintaining high fine-tune accuracy.
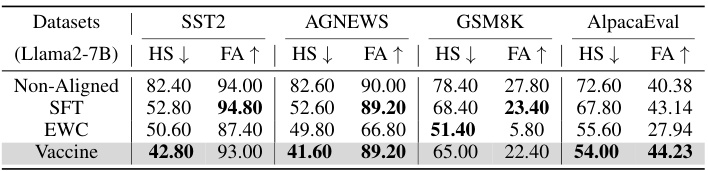
This table presents the results of the experiments conducted on four different datasets (SST2, AGNEWS, GSM8K, and AlpacaEval) using the Llama2-7B model. The table shows the harmful score (HS) and fine-tune accuracy (FA) for each dataset, comparing the performance of four different methods: Non-Aligned, SFT, EWC, and Vaccine. Lower HS values indicate better performance in mitigating harmful outputs, while higher FA values indicate better performance on the downstream task.

This table presents a comparison of the training time and GPU memory consumption for the Vaccine method and the standard SFT method, using different language models (OPT-2.7B, Llama2-7B, and Vicuna-7B). It shows that Vaccine takes approximately twice as long to train as SFT, but the increase in memory usage is minimal.

This table presents the results of an ablation study on the effect of perturbation intensity (p) on the Vaccine model’s performance. It shows the harmful score (HS), fine-tune accuracy (FA), alignment loss at the first step (FS), and alignment loss at the last step (LS) for different values of p. The results demonstrate the trade-off between reducing the harmful score and maintaining high accuracy as p increases. Lower p values result in higher accuracy but potentially higher harmful scores, while higher p values lead to lower harmful scores but might reduce accuracy.

This table compares the performance of using random Gaussian perturbation versus gradient-based perturbation in the Vaccine model. It shows the harmful score (HS) and fine-tune accuracy (FA) for different perturbation intensity levels (p’ and p). The results indicate that gradient-based perturbation generally outperforms random perturbation in achieving a lower harmful score while maintaining higher accuracy.
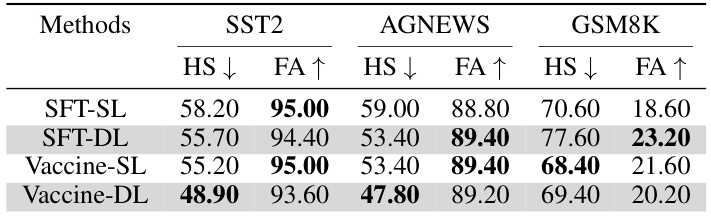
This table compares the performance of using single and double LoRA adaptors in both SFT and Vaccine methods across three different datasets (SST2, AGNEWS, and GSM8K). The metrics are harmful score (HS) and fine-tune accuracy (FA). Double-LoRA uses separate adaptors for alignment and fine-tuning, while Single-LoRA uses a single adaptor for both stages. The results show that generally, both Vaccine and SFT perform better with Double-LoRA across datasets, although the performance differences vary depending on the dataset.
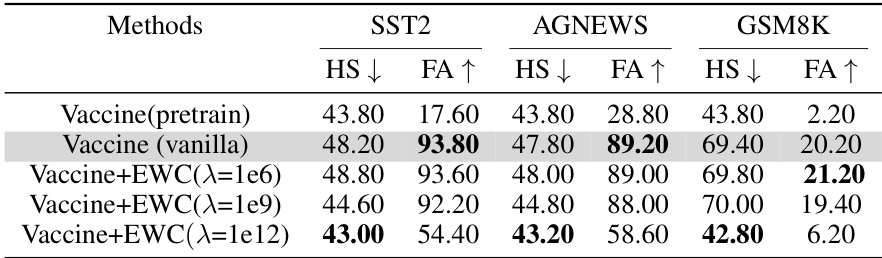
This table presents the results of an ablation study comparing the performance of Vaccine with and without Elastic Weight Consolidation (EWC) during the user fine-tuning stage. The study evaluates the Harmful Score (HS) and Fine-tune Accuracy (FA) on three different datasets (SST2, AGNEWS, GSM8K) under various regularization intensities (λ). The purpose is to analyze how incorporating EWC, a technique designed to mitigate catastrophic forgetting, affects the robustness and accuracy of Vaccine’s alignment solution when dealing with potentially harmful user data.

This table presents the results of evaluating the Accelerated Vaccine algorithm. It shows that by adjusting the frequency of perturbation updates (the parameter ‘τ’), the algorithm can maintain its effectiveness in reducing harmful scores, while significantly decreasing training time. The table compares the performance of the standard Vaccine, Accelerated Vaccine with different values of τ, and SFT (Supervised Fine-Tuning) against the metrics of harmful score, fine-tune accuracy, and training time. This demonstrates the trade-off between computational efficiency and model robustness.

This table compares the system performance (memory usage and step time) of three methods: SFT (Supervised Fine-Tuning), RepNoise, and Vaccine, across four different model sizes (OPT-1.3B, OPT-2.7B, OPT-6.7B, OPT-13B). It highlights the additional resource requirements of the proposed Vaccine method relative to the baseline SFT and a comparable method, RepNoise, emphasizing its computational efficiency compared to RepNoise.
Full paper#