↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual embodied instruction following, where AI agents execute multiple tasks based on real-time environmental information, is a major challenge in robotics. Current methods often struggle with efficiency and the dynamic nature of real-world settings. They frequently rely on repeated interactions to collect environmental knowledge, which is inefficient and can lead to outdated information.
The proposed ExRAP framework addresses these issues by integrating environment exploration into LLM-based planning. It employs memory to store environmental context and uses an information-based exploration strategy to efficiently gather new information. This approach leads to a better balance between exploration and exploitation, resulting in improved task success rates and execution efficiency. ExRAP consistently outperforms state-of-the-art methods in various simulated environments, demonstrating its robustness and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and effective framework for continual embodied instruction following, a crucial challenge in embodied AI. It significantly improves the efficiency and success rate of task completion by integrating environment exploration into the LLM-based planning process. This offers new avenues for research on more robust and adaptable AI agents capable of operating in dynamic, real-world settings. The findings will likely influence the development of more advanced embodied AI systems, impacting various fields such as robotics and autonomous driving.
Visual Insights#
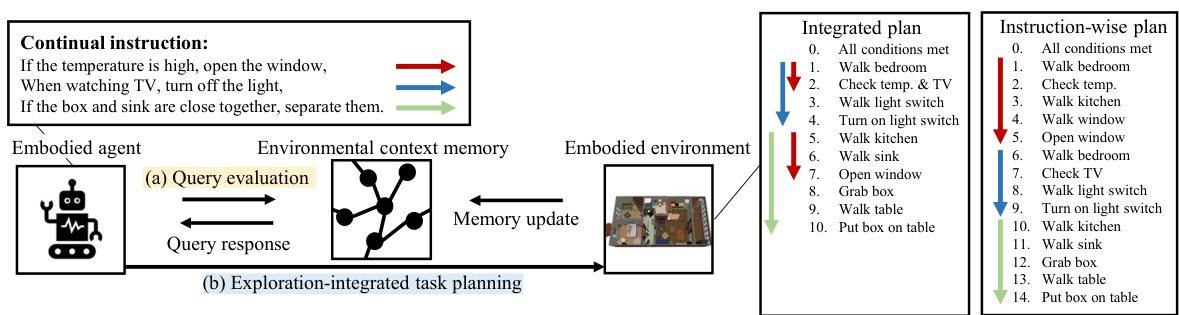
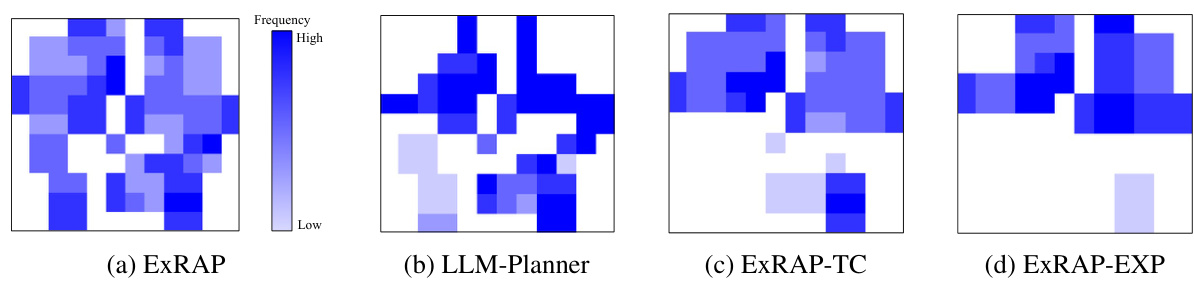
The figure illustrates the ExRAP framework for continual embodied instruction following. It contrasts an integrated planning approach with an instruction-wise approach. The integrated approach uses memory-augmented query evaluation and exploration-integrated task planning, resulting in more efficient task execution by considering multiple instructions simultaneously and leveraging an environmental context memory. The instruction-wise approach processes instructions one by one, leading to less efficient task completion.
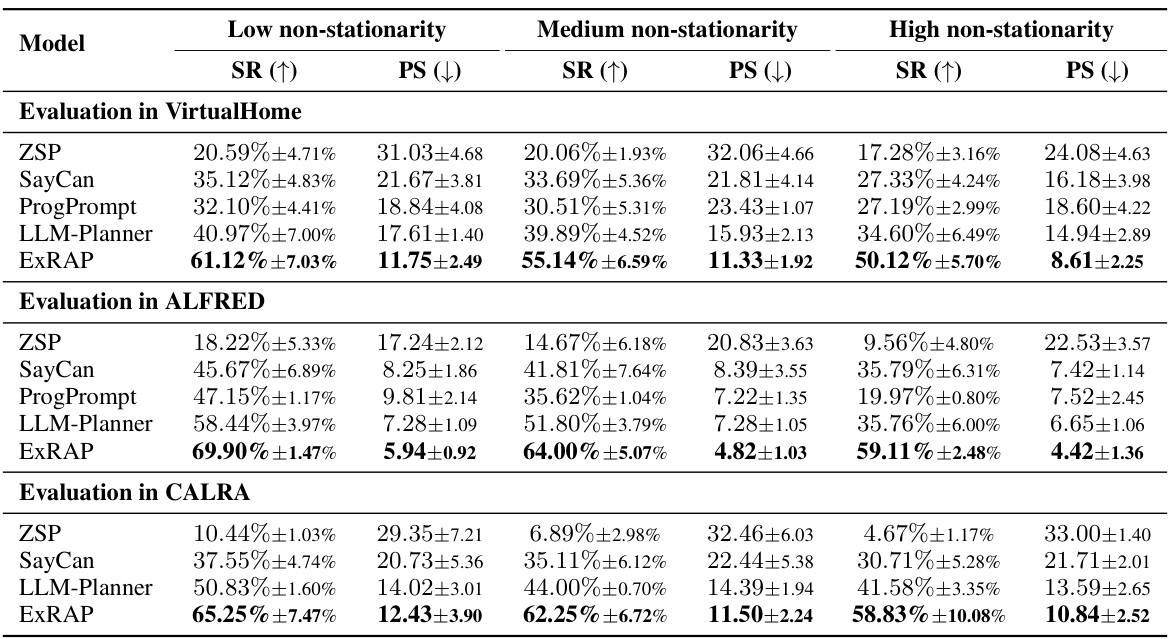
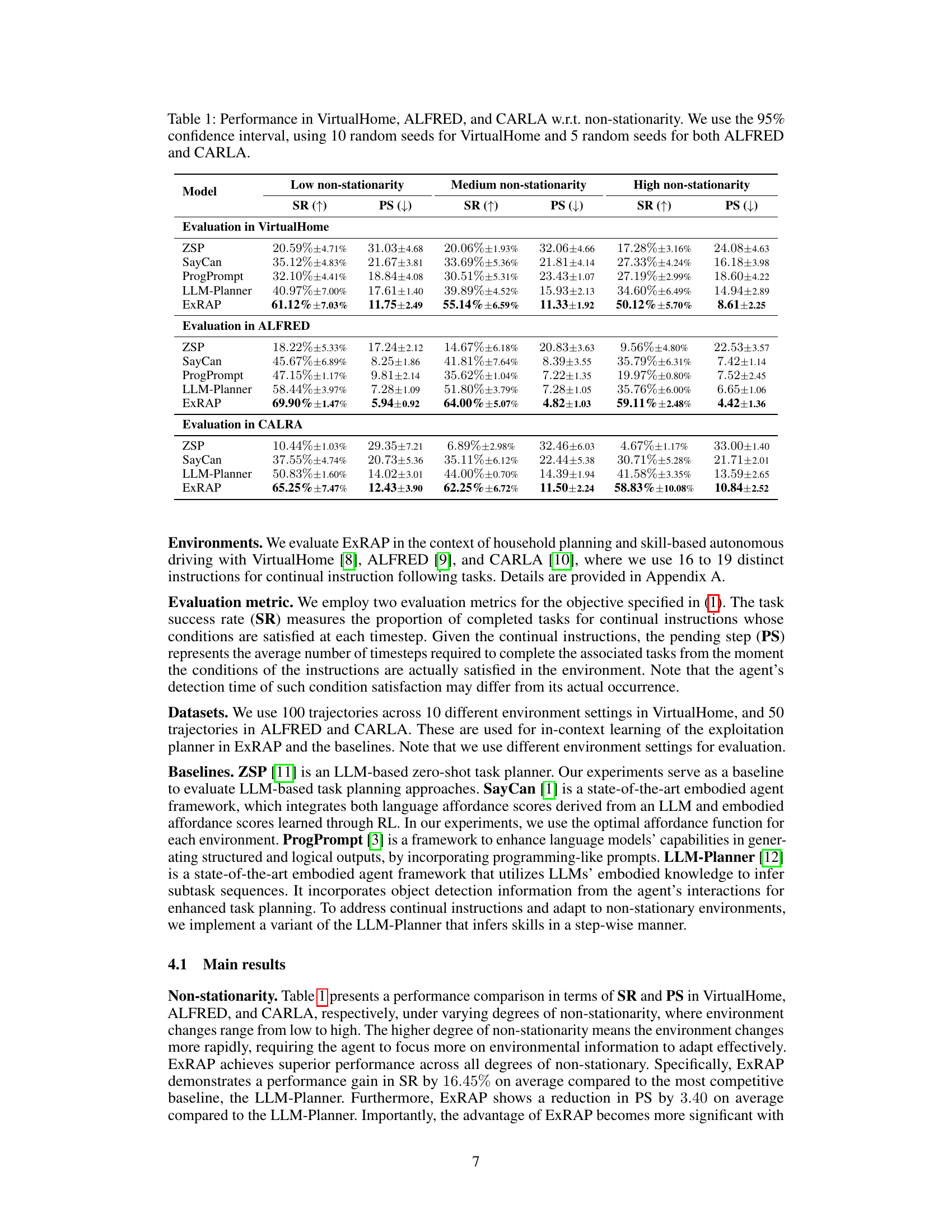
This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity (low, medium, high). The performance is measured using two metrics: Task Success Rate (SR) and average Pending Steps (PS). Higher SR indicates better performance, while lower PS means higher efficiency. The confidence intervals are calculated using multiple random seeds to provide a measure of statistical significance.
In-depth insights#
ExRAP Framework#
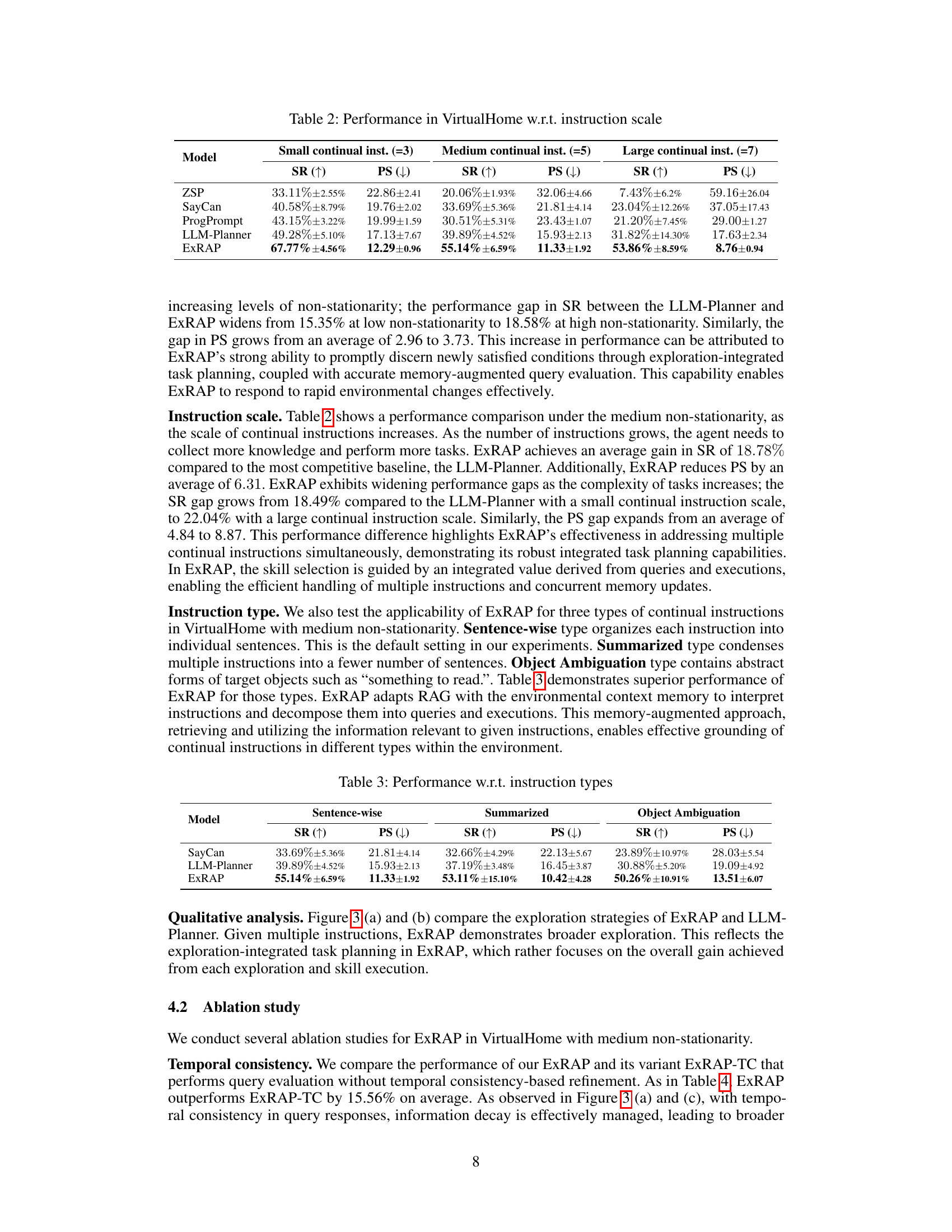
The ExRAP framework presents a novel approach to continual embodied instruction following, enhancing LLMs’ capabilities by integrating environmental context memory and information-based exploration. Its core innovation lies in the exploration-integrated task planning scheme, which intelligently balances memory updates with environmental exploration. This is crucial for efficiency in dynamic, non-stationary environments where continuous adaptation is key. Memory-augmented query evaluation ensures robust condition checking, while temporal consistency refinement mitigates knowledge decay. The framework’s effectiveness is demonstrated across diverse scenarios in VirtualHome, ALFRED, and CARLA, outperforming existing methods in both goal success and efficiency. Robustness against variations in instruction scale, type, and non-stationarity further highlights its practical potential.
Continual Planning#
Continual planning addresses the challenge of adapting decision-making processes to dynamic, evolving environments. Unlike traditional planning which assumes a static world, continual planning requires mechanisms for handling unexpected events, integrating new information, and adjusting plans in real-time. This necessitates efficient methods for monitoring the environment, detecting changes, and triggering plan updates. Key considerations include managing computational costs associated with frequent replanning and balancing exploration and exploitation, ensuring the agent effectively learns about the environment while completing tasks. Successful continual planners need robust mechanisms for maintaining and updating internal models of the world, handling uncertainty, and dealing with potential inconsistencies between model and reality. Robustness to both unforeseen circumstances and incomplete information is critical. A central theme is the intelligent selection of actions that maximize both efficiency and informational value simultaneously. Efficient exploration strategies are paramount to continual planning, providing the information necessary for informed decision-making.
Info-Based Exploration#
Info-based exploration in reinforcement learning (RL) aims to maximize the information gained from each action, thus efficiently exploring the environment and improving learning. Unlike random exploration, it prioritizes actions that yield the most informative outcomes, reducing the time and resources needed to build an accurate model of the environment. Uncertainty reduction is a key driver; actions that resolve uncertainty about the environment are favored. This approach is particularly useful in complex environments where exploration is costly or dangerous. Mutual information is often used as a metric to quantify the information gain, measuring the reduction in uncertainty about the environment’s state after taking an action. In the context of embodied AI, such methods are crucial for agents to efficiently discover and utilize relevant knowledge within their environment, leading to faster learning and better task performance.
Temporal Consistency#
Temporal consistency, in the context of embodied AI and continual instruction following, addresses the challenge of maintaining accurate and up-to-date environmental context memory. Information decay is a major concern; as the agent interacts with the environment, older information might become outdated or irrelevant. To mitigate this, temporal consistency mechanisms aim to refine the memory by detecting and resolving contradictions between newly acquired observations and existing knowledge. This often involves comparing the confidence levels assigned to queries based on the memory against current environmental conditions. Entropy-based methods can be particularly useful, as they directly quantify uncertainty or information decay in the memory, allowing the system to prioritize exploration or data collection strategies that maximize information gain and reduce uncertainty, thereby improving the accuracy and reliability of the query results and overall task completion.
Future of ExRAP#
The future of ExRAP hinges on addressing its current limitations and expanding its capabilities. Improving the efficiency of environmental exploration is crucial; perhaps integrating more sophisticated exploration strategies like active learning or curiosity-driven methods could reduce reliance on exhaustive exploration. Enhancing the robustness of the LLM-based query evaluator is vital, potentially through techniques like uncertainty quantification or incorporating more advanced reasoning mechanisms. Expanding the types of tasks ExRAP can handle beyond those in the current experimental setup will demonstrate its generalizability. This could involve complex multi-step tasks or tasks requiring intricate reasoning about the physical environment. Lastly, exploring the potential of ExRAP for real-world applications is essential, which will involve testing the system in real-world settings and addressing challenges like noisy sensor data and unpredictable environments. Addressing the computational cost associated with large language models, and improving the memory efficiency, will further enhance scalability and real-world practicality.
More visual insights#
More on figures

This figure illustrates the overall architecture of the ExRAP framework, showing the two main components: (a) Query evaluation and (b) Exploration-integrated task planning. The query evaluation process uses a memory-augmented query evaluator to assess the likelihood of queries based on the environmental context memory (TEKG). The exploration-integrated task planning involves two planners: an exploitation planner that focuses on completing tasks and an exploration planner that prioritizes updating the environmental context memory by maximizing information gain. The system selects the next skill based on a combination of the exploitation and exploration values.
This figure illustrates the two main components of the ExRAP framework: query evaluation and exploration-integrated task planning. The query evaluation process uses a memory-augmented query evaluator to assess the likelihood of queries based on the environmental context memory. The exploration-integrated task planning process involves two planners: an exploitation planner that focuses on task completion and an exploration planner that prioritizes information gain to improve the accuracy of future query evaluations. The final plan is a combination of both plans.

This figure illustrates the ExRAP framework, comparing its continual instruction following approach with a traditional instruction-wise method. ExRAP uses an integrated planning scheme that incorporates memory-augmented query evaluation and exploration-integrated task planning. The left side shows the ExRAP’s efficient task execution by integrating environmental context memory updates in both query evaluation and task planning; in contrast, the right side depicts the less-efficient instruction-wise approach.

This figure illustrates the two main components of the ExRAP framework: query evaluation and exploration-integrated task planning. The query evaluation process uses a temporal embodied knowledge graph (TEKG) to assess the likelihood of query conditions being met, factoring in potential information decay. Exploration-integrated task planning combines an exploitation planner (using LLMs and demonstrations) with an exploration planner (using information gain) to select the best action at each step, balancing task completion and environmental understanding.
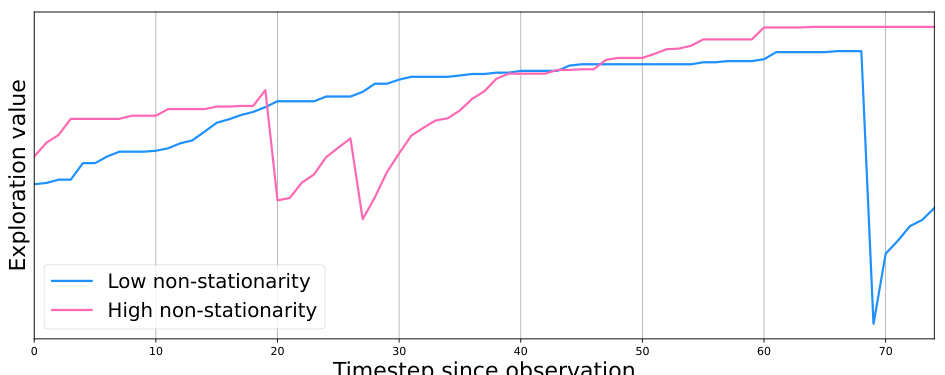
This figure shows the exploration value over time for two different levels of non-stationarity: low and high. The exploration value generally increases over time, indicating that the agent is actively learning and discovering new information about its environment. However, the exploration value also drops sharply at certain points in time, especially in the high non-stationarity case. This suggests that as the agent learns, it quickly becomes confident about certain aspects of its environment and therefore reduces its exploration. The higher non-stationarity condition leads to a more dramatic increase and decrease in exploration value, suggesting that the agent needs to explore more frequently in a rapidly changing environment.
More on tables
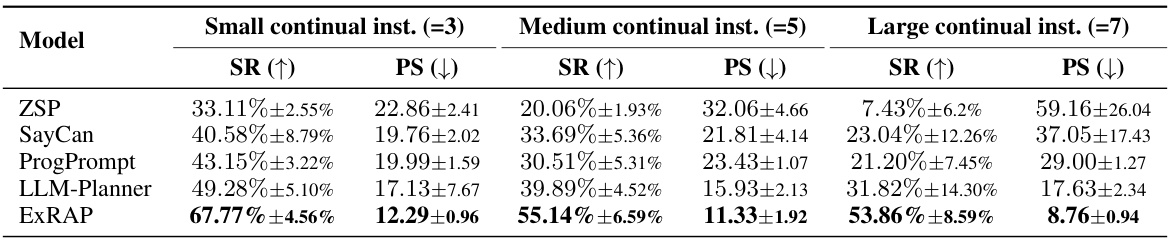
This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) on three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Steps (PS). Higher SR values and lower PS values indicate better performance. The table shows that ExRAP outperforms other state-of-the-art methods across all environments and non-stationarity levels.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) on three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Steps (PS). Higher SR indicates better performance, while lower PS indicates greater efficiency. The results show that ExRAP consistently outperforms the other methods across all environments and non-stationarity levels.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The performance is measured by two metrics: Success Rate (SR), indicating the percentage of successfully completed tasks, and Pending Step (PS), representing the average number of steps taken to complete a task. Higher SR values and lower PS values indicate better performance. The table shows that ExRAP consistently outperforms other methods across all environments and non-stationarity levels.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Step (PS). Higher SR indicates better performance, while lower PS also indicates better performance. The confidence intervals are based on multiple random seeds to show the statistical significance of the results.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Steps (PS). Higher SR indicates better performance, while lower PS indicates higher efficiency. The results show that ExRAP consistently outperforms other state-of-the-art methods across different environments and levels of non-stationarity.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) with varying degrees of non-stationarity (low, medium, and high). The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Steps (PS). The confidence intervals (95%) are based on multiple random seeds for each environment and model.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity (low, medium, and high). The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Step (PS). Higher SR indicates better performance, while lower PS indicates higher efficiency. The confidence intervals (95%) are calculated using multiple random seeds for each environment and non-stationarity level.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) with varying degrees of non-stationarity. The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Step (PS). Higher SR values indicate better performance, while lower PS values indicate greater efficiency. The confidence intervals are calculated using 10 random seeds for VirtualHome and 5 random seeds for ALFRED and CARLA. The table shows that ExRAP consistently outperforms other models in terms of both SR and PS, especially in high non-stationarity scenarios.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different simulated environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The results show the success rate (SR) and the average pending steps (PS) for each model in each environment and level of non-stationarity. Higher SR indicates better performance, while lower PS indicates greater efficiency.
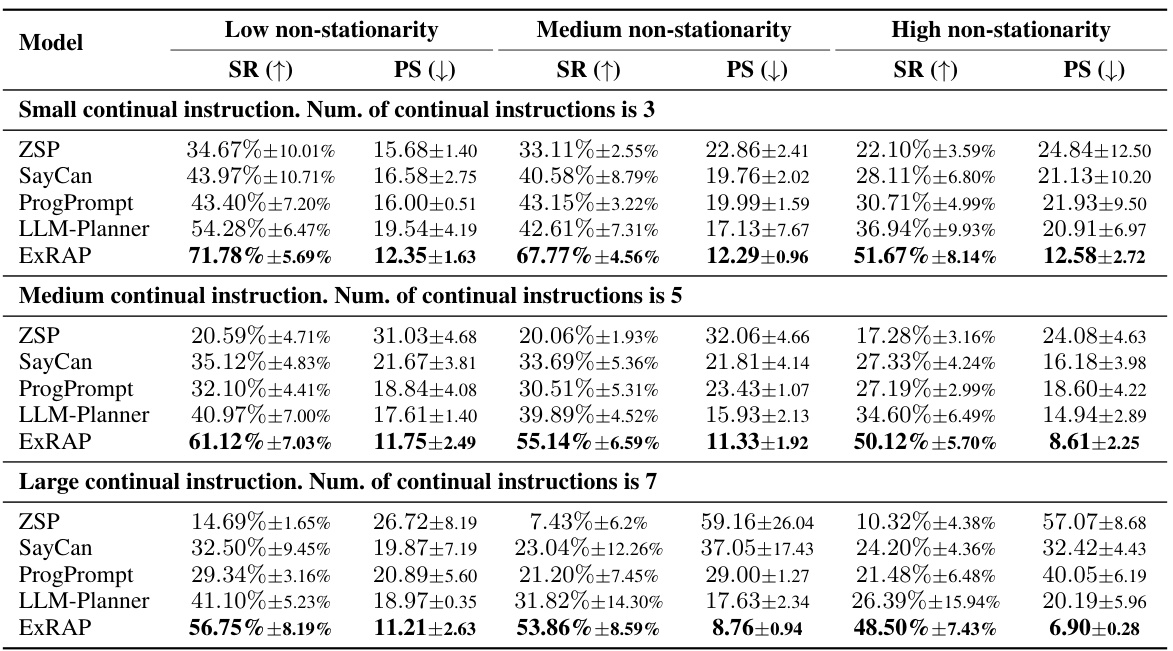
This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Steps (PS). Higher SR indicates better performance, while lower PS indicates higher efficiency. The results are reported as the average ± 95% confidence interval, using 10 random seeds for VirtualHome and 5 random seeds for both ALFRED and CARLA. Non-stationarity refers to how frequently the environment changes.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity (low, medium, and high). The performance is measured using two metrics: task success rate (SR) and average pending steps (PS). Higher SR values and lower PS values indicate better performance. The confidence interval (95%) is calculated using multiple random seeds for each environment and model.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) on three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The results are shown in terms of task success rate (SR) and average pending steps (PS). The confidence interval is 95%, with 10 random seeds used for VirtualHome and 5 for ALFRED and CARLA. Higher SR values and lower PS values indicate better performance.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) and three levels of environmental non-stationarity (low, medium, and high). The performance is measured using two metrics: task success rate (SR) and average pending steps (PS). Higher SR indicates better performance, and lower PS indicates higher efficiency. The confidence intervals are calculated using 10 random seeds for VirtualHome and 5 for ALFRED and CARLA.

This table presents the performance of ExRAP and other state-of-the-art methods across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The results show the success rate (SR) and average pending steps (PS) for each model. Higher SR indicates better performance, while lower PS indicates greater efficiency. Non-stationarity refers to the degree of change in the environment over time.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) under varying degrees of non-stationarity. The performance is measured using two metrics: Task Success Rate (SR) and Average Pending Steps (PS). Higher SR values are better, while lower PS values are better. The table shows that ExRAP consistently outperforms other models across all environments and non-stationarity levels.

This table presents the performance of different models (ZSP, SayCan, ProgPrompt, LLM-Planner, and ExRAP) across three different environments (VirtualHome, ALFRED, and CARLA) with varying degrees of non-stationarity. The performance is measured using two metrics: Success Rate (SR) and Pending Steps (PS). Higher SR indicates better performance, while lower PS indicates higher efficiency. The confidence intervals (95%) are calculated using multiple random seeds for each environment and model.
Full paper#