↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) suffer from order dependency—their outputs change when input order changes despite semantic equivalence. This inconsistency undermines reliability, especially in applications like multiple-choice questions or analyzing multiple inputs where order shouldn’t matter. This significantly impacts the trustworthiness of LLMs in critical decision-making scenarios.
This paper introduces Set-Based Prompting, a method to eliminate this order dependency. By modifying the input representation, it ensures that the LLM’s output remains consistent regardless of input order, without requiring any model retraining. Experiments show that this method has minimal impact on accuracy while effectively solving the order-dependency problem. This offers a practical solution to improve LLM reliability and fairness across various applications and is a valuable contribution to the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) because it addresses the critical issue of order dependency, impacting model reliability and fairness. The proposed Set-Based Prompting method offers a practical solution, enhancing the trustworthiness of LLM outputs across various applications. This work also opens up new avenues for research into modifying input representations to improve LLM performance and provides strong guarantees about LLM behavior, potentially leading to more robust and reliable LLMs in the future.
Visual Insights#

This figure demonstrates the impact of input order on the performance of Llama 2 7B Language Model. Panel (a) shows a correct prediction when the order of the options is the same as in the MMLU dataset. Panel (b) shows an incorrect prediction when the options are reversed. Panel (c) shows that Set-Based Prompting, a technique introduced in the paper, removes the order dependency, resulting in a correct answer regardless of the options order. This illustrates the core problem the paper aims to solve and the proposed solution’s effectiveness.

This table lists the language models used in the experiments, categorized by their origin (OpenAI, Meta, Mistral) and whether they are fine-tuned versions of base models. It shows the number of parameters in billions (B) for each model. The information is crucial for understanding the scope of the experiments and allows readers to assess the diversity and scale of the models tested.
In-depth insights#
Order-Free Prompting#
The concept of “Order-Free Prompting” in the context of large language models (LLMs) addresses the critical issue of order dependency, where the LLM’s output changes significantly depending on the sequence of input prompts, even if the semantic meaning remains the same. This is a major limitation for many applications demanding consistent responses. Order-free prompting aims to solve this issue by introducing techniques that make the LLM’s response independent of the input order. This might involve modifying the input representation to remove explicit ordering information or using specialized prompt engineering techniques to make the order irrelevant. The implications are significant: it could improve the reliability and consistency of LLMs, enhance fairness and reduce bias stemming from order-dependent behavior, and ultimately increase the trust and usability of LLMs in applications where consistent responses are crucial. However, achieving complete order independence might come with trade-offs, such as potential impact on the LLM’s overall accuracy or the efficiency of the prompting method itself. Further research is needed to explore optimal strategies and fully understand the trade-offs of various order-free prompting techniques.
Attention Mechanism#
The attention mechanism is a crucial component of transformer-based large language models (LLMs), enabling them to process sequential data more effectively. Its core function is to weigh the importance of different parts of the input sequence when generating an output. Instead of treating all input tokens equally, the attention mechanism assigns weights that reflect their relevance to the current token being processed. This weighting is determined through a learned process, allowing the model to focus on the most pertinent information and ignore less relevant parts. The attention mechanism’s ability to selectively focus on specific parts of the input is what makes LLMs capable of handling long sequences and complex relationships within the data. Different variations of the attention mechanism exist, such as self-attention, where the model attends to other parts of its own input, and cross-attention, where it attends to a separate input sequence. Understanding the inner workings of the attention mechanism is essential for improving LLM performance and addressing issues such as order dependence and the inability to process out-of-distribution inputs. Further research into the attention mechanism could unlock significant advancements in natural language processing and other areas that involve sequential data processing.
Empirical Evaluations#
A robust empirical evaluation section for this research paper would require a multifaceted approach. It should begin by clearly stating the goals of the evaluation: to demonstrate the effectiveness of Set-Based Prompting in mitigating order dependency in LLMs, and to assess the impact on model accuracy. The section would need to meticulously detail the experimental setup, including the specific LLMs used (versions, parameters), datasets selected (with justification for their relevance), and evaluation metrics (e.g., accuracy, F1-score, BLEU). A crucial aspect would involve a comparison of the proposed method against appropriate baselines (e.g., standard prompting with different orderings, other existing order-mitigation techniques). Detailed analysis of the results, including statistical significance testing, should be provided to support any claims of improvements. It is vital to discuss any unexpected findings or limitations, exploring potential reasons for any performance variations. Finally, the analysis should offer insights into the broader implications of these findings, possibly speculating on future directions for research in LLM prompt engineering and bias reduction.
Limitations & Future#
The research, while groundbreaking in demonstrating order-independence in LLMs without fine-tuning, presents some limitations. Set-Based Prompting’s impact on accuracy, while often minimal, shows variability across different models and datasets. This suggests potential challenges in applying the method universally without careful consideration of model architecture and task specificity. Future work could address this variability by exploring fine-tuning strategies to optimize Set-Based Prompting’s performance across the board. Furthermore, investigation into the interaction between Set-Based Prompting and other techniques, such as chain-of-thought prompting or instruction tuning, is crucial. Research should also explore extending the methodology to handle more complex input structures beyond simple parallel sub-sequences, such as nested or graph-based relationships between inputs. Understanding the effect on the model’s attention mechanism and the potential out-of-distribution effects is another vital research area. Ultimately, exploring how Set-Based Prompting can contribute to improving other aspects of LLM behavior, such as mitigating biases or enhancing robustness, presents fertile ground for future research.
LLM Order Issue#
The LLM order issue highlights the significant sensitivity of large language models (LLMs) to the order of input elements. Unlike humans, who can often grasp the meaning regardless of word order, LLMs exhibit order dependency, producing vastly different outputs when the sequence of inputs is altered. This inconsistency is problematic for tasks requiring analysis of multiple inputs or answers, such as multiple-choice questions. The impact extends beyond simple variations in phrasing; it affects the accuracy and reliability of LLM responses, potentially leading to biased or unfair outcomes in applications where input order is not semantically significant. Addressing this issue is crucial for enhancing the robustness and dependability of LLMs, making them more suitable for real-world applications requiring reliable and consistent performance across various input arrangements.
More visual insights#
More on figures

This figure displays the performance comparison of different LLMs on two datasets (CSQA and MMLU) with and without the proposed Set-Based Prompting technique. It highlights the impact of input order on model accuracy, showcasing that Set-Based Prompting mitigates order dependency, leading to more consistent results across different input orderings.
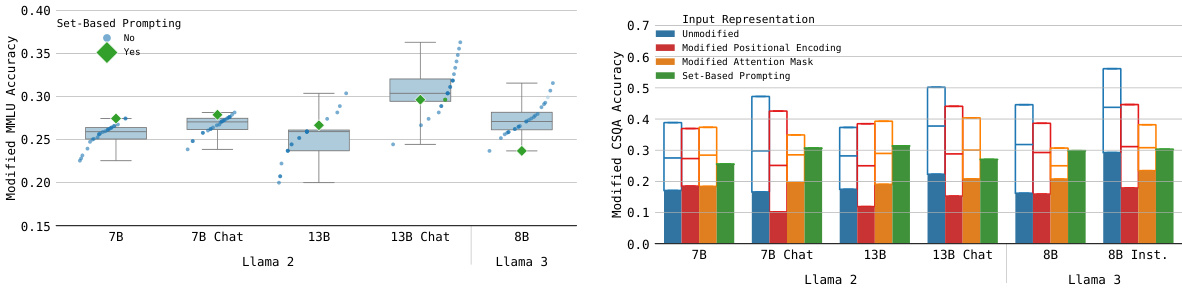
This figure shows the accuracy of different language models on two benchmark datasets (modified CSQA and modified MMLU) with and without using the proposed Set-Based Prompting method. The blue bars represent the accuracy obtained using the original question order and its reverse, illustrating order dependency. The green bars show accuracy with Set-Based Prompting applied, demonstrating order independence. The results indicate that Set-Based Prompting maintains reasonable accuracy while eliminating order dependency.
This figure shows the performance comparison of different LLMs on two datasets (Modified CSQA and Modified MMLU) with and without Set-Based Prompting. The blue bars represent the accuracy when the input order is either normal or reversed, while the green bar represents the accuracy using Set-Based Prompting, which is order-invariant. The different shades of blue show the best and worst results obtained from normal and reversed ordering scenarios. The results demonstrate the effect of Set-Based Prompting in reducing order dependence and achieving consistent performance across different input orders.
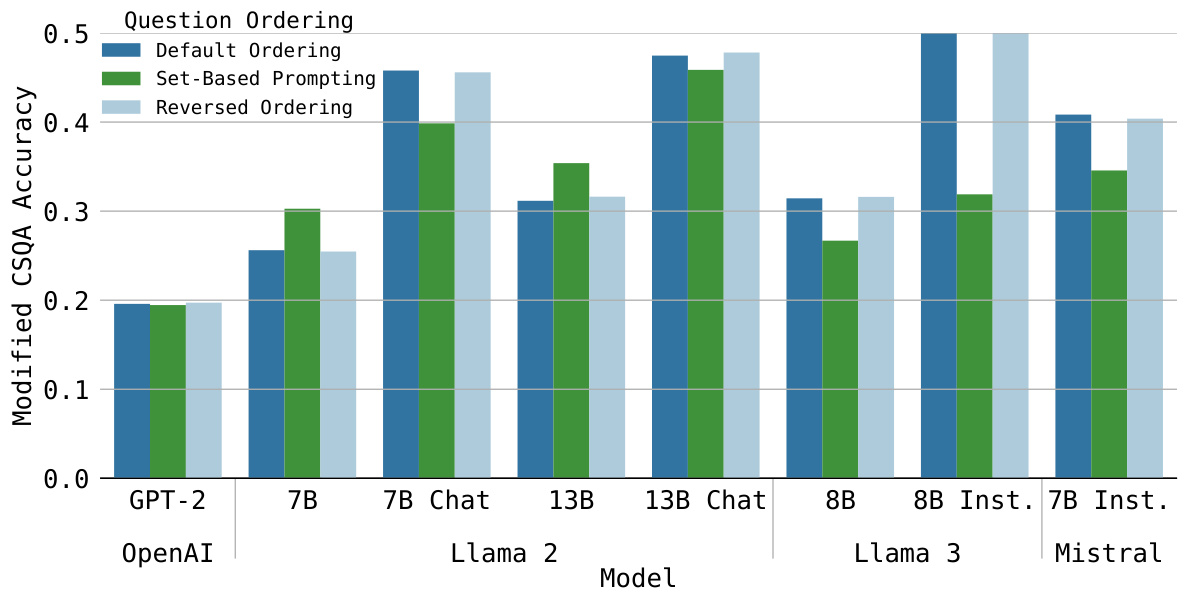
This figure shows the accuracy of different language models on two benchmark datasets (modified CSQA and modified MMLU) with and without Set-Based Prompting. The blue bars represent the accuracy using the default and reversed orderings of the options. The green bar represents the accuracy using Set-Based Prompting, which is order-invariant. The different shades of blue bars show the best and worst case scenarios for the default ordering.

This figure compares the accuracy of different LLMs on two datasets (Modified CSQA and Modified MMLU) with and without using Set-Based Prompting. For the models without Set-Based Prompting, two accuracy values are shown which represent the performance with default and reversed ordering of the input data. In contrast, the models with Set-Based Prompting show only one accuracy value because the technique makes the model order-independent. The figure helps visualize the impact of Set-Based Prompting on mitigating order dependency and its effect on overall model accuracy.

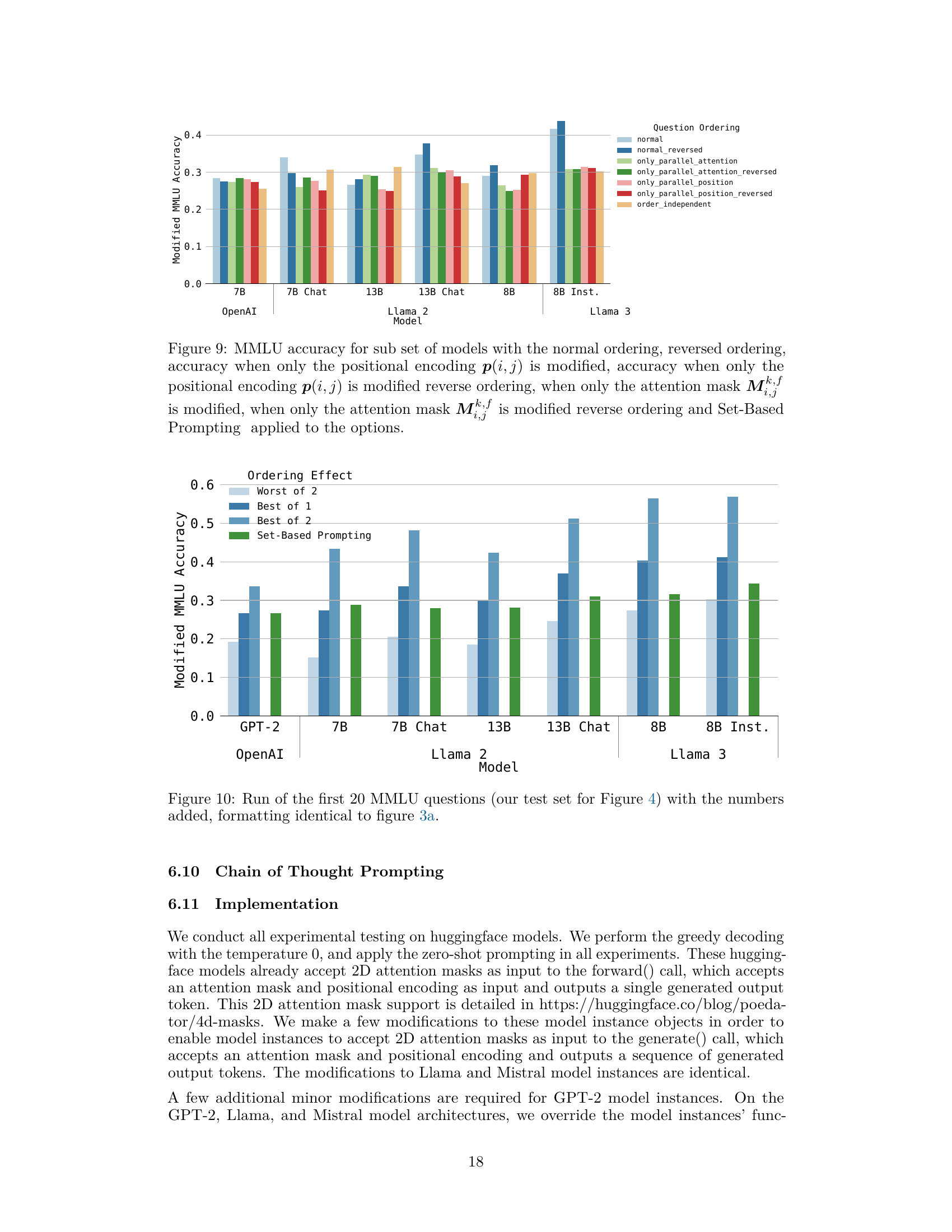
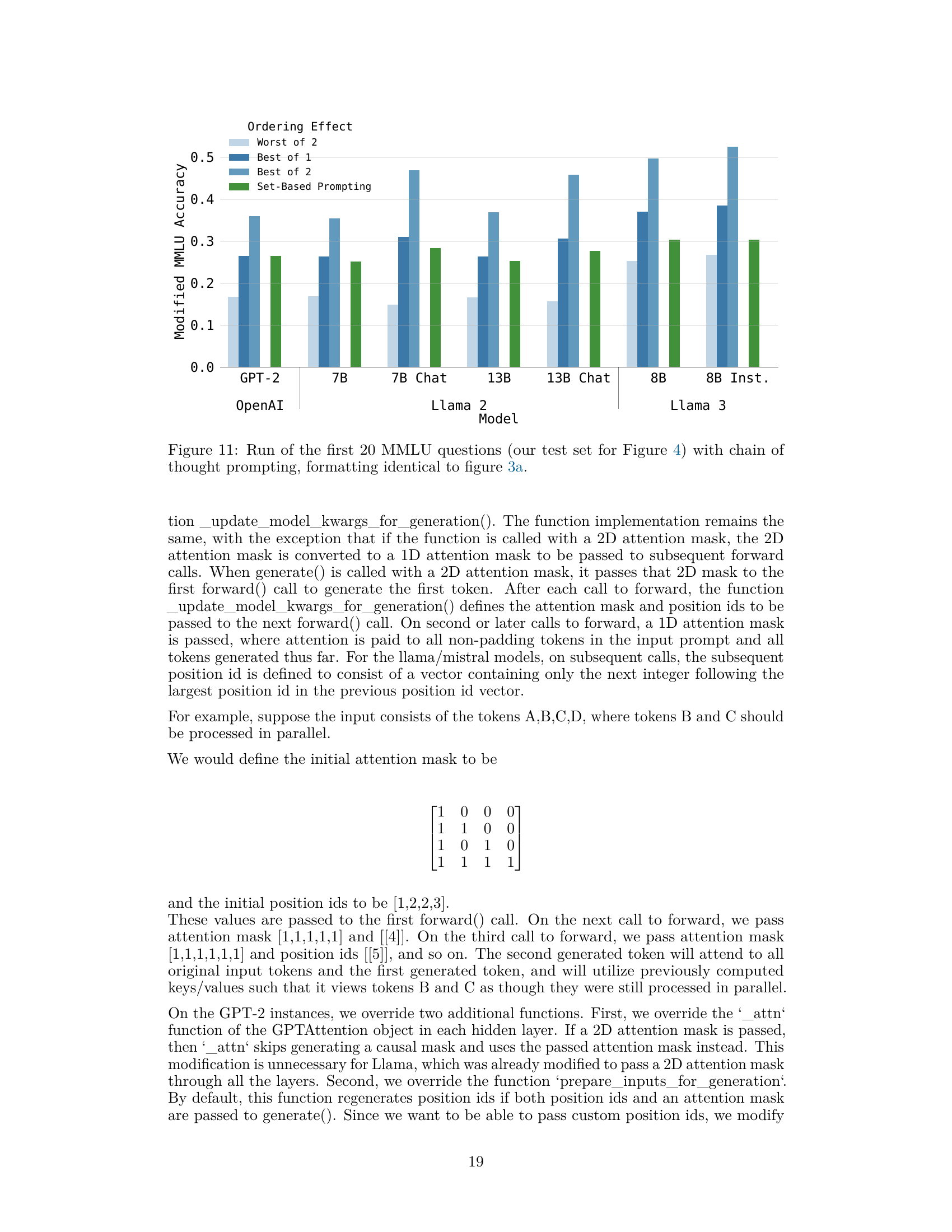
This figure shows the modified MMLU accuracy for a subset of models under various conditions. It compares the accuracy with normal and reversed question orderings, and when only the positional encoding or attention mask is modified. Finally, it displays the accuracy when using Set-Based Prompting. The purpose is to illustrate the impact of different modifications on the order dependency problem and how Set-Based Prompting improves accuracy.

This figure shows the accuracy results on two datasets (Modified CSQA and Modified MMLU) for several large language models (LLMs). Blue bars represent the performance without Set-Based Prompting, showing the variation between normal and reversed ordering (Worst of 2, Best of 2, and Best of 1). The green bar shows the accuracy achieved with Set-Based Prompting, demonstrating its consistency across different orderings.

The figure shows the accuracy of different language models on two benchmark datasets (CSQA and MMLU) with and without the proposed Set-Based Prompting technique. The blue bars represent the accuracy with normal and reversed orderings of the options. The green bars show the accuracy with Set-Based Prompting, which is order-invariant. The results demonstrate the effectiveness of Set-Based Prompting in mitigating order dependency in LLMs.
Full paper#