↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Decoding brain activity from stereotactic electroencephalography (sEEG) is challenging due to the variability in electrode placement across subjects. Existing methods mostly rely on single-subject models, limiting the ability to scale up datasets and improve model generalization. This severely hinders the development of robust and accurate brain-computer interfaces for clinical applications.
The researchers address this challenge by proposing “seegnificant,” a novel framework based on transformer networks. This approach uses convolutions to tokenize neural activity within individual electrodes, self-attention to capture long-term temporal dependencies, and integrates 3D electrode locations into the model to obtain robust neural representations. The model demonstrates high decoding accuracy on a large multi-subject dataset and exhibits successful few-shot transfer learning to new subjects, paving the way for broader applications in clinical settings.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel, scalable approach for multi-subject sEEG data integration, a significant hurdle in advancing sEEG-based neural decoding for human brain recordings. It opens avenues for creating more powerful and generalizable models for brain-computer interface applications and clinical diagnostics, addressing the limitations of current single-subject models. The research directly tackles the heterogeneity inherent in sEEG data, a major obstacle in improving the medical relevance of sEEG analysis.
Visual Insights#

This figure illustrates the architecture of the Seegnificant model. The model takes sEEG data as input. First, a temporal convolutional neural network (CNN) processes the time series data from each electrode independently to create temporal tokens, representing short segments of neural activity. These tokens are then processed through a self-attention mechanism in the time dimension to capture long-range temporal dependencies. Next, spatial information (3D coordinates) is added to the temporal tokens using positional encoding. These spatially enriched tokens are then further processed using a self-attention mechanism in the electrode dimension to capture spatial relationships between electrodes. Finally, the resulting neural representations are fed into subject-specific regression heads (MLP layers) to predict the behavioral outcome (reaction time in this case).

This table shows the per-subject R-squared values and training times for two different models: ‘Variant’ and ‘Ours’. The ‘Variant’ model represents an alternative architecture with a single 2D attention mechanism, while ‘Ours’ refers to the proposed model in the paper with separate attention mechanisms in time and electrode dimensions. The results highlight that the proposed model (‘Ours’) achieves better decoding performance with significantly reduced training time compared to the ‘Variant’ model.
In-depth insights#
sEEG Decoding#
Stereotactic electroencephalography (sEEG) decoding presents unique challenges and opportunities in neural decoding. sEEG’s high spatial resolution allows for precise localization of neural activity, but the variability in electrode placement across subjects poses a significant hurdle for building robust and generalizable models. Existing single-subject approaches lack scalability and generalizability. This paper addresses this limitation by proposing a novel, multi-subject training framework which effectively integrates data from multiple subjects, handling the variability in electrode placement and enabling the extraction of shared, global neural representations. This framework utilizes a transformer architecture incorporating a convolutional tokenizer to extract electrode-specific features and then combines these with spatial information to capture spatiotemporal dynamics across the entire brain network. This method shows promise in decoding behavioral response times even with limited data per subject, and demonstrates the power of multi-subject training for improving generalization performance. The key to success lies in the unified architecture capable of handling heterogeneous data while still effectively extracting shared, subject-independent neural representations.
Multi-Subject Model#
The multi-subject model presented tackles the challenge of heterogeneous electrode placement across individuals in stereotactic EEG (SEEG) data. By employing a shared trunk architecture, it extracts global neural representations that are common across subjects, and then uses subject-specific heads to tailor the model’s output to the unique statistical profile of each subject. This approach contrasts with single-subject models, achieving superior performance and demonstrating the potential for generalization across individuals. The strategy of using convolutional tokenization and self-attention in time and electrode dimensions effectively handles the variability in electrode number and placement, leading to a robust and scalable decoding model. The results showcase the model’s ability to decode behavioral response time from combined data, suggesting the value of this approach for future SEEG decoding research.
Transformer Network#
A transformer network, in the context of neural decoding from stereotactic EEG (SEEG), offers a powerful approach to capturing complex spatiotemporal relationships in neural data. Its strength lies in its ability to handle variable-length sequences and long-range dependencies, crucial for SEEG where electrode placement is highly irregular across subjects. The use of self-attention mechanisms allows the model to weigh the importance of different electrodes and time points, unlike traditional convolutional neural networks that struggle with this inherent variability. Tokenization of the neural activity through convolutions creates meaningful representations that are then processed by the self-attention layers. The spatial positional encoding further enhances the model’s understanding by incorporating the 3D location of each electrode. This architecture is thus well-suited for multi-subject training, allowing for better generalization across individuals and paving the way for improved clinical applications.
Transfer Learning#
The concept of transfer learning is crucial in this research, aiming to leverage knowledge gained from training a model on a large, diverse dataset of subjects to improve performance on new, unseen subjects. The core idea is that the model learns generalizable features during the initial training phase that can be effectively transferred to new subjects with minimal retraining. This approach is particularly relevant given the heterogeneity of sEEG data, where electrode placement and number vary greatly across individuals. By pretraining a model on a large multi-subject dataset, the researchers aim to overcome the limitations of single-subject models, which struggle to generalize and scale. The success of transfer learning in this context showcases the model’s ability to extract global, behaviorally relevant neural representations that are shared across individuals, improving decoding performance on subjects not included in the initial training. The transfer learning process highlights the model’s robust feature extraction capabilities and its potential for broad applicability. The ability to adapt to new subjects with limited data also suggests a significant improvement in efficiency and practicality over traditional methods, paving the way for more efficient and widely applicable sEEG-based neural decoding in clinical settings. The few-shot transfer learning capabilities of the model hold immense clinical value, enabling quicker and more effective individual analyses without the need for extensive data collection for each new subject.
Future Directions#
Future research could explore several promising avenues. Scaling up the dataset by incorporating data from a more diverse patient population and a wider range of behavioral tasks is crucial. This would allow for better generalization and more robust decoding models. Investigating multi-task learning approaches is another key direction. By training models on multiple behavioral tasks simultaneously, it might be possible to identify shared neural representations and further improve decoding accuracy and generalization capabilities. Finally, exploring self-supervised learning techniques would improve the quality and the generalizability of the trained models. This involves training models on large amounts of unlabeled data, which would make the learning process more robust and require less labeled data for accurate decoding of behavior.
More visual insights#
More on figures

This figure provides a visual overview of the behavioral experiment and the electrode placement used for the study. Panel A shows a schematic of the color change detection task, illustrating the different stages: pre-trial, stimulus, color-change delay, response, and response time. Panels B and C show the electrode placement projected onto the MNI brain template. Panel B shows electrode locations in four example subjects, distinguishing between electrodes used for model training (red dots) and those excluded (gray dots). Panel C shows electrodes from all subjects used in model training, providing a summary visualization of the data used in the study.

This figure compares the decoding performance of single-subject models versus multi-subject models (A) and finetuned multi-subject models (B) for each subject. The size of the circles represents the number of trials for each subject, ordered from smallest to largest. It visually demonstrates that using multi-subject models improves decoding performance compared to single-subject models, and further enhancement can be achieved by finetuning the multi-subject model for each individual subject.

This figure compares the decoding performance (R-squared) of single-subject models versus multi-subject models (A) and single-subject models versus finetuned multi-subject models (B) for each subject in the study. The size of the circles in the scatter plots represents the number of trials used for training. It shows that the multi-subject models generally outperform the single-subject models, and finetuning multi-subject models further boosts performance.

This figure compares the performance of various baseline models (PCA + Wiener, PCA + Ridge, PCA + XGB, MLP, CNN + MLP, PCA + Lasso) with the proposed Seegnificant model. The Seegnificant model is tested in several configurations: single-subject, multi-subject, multi-subject with fine-tuning, and single-subject with transfer learning. The results show that the multi-subject and transfer learning variants of Seegnificant outperform all baseline models, highlighting the benefits of the multi-subject training approach.
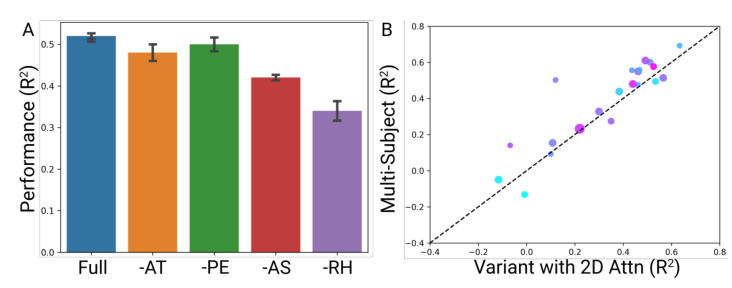
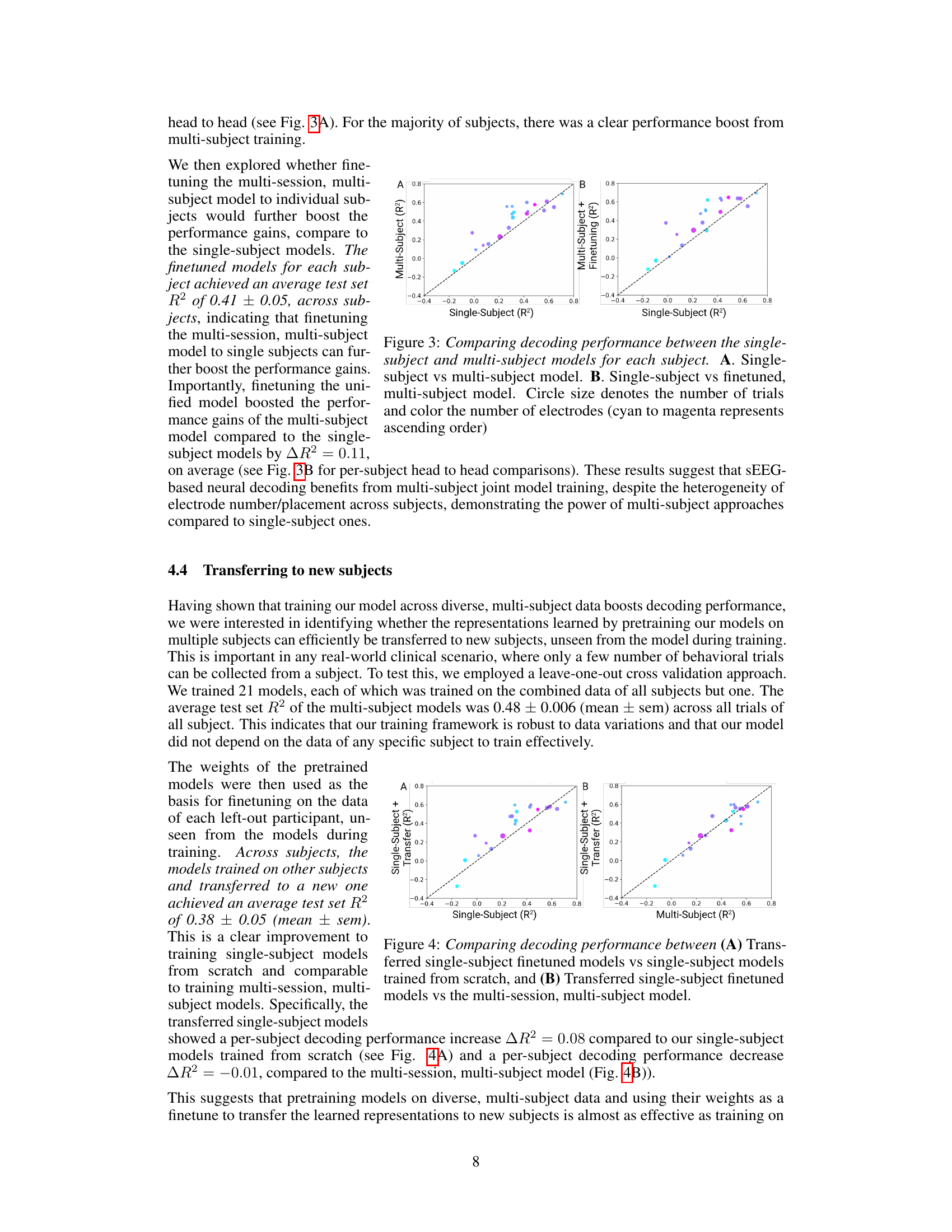
Figure 6 presents the results of an ablation study evaluating the impact of different components of the proposed model on decoding performance. Panel (A) shows a bar graph comparing the performance of the full model with versions where various components (temporal attention, spatial positional encoding, spatial attention, and subject-specific regression heads) have been removed. Panel (B) displays a scatter plot comparing the performance of the full multi-session, multi-subject model against a variant using a single 2D attention mechanism instead of separate temporal and spatial attention mechanisms.
This figure shows a scatter plot comparing the decoding performance (R-squared) of a multi-subject model trained with spatial positional encoding against the same model trained without it, for each of the 21 subjects. Each point represents a subject, with color indicating the number of electrodes used for that subject. The dashed line represents the line of equality (y = x). The plot shows that the inclusion of spatial positional encoding has a variable effect on individual subjects, with some showing improvement and others showing no significant change in performance. A statistical test comparing the two sets of results is mentioned in the paper’s appendix.
More on tables

This table shows the inference time of the multi-session, multi-subject model on two different machines: a commercial laptop and a server. The results are given for both CPU and GPU, demonstrating the model’s real-time applicability.

This table presents the per-subject R-squared values achieved by the model using three different positional encoding schemes: the scheme proposed by Vaswani et al. [2017], a Fourier-based scheme using MNI coordinates, and the RBF-based scheme proposed in the paper. The results show that the RBF-based scheme proposed in the paper performs comparably to the Fourier-based approach, and both significantly outperform the Vaswani et al. scheme.
Full paper#