↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world applications utilize tabular data, but labeling enough data for effective machine learning is often expensive or even impossible. This scarcity presents a major challenge for few-shot learning, particularly in tabular data due to the heterogeneity of the features and lack of spatial relationships commonly leveraged in image and text data. Existing methods often struggle to handle this data type effectively.
This paper introduces D2R2, a novel framework addressing the challenges of tabular few-shot learning. D2R2 uses a diffusion model to extract semantic knowledge, crucial for denoising and improving the effectiveness of few-shot learning. It also incorporates a random distance matching technique to preserve the distance between samples in the embedding space. Finally, to handle the potential multimodality of embeddings, it uses an iterative prototype scheme to improve classification. Experiments show that D2R2 significantly outperforms other state-of-the-art approaches on several benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on few-shot learning with tabular data, a common yet challenging problem in various fields. It presents a novel approach with state-of-the-art performance, opening up new avenues for research in this area. The proposed framework’s adaptability to various dataset types and its use of a diffusion model make it a significant contribution that can benefit diverse research communities.
Visual Insights#
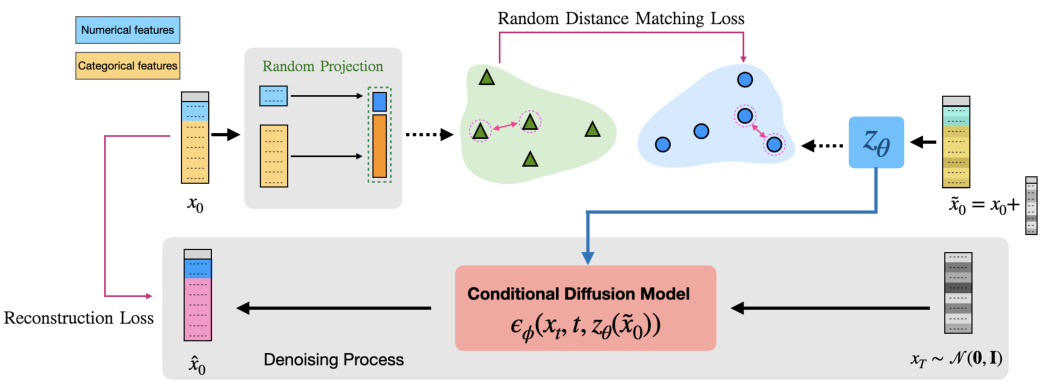
This figure illustrates the training process of the embedding space in the D2R2 model. It shows how numerical and categorical features are processed, undergoing noise perturbation and random projection before feeding into a conditional diffusion model for noise prediction. The model’s parameters are optimized using reconstruction and random distance matching (RDM) loss to preserve distance information in the embedding space, which is crucial for effective downstream classification.
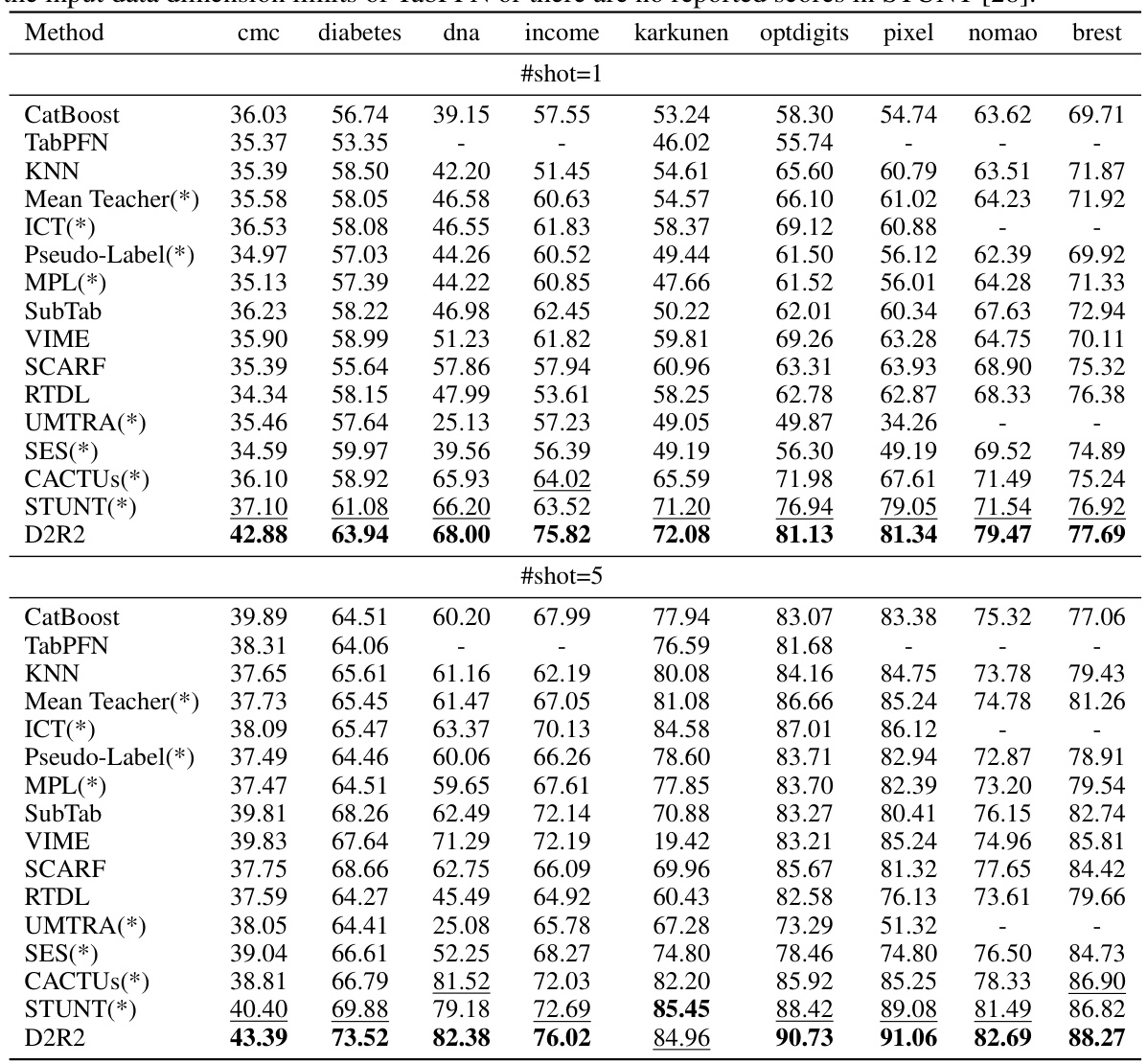
This table presents the classification accuracy results of various methods on nine datasets under two few-shot learning settings (1-shot and 5-shot). It compares the proposed D2R2 method with several baseline methods, including supervised, semi-supervised, self-supervised, and meta-learning approaches. The table highlights the superior performance of D2R2 across different datasets and settings.
In-depth insights#
Tabular Few-Shot#
The concept of “Tabular Few-Shot Learning” tackles the crucial challenge of classifying data with limited labeled examples, a common issue in real-world tabular datasets. Data scarcity is a primary hurdle, as annotating sufficient samples is often expensive or impossible. Traditional machine learning struggles in this low-data regime. The inherent heterogeneity of tabular data, with its mix of numerical and categorical features, further complicates the task. Existing methods often fail to effectively capture the relationships within this diverse feature space. Therefore, novel approaches are needed that can leverage the available limited labeled data and the potentially rich information within the unlabeled data. Effective feature representation and distance preservation among data points are vital for successful few-shot learning in tabular settings, often requiring specialized techniques to account for the mixed feature types. The development of robust models that can generalize well from limited data remains a central focus for researchers, as demonstrated by the exploration of diffusion models and other novel approaches to address this critical area.
Diffusion Models#
Diffusion models, a class of generative models, are revolutionizing various fields by learning complex data distributions through a diffusion process. They work by gradually adding noise to data until it becomes pure noise, then learning to reverse this process to generate new data points. This approach offers several advantages: high sample quality, the ability to generate diverse samples, and strong theoretical foundations. However, they also present challenges, such as computational cost and the potential for mode collapse (where the model fails to capture the full diversity of the data). Furthermore, effective training requires careful tuning of hyperparameters, including the noise schedule and the model architecture. The application of diffusion models to tabular data, however, presents unique challenges due to the inherent heterogeneity of tabular features and the scarcity of labeled data. Novel approaches are needed to effectively leverage the strengths of diffusion models while mitigating their limitations within the context of tabular data.
Distance Matching#
The concept of ‘Distance Matching’ in the context of a research paper likely revolves around techniques that leverage distance metrics to learn effective representations or improve model performance. It could involve preserving or aligning distances between data points in different embedding spaces, potentially using methods like random projections or other dimensionality reduction techniques to enhance class separability. The core idea is that semantically similar data points should have smaller distances in the learned representation, while dissimilar data points should be further apart. This is often employed in few-shot learning scenarios where labeled data is scarce. Distance matching techniques can help capture crucial semantic knowledge and refine the clustering behavior of embeddings, leading to improved classification accuracy and robustness, especially when dealing with multimodal or heterogeneous data types often encountered in tabular data. The effectiveness of distance matching hinges on selecting suitable distance metrics and projection methods appropriate for the characteristics of the data and downstream tasks.
Prototype Refinement#
Prototype refinement, in the context of few-shot learning, is crucial for improving classification accuracy, especially when dealing with limited labeled data and the inherent ambiguity in representing a class with scarce information. The core idea is to iteratively adjust prototypes to better reflect the underlying data distribution. This iterative process could involve incorporating new data points or adjusting existing prototypes based on the distance information between embeddings and refining the clustering of embeddings. The goal is to create robust, precise prototypes that accurately capture the characteristics of each class, reducing classification errors and increasing overall system robustness. This might entail handling multimodality by creating multiple prototypes per class, or employing weighted averages to improve prototype stability. A key aspect of successful prototype refinement is addressing issues such as high variance in prototypes due to limited labeled samples and the potential multimodality of feature embeddings. This is often done by strategically using distance information to incorporate knowledge from both labeled and unlabeled data. The effectiveness of prototype refinement methods heavily depends on properly integrating distance information from random projections or other approaches to avoid overfitting to noise and bias in limited datasets. Through these steps, the refined prototypes can enhance performance, especially in challenging few-shot scenarios by reducing erroneous classification arising from insufficiently representative initial prototypes.
Future Directions#
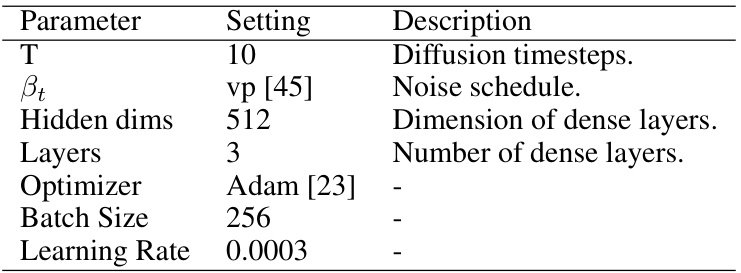
Future research could explore several promising avenues. Extending D2R2 to handle even more diverse data types beyond numerical and categorical features is crucial. Investigating the impact of different noise schedules and diffusion model architectures on performance warrants further study. Developing more sophisticated instance-wise prototype refinement strategies could significantly improve classification accuracy. A deeper theoretical understanding of the embedding space generated by the diffusion model, including its properties and relationship to distance information preservation, would provide valuable insights. Finally, applying D2R2 to real-world applications, such as fraud detection or disease diagnosis, and evaluating its performance on larger and more complex datasets will showcase its practical effectiveness and identify areas for further refinement. Addressing the limitations of reliance on pseudo-labels for hyperparameter selection is important to improve the robustness and generalizability of the approach.
More visual insights#
More on figures
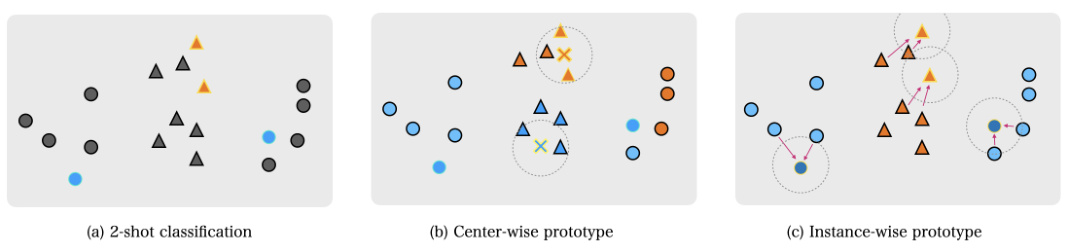
This figure illustrates the difference between using center-wise prototypes and instance-wise prototypes in a 2-shot classification scenario. Center-wise prototypes, which average embeddings of all support samples for a class, fail to handle multimodality in embeddings and lead to inaccurate classification when clusters within a single class are not well-separated. Instance-wise prototypes, on the other hand, leverage the weighted average of query embeddings and support embeddings to iteratively refine prototypes and are more robust to such multimodal situations, significantly improving classification accuracy.
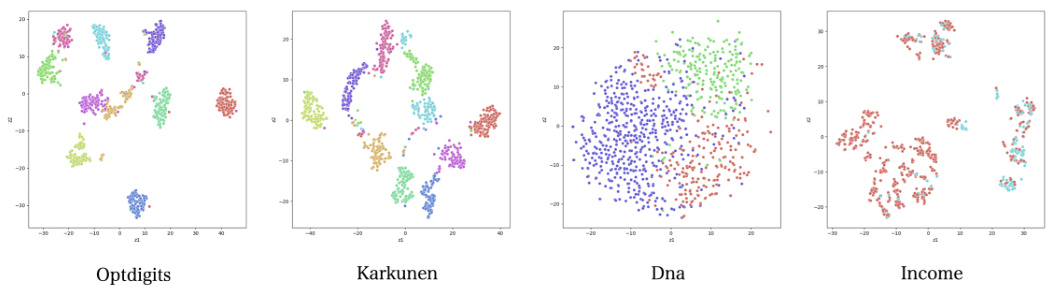
This figure shows t-SNE visualizations of the D2R2 embeddings for four datasets: Optdigits, Karkunen, Dna, and Income. Each point represents a randomly selected sample, and the color indicates its class label. The visualizations reveal that the embeddings often exhibit multimodality, meaning that samples from the same class are not clustered tightly together but rather spread across multiple distinct regions in the embedding space. This multimodality is particularly evident in the ‘dna’ dataset, where points of the red class appear in two separate clusters.
More on tables

This table presents the test accuracy results for various few-shot learning methods on nine different datasets. The results are averaged across 100 random seeds for both 1-shot and 5-shot scenarios. The table compares the proposed D2R2 method against multiple baselines including supervised, semi-supervised, self-supervised, and meta-learning approaches. Bold numbers indicate the best performance, and underlined numbers indicate the second-best performance for each dataset and scenario. Some cells are empty due to limitations of certain baselines or missing data in the original STUNT paper.

This table presents the test accuracy of different models on nine datasets, comparing the performance of D2R2 against various baseline methods (supervised, semi-supervised, self-supervised, and meta-learning). The results are averaged over 100 runs and reported for both 1-shot and 5-shot scenarios. The table highlights the superior performance of D2R2 compared to other methods. Some baseline results are taken from the STUNT paper.

This table presents the test accuracy results of the proposed D2R2 model and fifteen baseline models across nine different datasets in both 1-shot and 5-shot settings. The results are averaged over 100 random runs, and the best performing model for each dataset and setting is highlighted. The table demonstrates the superior performance of D2R2 compared to existing state-of-the-art methods.
This table presents the test accuracy results for various few-shot learning methods on nine different datasets. The accuracy is averaged over 100 runs with different random seeds. The table compares the proposed D2R2 method with several state-of-the-art baselines, including supervised, semi-supervised, self-supervised, and meta-learning approaches. Both 1-shot and 5-shot scenarios are evaluated. Empty cells indicate that the dataset either exceeded the input limitations of a particular baseline or that results weren’t reported in the referenced STUNT paper.

This table presents the test accuracy of different few-shot learning methods on nine datasets. It compares the proposed D2R2 method against 15 state-of-the-art baselines across two different experimental settings (1-shot and 5-shot). The table shows the average accuracy across 100 runs for each method and dataset. Some cells are empty due to limitations in the baselines or datasets.

This table presents the test accuracy results of various methods on nine different datasets for both 1-shot and 5-shot scenarios. The methods compared include supervised, semi-supervised, self-supervised, and meta-learning approaches. The table highlights the superior performance of the proposed D2R2 method across different dataset characteristics (numerical, categorical, mixed).
Full paper#