↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but slow. Speculative decoding aims to speed them up by first generating candidate tokens with a smaller, faster model, then verifying them with the larger model. However, existing methods often require training separate draft models, which is costly and inefficient. This paper’s core problem is that training separate draft model is costly and impractical.
The paper introduces Kangaroo, a new self-speculative decoding method that overcomes these limitations. Kangaroo cleverly leverages the existing LLM architecture, using a shallow sub-network and the LLM head as a self-drafting model, supplemented by a lightweight adapter module. It also employs a double early-exiting strategy (both layer and token level) to further enhance efficiency. Kangaroo achieves significant speedups (up to 2.04x) on various benchmarks, demonstrating its effectiveness and efficiency, especially when compared to existing self-drafting methods. It requires far fewer parameters, highlighting its practical applicability.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient self-speculative decoding framework, Kangaroo, that significantly accelerates large language model inference. This addresses a critical challenge in deploying LLMs for various applications by improving both speed and efficiency. The approach is particularly relevant given the increasing size and computational cost of modern LLMs, and its effectiveness on multiple benchmarks highlights its potential impact on future LLM research and development. The proposed method’s efficiency gains, achieved with fewer parameters than existing methods, are especially valuable.
Visual Insights#

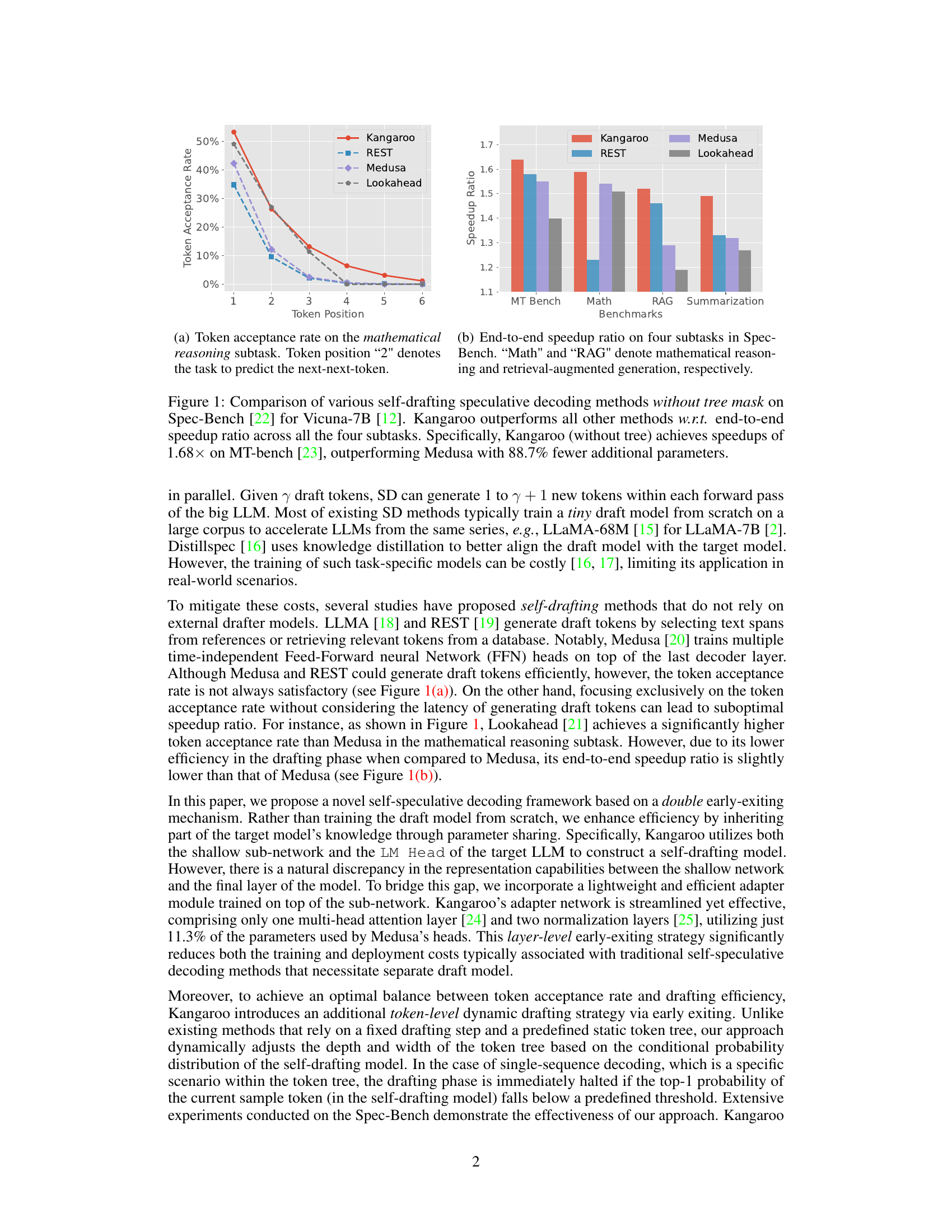
This figure compares the performance of Kangaroo against other self-drafting speculative decoding methods (Medusa, REST, and Lookahead) on the Spec-Bench benchmark using the Vicuna-7B language model. The comparison focuses on the token acceptance rate (the percentage of draft tokens accepted by the main model) and end-to-end speedup. Kangaroo demonstrates superior performance in terms of speedup across multiple subtasks, even with significantly fewer parameters than Medusa.
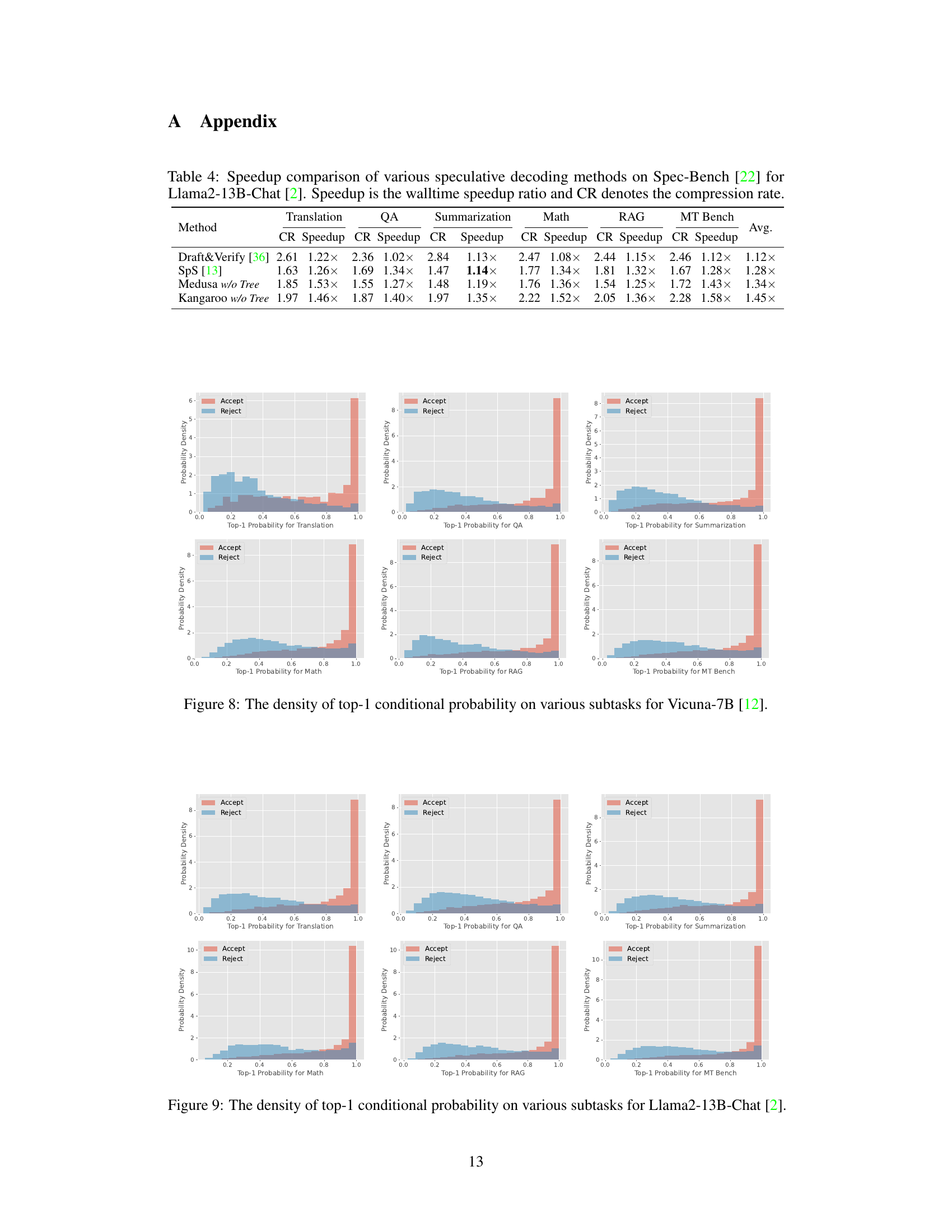
This table presents a comparison of different speculative decoding methods on the Spec-Bench benchmark using the Vicuna language model. It shows the wall-clock speedup achieved by each method and the compression rate (CR), which reflects the efficiency of token generation. The comparison includes methods such as Lookahead, Medusa (with and without tree), REST, and SpS, allowing for a performance evaluation of Kangaroo against existing techniques.
In-depth insights#
Self-Speculative Decoding#
Self-speculative decoding is a promising technique for accelerating large language model (LLM) inference. Unlike traditional speculative decoding, which relies on separate, trained draft models, self-speculative decoding leverages the target LLM itself to generate draft tokens, thus reducing the need for additional training data and computational resources. This approach typically involves using a smaller sub-network within the LLM to predict candidate tokens, followed by a verification step using the full LLM to confirm the predictions. The key advantage lies in its inherent efficiency as it bypasses the costs associated with separate model training. However, careful consideration must be given to the balance between the accuracy of the draft model and its speed, as well as strategies to minimize the overhead introduced by the verification step. Effective self-speculative decoding methods often incorporate early exiting mechanisms to dynamically adjust the prediction process, reducing computations for high-confidence tokens and further enhancing efficiency. Research in this area continues to explore optimal sub-network architectures, verification methods, and early-exiting strategies to maximize speed-up while preserving the accuracy and quality of the output.
Double Early Exiting#
The concept of “Double Early Exiting” in the context of accelerating LLMs suggests a two-staged approach to speculative decoding. The first stage involves an early exit from a shallow sub-network of the main LLM, generating draft tokens efficiently. This is crucial for speed because it avoids the full computational cost of the large model for each token. The second stage, or “double” aspect, executes a second early exit mechanism during the verification phase. This step dynamically assesses the confidence of predicted tokens. If confidence falls below a threshold, the computation is halted, preventing unnecessary processing of low-confidence predictions. This two-stage process combines the efficiency gains of shallow network processing with a dynamic approach to avoid wasting time on less-likely candidates, leading to considerable improvements in overall inference speed. The effectiveness of double early exiting relies on striking a balance: a shallow network needs sufficient capacity to have a high token acceptance rate, while the dynamic early exit mechanism must minimize unnecessary computations in the verification phase. The design elegantly addresses limitations of single-stage early exiting methods and prior self-drafting models by effectively leveraging the strengths of both approaches.
Adapter Network#
The concept of an ‘Adapter Network’ in the context of accelerating Large Language Models (LLMs) is crucial. It acts as a bridge, seamlessly integrating a lightweight module between a shallow sub-network and the full LLM. This design is key to addressing the representational gap that often arises when leveraging only a smaller part of the model for faster inference. The adapter network’s efficiency stems from its minimal parameter count, significantly reducing the computational overhead compared to training a separate draft model from scratch. Training focuses on aligning the adapter’s output with the full model’s behavior, thereby ensuring that the inferences from the accelerated, shallow network are consistent with the original LLM. Careful design of the adapter architecture, such as incorporating multi-head attention and normalization layers, is vital for its effectiveness. The adapter network is a significant innovation, enhancing the self-speculative decoding process by improving the token acceptance rate while controlling latency, ultimately leading to a more efficient and faster inference mechanism for LLMs.
Dynamic Drafting#
Dynamic drafting in large language models (LLMs) aims to optimize the decoding process by adaptively adjusting the number of tokens generated during the drafting phase. Unlike traditional speculative decoding methods that use a fixed drafting step, dynamic drafting leverages contextual information and confidence scores to determine when to stop drafting. This approach helps reduce unnecessary computations associated with verifying tokens that are unlikely to be accepted by the main LLM, thus improving efficiency. A crucial aspect is the confidence threshold, which determines when the drafting phase should halt. By dynamically adjusting this threshold, the model can effectively balance the trade-off between the token acceptance rate and the efficiency of the drafting phase. This method enhances the overall speed and efficiency of the LLM decoding process by reducing computational costs and improving the accuracy of the generated text. The introduction of a dynamic drafting strategy is a significant advancement in speculative decoding, showcasing a more adaptable and efficient approach to accelerate LLM inference.
Speedup Analysis#
A thorough speedup analysis in a research paper would go beyond simply presenting speedup numbers. It should meticulously dissect the factors contributing to performance gains. This involves comparing against relevant baselines, clearly stating the experimental setup (hardware, software, model size), and defining the metrics used (e.g., wall-clock time, throughput). A strong analysis would also delve into the scalability of the proposed method, showing how speedup changes with increasing model size or input sequence length. Furthermore, it is crucial to quantify the trade-offs. For instance, higher speedup might come at the cost of reduced accuracy or increased model complexity. A good speedup analysis will present a breakdown of the speedup to isolate the contributions of different components or techniques within the proposed method, ideally through ablation studies. Finally, the analysis needs to address potential limitations and discuss any scenarios where the speedup might be less significant or nonexistent. By rigorously analyzing and interpreting the results in this manner, researchers can build a robust case for the effectiveness and efficiency of their contributions.
More visual insights#
More on figures
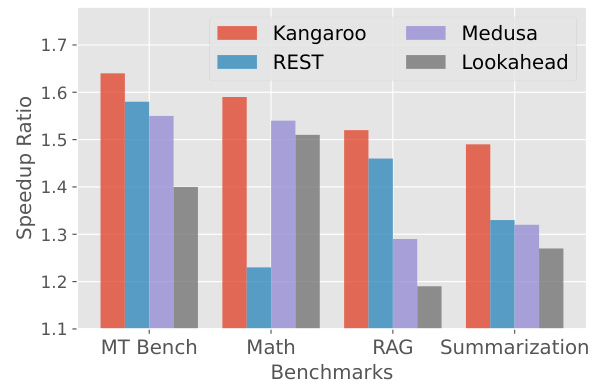
This figure compares the performance of Kangaroo and other self-drafting speculative decoding methods on four subtasks of the Spec-Bench benchmark using the Vicuna-7B language model. The left subplot shows the token acceptance rate for each method, plotting the rate against the token position, revealing how quickly each method confirms the generated tokens. The right subplot shows the end-to-end speedup of each method across the four subtasks (MT Bench, Math, RAG, Summarization). Kangaroo consistently demonstrates superior performance compared to other methods, showing substantial improvements in overall efficiency with fewer additional parameters.

This figure illustrates the Kangaroo framework during single-sequence verification. It highlights the use of a self-drafting model (Ms) composed of an adapter network (A) and a shallow sub-network of the target LLM (M♭). The self-drafting model generates draft tokens until a confidence threshold is met, at which point parallel computation is used to verify the tokens. The diagram shows two rounds of this process, illustrating how parallel computation reduces latency.

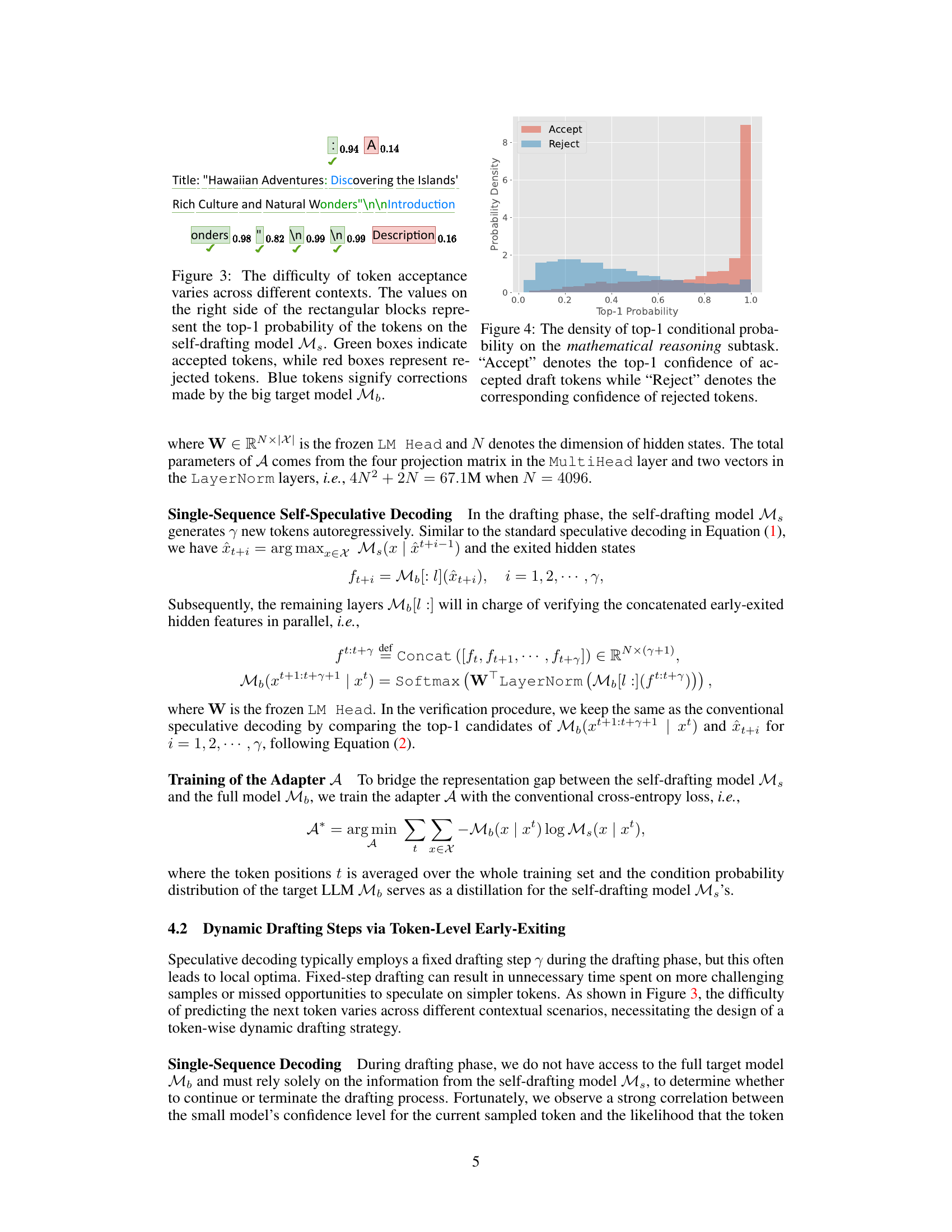
This figure shows the distribution of the top-1 probability (confidence) scores from the self-drafting model in Kangaroo. It compares the distributions for tokens that were accepted by the main language model (Accept) versus tokens that were rejected (Reject). The x-axis represents the top-1 probability, while the y-axis represents the probability density. The distributions clearly show that accepted tokens have significantly higher confidence scores than rejected tokens, demonstrating the effectiveness of the early exiting mechanism.
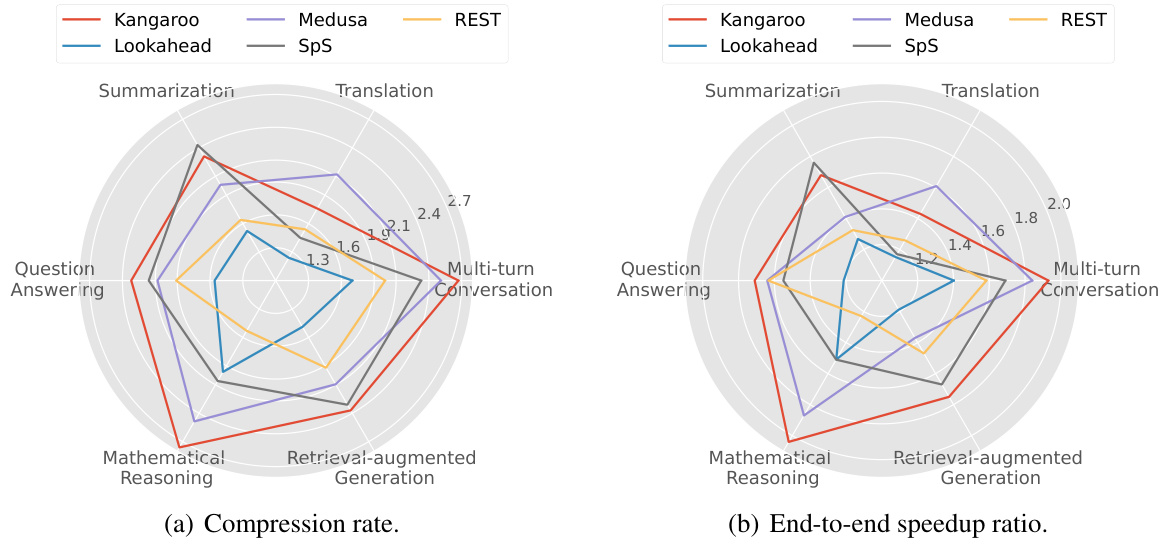
This figure compares the performance of various speculative decoding methods, including Kangaroo, Lookahead, Medusa, SpS, and REST, across six subtasks in Spec-Bench for the Vicuna-7B model. The left plot shows the compression rate, and the right plot shows the end-to-end speedup ratio. Kangaroo consistently outperforms other methods in most subtasks, particularly in mathematical reasoning and retrieval-augmented generation, demonstrating its effectiveness in accelerating large language model decoding.

This figure shows the relationship between the early-exit ratio (l/N) and the walltime speedup achieved by Kangaroo on four different LLMs: Vicuna-7B, Vicuna-13B, Vicuna-33B, and Llama2-13B-Chat. The x-axis represents the ratio of the number of early-exit layers (l) to the total number of layers (N) in the model. The y-axis represents the walltime speedup achieved by Kangaroo compared to standard decoding. The figure demonstrates that there is an optimal early-exit ratio for each model, beyond which the speedup decreases. The shaded area highlights the recommended range of early-exit ratios.
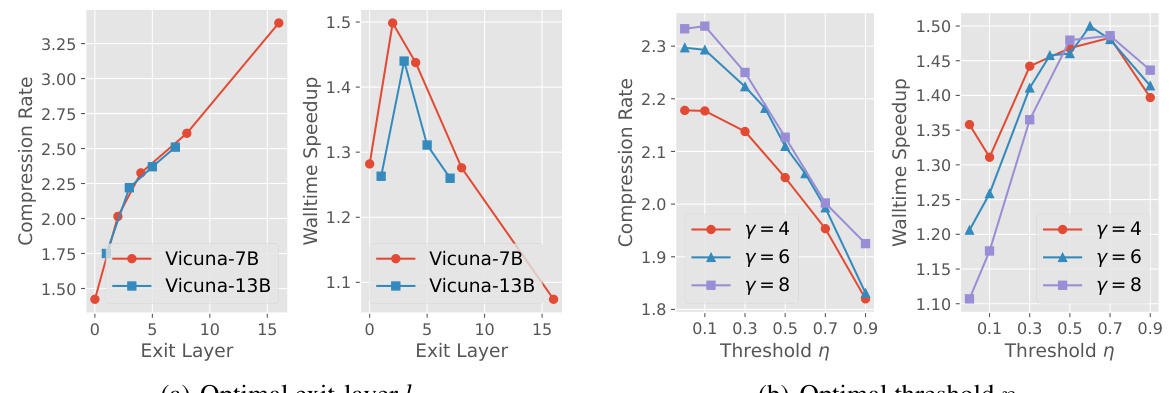
This figure shows the ablation study results on two hyperparameters: the depth of the shallow sub-network (l) and the early stopping threshold (η). The left two subfigures (a) show that increasing the depth of the shallow sub-network initially improves compression rate and speedup, but after a certain point, increasing the depth leads to diminishing returns and even performance degradation due to increased latency. The right two subfigures (b) illustrate that the optimal threshold (η) for the early stopping mechanism varies slightly with the number of drafting steps (γ) but remains relatively stable across different scenarios.

This figure shows the distribution of the top-1 conditional probability on various subtasks for Vicuna-7B. The x-axis represents the top-1 probability, and the y-axis represents the probability density. The figure is divided into six subplots, each corresponding to a different subtask: Translation, QA, Summarization, Math, RAG, and MT Bench. For each subtask, the distribution of the top-1 probability is shown for both accepted and rejected tokens. The figure helps visualize the relationship between the top-1 probability and the likelihood of a token being accepted or rejected.

This figure shows the distribution of the top-1 conditional probability generated by the self-drafting model (Ms) for accepted and rejected tokens across six subtasks of the Spec-Bench benchmark. The x-axis represents the top-1 probability, and the y-axis represents the probability density. Separate distributions are shown for accepted (green) and rejected (red) tokens, providing insights into how well the self-drafting model’s confidence correlates with token acceptance by the full model (Mb).
More on tables

This table presents the results of ablation studies conducted on the architecture of the adapter module A used in the Kangaroo model for Vicuna-7B. It compares different configurations of the adapter, including variations in the inclusion of Layer Normalization (LN) layers, the attention mechanism, the Feed-Forward Network (FFN), and the linear layer. Each configuration is evaluated for its speedup ratio on the Spec-Bench benchmark, which measures the overall improvement in decoding speed. The table allows researchers to understand the impact of each component on performance and efficiency, providing insights into design choices for similar models.

This table compares the performance of various speculative decoding methods on the Spec-Bench benchmark using the Vicuna language model. It shows the wall-clock speedup achieved by each method and the compression rate (CR), which represents the average number of tokens accepted per forward pass of the large model.

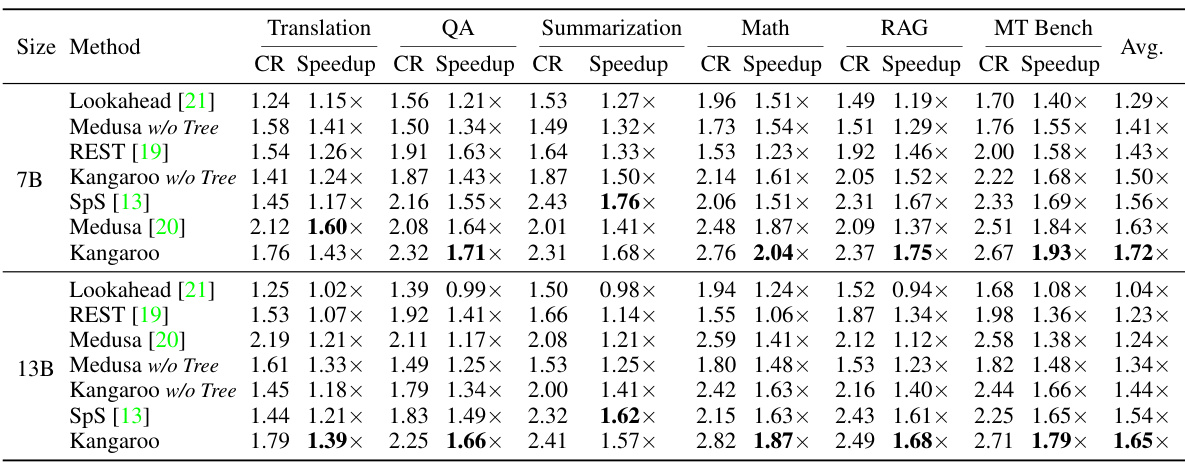
This table compares the performance of Kangaroo against several other speculative decoding methods (Lookahead, Medusa, REST, SpS) on the Spec-Bench benchmark using the Vicuna language model. The comparison considers two key metrics: wall-clock speedup (Speedup) and compression rate (CR). The results are presented for various subtasks within Spec-Bench (Summarization, Translation, QA, Math, RAG, MT Bench), showing the relative efficiency gains of each method for each subtask.
Full paper#