↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-agent environments pose challenges for autonomous agents due to the non-stationarity caused by unpredictable opponents. Traditional methods focus on short-sighted action prediction, limiting adaptability. The non-stationarity of the environment makes it difficult for agents to learn effective strategies when interacting with complex opponents.
This paper proposes OMG, a novel opponent modeling approach based on subgoal inference. Instead of predicting actions, OMG infers the opponent’s subgoals from historical trajectories. This method is more robust to different opponent policies because subgoals are often shared across multiple policies. Empirical evaluations show that OMG significantly improves adaptation compared to existing methods in various tasks, including cooperative and general-sum games.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-agent reinforcement learning because it introduces a novel opponent modeling method that significantly improves the adaptability and generalization of autonomous agents in complex environments. The subgoal inference approach offers a more robust and efficient way to handle unknown or diverse opponents, opening new avenues for research in collaborative and competitive scenarios. The empirical results demonstrate the method’s effectiveness across various tasks, highlighting its practical significance for real-world applications.
Visual Insights#
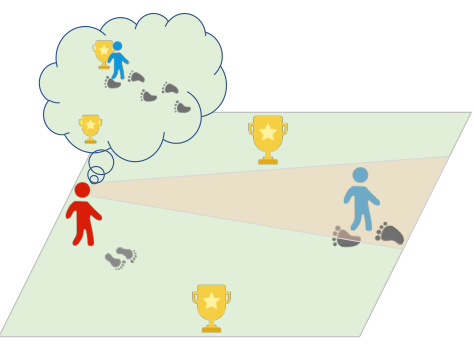
This figure illustrates how humans can infer the goals of others by observing their actions over several steps. It depicts multiple agents, possibly in a competitive scenario, moving towards different goals. By observing the trajectories of other agents, an agent can infer their likely goals, improving its decision-making in multi-agent environments. This concept is central to the proposed Opponent Modeling based on Subgoal Inference (OMG) method.
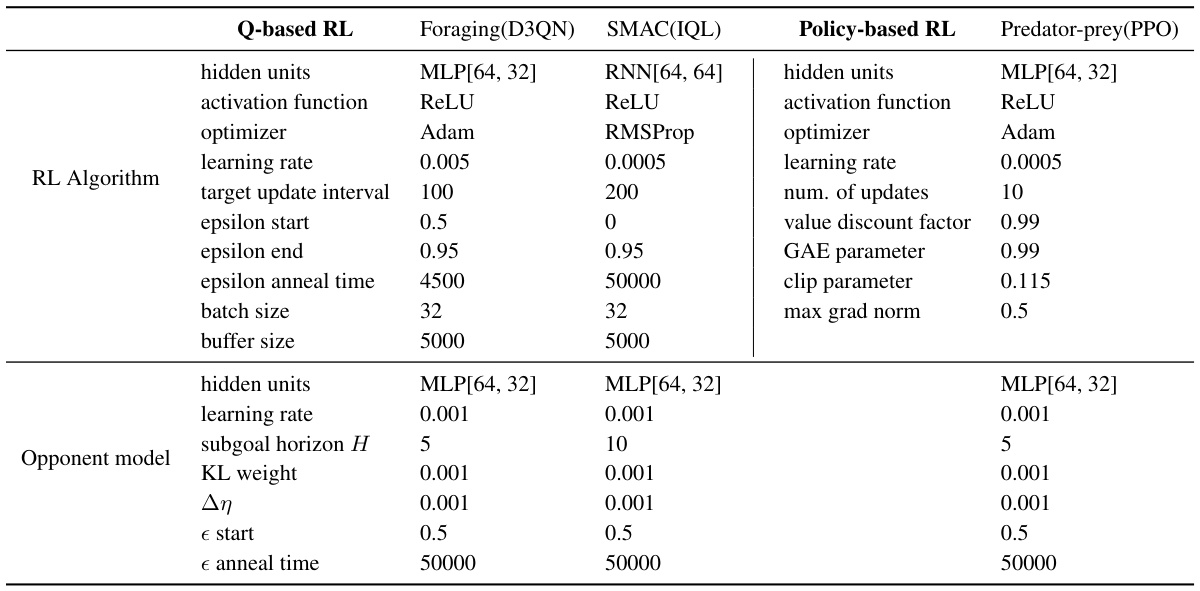
This table lists the hyperparameters used in the experiments for the three different reinforcement learning algorithms (D3QN, IQL, PPO) and the opponent model. It breaks down parameters such as hidden units, activation functions, optimizers, learning rates, and other key settings, allowing for reproducibility of the results.
In-depth insights#
Subgoal Inference#
The concept of ‘Subgoal Inference’ in multi-agent reinforcement learning focuses on predicting an opponent’s higher-level objectives rather than just their immediate actions. This approach is particularly valuable when dealing with complex tasks and unseen opponents, as subgoals are more likely to be shared across different opponent policies than specific action sequences. Inferring subgoals improves generalization, allowing agents to adapt more effectively to diverse strategies. The effectiveness of subgoal inference hinges on robust methods for identifying these subgoals from observed trajectories, often leveraging techniques like variational autoencoders to learn a meaningful representation of these high-level goals. Subgoal selection strategies also play a critical role, often adapting depending on whether the game is cooperative or competitive (e.g., optimistic vs. conservative selection). Successfully employing subgoal inference requires careful consideration of both the inference model and the subgoal selection mechanism to balance the trade-off between efficient learning and effective generalization to unseen opponents.
Opponent Modeling#
Opponent modeling in multi-agent reinforcement learning (MARL) is crucial for agents to effectively interact with and adapt to diverse opponents. Traditional methods often focus on predicting opponents’ actions, which can be shortsighted, particularly in complex tasks. The non-stationarity inherent in multi-agent environments, where opponents’ strategies may change, further complicates this approach. More sophisticated techniques, such as inferring opponents’ subgoals from their trajectories, offer significant advantages. By understanding the underlying goals rather than simply reacting to immediate actions, agents gain a deeper insight into opponent behavior and improve generalization to unseen opponents. This subgoal inference approach is particularly valuable in scenarios with diverse opponent policies where inferring shared subgoals allows for more robust and adaptive strategies. However, challenges remain. Accurately inferring subgoals, especially in noisy or partially observable environments, is a significant task and requires robust inference mechanisms. Furthermore, the choice of subgoal selection strategies (e.g., optimistic or conservative) needs careful consideration and may depend on the type of game (cooperative or competitive).
OMG Algorithm#
The proposed Opponent Modeling based on subGoals Inference (OMG) algorithm offers a novel approach to multi-agent reinforcement learning by inferring opponent subgoals rather than directly predicting actions. This shift in focus provides several key advantages. First, it leads to better generalization to unseen opponents, as subgoals are more likely to be shared across different opponent policies than specific action sequences. Second, OMG’s subgoal inference, implemented using a Conditional Variational Autoencoder (CVAE), enables the agent to develop a higher-level understanding of opponent intentions, improving the robustness and efficiency of learning. Two subgoal selection modes are introduced, catering to cooperative and general-sum games, demonstrating the algorithm’s adaptability across different game settings. The empirical results show that OMG outperforms existing methods in several multi-agent environments, highlighting the effectiveness of its subgoal-based approach. Inferring subgoals offers a more robust and efficient way to model opponents than action prediction, providing significant benefits in complex scenarios with diverse and unknown opponents.
Adaptation#
The concept of adaptation in multi-agent reinforcement learning (MARL) is crucial because agents often face unforeseen opponents or environments. Effective adaptation requires agents to generalize beyond their training data and quickly adjust to new situations. This paper introduces opponent modeling based on subgoal inference (OMG) as a method to enhance adaptation. Instead of directly predicting opponent actions, which can be short-sighted and prone to overfitting, OMG focuses on inferring the opponent’s underlying subgoals. This approach is advantageous because subgoals tend to be more stable and shared across different opponent policies, facilitating generalization. The empirical results demonstrate that OMG outperforms existing methods in adapting to unknown opponents across various tasks. The key to OMG’s success lies in its ability to leverage high-level representations (subgoals) rather than low-level actions, leading to improved generalization and faster learning. However, the effectiveness of subgoal inference depends on the choice of subgoal selection strategy and the horizon considered. The paper explores two selection strategies - optimistic and conservative - suited for different game types, highlighting the need for careful consideration of the problem context when implementing OMG. Future work could explore more sophisticated subgoal selection mechanisms and investigate the robustness of OMG in even more complex and dynamic MARL settings.
Generalization#
The study’s generalization capabilities are a crucial aspect, especially in multi-agent environments where unseen opponents are common. The core idea behind the proposed method’s generalization is its focus on inferring opponent subgoals rather than directly predicting actions. Subgoals, being higher-level representations of intentions, are more likely to be shared across different opponent policies, leading to better generalization. The empirical evaluation on the SMAC environment, known for its diverse opponent policies, supports this claim, showing that the method effectively adapts to unseen opponents. The success hinges on the effectiveness of the subgoal inference model, which leverages historical trajectories to infer future opponent subgoals. The use of a variational autoencoder further enhances robustness by providing a probabilistic representation of subgoals, making the approach less sensitive to noise and uncertainty in the observed data. However, the paper could benefit from a more in-depth analysis of the factors contributing to generalization success and a more rigorous comparison with other opponent modeling techniques specifically designed for generalization.
More visual insights#
More on figures
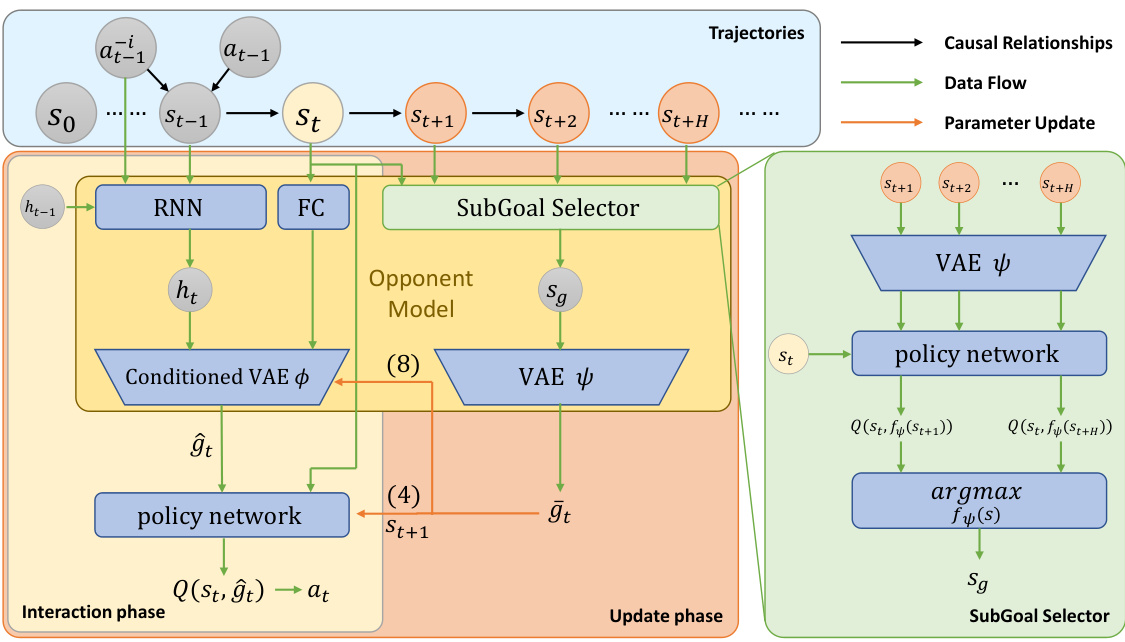
This figure illustrates the architecture of the Opponent Modeling based on subgoals inference (OMG) model. It shows two main phases: the interaction phase where the model infers the opponent’s subgoal using a conditional variational autoencoder (CVAE) and the update phase where the model refines its subgoal inference based on the entire trajectory and a value-based subgoal selection heuristic. The interaction phase uses the inferred subgoal to inform the agent’s policy, while the update phase uses a selected subgoal to improve the inference model.

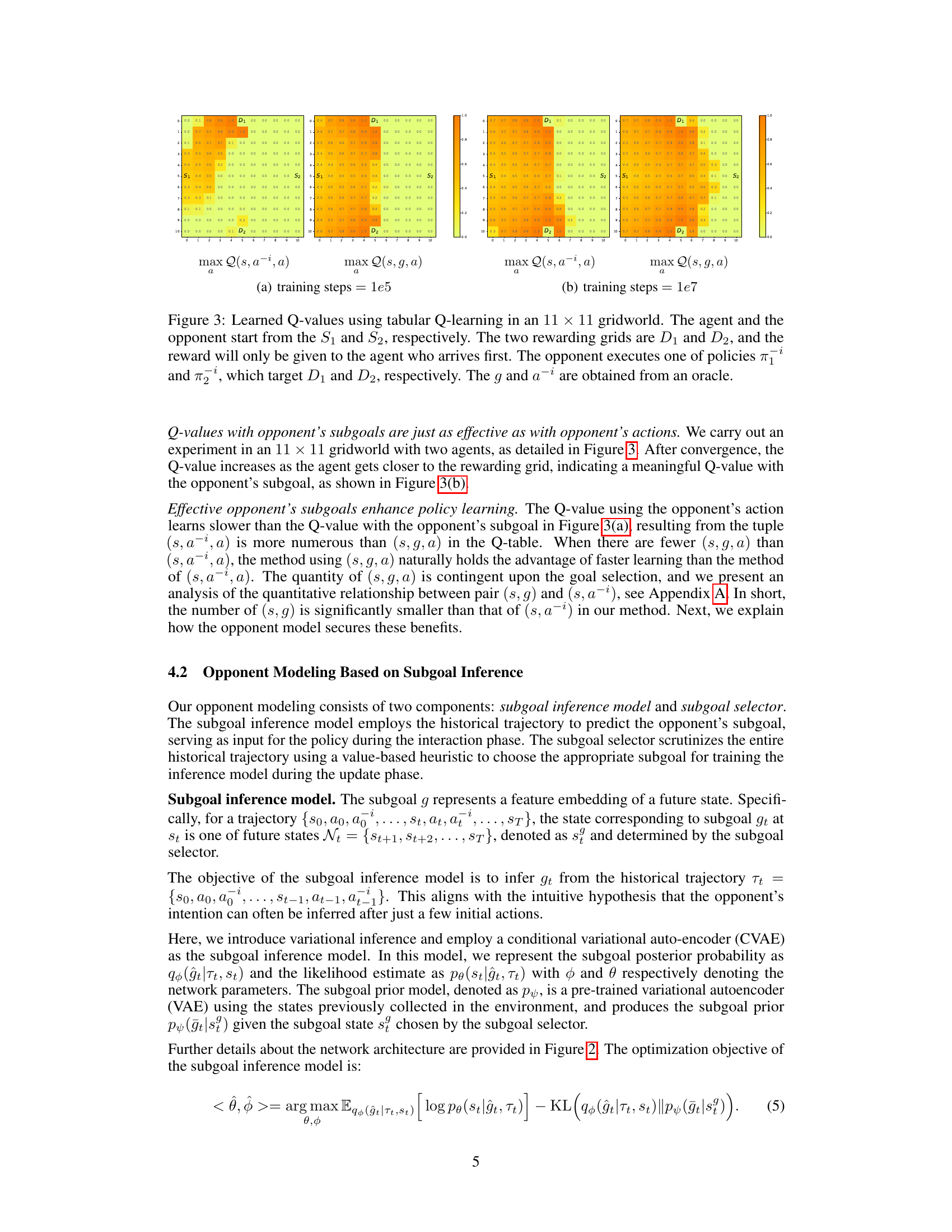
This figure shows the learned Q-values for an agent using tabular Q-learning in a gridworld scenario. Two scenarios are shown, one after 1e5 training steps and the other after 1e7 training steps. The goal is for the agent to reach either destination D1 or D2 before the opponent, who has a fixed policy targeting either D1 or D2. The heatmaps illustrate the Q-values (expected rewards) at different states (s), comparing using opponent’s actions (a¯i) vs opponent’s subgoal (g) in policy learning. The improvement in Q-value distribution as training progresses is evident, demonstrating that subgoal inference enhances learning compared to using opponent actions directly.
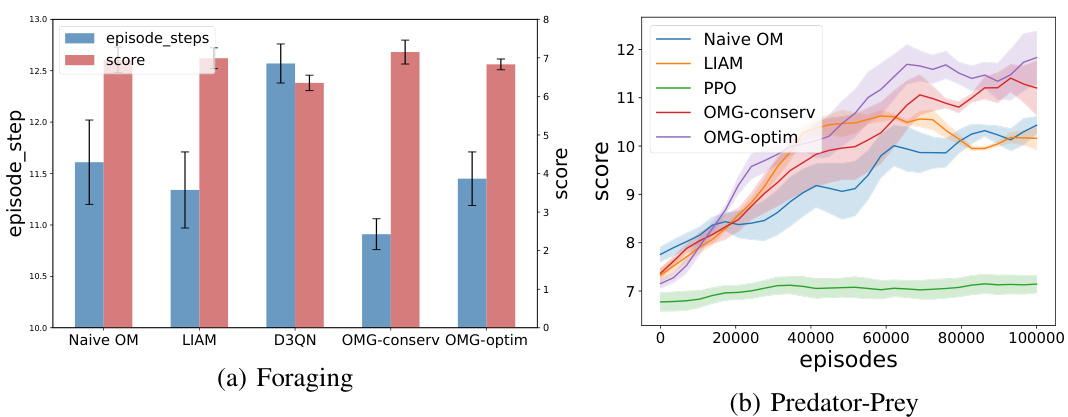
This figure shows the performance comparison of different methods in two environments: Foraging and Predator-Prey. In (a) Foraging, OMG achieves similar scores to the baselines but requires fewer steps per episode. In (b) Predator-Prey, OMG significantly outperforms the baselines. The results highlight OMG’s ability to predict opponent goals and adapt its strategy accordingly.
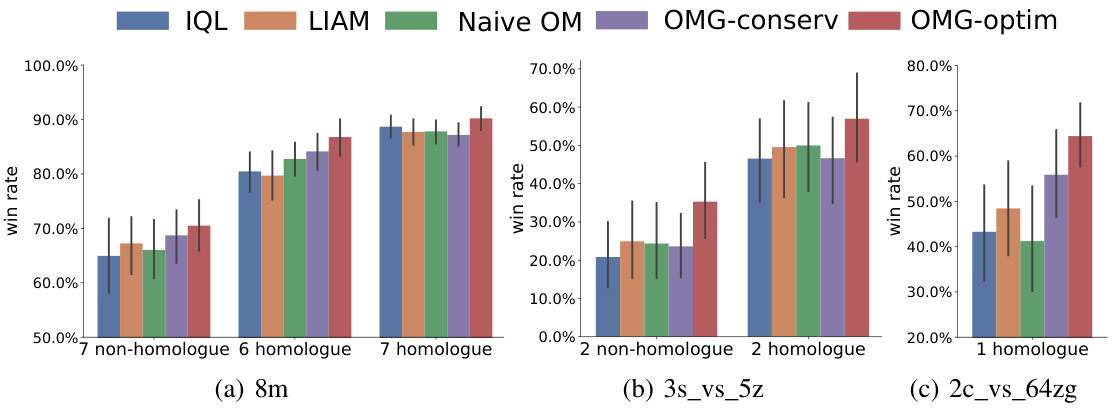
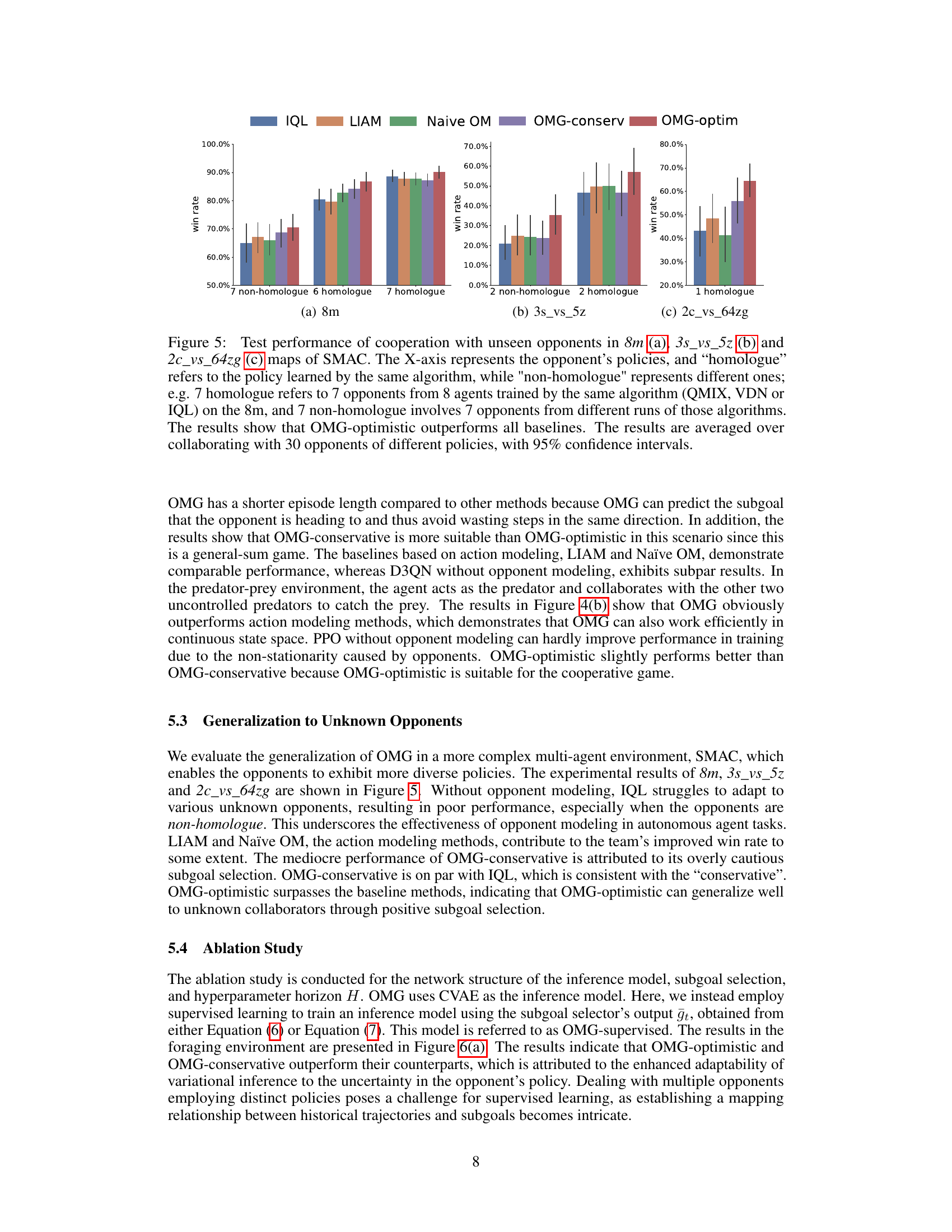
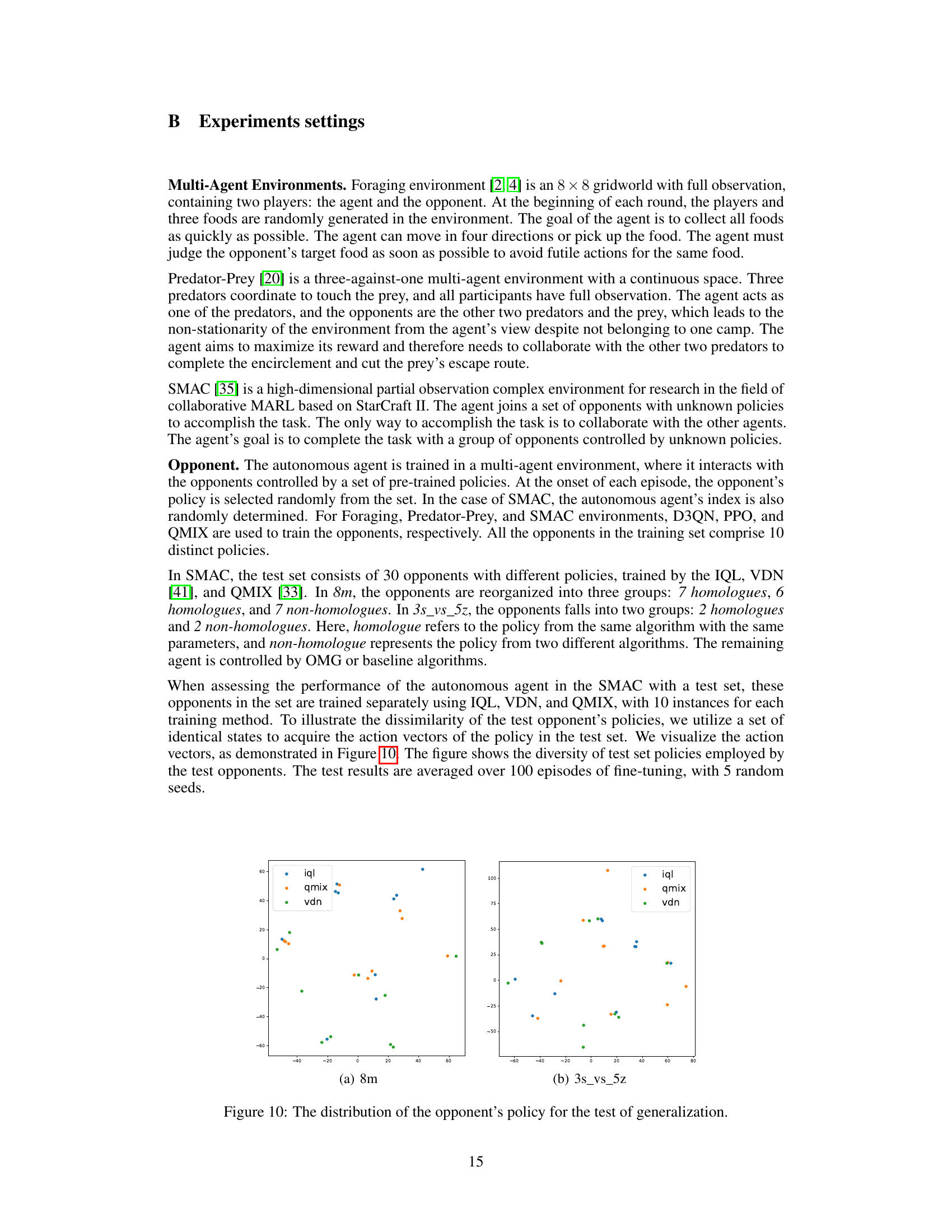
This figure displays the results of testing the cooperation performance of the OMG algorithm against unseen opponents in three different StarCraft II maps (8m, 3s_vs_5z, and 2c_vs_64zg) of the SMAC environment. The x-axis represents different opponent policy types, categorized as ‘homologue’ (policies trained by the same algorithm) and ’non-homologue’ (policies trained by different algorithms). The y-axis shows the win rate. The results demonstrate the superior performance of the OMG-optimistic variant compared to other methods (IQL, LIAM, Naive OM, OMG-conservative) across all maps and opponent types.
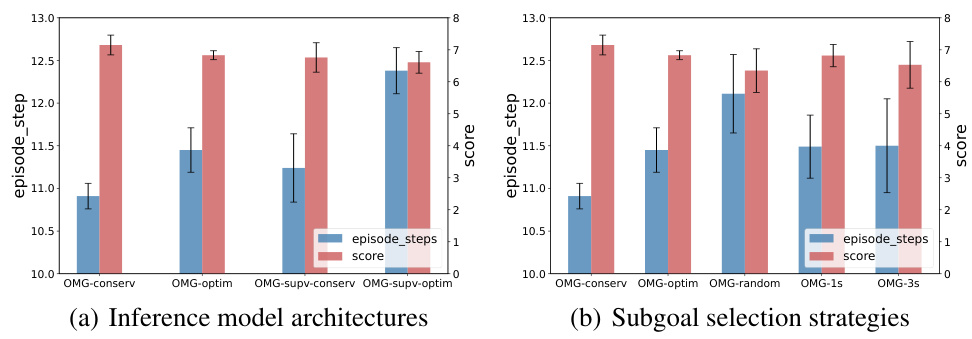
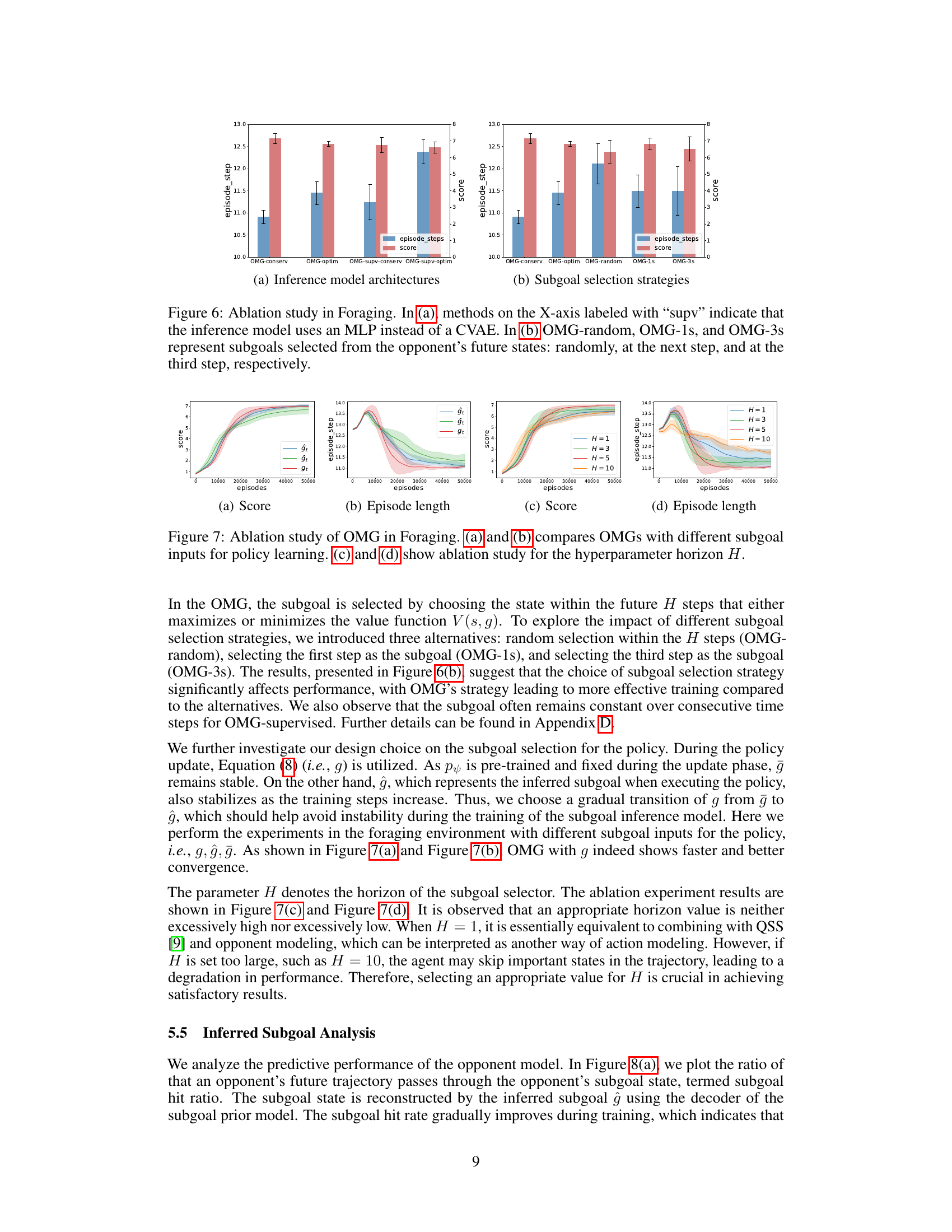
This figure shows the ablation study results for the proposed Opponent Modeling based on subgoal inference (OMG) method in the Foraging environment. Panel (a) compares the performance of OMG using a Conditional Variational Autoencoder (CVAE) for subgoal inference against a simpler Multilayer Perceptron (MLP) architecture. Panel (b) contrasts different subgoal selection strategies within OMG: random selection, selecting the next timestep’s state, and selecting the state three timesteps ahead. The results illustrate the impact of both the inference model architecture and the subgoal selection strategy on the overall performance of the OMG method.
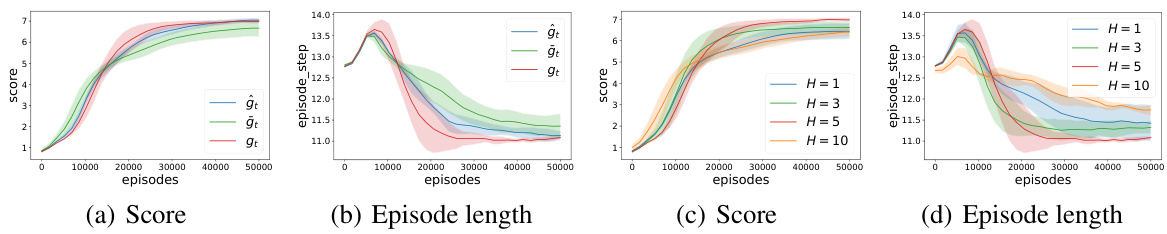
This figure presents the ablation study results of the Opponent Modeling based on subgoal inference (OMG) method in the Foraging environment. Parts (a) and (b) compare the performance of OMG with different subgoal input methods for policy learning, showing the impact of using inferred subgoals (ĝ), prior subgoals (ğ), and randomly selected subgoals on the agent’s score and episode length. Parts (c) and (d) explore the effect of varying the hyperparameter H (horizon of future states considered for subgoal selection) on the agent’s performance, demonstrating the influence of this parameter on both score and episode length.
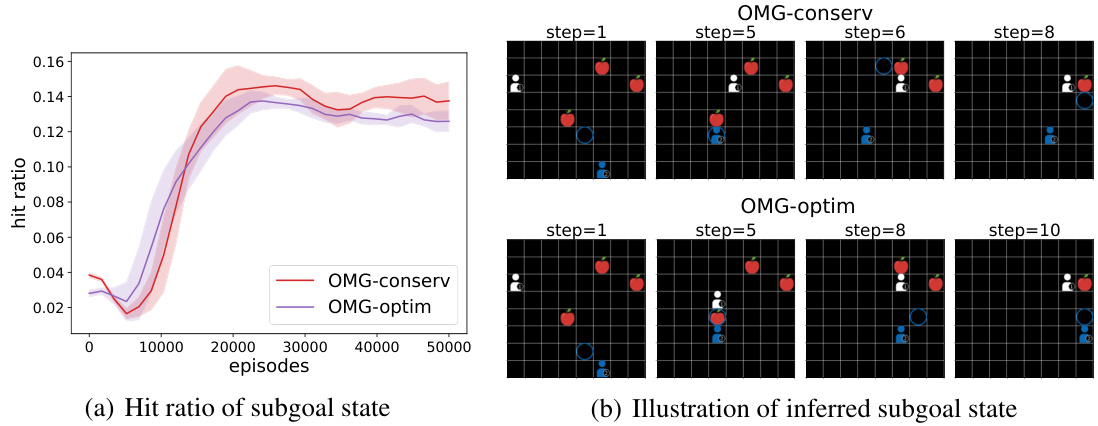
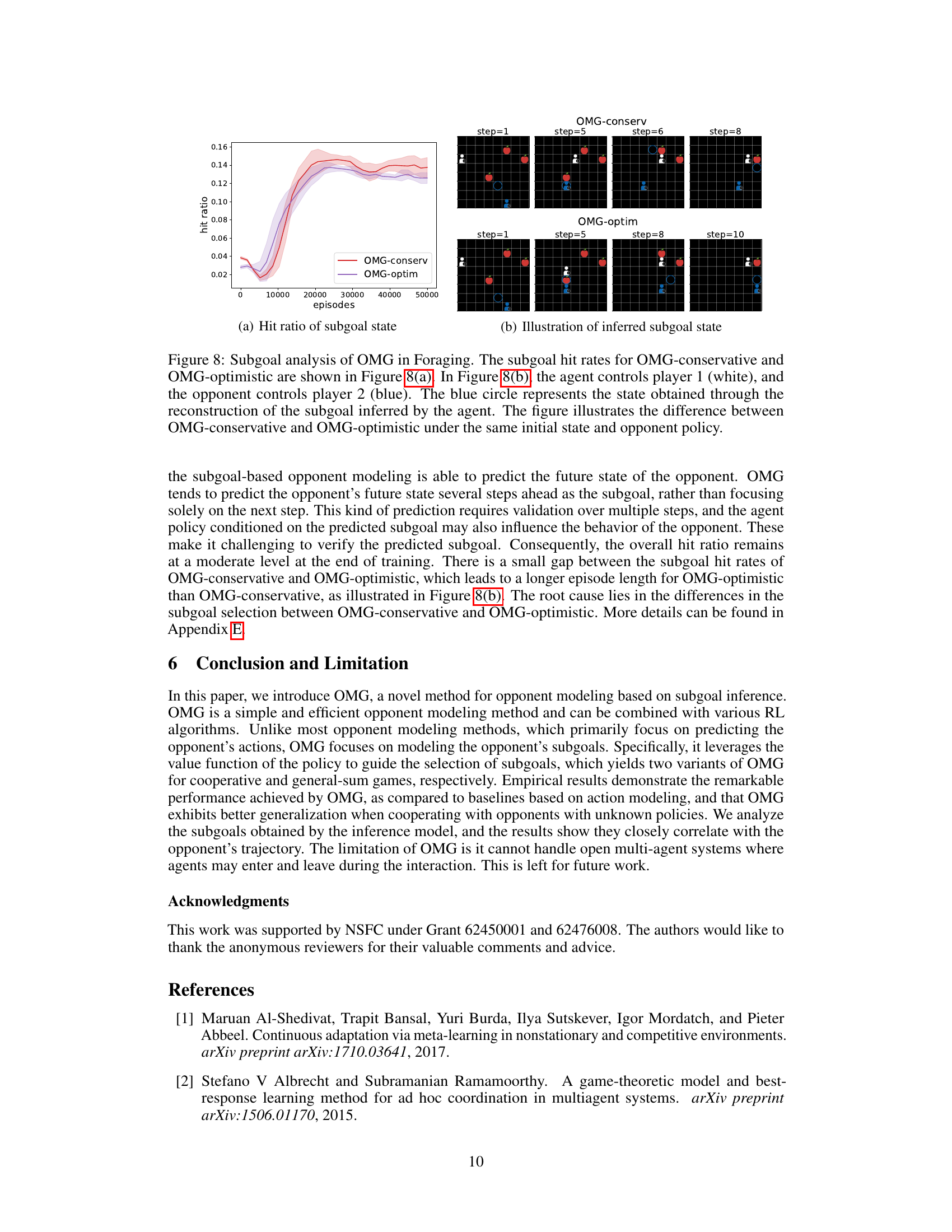
This figure analyzes the performance of the Opponent Modeling based on subgoal inference (OMG) method in a Foraging environment. Panel (a) shows the subgoal hit ratio (the percentage of times the model correctly predicts the opponent’s future state based on their subgoal) for both the optimistic and conservative versions of OMG. Panel (b) visually demonstrates, using a sample scenario, how the inferred subgoal (blue circle) helps the agent anticipate the opponent’s future movement. The difference between the optimistic and conservative versions of OMG is highlighted in this visualization, showing how their different subgoal selection strategies lead to different predictions.
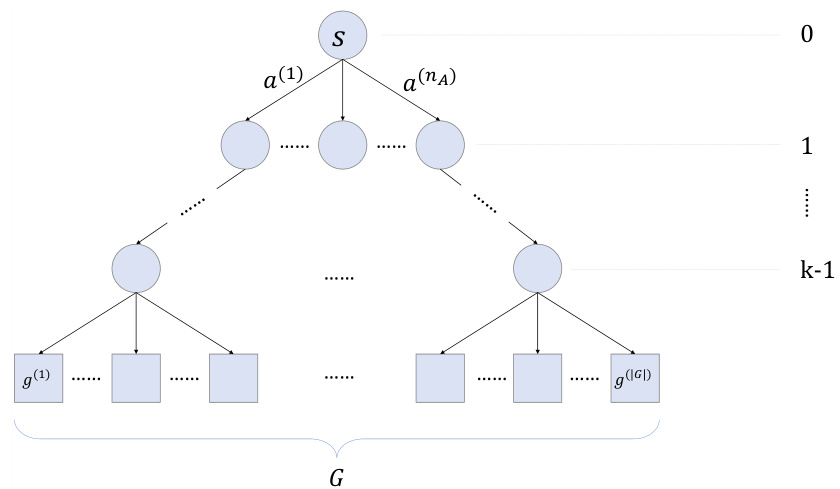
This figure illustrates a decision tree representing the opponent’s action sequences. Non-leaf nodes represent states, edges represent actions taken by the opponent, and leaf nodes represent the goal states. The tree is used to analyze and compare the number of state-action pairs (s, a) versus the number of state-subgoal pairs (s, g) in opponent modeling. This comparison helps demonstrate the efficiency gains of OMG’s subgoal-based approach over action-prediction methods.
This figure shows the test performance of the OMG algorithm in three different scenarios of the StarCraft II Multi-Agent Challenge (SMAC) environment against opponents with unseen policies. The x-axis represents different opponent policies; homologue indicates opponents trained using the same algorithm and parameters, non-homologue indicates opponents trained differently. The y-axis shows the win rate. The results demonstrate that the OMG-optimistic approach outperforms the baselines (IQL, LIAM, Naive OM) across the different scenarios and opponent types. The improved performance highlights the generalization capabilities of the OMG-optimistic method.
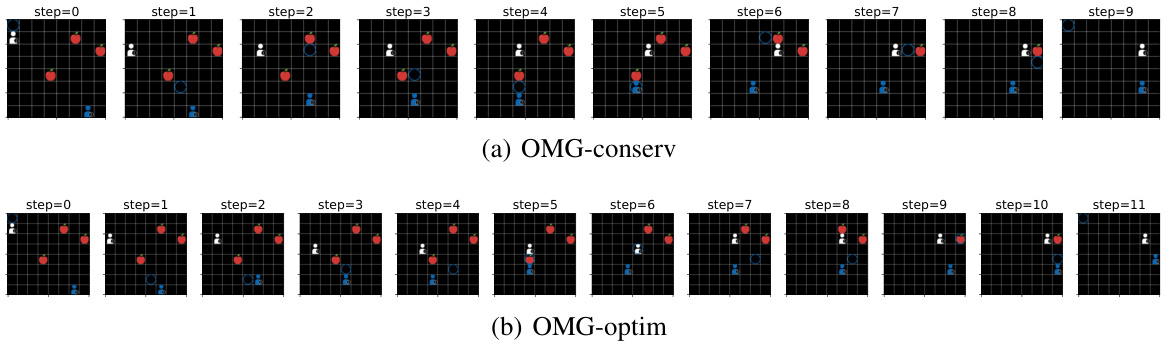
This figure analyzes the performance of the Opponent Modeling based on subgoal inference (OMG) method in the Foraging environment. Specifically, it shows the subgoal hit rate (the percentage of times the opponent actually visits the predicted subgoal state) for both the optimistic and conservative versions of the OMG algorithm. Additionally, it illustrates a sample trajectory for both versions to visually demonstrate how their different subgoal selection strategies influence the predicted path and overall performance.
More on tables

This table shows the win rates of QMIX and OMG-optim in the 8m map of the SMAC environment when facing different types of opponents: 7 non-homologue, 6 homologue, and 7 homologue. The results demonstrate that OMG-optim significantly outperforms QMIX, especially against non-homologous opponents (those trained with different algorithms).

This table shows the frequency distribution of subgoals selected from the set of future states NH = {st+k|1 ≤ k ≤ H}. The proportion indicates how frequently each state (st+1, st+2, st+3, st+4, st+5) was chosen as a subgoal across 100 trajectories. The data suggests a preference for selecting subgoals within the first few steps of the future trajectory.
Full paper#