↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Off-policy evaluation (OPE) in reinforcement learning is often hampered by unmeasured confounders, leading to biased policy value estimations. Existing methods frequently rely on restrictive assumptions, like the one-way unmeasured confounding assumption, which limits their applicability. These limitations motivate the need for more robust and flexible OPE methods that can handle complex real-world scenarios.
This paper proposes a novel two-way unmeasured confounding assumption, relaxing the limitations of the one-way assumption. A two-way deconfounder algorithm is developed, employing a neural tensor network to jointly learn unmeasured confounders and system dynamics. This approach yields a model-based estimator, providing consistent policy value estimation. The effectiveness is validated through theoretical analysis and numerical experiments, demonstrating superior performance to existing methods in various settings, particularly those with unmeasured confounders.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in causal reinforcement learning and off-policy evaluation because it directly addresses the limitations of existing methods when dealing with unmeasured confounders. Its introduction of the two-way unmeasured confounding assumption and the associated deconfounder algorithm provides a more flexible and realistic approach to handling this challenging problem. The theoretical results and empirical validation further enhance its significance and practical value, paving the way for more accurate and reliable policy evaluation in various real-world applications. The work also opens up new avenues for research on more sophisticated latent variable modeling and consistent policy value estimation.
Visual Insights#

This figure illustrates three different assumptions regarding unmeasured confounders in causal reinforcement learning: Unconstrained Unmeasured Confounding (UUC), One-way Unmeasured Confounding (OWUC), and Two-way Unmeasured Confounding (TWUC). Each panel shows a directed acyclic graph (DAG) representing the data generating process under a specific assumption. The nodes represent variables (observations, actions, rewards, and confounders), and the edges represent causal relationships. UUC assumes unrestricted unmeasured confounders, OWUC assumes time-invariant confounders, and TWUC assumes both trajectory-specific time-invariant and time-specific trajectory-invariant confounders, which is the assumption proposed in this paper.
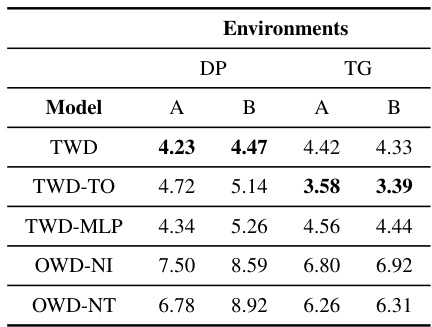
This table shows the LMSE of various estimators in different environments (simulated dynamic process and tumor growth example) and for different target policies (A and B). The models compared are the proposed Two-way Deconfounder (TWD) and its variants: TWD-TO (transition-only loss function), TWD-MLP (without neural tensor network), OWD-NI (One-way deconfounder without individual embedding), and OWD-NT (One-way deconfounder without time embedding). The results demonstrate the effectiveness of the neural tensor network and the two-way unmeasured confounding assumption in improving the accuracy of the off-policy value estimation.
In-depth insights#
Off-policy Eval#
Off-policy evaluation (OPE) in reinforcement learning presents a significant challenge due to the inherent difficulty of estimating the value of a target policy using data generated by a different behavior policy. The core issue stems from the presence of unmeasured confounders, variables that influence both the chosen actions and the observed outcomes. OPE methods often rely on assumptions like unconfoundedness, which are often violated in real-world scenarios. This necessitates advanced techniques to mitigate bias stemming from these unmeasured confounders. Model-based methods, such as the one proposed in this research, offer a powerful approach by learning the underlying system dynamics, which may include the impact of these hidden confounders. By learning this, a more accurate estimate of the target policy’s value can be produced. Key innovations in the proposed model include the introduction of a novel two-way unmeasured confounding assumption that relaxes restrictive assumptions, combined with the use of neural tensor networks for improved learning capabilities. However, challenges persist, including the potential for model misspecification and the need for sufficiently large datasets to effectively estimate the unmeasured confounders. The robustness and applicability of such models in complex settings remains an active research area.
Two-way Deconfounding#
The concept of “Two-way Deconfounding” tackles the challenge of unmeasured confounding in off-policy evaluation within causal reinforcement learning. Instead of assuming all confounders are either time-invariant or trajectory-invariant (as in one-way methods), this approach acknowledges the existence of both types. This nuanced perspective allows for more realistic modeling of complex real-world scenarios where confounders might vary across both time and trajectories. By utilizing a neural tensor network, the method aims to simultaneously learn both the time-invariant and trajectory-invariant confounders, disentangling their influences on actions and rewards. The resulting model then enables a more accurate estimation of policy value, reducing bias caused by unmeasured confounding. A key strength lies in the reduced dimensionality of the problem, as the number of confounders to estimate becomes significantly smaller than with an unconstrained model. However, the assumption itself needs to be carefully considered, its validity depending on the specific domain and application, and its effectiveness may be affected by the complexity of the relationships between confounders, actions, and rewards.
Neural Network Approach#
A neural network approach to off-policy evaluation (OPE) in reinforcement learning, particularly focusing on scenarios with unmeasured confounding, presents a promising avenue for accurate policy value estimation. The core idea involves using a neural network to learn both the system dynamics and the unmeasured confounders simultaneously. This approach moves beyond restrictive assumptions like unconfoundedness and allows for more realistic modeling of complex real-world settings. Key challenges include designing suitable network architectures (e.g., neural tensor networks) capable of capturing intricate interactions between observed variables and latent confounders, developing effective loss functions to balance learning objectives, and ensuring the model’s generalizability across various tasks and environments. Model-based estimators constructed from the learned neural network model can provide more robust OPE estimations, thereby reducing the impact of bias due to unmeasured confounding. Future research could explore more sophisticated network architectures, investigate alternative loss functions, and develop theoretical guarantees for the model’s consistency and accuracy.
OPE Estimator#
Off-policy evaluation (OPE) estimators are crucial for assessing the performance of a new policy without the need for online experimentation. A key challenge in OPE is the presence of unmeasured confounders, which bias standard estimators. The proposed two-way deconfounder addresses this by introducing a novel two-way unmeasured confounding assumption, effectively modeling confounders as both time-invariant and trajectory-invariant components. This approach enables learning of both the confounders and system dynamics simultaneously using a neural tensor network. The resultant model-based estimator offers enhanced accuracy and consistency compared to existing approaches. The theoretical guarantees and numerical results highlight the effectiveness of this innovative approach, offering a practical solution for accurate policy evaluation in challenging real-world scenarios where unmeasured confounders are prevalent. Further research could explore the algorithm’s robustness under variations of the two-way assumption and extend its applicability to more complex settings.
Future Work#
The ‘Future Work’ section of a research paper on causal reinforcement learning, focusing on off-policy evaluation with unmeasured confounders, could explore several promising directions. Extending the proposed two-way deconfounder to handle more complex scenarios with confounders that are both trajectory- and time-specific, or even policy-dependent, is crucial. Investigating the impact of model misspecification and proposing robust methods to handle such issues would significantly enhance the algorithm’s practical applicability. Developing efficient strategies for confounder selection is key because inappropriate selection can lead to biased estimators. Exploring different neural network architectures beyond the neural tensor network could improve performance, potentially through deeper or more sophisticated models for capturing complex interactions. Finally, empirical evaluation on a wider range of real-world datasets from diverse domains would strengthen the findings, demonstrating the algorithm’s generalizability and effectiveness in varied settings. Addressing these points will solidify the algorithm’s position as a robust and practical solution for off-policy evaluation in realistic reinforcement learning scenarios.
More visual insights#
More on figures

This figure shows the architecture of the proposed two-way deconfounder model and its performance in numerical experiments. (a) illustrates the model’s components: embedding vectors for trajectory-specific and time-specific latent confounders, a neural tensor network to capture interactions, transition and actor networks. (b) presents the mean squared error (MSE) of different methods under various unmeasured confounding assumptions for both data fitting and off-policy evaluation. The two-way deconfounder demonstrates the best performance for off-policy evaluation.
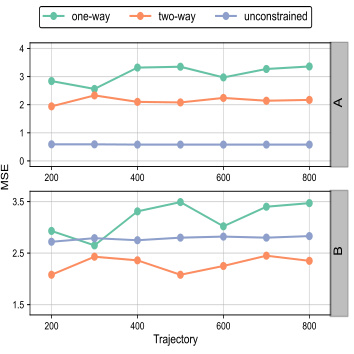
This figure shows the architecture of the proposed neural network and the comparison of mean squared errors (MSE) under different unmeasured confounding assumptions. The top panel compares MSE for fitting observed data, with the unconstrained model showing the lowest training error (overfitting). The bottom panel compares the MSE for off-policy value prediction, showing the two-way unmeasured confounding model achieves the lowest prediction error.

This figure compares the performance of different off-policy evaluation (OPE) estimators on two simulated datasets: a simple dynamic process and a tumor growth model. The logarithmic mean squared error (LMSE) and bias are shown for each estimator across different numbers of trajectories. The goal is to assess the accuracy and bias of these estimators in the presence of unmeasured confounding, under different assumptions on the nature of these confounders (one-way, two-way, or unconstrained). TWD is the proposed two-way deconfounder method.
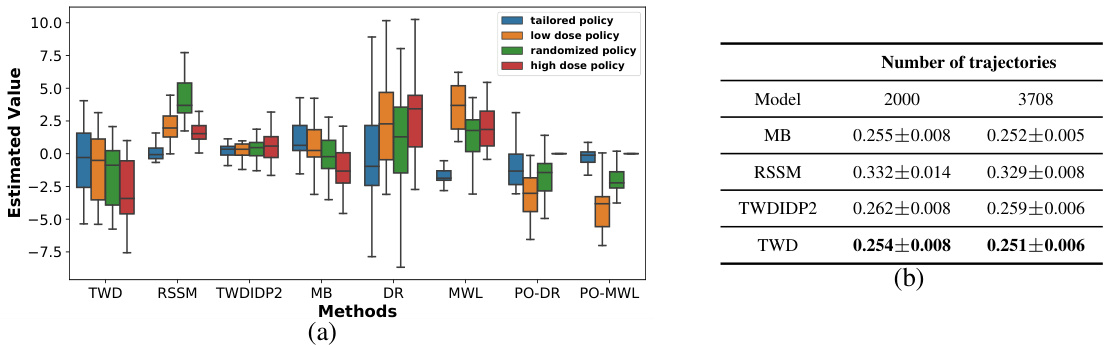
Figure 4 presents the results of applying various off-policy evaluation (OPE) methods on a real-world dataset, MIMIC-III. Panel (a) shows box plots comparing the estimated policy values for four different target policies (tailored, low dose, randomized, high dose) across multiple OPE methods. Panel (b) presents the average root mean squared error (RMSE) and standard error for each method’s predictions of immediate rewards and next observations, providing a quantitative comparison of their accuracy. The results highlight the relative performance of the proposed two-way deconfounder (TWD) against established baselines in a real-world medical setting.
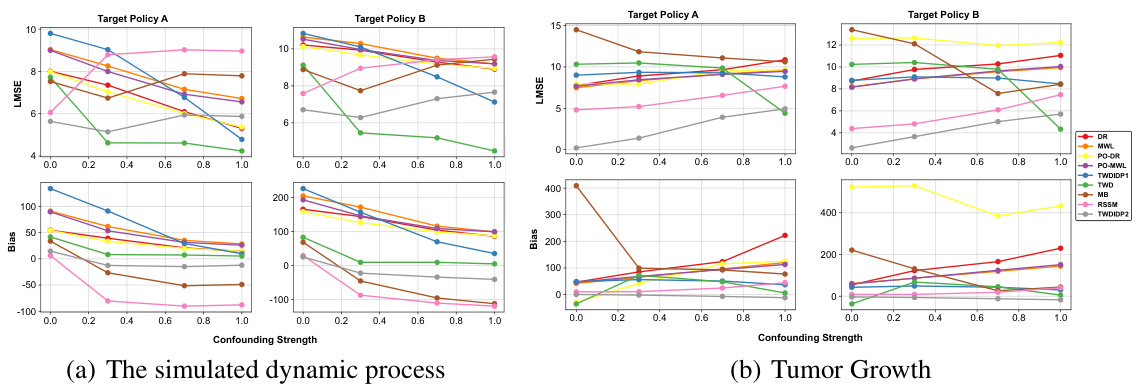
This figure presents the results of a comparative analysis between different off-policy evaluation (OPE) estimators applied to two simulated scenarios: a simulated dynamic process and a tumor growth model. The performance of various estimators, including the proposed Two-way Deconfounder, is evaluated using logarithmic mean squared error (LMSE) and bias. The results are displayed as line graphs to show the trend of each estimator’s performance across different confounding strengths. The figure is divided into two subfigures, one for each simulation scenario, each further divided into two panels illustrating LMSE and bias respectively for different target policies.
Full paper#



















