↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) struggle with long-context tasks. Existing strategies, like reducing input length or expanding context windows, have drawbacks: information loss or difficulty focusing on relevant information. This necessitates a new approach.
The proposed Chain-of-Agents (CoA) framework addresses this by using multiple worker agents to process segments of the long text sequentially, followed by a manager agent that synthesizes the results. This method mitigates the ’lost-in-the-middle’ problem and improves accuracy significantly across various tasks, outperforming existing techniques by up to 10%.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs on long-context tasks. It introduces a novel framework that significantly improves performance, addresses limitations of existing approaches like RAG and full-context methods, and opens new avenues for multi-agent LLM collaboration research. The findings challenge current assumptions about LLM limitations and offer a more efficient and effective approach to handling extensive inputs.
Visual Insights#
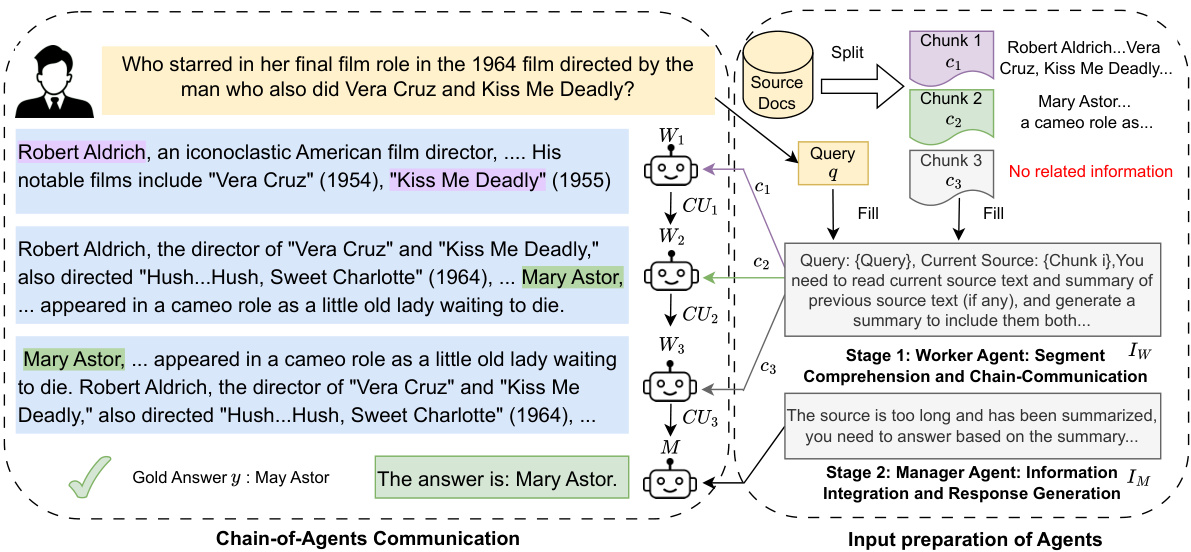
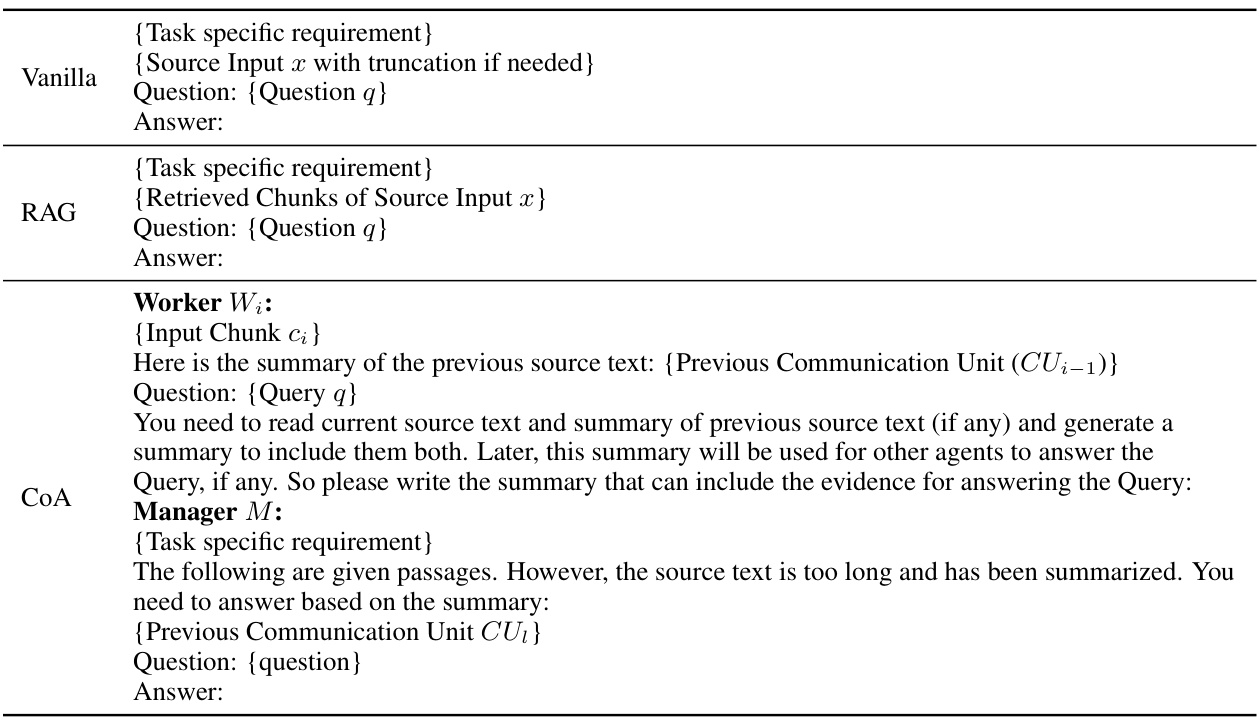
This figure illustrates the Chain-of-Agents (CoA) framework, which consists of two stages. In the first stage, multiple worker agents each process a segmented portion of a long input text. Each agent communicates its findings to the next agent in a sequential chain. The final worker agent passes its information to the manager agent. In the second stage, the manager agent synthesizes the information from all worker agents to produce a coherent final output. The figure highlights the communication units (CUi) between consecutive worker agents. This framework is designed to be training-free, task-agnostic, and highly interpretable.

This table compares Chain-of-Agents (CoA) with existing methods for handling long-context tasks. It contrasts approaches based on input reduction (truncation, RAG), window extension (position interpolation, long context models) and multi-agent LLMs. The comparison considers the ability to mitigate issues of focusing on the relevant portion of a long context, whether the method requires training, the amount of input text processed, agent type (single vs. multiple), task applicability (generic vs. query-based), and the level of interpretability.
In-depth insights#
Long-Context Agents#
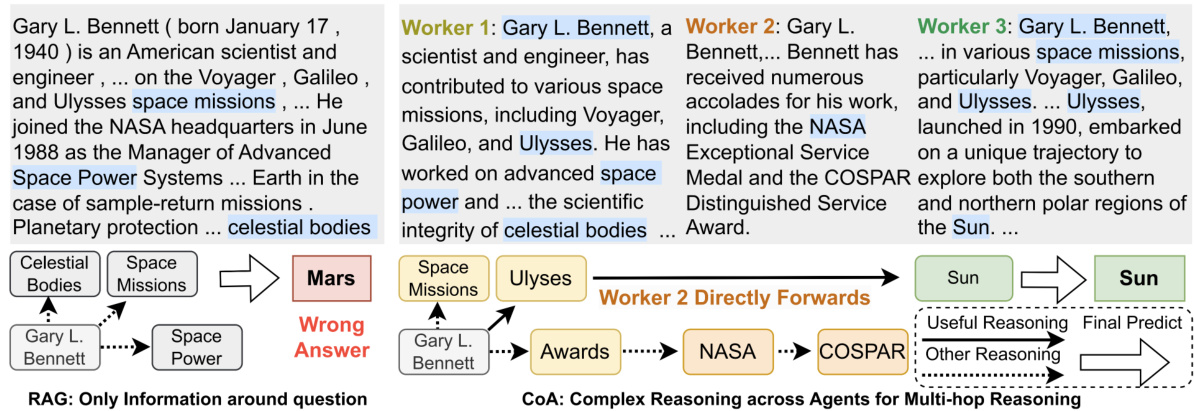
The concept of “Long-Context Agents” presents a compelling approach to enhance Large Language Model (LLM) capabilities. It addresses the limitations of current LLMs in handling extensive contextual information by decomposing complex tasks into smaller, manageable sub-tasks. Each sub-task is assigned to a specialized agent, allowing for focused processing and mitigating the “lost-in-the-middle” problem. The sequential communication between agents enables incremental knowledge aggregation and refined reasoning, producing a final output that synthesizes information from various parts of the long input. This approach shows potential for improving performance on a wide array of tasks involving long contexts such as question answering, summarization and code completion, as the distributed processing potentially improves efficiency over single-agent methods. However, challenges remain in optimizing agent communication and coordination, along with potential issues of scalability and cost for very extensive tasks. Further research is needed to fully explore the potential of this approach and to address these challenges. The interpretability of the agent chain offers significant advantages in debugging and understanding the model’s reasoning process.
Multi-Agent Collab#
Multi-agent collaboration in the context of large language models (LLMs) presents a novel approach to tackling complex tasks that exceed the capabilities of individual LLMs. This method leverages the strengths of multiple LLMs, each specializing in a particular aspect of the task, to achieve results beyond the scope of any single model. This approach offers several potential advantages, including enhanced efficiency by dividing the workload across multiple agents, improved performance by combining their individual strengths, and greater robustness as the failure of one agent does not necessarily compromise the entire process. However, effective multi-agent collaboration requires careful design of the communication protocols between agents and the overall system architecture. Efficient communication is crucial to ensure proper information flow and coordination amongst agents. Key considerations include choosing the appropriate communication methods and managing the complexity of inter-agent interactions. The design of individual agents is also critical, ensuring that each agent possesses the necessary skills and information to perform its assigned subtask. Finally, the evaluation of multi-agent systems needs to incorporate metrics assessing overall system performance as well as the individual contributions of each agent, acknowledging the inherent challenges in evaluating collaborative systems. Overall, while the full potential of multi-agent LLM collaboration is still being explored, it offers a promising avenue for building highly effective and robust AI systems.
CoA Framework#
The Chain-of-Agents (CoA) framework presents a novel approach to tackling long-context tasks by employing multi-agent collaboration among LLMs. Instead of relying on single-agent methods like RAG (Retrieval-Augmented Generation) which risk information loss due to input truncation, or full-context methods which struggle with maintaining focus on relevant information, CoA divides the long input into manageable chunks, each processed by a dedicated worker agent. These agents communicate sequentially, building upon previous results to aggregate information and perform reasoning. This interleaved reading and reasoning approach mitigates the ’lost-in-the-middle’ problem often seen with extended context windows. A final manager agent synthesizes the contributions from worker agents to produce a coherent output. The framework’s task-agnostic nature makes it adaptable to diverse applications, and its high interpretability aids in understanding the reasoning process. Its efficiency is further demonstrated by a comparison of its time complexity with that of full-context methods, highlighting its advantage in handling long inputs.
Interpretability#
The concept of interpretability in AI models is crucial, particularly within the context of complex systems like the Chain-of-Agents framework. Understanding the decision-making processes of each agent is vital to assess the overall system’s reliability and functionality. The framework’s design, leveraging sequential communication between agents, inherently promotes a level of interpretability, as the reasoning chain can be traced. Each agent’s output is a communication unit that forms part of a larger, understandable narrative. The modularity of the CoA architecture enhances interpretability by isolating each agent’s role and responsibilities within the broader context. This approach contrasts with monolithic models where the decision process is opaque. However, the limits of interpretability remain as the reasoning chain length grows. The need to synthesize information from multiple agents into a final, coherent output presents a challenge. While each agent’s contribution may be understandable, the manager agent’s synthesis process could introduce complexity, obscuring the overall reasoning process. Therefore, techniques to visualize and simplify the manager agent’s decision-making process are needed to ensure the framework’s effectiveness and transparent understanding.
Future of CoA#
The future of Chain-of-Agents (CoA) looks promising, with potential for significant advancements. Improved agent design could lead to more efficient communication and specialized reasoning, enabling CoA to tackle even more complex long-context tasks. Enhanced communication protocols beyond simple sequential messaging, such as incorporating negotiation or collaborative reasoning techniques, could improve the accuracy and efficiency of the agent interactions. Integration with other LLMs and AI tools would expand CoA’s capabilities, allowing for better retrieval, summarization, and inference. Addressing the limitations of individual LLMs, such as the ’lost-in-the-middle’ effect, will remain critical for further improving CoA’s performance. Finally, exploring more sophisticated agent architectures and learning mechanisms will be crucial for building more robust and adaptable CoA systems. Furthermore, research on the optimal number of agents and methods for dynamic task allocation could greatly enhance CoA’s versatility and scalability. The development of CoA is at the cutting edge of long-context understanding, and the future holds much potential for this collaborative approach to LLM-based reasoning.
More visual insights#
More on figures

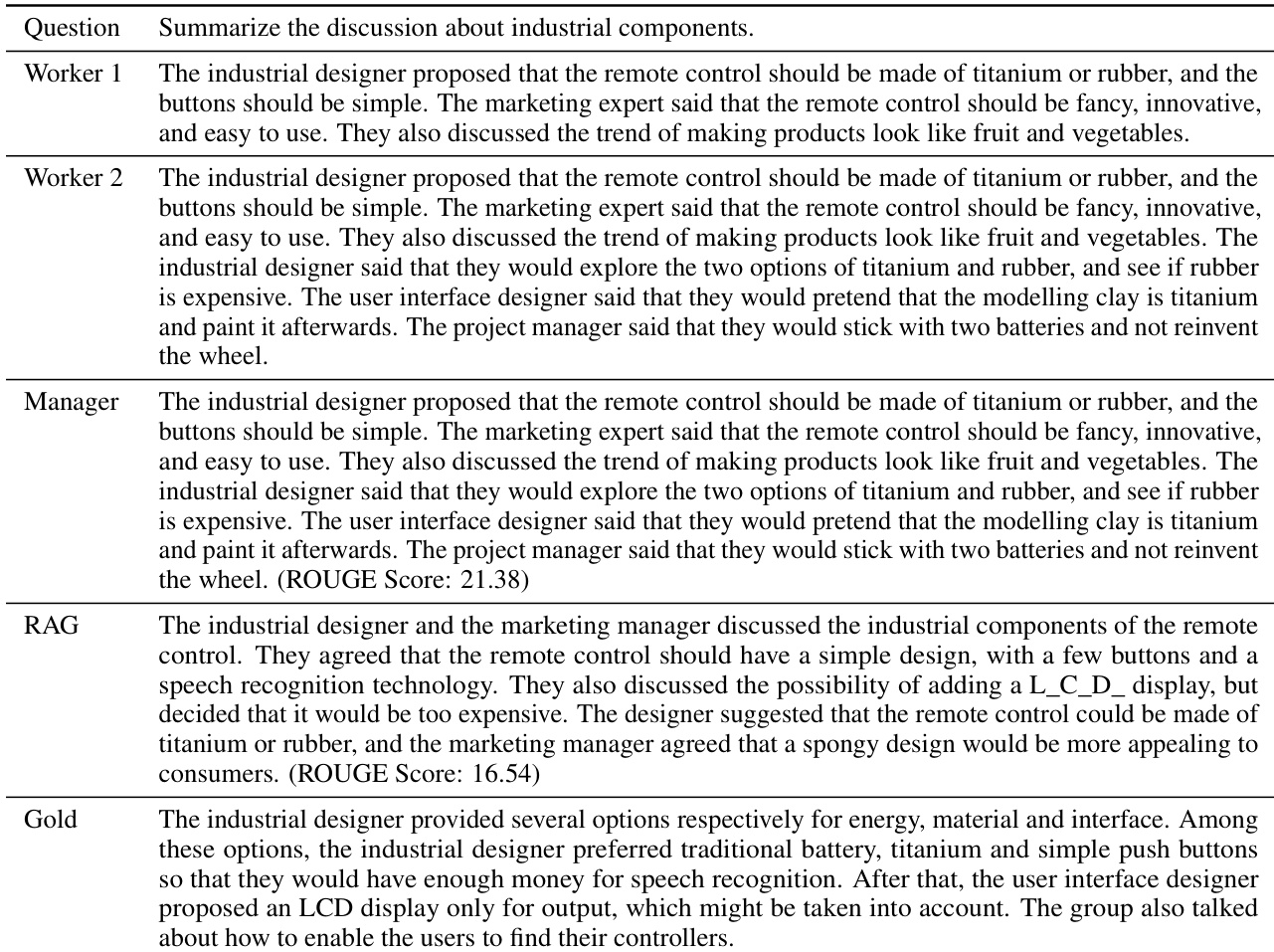
This figure shows the performance comparison between the full-context model (Full-200k) and the Chain-of-Agents model (CoA-8k) on the BookSum dataset. The x-axis represents the number of tokens in the source input, grouped into bins (0-80k, 80-160k, etc.). The y-axis represents the average ROUGE score, a metric for evaluating summarization quality. The figure demonstrates that CoA consistently outperforms the full-context approach across all input lengths, and that the performance difference between the two methods is more pronounced as the input length increases, indicating that CoA is particularly effective for handling very long inputs.
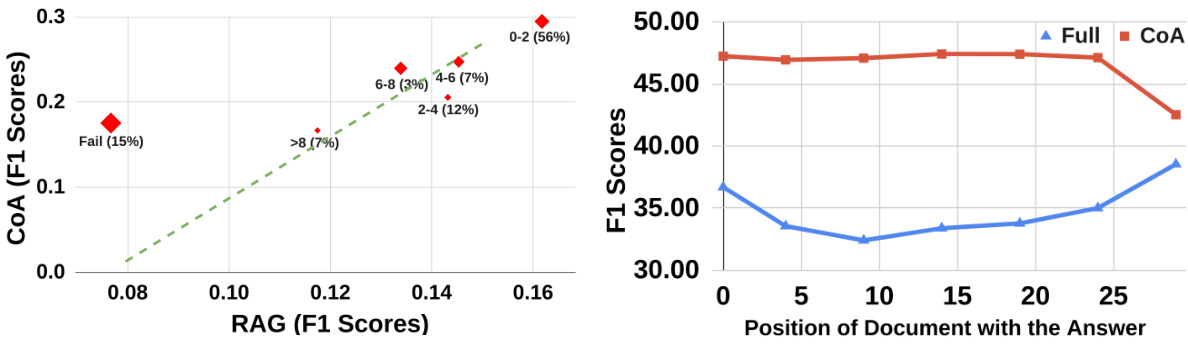
This figure shows a comparison of the performance of RAG and CoA on the NarrativeQA dataset. The x-axis represents the F1 score achieved by RAG, while the y-axis represents the F1 score achieved by CoA. Each point on the graph represents a bin of samples, categorized by the position of the chunk containing the gold answer within the RAG input. The number near each point indicates the bin’s index and the percentage of samples in that bin. The size of each point visually represents the performance improvement of CoA over RAG for that bin. The dashed line indicates the trend line, showing the general improvement of CoA over RAG.
This figure illustrates the Chain-of-Agents (CoA) framework. CoA consists of two stages: 1) Worker agents that sequentially process segmented parts of a long input text and communicate their findings to the next agent in the chain, and 2) A manager agent that synthesizes information from all worker agents to produce a final output. Each communication between worker agents is a ‘communication unit’ (CU). The framework addresses the challenge of LLMs struggling with long contexts by breaking down the task into smaller, manageable segments.
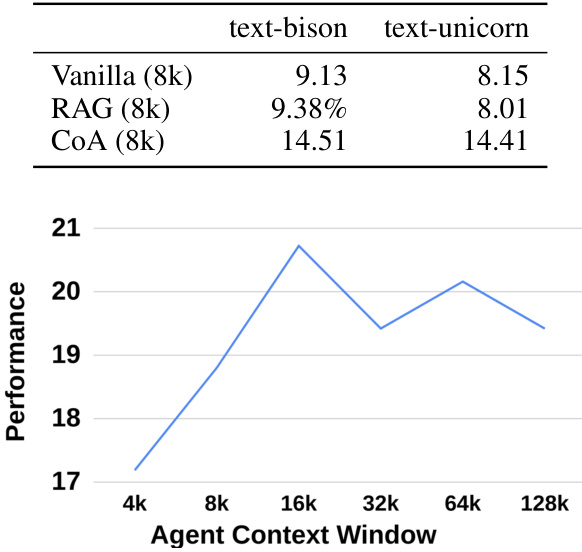
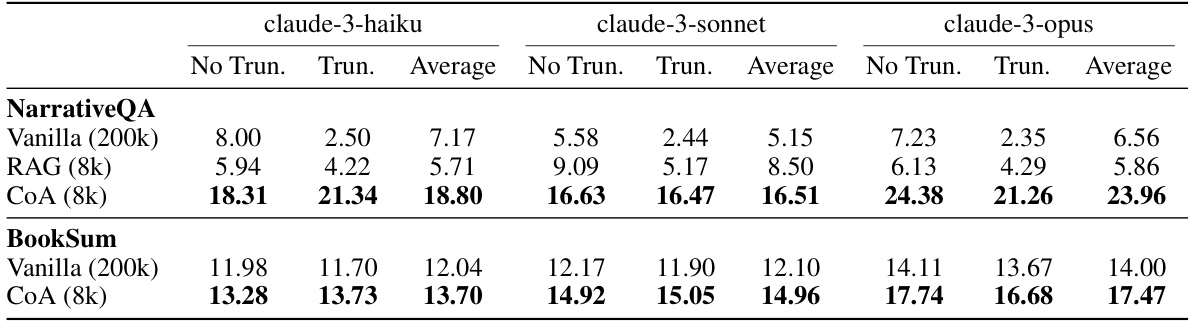
This figure demonstrates the performance of the Chain-of-Agents (CoA) model using the Claude 3 Haiku model on the NarrativeQA dataset. The x-axis shows different context window sizes used for each agent within the CoA framework, and the y-axis displays the corresponding performance. The graph shows that the CoA model achieves its best performance with a 16k context window size for the agents, demonstrating the model’s robustness to variations in agent context window size. The performance remains relatively stable even as the context window size increases beyond the optimal value. This suggests that CoA is relatively insensitive to the specific choice of context window size within a reasonable range.
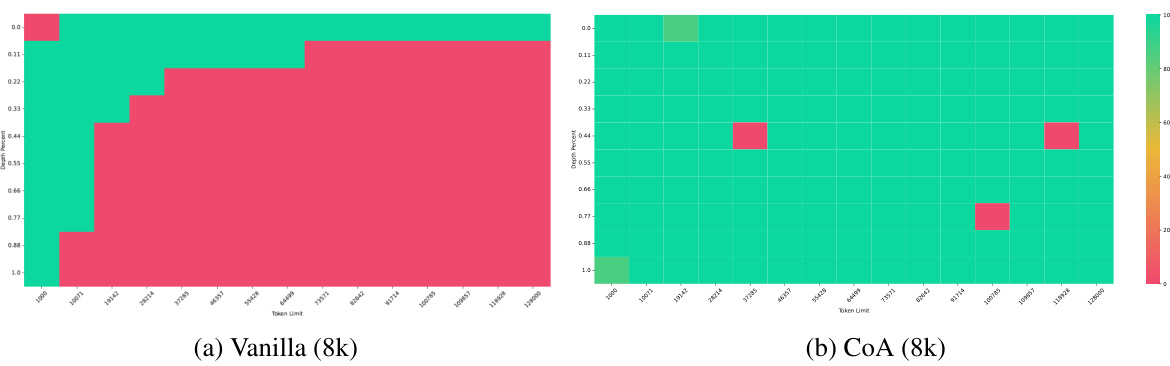
This figure compares the performance of the Vanilla model and the CoA model on the NIAH PLUS test. The heatmap visualization shows that the CoA model (with an 8k context window) significantly outperforms the Vanilla model, achieving much higher accuracy scores across a range of input lengths. The greener cells represent higher accuracy while redder cells represent lower accuracy, illustrating CoA’s effectiveness in long context understanding tasks.
More on tables

This table compares Chain-of-Agents (CoA) with existing methods for handling long-context tasks. It contrasts approaches based on input reduction (truncation and RAG) and window extension, highlighting CoA’s unique ability to mitigate issues related to receptive field and context focus while maintaining high interpretability and training-free nature.

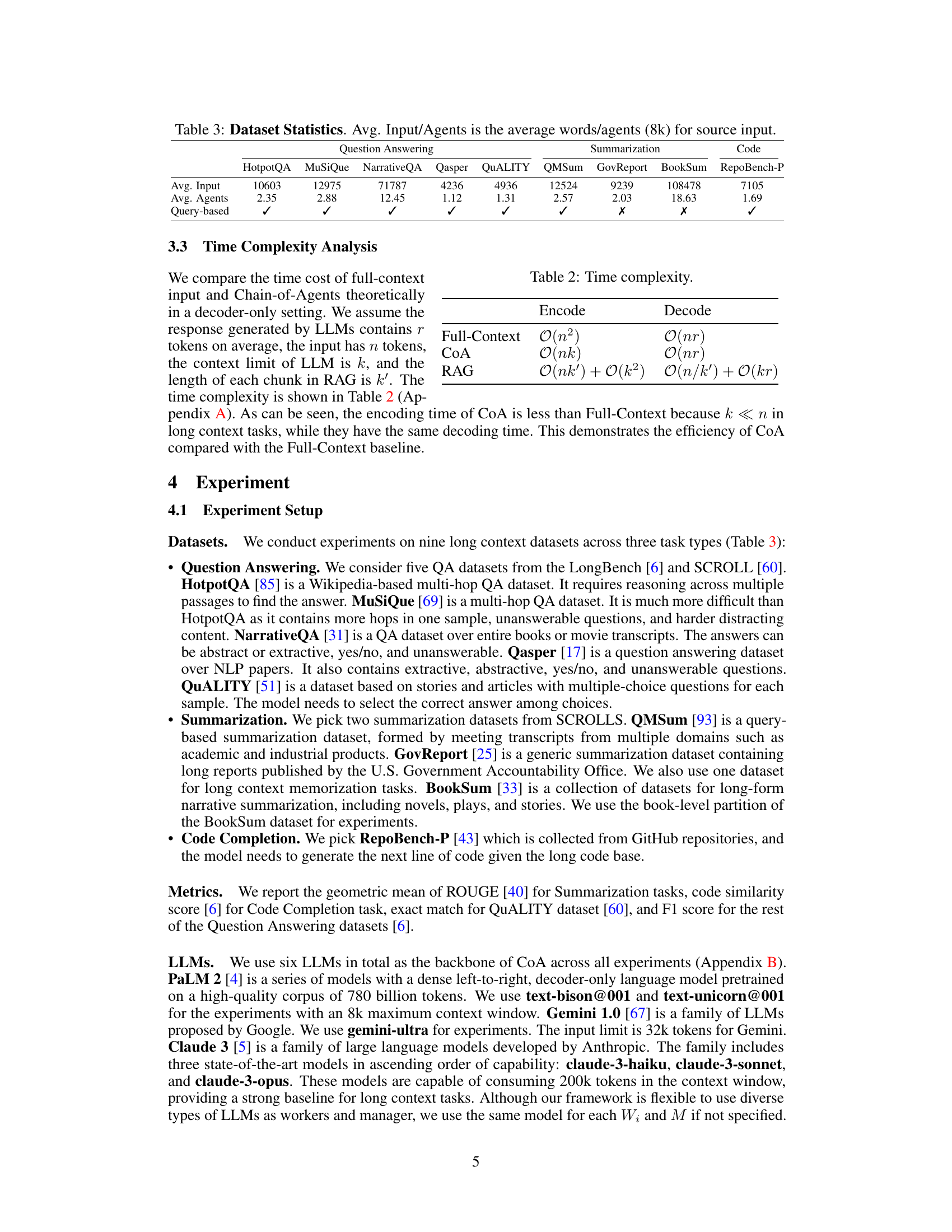
This table presents statistics for nine datasets used in the experiments, categorized into question answering, summarization, and code completion tasks. For each dataset, it shows the average input length in words, the average number of agents used in the Chain-of-Agents framework, and whether the task is query-based or not. The average input length is given in words, and the average number of agents represents how many agents were used on average to process the input for each dataset using an 8k word limit per agent. Query-based indicates whether the task requires a specific query to guide the processing of the input text.

This table compares the time complexity of three different methods for handling long-context tasks: Full-Context, CoA (Chain-of-Agents), and RAG (Retrieval-Augmented Generation). The time complexity is broken down into encoding and decoding phases. The notation used shows that Full-Context has a quadratic time complexity for encoding (O(n²)), while CoA and RAG show linear time complexity in terms of n, the input length, but with different dependencies on the context window size (k for CoA, k’ for RAG). Decoding time complexity for all three methods is linear (O(nr)), indicating a dependence on the response length (r).
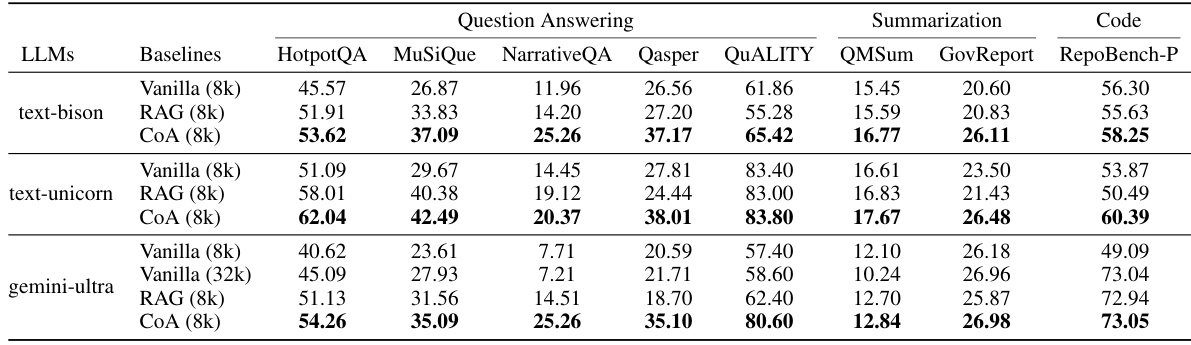
This table presents the performance comparison of the proposed Chain-of-Agents (CoA) framework against two baseline methods: Vanilla (Full-Context) and RAG (Retrieval-Augmented Generation) across nine different datasets encompassing three task types: Question Answering, Summarization, and Code Completion. The results are shown for six different Large Language Models (LLMs) as backbones for each method. The table highlights CoA’s significant performance improvements over the baselines in all datasets and across all LLMs.
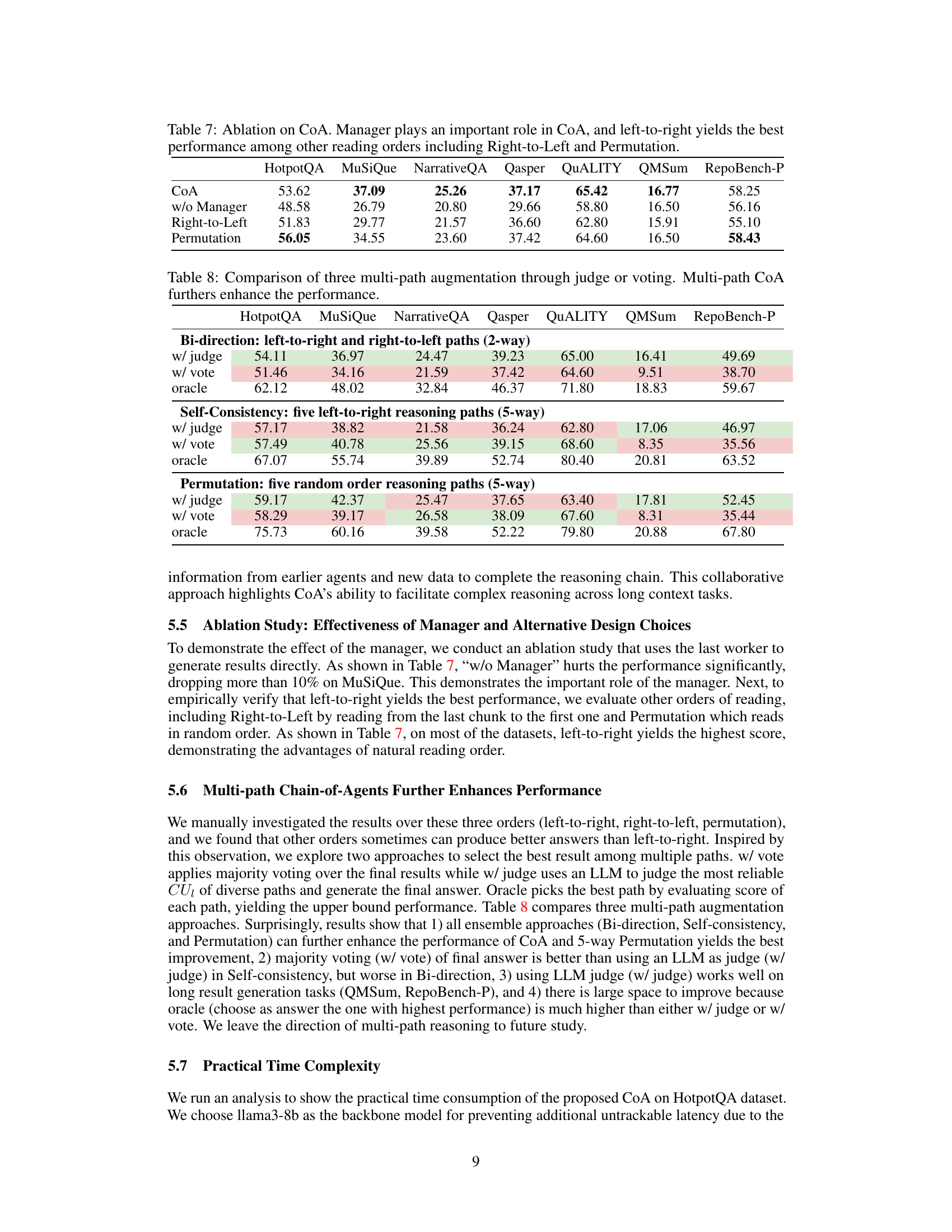
This table compares the performance of Chain-of-Agents (CoA) against two other multi-agent approaches: Merge and Hierarchical. The comparison is made across eight different datasets, focusing on the performance of each method using various Language Models (LLMs) as the backbone. The results demonstrate that CoA, with its sequential agent communication, outperforms the parallel approaches of Merge and Hierarchical, highlighting the effectiveness of CoA’s unique communication strategy for long context tasks.

This table presents the overall performance comparison of the proposed Chain-of-Agents (CoA) framework against two strong baseline methods: Vanilla (Full-Context) and RAG (Retrieval-Augmented Generation), across nine different datasets encompassing three types of tasks: Question Answering, Summarization, and Code Completion. The results are shown for six different large language models (LLMs) as backbones, demonstrating the consistent superior performance of CoA across various LLMs and tasks.

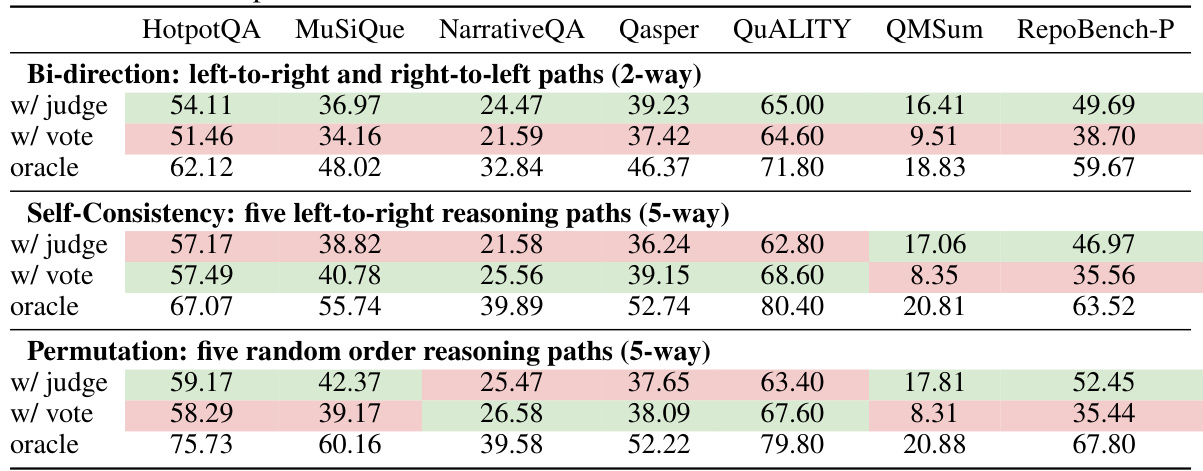
This table presents the ablation study results on the Chain-of-Agents (CoA) framework. It shows the impact of removing the manager agent, and it compares the performance of three different reading orders: left-to-right, right-to-left, and permutation. The results demonstrate the importance of the manager agent in the CoA framework and the effectiveness of a left-to-right reading order.
This table compares the performance of Chain-of-Agents (CoA) against two other multi-agent approaches: Merge and Hierarchical. The comparison is made across nine datasets, focusing on the performance of each method on various question answering, summarization, and code completion tasks. CoA consistently outperforms both other methods, highlighting the effectiveness of its sequential communication structure compared to parallel strategies.

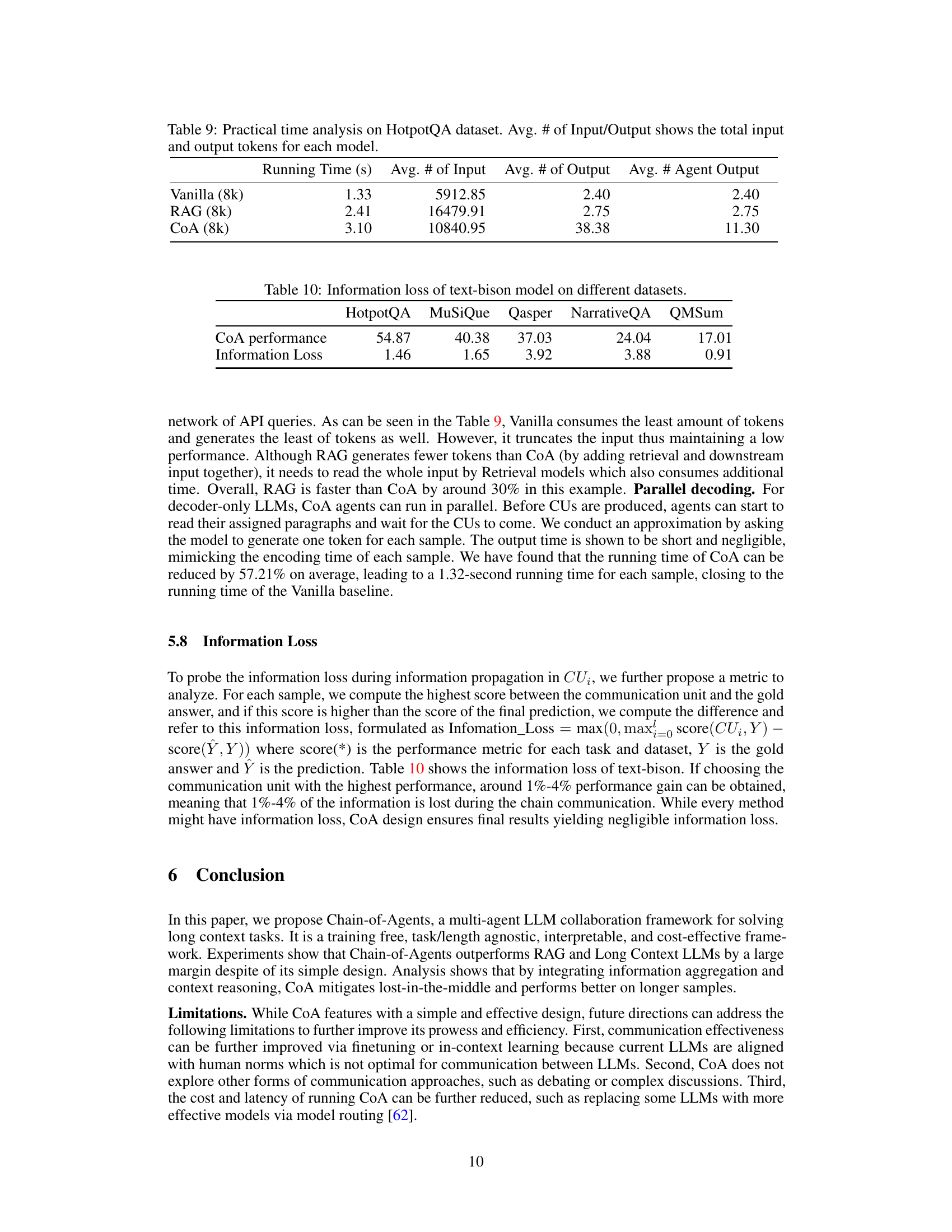
This table shows the average running time, the average number of input tokens, the average number of output tokens, and the average number of agent outputs for three different models: Vanilla (8k), RAG (8k), and CoA (8k) on the HotpotQA dataset. It demonstrates the time efficiency and token usage of each model, highlighting the trade-offs between model complexity and performance.

This table presents the performance of the Chain-of-Agents (CoA) framework using the text-bison model on five different datasets and the corresponding information loss during the communication process between agents. The information loss metric quantifies the difference between the highest score achieved by any communication unit (CUi) and the final prediction score against the gold standard, indicating the amount of information lost during the sequential communication among the agents.
This table compares Chain-of-Agents (CoA) with existing methods for handling long-context tasks. It contrasts different approaches based on their ability to manage receptive field issues (Rec./Foc.), the amount of input tokens processed (Read), whether they require training (No Train), the type of agent used (Single/Multiple), the method’s general applicability (Applicability), and the method’s interpretability (Inter.). The table highlights CoA’s advantages in mitigating issues related to both receptive field and focusing, and its ability to process the entire input with multiple agents while maintaining high interpretability.

This table compares Chain-of-Agents (CoA) with existing methods for handling long-context tasks. It contrasts approaches based on input reduction (truncation and RAG) and window extension, highlighting CoA’s ability to mitigate issues with receptive field and context focus. The table also shows the number of tokens processed by each approach, its trainability, the type of agent (single or multiple), its applicability, and its interpretability.

This table compares the performance of Chain-of-Agents (CoA) with the best results reported in previous studies across nine different datasets. The datasets cover question answering, summarization, and code completion tasks. The table shows that CoA achieves either better or comparable performance compared to previous state-of-the-art methods, with notable improvements in some categories. The asterisk (*) indicates that certain prior results required further model training, while CoA is a training-free method.
This table presents the statistics of nine datasets used in the experiments, categorized into three task types: Question Answering, Summarization, and Code Completion. For each dataset, it lists the average input length (in words), the average number of agents used (considering an 8k word limit per agent), and an indicator specifying whether the dataset is query-based or not. The table provides context on the scale and nature of the datasets used to evaluate the Chain-of-Agents (CoA) framework.

This table compares the performance of Chain-of-Agents (CoA) against the best previously reported results on nine different datasets, encompassing question answering, summarization, and code completion tasks. It highlights CoA’s performance relative to existing state-of-the-art models, indicating whether those models required further training to achieve their reported scores. The table provides a quantitative assessment of CoA’s effectiveness across various long-context tasks.

This table compares the performance of Chain-of-Agents (CoA) with the best results reported in previous studies on nine different datasets. Each dataset represents a different task (question answering, summarization, and code completion). The numbers represent the performance scores achieved, indicating that CoA either matches or surpasses the state-of-the-art in most cases. The asterisk (*) denotes that a model required further training to achieve the reported score.

This table presents a comparison of the performance of the vanilla model and the proposed Chain-of-Agents (CoA) model on the BookSum dataset. The performance is measured using different context window sizes (4k, 8k, 16k, and 32k tokens) for the text-bison-32k model. The table shows that CoA consistently outperforms the vanilla model across all context window sizes. The improvement is most significant at 8k and 16k context windows.

This table compares Chain-of-Agents (CoA) with existing methods for handling long-context tasks. It contrasts different approaches based on three criteria: whether they address issues of focusing on relevant information within long contexts, whether they require training, and the number of tokens the model processes (Read). The interpretability of each method is also assessed.

This table compares Chain-of-Agents (CoA) with existing methods for handling long-context tasks. It contrasts approaches based on input reduction (truncation and RAG) and window extension. The comparison focuses on the ability to address inaccurate receptive fields, the number of tokens processed, whether the method requires training, the applicability of the method to different task types, and the interpretability of the method.
Full paper#