↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but suffer from inherent biases that lead to unpredictable outputs and sensitivity to input design. Previous works mainly addressed this through external modifications, ignoring the internal mechanisms causing this issue. This hinders the reliability and adaptability of LLMs in various applications.
The paper introduces UniBias, a novel method that directly tackles internal LLM bias by identifying and neutralizing biased components within the model’s architecture, specifically in the feedforward neural networks and attention mechanisms. Through experiments, UniBias significantly enhances the performance and robustness of in-context learning, outperforming existing debiasing techniques. This internal approach offers a new direction for addressing LLM bias, paving the way for more reliable and robust language models.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to mitigating LLM bias by directly manipulating internal LLM components. This is significant because existing methods typically focus on external adjustments, leaving the internal mechanisms poorly understood. The findings could potentially improve the robustness and reliability of LLMs across various applications. The research also opens new avenues for investigating bias in LLMs, paving the way for more effective bias mitigation strategies.
Visual Insights#
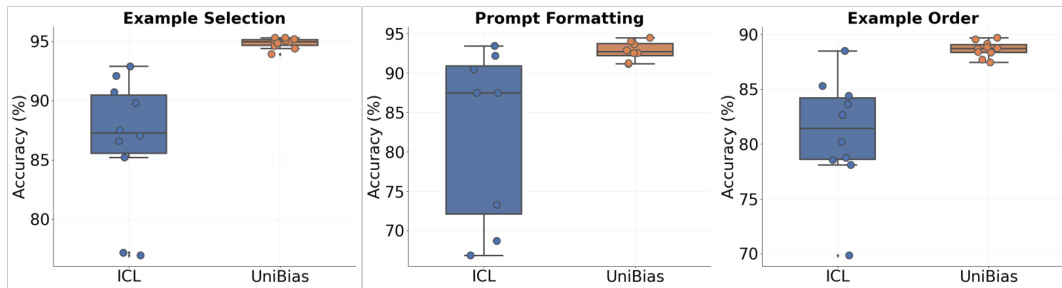
The figure shows the impact of prompt brittleness on the accuracy of In-context Learning (ICL) and how the proposed UniBias method improves the robustness of ICL across different design settings (example selection, prompt formatting, and example order). The box plots visually represent the accuracy distributions for both ICL and UniBias under various conditions, showcasing UniBias’s improved performance and reduced sensitivity to prompt variations. The datasets used are SST2 for example selection and prompt formatting, and AGNews for example order.
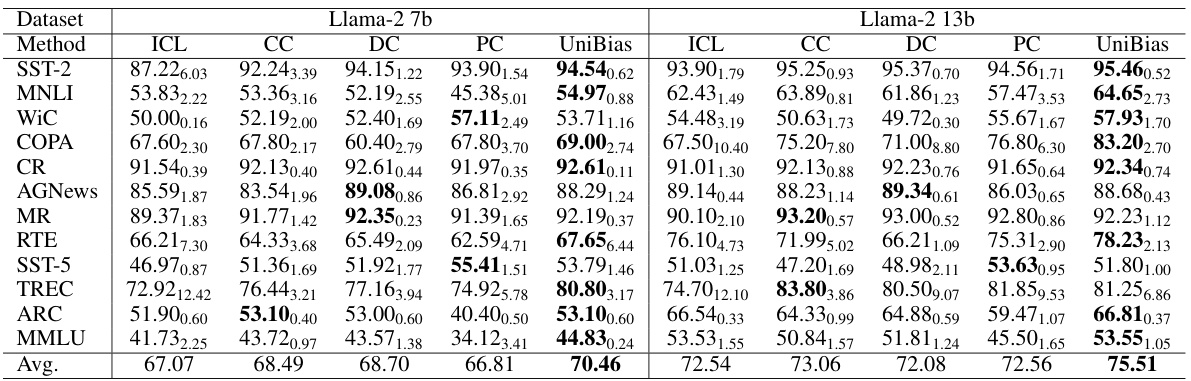
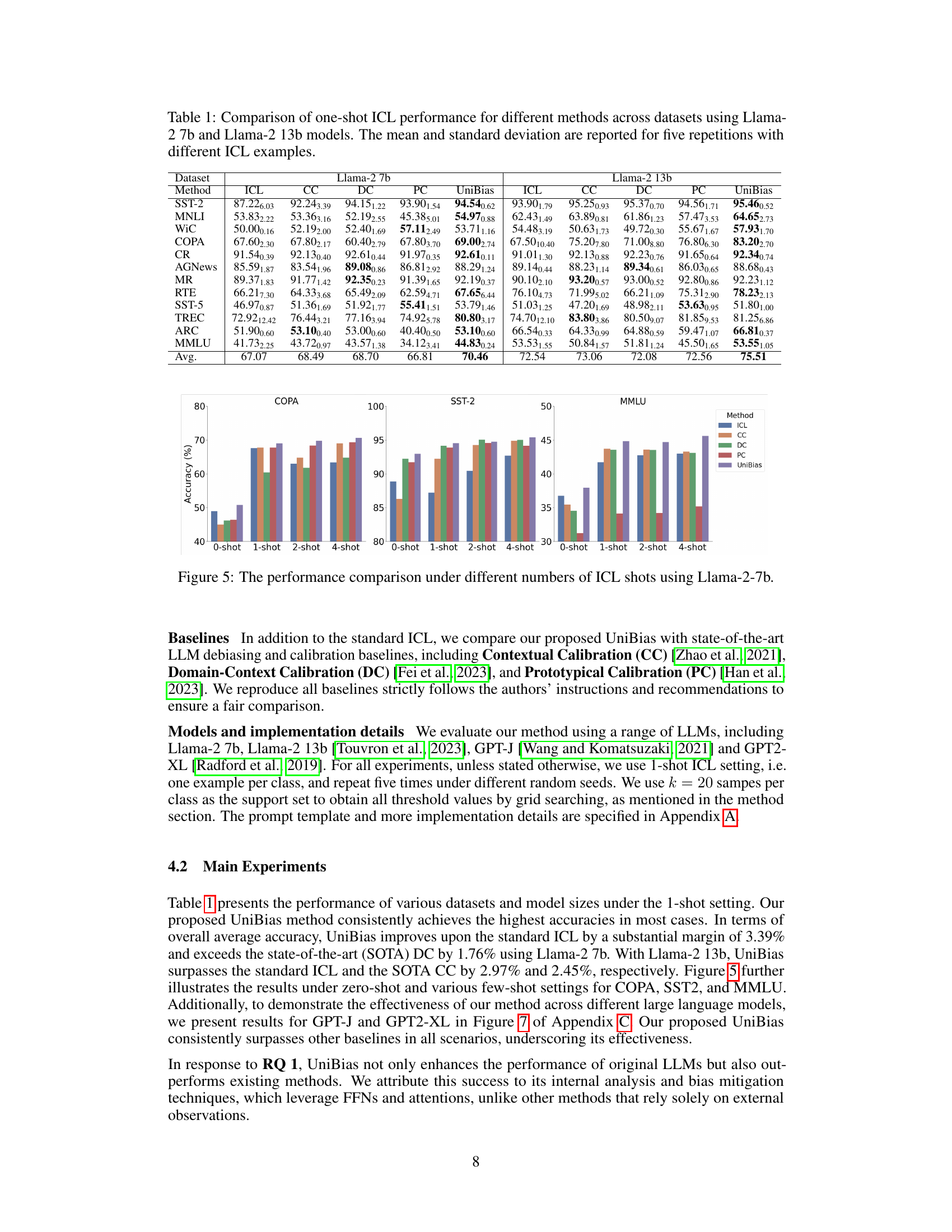
This table presents a comparison of the performance of different methods for one-shot in-context learning (ICL) across twelve different datasets, using two different sized language models (Llama-2 7b and Llama-2 13b). The performance metric is accuracy, and the results are averaged over five repetitions with different ICL examples to provide a measure of variability. The methods compared include standard ICL, Contextual Calibration (CC), Domain-Context Calibration (DC), Prototypical Calibration (PC), and the proposed UniBias method.
In-depth insights#
LLM Bias Unveiling#
LLM bias unveiling involves a multifaceted investigation into the root causes of biases within large language models. Mechanistic interpretability plays a crucial role, examining the contributions of individual components, specifically feedforward neural networks (FFNs) and attention heads, to understand how these elements influence model predictions. By analyzing FFN vectors and attention heads, researchers can pinpoint those contributing to biased outcomes. This involves techniques like projecting these components into the vocabulary space to assess their impact on label predictions. Identifying biased components, such as FFN vectors consistently favoring certain labels or attention heads prioritizing specific examples, is key. The unveiled biases may manifest as vanilla label bias, recency bias, or selection bias. This understanding is essential for developing effective mitigation strategies.
Internal Attention#
The concept of “Internal Attention” in the context of a research paper likely refers to the investigation of attention mechanisms within a neural network model, specifically focusing on how these mechanisms contribute to the model’s overall behavior. This would involve analyzing the internal workings of the attention layers, examining how the model weights different parts of the input data, and potentially exploring techniques to modify or interpret these attention patterns. A deep dive into internal attention might involve visualizations of attention weights, showing which parts of the input the model deemed most relevant at each layer. The research could also probe whether biases or limitations in the attention mechanism are contributing to errors, suboptimal performance, or other undesirable aspects of the model’s output. Understanding internal attention is crucial for improving model transparency and interpretability, allowing researchers to identify and potentially correct flaws, which would result in a more robust and reliable system.
FFN Manipulation#
The concept of “FFN Manipulation” in the context of a research paper likely refers to techniques aimed at modifying the behavior of feedforward neural networks (FFNs) within large language models (LLMs). The core idea revolves around identifying and altering specific FFN components to mitigate biases that might skew the LLM’s output. This might involve analyzing the contribution of individual FFN vectors to understand how they influence the model’s predictions. Then, techniques such as masking or adjusting weights of biased FFN vectors are employed to correct skewed predictions. This approach contrasts with methods focusing solely on external adjustments of LLM outputs, offering a novel way to tackle bias at a more fundamental level within the model itself. The success of such manipulation hinges on the ability to accurately pinpoint the specific FFN components responsible for undesirable biases and then subtly alter their influence without substantially impairing the overall functionality of the LLM. This targeted approach promises higher effectiveness and potentially more robustness compared to solely relying on post-processing techniques. The effectiveness would likely be further evaluated through empirical experiments demonstrating improved performance on various NLP benchmarks and reduced sensitivity to different prompt designs.
UniBias Method#
The UniBias method proposes a novel approach to mitigate LLM bias by directly manipulating internal model components. Instead of relying on external adjustments of model outputs, UniBias focuses on identifying and eliminating biased Feedforward Neural Networks (FFNs) and attention heads within the LLM. This is achieved through an inference-only process that analyzes the contribution of individual FFN vectors and attention heads to label predictions, utilizing criteria such as relatedness, bias, and variance. By effectively identifying and masking these biased components, UniBias enhances the robustness of In-Context Learning (ICL) and significantly improves performance across various NLP tasks, alleviating the issue of prompt brittleness. The method’s effectiveness is demonstrated across multiple datasets and LLMs, showcasing its potential for creating more reliable and less biased language models. A key strength lies in its ability to directly address the internal mechanisms that cause bias, offering a new direction for LLM bias mitigation.
Future Directions#
Future research should prioritize refining UniBias’s efficiency by reducing reliance on grid search and potentially developing methods to identify globally biased components applicable across diverse tasks. Investigating the interaction between biased components and prompt engineering techniques to optimize prompt design for mitigating bias is crucial. Further exploration into the application of UniBias to other LLMs and architectural variations is needed to determine its generalizability. A deeper dive into the causal relationships between specific internal components (FFNs, attention heads) and various bias phenomena (vanilla label bias, recency bias, etc.) would enhance our understanding of LLM bias mechanisms. Finally, researching potential ethical implications of manipulating internal LLM structures, and developing safety mechanisms to prevent misuse, is paramount.
More visual insights#
More on figures

This figure shows the accumulated uncontextual FFN logits for different label names in a sentiment analysis task, along with their corresponding zero-shot prediction frequencies on the SST-2 dataset. It demonstrates how the uncontextual accumulated FFN logits, reflecting the inherent bias of the LLM toward predicting certain label names without input context, correlate with prediction frequencies. Labels with higher accumulated logits tend to have higher prediction frequencies.

This figure shows the internal mechanism of recency bias in LLMs. It compares the behavior of a biased attention head (layer 16, head 29) and an unbiased attention head (layer 16, head 19) in terms of the attention weights assigned to examples at different positions and the label logits of the corresponding attention head’s output. The biased attention head consistently assigns larger weights to the last example regardless of its label, demonstrating the recency bias. In contrast, the unbiased attention head assigns similar weights to both examples.

This figure shows the internal mechanism of selection bias in LLMs. The leftmost subplot displays the accumulated FFN label logits, revealing an inherent bias favoring option A. The middle and rightmost subplots illustrate the attention weights assigned by a biased attention head (layer 24, head 29) to different option positions, both in the original and reversed option sequences. The biased attention head consistently assigns higher weights to the first option, regardless of the ground truth label, thus revealing the positional bias which contributes to the selection bias.

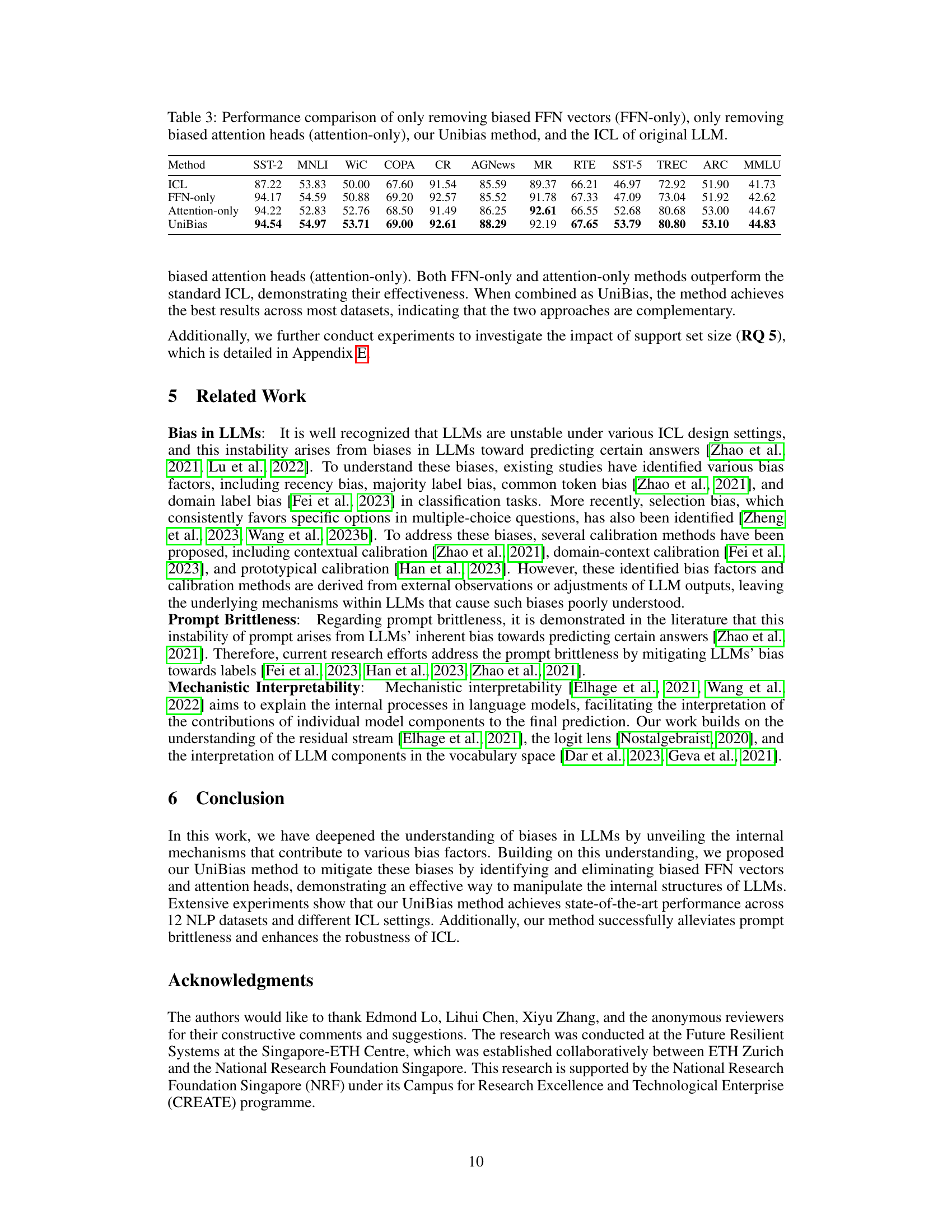
This figure compares the performance of different methods (ICL, CC, DC, PC, and UniBias) on three datasets (COPA, SST-2, and MMLU) under varying numbers of in-context learning (ICL) shots (0-shot, 1-shot, 2-shot, and 4-shot). It visually demonstrates the effectiveness of the UniBias method in improving the accuracy and robustness of ICL across different shot settings and datasets. The results show that UniBias consistently outperforms other methods across all datasets and shot settings, highlighting its effectiveness in mitigating LLM bias.

This figure compares the performance of the UniBias method against several baseline methods (ICL, CC, DC, and PC) across six different datasets (SST-2, WiC, COPA, MR, RTE, and the average performance across all datasets) using two different language models: GPT-J and GPT2-XL. It shows the accuracy achieved by each method on each dataset, providing a visual representation of the relative effectiveness of UniBias compared to the baselines. The results clearly demonstrate UniBias’ superiority over other methods across most datasets and language models.
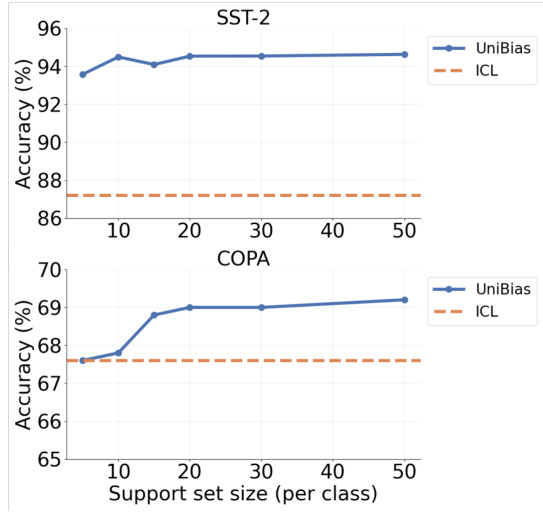
This figure shows the impact of support set size on the performance of the UniBias method. Two datasets, SST-2 and COPA, are used for evaluation. The x-axis represents the support set size (number of samples per class), and the y-axis represents the accuracy. The results indicate that performance generally improves with larger support sets but stabilizes beyond a certain point (around 20-30 samples per class). In both datasets, UniBias consistently outperforms the standard ICL (In-context learning) method across all support set sizes.
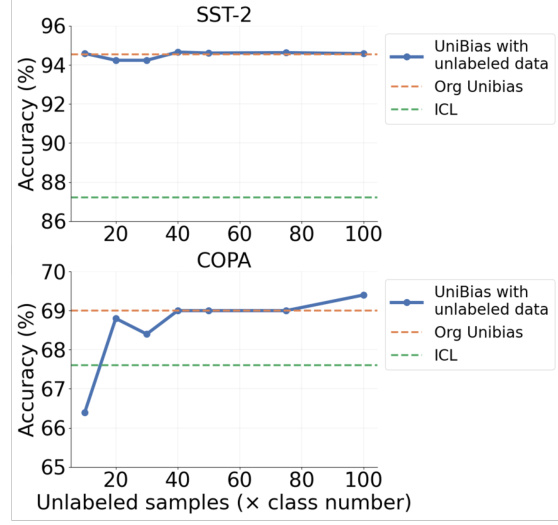
This figure shows the performance comparison of the UniBias method using unlabeled samples for the support set against the standard ICL and the original UniBias method. The x-axis represents the number of unlabeled samples multiplied by the number of classes, while the y-axis shows the accuracy. Two datasets, SST-2 and COPA, are included. The results suggest that using unlabeled samples in UniBias achieves similar performance compared to using labeled samples, which is beneficial when labeled data is scarce.
More on tables

This table presents a comparison of the performance of different methods on various NLP tasks using two different sizes of the Llama-2 language model. The methods compared are standard In-Context Learning (ICL), Contextual Calibration (CC), Domain-Context Calibration (DC), Prototypical Calibration (PC), and the proposed UniBias method. The performance is measured as accuracy, with mean and standard deviation calculated over five repetitions using different example sets for each task.

This table presents a comparison of the performance of different methods on twelve datasets using two different Llama models (7B and 13B parameters). The methods compared are the standard In-context Learning (ICL), Contextual Calibration (CC), Domain-Context Calibration (DC), Prototypical Calibration (PC), and the proposed UniBias method. The table shows the mean and standard deviation of accuracy across five repetitions, each with different in-context learning examples. This allows for an assessment of the robustness and effectiveness of each method across various datasets and model sizes.
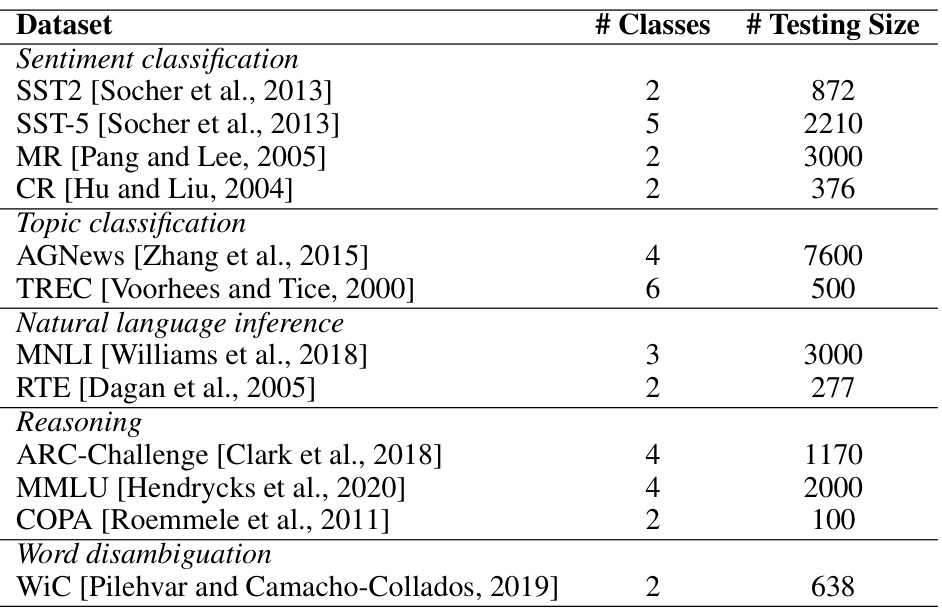
This table lists the twelve datasets used in the UniBias experiments, categorized by task (sentiment classification, topic classification, natural language inference, reasoning, and word disambiguation). For each dataset, the number of classes and the size of the test set are provided. The datasets represent a diverse range of natural language processing tasks and are used to demonstrate the effectiveness of UniBias across various scenarios.
This table presents a comparison of the performance of different methods on twelve datasets using two different Llama models. The performance metric is one-shot in-context learning (ICL) accuracy. The methods compared are standard ICL, Contextual Calibration (CC), Domain-Context Calibration (DC), Prototypical Calibration (PC), and the proposed UniBias method. Results are averaged over five runs with different example sets and show the mean and standard deviation of the accuracy for each method on each dataset.

This table presents a comparison of the performance of different methods (ICL, CC, DC, PC, UniBias) on 12 different NLP datasets using two different Llama language models (7B and 13B parameters). The results are averaged over five repetitions with different in-context learning (ICL) examples, showing the mean accuracy and standard deviation for each method and dataset. This allows for a comprehensive comparison of the effectiveness of each method across various tasks and model sizes.
This table presents a comparison of the performance of one-shot in-context learning (ICL) across various datasets using two different Llama models (Llama-2 7b and Llama-2 13b). Multiple methods are compared, including standard ICL and several debiasing/calibration techniques. The results are averaged over five repetitions to account for variance introduced by selecting different in-context learning examples. Mean accuracy and standard deviation are reported for each method/dataset combination.
Full paper#