↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Sharing trained graph neural network (GNN) models, while seemingly privacy-preserving, can inadvertently leak sensitive training data properties. Current methods for detecting this risk are computationally expensive, hindering practical application.
This paper introduces an efficient graph property inference attack. By leveraging model approximation techniques and a novel model selection mechanism, this attack requires training only a small set of models and can achieve significantly higher accuracy and efficiency than existing approaches. The method utilizes model approximation and a diversity-error optimization to ensure both accuracy and diversity of approximated models. Experiments demonstrate substantial performance gains in various real-world scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with graph neural networks (GNNs) and handling sensitive data. It presents a novel and efficient method for assessing the risk of privacy breaches associated with sharing trained GNN models. The efficient model approximation technique proposed offers significant advancements in computational efficiency over existing approaches, making it more practical for real-world applications. This work opens up avenues for further research in privacy-preserving machine learning techniques for graph data and improves the security of GNN model sharing.
Visual Insights#
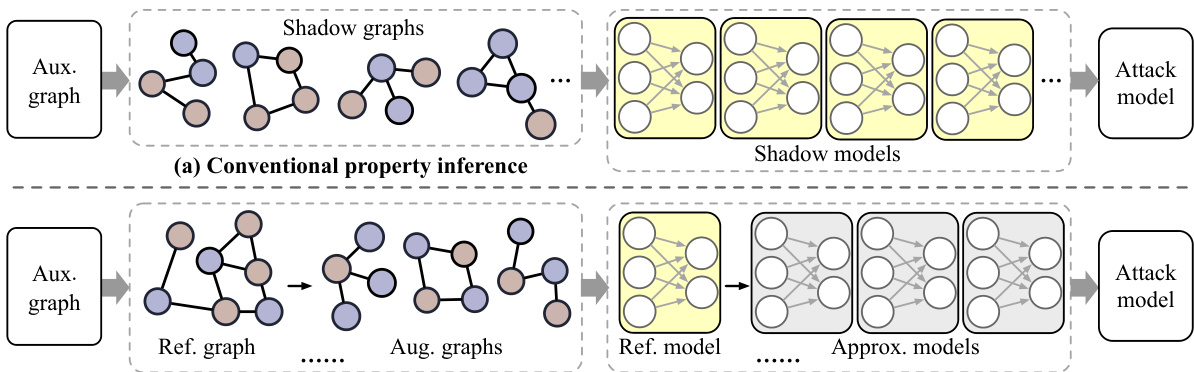
This figure compares the conventional graph property inference attack with the proposed attack in the paper. The conventional approach (a) involves training numerous shadow models on diverse shadow graphs, which is computationally expensive. In contrast, the proposed approach (b) trains only a few reference models and generates approximated models through model approximation techniques. This significantly reduces the computational cost while still achieving high attack accuracy. The yellow shading highlights the model training stage, illustrating the main source of computational cost in both approaches.
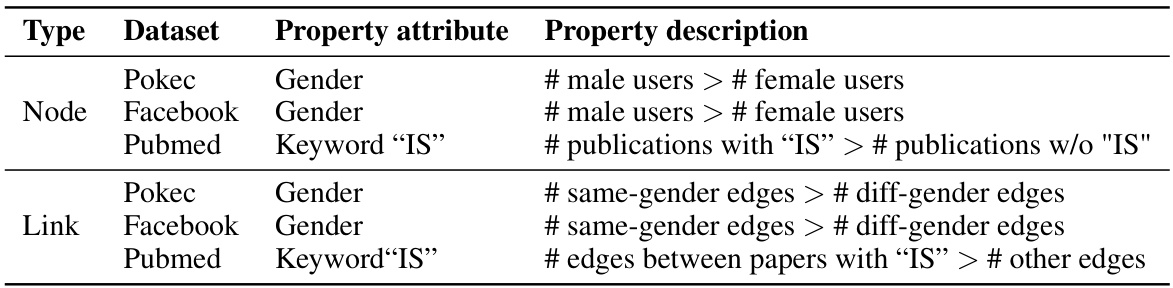
This table presents the properties that were targeted in the graph property inference attack experiments described in the paper. For each of three datasets (Pokec, Facebook, and Pubmed), it lists whether the property being inferred is a node property or a link property, the specific attribute used to define the property (gender or keyword ‘IS’), and a description of the property itself. For example, for the Pokec dataset and a node property, the property is defined as whether the number of male users is greater than the number of female users. The table provides context for understanding the experimental results.
In-depth insights#
GNN Property Inference#
GNN property inference attacks exploit the vulnerability of trained Graph Neural Network (GNN) models to reveal sensitive information about their training data. The core idea is that a GNN, even after training is complete, may implicitly encode properties of the graph it was trained on. Attackers leverage this by crafting queries or using auxiliary data to indirectly infer sensitive properties (e.g., average transaction value, community structures) without direct access to the training data itself. This poses a significant privacy risk, especially in collaborative settings where pre-trained GNN models are shared. Efficient attacks are crucial, hence, research focuses on minimizing the computational cost associated with generating shadow models (used to simulate different graph properties) by employing approximation techniques and carefully selecting diverse model variations to enhance attack accuracy. The challenge is to balance diversity (to better generalize the attack) with the accuracy of approximating models to avoid error propagation. Ultimately, the effectiveness of these attacks underscores the need for privacy-preserving techniques during GNN model development and deployment.
Model Approximation#
The concept of ‘Model Approximation’ in the context of graph neural networks (GNNs) is crucial for efficient property inference attacks. Instead of training numerous shadow models, which is computationally expensive, this technique leverages approximations. By training only a few models and applying perturbation techniques (like removing nodes/edges), a sufficient number of approximated shadow models can be generated. This significantly speeds up the attack process. However, ensuring both diversity (a broad range of models) and low error in approximations presents a challenge. Methods employing edit distance and theoretical error bounds help select diverse yet accurate approximated models, further enhancing attack efficacy. This approach effectively balances computational efficiency with the accuracy of the attack model.
Diversity Enhancement#
The ‘Diversity Enhancement’ section is crucial for the success of the proposed graph property inference attack. It tackles the challenge of ensuring that the approximated models offer a broad range of perspectives, preventing overfitting to specific graph characteristics. The method cleverly leverages structure-aware random walks to sample diverse reference graphs, capitalizing on community detection to select starting nodes from distinct graph regions. This ensures the augmented graphs reflect varied structural properties. Furthermore, a novel selection mechanism is introduced to balance diversity and accuracy of these approximated models. By using edit distance to measure diversity and a theoretically grounded criterion to assess approximation errors, this selection process guarantees a diverse set of models with minimal inaccuracies. This approach, formulated as a solvable programming problem, efficiently identifies the optimal subset of augmented graphs for the attack, significantly improving both efficiency and effectiveness.
Empirical Evaluation#
A robust empirical evaluation section is crucial for validating the claims of a research paper. It should meticulously document the experimental setup, including datasets used, evaluation metrics, and baselines for comparison. A clear description of the methodology, including data preprocessing, model training procedures, and parameter settings, is essential for reproducibility. The results should be presented concisely, using tables and figures to highlight key findings. Importantly, the analysis should not only report the performance but also discuss potential sources of error, limitations, and unexpected observations. Statistical significance tests should be applied to confirm the reliability of results, while ablation studies would demonstrate the contribution of individual components. Finally, a thorough discussion of the findings relative to existing work, potential limitations, and directions for future research would enhance the impact and credibility of the empirical evaluation.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the attack model to handle more complex graph structures and diverse GNN architectures is crucial for broader applicability. Investigating the impact of different data augmentation techniques on the efficiency and accuracy of the attack method would further refine its performance. Developing robust defenses against these attacks is critical for protecting sensitive information, requiring investigation into novel GNN training methods or data pre-processing techniques. Furthermore, a comprehensive analysis of the trade-off between attack efficiency and accuracy across various graph sizes and data characteristics is needed. Addressing the challenges posed by black-box settings, where the internal workings of the model are unknown, is also an important direction for future work. Finally, exploring the application of this research to address broader privacy concerns in other machine learning domains beyond graph neural networks would provide valuable insights.
More visual insights#
More on figures
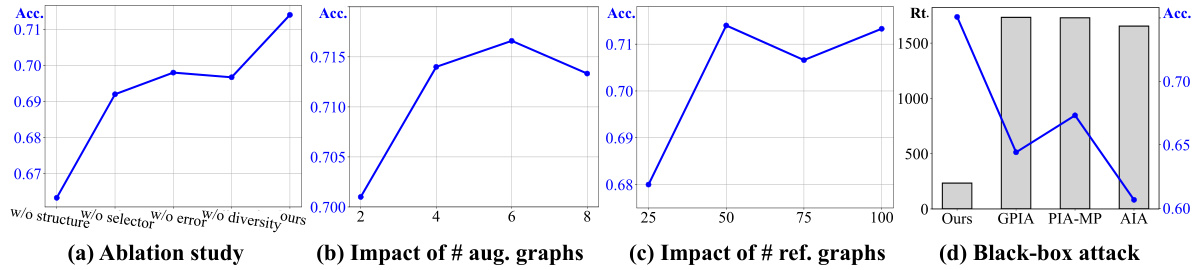
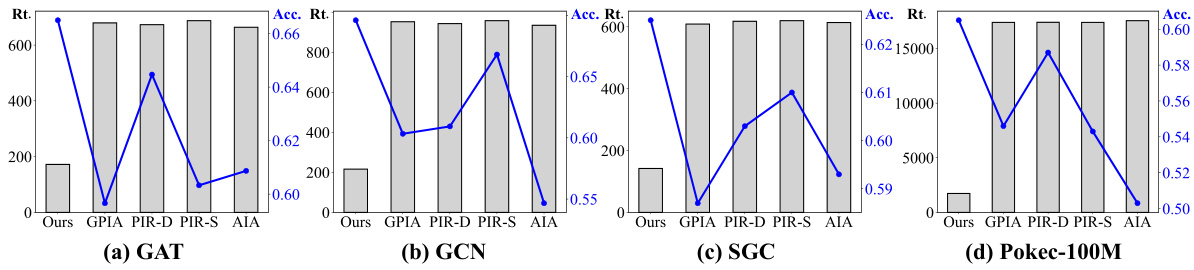
This figure presents the results of an ablation study and hyperparameter analysis for a graph property inference attack. (a) shows the impact of removing individual components of the proposed attack method on its effectiveness. (b) and (c) illustrate how the number of augmented and reference graphs influence attack accuracy. Finally, (d) compares the performance of the proposed attack method against several baselines in a black-box setting, demonstrating its improved accuracy and efficiency.
This figure compares the conventional graph property inference attack with the proposed method in the paper. The conventional approach involves training numerous shadow models, which is computationally expensive. In contrast, the proposed method trains only a small set of models and then generates approximated shadow models, significantly reducing the computational cost. The yellow shading highlights the model training process, emphasizing the main difference in computational cost between the two methods. (a) shows the traditional method’s heavy reliance on many shadow models. (b) illustrates the proposed method which uses a few reference models and then efficiently generates many approximated shadow models, hence reducing the computational burden.
More on tables
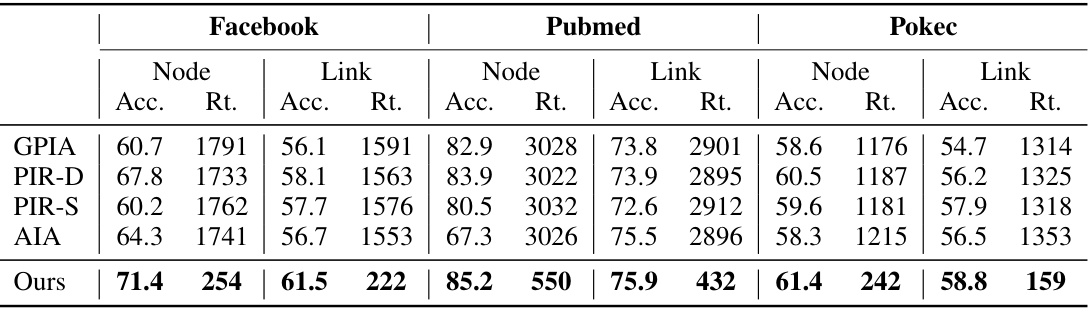
This table presents a comparison of the proposed attack method’s performance against four baseline methods across six real-world datasets (Facebook, Pubmed, Pokec) and two types of properties (node and link). The performance metrics considered are accuracy and runtime (in seconds). The table highlights the superior efficiency and effectiveness of the proposed method in the white-box setting, where the attacker has full knowledge of the target model’s architecture and parameters.
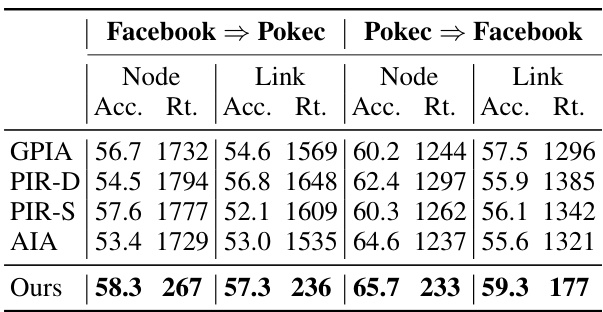
This table presents a comparison of the proposed graph property inference attack method against four state-of-the-art baseline methods. The comparison is conducted on three real-world datasets (Facebook, Pubmed, and Pokec) and for two types of properties (node and link properties). The metrics used for comparison are accuracy, runtime (in seconds), and the best-performing method for each dataset and property type is highlighted in bold. The results demonstrate the efficiency and effectiveness of the proposed method compared to existing approaches.

This table lists the properties that were targeted in the graph property inference attacks. The table specifies the dataset used (Pokec, Facebook, Pubmed), whether the property is a node property or link property, the specific attribute used to define the property (e.g., Gender, Keyword ‘IS’), and a description of what constitutes the property being measured (e.g., the number of male users vs. the number of female users). The ‘#’ symbol indicates that the property is defined in terms of a count of nodes or edges.
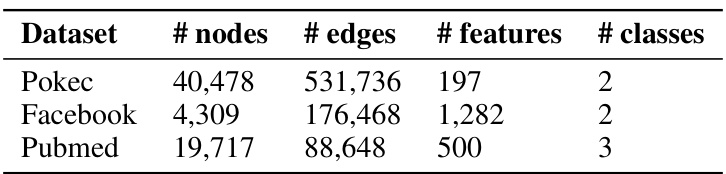
This table lists the properties that were targeted by the graph property inference attack across three real-world datasets: Pokec, Facebook, and Pubmed. For each dataset, two types of properties are considered: node properties and link properties. The node properties are defined by the relative number of nodes possessing a certain attribute (gender or presence of keyword ‘IS’), while the link properties are defined by the ratio of edges connecting nodes with that specific attribute. This table provides a summary of the sensitive properties considered in the experiment.

This table lists the properties that were targeted in the graph property inference attacks conducted in the paper. Each row represents a dataset (Pokec, Facebook, Pubmed) and a type of property (node or link). The ‘Property attribute’ column indicates the specific attribute used to define the property (e.g., gender for node properties, presence of the keyword ‘IS’ for link properties). The ‘Property description’ column provides a more detailed explanation of the property being tested, including an inequality that represents the condition of interest. For example, for the Facebook node property, the attack attempts to determine if the number of male users exceeds the number of female users.

This table presents a comparison of the proposed attack method against four baseline methods across six real-world datasets. The comparison includes the accuracy and runtime (in seconds) for both node and link properties under a white-box setting. The best results for each dataset and property type are highlighted in bold, illustrating the superior efficiency and effectiveness of the proposed method.
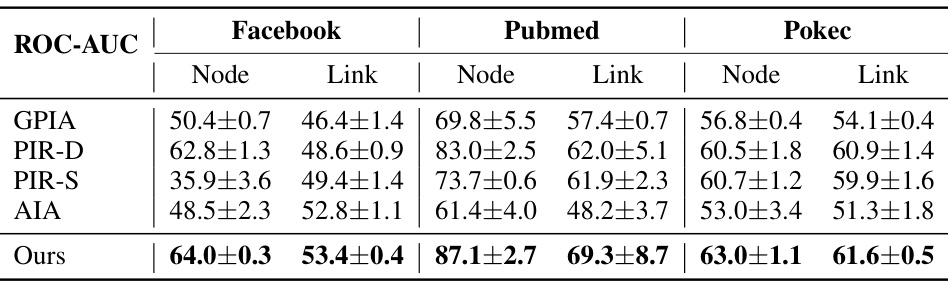
This table compares the performance of different graph property inference attack methods in terms of accuracy and runtime across three real-world datasets (Facebook, Pubmed, Pokec) and two types of properties (node properties and link properties). It shows that the proposed method outperforms existing methods, achieving higher accuracy and significantly lower runtime.
Full paper#