↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Model-based reinforcement learning (MBRL) aims to improve sample efficiency and generalization in reinforcement learning (RL), often by incorporating pre-trained visual representations (PVRs). However, the effectiveness of PVRs in MBRL remains largely unexplored. Many existing studies focus on model-free RL, leaving the MBRL context largely unaddressed. This creates a critical gap in our understanding of how to best leverage visual information for efficient and generalizable RL agents.
This paper rigorously benchmarks various PVRs on challenging control tasks using a model-based RL approach. The study reveals a surprising finding: current PVRs do not improve sample efficiency and often hinder generalization to out-of-distribution (OOD) settings compared to learning visual representations from scratch. The research further highlights that data diversity and network architecture are the most critical factors determining OOD generalization performance. Analyzing learned dynamics models showed that those trained from scratch had better accuracy, particularly in reward prediction.
Key Takeaways#
Why does it matter?#
This paper challenges the common assumption that pre-trained visual representations (PVRs) always improve model-based reinforcement learning (MBRL). It reveals that PVRs often fail to enhance sample efficiency or generalization in MBRL, highlighting the need for further investigation into effective representation learning strategies within this model-based setting and opening new avenues for research in efficient RL.
Visual Insights#

This figure shows the architectures of the PVR-based DreamerV3 and TD-MPC2 models. Both models use pre-trained visual representations (PVRs) as input. DreamerV3 uses a recurrent architecture with an encoder that maps the PVR output and recurrent state to a discrete latent variable, while TD-MPC2 uses a stack of the last three PVR embeddings as input to its encoder. The figure highlights the integration of the PVRs into the existing model architectures, showing how the pre-trained representations are incorporated into the overall model.
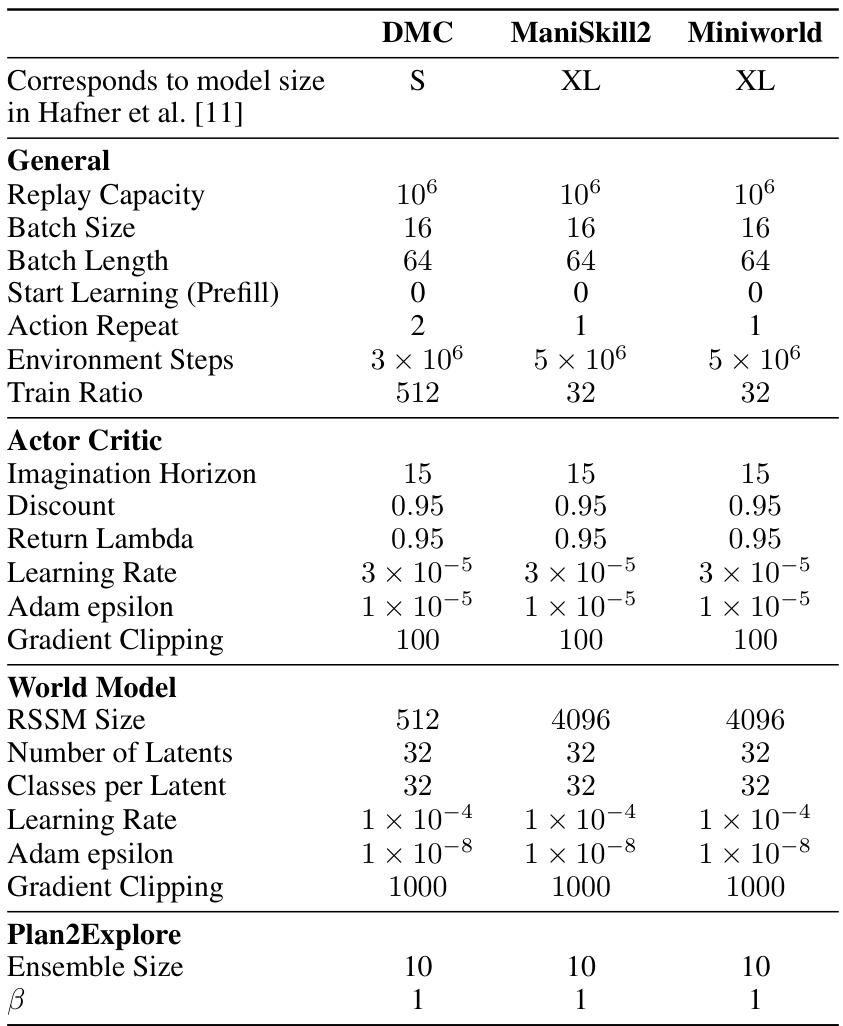
This table presents the hyperparameters used for training the DreamerV3 model across three different environments: DeepMind Control Suite (DMC), ManiSkill2, and Miniworld. It breaks down the hyperparameters into general settings (applicable across all environments) and world model specific settings. The general settings include replay capacity, batch size, batch length, and other training parameters. World model settings encompass RSSM size, number of latents, and classes per latent. The table highlights the variations in hyperparameter values across the three environments, reflecting the adaptations made to optimize performance in each specific simulation.
In-depth insights#
PVRs in MBRL#
The integration of Pre-trained Visual Representations (PVRs) within Model-Based Reinforcement Learning (MBRL) presents a complex and intriguing research area. Initial expectations suggested that leveraging PVRs would significantly improve MBRL’s sample efficiency and generalization capabilities by providing rich, readily available visual features. However, this paper surprisingly reveals that this isn’t the case. Current PVRs fail to consistently outperform learning representations from scratch in MBRL settings. This challenges the assumptions underlying many previous model-free RL approaches. The authors propose that this inefficiency stems from the objective mismatch inherent in MBRL, where optimizing the dynamics model and agent performance simultaneously creates challenges for incorporating pre-trained features effectively. The impact of PVR properties, such as data diversity and network architecture, were also explored, with data diversity significantly outperforming architecture in promoting out-of-distribution (OOD) generalization.
OOD Generalization#
The concept of ‘OOD Generalization’ in the context of visual reinforcement learning (VRL) is crucial for creating robust and adaptable agents. The study investigates how well pre-trained visual representations (PVRs) enable model-based reinforcement learning (MBRL) agents to generalize to out-of-distribution (OOD) scenarios. Surprisingly, the results reveal that PVRs do not significantly enhance generalization compared to learning representations from scratch. This challenges the common assumption that pre-trained models inherently transfer well to new tasks. The analysis suggests a potential disconnect between the general nature of PVRs and the specific needs of MBRL, possibly due to issues in objective function mismatch between training and evaluation. Data diversity and network architecture emerge as more important factors for OOD generalization. Understanding this discrepancy highlights the need for further research into training PVRs specifically suited for MBRL and for developing techniques to bridge the gap between general visual representations and task-specific requirements for improved real-world applicability.
Model Quality#
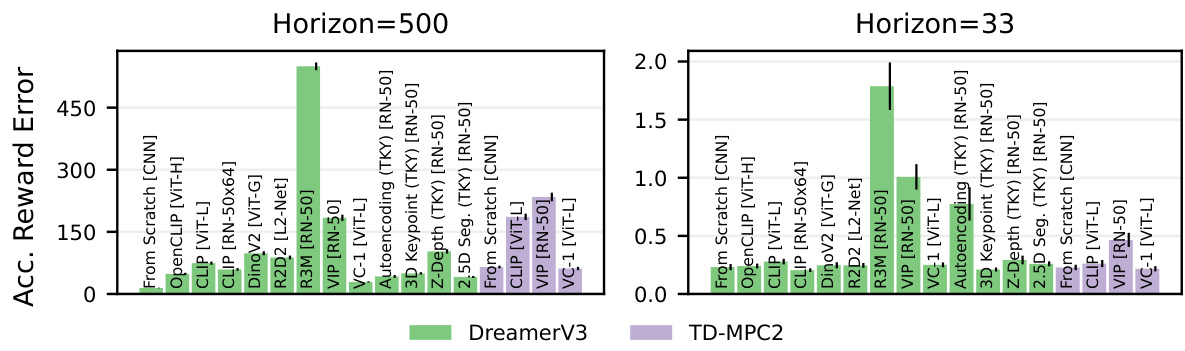
Analyzing model quality in the context of model-based reinforcement learning (MBRL) with pre-trained visual representations (PVRs) reveals crucial insights. The study directly compares the performance of models trained from scratch versus those leveraging PVRs, finding that models trained from scratch often exhibit superior accuracy. This unexpected result challenges the assumption that PVRs inherently improve data efficiency and generalization in MBRL. A deeper investigation into the quality of learned dynamics models and reward prediction reveals that models trained from scratch show less accumulation error and better reward prediction accuracy. This suggests that the objective mismatch inherent in MBRL training, where the dynamics and policy optimization are decoupled, makes it challenging for PVRs to provide benefits, highlighting the importance of data diversity and network architecture in achieving robust out-of-distribution generalization.
PVR Properties#
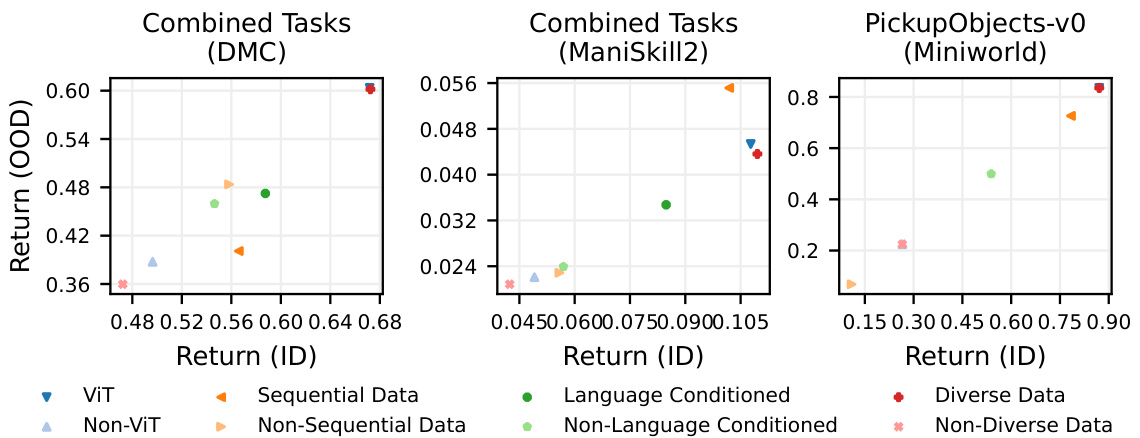
Analyzing the properties of pre-trained visual representations (PVRs) reveals crucial insights into their effectiveness in model-based reinforcement learning (MBRL). Data diversity emerges as a critical factor, with PVRs trained on broader datasets exhibiting superior generalization capabilities to out-of-distribution (OOD) settings. The network architecture also plays a role, where Vision Transformers (ViTs) show promise compared to convolutional neural networks (CNNs). Interestingly, language conditioning and sequential data in PVR training do not consistently translate into improved MBRL performance, suggesting that these aspects might be less crucial than initially assumed. This analysis emphasizes the importance of focusing on data diversity and architectural choices when selecting PVRs for MBRL applications. Further research should investigate the interaction of PVR properties with MBRL training dynamics and the impact of different reward models.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending the study to encompass a wider range of MBRL algorithms and various robotic manipulation tasks would strengthen the generalizability of the findings. Investigating alternative visual representation learning methods and pre-training strategies beyond those evaluated is crucial. A deeper investigation into the interplay between the quality of learned dynamics and reward models within MBRL, and how it is affected by PVRs, is needed. Moreover, exploring techniques to mitigate the objective mismatch inherent in MBRL when integrating PVRs could significantly enhance performance. Finally, applying this research to real-world robotic systems in diverse and challenging environments will be essential for validating the practical implications and limitations of using PVRs in model-based reinforcement learning.
More visual insights#
More on figures

This figure shows example images from the three different simulated robotic control environments used in the paper: DeepMind Control Suite (DMC), ManiSkill2, and Miniworld. It highlights the variety of tasks, illustrating the diverse challenges faced by the reinforcement learning agents. The caption notes the differing camera perspectives used in each environment; DMC and Miniworld use the agent’s perspective, while ManiSkill2 uses a wrist-mounted camera perspective.
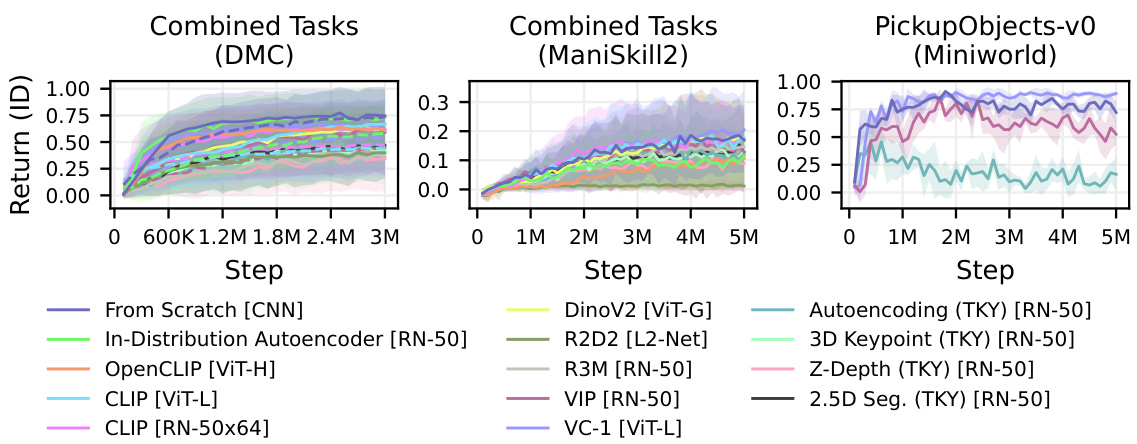
This figure presents a comparison of the in-distribution performance and data efficiency of different visual representations (including pre-trained visual representations (PVRs) and representations learned from scratch) across three robotic control environments: DeepMind Control Suite (DMC), ManiSkill2, and Miniworld. The results show that, especially on the DMC tasks, representations learned from scratch generally outperformed the PVRs in terms of both performance and data efficiency. The figure uses lines to show average performance and shaded areas to illustrate standard deviations; solid lines depict DreamerV3 and dashed lines depict TD-MPC2. Individual environment-specific graphs are available in the appendix.

This figure shows the average normalized performance (with standard error bars) of different visual representation methods on three benchmark datasets (DMC, ManiSkill2, and Miniworld) in an out-of-distribution (OOD) setting. The key finding is that the ‘From Scratch’ method, where the visual representation is learned from scratch, consistently outperforms all pre-trained visual representations (PVRs) across all three datasets in terms of OOD performance. This suggests that pre-trained models are not as effective for model-based reinforcement learning (MBRL) in OOD scenarios as previously thought.
This figure compares the average normalized performance of different visual representations on three distinct benchmark environments (DMC, ManiSkill2, and Miniworld) in out-of-distribution (OOD) settings. The key finding is that the baseline model which learns representations from scratch consistently outperforms all pre-trained visual representations (PVRs), even when the evaluation is done on data that differs from the training data. The thin black lines represent the standard error, providing a measure of the variability in performance.
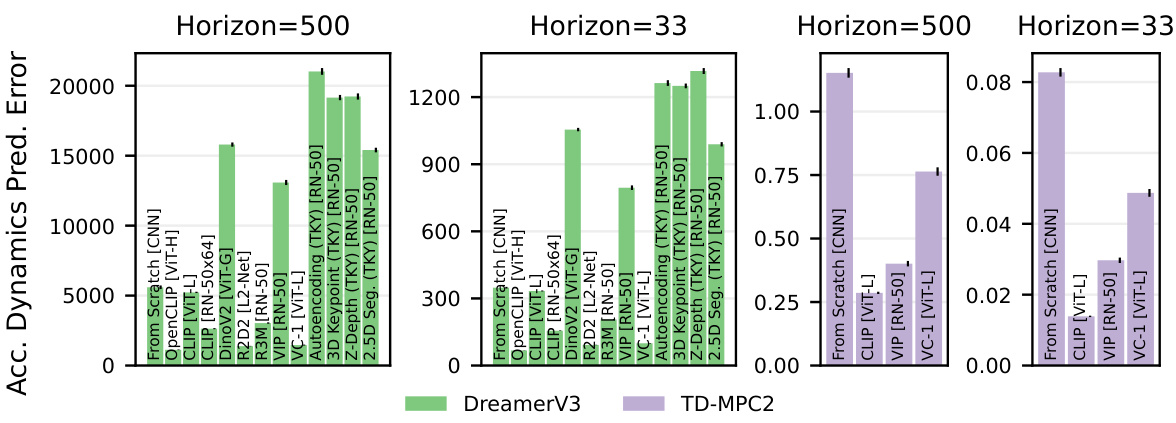
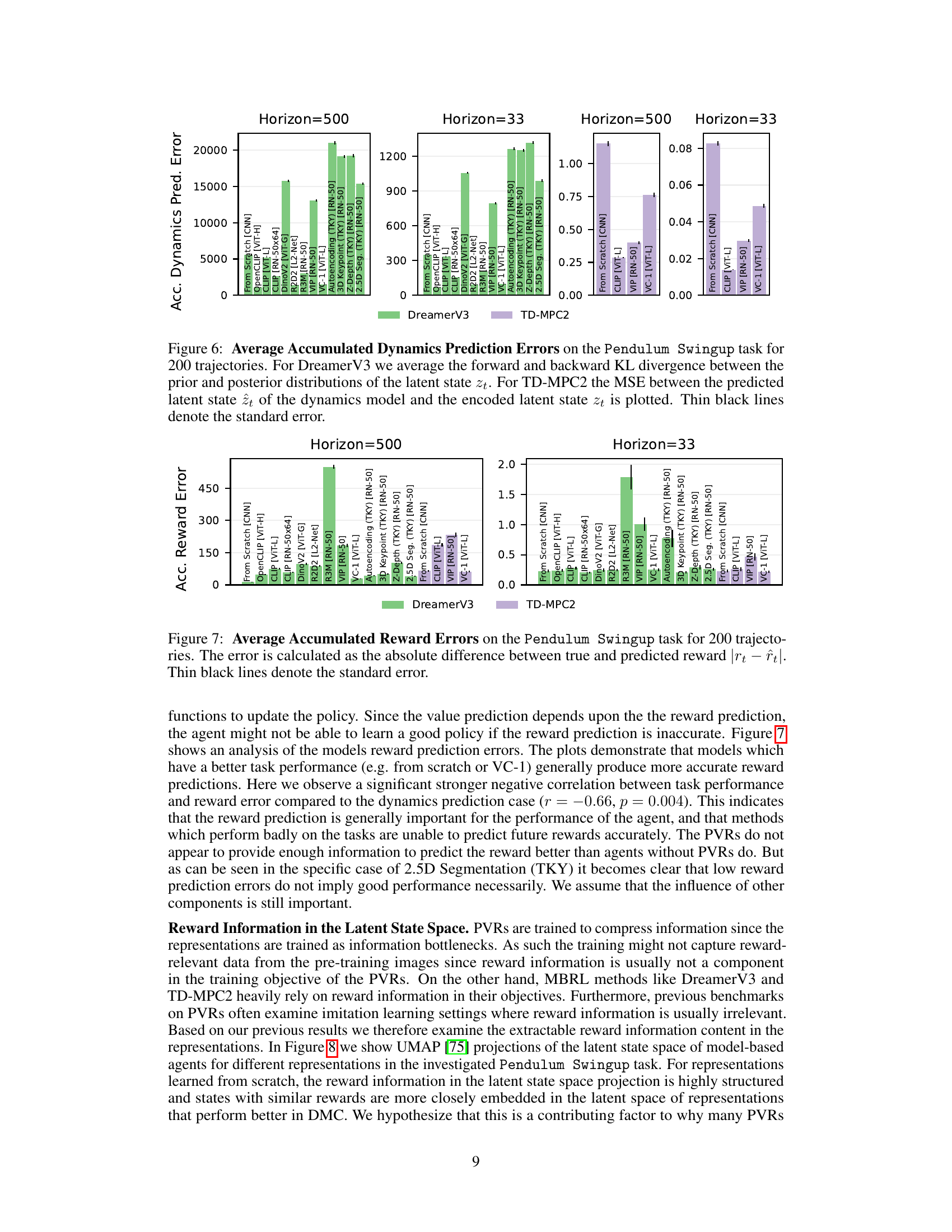
This figure presents a comparison of the accumulated dynamics prediction errors for two model-based reinforcement learning algorithms, DreamerV3 and TD-MPC2, across different visual representations. The x-axis represents the visual representation used, while the y-axis shows the accumulated prediction error over a horizon of 500 and 33 time steps, respectively. DreamerV3’s error is measured using KL divergence, while TD-MPC2’s uses Mean Squared Error (MSE). The results show the relative accuracy of the learned dynamics models when using different visual representations within the context of model-based RL.
This figure compares the dynamics prediction errors of various visual representations used in two different model-based reinforcement learning algorithms, DreamerV3 and TD-MPC2, on the Pendulum Swingup task. The x-axis represents different visual representations (PVRs), including those trained from scratch and several pre-trained models. The y-axis represents the accumulated dynamics prediction error, showing the difference between the predicted and actual latent states of the environment models. The plots for two time horizons (500 and 33 timesteps) are shown, indicating the error over longer and shorter prediction windows. The error metrics used are the average forward and backward Kullback-Leibler divergence for DreamerV3 and the Mean Squared Error (MSE) for TD-MPC2. The results illustrate how the quality of the dynamics prediction varies across different visual representations, potentially influencing the overall performance of the model-based RL agents.

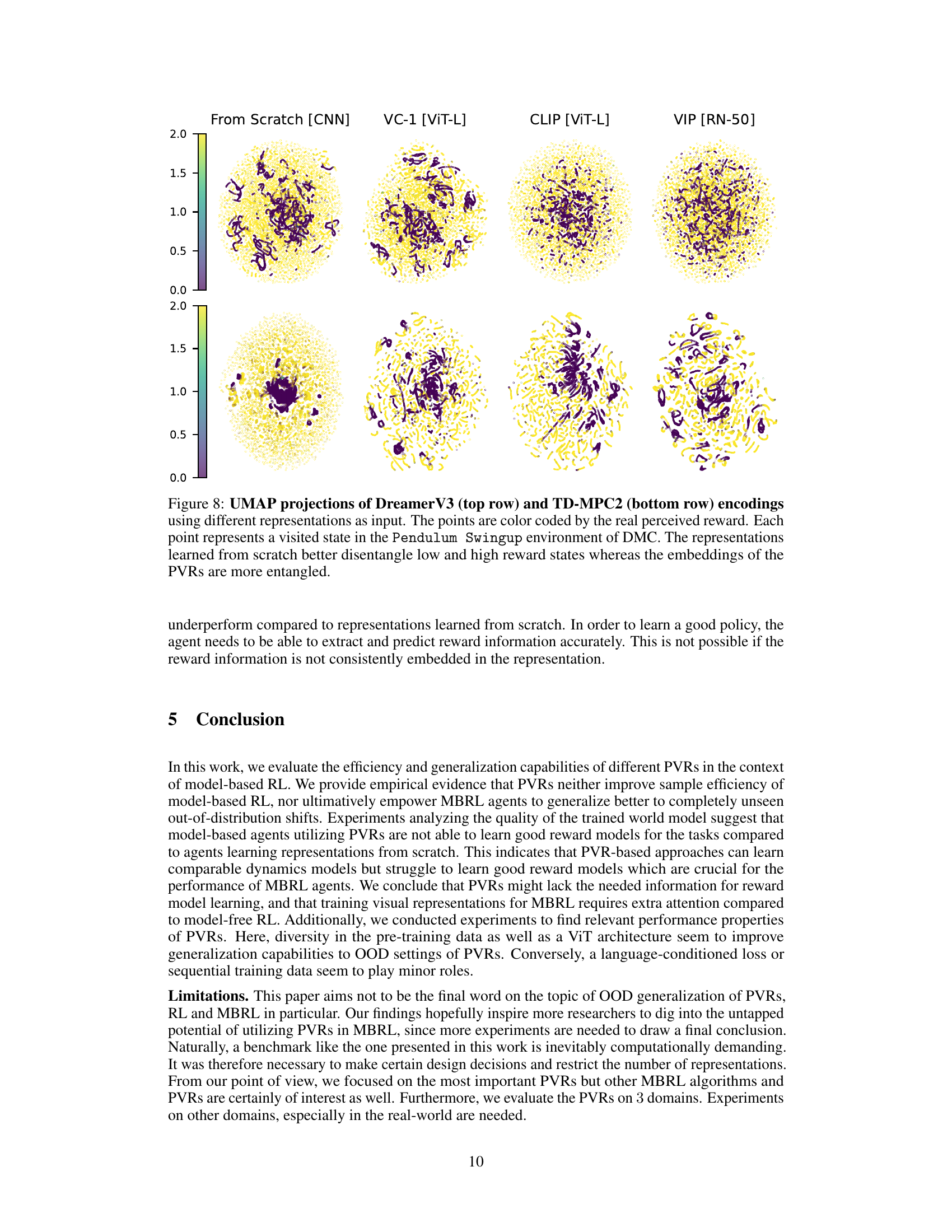
This figure visualizes the latent space representations generated by different models (DreamerV3 and TD-MPC2) using various visual representations, including one trained from scratch and several pre-trained visual representations (PVRs). UMAP is used to reduce the dimensionality of the latent space for visualization. Each point represents a state visited by the agent during the Pendulum Swingup task. The color of each point represents the actual reward received in that state. The figure shows that models using representations trained from scratch produce more clearly separated clusters of high and low reward states than those using PVRs, suggesting that models trained from scratch produce latent spaces better organized according to the reward.

This figure compares the performance of using linear layers versus multilayer perceptrons (MLPs) as encoders in a model-based reinforcement learning (MBRL) setting. The results show that performance is not significantly affected by the choice of encoder architecture, indicating that using the simpler linear layer is sufficient and doesn’t negatively impact performance.
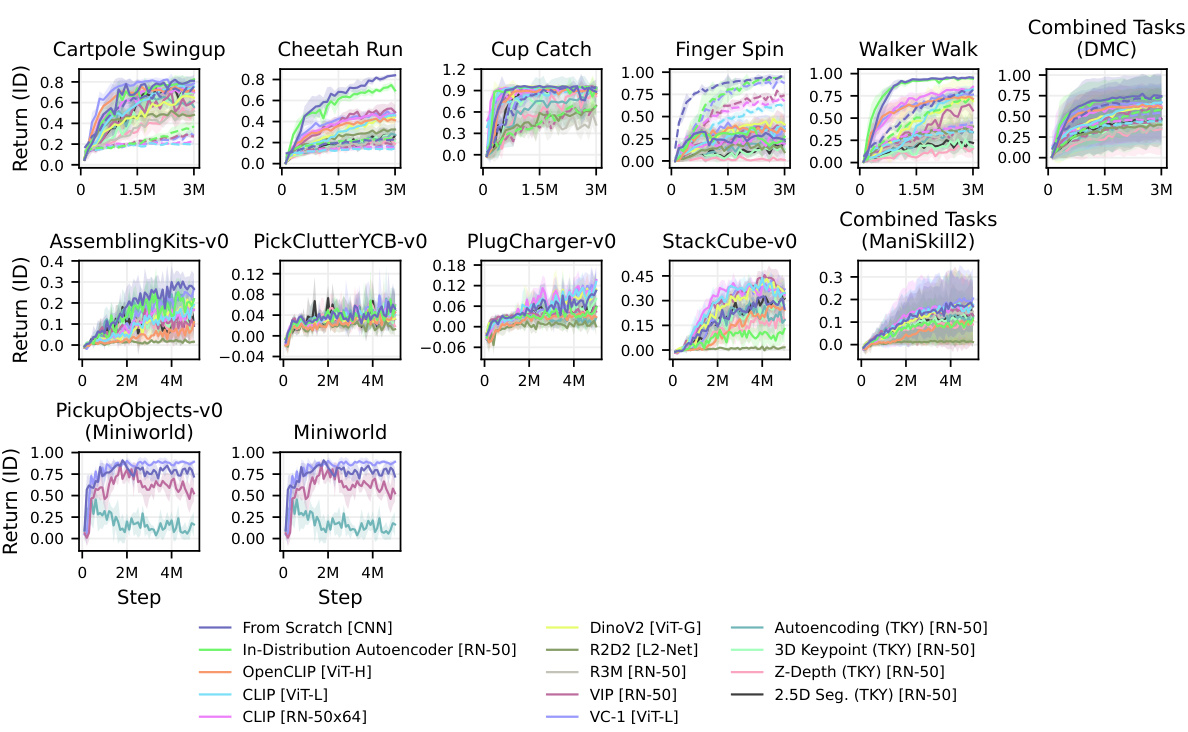
This figure compares the performance and data efficiency of various visual representations (learned from scratch and pre-trained) in three different robotic control tasks environments (DMC, ManiSkill2, Miniworld). The graph plots the average return (reward) of different methods over the number of steps in the training process, highlighting the data efficiency of each approach. The shaded regions represent the standard deviation, indicating variability across multiple training runs. The figure provides insights into how effectively different visual representations learn and generalize in model-based reinforcement learning (MBRL) settings.
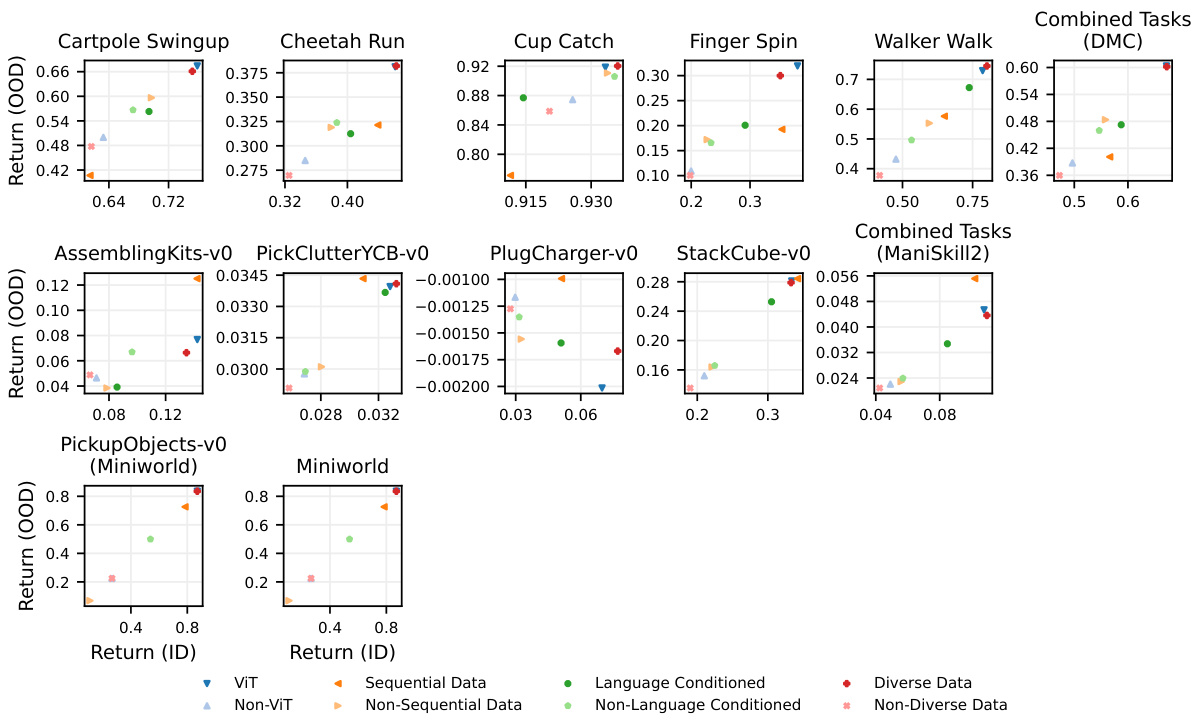
This figure shows the performance of different categories of PVRs on in-distribution (ID) and out-of-distribution (OOD) tasks. Each point represents the interquartile mean (IQM) performance of a group of PVRs sharing a common property (e.g., using Vision Transformers (ViT), trained on sequential data, etc.). The x-axis shows ID performance, and the y-axis shows OOD performance. The figure indicates that ViT-based PVRs and those trained on diverse data tend to generalize better to OOD settings. The effect of sequential data is less clear, providing benefits in some environments but not others.

The figure shows the ablation study of transformer blocks within the VC-1 model on the Walker Walk task in the DeepMind Control Suite. The results indicate that using only half of the transformer blocks in VC-1 achieves performance comparable to using the full model. Interestingly, the blocks closer to the output seem to contain most of the crucial information as performance degrades significantly when using less than half of the blocks. This suggests that the early layers of VC-1 might not contain sufficiently useful information for model-based reinforcement learning (MBRL).
More on tables

This table presents a comprehensive overview of the pre-trained visual representations (PVRs) used in the experiments. Each row details a specific PVR, providing its name, the loss function used during training, the dataset it was trained on, its network architecture (backbone), and the dimensionality of its resulting embedding vector. The table facilitates understanding of the different PVRs and their characteristics, enabling comparison and analysis of their performance in the context of the study.
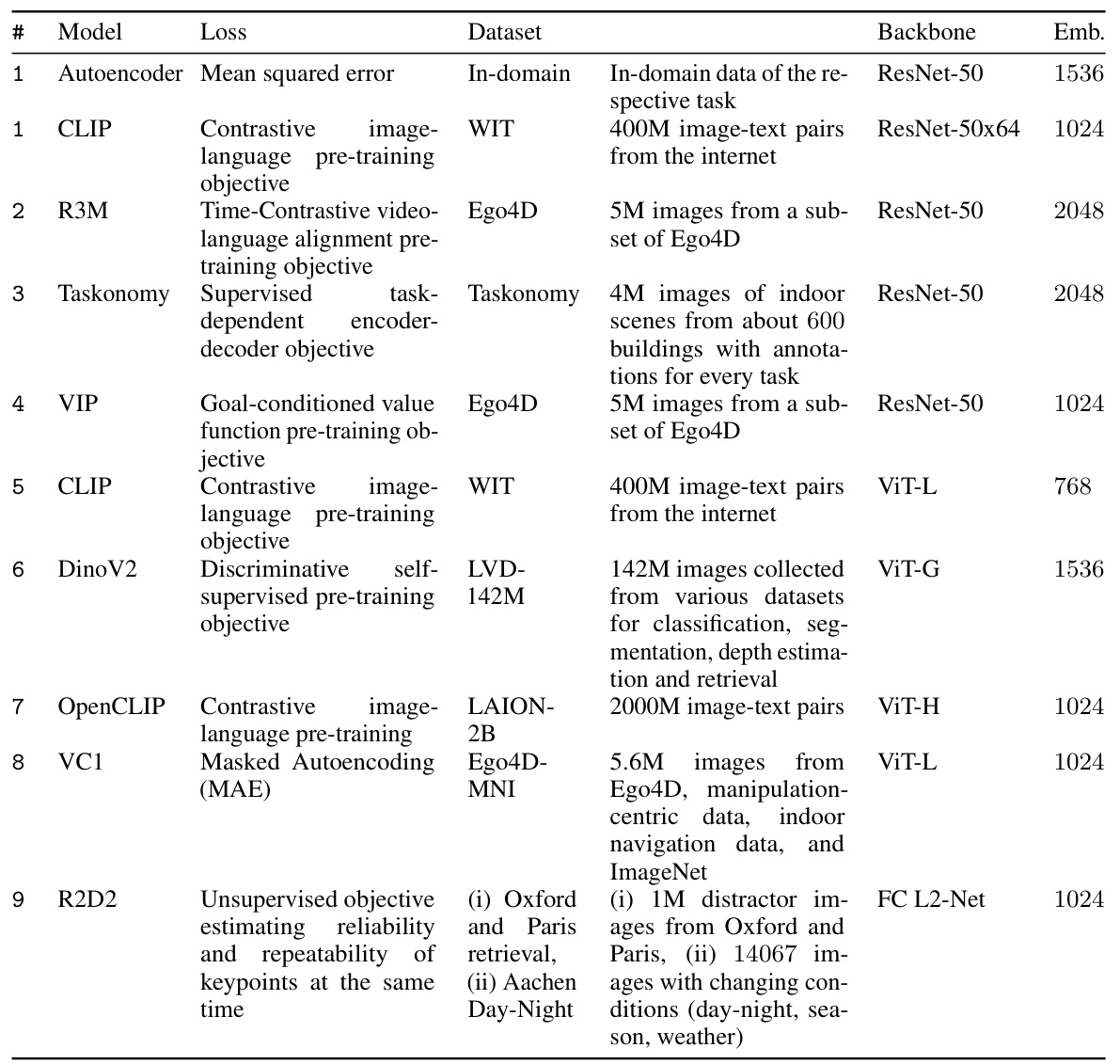
This table provides a detailed overview of the pre-trained visual representations (PVRs) used in the experiments. For each PVR, it lists the loss function used during training, the dataset on which it was trained, the backbone architecture of the model (e.g., ResNet-50, ViT-L), and the dimensionality of the resulting embedding vector. The table is organized alphabetically by PVR name and further sorted by backbone architecture.

This table provides a comprehensive overview of the pre-trained visual representations (PVRs) used in the study. For each PVR, it lists the loss function used during training, the dataset it was trained on, its underlying architecture (backbone), and the dimensionality of its output embedding.
Full paper#