↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating realistic videos with physically plausible motion remains a challenge in computer vision. Existing video diffusion models often require extensive training and produce videos biased toward their training data. Furthermore, achieving fine-grained control over motion dynamics within these models is difficult.
MotionCraft tackles these issues with a novel zero-shot approach. It leverages an optical flow derived from a physics simulation to warp the latent space of a pre-trained image diffusion model (like Stable Diffusion). This allows for the creation of physics-based videos with complex and user-controllable motion, while simultaneously generating missing content consistently with scene evolution. Experiments demonstrate qualitative and quantitative improvements over state-of-the-art zero-shot video generators, showing the effectiveness of this approach for generating videos with finely prescribed, complex motion.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents MotionCraft, a novel approach to zero-shot video generation that achieves high-quality, physically realistic videos by leveraging physics simulations. This addresses limitations of existing methods which struggle with temporal consistency and fine-grained motion control. The zero-shot nature and impressive results make this method highly valuable across various video generation applications.
Visual Insights#

This figure compares the results of MOTIONCRAFT and T2V0 in simulating a melting statue. The top row shows MOTIONCRAFT’s output, where the model realistically simulates the melting process by warping the noise latent space using fluid dynamics. In contrast, the bottom row displays T2V0’s result, which simply moves the statue downwards without simulating the melting effect.

This table presents quantitative results comparing MOTIONCRAFT and T2V0 across different video generation scenarios. The metrics used are Frame Consistency (average cosine similarity of CLIP embeddings of consecutive frames) and Motion Consistency (SSIM metric between the first frame and the second frame after applying reverse optical flow). Higher scores indicate better consistency and realism. The results show that MOTIONCRAFT outperforms T2V0 in both metrics, suggesting higher visual quality in generated videos.
In-depth insights#
Latent Space Warping#
Latent space warping, in the context of video generation, is a powerful technique that offers a unique approach to animating images. Instead of directly manipulating pixels, it modifies the underlying latent representation of an image, which is a compressed encoding of the image’s features. By applying transformations to this latent space, such as warping based on optical flow from a physics simulation, one can generate videos with realistic and physically plausible motion. The key advantage is that the generative model’s inherent knowledge of image structure and consistency is leveraged, resulting in high-quality videos without artifacts or missing content often seen when manipulating pixel space directly. This approach proves particularly effective for creating videos with complex motion dynamics. However, challenges remain in precisely controlling the generated content and ensuring a seamless transition between frames, which are topics for future research. Another key aspect is the correlation between the latent space and the image space, which is crucial for successful warping. A strong correlation enables the desired motion to be accurately reflected in the generated video. Research in this field is actively exploring ways to improve the accuracy and efficiency of latent space warping, potentially by refining methods for estimating optical flow or developing advanced techniques for latent space manipulation.
Physics-Based Animation#
Physics-based animation aims to simulate realistic movement by modeling the physical forces acting on objects. This approach offers greater realism and control compared to traditional animation techniques, allowing for the creation of complex and believable motion. Key elements involve defining physical properties (mass, elasticity, etc.), applying relevant forces (gravity, friction, etc.), and numerically solving equations of motion. The resulting simulations can then be rendered as animation. However, challenges exist in balancing computational efficiency with the desired level of detail. Simulating highly complex scenarios can require significant processing power, often necessitating approximations and simplifications. Furthermore, the integration of physics into creative processes requires both technical expertise and artistic vision to create compelling results. Successful physics-based animation hinges on finding the ideal balance between accuracy and artistic expression.
Zero-Shot VideoGen#
Zero-shot video generation, a fascinating area of research, aims to create videos without explicit training on video data. This poses significant challenges, as it requires models to learn intricate spatiotemporal relationships and generate coherent motion from limited information. Physics-based approaches offer a promising solution, leveraging our understanding of how objects move in the real world to guide the generation process. By integrating physical simulations to inform motion dynamics, models can produce more realistic videos. This approach necessitates innovative methods of encoding this physics-based information and seamlessly incorporating it into existing generative models, likely diffusion-based models which excel in image generation. A key challenge is the efficient integration of physical simulations with the latent space of these generative models. It’s crucial that this integration avoids introducing artifacts or inconsistencies in the generated sequence. Moreover, the ability to generate diverse and complex motion is highly desirable, requiring the use of flexible, expressive physics simulation tools. Future work will likely focus on enhancing the realism and diversity of generated motion, further integrating multi-agent interactions and the ability to condition generation on more detailed semantic specifications than simple text prompts.
MCFA & Spatial-η#
The proposed method, MotionCraft, introduces two novel mechanisms: MCFA (Multiple Cross-Frame Attention) and Spatial-η. MCFA enhances video generation consistency by enabling the model to attend to both the current frame and previous frames, leveraging information from multiple frames for a more coherent temporal evolution. This is a significant improvement over existing methods that only consider single-frame context. Spatial-η further refines the generation process by dynamically switching between DDIM (Denoising Diffusion Implicit Models) and DDPM (Denoising Diffusion Probabilistic Models) sampling strategies on a pixel-by-pixel basis. This adaptive sampling allows the model to generate novel content in areas requiring creativity (using DDPM) while maintaining consistency in other regions (using DDIM). The combination of MCFA and Spatial-η demonstrates a synergistic effect in MotionCraft’s ability to produce high-quality, temporally consistent videos with complex dynamics. The innovative use of these techniques highlights a significant contribution to zero-shot video generation, offering a more powerful and nuanced approach than previous state-of-the-art methods.
Future Work & Limits#
The paper’s “Future Work & Limits” section would ideally delve into several key areas. First, addressing the limitations of relying solely on pre-trained image diffusion models is crucial. The inherent biases and limitations of these models directly impact the quality and realism of the generated videos. Future work should explore incorporating techniques to mitigate these biases, perhaps by incorporating fine-tuning or developing more robust methods for generating novel content. Second, expanding the range of physics simulations incorporated is important. The current work showcases rigid body physics, fluid dynamics, and multi-agent systems; however, exploring other complex physics simulations would significantly broaden the applicability of the approach. This includes considering more sophisticated simulation techniques for modelling complex phenomena, or integrating physics engines capable of handling deformable objects and non-linear dynamics. Third, developing more refined methods for optical flow estimation and integration within the latent space is essential. Improving the accuracy and robustness of optical flow extraction from the simulation could minimize artifacts and increase the fidelity of the generated videos. Finally, a key consideration for future work is the development of techniques for more comprehensive evaluation. While the paper employs quantitative metrics such as frame consistency and motion consistency, incorporating more nuanced qualitative analyses and potentially user studies could offer a more complete understanding of the system’s performance and user experience.
More visual insights#
More on figures

This figure provides a visual example of the correlation between image space and latent space optical flow. It shows RGB frames and their corresponding latent representations (in Stable Diffusion), with the estimated optical flow overlaid on both. The final image shows a correlation map highlighting the relationship between the flows in these two spaces.
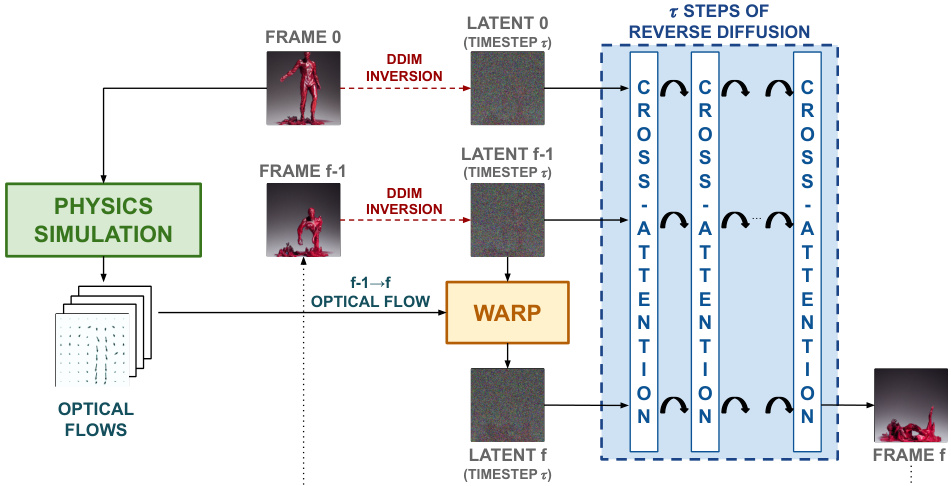
This figure illustrates the overall architecture of the proposed MOTIONCRAFT model. It shows how a video is generated from a starting image. The process involves using a pretrained still image generative model and warping its noise latents according to optical flows derived from a physics simulation. The optical flows guide the model to generate frames consistent with the simulated motion, creating realistic videos.

This figure shows a high-level overview of the MOTIONCRAFT architecture. It starts with a single input image, which is encoded into a latent space. A physics simulation generates optical flow data, representing the motion that should be applied to the image. This optical flow is then used to warp the noise latents, effectively injecting the motion information. The modified latents are then fed through a reverse diffusion process (using a pretrained still-image generative model) to generate a sequence of video frames. This process highlights the key steps: encoding, warping, and decoding, showing how the model generates physics-based videos without explicit training on video data.

This figure compares the results of MOTIONCRAFT and T2V0 [20] for a rigid motion simulation of a satellite orbiting a city. The top row shows frames generated by MOTIONCRAFT, demonstrating smooth, consistent motion and generation of new city features as the satellite moves. The bottom row shows the results of T2V0, revealing less natural motion and a lack of generation of new city areas.

This figure compares the results of MOTIONCRAFT and T2V0 for a rigid body motion simulation of the Earth rotating. MOTIONCRAFT generates a video where the Earth smoothly rotates, revealing new portions of the continents as the rotation progresses, with no noticeable artifacts or inconsistencies. In contrast, T2V0’s attempt at generating a similar video fails to maintain consistent visual details or coherent temporal evolution.

This figure shows the ablation study on the cross-frame attention mechanism of MOTIONCRAFT. The top row shows the result without using any cross-frame attention. The second row shows using only the initial frame as attention. The third row shows using only the previous frame as attention. The bottom row shows the result using both the initial and previous frames as attention, which is the proposed method in the paper. By comparing these results, the authors demonstrate the necessity of using both initial and previous frames to generate plausible videos.

This figure compares the results of MOTIONCRAFT and T2V0 [20] when simulating a flock of birds using a multi-agent system. The top row shows the video generated by MOTIONCRAFT, demonstrating smooth, consistent motion and realistic flocking behavior. The bottom row displays the output of T2V0 [20], which exhibits inconsistent motion and changes in the number of birds throughout the sequence.

This figure compares the results of a revolving earth simulation using two different methods: MOTIONCRAFT and T2V0. MOTIONCRAFT is able to generate a consistent video sequence where the earth rotates smoothly, and new landmasses are generated as expected. T2V0, on the other hand, struggles to maintain consistency, leading to artifacts and inconsistencies in the generated video.

This figure compares the results of MOTIONCRAFT and T2V0 [20] on a video generation task involving a rotating Earth. The top row shows frames generated by MOTIONCRAFT, demonstrating the model’s ability to generate a realistic and temporally consistent sequence showing the Earth’s rotation. New parts of the Earth’s surface are seamlessly generated as they come into view, indicating the model’s skill in generating coherent, novel content alongside consistent animation. The bottom row shows frames from T2V0 [20], showcasing the model’s limitations and failure to produce temporally consistent and realistic results. The comparison highlights MOTIONCRAFT’s superior performance in generating videos with complex, smooth motion.

This figure shows several additional results obtained using the proposed MOTIONCRAFT model. The first three rows showcase various video generation results using different physics simulations and initial image prompts. The bottom row demonstrates the model’s adaptability by applying it to a different image generation model (SDXL), highlighting its versatility and ability to generate high-resolution videos.

This figure compares the results of MOTIONCRAFT and T2V0 [20] on a rigid body motion simulation of a satellite orbiting Earth. The top row shows the frames generated by MOTIONCRAFT, while the bottom row displays the results from T2V0 [20]. The figure visually demonstrates that MOTIONCRAFT produces more realistic and temporally consistent results than T2V0 [20], particularly in handling the generation of new content as the satellite moves, showing its superior capability in synthesizing complex motion dynamics.

This figure shows the ablation study on the cross-frame attention mechanism of MotionCraft. It compares four variations: no cross-frame attention, attending only to the initial frame, attending only to the previous frame, and attending to both the initial and previous frames (the proposed method). The results demonstrate that attending to both the initial and previous frames is crucial for generating consistent and plausible video frames.

This figure compares the results of MOTIONCRAFT and T2V0 in simulating a satellite orbiting Earth. The top row shows the video generated by MOTIONCRAFT, demonstrating consistent and coherent generation of new parts of the city as the satellite moves. The bottom row shows the corresponding video from T2V0, which exhibits inconsistencies and a lack of coherent content generation as the satellite moves.

This figure compares the results of MOTIONCRAFT and T2V0 for a fluid dynamics simulation of two dragons breathing fire. MOTIONCRAFT produces a more realistic and temporally consistent animation of the fire, including realistic changes in illumination and occlusion due to the smoke. In contrast, T2V0 shows inconsistencies, such as the dragons changing appearance over time and the lack of realistic occlusion.

This figure compares the results of revolving Earth simulation using MOTIONCRAFT and T2V0 methods. MOTIONCRAFT is able to generate a video of Earth rotating smoothly, and realistically generating new content as parts of Earth move out of frame and new parts move into frame, showcasing seamless transitions and content generation. In contrast, T2V0 struggles with temporal consistency and produces less coherent results, demonstrating MOTIONCRAFT’s superiority in handling complex motion dynamics.

This ablation study shows the effects of different cross-frame attention mechanisms on video generation quality. The first row shows results without using any cross-frame attention. The second and third rows demonstrate the effect of attending only to the initial or previous frame respectively. The last row demonstrates the results when attending to both the initial and previous frames, which is the method proposed in the paper.

This ablation study investigates the impact of the cross-frame attention mechanism on video generation quality. Four different configurations are compared: (1) no cross-frame attention; (2) attention only to the initial frame; (3) attention only to the previous frame; and (4) attention to both the initial and preceding frame (the proposed method in the paper). Visual results are shown for a satellite view of the earth and two other scenes demonstrating the superiority of the proposed approach.

This figure demonstrates a comparison of pouring a drink simulation using different methods. The first row shows the Eulerian simulation using the Φ-flow library. The second row displays the resulting optical flow generated from the simulation. The third row presents the video generated using MOTIONCRAFT, which uses this optical flow to manipulate the latent space of Stable Diffusion. The final row shows the result when the optical flow is applied directly to the pixel space of the image. This comparison highlights how MOTIONCRAFT generates a more realistic video compared to direct pixel-space manipulation by leveraging the generative model’s understanding of image structure and coherence.

This figure shows the results of simulating a melting man using two different approaches: Eulerian and Lagrangian simulations. The top two rows display the optical flow and resulting video frames from MOTIONCRAFT using an Eulerian simulation (fluid modeled as a set of particles). The bottom two rows show the same but using a Lagrangian simulation (fluid modeled as a field). The difference in the simulations results in different visualizations of the melting process.
Full paper#



















