↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Linear attention Transformer models have generally underperformed compared to conventional Transformer models. The Mamba model, a state-space model, has demonstrated impressive efficiency and accuracy in handling high-resolution images across various vision tasks. However, the factors behind Mamba’s success have remained unclear. This study addresses this gap by analyzing the similarities and differences between the effective Mamba model and subpar linear attention Transformer models. The researchers reformulate both models using a unified framework, revealing that Mamba is essentially a variant of linear attention Transformer with six key distinctions.
This paper meticulously analyzes each of the six distinctions: input gate, forget gate, shortcut, lack of attention normalization, single-head design, and modified block design. Through both theoretical analysis and empirical evaluation using vision tasks like image classification and high-resolution dense prediction, the study identifies the forget gate and block design as the core contributors to Mamba’s success. Building upon these findings, the researchers propose a new model, Mamba-Inspired Linear Attention (MILA), by incorporating these key design elements into linear attention. MILA demonstrates superior performance across various vision tasks while also exhibiting parallelizable computation and fast inference speeds, thus showcasing the potential of linear attention for advanced visual processing.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between high-performing state-space models and underperforming linear attention mechanisms in vision. By identifying key design choices that lead to Mamba’s success and incorporating them into a new model (MILA), this research unlocks new possibilities for efficient and effective visual processing, especially for high-resolution images. It offers a unified framework for understanding both model types, opening new avenues for model design and optimization within the vision domain. The improved speed and accuracy of MILA showcase its potential to advance various computer vision tasks.
Visual Insights#
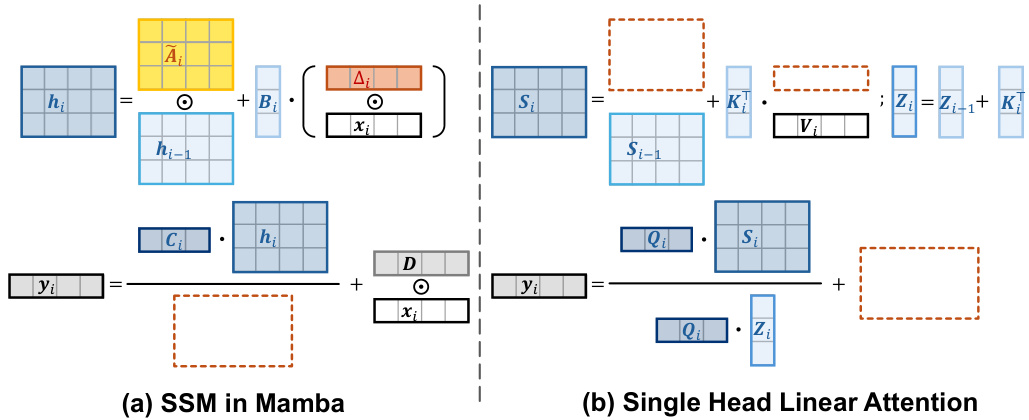
This figure illustrates the core similarities and differences between the selective state space model (SSM) in Mamba and the single-head linear attention mechanism. Panel (a) shows the SSM equations and architecture, highlighting the input gate (Ai), forget gate (A₁), and shortcut (Dx). Panel (b) shows the corresponding linear attention equations and architecture. The caption points out that the SSM closely resembles the linear attention but with the added gates and shortcut. The key difference is the absence of normalization (QiZi) in the SSM.
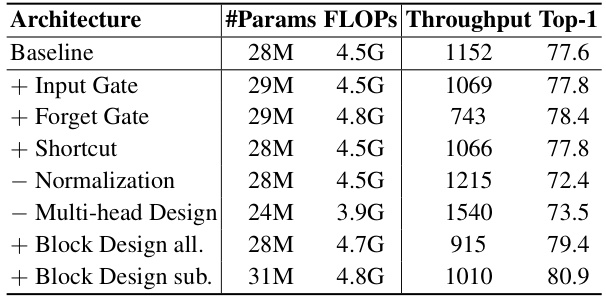
This table presents the results of ablation experiments conducted to assess the impact of six design choices in the Mamba model on ImageNet-1K classification. The baseline is a Swin Transformer model with Softmax attention replaced by linear attention. Each row adds or removes one of the Mamba design elements (input gate, forget gate, shortcut, normalization, multi-head design, and block design), showing the effect on the model’s performance in terms of parameters, FLOPs, throughput, and top-1 accuracy.
In-depth insights#
Mamba’s Linearity#
The core of Mamba’s efficiency lies in its linear time complexity, a stark contrast to the quadratic complexity of standard Transformers. This linearity stems from its innovative selective state space model, which cleverly reformulates attention mechanisms. Instead of computing all pairwise relationships between input tokens, Mamba selectively attends to relevant information, drastically reducing computational cost. This is achieved through a series of gating mechanisms and a modified block design that prioritizes efficiency without sacrificing representational power. Careful design choices, such as the forget gate, strategically control information flow, enabling faster convergence and reduced memory requirements. While the paper highlights a surprising similarity between Mamba and simpler linear attention transformers, Mamba’s unique architectural choices — particularly its selective nature and modified block structure — are key to its success, ultimately demonstrating that linear attention can achieve impressive performance in vision tasks. The careful balance of efficiency and performance makes Mamba a compelling alternative to traditional Transformers for various visual applications.
Gate Mechanisms#
Gate mechanisms are crucial for controlling information flow in neural networks. Input gates determine which information from the input is relevant and should be processed further, effectively filtering out noise or irrelevant features. Forget gates, conversely, decide what information from the previous state should be discarded, preventing the network from retaining outdated or unnecessary data, enabling it to adapt to new information. The effective use of gates significantly impacts a model’s ability to learn complex patterns, enhancing efficiency, and improving performance, particularly with high-resolution inputs and long sequences. The design and implementation of gate mechanisms are highly relevant to optimizing model architecture and the overall efficiency of the network. Understanding the interplay between input and forget gates is critical for creating robust and effective models; this interaction allows for selective memory and adaptation, leading to superior performance on complex tasks.
MILA: Improved Model#
The heading ‘MILA: Improved Model’ suggests a significant advancement over a previous model, likely referred to as Mamba in the context of the paper. MILA likely incorporates key improvements identified through a thorough analysis of Mamba’s strengths and weaknesses. This analysis probably involved a comparison with linear attention transformers to pinpoint the factors that contributed to Mamba’s effectiveness, specifically in handling high-resolution inputs for vision tasks. The improvements in MILA likely focus on addressing Mamba’s limitations, such as the computational cost associated with its recurrent calculation, and improve its performance in visual tasks like image classification and high-resolution dense prediction. The core improvements might involve changes to the block design and modifications to the forget gate mechanism which could result in a model that is both more efficient and more powerful than its predecessor. The name “MILA” itself suggests a lineage and an enhancement, implying a model that builds upon the established success of Mamba while adding a significant level of improvement.
Vision Task Results#
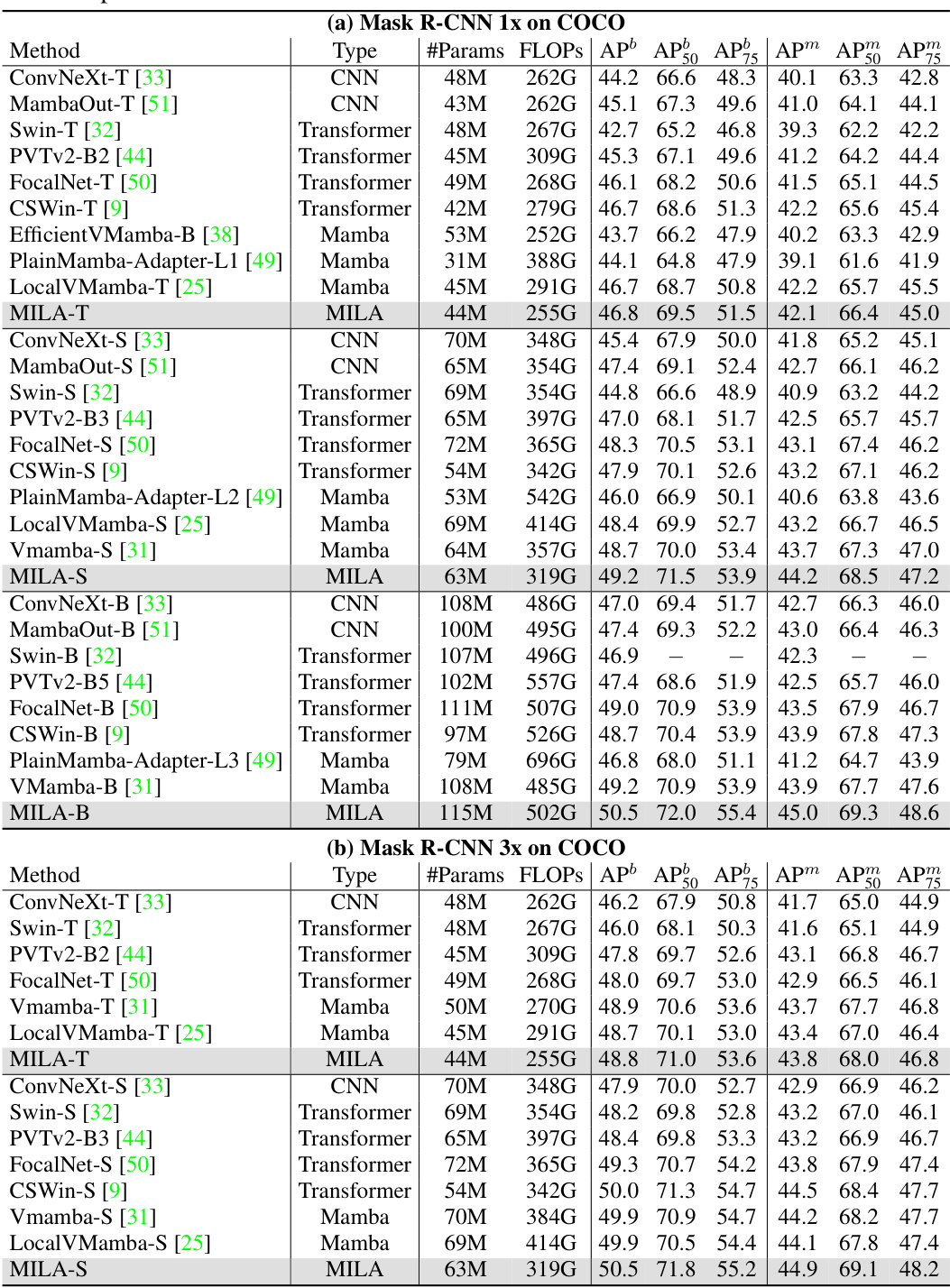
A dedicated ‘Vision Task Results’ section would ideally present a thorough evaluation of the proposed method across a range of standard vision tasks. Quantitative results, such as precision, recall, F1-score, and Intersection over Union (IoU) for object detection, or accuracy and mean Average Precision (mAP) for image classification, would be crucial. The results should be compared against state-of-the-art (SOTA) methods to establish the model’s effectiveness. Crucially, the choice of datasets used should be justified, reflecting diversity in image content and complexity to demonstrate generalizability. An analysis of performance across different subsets of the data (e.g., based on object size or image resolution) would provide further insight. Finally, the discussion should acknowledge limitations of the results, such as potential biases in the datasets or areas where the method underperforms, and suggest future research directions to overcome these limitations.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Extending MILA’s effectiveness to other modalities beyond vision, such as natural language processing or time series analysis, would be valuable. Investigating the impact of different positional encodings on MILA’s performance, particularly in scenarios where the forget gate is replaced, warrants further investigation. A deeper analysis of the interplay between the forget gate and block design, potentially exploring alternative mechanisms that achieve similar benefits, would enhance our understanding of Mamba’s success. Scaling MILA to extremely long sequences and evaluating its performance in such contexts is crucial for demonstrating its practical applicability. Finally, exploring the integration of multi-head attention within the MILA framework while maintaining computational efficiency is a significant challenge that deserves dedicated research effort.
More visual insights#
More on figures

This figure illustrates the selective state space model used in Mamba and its equivalent reformulation. The left side shows the selective SSM model with input-dependent parameters Ai, Bi, and Ci. The right side shows an equivalent form, making the formulas easier to analyze and compare with the linear attention formulation. It highlights the key components of how the hidden state (hi) is updated based on the previous hidden state (hi-1) and current input (xi). The output (yi) is then calculated from the updated hidden state and input. The figure’s purpose is to simplify the understanding of the Mamba model’s core operations before connecting them to linear attention.

This figure compares the macro architecture designs of three different model types: Linear Attention Transformer, Mamba, and MILA (the proposed model). It visually represents the arrangement of blocks and layers within each architecture, highlighting their similarities and differences. Each model’s architecture is displayed as a sequence of blocks, including linear attention, multi-layer perceptrons (MLPs), normalization layers, and convolutional layers. The figure effectively illustrates the modifications and additions introduced in MILA to improve upon both the Linear Attention Transformer and Mamba architectures.

This figure shows visualizations and analyses of the input and forget gate values in the Mamba model. (a) shows examples of input gate value distributions across different image regions. (b) illustrates how the average forget gate value changes across different model layers. (c) demonstrates the effect of different forget gate values on the model’s output, showing how higher values lead to more attenuation of previous hidden states.

This figure shows the standard deviation of token lengths in different layers of a model with and without attention normalization. The standard deviation of token lengths in the model without normalization is significantly larger, especially in the last two layers, indicating that longer tokens tend to dominate the whole feature map, while shorter tokens may fail to represent their corresponding semantics. The normalization helps to alleviate this issue.
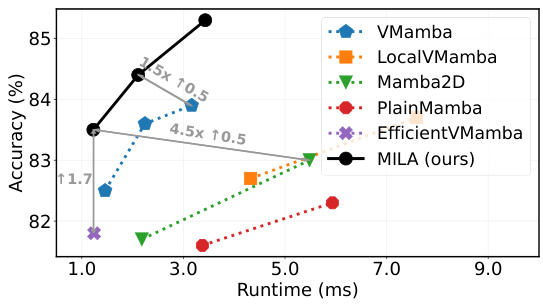
This figure shows the trade-off between accuracy and inference speed for different vision Mamba models and the proposed MILA model on a RTX3090 GPU. The x-axis represents inference time in milliseconds, and the y-axis represents the top-1 accuracy on ImageNet. MILA significantly outperforms other models in terms of both accuracy and speed, demonstrating the effectiveness of the proposed improvements.
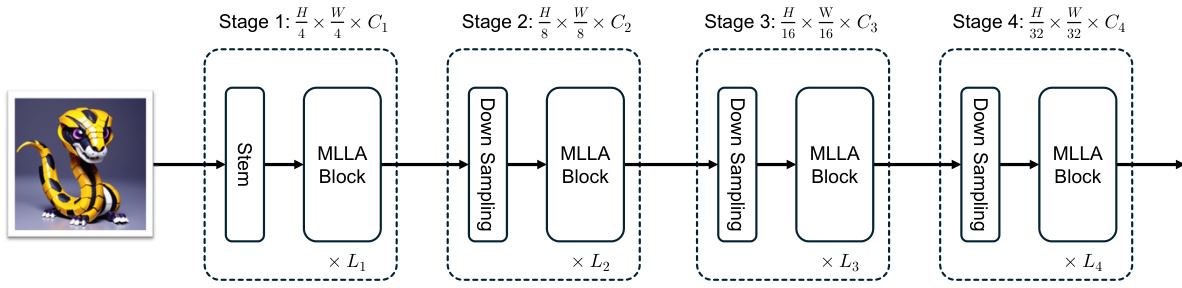
This figure compares the macro architecture designs of three different models: Linear Attention Transformer, Mamba, and MILA (the authors’ proposed model). Each model is represented visually with blocks that indicate different operations (linear layers, MLPs, normalization, etc.). The figure illustrates how MILA incorporates design elements from both linear attention Transformers and Mamba to create its architecture, highlighting the differences in the overall design and the ways in which the blocks are arranged and connected. The goal of the figure is to visually demonstrate the relationships and differences between the models at a high level.
More on tables
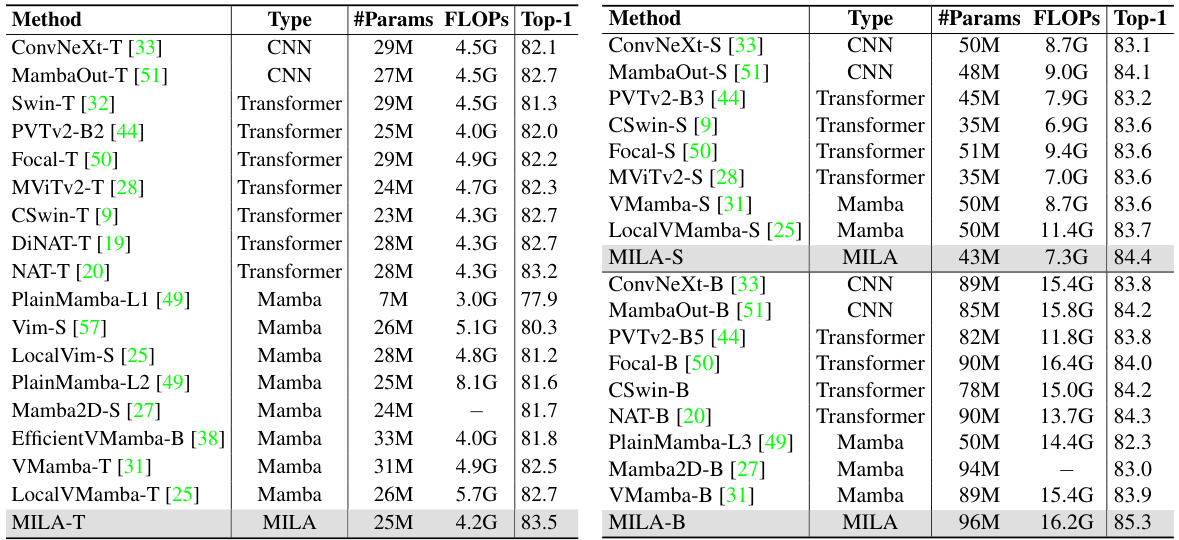
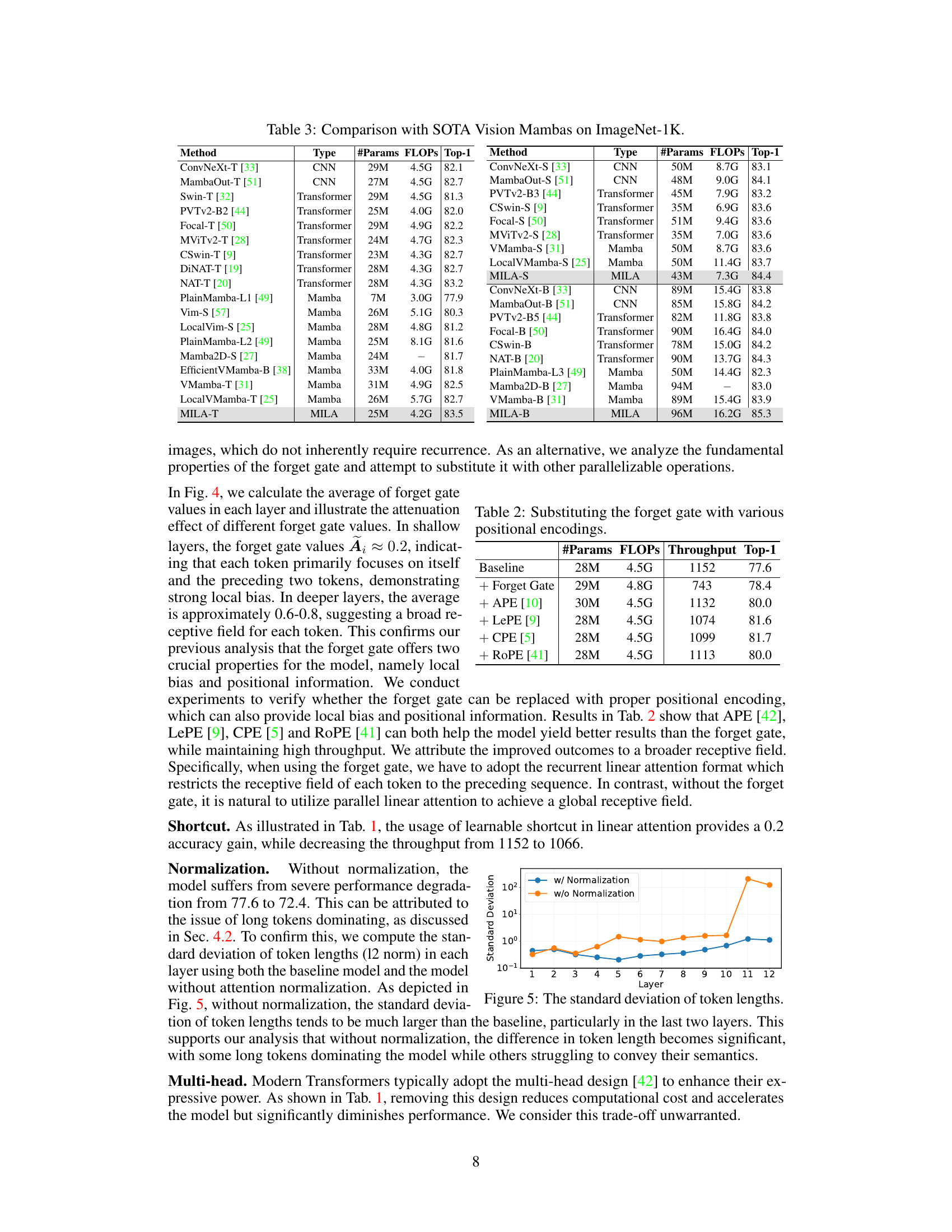
This table compares the performance of the proposed MILA model with other state-of-the-art vision Mamba models on the ImageNet-1K dataset. It shows the number of parameters, FLOPS (floating point operations per second), and top-1 accuracy for each model. The table highlights MILA’s superior performance and scalability across various model sizes.
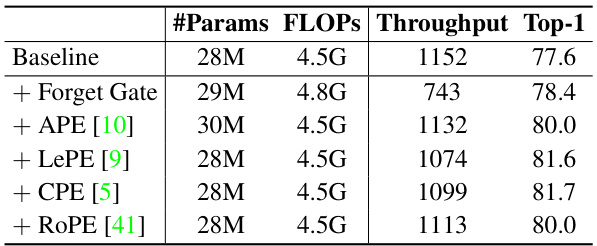
This table presents the results of an ablation study on ImageNet-1K, evaluating the impact of six design distinctions between Mamba and linear attention Transformer. The baseline model uses linear attention. Each row adds one of the following: input gate, forget gate, shortcut, normalization, multi-head design, and the Mamba block design (two variants). The table shows the model’s #Params, FLOPs, throughput, and Top-1 accuracy for each variation. This allows for assessing the relative contribution of each design choice to the overall performance.
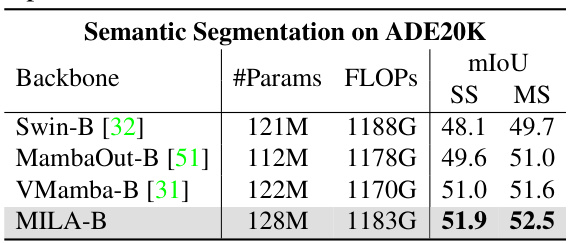
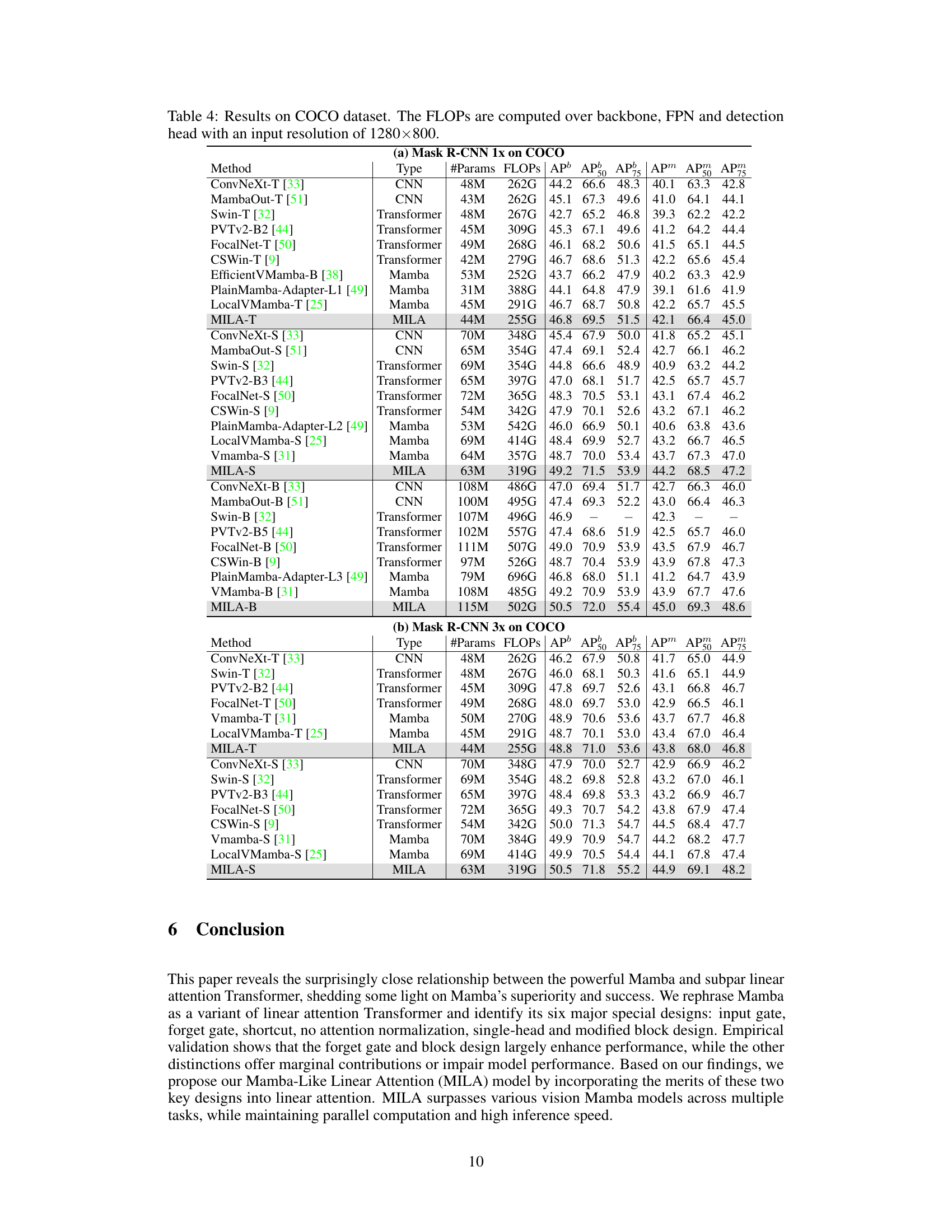
This table presents the results of semantic segmentation on the ADE20K dataset using the UperNet model. It compares the performance of different backbones (Swin-B, MambaOut-B, VMamba-B, and MILA-B) in terms of model parameters (#Params), floating-point operations (FLOPs), and mean Intersection over Union (mIoU) scores. The mIoU is reported for both single-scale (SS) and multi-scale (MS) inference.
This table presents the ablation study results on ImageNet-1K, evaluating the impact of six design choices (input gate, forget gate, shortcut, normalization, multi-head design, and block design) on the baseline linear attention model. It shows the number of parameters, FLOPs (floating point operations), throughput, and Top-1 accuracy for each variation. The results highlight the relative importance of each design choice in improving the model’s performance.
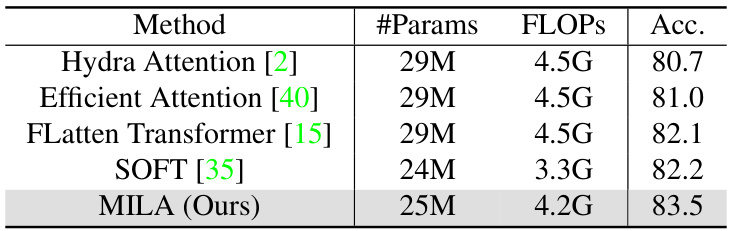
This table compares the performance of MILA with other advanced linear attention methods on ImageNet-1K classification. It shows that MILA achieves a higher accuracy (83.5%) than the other methods, while maintaining a relatively low number of parameters and FLOPs. This highlights MILA’s effectiveness and efficiency compared to state-of-the-art linear attention approaches.

This table presents the results of MILA models trained without the MESA (an overfitting prevention strategy) technique. It compares the performance of MILA models (with and without MESA) to other vision Mamba models, showcasing the effectiveness of the MILA models even without MESA. The table includes the number of parameters, FLOPs (floating-point operations), and top-1 accuracy for each model. The results highlight that MILA models consistently achieve higher accuracy than the other Vision Mamba models, suggesting its robustness and efficiency.

This table presents the results of ablation studies performed on ImageNet-1K to evaluate the impact of six design choices differentiating Mamba from a standard linear attention Transformer. The baseline is a Swin Transformer with Softmax attention replaced by linear attention. Each row adds one Mamba design choice (input gate, forget gate, shortcut, normalization, multi-head, block design). The table shows the number of parameters, FLOPs (floating-point operations), throughput (images/second), and Top-1 accuracy for each model variant.
Full paper#