↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current novel view synthesis methods struggle with noisy raw images, especially 3D Gaussian Splatting (3DGS), leading to poor reconstruction and slow speeds. This is particularly problematic in scenarios with limited training views, hindering real-world applications. The inherent noise in raw images significantly degrades the quality and speed of 3DGS. The presence of noise causes 3DGS to produce numerous thin and elongated Gaussian shapes, impacting visual quality and inference speed.
To tackle this, the authors introduce a novel self-supervised learning framework. This framework integrates a noise extractor and employs a robust reconstruction loss function that leverages a noise distribution prior. Experiments demonstrate that the proposed method surpasses existing state-of-the-art methods in reconstruction quality and inference speed, particularly when training with limited views. The superior performance stems from the joint denoising and reconstruction approach, which effectively separates noise from the raw image data before 3DGS reconstruction, improving quality and speed across a broad range of training views.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on novel view synthesis and 3D scene representation, particularly those using raw images. It directly addresses the challenges of noise in raw images, a significant hurdle in achieving high-quality and real-time 3D reconstruction. The proposed method offers a significant advancement in HDR 3D reconstruction from limited views, opening new avenues for research in computer vision and graphics. Furthermore, the open-source code release greatly benefits the research community.
Visual Insights#
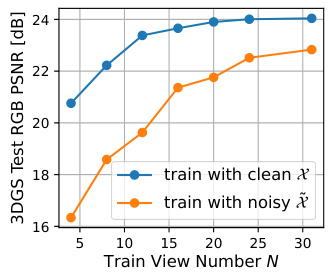
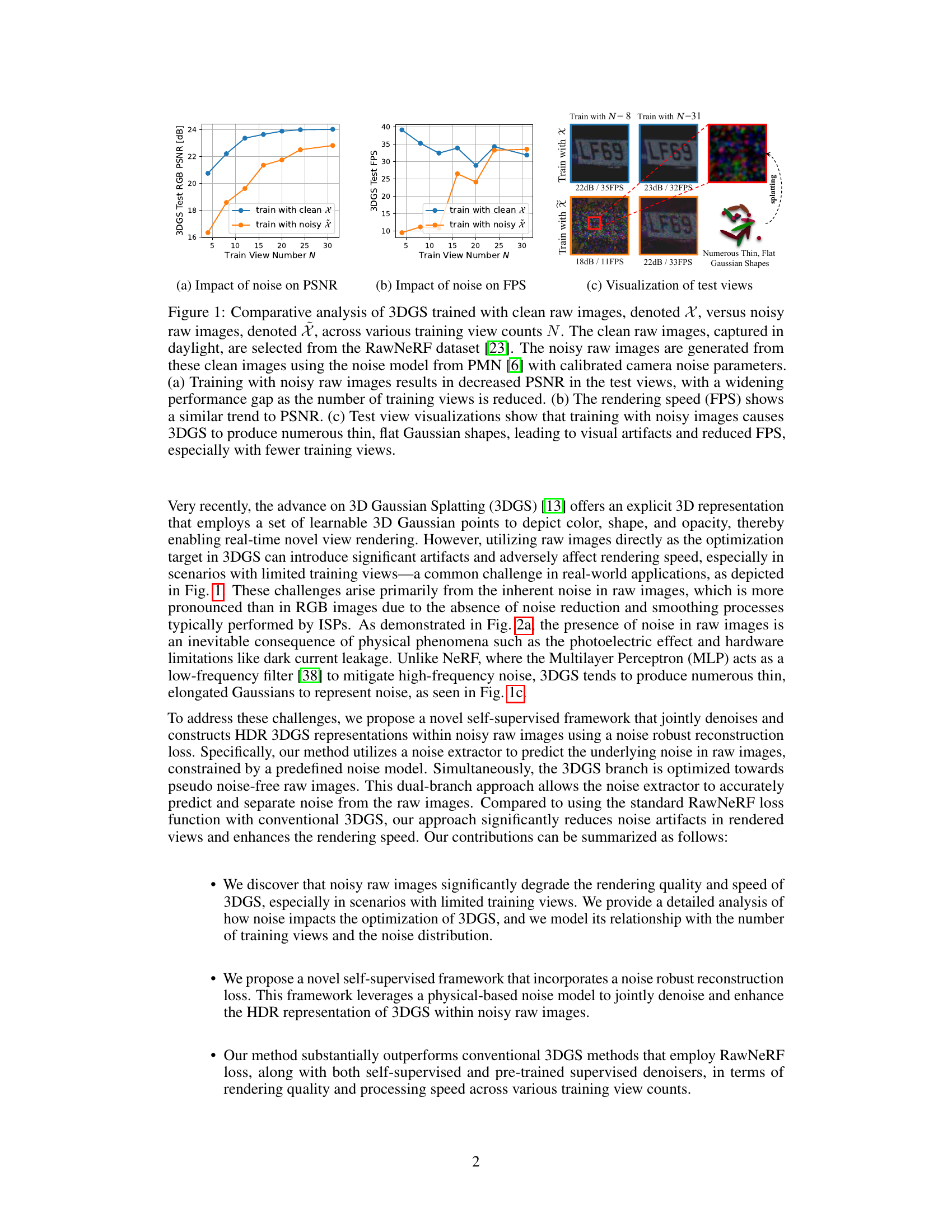
This figure presents a comparative analysis of 3D Gaussian Splatting (3DGS) trained on clean versus noisy raw images. It shows that training with noisy raw images leads to a significant decrease in Peak Signal-to-Noise Ratio (PSNR) and Frames Per Second (FPS), especially when the number of training views is limited. The visualization demonstrates that the noisy training data causes 3DGS to generate numerous thin and flat Gaussian shapes, resulting in visual artifacts.

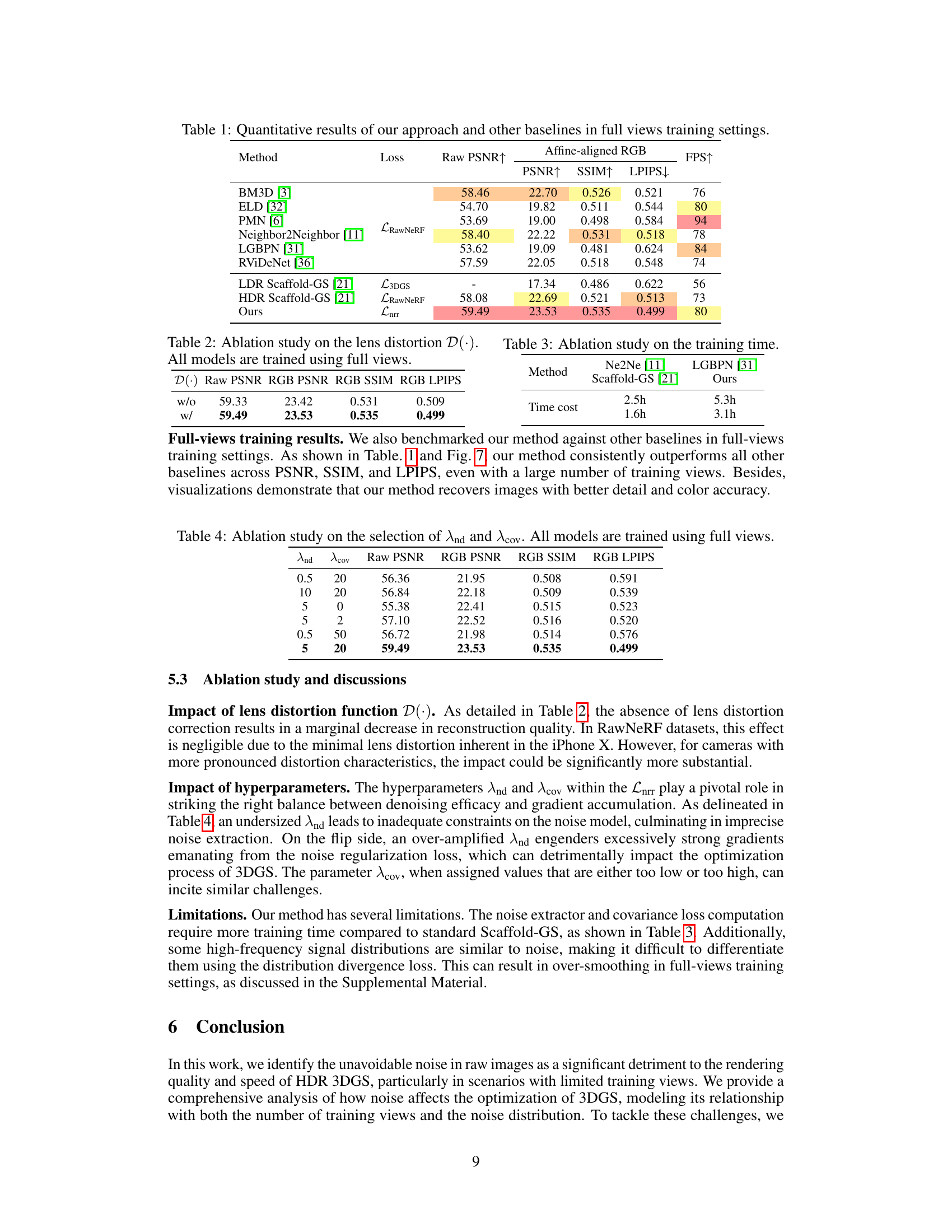
This table presents a quantitative comparison of the proposed method with various baselines in terms of rendering quality metrics (PSNR, SSIM, LPIPS) and speed (FPS) when trained with full views. The baselines include traditional and deep-learning-based denoisers, as well as LDR and HDR versions of Scaffold-GS. It highlights the superior performance of the proposed method across all metrics.
In-depth insights#
Raw 3DGS Denoising#
The concept of “Raw 3DGS Denoising” presents a crucial challenge and opportunity in 3D scene reconstruction. Raw images, while containing rich HDR information, are inherently noisy, significantly impacting the performance of 3D Gaussian Splatting (3DGS). Directly applying 3DGS to raw data results in numerous thin, elongated Gaussian shapes that overfit the noise, leading to poor reconstruction quality and slow inference speeds. Therefore, effective denoising strategies are critical for leveraging the benefits of raw data with 3DGS. A promising approach involves a self-supervised learning framework, trained to predict and remove noise from raw images prior to 3DGS reconstruction. This framework could incorporate a noise model informed by the physics of image acquisition, potentially using a noise extractor network coupled with a noise-robust loss function. This technique would enable the reconstruction of high-quality HDR 3D scenes even from noisy raw images, thereby improving rendering quality and inference speed. Furthermore, the success of this approach depends on careful consideration of various noise sources and efficient separation techniques, potentially incorporating lens distortion correction for a more realistic model. The key to success lies in balancing noise removal with the preservation of essential scene details.
Noise Robust Loss#
The concept of a ‘Noise Robust Loss’ function in the context of 3D Gaussian Splatting (3DGS) for novel view synthesis from raw images is crucial. Raw images, while offering superior high dynamic range (HDR) information, are inherently noisy. A standard loss function would penalize the reconstruction based on this noise, leading to inaccuracies and overfitting. Therefore, a robust loss function is designed to disentangle the noise from the actual scene signal. This often involves a noise estimation component, typically a separate neural network, predicting the noise distribution in the raw images. The loss is then calculated between the denoised raw image and the 3DGS reconstruction, rather than directly comparing the noisy input and the output. This approach ensures that the loss function focuses on accurately representing the underlying scene, ignoring the spurious noise fluctuations, leading to higher-quality reconstructions with improved visual fidelity. Furthermore, such a loss function might incorporate a regularization term to control noise patterns, such as minimizing spatial correlations between noise estimations to prevent the 3DGS model from learning and reproducing the noise itself. The success of a noise-robust loss relies heavily on the accuracy and efficiency of the noise estimation model and its seamless integration with the main 3DGS loss, enabling a fast and accurate novel view synthesis process.
Limited View 3DGS#
The concept of ‘Limited View 3DGS’ explores the challenges and potential solutions when reconstructing 3D scenes using Gaussian Splatting (3DGS) with a restricted number of input views. This scenario is particularly relevant in real-world applications where acquiring many viewpoints might be impractical or costly. The core problem lies in the inherent limitations of 3DGS in handling noise, especially when data is scarce. With fewer views, the algorithm struggles to differentiate between actual scene details and noise, leading to artifacts and inaccurate reconstructions. Researchers are actively investigating techniques like noise-robust loss functions and self-supervised learning to mitigate these issues. These methods aim to improve both the quality and speed of 3D model generation, even under limited view conditions. Data augmentation, using noise models to generate synthetic noisy images during training, could potentially aid in robust model creation. The research into ‘Limited View 3DGS’ promises to expand the practical applications of 3DGS by enhancing its resilience to real-world data constraints.
Lens Distortion Fix#
The heading ‘Lens Distortion Fix’ suggests a crucial preprocessing step in 3D scene reconstruction from raw images. Accurate lens distortion correction is vital because raw images, unlike processed RGB images, lack the lens distortion correction applied during standard image processing pipelines. Therefore, failing to correct for lens distortion will lead to inaccurate 3D scene representations, affecting the accuracy of depth estimations and overall 3D model quality. The method employed likely involves a distortion map, a pre-computed transformation that maps distorted pixel coordinates to their undistorted counterparts. This correction is essential for algorithms like 3D Gaussian Splatting which rely on precise geometric correspondences between different views to accurately reconstruct the 3D scene. The effectiveness of any distortion correction technique should be evaluated by assessing its impact on the final 3D model’s accuracy and whether it introduces any additional artifacts or computational overhead. A high-quality lens distortion correction is fundamental to ensuring that downstream processes, such as 3D reconstruction, produce high-fidelity results.
Future Enhancements#
Future enhancements for this research could explore several promising avenues. Improving the noise model by incorporating more sophisticated representations of real-world noise patterns, especially in challenging conditions like low-light scenarios or high-motion sequences, would greatly improve robustness. Expanding the framework’s applicability to other 3D reconstruction techniques beyond 3D Gaussian Splatting, potentially adapting it for neural radiance fields (NeRFs) or other implicit or explicit methods, would broaden its impact. Investigating alternative loss functions that are less sensitive to outliers or noise could further enhance the accuracy and efficiency of the reconstruction process. A key area for future work is developing more robust lens distortion correction techniques, addressing limitations of current methods and improving the fidelity of the final reconstruction, especially in challenging scenarios with significant lens distortions. Finally, exploring efficient techniques for handling large-scale scenes or incorporating temporal information for video processing is crucial for real-world applications.
More visual insights#
More on figures

This figure compares the performance of 3DGS trained on clean vs. noisy raw images. It shows that noisy images significantly reduce PSNR and FPS (frames per second), especially when training data is limited. The visualization shows that noisy training data leads to numerous thin, flat Gaussian shapes in the 3D model, degrading reconstruction quality and speed.
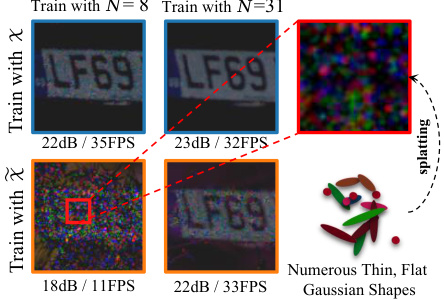
This figure presents a comparative analysis of 3D Gaussian Splatting (3DGS) trained with clean versus noisy raw images, showing the impact of noise on PSNR (peak signal-to-noise ratio), FPS (frames per second), and visual quality across different numbers of training views. The results demonstrate that noise significantly degrades the performance of 3DGS, particularly when the number of training views is limited. Training with noisy data leads to lower PSNR, lower FPS, and the creation of numerous thin and elongated Gaussian shapes in the 3D representation, leading to visual artifacts.
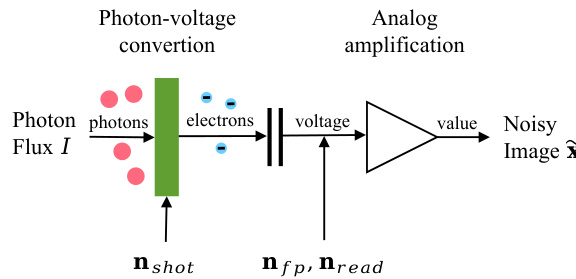
This figure illustrates how noise affects the 3DGS optimization process. Panel (a) shows the different noise sources introduced during image capture, from photon flux to the final noisy image. Panel (b) focuses on a single point in the 3D scene and shows how noise from multiple noisy raw images affects the optimal target for 3D Gaussian Splatting reconstruction.

This figure illustrates how noise affects the 3D Gaussian Splatting (3DGS) optimization process. Panel (a) shows the stages of image capture where noise is introduced. Panel (b) shows how noise in multiple raw images of the same scene point (r) leads to a variance in the optimal target for 3DGS, which is represented as the discrepancy between the clean pixel intensity and the expected value of the noisy pixel intensities.

This figure shows how a 3D Gaussian Splatting (3DGS) model’s reconstruction changes over training iterations. Initially, the model accurately represents the scene. As training progresses, the model starts to fit the noise in the raw image data, leading to a less accurate and more noisy representation.
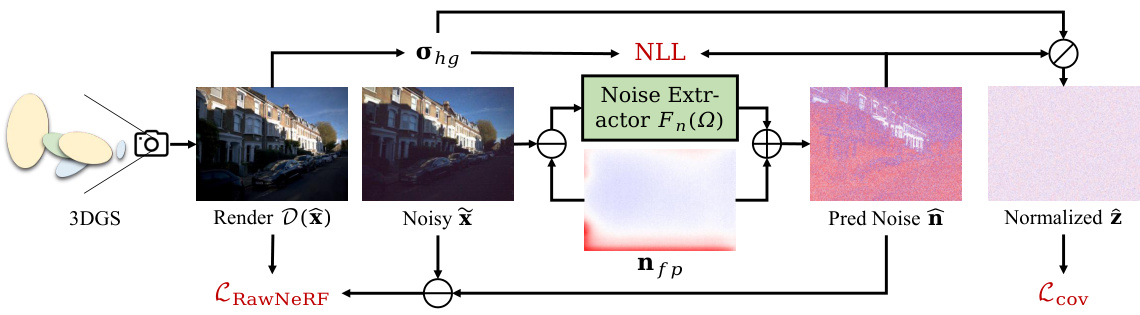
This figure illustrates the proposed noise-robust reconstruction loss function, Lnrr. It’s composed of three parts: the RawNeRF reconstruction loss (comparing the rendered, distortion-corrected image to a denoised version of the input), the negative log-likelihood (NLL) loss (measuring the difference between the predicted noise and the expected noise distribution), and the covariance loss (Lcov) (penalizing spatial correlations in the predicted noise). The process starts with a noisy raw image which passes through a noise extractor to produce an estimate of the noise. This noise estimate is used to calculate the NLL and Lcov losses, and the denoised image is used for the RawNeRF loss. The three losses are combined to form the final Lnrr loss, which guides the training process of the 3DGS model.

The figure shows a comparative analysis of different methods for 3D Gaussian Splatting (3DGS) in terms of PSNR, SSIM, LPIPS, and FPS. The x-axis represents the number of training views, and the y-axis shows the performance metrics. The results are broken down for different methods, including baselines that use RGB images, two-stage methods combining denoising and 3DGS, and the authors’ proposed method. The graph helps visualize how the number of training views affects the quality and speed of 3D scene reconstruction with 3DGS, demonstrating the improvement achieved by the authors’ noise-robust approach.
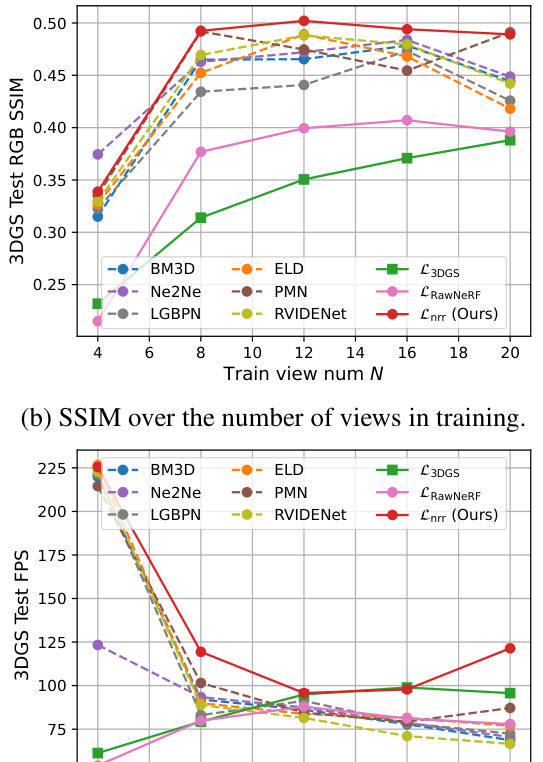
This figure presents a comparative analysis of different methods for 3D Gaussian Splatting (3DGS) in terms of rendering quality and speed, specifically focusing on scenarios with limited training views. The methods compared include various baselines and the proposed method. The metrics used for evaluating rendering quality include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Frames per second (FPS) is used to measure speed. The results show that the proposed method outperforms all baselines across various metrics and view counts, highlighting its effectiveness in limited data scenarios.

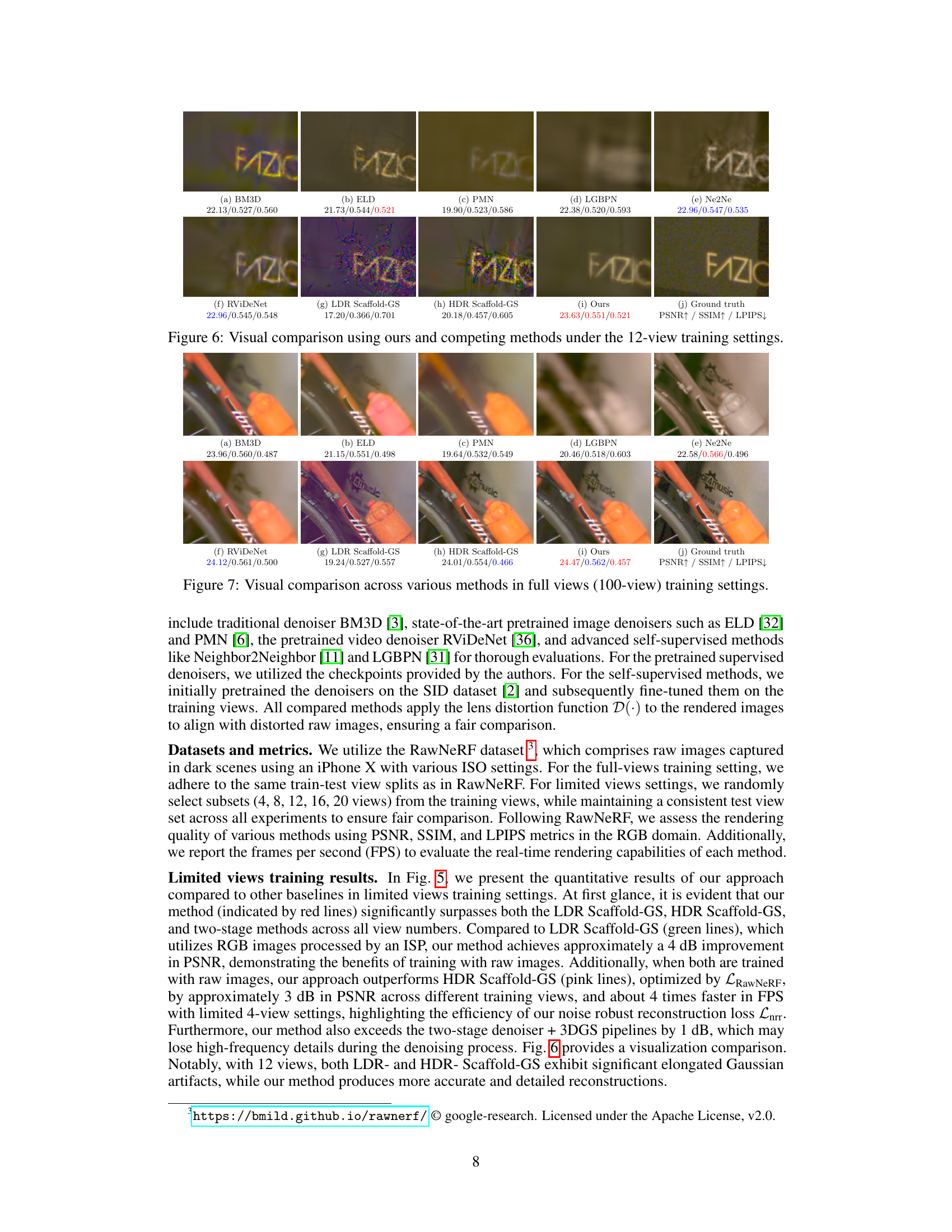
This figure provides a visual comparison of the proposed method against several competing methods under limited training views (12 views). It shows that the proposed method produces significantly higher-quality images, demonstrating its ability to effectively handle noise and reconstruct detailed scenes, unlike the other methods, that either exhibit noise artifacts or overly smooth results. The PSNR, SSIM, and LPIPS values are included beneath each image for quantitative comparison.

This figure presents a visual comparison of different novel view synthesis methods on the ‘ar4music’ scene from the RawNeRF dataset. The methods compared include traditional denoisers (BM3D, ELD, PMN, LGBPN), a self-supervised denoiser (Ne2Ne), a video denoiser (RViDeNet), and 3DGS models (LDR and HDR Scaffold-GS), along with the proposed method. The comparison shows the visual quality of the rendered images and highlights the improvement achieved by the proposed approach in terms of detail, color accuracy and noise reduction compared to existing methods. The PSNR, SSIM and LPIPS metrics are also provided for each method.

This figure shows a comparison of results from HDR Scaffold-GS and the proposed method on a scene with reflective surfaces. While the proposed method achieves higher PSNR by reducing noise artifacts, it produces overly smooth results in reflective areas, indicating a limitation of the approach in handling such scenarios.

This figure showcases a comparison between the proposed method and HDR Scaffold-GS on the RawNeRF dataset. While the proposed method achieves higher PSNR by reducing noise artifacts, it results in overly smoothed images, particularly in areas containing reflections, highlighting a limitation where high-frequency details are lost in the smoothing process. The images depict a piano with its brand name visible. The top images are close-up views of the piano’s nameplate, and the bottom images are zoomed-in views of the same region, showcasing the differences in rendering quality between the two methods.

This figure compares the results of RawNeRF, HDR Scaffold-GS, and the proposed method on a scene with full views training. The zoomed-in images highlight the difference in noise handling. RawNeRF utilizes an MLP, effectively acting as a low-pass filter, reducing noise impact. HDR Scaffold-GS shows increased sensitivity to noise, creating thin, flat Gaussian shapes in the rendering. In contrast, the proposed method better handles the noise, resulting in a cleaner image and improved rendering speed.
More on tables

This table presents a quantitative comparison of the proposed method against various baselines in terms of PSNR, SSIM, LPIPS, and FPS metrics. The comparison is conducted using a full-view training setting. The results demonstrate the superior performance of the proposed approach in terms of rendering quality and speed.
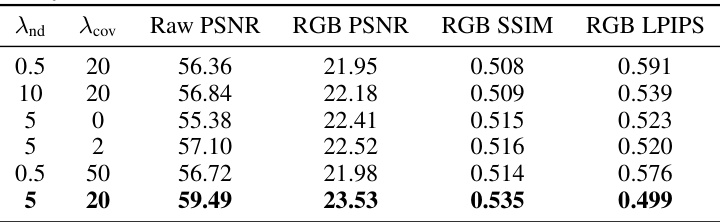
This table presents the results of an ablation study conducted to determine the optimal values for the hyperparameters λnd and λcov used in the noise-robust reconstruction loss function (Lnrr). The study varied these parameters across different settings while training models using all available views. The results are evaluated using Raw PSNR, RGB PSNR, RGB SSIM, and RGB LPIPS metrics, providing insights into the effect of different weighting schemes for the noise components on the overall model performance.

This table presents a quantitative comparison of different methods on the LLFF dataset using only 3 training views. The metrics used are Raw PSNR, RGB PSNR, and FPS, providing a comparison of reconstruction quality and rendering speed across various methods, including BM3D, PMN, Neighbor2Neighbor, FSGS, and the authors’ proposed method. The table also shows results for different downsampling ratios (1/4 and 1/8) of the input resolution. The results demonstrate the performance differences across the different approaches and conditions.
Full paper#