↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multi-modal models struggle with the inherent difference between 2D non-causal image processing and 1D causal text processing. Existing 1D causal vision models suffer from an ‘over-focus’ issue where attention concentrates on a small part of the image, hindering feature extraction and optimization. This limits their ability to represent images effectively in unified multi-modal systems.
To address this, the researchers introduce De-focus Attention Networks. These networks employ learnable bandpass filters to create diverse attention patterns, preventing over-focus. They also incorporate large drop path rates and an auxiliary loss for global understanding tasks, further improving optimization and broader token attention. Extensive experiments demonstrate that this approach achieves performance comparable to 2D non-causal methods across various tasks, including global perception, dense prediction, and multi-modal understanding. This work significantly advances the use of 1D causal modeling for visual representation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the performance gap between 1D causal and 2D non-causal vision models by introducing De-focus Attention Networks. This opens exciting new avenues for research in unified multi-modal models, which are currently a major focus in the field. The findings could lead to more efficient and effective visual representation learning methods.
Visual Insights#
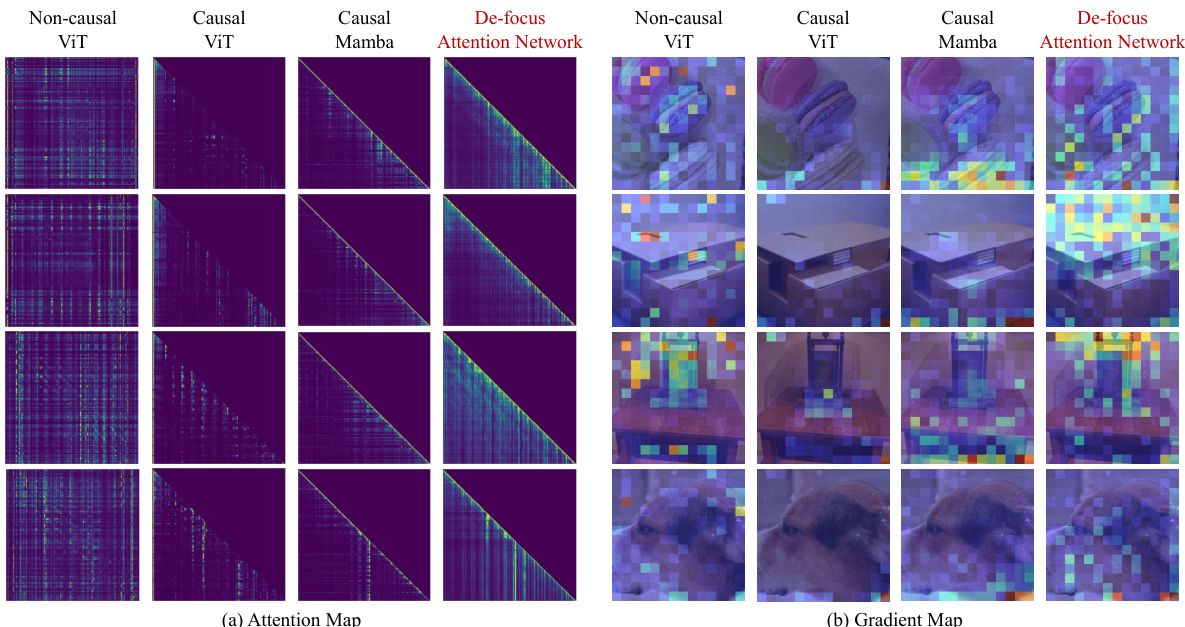
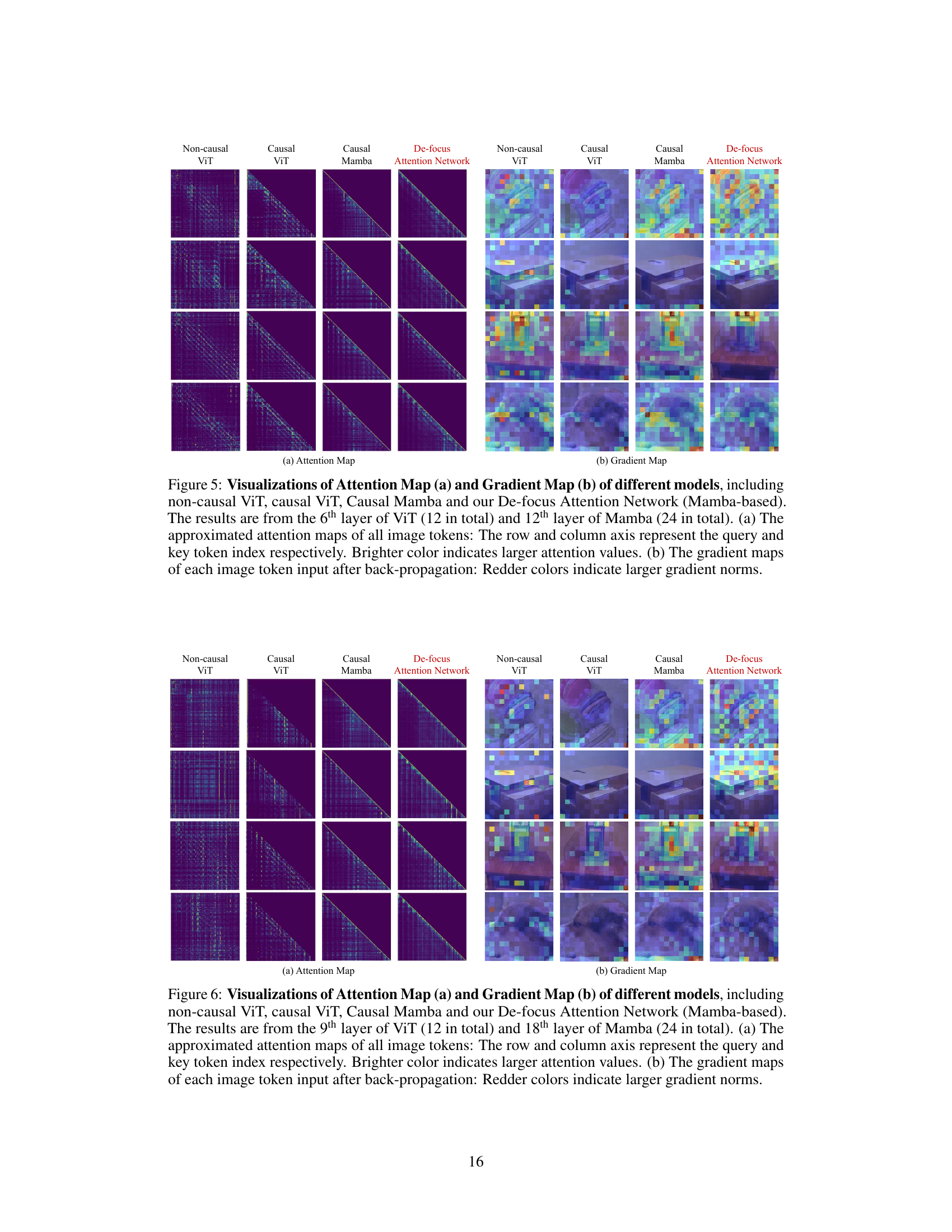
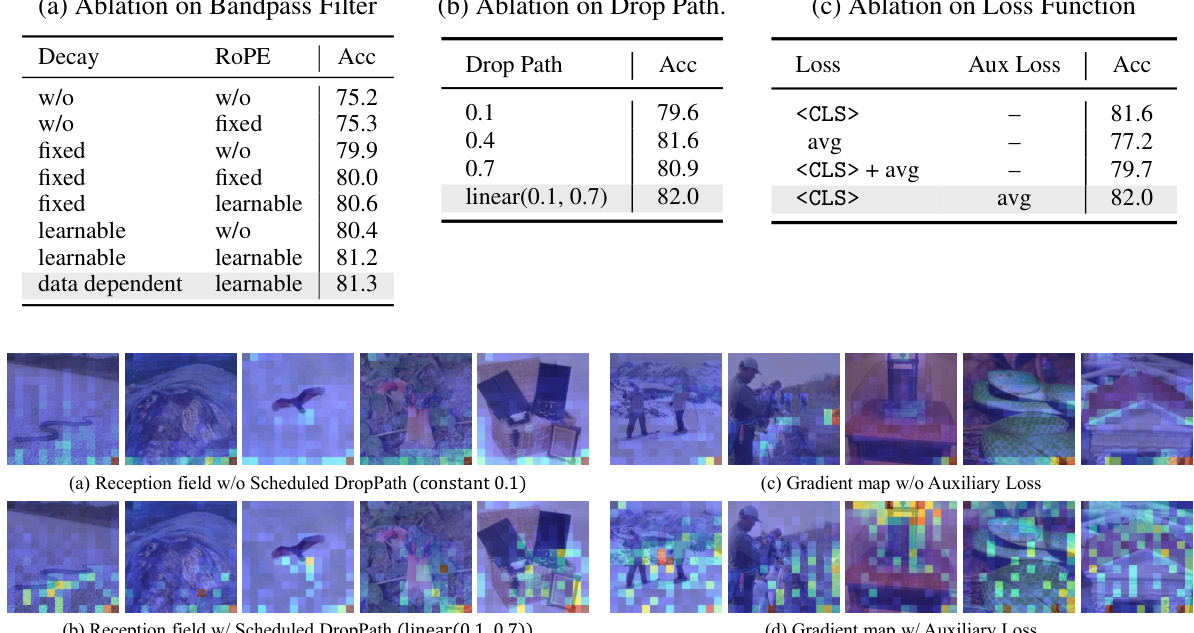
This figure visualizes attention maps and gradient maps for four different models: Non-causal ViT, Causal ViT, Causal Mamba, and the proposed De-focus Attention Network. The attention maps show where the model focuses its attention, highlighting the ‘over-focus’ issue in 1D causal models. The gradient maps show how gradients flow during backpropagation, illustrating the impact of over-focus on model optimization.
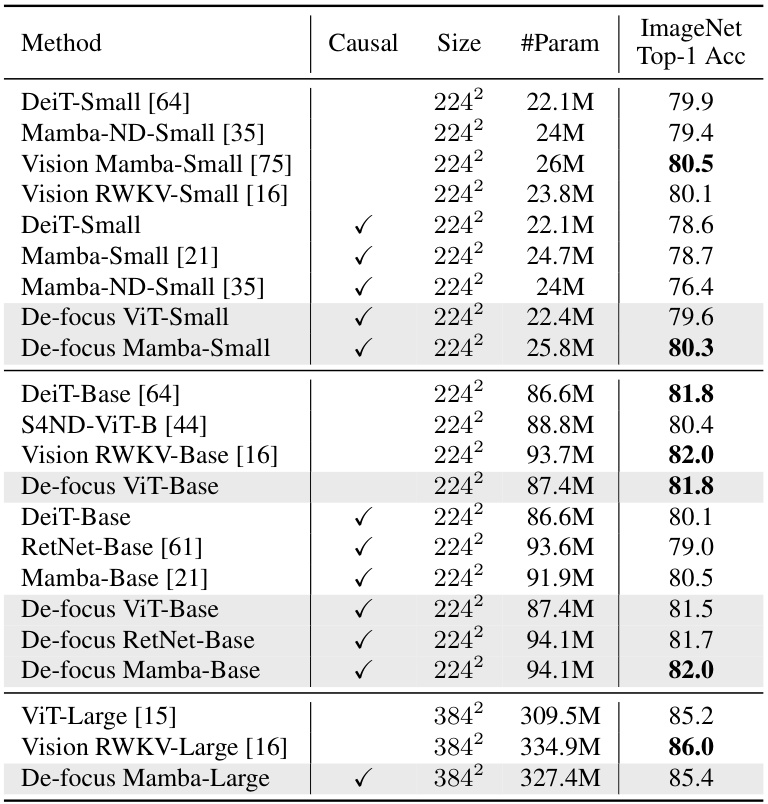
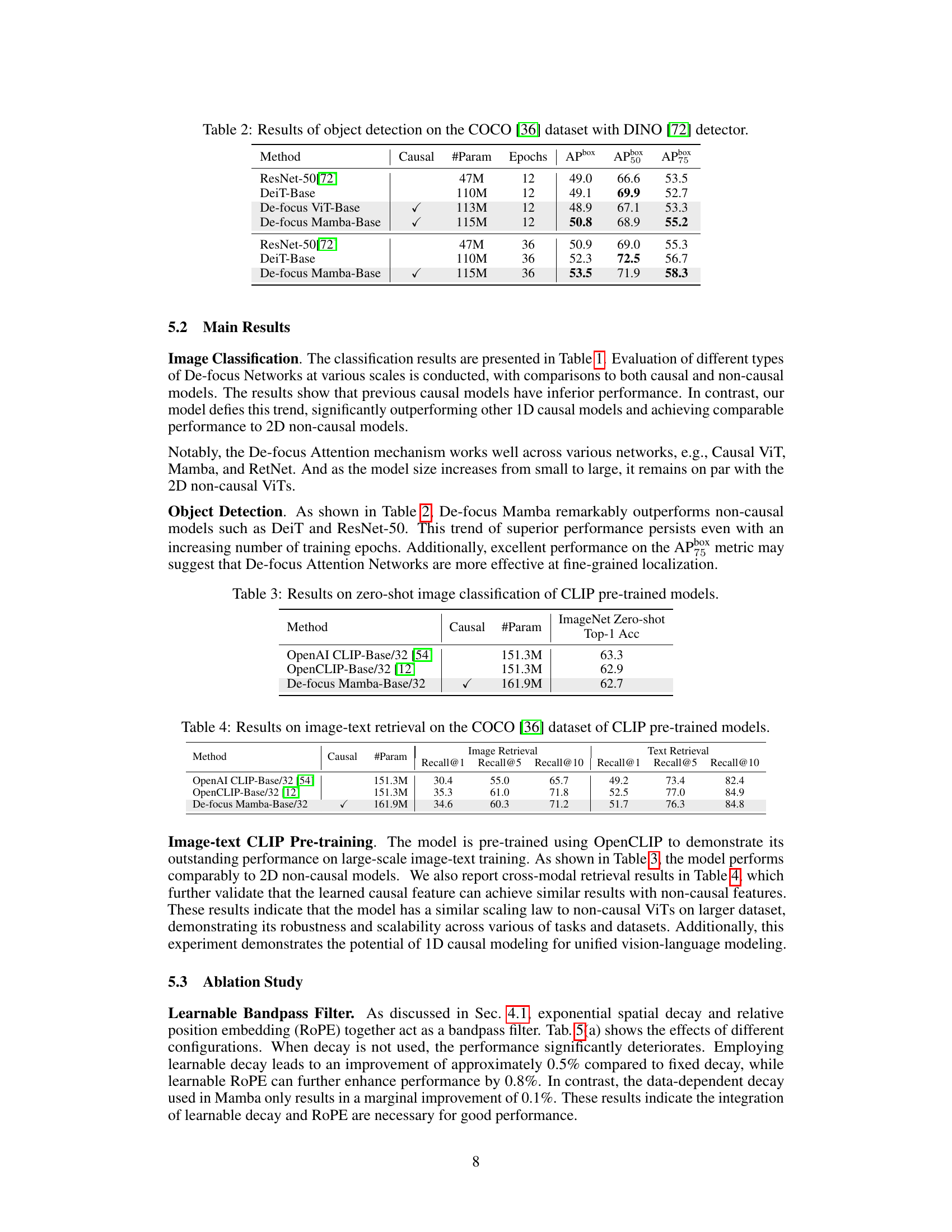
This table compares the top-1 accuracy on ImageNet-1K for various image classification models. It contrasts causal models (indicated by a checkmark in the ‘Causal’ column) against non-causal models. The table includes details on model size (Size), number of parameters (#Param), and the achieved top-1 accuracy. The results show a performance comparison between different model architectures, highlighting the performance of the proposed De-focus Attention Networks.
In-depth insights#
1D Causal Vision#
The concept of “1D Causal Vision” represents a significant paradigm shift in computer vision, challenging the conventional reliance on 2D non-causal models. It leverages the strengths of 1D causal modeling, primarily used in natural language processing, to process visual data sequentially. This approach has the potential to simplify model architectures, improve efficiency, and facilitate better integration with language models in multi-modal applications. However, a major hurdle is the “over-focus” problem, where attention mechanisms concentrate excessively on limited visual information, hindering the extraction of diverse features. Addressing this challenge, as explored in this paper, is crucial to fully realizing the potential of 1D causal vision. Successfully overcoming this limitation would lead to a more unified and streamlined multi-modal AI landscape, with implications for various tasks such as image classification, object detection, and image-text retrieval. The efficacy of 1D causal vision hinges on developing novel techniques to effectively guide attention and mitigate the over-focus issue. The proposed method of incorporating learnable bandpass filters, combined with optimization strategies such as scheduled drop path rates and an auxiliary loss, aims to address this challenge, resulting in comparable or superior performance compared to conventional 2D methods.
De-focus Attention#
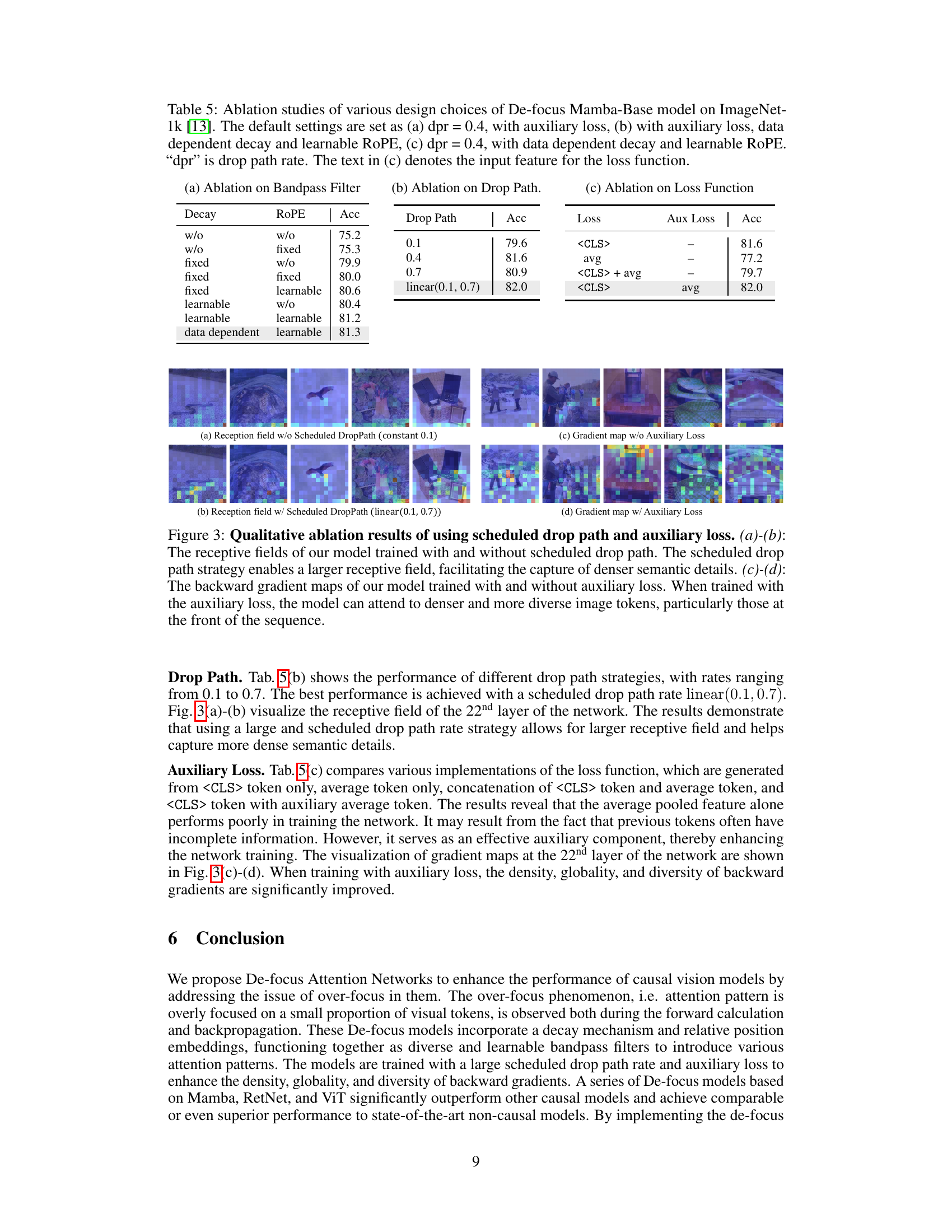
The concept of “De-focus Attention” presents a novel approach to addressing the limitations of 1D causal vision models. Standard 1D models often suffer from an “over-focus” issue, where attention mechanisms concentrate excessively on a small subset of visual tokens, hindering feature diversity and gradient optimization. De-focus Attention mitigates this by incorporating learnable bandpass filters. These filters create varied attention patterns, ensuring that even if over-focusing occurs in one filter, the overall attention remains diverse due to contributions from other filters with different frequency responses. This approach is further enhanced by employing large, scheduled drop path rates during training. This encourages the model to attend to a broader range of tokens, promoting robustness and preventing over-reliance on network depth. Finally, an auxiliary loss function applied to globally pooled features further improves optimization, particularly by enriching the gradients used in backpropagation. This is crucial as it ensures that the entire feature set is effectively used for learning, leading to improved performance across various tasks like image classification, object detection, and multi-modal understanding.
Over-focus Issue#
The “Over-focus Issue” in 1D causal visual models highlights a critical limitation: attention mechanisms excessively concentrate on a small subset of visual tokens, neglecting the broader context. This phenomenon hinders the model’s ability to extract diverse visual features, resulting in suboptimal gradient flow during backpropagation. The over-focus problem stems from the inherent nature of 1D causal modeling and its limitations in capturing the rich spatial relationships present in images. Addressing this requires strategies that encourage a wider attention scope, such as learnable bandpass filters or auxiliary loss functions that reward global feature understanding. Overcoming the over-focus issue is key to unlocking the full potential of 1D causal visual representations, enabling them to compete effectively with more established 2D methods.
Network Optimization#
The research paper focuses on enhancing 1D causal visual representation learning, particularly addressing the ‘over-focus’ issue in existing models. A key aspect of this is network optimization, which involves strategies to encourage the model to attend to a broader range of visual tokens. This is achieved through several techniques: introducing learnable bandpass filters to create varied attention patterns, using large and scheduled drop path rates during training, and employing an auxiliary loss on globally pooled features. The filters prevent over-concentration on a small subset of tokens, while the drop path rates and auxiliary loss improve optimization by encouraging attention to a wider range of features and improving the gradient flow to enhance global understanding. These optimizations are crucial for the model to learn more diverse and robust representations of visual data, thereby bridging the performance gap between 1D causal and 2D non-causal models. The effectiveness of these strategies is validated through extensive experiments.
Future Directions#
Future research could explore extending De-focus Attention Networks to video processing, leveraging the temporal dimension alongside spatial information. The impact of different filter designs and their effects on feature extraction warrants further investigation. Another promising avenue is adapting the approach for 3D visual data, moving beyond the 1D causal representation currently used. Combining De-focus Attention with other causal modeling techniques (like state-space models) could lead to even more robust and efficient multi-modal models. A thorough exploration into the trade-offs between computational cost and performance gains at different scales is vital. Finally, investigating the applicability of De-focus Attention in other domains beyond vision and language should prove fruitful, potentially unlocking advancements in time-series analysis or other sequence-based tasks.
More visual insights#
More on figures

The figure illustrates the architecture of the De-focus Attention Network. The left part shows the detailed architecture of a De-focus Causal Attention Block, highlighting the learnable bandpass filter and its components (learnable decay, learnable RoPE, and projection layer). The right part shows the overall network architecture, indicating the sequence of De-focus Causal Attention Blocks, drop path mechanism, average pooling, and the auxiliary loss used for optimization. It explains how the learnable bandpass filter, drop path, and auxiliary loss work together in the 1D causal visual representation learning.
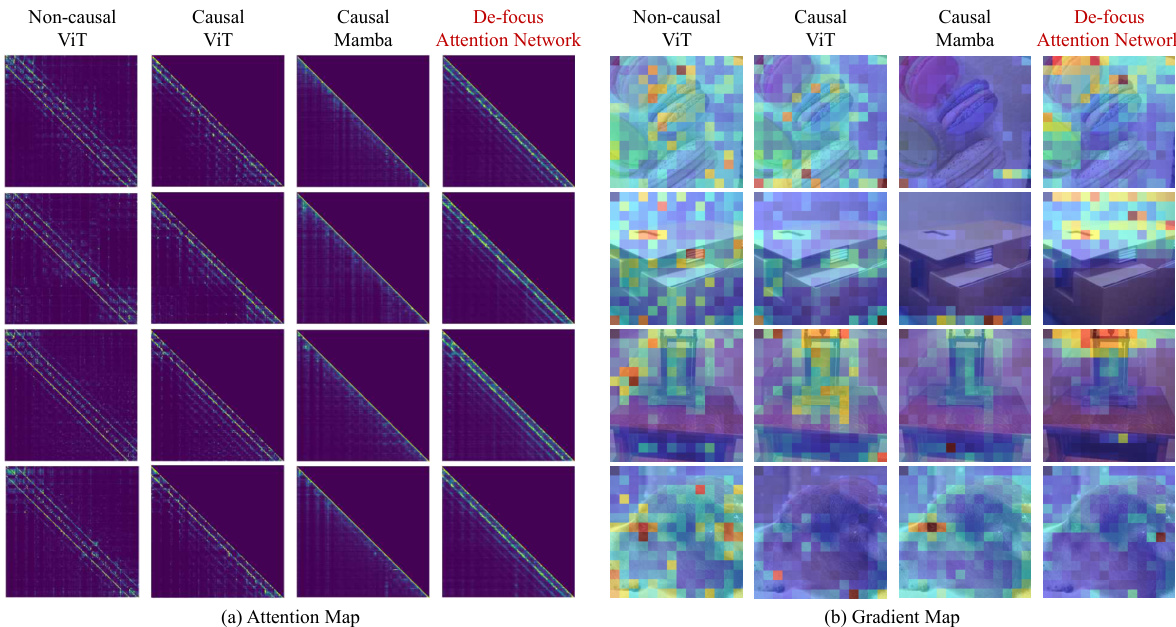
This figure visualizes the attention maps and gradient maps from the 11th layer of ViT and the 22nd layer of Mamba models. It compares the attention and gradient patterns of a non-causal ViT, a causal ViT, a causal Mamba, and the proposed De-focus Attention Network. Brighter colors in the attention maps indicate stronger attention weights, while redder colors in the gradient maps represent larger gradient norms. The visualization highlights the ‘over-focus’ issue in 1D causal models, where attention concentrates on a small subset of visual tokens.
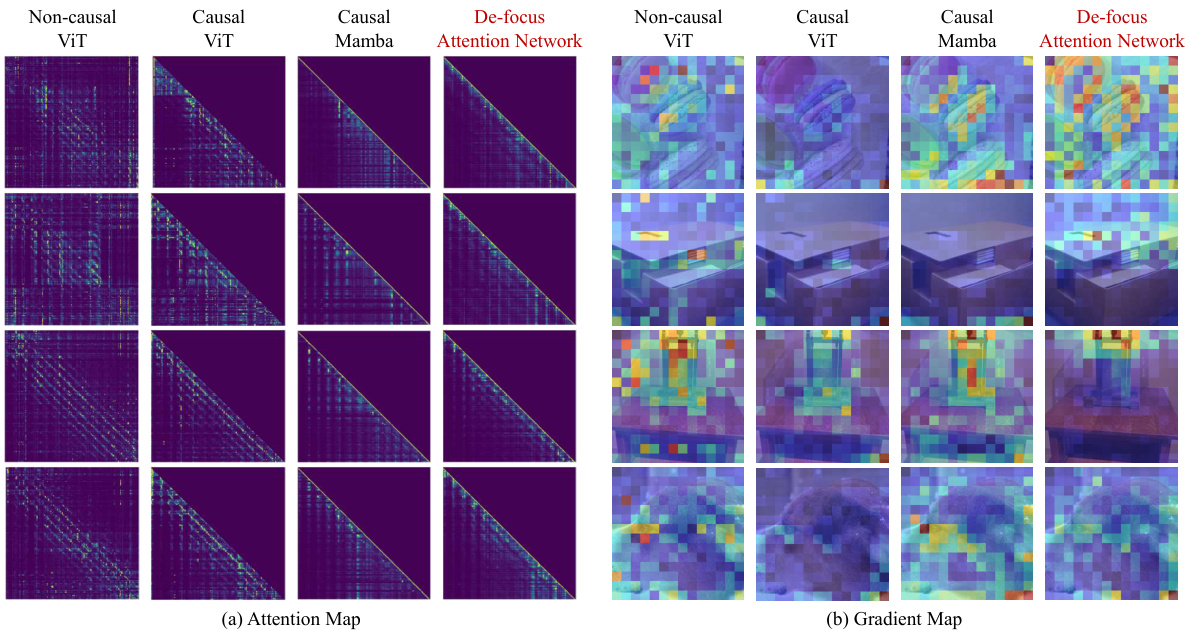
The figure visualizes the attention maps and gradient maps of four different models: non-causal ViT, causal ViT, causal Mamba, and the proposed De-focus Attention Network. It highlights the ‘over-focus’ issue in 1D causal models, where attention concentrates on a small portion of visual tokens, hindering feature extraction and gradient optimization. The De-focus Network addresses this by creating diverse attention patterns. The visualizations show that the proposed model has a more balanced distribution of attention and gradients across image tokens.
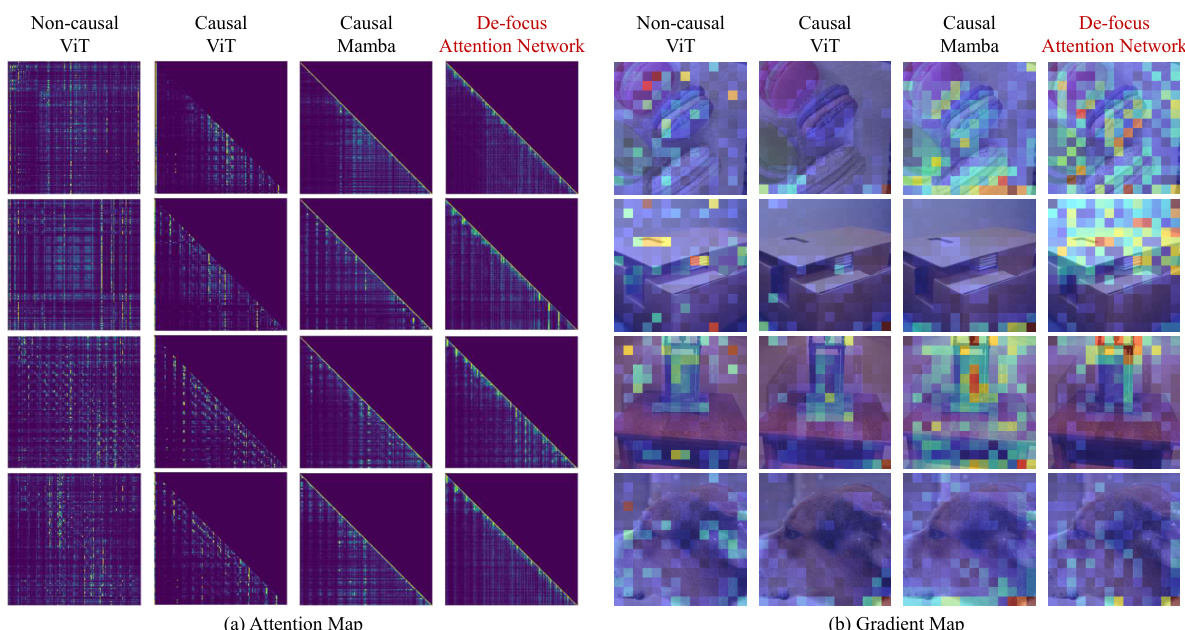
This figure visualizes the attention maps and gradient maps of different vision models, including non-causal and causal versions of Vision Transformers (ViTs) and Mamba models. It highlights the ‘over-focus’ issue in 1D causal models, where attention concentrates on a small portion of visual tokens, and gradients are not effectively distributed. The De-focus Attention Network is shown to have a more balanced attention and gradient distribution.

This figure illustrates how image patches are divided into sections and then rearranged before being fed into the model. The original image is divided into smaller 2x2 sections. These sections are then scanned in a specific order (shown in the figure) and concatenated into a single sequence for processing by the 1D causal model. This rearrangement is done to address the challenges of processing 2D images with a 1D causal model and improves performance on object detection tasks.
More on tables
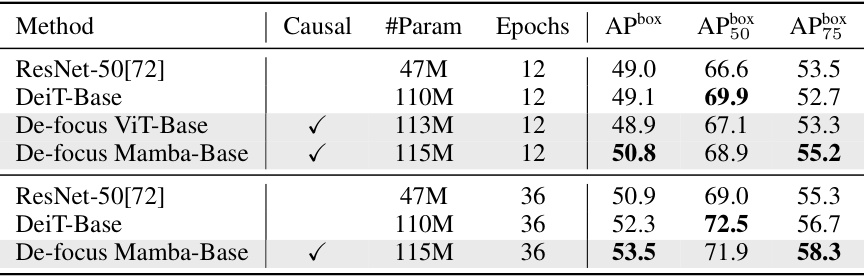
This table presents the results of object detection experiments conducted on the COCO dataset using the DINO detector. Different models, including ResNet-50, DeiT-Base, and De-focus Mamba-Base, are evaluated. The table shows the performance metrics (APbox, AP50, AP75) for each model trained for 12 and 36 epochs. The results demonstrate the superior performance of De-focus Mamba-Base compared to other models.
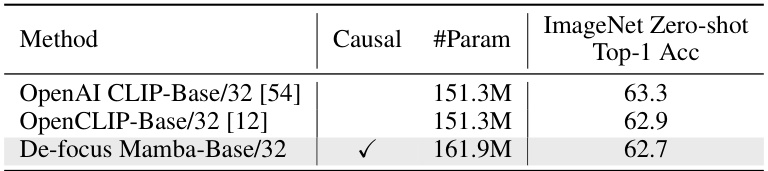
This table presents the results of zero-shot image classification on the ImageNet dataset using various CLIP pre-trained models. It compares the top-1 accuracy achieved by OpenAI CLIP, OpenCLIP, and the proposed De-focus Mamba model. The table highlights the performance of the De-focus Mamba model in comparison to existing state-of-the-art models, showcasing its competitive performance in zero-shot image classification.

This table presents the results of image-text retrieval on the COCO dataset using CLIP pre-trained models. It compares the performance of OpenAI CLIP-Base/32, OpenCLIP-Base/32, and the De-focus Mamba-Base/32 model across various recall metrics (@1, @5, @10) for both image retrieval and text retrieval. The table shows that the De-focus model shows comparable performance to state-of-the-art non-causal models.
This table compares the top-1 accuracy of various causal and non-causal attention models on the ImageNet-1K dataset. It shows the model size (#Param), the image resolution used (Size), and the resulting Top-1 accuracy. The table includes both small and base versions of DeiT, Mamba, and Vision RWKV, along with the De-focus attention network proposed in the paper. The results demonstrate the De-focus network’s ability to achieve comparable or superior performance to 2D non-causal models.

This table compares the top-1 accuracy of various causal and non-causal models on the ImageNet-1K dataset for image classification. It shows the model name, whether it uses causal attention, the model size, the number of parameters, and the achieved top-1 accuracy. The comparison highlights the performance of the proposed De-focus Attention Networks against existing causal and non-causal methods.
This table compares the top-1 accuracy of various causal and non-causal models on the ImageNet-1K dataset. It shows the impact of using causal attention mechanisms (with and without the proposed De-focus Attention Network) on model performance across different model sizes (small, base, large). The results highlight the effectiveness of the proposed method in bridging the performance gap between 1D causal and 2D non-causal vision models.
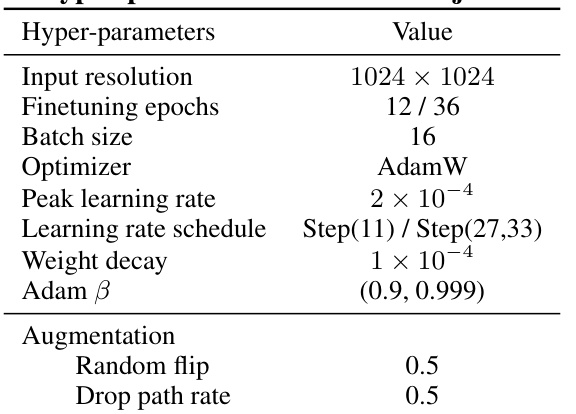
This table presents the results of object detection experiments conducted on the MS COCO dataset using the DINO detector. Different models are compared based on their performance across various metrics (APbox, AP50, AP75, and AP) and with two different training durations (12 and 36 epochs). The models include ResNet-50, DeiT-Base, De-focus ViT-Base, and De-focus Mamba-Base. The data shows how the De-focus models compare to standard models in object detection.

This table compares the top-1 accuracy of various causal and non-causal attention models on the ImageNet-1K image classification benchmark. It shows the model name, whether it uses causal attention, the model size, the number of parameters, and the achieved top-1 accuracy. The results demonstrate the performance of the proposed De-focus Attention Networks in comparison to existing causal and non-causal models.
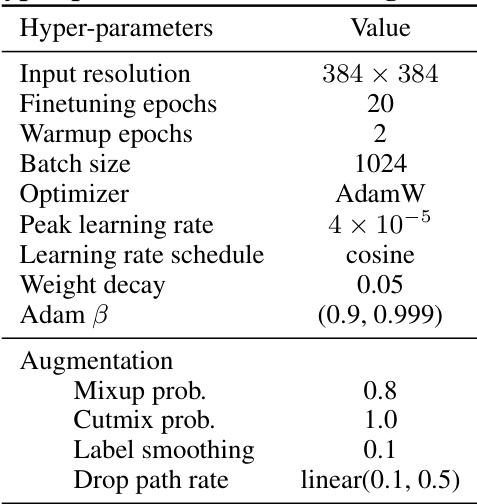
This table compares the top-1 accuracy of various causal and non-causal vision models on the ImageNet-1K image classification benchmark. It showcases the performance of different model sizes (small, base, large) including DeiT, Mamba, Vision Mamba, Vision RWKV and the proposed De-focus Attention Networks (applied to ViT, RetNet, and Mamba). The table highlights the impact of the proposed De-focus attention mechanism on improving the accuracy of 1D causal models, demonstrating their competitiveness against traditional 2D non-causal approaches.
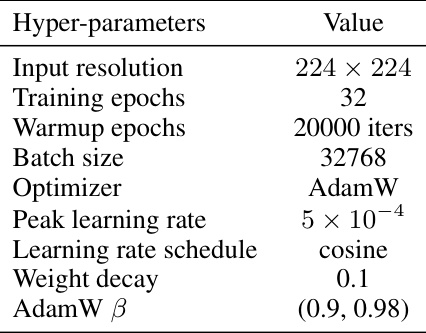
This table compares the top-1 accuracy of various causal and non-causal attention models on the ImageNet-1K dataset. It shows the model size, number of parameters, and top-1 accuracy for each model. The table highlights the performance of De-focus attention networks in comparison to other causal and non-causal models, demonstrating their improved accuracy.
Full paper#