↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but computationally expensive, hindering their deployment on resource-limited devices. Current compression methods mainly focus on weight optimization, neglecting architecture exploration. Existing architecture search methods are computationally expensive for LLMs.
This research introduces a novel training-free framework to identify optimal subnets within pre-trained LLMs, enhancing inference speed without the need for retraining. It leverages weight importance to initialize an efficient architecture, employing an evolution-based algorithm for global search. A reformation algorithm refines the weights of the identified subnets using omitted weights and limited calibration data. The results demonstrate significantly improved performance and reduced memory usage compared to SOTA methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel training-free architecture search framework for efficient large language models (LLMs). This addresses the critical challenge of LLM deployment on resource-constrained devices by significantly reducing memory usage and accelerating inference without requiring retraining. The training-free approach reduces computational costs and enables the exploration of more complex architectures, opening exciting new avenues for LLM optimization and research. The superior performance compared to state-of-the-art (SOTA) methods makes it highly relevant to the current trends in LLM compression and efficiency.
Visual Insights#

This figure presents the perplexity results on the WikiText2 dataset with a sequence length of 2048. It compares the performance of the proposed method against several state-of-the-art (SOTA) baselines across different LLM families (OPT and LLaMA) and varying model sizes. The x-axis represents the inheriting ratio, and the y-axis shows the perplexity. Lower perplexity indicates better performance. The figure demonstrates the superior performance of the proposed method across various models and inheriting ratios, showcasing its effectiveness in generating efficient subnets.

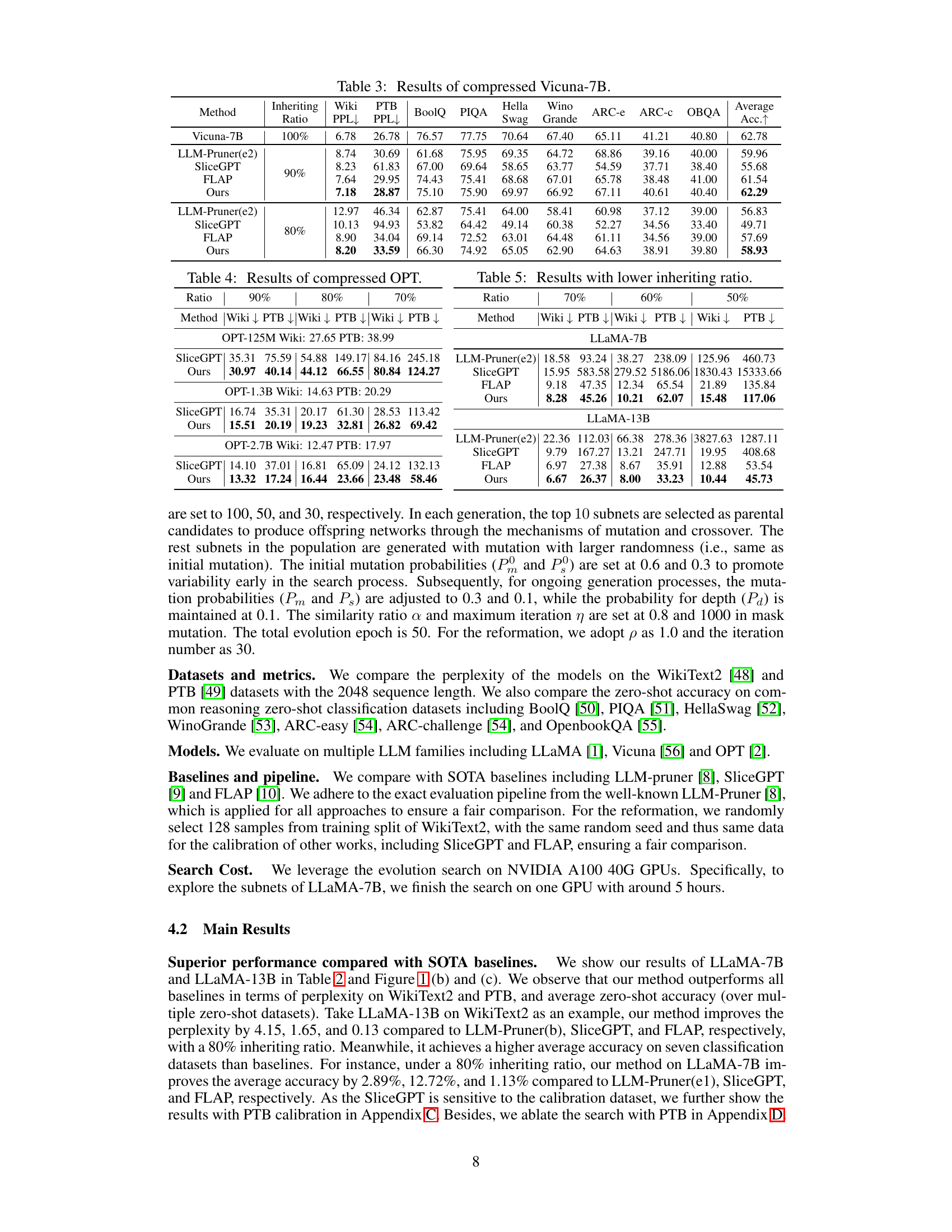
This table presents the results of compressed LLaMA-7B and LLaMA-13B models on several benchmark datasets. It shows perplexity scores (lower is better) on WikiText2 and PTB, and accuracy scores (higher is better) across seven common sense reasoning datasets. Different model compression methods (LLM-Pruner, SliceGPT, FLAP, and the proposed method) are compared at various weight inheritance ratios (e.g., 90%, 80%). The table highlights the performance improvements achieved by the authors’ method across various model sizes and datasets.
In-depth insights#
Training-Free Search#
The concept of “Training-Free Search” in the context of large language model (LLM) optimization represents a paradigm shift away from traditional architecture search methods. These methods typically involve extensive training, which is computationally expensive and time-consuming, especially for LLMs with billions of parameters. A training-free approach, therefore, offers a significant advantage by directly searching within the pre-trained weights of the original LLM, identifying optimal subnetworks without needing additional training. This approach reduces the computational cost substantially. The key challenge for this lies in efficiently evaluating candidate subnetworks to guide the search effectively. Novel techniques are needed to rapidly assess and compare the performance of different subnets without relying on full retraining. The success of such methods critically hinges on the ability to effectively leverage information encoded in the pre-trained weights to identify high-performing subnetworks quickly. The effectiveness of a training-free search approach will depend greatly on the efficiency and accuracy of the algorithms used for evaluating candidate subnetworks. The potential benefits are enormous for deployment of smaller, faster models on resource-constrained devices, offering a powerful way to make LLMs more accessible and practical.
Subnet Reformation#
The concept of ‘Subnet Reformation’ in the context of large language model (LLM) optimization is a novel approach to enhance the performance of pruned subnetworks. Instead of relying solely on weight optimization techniques like pruning or quantization, it focuses on refining the weights of the selected subnetwork. This is achieved by leveraging the information contained in the weights that were removed during the pruning process. The reformation process involves a careful recalibration step, potentially using a small amount of additional data, to adjust the remaining weights and counteract any performance degradation caused by the pruning. This approach, therefore, attempts to recover the information loss inherent in traditional subnet selection methods by intelligently incorporating the omitted weights, potentially leading to significantly improved performance compared to solely pruning-based methods. The success of subnet reformation depends heavily on the effectiveness of the recalibration algorithm. A well-designed algorithm should be able to efficiently learn the necessary adjustments to the pruned weights and avoid overfitting to the limited calibration data, while simultaneously reducing computation and memory requirements.
LLM Compression#
LLM compression techniques aim to reduce the substantial computational and memory footprint of large language models (LLMs) while preserving performance. Weight pruning, quantization, and knowledge distillation are common methods, but they primarily focus on weight optimization, neglecting architectural improvements. Structured pruning methods offer a more sophisticated approach by targeting redundant network structures. However, even these techniques may overlook the potential for significant compression through optimal architecture design. Training-free architecture search is a promising area, exploring efficient subnetworks within existing models to accelerate inference. Reformation algorithms can further refine these compressed models by intelligently utilizing omitted weights, requiring minimal calibration data. This multi-pronged approach addresses the inherent redundancy in LLMs at both the weight and architectural levels. The combined strategy yields significant memory savings and inference acceleration, crucial for deploying LLMs on resource-constrained devices, without requiring extensive retraining.
Efficient Inference#
Efficient inference is a crucial aspect of large language models (LLMs), focusing on optimizing the speed and resource consumption of model execution. The paper emphasizes training-free methods to achieve this, avoiding the computational cost of retraining. This approach centers on identifying and utilizing optimal subnetworks within pre-trained LLMs, effectively reducing the model’s size without significant performance degradation. A key innovation is the introduction of a reformation algorithm, which refines the weights of the selected subnetwork using omitted weights and minimal calibration data. This intelligent refinement process significantly enhances the performance and efficiency of the smaller model. The framework demonstrates superior performance compared to existing training-free techniques on various benchmarks, indicating the effectiveness of the proposed method in striking a balance between efficiency and accuracy. Reduced GPU memory usage and inference acceleration are key advantages of this approach, particularly significant for deploying LLMs on resource-constrained devices.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the training-free architecture search is crucial, potentially through more sophisticated initialization strategies or by incorporating learning mechanisms. Investigating the generalization capabilities of the generated subnets across diverse LLMs and tasks warrants attention. A key challenge is to develop more robust methods for weight reformation, especially in scenarios with highly complex or sparse models. Finally, exploring the trade-offs between accuracy, model size and inference speed at a granular level could lead to new design principles for highly efficient LLMs. The development of innovative compression techniques tailored to the unique architectures of LLMs and the extension to multimodal LLMs are also important next steps.
More visual insights#
More on figures

This figure illustrates the three main stages of the proposed framework for efficient large language model (LLM) compression. Stage 1 (Initialization): An initial architecture is constructed based on the weight importance of the original LLM, with weights inheriting a certain ratio. Stage 2 (Search): An evolutionary search process is used to identify the globally efficient architecture/subnet within the original LLM, which includes mask mutation, crossover, and candidate evaluation. Stage 3 (Reformation): A reformation algorithm refines the inherited weights from the original LLM to improve performance using the omitted weights and a small amount of calibration data.
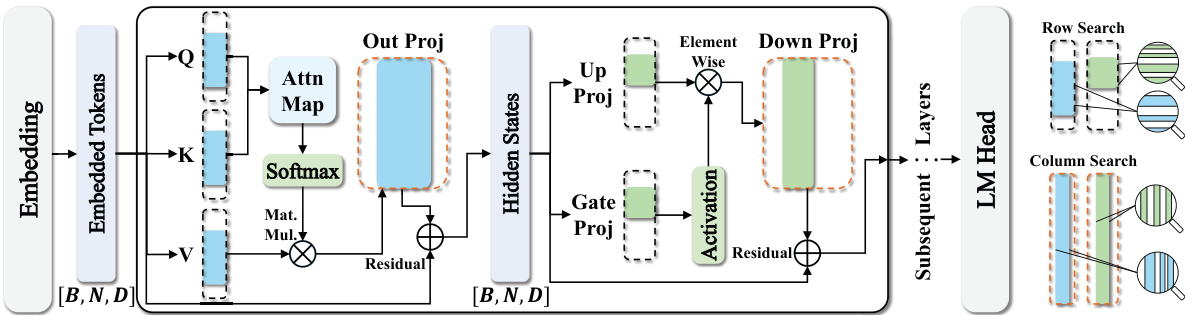
This figure illustrates the process of generating subnets for the LLaMA family of LLMs. It shows how the selection masks, Sattn (for self-attention modules) and Smlp (for MLP modules), are used to identify specific rows or columns within the original weight matrices that are then kept, while others are omitted, creating smaller subnets. The colors (blue and green) highlight the areas where the masks apply. The figure also shows how the structural subnets (rows or columns) are searched using a row or column search mechanism. This allows for a training-free approach to model compression by directly modifying the architecture without retraining.
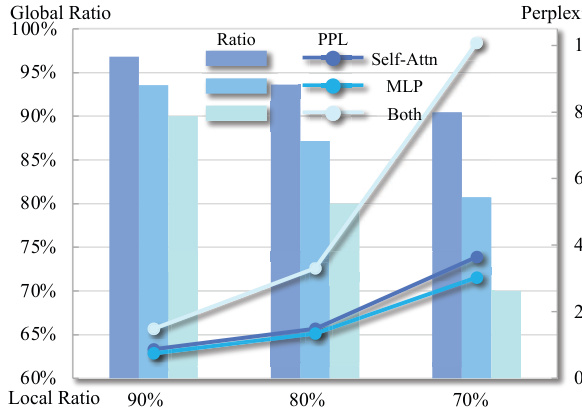
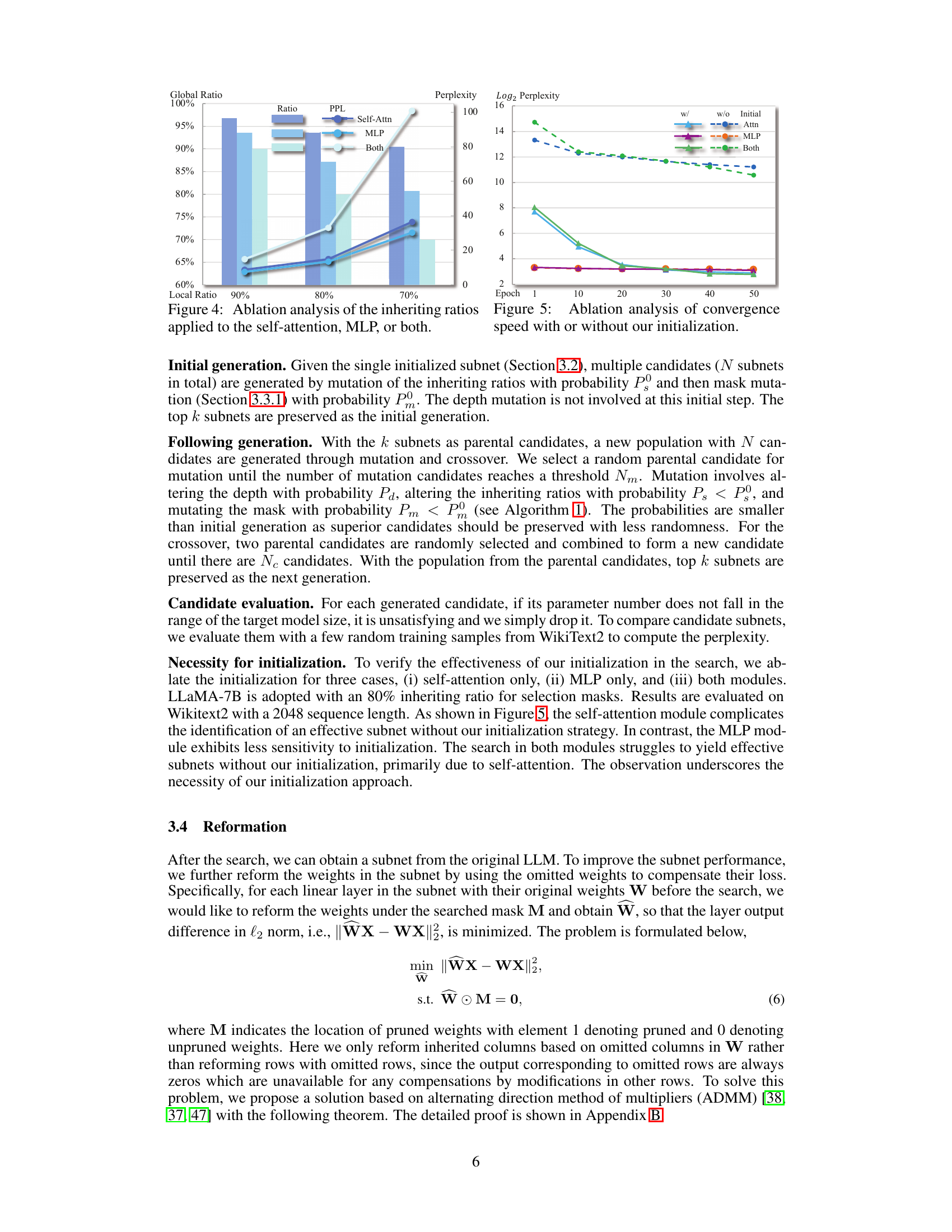
This figure presents an ablation study on the impact of different inheriting ratios applied to various parts of the model architecture. It shows perplexity results and the ratio of parameters inherited in three scenarios: self-attention only, MLP only, and both modules. The goal is to determine which parts of the LLM benefit most from reduced parameter counts and to investigate the effects of a non-uniform ratio across the model.
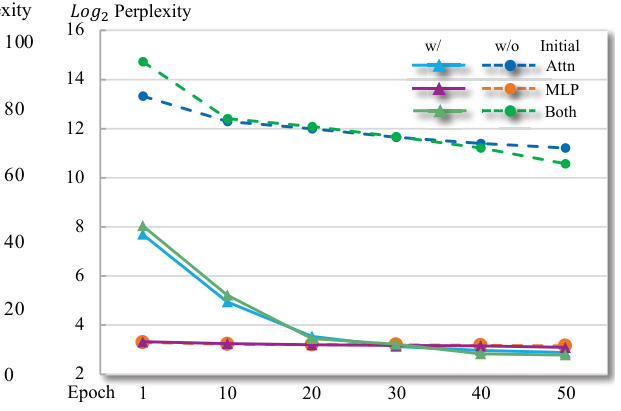
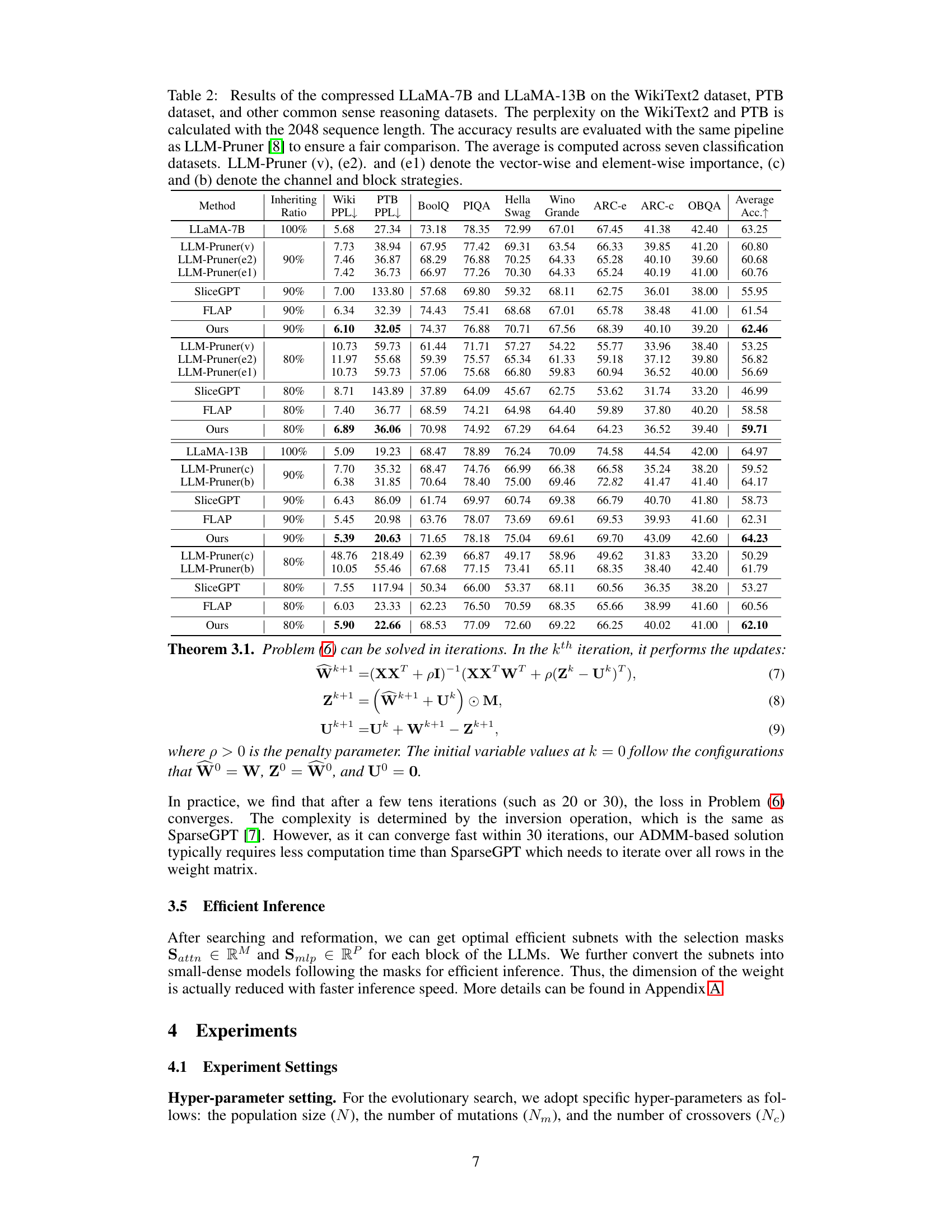
This figure displays an ablation study comparing the convergence speed of the proposed architecture search method with and without initialization. The y-axis represents the log2 perplexity (a measure of model performance), and the x-axis shows the epoch number (iterations of the search process). Different lines represent different scenarios: using initialization with self-attention only, MLP only, both self-attention and MLP, and the results without any initialization. The results demonstrate the effectiveness of the proposed initialization strategy in speeding up convergence and achieving lower perplexity.

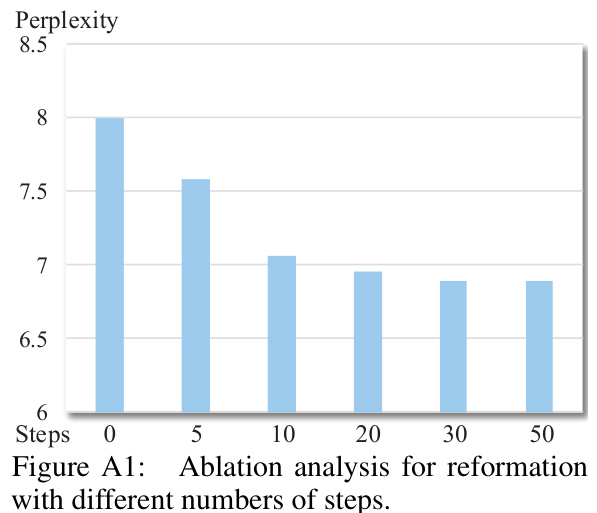
The figure shows the ablation study on the reformation process using different numbers of samples. The x-axis represents the inheriting ratio, and the y-axis shows the perplexity. The bars illustrate the perplexity results with no reformation (w/o reform), and reformation using 128, 512, and 1024 samples, respectively. The results demonstrate that reformation improves the perplexity score, and that using more samples does not dramatically improve the performance past a certain number of samples.

This figure shows the memory consumption and inference speed of the LLaMA-7B model on an NVIDIA A100 40G GPU, for different inheriting ratios (100%, 90%, 80%, 70%, 60%, 50%). It demonstrates that reducing the inheriting ratio leads to lower memory usage and faster generation speed. The trade-off between model size and performance is clearly visualized.
This figure displays the perplexity results for various LLMs (OPT and LLaMA families) on the WikiText2 dataset using sequences of length 2048. Different methods for model compression are compared, including SliceGPT, LLM-Pruner, FLAP, and the proposed ‘Ours’ method. The x-axis represents the percentage of weights retained in the model, and the y-axis represents the perplexity. Lower perplexity indicates better performance. The figure illustrates that the ‘Ours’ method consistently outperforms other methods across different model sizes and retention rates, achieving significantly lower perplexity scores.

This figure displays the perplexity results achieved by different methods on the WikiText2 dataset, using sequences of length 2048. It compares the performance of the proposed method against several state-of-the-art (SOTA) baselines across four different LLM families (OPT and LLaMA) and various model sizes, illustrating the impact of varying the proportion of weights inherited from the original model. Lower perplexity indicates better performance.
More on tables
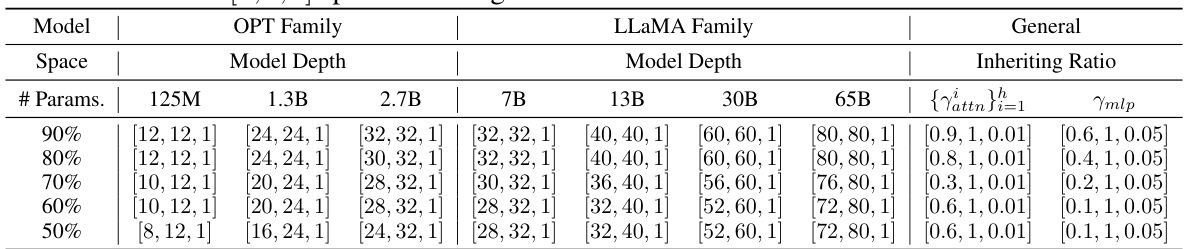
This table presents the search space used in the evolutionary algorithm to find efficient subnetworks within various large language models (LLMs). It defines the range of values for three key parameters that define the architecture of the searched subnets: - Model depth: The number of layers in the LLM subnetwork. Separate ranges are defined for OPT and LLaMA model families to account for architectural differences. - Inheriting ratio for self-attention: The percentage of weights from the original LLM’s self-attention module to be inherited into the subnetwork. - Inheriting ratio for MLP: The percentage of weights from the original LLM’s Multi-Layer Perceptron (MLP) module to be inherited into the subnetwork. Different inheriting ratios are tested for different model sizes (125M, 1.3B, 2.7B parameters for OPT; 7B, 13B, 30B, 65B parameters for LLaMA). The table provides the range for each parameter, enabling a systematic exploration of the architecture search space.
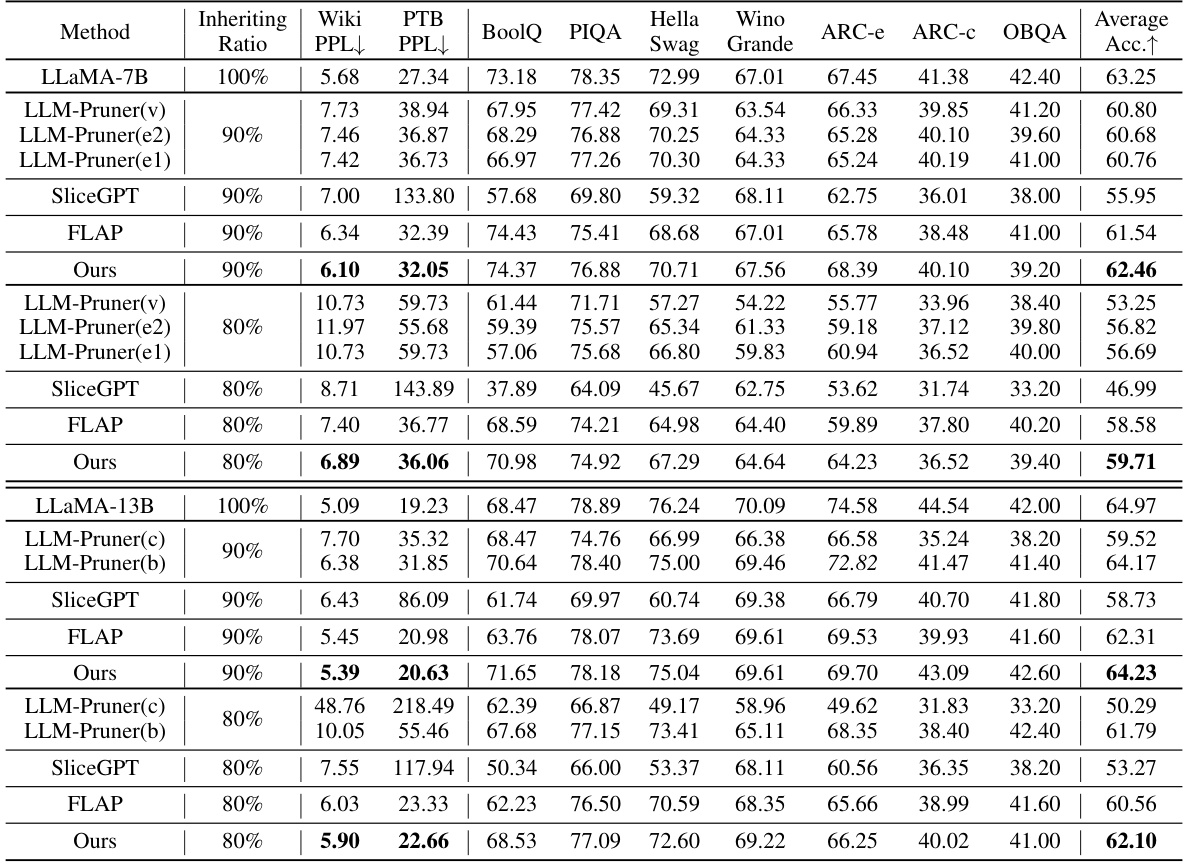
This table presents the results of compressing LLaMA-7B and LLaMA-13B language models using different methods, including the proposed method and several state-of-the-art baselines. It shows the perplexity scores (a measure of how well the model predicts text) on the WikiText2 and Penn Treebank (PTB) datasets, along with accuracy scores on seven common sense reasoning datasets. The comparison is made at different compression ratios (inheriting ratios), showing the trade-off between model size and performance. Various pruning strategies within LLM-Pruner are also compared.
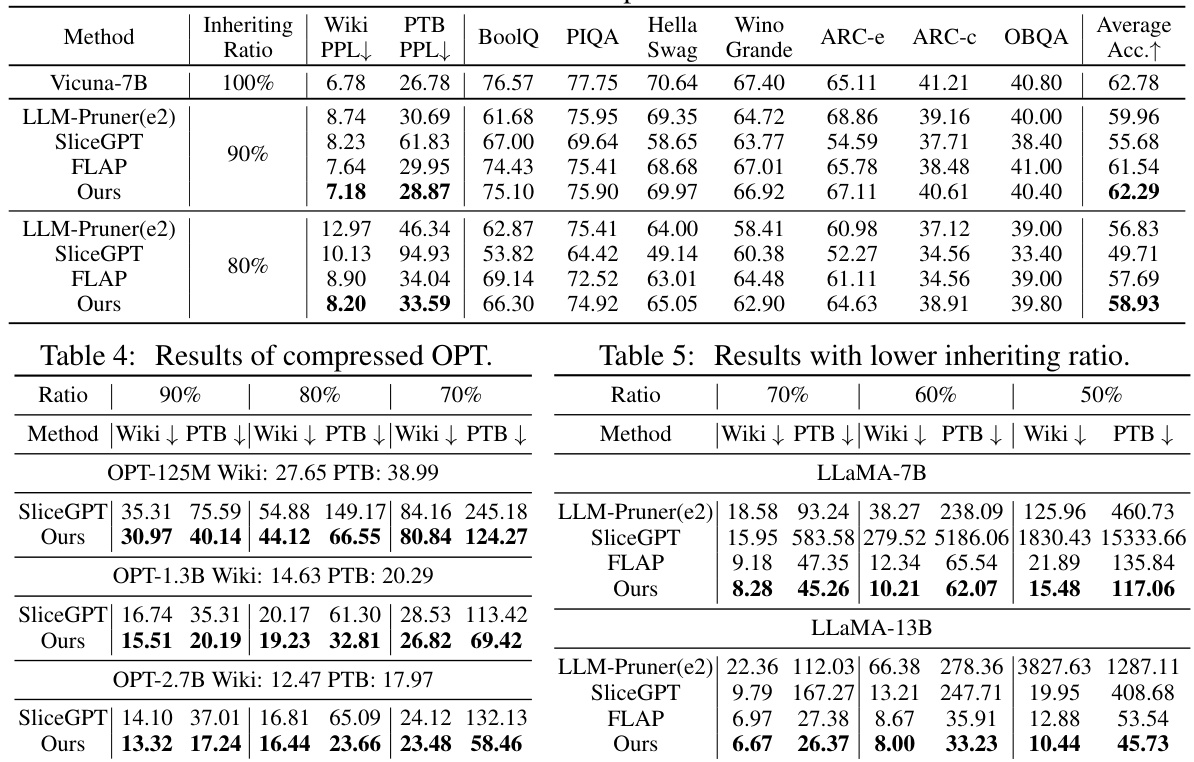
This table presents the results of compressing two large language models, LLaMA-7B and LLaMA-13B, using different methods. It shows the perplexity scores (a measure of how well the model predicts text) on two benchmark datasets, WikiText2 and PTB, as well as accuracy scores on seven common sense reasoning datasets. The table compares the performance of the proposed method against three state-of-the-art baselines (LLM-Pruner, SliceGPT, and FLAP) across different weight inheriting ratios (the percentage of original weights kept in the compressed model). Different pruning strategies within LLM-Pruner are also compared.

This table presents the results of applying the proposed method to extra-large LLaMA models (30B and 65B parameters). It shows the perplexity scores achieved on the Wiki and PTB datasets at various inheriting ratios (100%, 90%, 80%, 70%, 60%, 50%). The results are compared against the FLAP baseline, demonstrating the superior performance of the proposed method even with larger models and lower inheriting ratios.
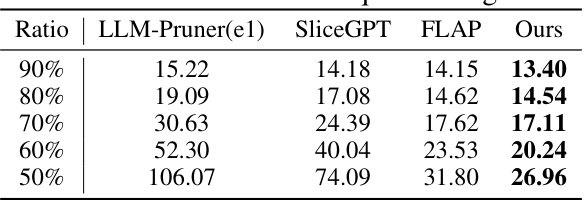
This table presents the perplexity results for the LLaMA-7B model on the WikiText2 dataset using sequences of length 128. The results are shown for different inheriting ratios (90%, 80%, 70%, 60%, and 50%), comparing the performance of the proposed method against several baselines: LLM-Pruner(el), SliceGPT, and FLAP. Lower perplexity values indicate better performance.

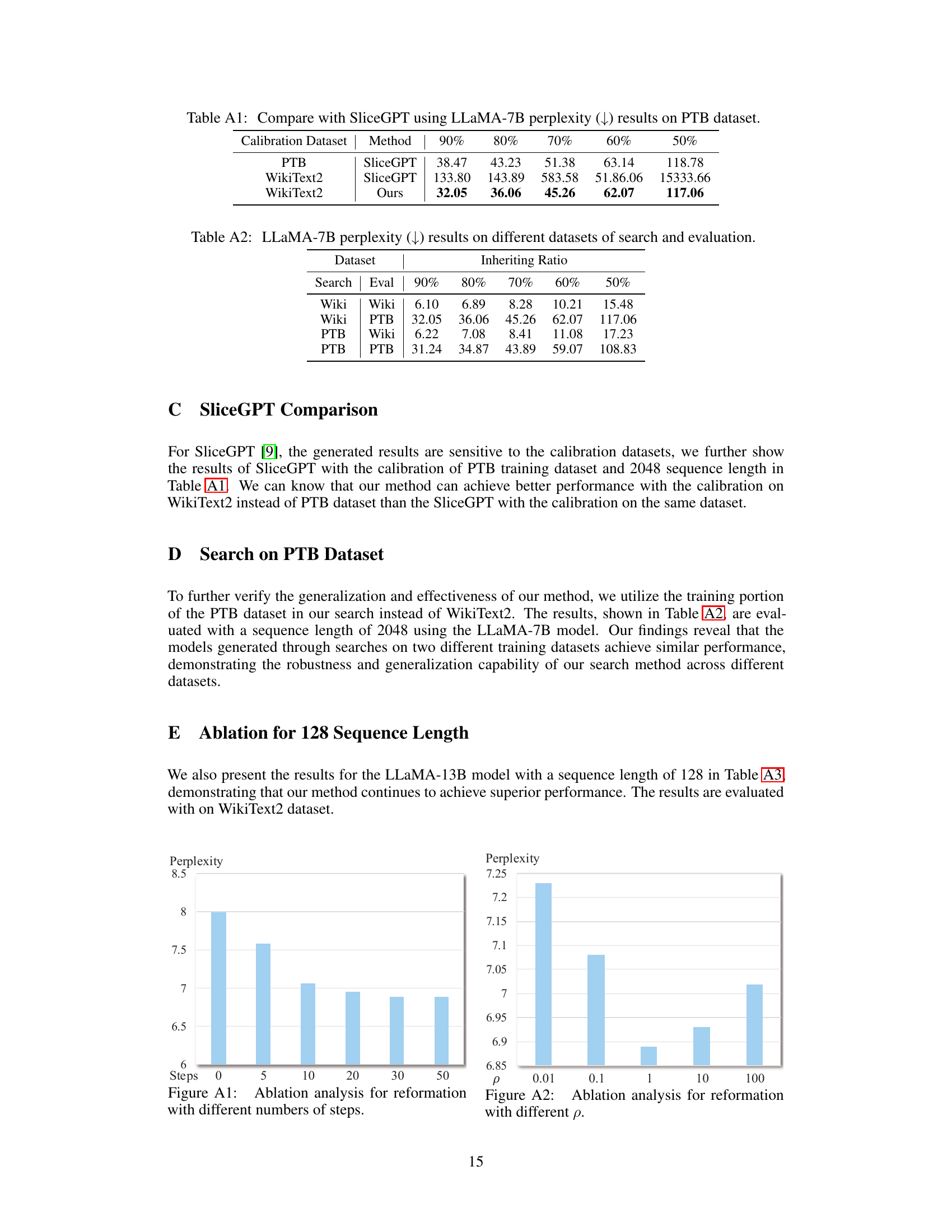
This table compares the perplexity results of SliceGPT and the proposed method on the PTB dataset using the LLaMA-7B model. It demonstrates the impact of different calibration datasets (PTB and WikiText2) on the performance of SliceGPT, highlighting that SliceGPT’s performance is sensitive to the choice of calibration dataset. The proposed method shows consistently better performance across varying inheriting ratios, regardless of the calibration dataset used. This emphasizes the robustness and effectiveness of the proposed approach.
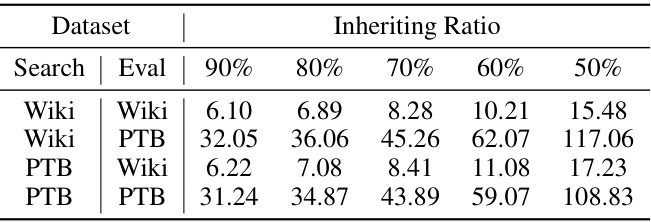
This table presents the perplexity scores achieved by the LLaMA-7B model on WikiText2 and Penn Treebank (PTB) datasets, using different combinations of datasets for search and evaluation, along with varying inheriting ratios. The perplexity is a measure of how well the model predicts the next word in a sequence, with lower scores indicating better performance. The table shows that the model’s performance varies depending on which dataset was used during the search phase, and that a lower inheriting ratio generally leads to worse performance.

This table presents the perplexity results for the LLaMA-13B model on the WikiText2 dataset using different inheriting ratios (90%, 80%, 70%, 60%, 50%). The perplexity, a measure of how well the model predicts the next word, is compared across four methods: LLM-Pruner(e1), SliceGPT, FLAP, and the authors’ proposed method. Lower perplexity indicates better performance. The table shows that the proposed method achieves lower perplexity than the baselines across all inheriting ratios, demonstrating its superior performance in generating text even with short sequence lengths.
Full paper#