TL;DR#
3D object detection using multiple cameras is valuable but faces challenges: adapting to new environments with different camera placements is difficult and requires many annotations. Current methods struggle to achieve satisfactory adaptation to unseen target datasets because of geometric misalignment between the source and target domains. There are also constraints on resources, such as training models and collecting annotations.
The proposed UDGA framework addresses these issues. It introduces Multi-view Overlap Depth Constraint, which leverages the strong association between multiple views to reduce geometric misalignment. It also incorporates Label-Efficient Domain Adaptation, handling unfamiliar targets with limited labeled data while maintaining source domain knowledge. Experiments on large-scale benchmarks show that UDGA outperforms state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical challenge of adapting 3D object detectors to new environments with limited resources. It presents a novel framework that significantly improves performance in unseen domains while reducing annotation needs, directly impacting the development of robust and cost-effective autonomous systems. The proposed techniques also offer valuable insights into domain generalization and adaptation methods, opening new research avenues in computer vision.
Visual Insights#
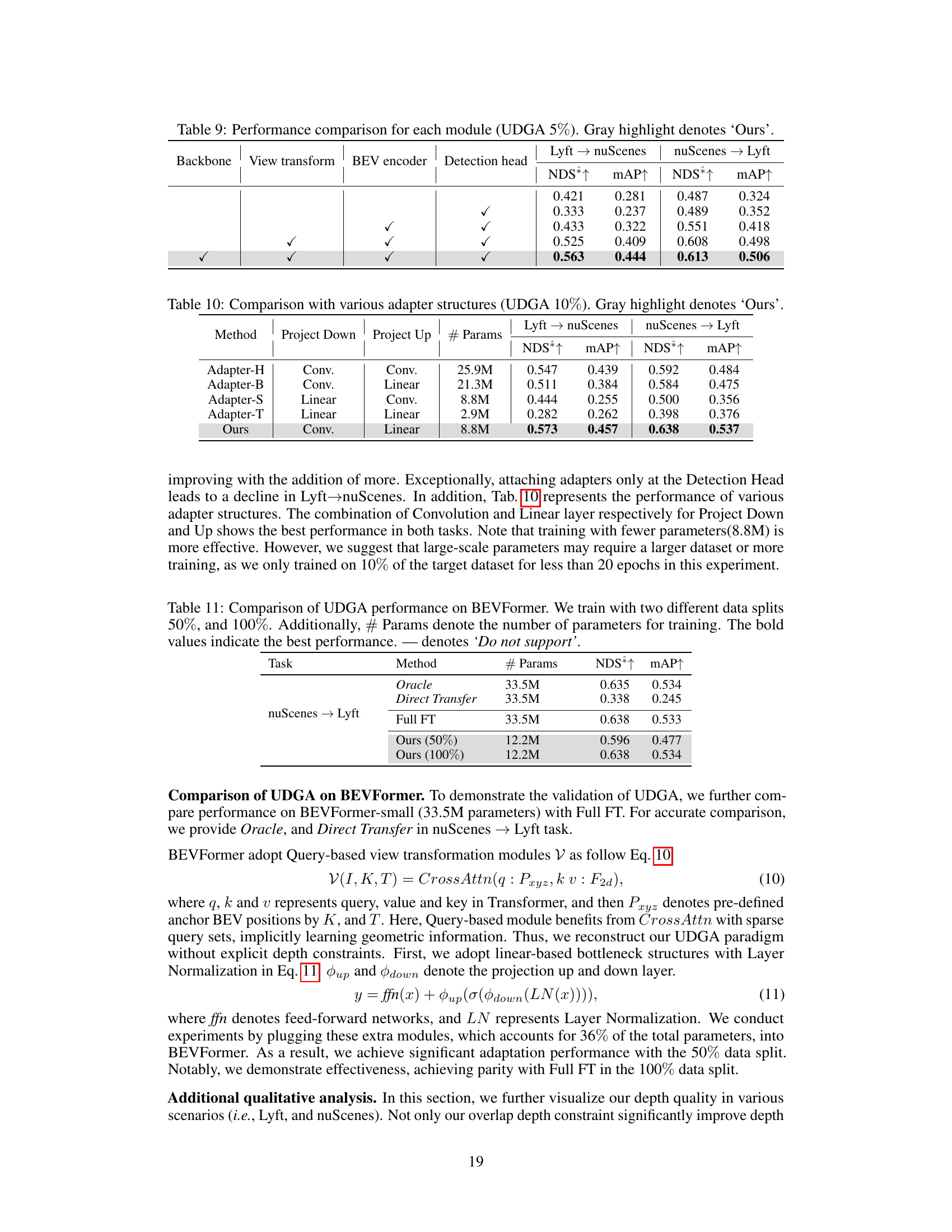
🔼 This figure compares the performance of different methods for multi-view 3D object detection in both source and target domains. The methods compared are: Direct Transfer (DT), CAM-Convs, DG-BEV, PD-BEV (with and without unsupervised domain adaptation (UDA)), and the proposed UDGA method. The performance metric used is Average NDS (Normalized Distance Score), calculated by averaging NDS scores from both source and target domains. The results show that the proposed UDGA significantly outperforms other methods, particularly when only 5% of the target domain labels are used for adaptation.
read the caption
Figure 1: Comparison of performance in both source and target domains (Tab. 6). Here, “Average” (orange dots) refers to mean NDS in both the source and target domains. We draw comparisons with prior methods CAM-Conv [13], DG-BEV [14] and PD-BEV [15] offering an empirical lower and upper bounds, DT and Oracle. Note that we only use 5% of the target label for Domain Adaptation.

🔼 This table compares the proposed Unified Domain Generalization and Adaptation (UDGA) method’s performance with other state-of-the-art (SOTA) domain generalization techniques across three benchmark datasets (Lyft, nuScenes, and Waymo). It shows the performance metrics NDS*, mAP, mATE, mASE, MAOE, and Closed Gap for each method and dataset combination, focusing on the ‘car’ object category. The bold values highlight the best performing method for each task. The Closed Gap metric provides a relative performance improvement compared to a direct transfer approach (without domain adaptation).
read the caption
Table 1: Comparison of Domain Generalization performance with existing SOTA techniques. The bold values indicate the best performance. Note that all methods are evaluated on ‘car’ category.
In-depth insights#
Multi-view 3D OD#
Multi-view 3D object detection (3D OD) leverages multiple cameras to overcome limitations of single-view approaches. This offers several advantages: richer contextual information, improved depth perception, and robustness to occlusions. However, challenges exist in handling perspective distortions, camera misalignments, and the computational cost of processing multiple views. Effective solutions often involve sophisticated techniques for geometric calibration, feature fusion, and efficient network architectures. Key research directions focus on improving accuracy and generalization across varying viewpoints and environments, as well as developing more efficient and resource-friendly methods for real-time applications such as autonomous driving and robotics.
Domain Generalization#
Domain generalization, in the context of the provided research paper, tackles the challenge of building machine learning models that can effectively perform across various unseen environments or data distributions. The core problem is that traditional supervised learning methods often struggle when presented with data that significantly differs from their training data, leading to reduced performance. The paper likely addresses this by exploring techniques that encourage the model to learn more generalizable features, reducing overfitting to specific training data. This might involve using data augmentation, adversarial training methods, or other regularization techniques to improve robustness and adaptability to novel domains. A key aspect is likely the development of algorithms that can handle distributional shifts in data, whether it’s due to variations in sensor configurations, environmental conditions, or other factors. Ultimately, a successful domain generalization approach aims to create models that are both accurate and robust, capable of performing well in real-world scenarios where the exact nature of the data is unpredictable.
Depth Consistency#
Depth consistency in multi-view 3D object detection is crucial for accurate and robust performance. Inconsistent depth estimations across multiple camera views lead to significant errors in 3D object localization and pose estimation. Addressing this challenge often involves sophisticated techniques that leverage geometric constraints or learn view-invariant features. The core idea is to ensure that the perceived depth of an object remains relatively consistent regardless of the viewing angle or camera position. Methods to enforce depth consistency can include: penalizing discrepancies in depth predictions between adjacent views, incorporating multi-view geometric constraints, and leveraging depth supervision from other sensors like LiDAR. Successful depth consistency techniques are key to bridging the domain gap, making camera-based 3D object detection more robust and reliable across varying environments and viewpoints.
Label-Efficient DA#
Label-efficient domain adaptation (LEDA) tackles the challenge of adapting models to new domains with limited labeled data. The core idea is to leverage pre-trained knowledge from a source domain while efficiently fine-tuning the model to adapt to the target domain using minimal target labels. This approach addresses two crucial limitations: the scarcity of labeled data in target domains and resource constraints, which includes both computational resources and annotation costs. By carefully designing the adaptation strategy, often involving specialized network modules like adapters or low-rank updates, LEDA aims to maximize transfer learning from the source domain while minimizing catastrophic forgetting. The effectiveness of this approach depends heavily on the selection of appropriate architectures and training methodologies that strike a balance between preserving source knowledge and adapting to target-specific characteristics. The success also relies on the inherent similarity and transferable knowledge between the source and target domains. The ability to effectively generalize to unseen data and situations remains a key challenge and represents a significant area for future research and improvements.
Future of 3DOD#
The future of 3D object detection (3DOD) is brimming with potential. Further advancements in sensor technology, particularly in LiDAR and camera systems, will lead to richer, more accurate data. Improved fusion techniques will seamlessly integrate multi-modal sensor data, enhancing 3DOD’s robustness and reliability. Sophisticated deep learning architectures will continue to evolve, improving accuracy and efficiency in diverse environments. Addressing the challenges of domain adaptation and generalization will be crucial for deploying 3DOD across various scenarios. The development of more efficient training methods and techniques for dealing with limited labeled data are essential for practical applications. Ultimately, the future of 3DOD will likely involve a shift towards more robust, adaptable, and ethically responsible systems capable of operating reliably and safely in real-world environments.
More visual insights#
More on figures
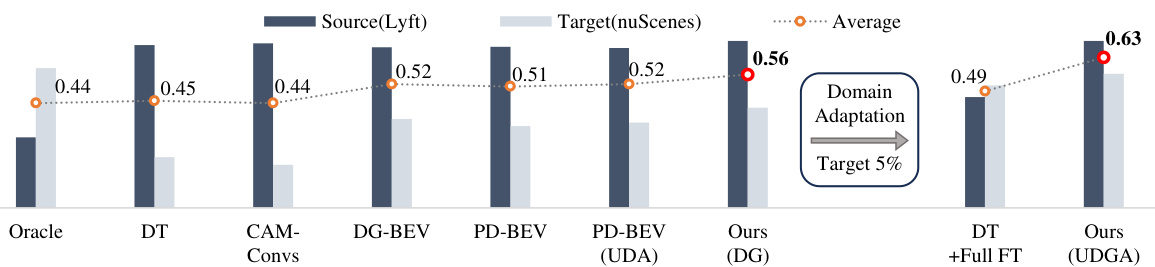
🔼 This figure shows the impact of camera extrinsic parameter shifts on multi-view 3D object detection. (a) demonstrates the significant difference in perspective views (approximately 30% translation) between source and target camera installations. (b) illustrates the resulting performance drop (up to 67% in mAP and NDS) of a source-trained network when applied to the target domain due to the extrinsic shift. The experiment uses CARLA simulation to induce this shift.
read the caption
Figure 2: (a) An illustration of multi-view installation translation difference. The first (i.e., source) and second (i.e., target) rows are two perspective views of the same scene captured from different installation points. The translation gap between these views is substantial, approximately 30%. (b) Source trained network shows poor perception capability in target domain, primarily due to extrinsic shifts. In ∆Height, mAP and NDS have dropped up to -67% compared to source. Note that we simulate the camera extrinsic shift leveraging CARLA [52] (refer to Appendix A for further details).

🔼 This figure illustrates the proposed Unified Domain Generalization and Adaptation (UDGA) framework. The framework consists of two main components: the Multi-view Overlap Depth Constraint, which addresses geometric inconsistencies across different viewpoints, and the Label-Efficient Domain Adaptation, which enables efficient adaptation to new domains with limited labeled data. The framework is designed to be used in a two-phase process: pre-training on a source domain and then fine-tuning on a target domain. The depth constraint is applied during both phases, while the domain adaptation is applied only during the fine-tuning phase.
read the caption
Figure 3: An overview of our proposed methodologies. Our proposed methods comprise two major parts: (i) Multi-view Overlap Depth Constraint and (ii) Label-Efficient Domain Adaptation (LEDA). In addition, our framework employs two phases (i.e., pre-training, and then fine-tuning). Note that we adopt our proposed depth constraint in both phases, and LEDA only in the fine-tuning phase.
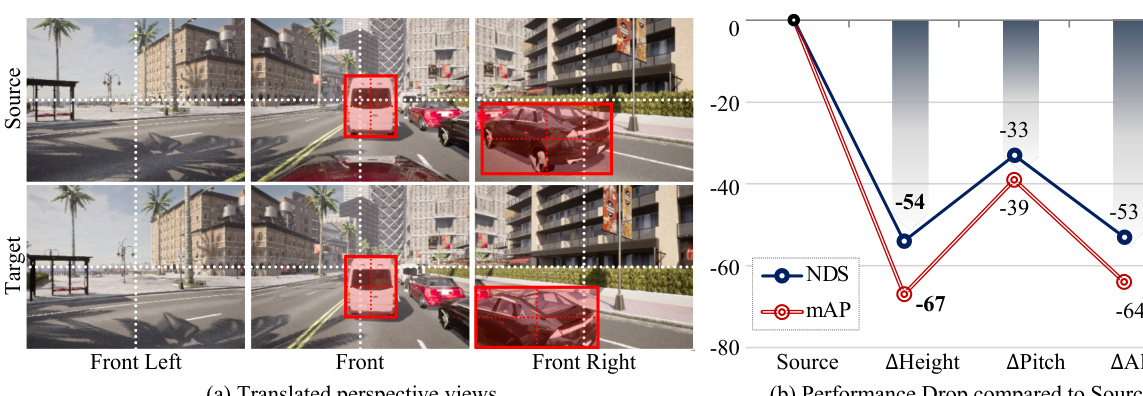
🔼 This figure shows a qualitative comparison of depth estimation results from three different methods: ground truth LiDAR data, BEVDepth method, and the proposed ‘Ours’ method. The comparison is done on front-view images from the Lyft dataset. Yellow boxes highlight areas where the proposed method shows improved depth estimation compared to BEVDepth, particularly in challenging areas such as far distances and occluded objects.
read the caption
Figure 5: Qualitative depth visualizations of front view lineups in Lyft. The top row illustrates sparse depth ground truths projected from LiDAR point clouds. The middle and bottom rows are the qualitative results of BEVDepth and Ours, respectively. Yellow boxes highlight the improved depth.

🔼 This figure shows paired samples from the Carla dataset used for evaluating the model’s performance under various simulated camera position changes. Each row represents a different type of simulated change (Source, Height, Pitch, All), showing how the scene is captured from different viewpoints. The images illustrate how the changes in camera height and pitch affect the view of the scene. The figure is used to demonstrate the robustness of the proposed method in handling these variations, a key aspect in multi-view 3D object detection.
read the caption
Figure 6: The paired sample of each evaluation set in Carla dataset.

🔼 This figure shows a qualitative comparison of depth estimation results between BEVDepth and the proposed method (Ours) on Lyft and nuScenes datasets. The top row displays the ground truth (GT) depth maps from LiDAR data, while the middle and bottom rows show the depth maps generated by BEVDepth and the proposed method, respectively. The visualization highlights the improved depth consistency achieved by the proposed method, especially in challenging scenarios with occlusions and sparse LiDAR data.
read the caption
Figure 7: Multi-view visualization of the depth estimation of BEVDepth and Ours for (a)Lyft and (b)nuScenes samples. In general, our depth consistency was better in the Lyft dataset, while it was difficult to make a quantitative comparison in the case of nuScenes due to the sparseness of the LiDAR point clouds. The depth range is from 1m to 60m. Best viewed in color.
More on tables
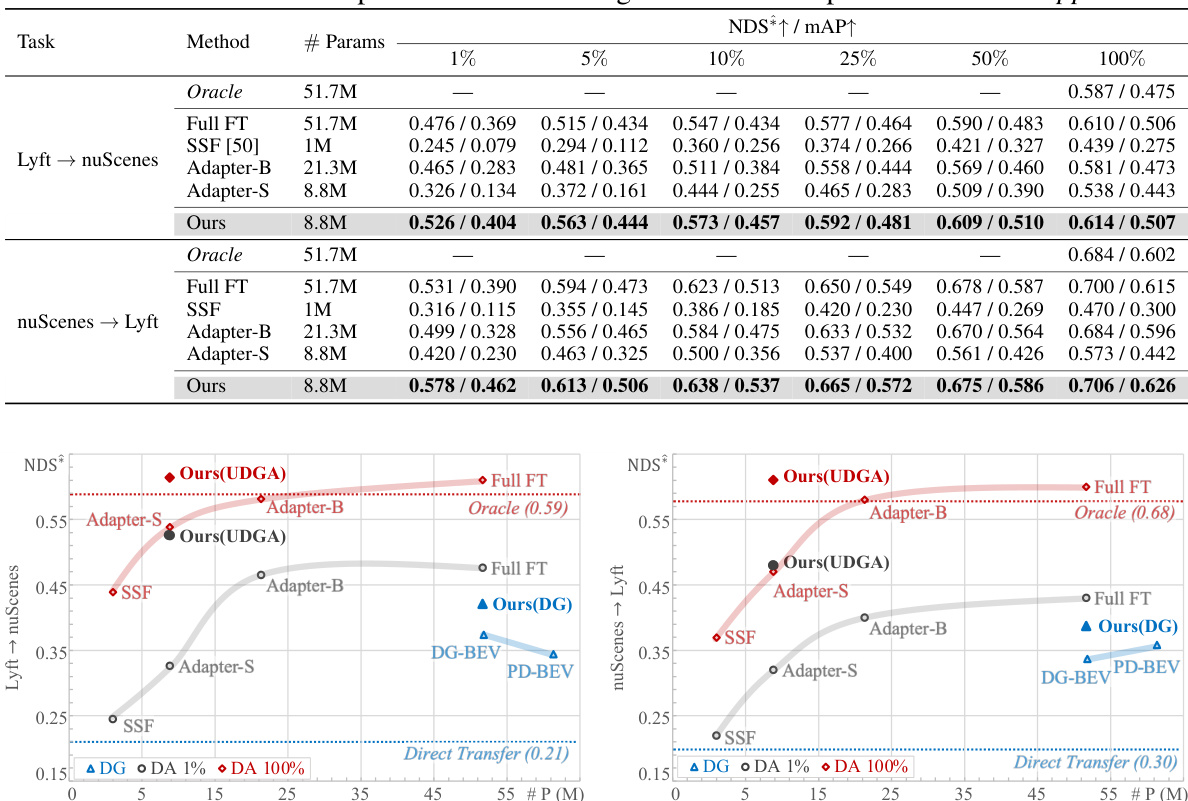
🔼 This table compares the performance of the proposed Unified Domain Generalization and Adaptation (UDGA) method against other Parameter-Efficient Fine-Tuning (PEFT) methods on the BEVDepth model. It shows how the performance changes based on the amount of target data available (from 1% to 100%) and the number of parameters used for training. The table also includes the performance of an oracle model (which has access to all target data) and a baseline model that performs direct transfer from the source domain without adaptation.
read the caption
Table 2: Comparison of UDGA performance on BEVDepth with various PEFT modules, SSF [50], and Adapter [48]. We construct six different target data splits from 1% to 100%. Additionally, # Params denote the number of parameters for training. Note that represents ‘Do not support’.

🔼 This table presents the ablation study results for the Unified Domain Generalization and Adaptation (UDGA) framework. It shows the impact of different components of the UDGA framework (pre-trained blocks B, LEDA blocks A, and the loss functions) on the model’s performance in terms of NDS* and mAP for two cross-domain tasks: Lyft to nuScenes and nuScenes to Lyft. The study uses 10% of the target domain data for adaptation. Each row represents a different configuration of the framework, with checkmarks indicating the inclusion of specific components. The results demonstrate the effectiveness of the UDGA components in improving the model’s performance.
read the caption
Table 3: Ablation studies on UDGA (10% Adaptation). B and A represents pre-trained blocks and LEDA blocks, respectively. Note that we train B and A, alternatively (i.e., pre-train and fine-tune).
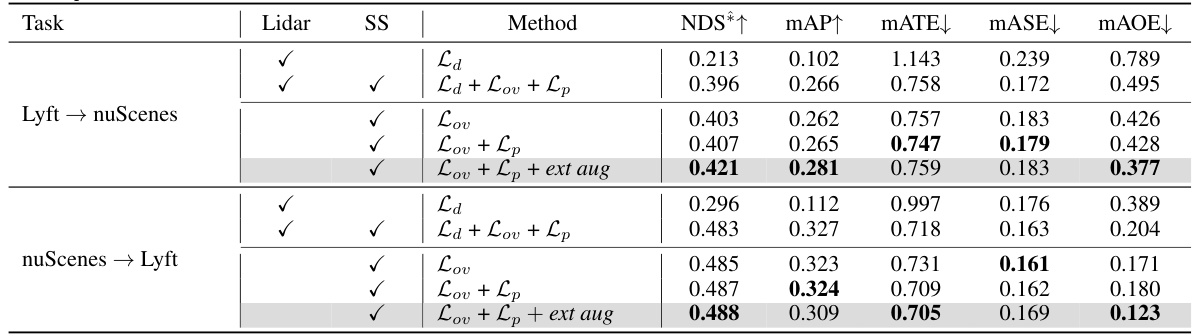
🔼 This table presents the ablation study results on the impact of the proposed depth constraint modules (Lov and Lp) on domain generalization performance. It compares the results using LiDAR depth supervision, self-supervised overlap depth, and different combinations of Lov and Lp, along with additional external augmentation. The performance metrics (NDS*, mAP, mATE, mASE, mAOE) are reported for two domain generalization tasks: Lyft → nuScenes and nuScenes → Lyft.
read the caption
Table 4: Ablation studies on Domain Generalization with our novel depth constraint modules, Lov and Lp. Lidar and SS each represents LiDAR depth supervision and Self-Supervised overlap depth.

🔼 This table compares the proposed method’s performance with state-of-the-art (SOTA) techniques in domain generalization for multi-view 3D object detection. It shows the results on three different cross-domain scenarios (Lyft to nuScenes, nuScenes to Lyft, and Waymo to nuScenes). The metrics used for comparison include NDS, mAP, mATE, mASE, and MAOE. The ‘Oracle’ and ‘Direct Transfer’ rows provide upper and lower bound performance, respectively. The table highlights that the proposed method significantly outperforms existing SOTA techniques in the challenging cross-domain scenarios.
read the caption
Table 1: Comparison of Domain Generalization performance with existing SOTA techniques. The bold values indicate the best performance. Note that all methods are evaluated on ‘car’ category.

🔼 This table compares the performance of the proposed Unified Domain Generalization and Adaptation (UDGA) method with other state-of-the-art (SOTA) domain generalization techniques. The comparison is done across several benchmark datasets (Lyft, nuScenes, and Waymo) and focuses on the ‘car’ object category. The results are presented using several metrics (NDS*, mAP, mATE, mASE, MAOE) to assess the overall performance and a ‘Closed Gap’ metric, which shows the relative improvement of each method compared to a simple direct transfer approach. The ‘Oracle’ row provides an upper bound representing the ideal performance achievable with full supervision on the target domain.
read the caption
Table 1: Comparison of Domain Generalization performance with existing SOTA techniques. The bold values indicate the best performance. Note that all methods are evaluated on ‘car’ category.

🔼 This table presents the results of experiments conducted using CARLA simulation to evaluate the model’s performance under simulated domain changes. The model was trained exclusively on the source domain data and tested on three different target domains. The ‘diff’ row shows the difference in performance metrics between the source and each target domain. The bold values highlight the most significant performance drops in the target domains.
read the caption
Table 7: Performance under CALRA-simulated domain changes. The model is trained exclusively on Source. The diff shows the Source-Target difference. The bold values indicate the worst difference.
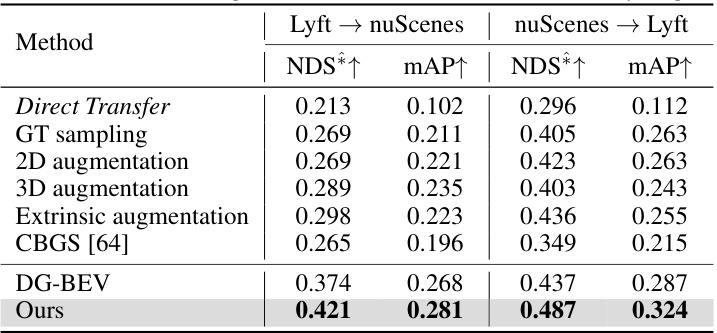
🔼 This table compares the performance of the proposed Unified Domain Generalization and Adaptation (UDGA) method with other state-of-the-art (SOTA) domain generalization techniques on the task of multi-view 3D object detection. The results are presented for three different domain adaptation scenarios (Lyft → nuScenes, nuScenes → Lyft, and Waymo → nuScenes), each showing the NDS (NuScenes Detection Score), mAP (mean Average Precision), mATE (mean Average Translation Error), mASE (mean Average Scale Error), and mAOE (mean Average Orientation Error) metrics for the ‘car’ category. The ‘Oracle’ row represents the upper bound performance achievable with full supervision on the target domain, while ‘Direct Transfer’ represents the lower bound performance achieved without any domain adaptation. The ‘Closed Gap’ metric shows the improvement achieved by each method compared to direct transfer.
read the caption
Table 1: Comparison of Domain Generalization performance with existing SOTA techniques. The bold values indicate the best performance. Note that all methods are evaluated on ‘car’ category.

🔼 This table presents an ablation study analyzing the contribution of each module (backbone, view transformer, BEV encoder, and detection head) to the overall performance of the UDGA method with 5% target domain adaptation. The results are shown separately for the Lyft to nuScenes and nuScenes to Lyft domain adaptation tasks. The gray highlighted row indicates the full UDGA model’s performance, serving as a benchmark for comparison against models with individual modules removed.
read the caption
Table 9: Performance comparison for each module (UDGA 5%). Gray highlight denotes 'Ours'.

🔼 This table presents a comparison of the performance of different adapter structures within the UDGA framework when using 10% of the target data for adaptation. Different combinations of convolutional and linear layers were tested for the ‘Project Down’ and ‘Project Up’ modules of the adapter. The results are presented in terms of NDS* and mAP for both Lyft→nuScenes and nuScenes→Lyft domain adaptation tasks. The table highlights that using a convolutional layer for the Project Down module and a linear layer for the Project Up module (Ours) yields the best overall performance.
read the caption
Table 10: Comparison with various adapter structures (UDGA 10%). Gray highlight denotes ‘Ours’.
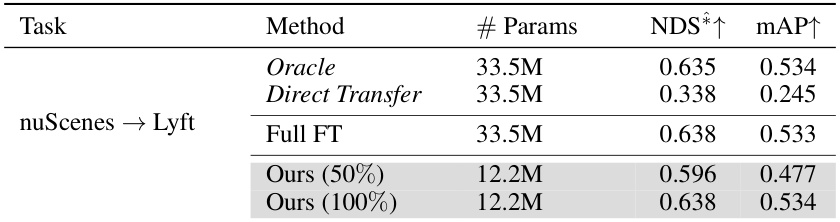
🔼 This table compares the performance of the proposed Unified Domain Generalization and Adaptation (UDGA) method against other Parameter-Efficient Fine-Tuning (PEFT) methods such as SSF and Adapter. It shows the impact of different amounts of target data (1% to 100%) on the performance of the model. The number of parameters used for training is also included for each method, allowing for a comparison of efficiency.
read the caption
Table 2: Comparison of UDGA performance on BEVDepth with various PEFT modules, SSF [50], and Adapter [48]. We construct six different target data splits from 1% to 100%. Additionally, # Params denote the number of parameters for training. Note that represents 'Do not support'.
Full paper#