↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current cross-embodiment reinforcement learning (RL) methods struggle to transfer knowledge between robots with different physical characteristics. They often learn solutions tightly coupled to specific tasks, hindering generalization. This limits the applicability of RL in real-world scenarios where robots may encounter diverse situations and physical forms. Existing unsupervised RL methods, focusing on single-embodiment pre-training, also fall short in addressing this challenge.
To overcome this, the paper introduces Cross-Embodiment Unsupervised RL (CEURL) and proposes PEAC, a novel algorithm. PEAC uses an intrinsic reward function that encourages learning embodiment-aware, task-agnostic knowledge. Extensive experiments demonstrate PEAC’s superiority in enabling robots to quickly adapt to new tasks and different physical bodies (embodiments). The results highlight PEAC’s effectiveness in improving both adaptation performance and generalization across various simulated and real-world scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning and robotics. It addresses the critical challenge of generalizing RL agents across different robot embodiments, a major hurdle in real-world applications. The proposed unsupervised pre-training method, PEAC, offers a novel solution and opens doors for more robust and adaptable robots, impacting multiple research areas. Furthermore, the flexible integration of PEAC with existing RL techniques expands its applicability and provides a valuable tool for future research.
Visual Insights#
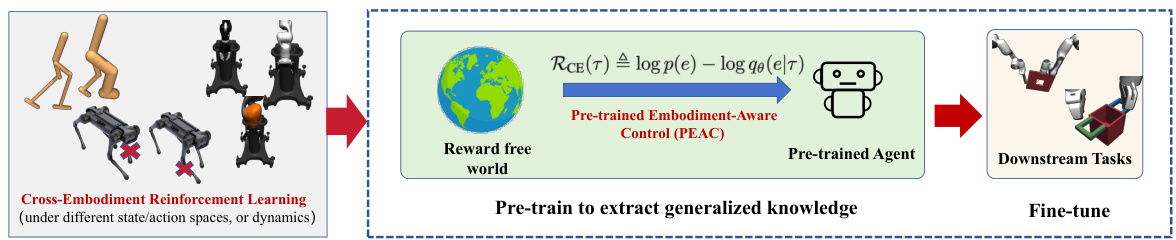
This figure illustrates the overall framework of Cross-Embodiment Unsupervised Reinforcement Learning (CEURL). It shows three stages: 1) Cross-Embodiment setting depicting the challenge of training RL agents across different robot morphologies. 2) The PEAC algorithm’s pre-training phase in reward-free environment to learn embodiment-aware knowledge using a novel intrinsic reward function. 3) The downstream task fine-tuning stage, where the pre-trained agent adapts quickly to new tasks.

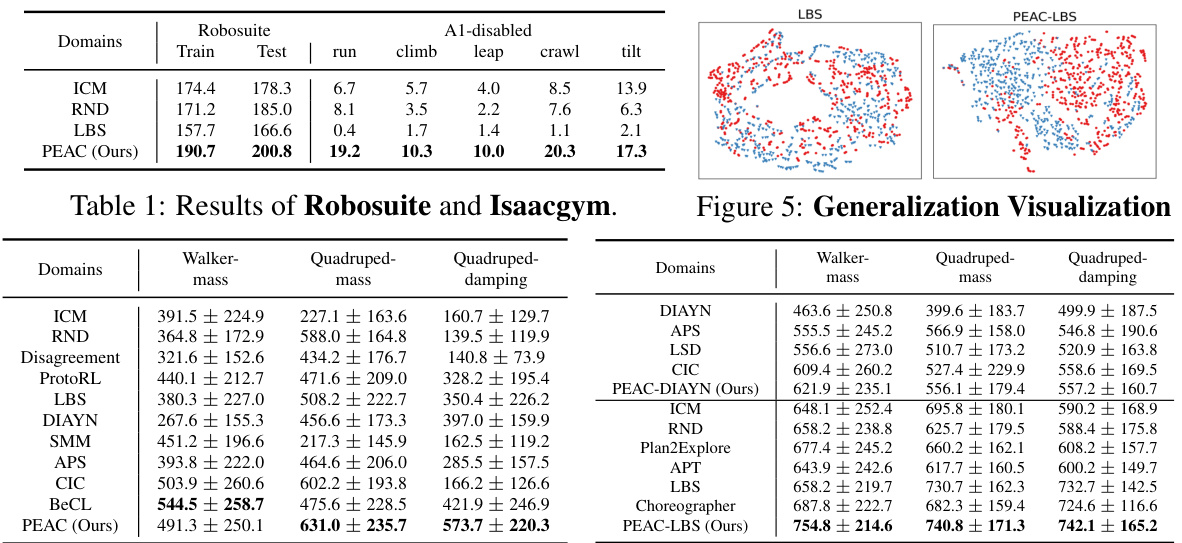
This table shows the parameter ranges for the mass (m) and damping (l) factors used in the state-based and image-based DeepMind Control Suite (DMC) experiments. It details the values used for training and generalization across three different embodiment settings: Walker-mass, Quadruped-mass, and Quadruped-damping.
In-depth insights#
CEURL Framework#
The Cross-Embodiment Unsupervised Reinforcement Learning (CEURL) framework offers a novel approach to training RL agents that can generalize across diverse embodiments. It departs from traditional methods by emphasizing unsupervised pre-training in reward-free environments, allowing agents to learn embodiment-aware representations without task-specific biases. This is achieved by formulating the problem as a Controlled Embodiment Markov Decision Process (CE-MDP), explicitly modeling the distribution of embodiments and their inherent variability. The framework’s focus on unsupervised learning is crucial, as it enables the discovery of task-agnostic skills and strategies that facilitate adaptation to downstream tasks. A key innovation is the introduction of an embodiment-aware intrinsic reward function, guiding exploration towards states that are informative about embodiment distinctions. Ultimately, the CEURL framework aims to bridge the gap between simulation and real-world deployment, significantly reducing the data requirements for new embodiments and enhancing the robustness and adaptability of RL agents in real-world scenarios.
PEAC Algorithm#
The PEAC (Pre-trained Embodiment-Aware Control) algorithm is a novel method for cross-embodiment unsupervised reinforcement learning. Its core innovation is the introduction of a cross-embodiment intrinsic reward function, RCE, designed to encourage the agent to learn embodiment-aware knowledge independent of specific tasks. This is a significant departure from previous methods, which often resulted in task-specific knowledge transfer. PEAC is formulated within the framework of a Controlled Embodiment Markov Decision Process (CE-MDP), providing a principled theoretical foundation. Its flexible design allows for seamless integration with existing unsupervised RL techniques, such as exploration and skill discovery methods, enhancing the exploration and skill acquisition process across diverse embodiments. Empirical evaluations demonstrate PEAC’s effectiveness in improving adaptation performance and cross-embodiment generalization, outperforming existing state-of-the-art methods across various simulated and real-world environments. The algorithm’s ability to effectively pre-train agents in reward-free environments and then quickly adapt to new downstream tasks addresses a key challenge in deploying RL agents in real-world scenarios.
Empirical Results#
The empirical results section of a research paper should present a robust evaluation of the proposed method. It needs to clearly demonstrate the method’s effectiveness compared to relevant baselines across a diverse range of experimental settings. The choice of metrics should directly reflect the paper’s claims and goals. Results should be presented with appropriate statistical significance measures, like error bars or confidence intervals, to show the reliability of findings. Visualizations, such as graphs or charts, can greatly aid in understanding the results. The discussion should not only describe the observed outcomes but also analyze their implications, providing insights into why certain results were obtained, and potentially suggesting areas for future work. A well-written empirical results section is crucial for establishing the validity and impact of the research.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a complex system. In the context of a machine learning model, this involves removing or altering specific parts (e.g., layers, modules, hyperparameters) to observe the impact on overall performance. The goal is to isolate and quantify the contribution of each component, providing a more nuanced understanding of the model’s inner workings. Well-designed ablation studies help in debugging, identifying critical features, guiding architectural improvements, and building intuition. For instance, removing a particular module might drastically reduce performance, highlighting its vital role, while altering a hyperparameter only slightly affects the outcome, suggesting its minor influence. The insights from ablation studies improve model interpretability and lead to more robust and efficient designs. Careful selection of components to ablate and a rigorous experimental design are crucial for reliable results; otherwise, the study may yield misleading conclusions, hindering the development process.
Future Work#
Future research directions stemming from this work on cross-embodiment unsupervised reinforcement learning (CEURL) could focus on handling more diverse embodiments with significantly different structures. The current approach assumes some structural similarity, limiting its applicability to robots with vastly different morphologies. Addressing the limitations of existing unsupervised RL methods in tackling more challenging downstream tasks is also crucial. Investigating more efficient methods for cross-embodiment exploration and skill discovery is a key area for improvement, especially within complex and unpredictable real-world scenarios. Developing more robust and efficient algorithms which can handle noisy or incomplete data and adapt to unforeseen changes in the environment is another vital aspect of future research. Finally, extending the methodology to multi-agent systems presents a significant opportunity for impactful advancements in collaborative robotics and complex decision-making.
More visual insights#
More on figures

This figure shows the benchmark environments used in the paper to evaluate the proposed PEAC algorithm. The environments are diverse, including simulated environments from the DeepMind Control Suite (DMC), Robosuite, and Isaacgym. The environments represent a variety of tasks and robotic platforms, demonstrating the versatility and generalizability of the PEAC approach across different embodiments and challenges.
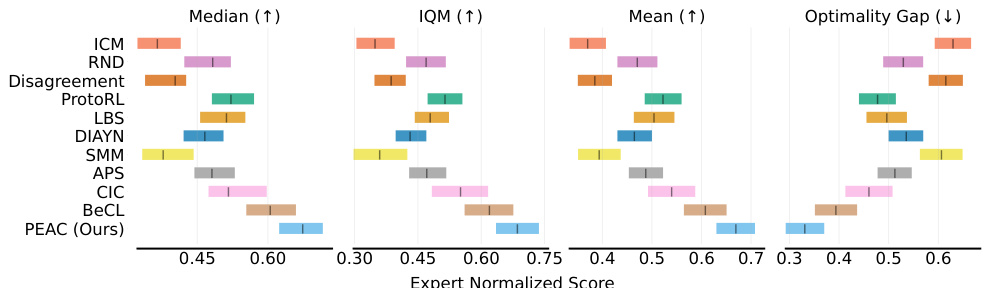
This figure shows the performance comparison of different algorithms on state-based DeepMind Control Suite (DMC) tasks. Four metrics are presented: Median, Interquartile Mean (IQM), Mean, and Optimality Gap. Each algorithm was tested across three different embodiment settings and four downstream tasks, with ten random seeds used for each combination, resulting in 120 runs per algorithm. The figure visually represents the performance of PEAC against other state-of-the-art unsupervised reinforcement learning methods. The y-axis represents the algorithm, and the x-axis shows the performance scores.
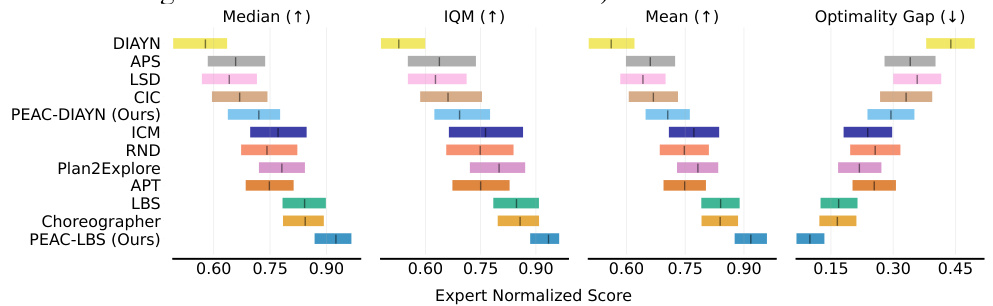
This figure shows the performance comparison of different algorithms on image-based DeepMind Control Suite (DMC) tasks. Multiple algorithms (including PEAC and its variants) were evaluated across three different embodiment settings and four downstream tasks. Each data point represents the average of 36 runs (10 seeds x 3 embodiment settings x 4 tasks). The metrics used are Median, Interquartile Mean (IQM), Mean, and Optimality Gap, providing a comprehensive evaluation of the algorithms’ performance in the cross-embodiment setting.
This figure illustrates the concept of Cross-Embodiment Unsupervised Reinforcement Learning (CEURL) and the proposed PEAC algorithm. The left panel shows different embodiments and how direct training on downstream tasks can lead to task-specific knowledge, while CEURL pre-trains agents in reward-free settings for embodiment-aware knowledge. The center panel details PEAC, highlighting its intrinsic reward function, and the right panel demonstrates the improved generalization and faster adaptation to downstream tasks.

This figure showcases the benchmark environments used in the paper’s experiments to evaluate the proposed PEAC algorithm. These include simulated environments from the DeepMind Control Suite (DMC), Robosuite, and Isaac Gym. DMC provides various simulated robotic tasks with different state and image-based observation modalities. Robosuite offers a range of robotic manipulation tasks, and Isaac Gym is used for simulating legged robots and real-world scenarios. The diversity of these platforms allows for a comprehensive evaluation of PEAC’s performance across different types of robots and tasks.

This figure displays ablation studies on the impact of varying pre-training timesteps on the performance of different algorithms in image-based DeepMind Control Suite (DMC). The x-axis represents the number of pre-training steps (100k, 500k, 1M, and 2M), and the y-axis represents the expert normalized score. The figure visualizes how the performance of different algorithms, including PEAC-LBS, PEAC-DIAYN, and various baselines (LBS, APT, Plan2Explore, RND, ICM, DIAYN, APS, LSD, CIC, Choreographer), changes with the amount of pre-training. This helps understand the impact of pre-training duration on cross-embodiment adaptation and skill discovery.
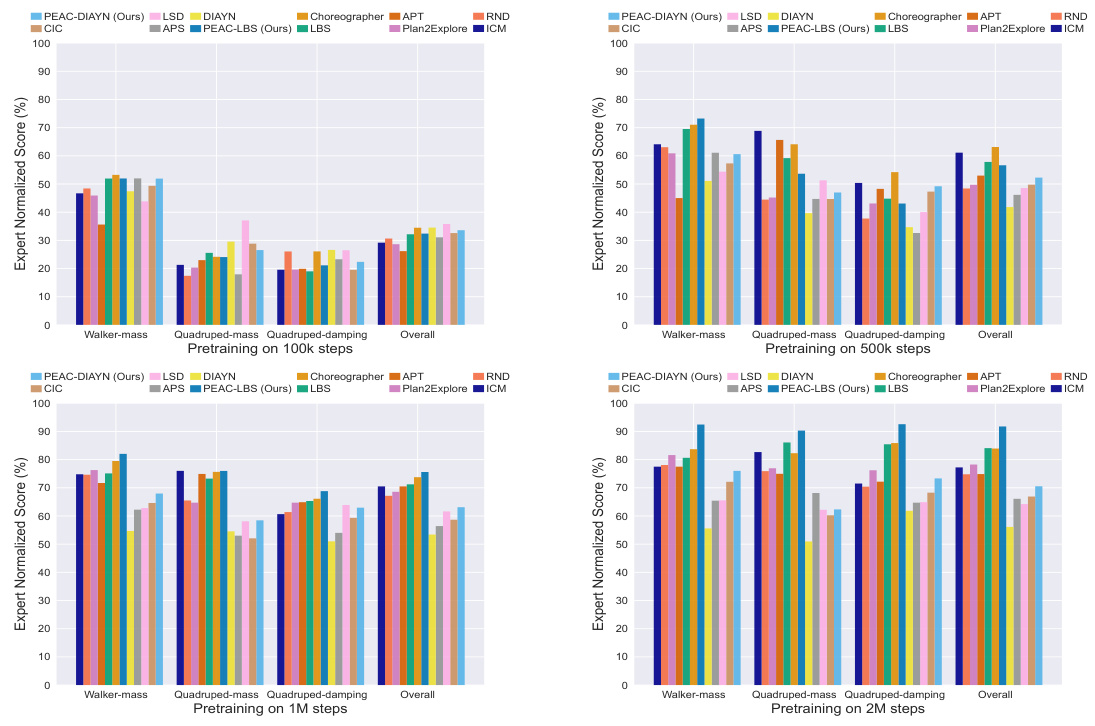
This figure presents an ablation study on the effect of different pre-training steps on the performance of various algorithms in image-based DeepMind Control Suite (DMC) environments. It shows expert normalized scores for different algorithms (PEAC-DIAYN, LSD, DIAYN, CIC, PEAC-LBS, LBS, Choreographer, APT, Plan2Explore, RND, ICM) across three different embodiment settings (Walker-mass, Quadruped-mass, Quadruped-damping) and an overall average. The results are shown separately for pre-training steps of 100k, 500k, 1M, and 2M steps, illustrating how the performance of each algorithm changes with varying pre-training durations.

This figure visualizes the generalization ability of pre-trained models to unseen embodiments using t-SNE dimensionality reduction. The plots show the hidden states extracted from the models when sampling trajectories in different, previously unseen embodiments. Different colored points represent states from different embodiments. The figure illustrates the ability of PEAC-LBS to better distinguish between the different unseen embodiments compared to other baselines.

This figure shows four different benchmark environments used in the paper. These are variations of the walker and cheetah robots, modified to have different leg lengths (Walker-length) and torso lengths (Cheetah-torsolength). These variations were used to test the generalizability of the PEAC algorithm to unseen embodiments with different morphologies.

This figure showcases the benchmark environments used to evaluate the PEAC algorithm. It includes simulated environments from the DeepMind Control Suite (DMC), Robosuite, and Isaac Gym. These environments represent a variety of robotic platforms and tasks, testing the algorithm’s ability to generalize across different embodiments (robot designs and capabilities). The image visually shows examples of the diverse robots and tasks, highlighting the scope of the experiments.
More on tables

This table lists the parameters used for the state-based and image-based DeepMind Control Suite (DMC) experiments. It shows the range of mass values (m) used for the Walker and Quadruped robots and the range of damping values (l) used for the Quadruped robot in both training and generalization phases of the experiments. These parameters define the different embodiments used in the cross-embodiment experiments.
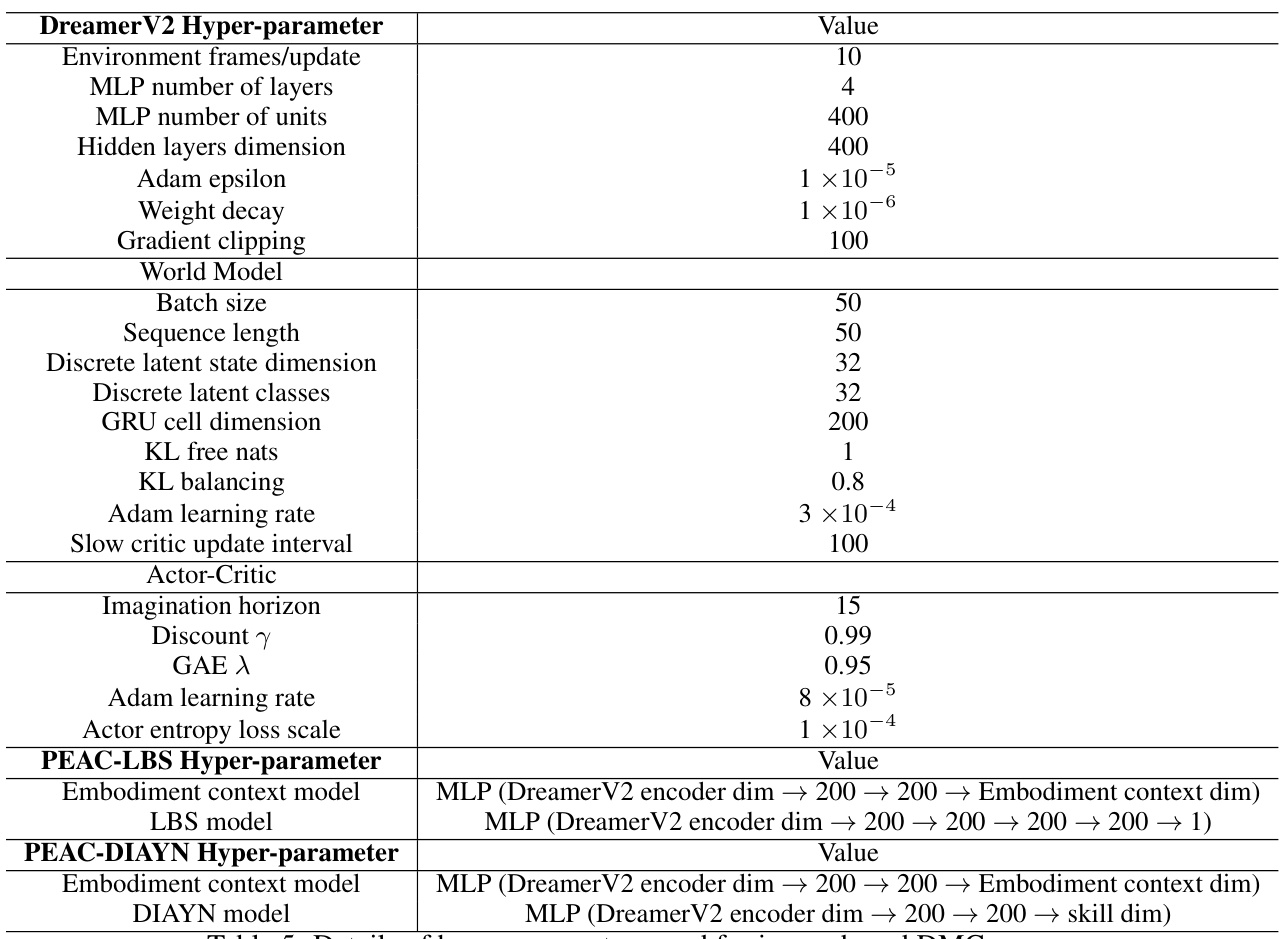
This table shows the parameters used for generating different embodiments in both state-based and image-based DeepMind Control Suite (DMC) experiments. For state-based DMC, three different embodiment distributions are created by varying the mass (Walker-mass, Quadruped-mass) or damping (Quadruped-damping) of the robots. The table specifies the range of mass or damping values used during training and generalization phases for each embodiment setting. For image-based DMC, the same three embodiment distributions and parameter ranges are used.
This table shows the performance of PEAC and baselines on Robosuite and Isaacgym benchmark environments. It compares the average cumulative reward achieved by different algorithms across various tasks and robotic platforms (Panda, IIWA, Kinova3, Jaco, and Aliengo). It highlights PEAC’s superior performance in few-shot learning and generalization to unseen embodiments. The results demonstrate the effectiveness of PEAC in both simulated and real-world environments.
This table lists the hyperparameters used for the Isaacgym experiments. It includes parameters for the Proximal Policy Optimization (PPO) algorithm, such as the clip range, generalized advantage estimation (GAE) lambda, learning rate, reward discount factor, minimum policy standard deviation, number of environments, and batch sizes. Additionally, it shows the hyperparameters specific to the Pre-trained Embodiment-Aware Control (PEAC) algorithm, including the type of historical information encoder (GRU), the length of the encoded historical information, and the architecture of the embodiment context model (MLP).

This table presents the aggregate performance metrics (Median, IQM, Mean, and Optimality Gap) for various unsupervised reinforcement learning algorithms in the state-based DeepMind Control Suite (DMC) benchmark. Each algorithm was evaluated across three different embodiment settings (different mass or damping), four downstream tasks, and ten random seeds. The table summarizes the overall performance across all these conditions. The results show the effectiveness of each algorithm, particularly compared against the proposed PEAC algorithm.
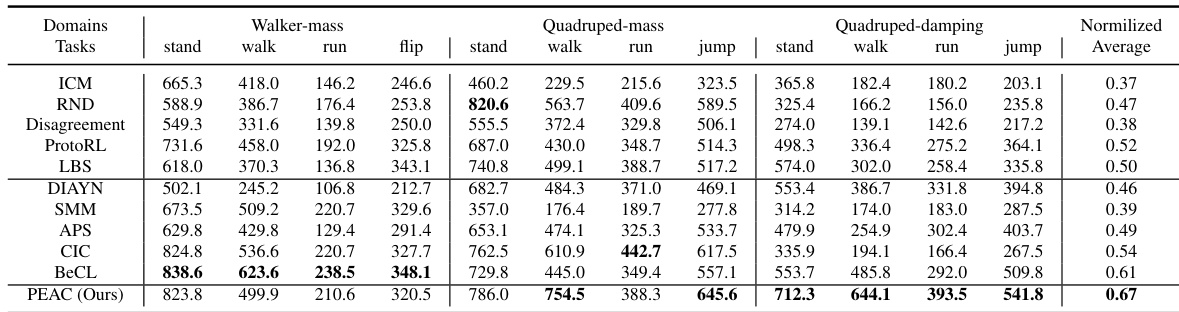
This table presents the performance comparison of different reinforcement learning algorithms on state-based DeepMind Control Suite (DMC) tasks. Four metrics (Median, Interquartile Mean (IQM), Mean, and Optimality Gap) are used to evaluate the performance across three different embodiment settings and four downstream tasks. Each algorithm was trained with 10 different random seeds, resulting in a total of 120 runs (3 embodiment settings * 4 tasks * 10 seeds) for each algorithm. The table highlights the performance of the PEAC algorithm in comparison to several baselines.
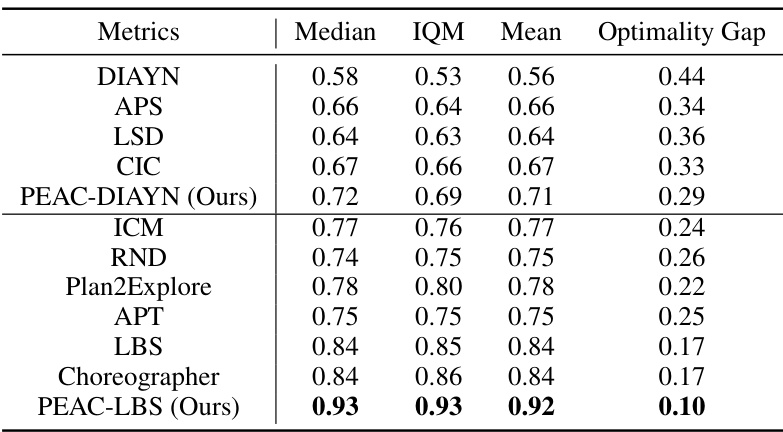
This table presents the aggregate performance metrics for various algorithms on image-based DeepMind Control Suite (DMC) tasks. It shows the median, interquartile mean (IQM), mean, and optimality gap across different algorithms. The experiments involved 3 embodiment settings, 3 random seeds for each setting, and 4 downstream tasks, resulting in 36 runs per algorithm.

This table presents the detailed results of the generalization ability of the fine-tuned models in state-based DeepMind Control Suite (DMC) using unseen embodiments. The average cumulative rewards of different algorithms are shown for different downstream tasks and embodiments (Walker-mass, Quadruped-mass, and Quadruped-damping). This allows for assessment of the generalization performance of the pre-trained models across various unseen embodiments.

This table presents the results of the Robosuite and Isaacgym experiments. It shows the performance of the PEAC algorithm compared to baselines (ICM, RND, LBS) across various tasks (climb, leap, crawl, tilt) and embodiment settings (Al-disabled). The metrics used to evaluate the performance are not specified in the caption itself but are likely related to the success rate of completing each task or other performance metrics relevant to legged locomotion. Higher numbers likely indicate better performance.

This table presents the aggregate performance metrics for various reinforcement learning algorithms on state-based DeepMind Control Suite (DMC) tasks. The metrics include median, interquartile mean (IQM), mean, and optimality gap (OG). Each algorithm was evaluated across three embodiment settings, with ten seeds used for training and evaluation on four downstream tasks per embodiment, resulting in 120 total runs per algorithm. The table allows comparison of the different algorithms’ performance across these metrics, indicating their relative effectiveness and stability.

This table presents the ablation study results in state-based DeepMind Control Suite (DMC) by adding the embodiment discriminator to the baselines. The results show that adding the embodiment discriminator to the baselines improves performance, and PEAC still outperforms the baselines.

This table presents the average cumulative reward achieved by different algorithms across various downstream tasks in state-based DeepMind Control Suite (DMC) environments. The experiments involve three distinct embodiment settings (Walker-mass, Quadruped-mass, Quadruped-damping) and four downstream tasks (stand, walk, run, flip). Each setting is tested with 10 random seeds, and the average cumulative reward is reported for each algorithm. This table helps to evaluate the generalization performance of each algorithm to unseen embodiments in state-based DMC.

This table presents the aggregate performance metrics for various algorithms on state-based DeepMind Control Suite (DMC) tasks. The metrics shown include median, interquartile mean (IQM), mean, and optimality gap (OG), providing a comprehensive performance summary. Each algorithm was evaluated across three different embodiment settings, with 10 seeds per setting and four downstream tasks for each seed. This resulted in 120 runs (3 settings * 4 tasks * 10 seeds) per algorithm, ensuring robust statistical analysis.
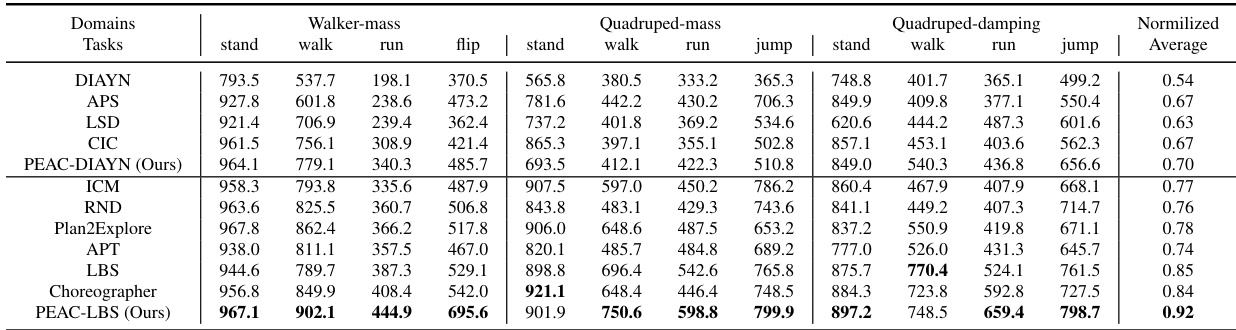
This table presents the average cumulative reward achieved by different reinforcement learning algorithms across various tasks and embodiments in state-based DeepMind Control Suite (DMC). The results are averaged over 10 seeds for each condition. The ’evaluation embodiments’ refers to test environments that the pre-trained agents were not trained on, demonstrating generalization capacity.
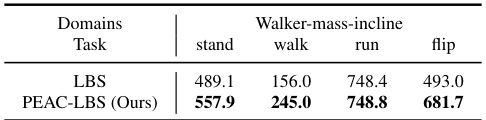
This table presents the results of the image-based DMC experiments for the Walker-mass-incline setting. The results show the average cumulative reward for each of four downstream tasks (stand, walk, run, and flip) for two algorithms: LBS and PEAC-LBS. PEAC-LBS consistently outperforms LBS in all tasks, suggesting its enhanced effectiveness in the more challenging incline terrain.

This table presents the quantitative results of applying different algorithms (DIAYN, PEAC-DIAYN, LBS, Choreographer, and PEAC-LBS) to the Walker-Cheetah environment in image-based DeepMind Control Suite (DMC). The environment involves two different types of robots (Walker and Cheetah) with varying tasks (stand, run, flip). Each algorithm’s performance is measured across four distinct task combinations, evaluating its effectiveness in handling the diverse embodiments.

This table presents the detailed results of the Walker-Humanoid experiment in image-based DeepMind Control Suite (DMC). The experiment involves two different robots, a Walker and a Humanoid, each performing various locomotion tasks. The results show the average cumulative reward (mean of 3 seeds) achieved by each algorithm for different tasks and robot combinations, providing a quantitative comparison of the performance of different algorithms under cross-embodiment conditions.

This table presents the results of the experiments conducted on two variations of the image-based DeepMind Control Suite (DMC) benchmark: Walker-length and Cheetah-torso_length. These variations modify the morphology of the robots, specifically altering leg length (Walker-length) and torso length (Cheetah-torso_length). The table shows the average cumulative reward achieved by different algorithms across various locomotion tasks (stand, walk, run, flip, run_backward, flip_backward) for each embodiment type. The algorithms compared include DIAYN, PEAC-DIAYN, LBS, Choreographer, and PEAC-LBS, all of which are discussed extensively in the paper. The table highlights the performance differences of these algorithms across tasks and embodiments, illustrating their ability to generalize across varied morphologies.
Full paper#



















