↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current research on large language models (LLMs) directly probes for complete world states, overlooking potential internal abstractions. This paper argues that LLMs may employ different levels of abstraction, prioritizing task-relevant information over complete world representation. Existing research lacks a systematic approach to probe for different levels of world abstraction, leading to contradictory findings.
To address this gap, this paper proposes a novel framework based on state abstraction theory from reinforcement learning. The study introduces a new text-based planning task, REPLACE, with a highly structured state space enabling the precise derivation and identification of different levels of world-state abstractions. Experiments using various LLMs reveal that fine-tuning and advanced pre-training improve the model’s ability to maintain goal-oriented abstractions during decoding, prioritizing task completion over the full world state and its dynamics. This work provides a more nuanced approach to analyzing LLMs, reconciling conflicting conclusions from past studies and shedding light on how LLMs construct internal world representations.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework for probing world representations in LLMs, addressing the limitations of existing methods. It reveals that successful LLMs prioritize goal-oriented abstractions over complete world state recovery, offering insights into the inner workings of these models and informing future research in LLM interpretability and design. This research also reconciles contradictory findings in the field and presents a new benchmark task for evaluating LLMs.
Visual Insights#
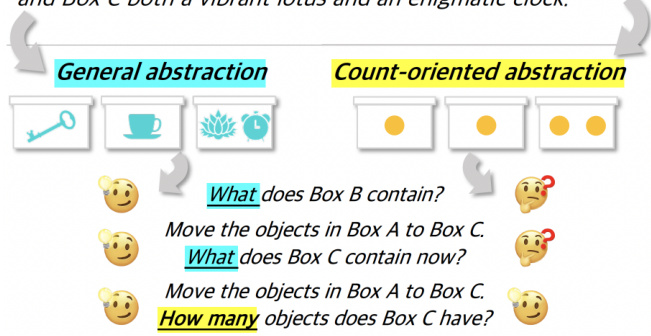
This figure illustrates two different ways of representing the state of a world described in a short text passage. The ‘General abstraction’ provides a detailed representation including the identity and location of each object. This allows answering various questions about the objects and their locations. The ‘Count-oriented abstraction’, on the other hand, simplifies the representation by only counting the number of objects in each container, which limits the types of questions it can answer to those related to counts.

This table presents the results of probing experiments conducted on the GRIPPER dataset. It shows the recovery rate (a measure of how well the model’s internal representations capture the predicates) for various predicates categorized by their abstraction level (raw, world-irrelevant, Q*-irrelevant, π*-irrelevant). Different LLMs (Llama2, Mistral, Llama3, Pythia, Phi3, and a Transformer baseline) are evaluated, allowing for a comparison of their ability to maintain different abstraction levels. The percentages reflect the accuracy of recovering each predicate from the LLM’s representations.
In-depth insights#
LLM World Models#
The concept of “LLM World Models” is a fascinating and rapidly evolving area of research. It explores whether large language models (LLMs) internally build representations of the world that go beyond simply processing text. Current research suggests a nuanced picture, with evidence for LLMs building various levels of world abstraction, rather than a single, complete model. Some studies show that LLMs can effectively extract specific details about entities and their relationships within a described scene. Others indicate a reliance on abstract representations that suffice for task completion, rather than a holistic state recovery. The level of abstraction seems to depend on both the pre-training and fine-tuning of the model, as well as the specific task. Goal-oriented abstractions, simplifying the world to prioritize task success over perfect state representation, are frequently observed. Further work needs to investigate the precise mechanisms LLMs employ to construct and utilize these internal world models, addressing the tension between building complete models and efficient, task-focused representations.
State Abstraction Lens#
The concept of a ‘State Abstraction Lens’ offers a novel perspective for analyzing large language models (LLMs). Instead of directly probing for a complete world state, which can be overly complex and yield inconsistent results, this approach focuses on how LLMs abstract the world state into different levels of representation. This is crucial because task completion often doesn’t require a full world model, but rather a simplified abstraction sufficient for the specific task. The framework, inspired by reinforcement learning, distinguishes between general abstractions useful for predicting future states and goal-oriented abstractions guiding actions towards task completion. This nuanced view helps resolve contradictions in prior research by acknowledging the varying needs for abstraction across different tasks. By examining the types of abstractions maintained during decoding (e.g., Q-irrelevant or π-irrelevant), we can gain insights into how LLMs prioritize task goals over full world state recovery.** This lens enhances our understanding of LLMs’ internal representations and their ability to effectively solve complex tasks through abstraction.
REPLACE Task Design#
The REPLACE task, designed for probing LLM world representations, cleverly uses a text-based planning scenario. Its core is a simplified world of containers and objects, manipulated by an LLM-agent to achieve a goal state. This modularity is key, as it allows for precise definition of different levels of state abstraction, from the raw state to goal-oriented abstractions that prioritize task completion over full world state recovery. The design facilitates isolating the specific types of abstraction LLMs use, and its structured state space allows for accurate probing of different abstraction levels. The task’s simplicity is a strength, not a weakness, enabling focused evaluation of the LLMs’ abstract reasoning capabilities rather than obscuring insights with complex world dynamics. The use of synthetic data, while limiting ecological validity, ensures controlled experiments and reduces confounding factors, aiding in clear interpretation of results. The combination of a well-defined task and a controlled experimental setup is crucial for drawing insightful conclusions about the nature of world representations within LLMs.
Probing Experiments#
The probing experiments section is crucial for validating the paper’s framework. The researchers use a well-designed text-based planning task, REPLACE, to rigorously assess different levels of state abstraction in LLMs’ internal representations. Fine-tuning and advanced pre-training significantly impact the type of abstraction preserved, with fine-tuned models prioritizing goal-oriented abstractions for task completion over recovering the full world state. This finding is particularly important as it clarifies conflicting results from previous studies. By examining the recoverability of different types of abstractions, the paper provides strong evidence supporting its framework, resolving the contradictions found in previous LLM probing studies. The experiments’ design is systematic, using multiple LLMs, and focusing on both success and quality of the model’s response, to present a well-rounded, in-depth analysis.
Future Work#
This research paper explores how large language models (LLMs) build internal representations of the world, focusing on state abstraction. Future work could significantly expand on the current framework by applying it to more complex and realistic tasks beyond the synthetic REPLACE task. Investigating LLMs’ handling of noisy or incomplete textual descriptions of the world would add robustness to the findings. A comparative analysis across different LLM architectures and training paradigms is crucial, including exploring the impact of different pre-training datasets and fine-tuning methods on state abstraction. Furthermore, research could delve deeper into the mechanistic aspects of how LLMs create these abstractions, potentially using techniques like probing classifiers on intermediate layers to understand their internal representations more comprehensively. The development of more realistic and richly annotated datasets would also significantly benefit the field, enabling more rigorous evaluations and allowing the proposed framework to be tested in real-world scenarios. Finally, exploring the relationship between LLM-built abstractions and human cognitive models of world understanding would offer valuable cross-disciplinary insights.
More visual insights#
More on figures

This figure shows how abstract predicates and actions are derived from raw predicates in the REPLACE task. The raw predicates represent the basic state of the world, such as the location of objects and the agent. The abstract predicates represent higher-level concepts, such as the proximity of objects to the agent or the overall goal of the task. The figure visually depicts how the different levels of abstraction are interconnected and how they combine to derive the actions taken by the agent.

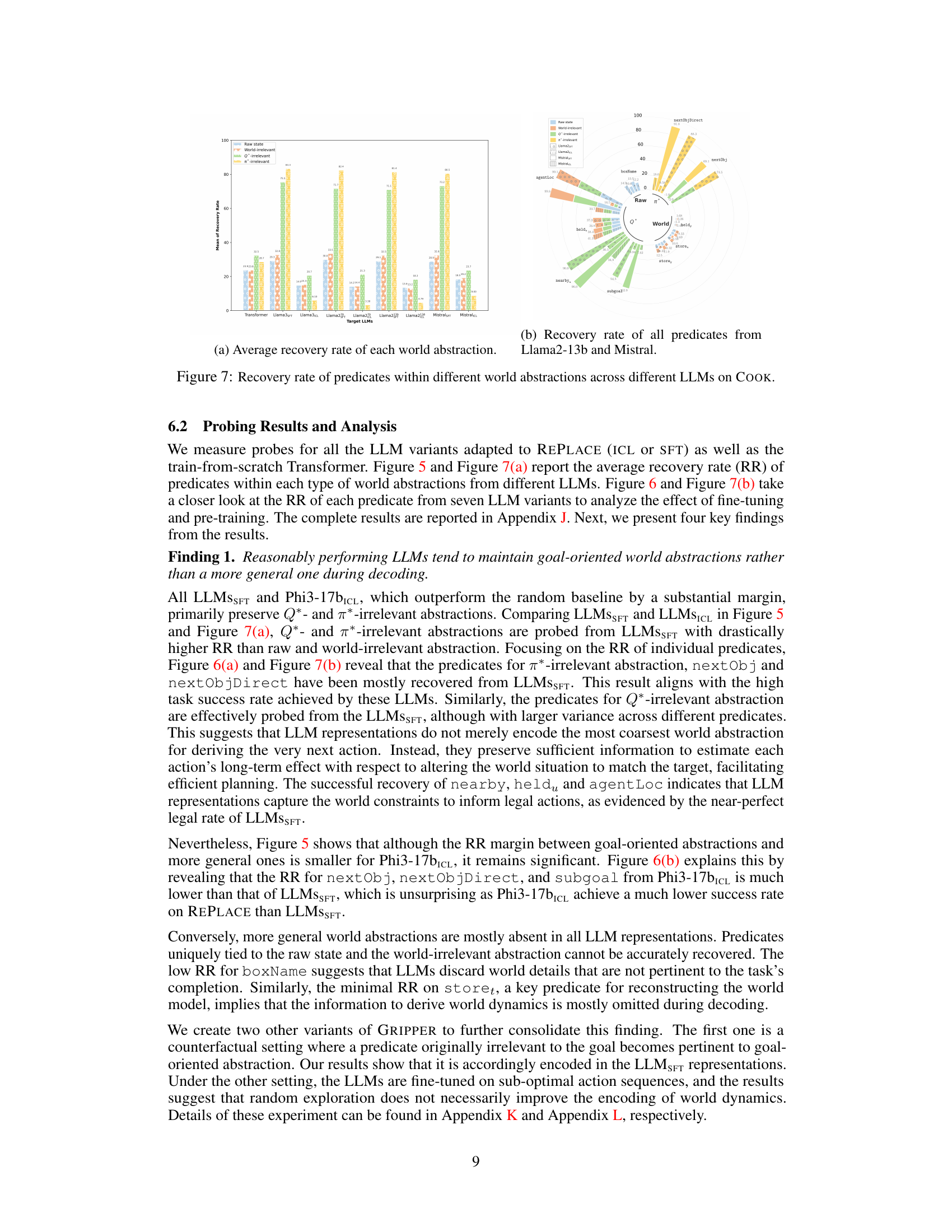
This figure shows the average recovery rate of different world state abstractions (raw state, world-irrelevant, Q*-irrelevant, π*-irrelevant) across various LLMs tested on the GRIPPER dataset. The LLMs include both those fine-tuned and those using in-context learning. The graph allows for comparison of how well each abstraction type is maintained by different models and training methods.

This figure shows the recovery rate of different predicates for various LLMs on the GRIPPER dataset. Predicates are categorized by their coarsest abstraction level (raw state, world-irrelevant, Q*-irrelevant, π*-irrelevant). The color-coding helps visualize which predicates contribute to multiple abstraction levels. The figure highlights the relative success of different LLMs in recovering various levels of abstraction, providing insights into which aspects of world knowledge they maintain during the task.
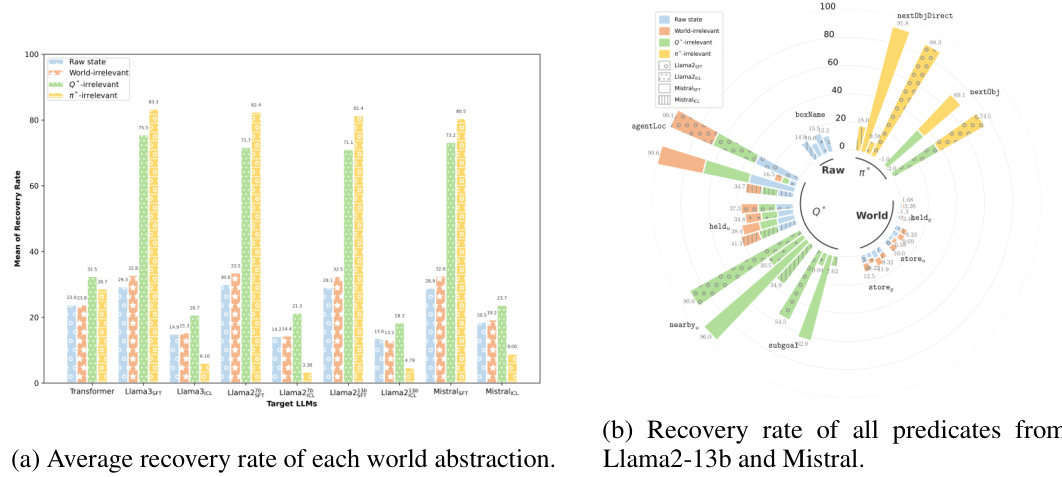
This figure shows the average recovery rate of different world abstractions (raw state, world-irrelevant, Q*-irrelevant, and π*-irrelevant) across various LLMs tested on the GRIPPER dataset. The recovery rate reflects how well the LLMs maintained the different abstraction levels during their decoding process for task completion. It shows the relative success of probes designed to extract raw versus abstract world states from the LLM’s internal representations.
More on tables

This table presents the performance of Llama2-13b and Mistral language models on two datasets, GRIPPER and COOK, in terms of the percentage of legal actions, successful task completions, and optimal solutions (achieving the goal with the minimum number of steps). It shows the models’ performance before and after fine-tuning (FT) and demonstrates the improvement in planning abilities after fine-tuning.
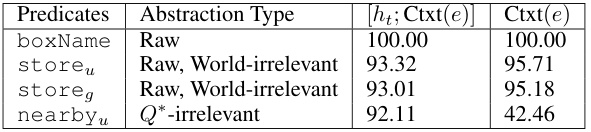
This table presents the results of probing experiments using different encoding methods for label candidates in the context of LLM representations. Specifically, it compares the recovery rate of various predicates using two methods: one incorporating the hidden states (ht) from the LLM and the contextualized embedding (Ctxt(e)) of the label candidate, and another using only the contextualized embedding (Ctxt(e)). The table shows that for some predicates, incorporating the hidden states improves performance, while for others it does not. This highlights the nuances of probing LLM representations, and the importance of selecting an appropriate approach depending on the specific predicate.

This table lists the different textual templates used for the predicates in the GRIPPER and COOK datasets. The templates provide variations in how the same predicate is expressed, adding to the realism and diversity of the datasets. For example, the ‘store’ predicate has multiple variations like ‘container contains object’, ‘container holds object’, etc., for both datasets. The ‘boxName’, ‘grab’, ‘put’, and ‘move’ predicates also have several variations, reflecting different ways of describing container names and actions.
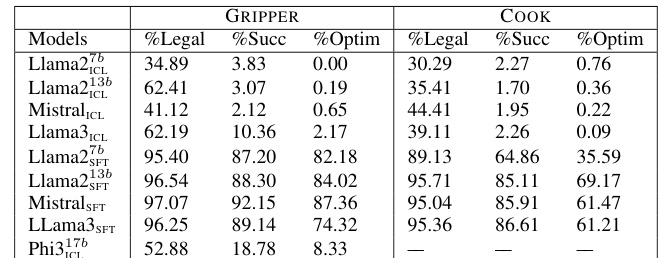
This table presents the performance of Llama2-13b and Mistral language models on two different datasets, GRIPPER and COOK. The performance is measured using three metrics: '%Legal' (the percentage of actions that comply with the task constraints), '%Succ' (the percentage of trials that successfully achieve the target state), and '%Optim' (the percentage of successful trials that achieve the target state using the minimum number of actions). The table shows that fine-tuning (SFT) significantly improves the performance of both models on both datasets, compared to using in-context learning (ICL).

This table presents the results of probing experiments conducted on the GRIPPER dataset. It shows the recovery rate, which is a normalized F1-score, for various predicates across different LLMs. Each predicate is categorized by its corresponding abstraction type (Raw, World-irrelevant, Q*-irrelevant, π*-irrelevant) which reflects the level of abstraction that a predicate maintains within an LLM’s representation. The table offers insights into how well the different types of world abstractions are preserved within various LLMs’ internal representations during decoding, indicating whether LLMs prioritize maintaining the complete world state, goal-oriented information or task-related details only.

This table presents the performance of probing different predicates across various LLMs on the GRIPPER dataset. The recovery rate, a measure of how well the predicates could be recovered from the LLM’s representations, is shown. The table breaks down the results by abstraction type (Raw, World-irrelevant, Q*-irrelevant, π*-irrelevant) to analyze how different types of abstractions affect the ability to recover the predicates from the LLMs. It compares the performance of different models (Llama2, Llama2-13b, Mistral, Llama3, Phi3-17b, Pythia-70m, Transformer).

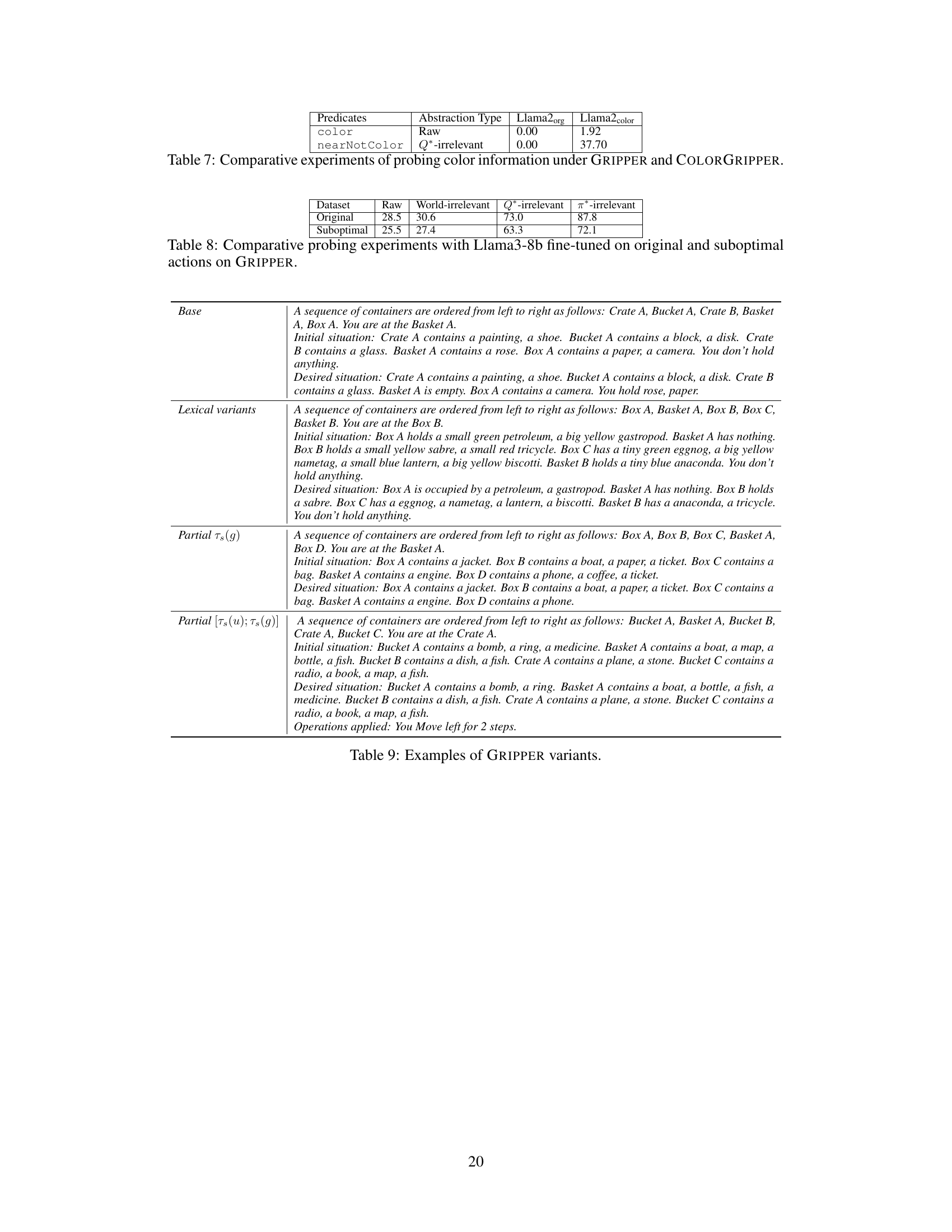
This table presents a comparison of the results from probing experiments conducted on two different datasets: GRIPPER and COLORGRIPPER. The experiments involved assessing the ability of language models to identify specific color information. The table shows that the recovery rate for color information is low when the color is irrelevant to the task (GRIPPER), but the recovery rate is significantly improved (37.70) when the color information becomes relevant to the task (COLORGRIPPER). This highlights that the model’s ability to recover information is linked to task relevance, supporting the idea of goal-oriented abstraction.

This table presents a comparison of probing experiment results using Llama3-8b, fine-tuned on two different versions of the GRIPPER dataset: one with original, optimal action sequences and another with suboptimal sequences. The goal is to assess how the use of suboptimal actions influences the recovery rates of different types of world abstractions (Raw, World-irrelevant, Q*-irrelevant, and π*-irrelevant). Recovery rate represents the success of probing, indicating how well different levels of abstraction are maintained in the LLM’s representations.

This table shows the performance of different LLMs on two datasets, GRIPPER and COOK. The performance is measured using three metrics: the percentage of legal actions (following the task constraints), the success rate (achieving the target state), and the optimality rate (achieving the target state with the minimum number of actions). The table compares the performance of different LLMs (Llama2, Mistral, Llama3, Phi3) using in-context learning (ICL) and supervised fine-tuning (SFT).
Full paper#