↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but slow, hindering real-time applications. Speculative decoding attempts to speed things up by using a smaller, faster model to create a draft, which is then reviewed by the larger model. However, this approach is inefficient due to slow autoregressive generation in the drafting process and uneven time allocation.
This paper introduces Cascade Speculative Drafting (CS Drafting) to solve these problems. CS Drafting uses two types of cascades: the Vertical Cascade replaces slow neural model generation with faster statistical methods, and the Horizontal Cascade optimizes time allocation by prioritizing more important tokens. Experiments show CS Drafting achieves substantial speedups compared to existing methods, making LLMs more efficient and practical for real-world use.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) optimization. It offers significant speed improvements in LLM inference, addressing a major bottleneck in deploying LLMs in real-world applications. The novel Cascade Speculative Drafting method provides new avenues for research into improving LLM efficiency, particularly for long-form text generation, impacting various NLP tasks and services.
Visual Insights#

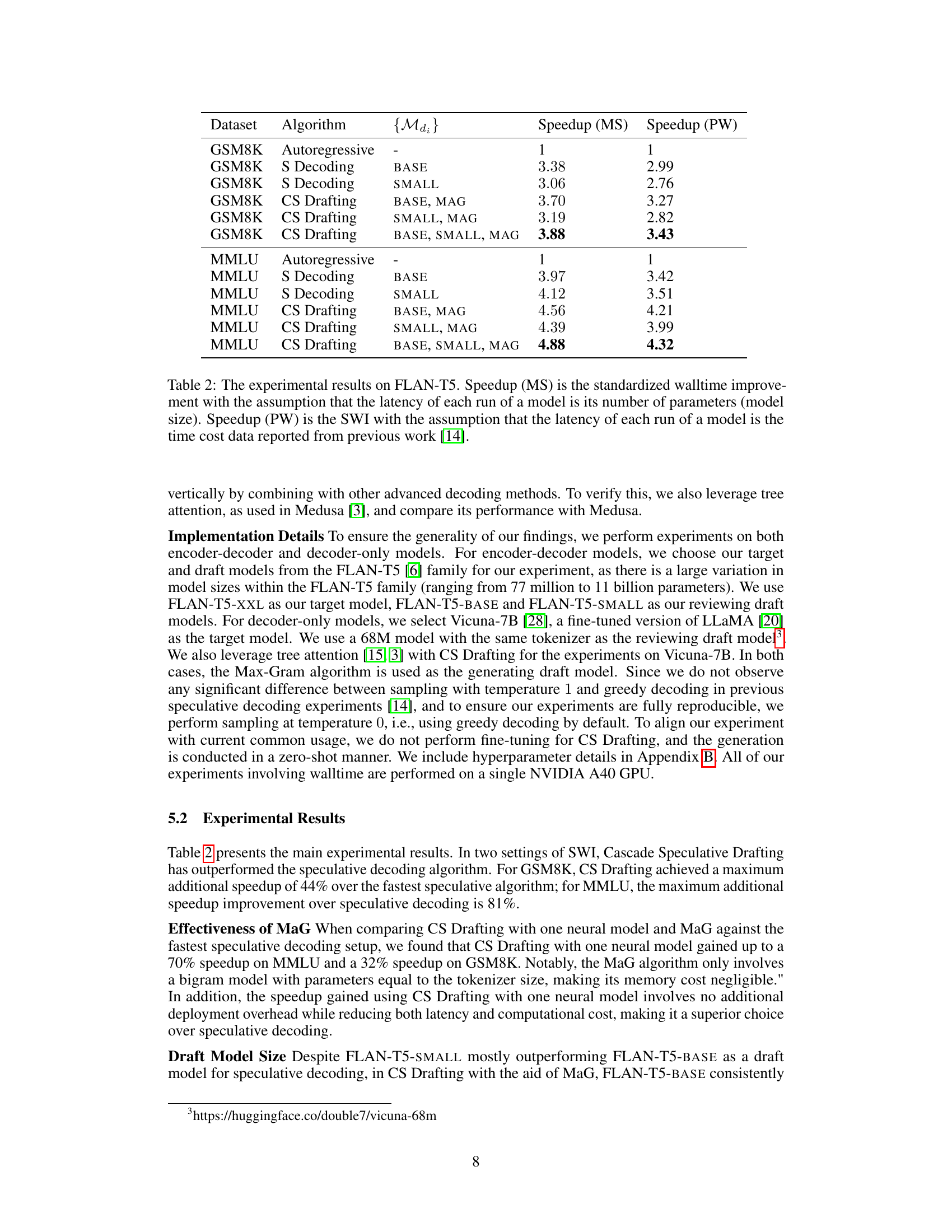
🔼 This figure illustrates the Cascade Speculative Drafting (CS Drafting) algorithm, which uses two cascades to improve efficiency. The Vertical Cascade uses a series of increasingly smaller models to generate drafts, reducing the reliance on slow autoregressive generation. The Horizontal Cascade optimizes time allocation by using larger models for important tokens and smaller models for less important tokens. The combination of these cascades leads to significant speed improvements compared to baseline methods.
read the caption
Figure 1: The CS Drafting algorithm features a recursive and resource-efficient design, implemented through two cascades: the horizontal cascade and the vertical cascade. The horizontal cascade involves using larger draft models to generate the earlier tokens and smaller models for the later tokens. The vertical cascade requires each model to review drafts from smaller models with the exception of the smallest model, which is a statistical language model. As the horizontal cascade and vertical cascade are orthogonal, CS Drafting combines both approaches for optimal efficiency. The figure shows an example of Cascade Speculative Drafting with target model Mt and draft models Md1, Md2, and Md3.

🔼 This table shows the simulated Expected Walltime Improvement Factor (EWIF) under the assumption that the acceptance distribution follows a Bernoulli distribution. It compares the EWIF of speculative decoding with and without a horizontal cascade using different FLAN-T5 models (BASE and SMALL). The results demonstrate that the horizontal cascade improves the EWIF in both CNN Dailymail and WMT EnDe datasets.
read the caption
Table 1: Simulated EWIF under the assumption that the acceptance distribution is a Bernoulli distribution. BASE and SMALL refer to FLAN-T5-BASE and FLAN-T5-SMALL. In the simulation, speculative sampling with horizontal cascade exceeded the performance of the vanilla speculative decoding on both CNN Dailymail [16] and WMT EnDe [2] datasets.
In-depth insights#
Cascade Drafting Speedup#
The concept of “Cascade Drafting Speedup” presented in the research paper proposes a novel approach to accelerate large language model (LLM) inference. It leverages a cascading architecture of multiple draft models, each progressively smaller and faster than the previous one. The vertical cascade eliminates slow autoregressive generation by using statistical language models as a base, significantly improving efficiency. The horizontal cascade optimizes the allocation of drafting resources by employing larger models for initial, more impactful tokens and smaller ones for later, less critical tokens. The combination of vertical and horizontal cascades leads to a substantial speedup in the overall inference process compared to standard speculative decoding and other baselines. This speedup is achieved without compromising the quality of LLM outputs, as the target model validates the drafts and maintains the original output distribution. The effectiveness of this technique is substantiated through both theoretical analysis and empirical evaluations across various datasets and language models, showcasing significant improvements in wall-time and standardized wall-time improvement.
Vertical Cascade Gains#
The concept of a ‘Vertical Cascade’ within the context of a large language model (LLM) likely refers to a hierarchical or recursive approach to speculative decoding. Instead of having a single smaller model generate drafts for a larger model to validate, a vertical cascade would involve multiple models of varying sizes, each building upon the output of the smaller one before final validation. This approach is designed to mitigate the inefficiencies of autoregressive generation inherent in smaller models, significantly reducing latency while preserving output quality. The smallest model in the cascade might even be a simple statistical model, reducing the computational burden of early-stage draft generation. The efficiency gains stem from the reduced computational cost and time spent generating less important tokens, as later tokens in a sequence have a lower probability of acceptance by the target model. Essentially, the vertical cascade optimizes the drafting process itself, creating a layered validation that prioritizes accuracy and efficiency in generating output. A key benefit is that it addresses a critical limitation of speculative decoding: the time-consuming nature of autoregressive generation. The cascading approach efficiently leverages the strengths of models of different sizes, offering a considerable speed-up over traditional methods.
Horizontal Cascade#
The Horizontal Cascade, as described in the research paper, is a crucial optimization strategy within the Cascade Speculative Drafting algorithm. It leverages the observation that the probability of a token generated by a draft model being accepted by the target model decreases as the token’s position in the sequence increases. This means tokens generated later are less likely to be ‘correct’ and therefore less important. To improve efficiency, the Horizontal Cascade uses larger, more powerful draft models for the initial tokens, where acceptance probability is highest. As the sequence progresses and the acceptance likelihood of subsequent tokens diminishes, smaller, faster models are employed. This dynamic allocation of resources ensures that computational power is focused on the tokens that are most likely to be validated and incorporated into the final output. The core benefit is a significant reduction in latency without sacrificing output quality, achieved by intelligently matching the model’s capacity to the probability of a token’s acceptance.
Max-Gram Efficiency#
The Max-Gram algorithm, designed for efficient statistical language model drafting, focuses on identifying frequently recurring words and phrases from the input query within the generated text. By leveraging maximal matches, it avoids the cost of generating these tokens from a larger, slower model, improving efficiency significantly. Its core function is to identify and reuse existing tokens from the input query or prior generations, reducing reliance on costly autoregressive generation, thus enhancing both speed and reducing computational cost. The algorithm’s effectiveness is particularly apparent in scenarios where repetitive phrases dominate the output, such as in question-answering tasks. While it uses a fallback bigram model for infrequent tokens, the Max-Gram’s primary strength lies in its ability to rapidly identify and re-use common phrases, maximizing speed in common usage patterns. This method directly addresses the issue of autoregressive model inefficiency by selectively using a simpler model to replace unnecessary generations. The combination with vertical and horizontal cascades further amplifies Max-Gram’s impact on overall efficiency. Therefore, Max-Gram plays a crucial role in optimizing the speed of Cascade Speculative Drafting.
Future Research#
Future research directions stemming from this Cascade Speculative Drafting (CSD) method could explore several promising avenues. Improving the efficiency of the Max-Gram algorithm is crucial, potentially through incorporating more sophisticated statistical language modeling techniques or leveraging advancements in efficient pattern matching algorithms. Investigating alternative cascading strategies beyond the vertical and horizontal cascades presented would be valuable to optimize performance under various conditions. Exploring different model selection criteria for the draft models, possibly incorporating metrics beyond simple size or speed, could lead to superior performance. Furthermore, research into adaptive algorithms to dynamically adjust the cascade depth and model selection based on the input text or generation progress would enhance the system’s robustness. Finally, comprehensive studies are needed to assess the generalization ability of CSD across a broader range of LLMs and tasks, including real-world applications. This would confirm its practicality and scalability beyond the benchmark datasets utilized in this research.
More visual insights#
More on tables
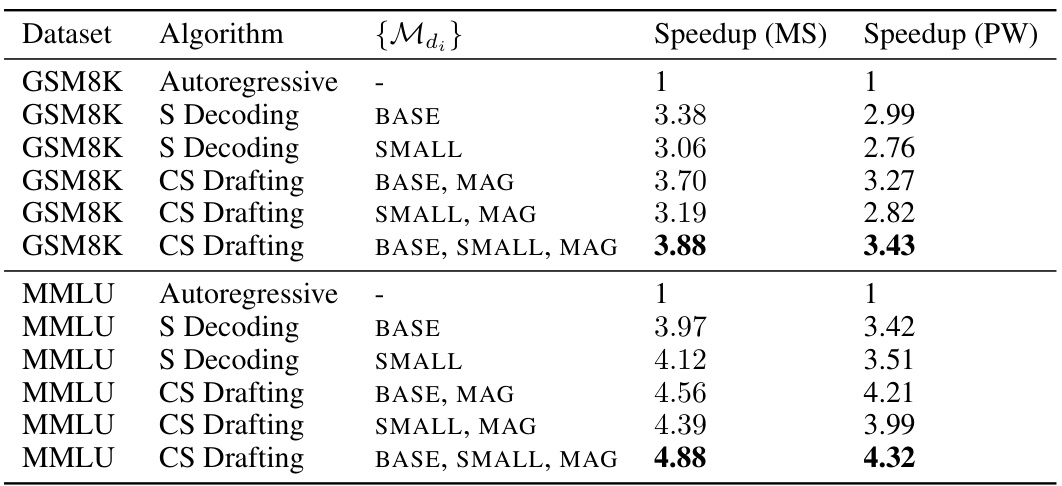
🔼 This table shows the speedup achieved by different methods (autoregressive, speculative decoding, and Cascade Speculative Drafting) on two datasets (GSM8K and MMLU) using FLAN-T5 models of different sizes. Speedup is calculated in two ways: Speedup (MS) assumes model latency is proportional to the number of parameters, while Speedup (PW) uses latency data from prior work. The table demonstrates that Cascade Speculative Drafting consistently outperforms other methods.
read the caption
Table 2: The experimental results on FLAN-T5. Speedup (MS) is the standardized walltime improvement with the assumption that the latency of each run of a model is its number of parameters (model size). Speedup (PW) is the SWI with the assumption that the latency of each run of a model is the time cost data reported from previous work [14].
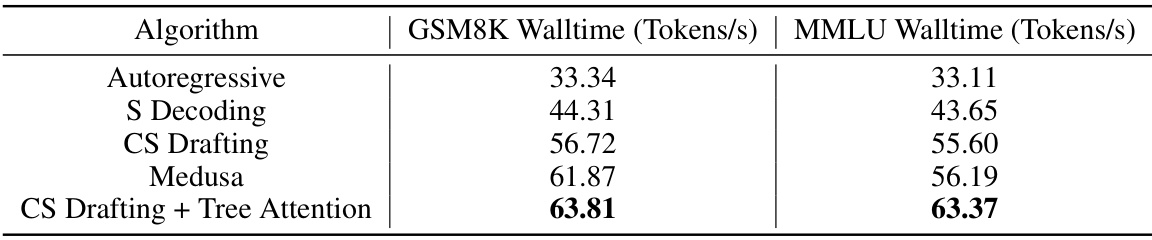
🔼 This table presents the experimental results on the Vicuna-7B model. It compares the walltime (tokens per second) achieved by different algorithms on two datasets: GSM8K and MMLU. The algorithms include autoregressive decoding, speculative decoding (S Decoding), Cascade Speculative Drafting (CS Drafting), Medusa, and CS Drafting combined with tree attention. The results show that CS Drafting with tree attention achieves the best performance, indicating the effectiveness of the proposed approach in improving language model inference speed.
read the caption
Table 3: The experimental results on Vicuna-7B.
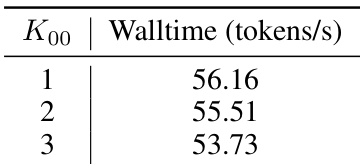
🔼 This table presents the results of experiments conducted on the GSM8K dataset using the Vicuna-7B model. The experiments varied the generation length limits, and the table shows the resulting wall-time (tokens per second) for each limit. This demonstrates the performance of the model under different conditions.
read the caption
Table 4: Results on GSM8K with Vicuna-7B under different generation length limits.

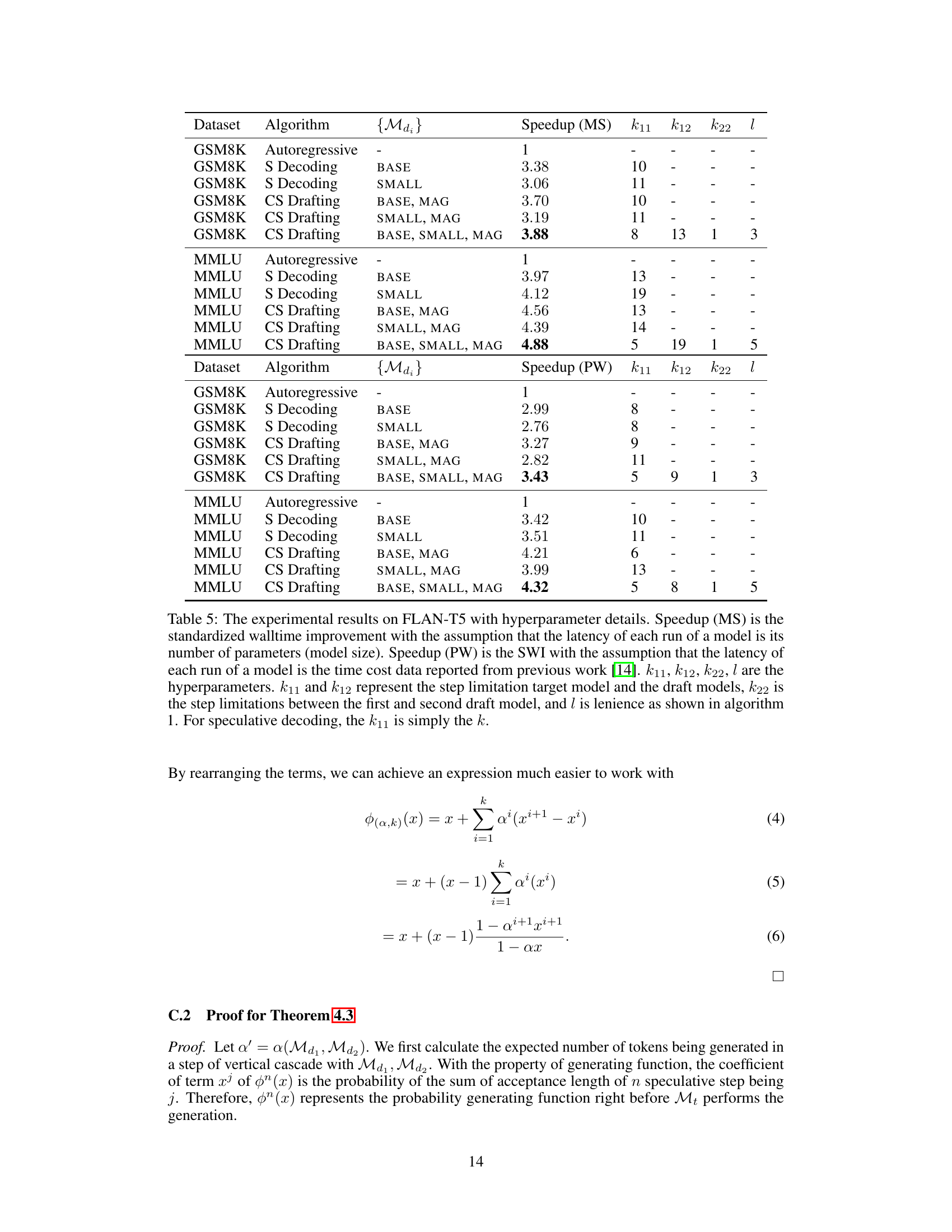
🔼 This table presents the experimental results of the Cascade Speculative Drafting (CS Drafting) algorithm on the FLAN-T5 model for two datasets: GSM8K and MMLU. It compares the speedup achieved by CS Drafting against autoregressive decoding and standard speculative decoding. The speedup is calculated using two different assumptions for model latency: one based on model size and another based on previously reported time cost data. The table also shows the hyperparameters used for each configuration of CS Drafting.
read the caption
Table 2: The experimental results on FLAN-T5. Speedup (MS) is the standardized walltime improvement with the assumption that the latency of each run of a model is its number of parameters (model size). Speedup (PW) is the SWI with the assumption that the latency of each run of a model is the time cost data reported from previous work [14].
Full paper#