↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) are powerful but prone to errors, and directly fine-tuning them is resource-intensive. Model editing offers an alternative, but current methods face challenges such as knowledge distortion and the potential for catastrophic forgetting. This paper investigates the impact of various editing methods on LLMs’ general abilities.
The study systematically evaluates multiple editing methods on diverse LLMs. Researchers discover that current model editing methods are only effective for small-scale knowledge updates. Increasing the number of edits substantially degrades performance and compromises safety. Instruction-tuned models are more robust to editing, and larger models are more resistant to this effect than smaller ones. The paper’s findings underscore the need for more reliable large-scale editing methods and emphasize the importance of rigorously evaluating the safety of edited LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals the limitations of current language model editing techniques. It challenges the prevailing assumption that these methods can easily update knowledge and highlights safety concerns. This research steers future development toward more robust and reliable editing methods, essential for responsible LLM deployment. It directly impacts research directions and practical applications of LLMs by exposing the risks and inadequacies of current editing practices.
Visual Insights#

🔼 This figure shows the impact of model editing on knowledge retention. The left panel demonstrates that model editing methods effectively update knowledge within language models by showing an example question and its correct answer after editing. The right panel illustrates the pitfalls of scaling model editing. When many edits are introduced, the model struggles to maintain the edited knowledge.
read the caption
Figure 1: Illustration about the model editing and its pitfalls in retaining edited knowledge. Left panel: model editing methods can efficiently update knowledge within language models; Right panel: when scaling editing to thousands, the model can't retain edited knowledge, see [17] for details.
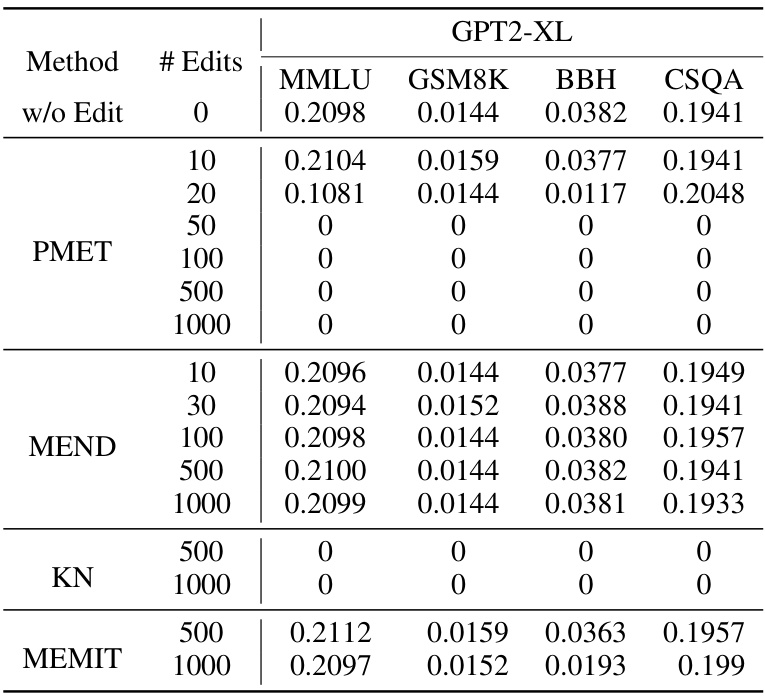
🔼 This table presents the results of experiments conducted using the GPT2-XL language model. The table shows the performance of different model editing methods (PMET, MEND, KN, MEMIT) across different numbers of edits (10, 30, 100, 500, 1000) on four benchmark tasks (MMLU, GSM8K, BBH, CSQA). The ‘w/o Edit’ row shows baseline performance with no editing applied. A value of 0 indicates complete failure after editing.
read the caption
Table 1: Evaluation results of GPT2-XL. experiments are conducted on a sever with 8 RTX 4090 GPUs.
In-depth insights#
LLM Editing Limits#
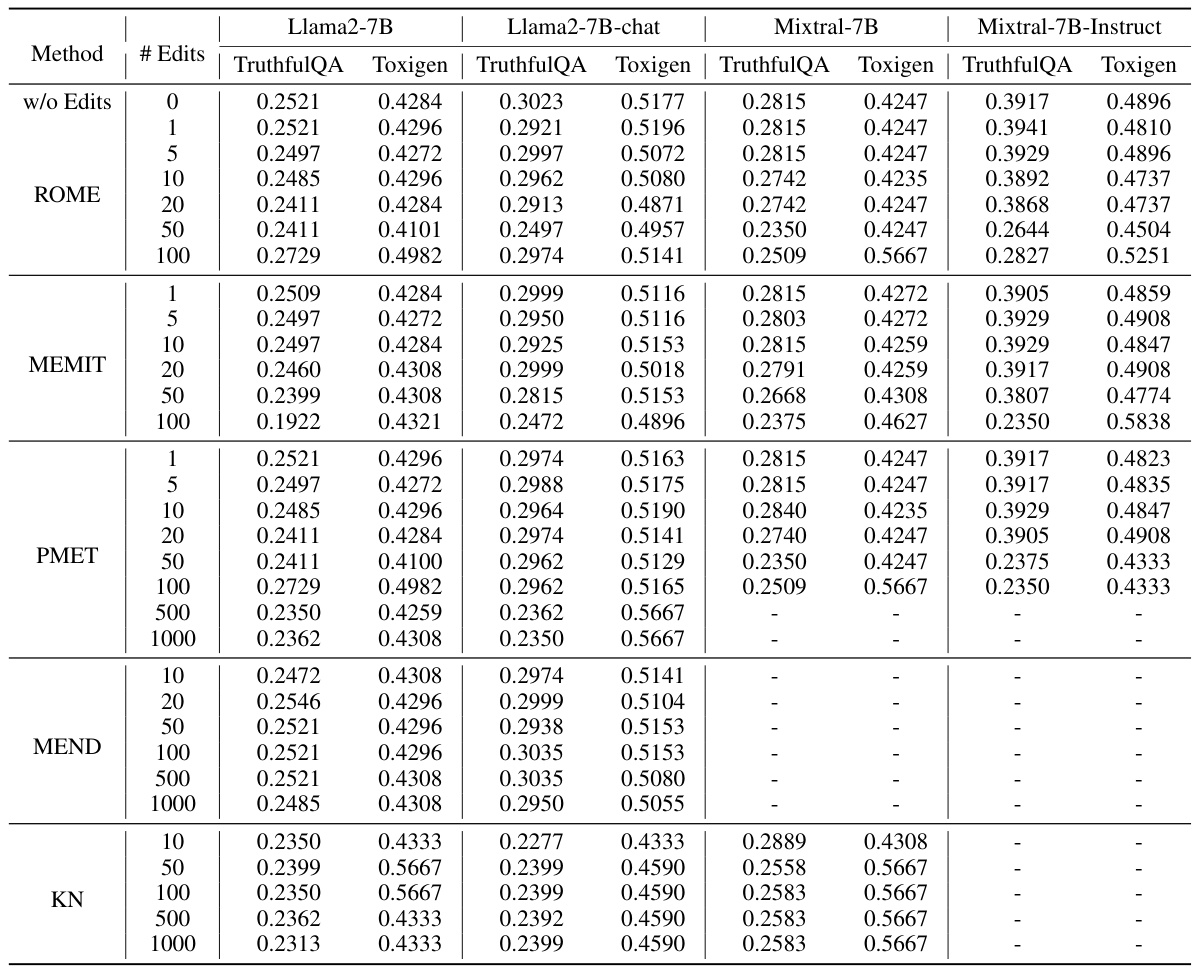
The concept of LLM editing, while promising for efficiently updating knowledge within large language models, faces significant limitations. Current methods prove effective only for small-scale updates, quickly degrading performance on general benchmarks as the number of edits increases. This suggests that these editing techniques disrupt the underlying knowledge structure of the model, causing performance deterioration and even potentially a ‘muting effect’ where the model produces empty responses. Instruction-tuned models show improved robustness compared to base models, demonstrating a slower decline in general capabilities with sequential editing. Similarly, larger language models also exhibit better resilience to this type of editing. Safety is a critical concern, with the empirical findings demonstrating that even with a small number of edits, the safety of edited LLMs can be significantly compromised, regardless of initial safety alignment. Overall, these limitations highlight the need for further research into more reliable, large-scale, and safety-conscious LLM editing methods.
Sequential Editing#
Sequential editing in large language models (LLMs) presents a unique challenge. Unlike single-shot edits that modify the model’s understanding of one specific fact, sequential editing involves making multiple edits consecutively. This process raises crucial questions about the model’s ability to retain previous updates while integrating new information, highlighting the risk of knowledge conflicts, distortion, and catastrophic forgetting. Evaluating the effects of sequential editing requires careful consideration of factors including the order of edits, the number of edits, and the method employed. The potential for negative side effects, such as a decline in the model’s overall performance or compromised safety, underscores the need for robust and reliable methods, and further research in this area is crucial. The long-term effects and practical implications of repeated model edits on the model’s internal structure remain largely unexplored, demanding further investigation to assess their suitability for real-world applications.
Instruction Tuning#
Instruction tuning is a crucial technique for aligning large language models (LLMs) with human intent. By training the model on a dataset of instructions and their corresponding desired outputs, instruction tuning enhances the model’s ability to follow complex directions and generate more relevant and helpful responses. This method addresses limitations of traditional supervised fine-tuning which may overfit to specific examples or fail to generalize well to unseen instructions. Instruction tuning, unlike simple fine-tuning, emphasizes the model’s understanding of the task’s intent, rather than just memorizing input-output pairs. The resulting models often exhibit improved performance on downstream tasks that require nuanced understanding or complex reasoning, such as question answering or text summarization. However, the effectiveness of instruction tuning is highly dependent on the quality and diversity of the instruction dataset used. A well-crafted dataset with varied instructions and high-quality responses is key to achieving significant improvements. Furthermore, instruction tuning can be computationally expensive, requiring substantial resources to train large models effectively. Despite these challenges, instruction tuning is a powerful tool for enhancing the usability and practicality of LLMs, making them more aligned with human expectations and more effective for various real-world applications. Research into more efficient and effective instruction tuning methods is an active area of development, focusing on improving dataset creation, training algorithms, and resource management.
Model Scale Effects#
Analyzing the effects of model scale on language models reveals crucial insights. Larger models, possessing more parameters, generally exhibit greater robustness to editing methods. This suggests that the intricate knowledge structures within massive models are less easily disrupted by modifications. Smaller models, conversely, display higher sensitivity to edits, often experiencing more significant performance degradation. This difference in resilience could be attributed to the increased redundancy and robustness inherent in larger architectures. The findings underscore the importance of considering model size when designing and implementing editing techniques, optimizing strategies for smaller models and expecting different outcomes based on scale.
Safety & Reliability#
A thorough analysis of a research paper’s section on safety and reliability would delve into the methods used to assess and mitigate risks associated with the technology presented. This would involve examining the metrics employed to quantify safety, such as false positive and false negative rates, and the techniques used to ensure the reliability of the system. Testing methodologies, including the types of datasets and scenarios used, would be critically evaluated. The discussion would also consider potential failure modes and their likelihood, as well as the robustness of the system under stress or adversarial conditions. A key aspect would be exploring the transparency and explainability of safety mechanisms, including how they are implemented and monitored. Finally, a comprehensive analysis would address the trade-offs between safety, reliability and other desirable system characteristics, highlighting areas where further research and development are needed to improve the overall safety and trustworthiness of the technology.
More visual insights#
More on figures
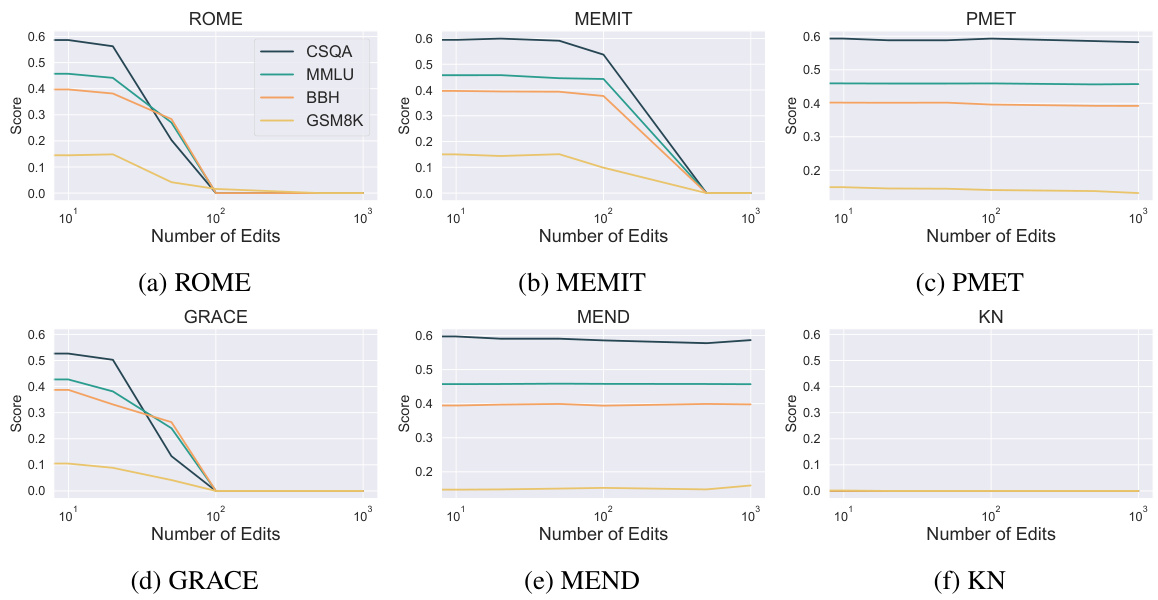
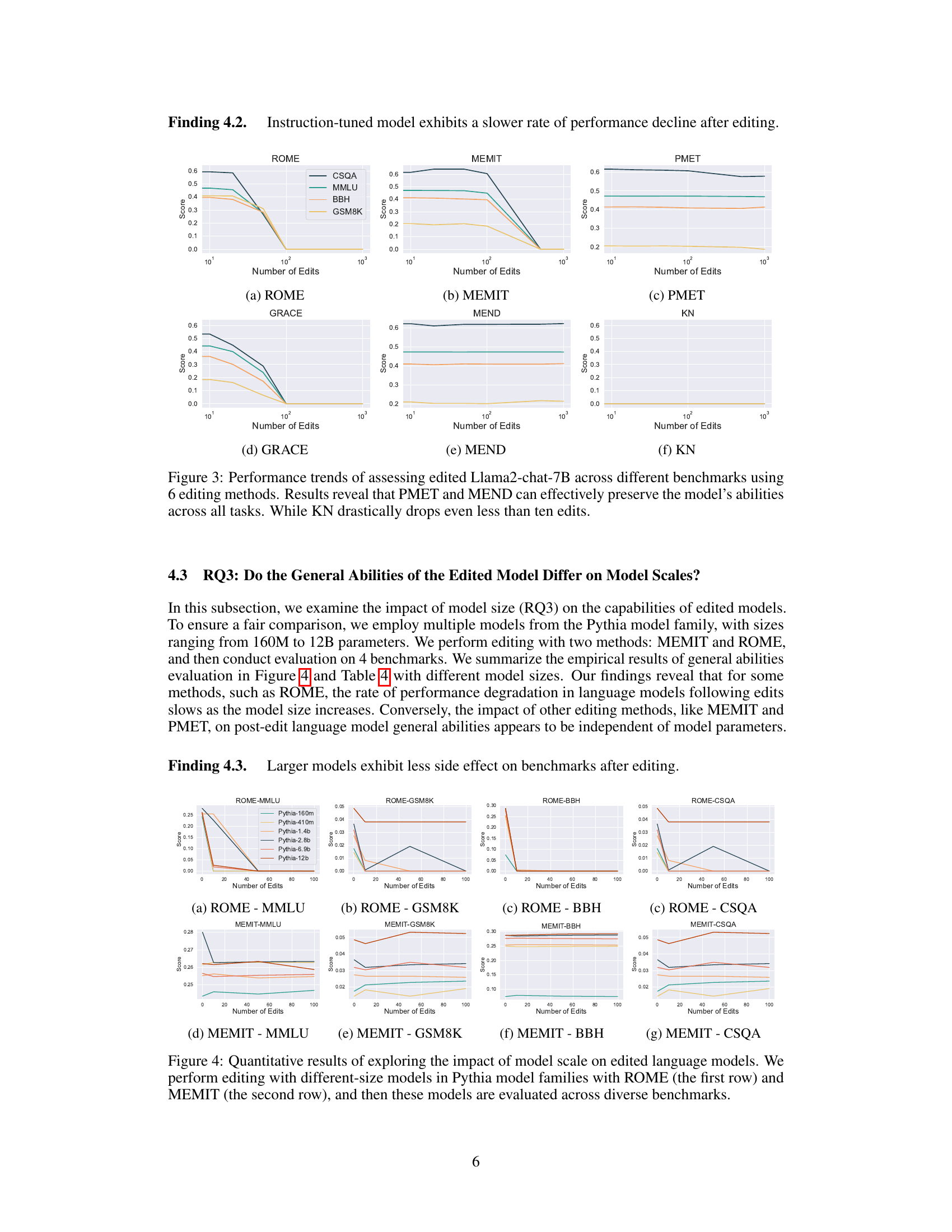
🔼 This figure displays the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base model across five benchmark tasks (CSQA, MMLU, BBH, GSM8K). The x-axis represents the number of edits applied, and the y-axis shows the model’s score on each benchmark task. The results show that PMET and MEND methods are more robust to editing and maintain high performance, even with a high number of edits. However, the KN method demonstrates a significant performance decline with a very small number of edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model's abilities across all tasks. While KN drastically drops even less than ten edits.
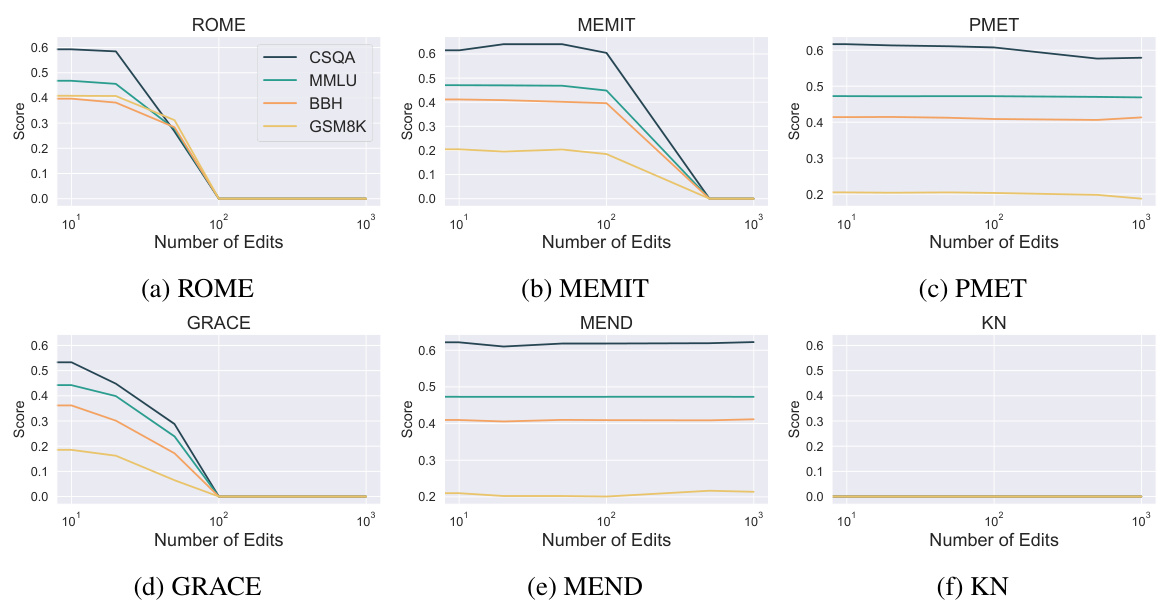
🔼 This figure displays the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base language model across five benchmark tasks (CSQA, MMLU, BBH, GSM8K). The x-axis represents the number of edits performed, while the y-axis shows the model’s score on each benchmark task. The results show that PMET and MEND are more robust to editing and maintain good performance across tasks, even with a large number of edits. In contrast, KN exhibits a drastic drop in performance with fewer than ten edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.

🔼 This figure presents the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base language model across five benchmark tasks (CSQA, MMLU, BBH, GSM8K). The x-axis represents the number of edits applied to the model, and the y-axis shows the model’s score on each benchmark. The results show that PMET and MEND methods maintain relatively high performance even with a large number of edits, whereas KN shows a significant drop in performance with only a small number of edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.

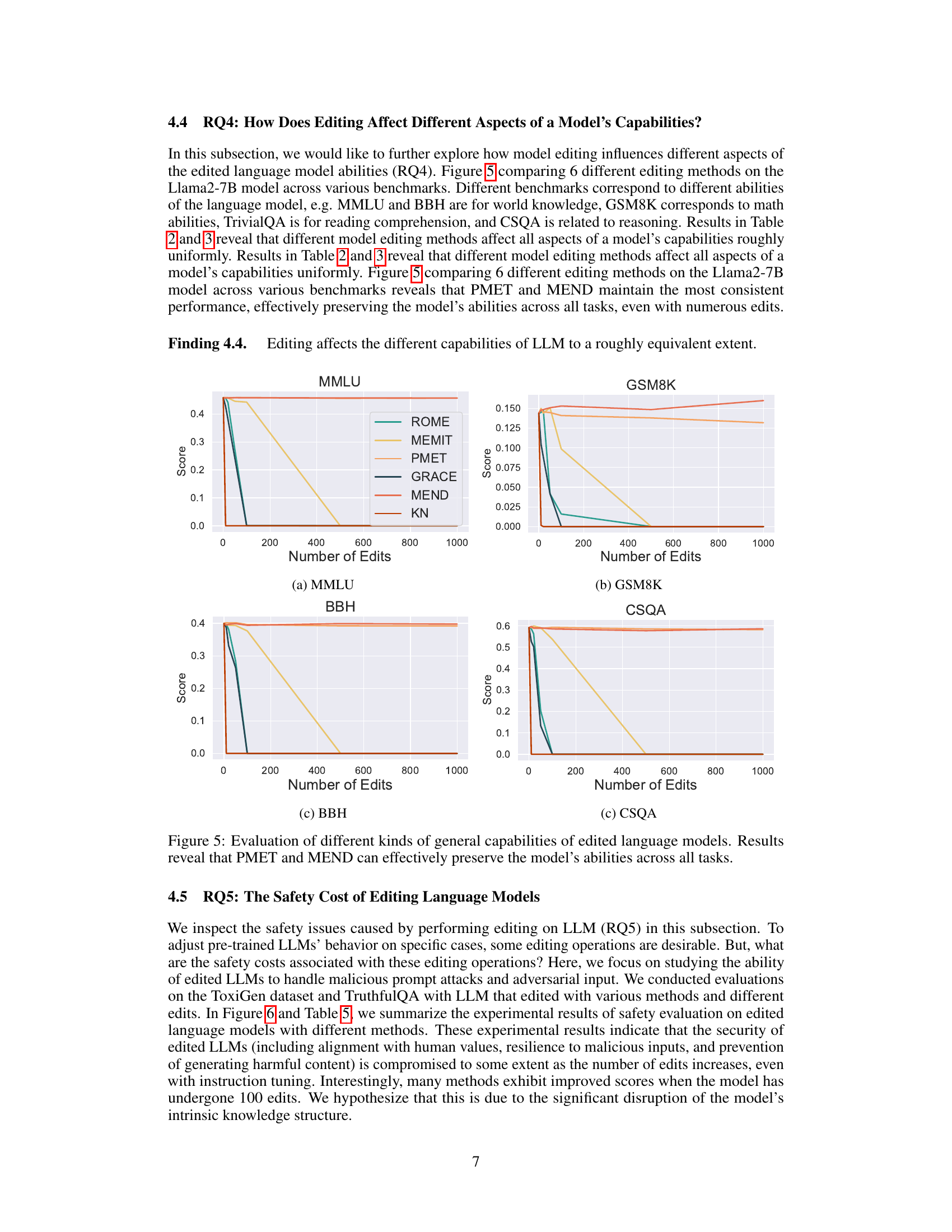
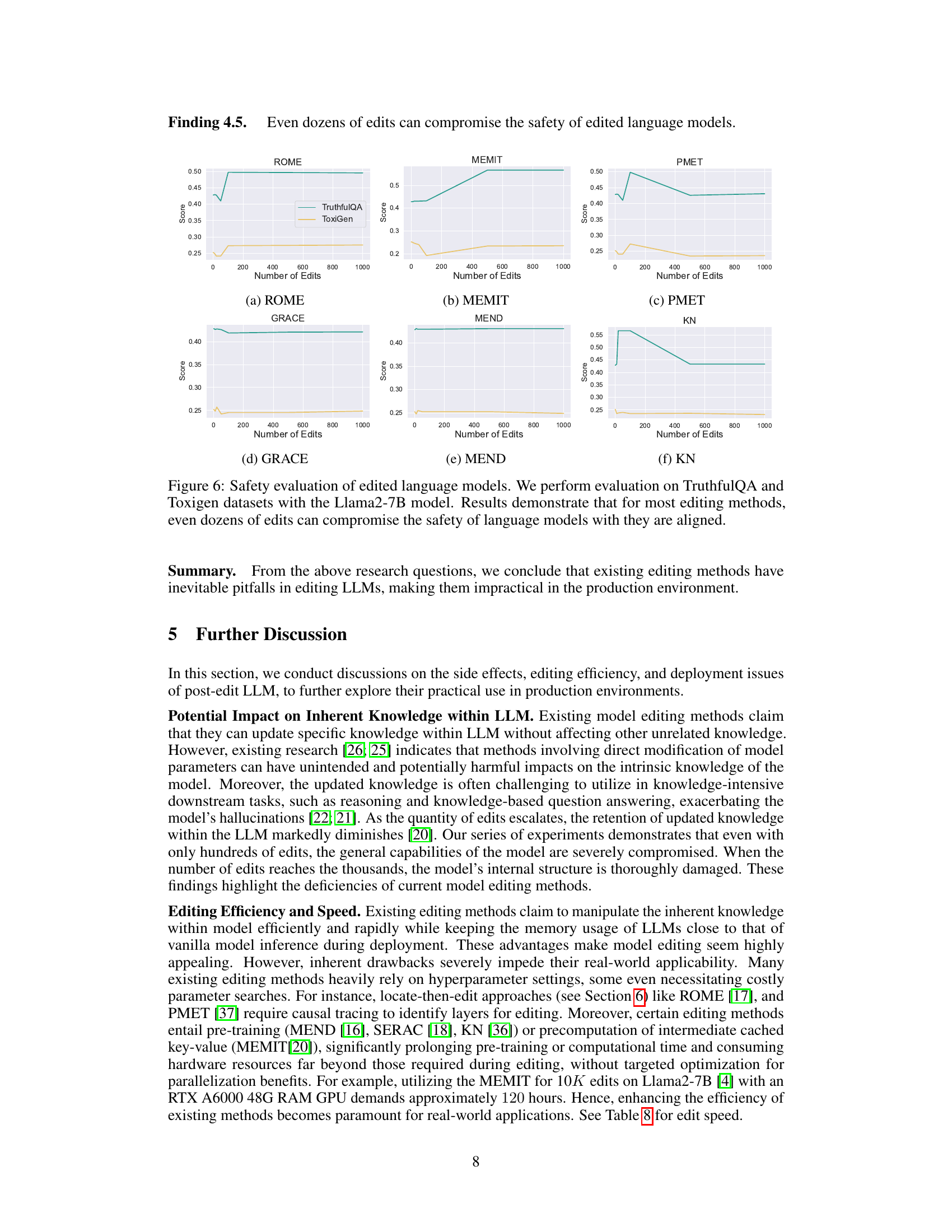
🔼 This figure displays the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base model across five benchmark tasks (MMLU, GSM8K, BBH, CSQA, and Safety). Each graph shows the performance of a single method, plotted against the number of edits. The results demonstrate that PMET and MEND consistently maintain the model’s performance across all tasks, even with increasing numbers of edits, while KN shows significant performance degradation very early. This illustrates the varying robustness of different editing methods to edits and highlights the susceptibility of some methods to performance degradation with even small numbers of edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.

🔼 This figure shows the performance trends of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base model across five benchmark tasks (CSQA, MMLU, BBH, GSM8K). The results indicate that PMET and MEND are the most effective at preserving the model’s abilities across all tasks, even with a large number of edits. In contrast, KN shows a significant performance drop with fewer than ten edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model's abilities across all tasks. While KN drastically drops even less than ten edits.

🔼 This figure shows the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base language model across five different benchmark tasks (CSQA, MMLU, BBH, GSM8K). The x-axis represents the number of edits applied to the model, and the y-axis represents the model’s performance on each benchmark task. The results indicate that PMET and MEND methods are most effective in preserving the model’s overall abilities, even with a relatively large number of edits. In contrast, the KN method shows a significant performance drop with less than 10 edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.

🔼 This figure shows the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base model across five benchmark tasks (CSQA, MMLU, BBH, GSM8K). The x-axis represents the number of edits, and the y-axis represents the score achieved on each benchmark task. The figure demonstrates that PMET and MEND methods show better performance retention even with increased number of edits, while KN shows a rapid performance drop.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.

🔼 The figure shows the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base model across five different benchmark tasks (CSQA, MMLU, BBH, GSM8K). The x-axis represents the number of edits performed, and the y-axis represents the score achieved on each benchmark. The results show that PMET and MEND are more robust to editing and maintain the model’s general abilities even with a large number of edits. In contrast, KN shows a significant performance drop after only a few edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model's abilities across all tasks. While KN drastically drops even less than ten edits.

🔼 This figure displays the performance trends of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base model across five benchmark tasks (CSQA, MMLU, BBH, GSM8K, and a combined score). The results show that PMET and MEND consistently maintain the model’s abilities across all tasks, even as the number of edits increases. In contrast, the KN method shows a significant performance drop with fewer than ten edits. This demonstrates the varying robustness of different model editing techniques when scaling the number of edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.
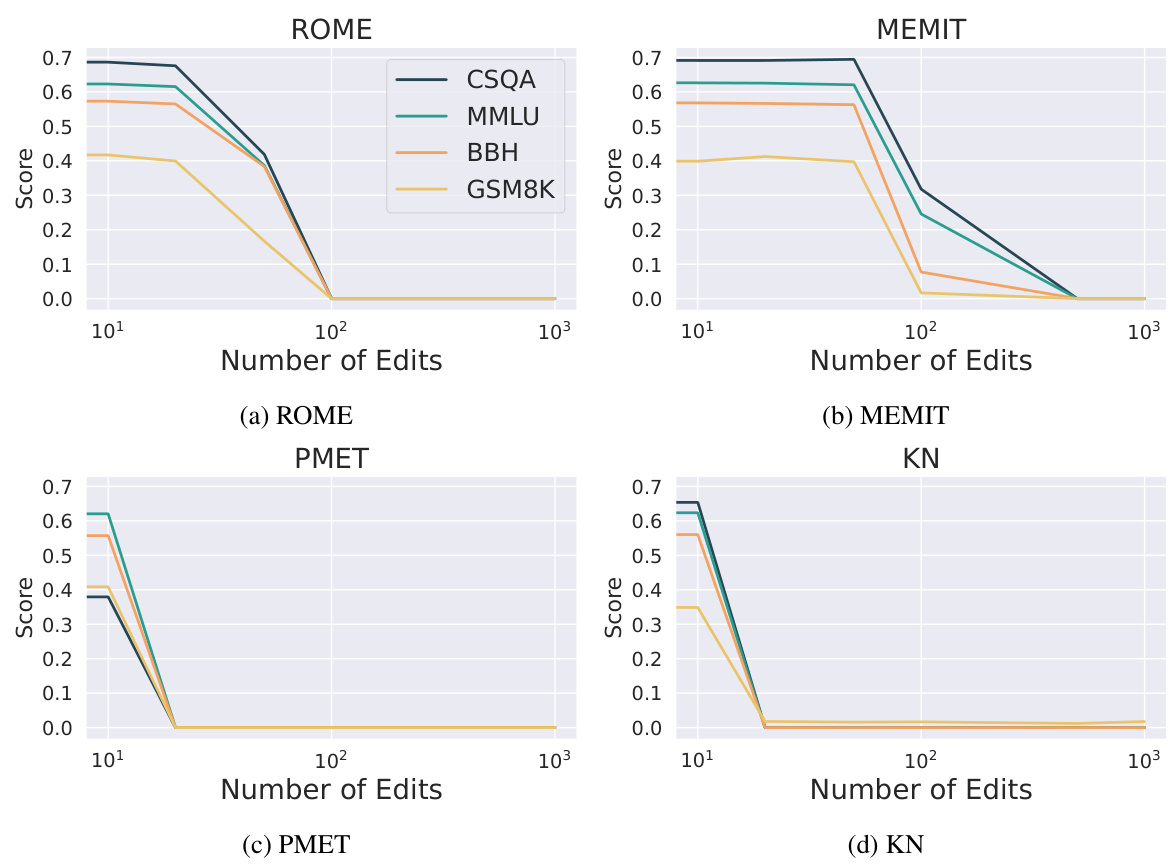
🔼 This figure displays the performance of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base language model. The models were evaluated on multiple benchmark tasks across various numbers of edits. The results show that PMET and MEND maintain good performance across all tasks even with many edits, while KN shows a significant drop in performance with only a small number of edits. The graph visually represents the robustness and limitations of different editing techniques.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.
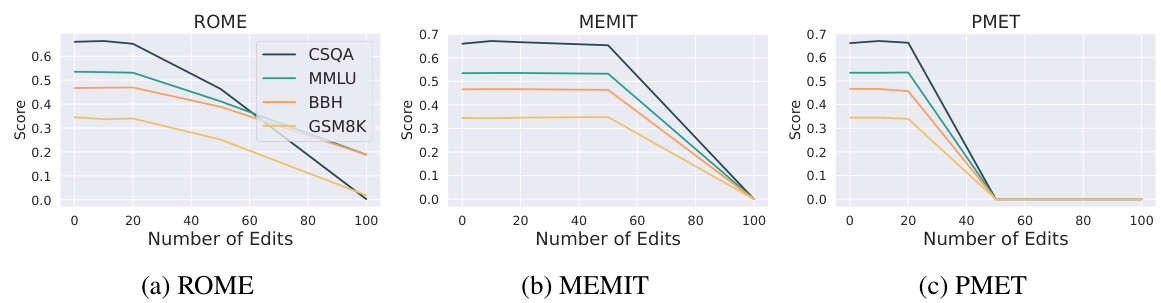
🔼 This figure displays the performance trends of six different model editing methods (ROME, MEMIT, PMET, GRACE, MEND, and KN) on the Llama2-7B base model across five different benchmark tasks (CSQA, MMLU, BBH, GSM8K). The x-axis represents the number of edits applied to the model, and the y-axis shows the performance score on each benchmark. The results demonstrate that PMET and MEND methods are more robust and effectively preserve the model’s capabilities across various tasks even with a larger number of edits, while KN shows a significant performance drop even with fewer than ten edits.
read the caption
Figure 2: Performance trends of evaluating edited Llama2-7B base model across different benchmarks using six editing methods. Results reveal that PMET and MEND can effectively preserve the model’s abilities across all tasks. While KN drastically drops even less than ten edits.
More on tables
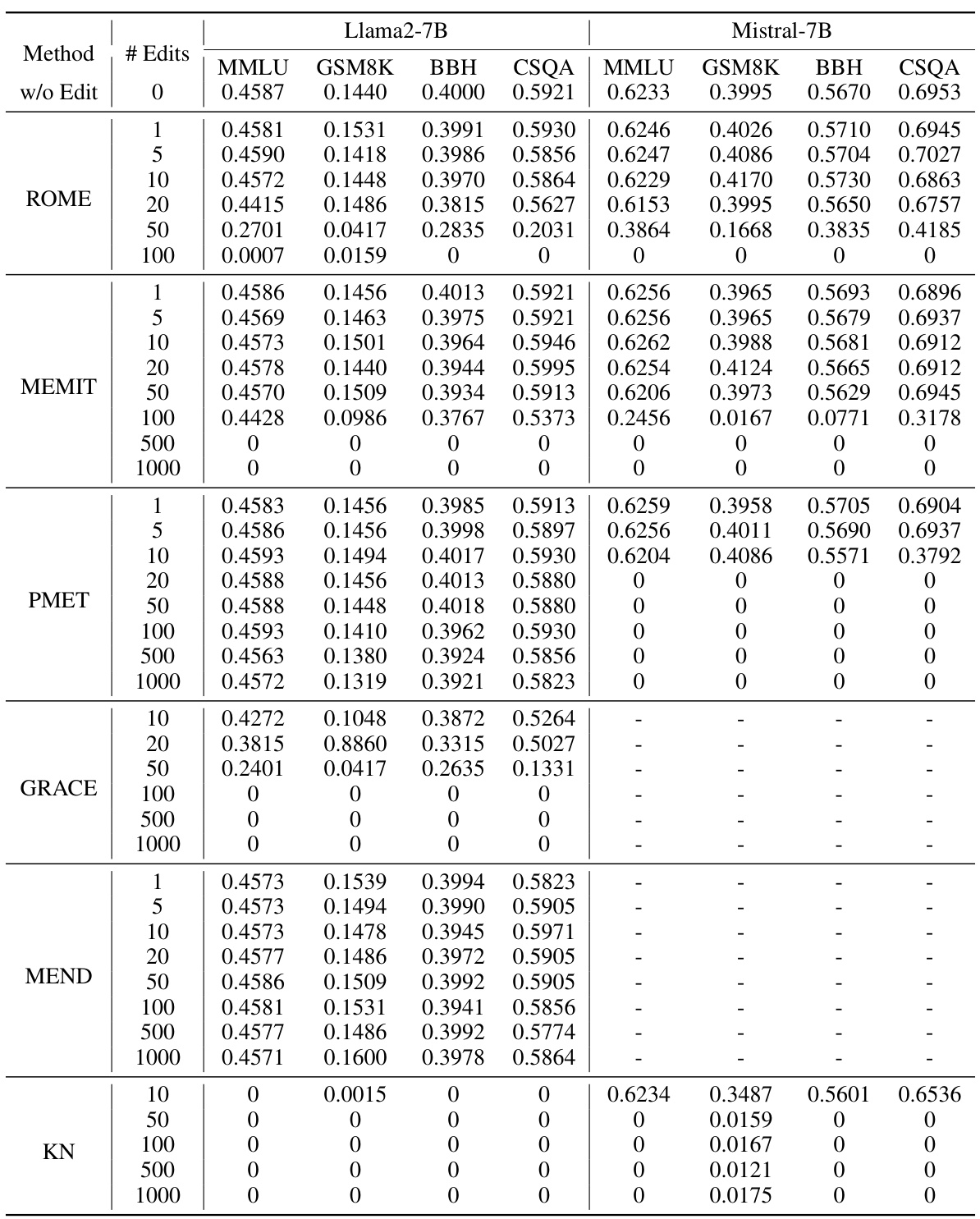
🔼 This table presents the results of evaluating different model editing methods on the general abilities of base language models (not instruction-tuned). It shows the performance (MMLU, GSM8K, BBH, CSQA) of Llama2-7B and Mistral-7B models after applying various editing methods with different numbers of edits. The higher score indicates better performance. Note that MEND and GRACE methods were not tested on Mistral-7B.
read the caption
Table 2: Results on evaluating the impact of different editing methods and numbers of edits on edited language models (base model). All editing is conducted on COUNTERFACT dataset with a fixed seed for a fair comparison. For all 4 tasks in this table, the higher score indicates a better performance. MEND and GRACE are not available for Mistral-7B.

🔼 This table presents the results of experiments evaluating the impact of different model editing methods and varying numbers of edits on the general capabilities of base language models (not instruction-tuned). The experiments were conducted using the COUNTERFACT dataset, ensuring consistent conditions across different editing approaches. The results are scored across four different benchmark tasks (MMLU, GSM8K, BBH, CSQA), with higher scores representing better performance.
read the caption
Table 2: Results on evaluating the impact of different editing methods and numbers of edits on edited language models (base model). All editing is conducted on COUNTERFACT dataset with a fixed seed for a fair comparison. For all 4 tasks in this table, the higher score indicates a better performance. MEND and GRACE are not available for Mistral-7B.

🔼 This table presents the results of evaluating the impact of different model editing methods and varying numbers of edits on the general capabilities of several base language models. The models were evaluated on four tasks (MMLU, GSM8K, BBH, CSQA) using the COUNTERFACT dataset. The table shows the performance (higher scores are better) for each method across different numbers of edits. Note that MEND and GRACE methods were not used for the Mistral-7B model.
read the caption
Table 2: Results on evaluating the impact of different editing methods and numbers of edits on edited language models (base model). All editing is conducted on COUNTERFACT dataset with a fixed seed for a fair comparison. For all 4 tasks in this table, the higher score indicates a better performance. MEND and GRACE are not available for Mistral-7B.
🔼 This table presents the results of an experiment evaluating the impact of different model editing methods and varying numbers of edits on the general capabilities of base language models. Four different evaluation tasks (MMLU, GSM8K, BBH, CSQA) were used to assess the models’ performance, and the results are shown for different editing methods (ROME, MEMIT, PMET, GRACE, MEND, KN) and numbers of edits. The table highlights that some methods are more robust to editing than others and that performance generally degrades as the number of edits increases. MEND and GRACE methods were not applicable to the Mistral-7B model.
read the caption
Table 2: Results on evaluating the impact of different editing methods and numbers of edits on edited language models (base model). All editing is conducted on COUNTERFACT dataset with a fixed seed for a fair comparison. For all 4 tasks in this table, the higher score indicates a better performance. MEND and GRACE are not available for Mistral-7B.
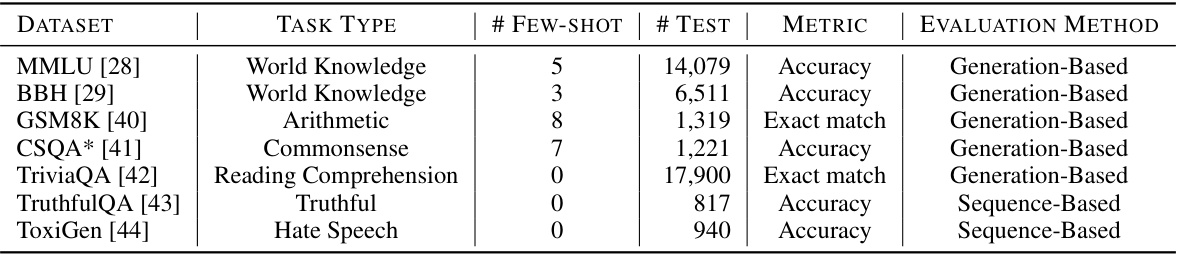
🔼 This table presents the details of the seven datasets used in the paper’s evaluation benchmark. It shows the task type for each dataset, the number of few-shot examples used for prompting, the number of test examples, the metric used for evaluation (Accuracy or Exact Match), and the evaluation method employed (Generation-Based or Sequence-Based). The table also notes that the CSQA dataset lacks publicly available test set labels, and the evaluation followed the setting described in references [80] and [78].
read the caption
Table 6: The statistics of the datasets used in this paper. # Ex. are the number of few-shot chain-of-thought exemplars used to prompt each task in evaluation. # TEST denote the number of training data and test data, respectively. *: CSQA do not have publicly available test set labels, so we simply follow the setting by [80; 78] to evaluate the performance of the development set.

🔼 This table presents the results of evaluating the impact of various model editing methods on the general capabilities of base language models (not instruction-tuned). It shows the performance (MMLU, GSM8K, BBH, CSQA) of Llama2-7B and Mistral-7B models after applying different editing methods (ROME, MEMIT, PMET, GRACE, MEND, KN) with varying numbers of edits (1, 5, 10, 20, 50, 100, 500, 1000). Higher scores indicate better performance. Note that MEND and GRACE methods were not evaluated for the Mistral-7B model.
read the caption
Table 2: Results on evaluating the impact of different editing methods and numbers of edits on edited language models (base model). All editing is conducted on COUNTERFACT dataset with a fixed seed for a fair comparison. For all 4 tasks in this table, the higher score indicates a better performance. MEND and GRACE are not available for Mistral-7B.

🔼 This table shows the performance of different language models (Llama2-7B and Mistral-7B) after applying different editing methods with varying numbers of edits. The performance is measured across four different tasks (MMLU, GSM8K, BBH, CSQA). The results help to understand how different editing methods affect the models’ general abilities and how the number of edits impacts performance.
read the caption
Table 2: Results on evaluating the impact of different editing methods and numbers of edits on edited language models (base model). All editing is conducted on COUNTERFACT dataset with a fixed seed for a fair comparison. For all 4 tasks in this table, the higher score indicates a better performance. MEND and GRACE are not available for Mistral-7B.
Full paper#